
Повторяться, но каждый раз по-новому – разве не это есть искусство?
Станислав Ежи Лец, из книги «Непричёсанные мысли»
Словарь определяет репликацию как процесс поддержания двух (или более) наборов данных в согласованном состоянии. Что такое «согласованное состояние наборов данных» – отдельный большой вопрос, поэтому переформулируем определение проще: процесс изменения одного набора данных, называемого репликой, в ответ на изменения другого набора данных, называемого основным. Совсем не обязательно наборы при этом будут одинаковыми.

Поддержка репликации баз данных – одна из важнейших задач администратора: почти у каждой сколько-нибудь важной базы данных есть реплика, а то и не одна.
Среди задач, решаемых репликацией, можно назвать как минимум
- поддержку резервной базы данных на случай потери основной;
- снижение нагрузки на базу за счёт переноса части запросов на реплики;
- перенос данных в архивные или аналитические системы.
В этой статье я расскажу о видах репликации и о том, какие задачи решает каждый вид репликации.
Можно выделить три подхода к репликации:
- Блочная репликация на уровне системы хранения данных;
- Физическая репликация на уровне СУБД;
- Логическая репликация на уровне СУБД.
Блочная репликация
При блочной репликации каждая операция записи выполняется не только на основном диске, но и на резервном. Таким образом тому на одном массиве соответствует зеркальный том на другом массиве, с точностью до байта повторяющий основной том:
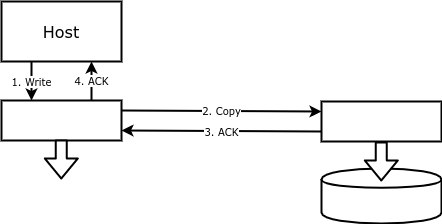
К достоинствам такой репликации можно отнести простоту настройки и надёжность. Записывать данные на удалённый диск может либо дисковый массив, либо нечто (устройство или программное обеспечение), стоящее между хостом и диском.
Дисковые массивы могут быть дополнены опциями, позволяющими включить репликацию. Название опции зависит от производителя массива:
| Производитель | Торговая марка |
|---|---|
| EMC | SRDF (Symmetrix Remote Data Facility) |
| IBM | Metro Mirror – синхронная репликация Global Mirror – асинхронная репликация |
| Hitachi | TrueCopy |
| Hewlett-Packard | Continuous Access |
| Huawei | HyperReplication |
Если дисковый массив не способен реплицировать данные, между хостом и массивом может быть установлен агент, осуществляющей запись на два массива сразу. Агент может быть как отдельным устройством (EMC VPLEX), так и программным компонентом (HPE PeerPersistence, Windows Server Storage Replica, DRBD). В отличие от дискового массива, который может работать только с таким же массивом или, как минимум, с массивом того же производителя, агент может работать с совершенно разными дисковыми устройствами.
Главное назначение блочной репликации – обеспечение отказоустойчивости. Если база данных потеряна, то можно перезапустить её с использованием зеркального тома.
Блочная репликация хороша своей универсальностью, но за универсальность приходится платить.
Во-первых, никакой сервер не может работать с зеркальным томом, поскольку его операционная система не может управлять записью на него; с точки зрения наблюдателя данные на зеркальном томе появляются сами собой. В случае аварии (отказ основного сервера или всего ЦОДа, где находится основной сервер) следует остановить репликацию, размонтировать основной том и смонтировать зеркальный том. Как только появится возможность, следует перезапустить репликацию в обратном направлении.
В случае использования агента все эти действия выполнит агент, что упрощает настройку, но не уменьшает время переключения.
Во-вторых, сама СУБД на резервном сервере может быть запущена только после монтирования диска. В некоторых операционных системах, например, в Solaris, память под кеш при выделении размечается, и время разметки пропорционально объёму выделяемой памяти, то есть старт экземпляра будет отнюдь не мгновенным. Плюс ко всему кеш после рестарта будет пуст.
В-третьих, после запуска на резервном сервере СУБД обнаружит, что данные на диске неконсистентны, и нужно потратить значительное время на восстановление с применением журналов повторного выполнения: сначала повторить те транзакции, результаты которых сохранились в журнале, но не успели сохраниться в файлы данных, а потом откатить транзакции, которые к моменту сбоя не успели завершиться.
Блочная репликация не может использоваться для распределения нагрузки, а для обновления хранилища данных используется похожая схема, когда зеркальный том находится в том же массиве, что и основной. У EMC и HP эта схема называется BCV, только EMC расшифровывает аббревиатуру как Business Continuance Volume, а HP – как Business Copy Volume. У IBM на этот случай нет специальной торговой марки, эта схема так и называется – «mirrored volume».

В массиве создаются два тома, и операции записи синхронно выполняются на обоих (A). В определённое время зеркало разрывается (B), то есть тома становятся независимыми. Зеркальный том монтируется к серверу, выделенному для обновления хранилища, и на этом сервере поднимается экземпляр базы данных. Экземпляр будет подниматься так же долго, как и при восстановлении с помощью блочной репликации, но это время может быть существенно уменьшено за счёт разрыва зеркала в период минимальной нагрузки. Дело в том, что разрыв зеркала по своим последствиям эквивалентен аварийному завершению СУБД, а время восстановление при аварийном завершении существенно зависит от количества активных транзакций в момент аварии. База данных, предназначенная для выгрузки, доступна как на чтение, так и на запись. Идентификаторы всех блоков, изменённых после разрыва зеркала как на основном, так и на зеркальном томе, сохраняются в специальной области Block Change Tracking – BCT.
После окончания выгрузки зеркальный том размонтируется (С), зеркало восстанавливается, и через некоторое время зеркальный том вновь догоняет основной и становится его копией.
Физическая репликация
Журналы (redo log или write-ahead log) содержат все изменения, которые вносятся в файлы базы данных. Идея физической репликации состоит в том, что изменения из журналов повторно выполняются в другой базе (реплике), и таким образом данные в реплике повторяют данные в основной базе байт-в-байт.
Возможность использовать журналы базы данных для обновления реплики появилась в релизе Oracle 7.3, который вышел в 1996 году, а уже в релизе Oracle 8i доставка журналов с основной базы в реплику была автоматизирована и получила название DataGuard. Технология оказалась настолько востребованной, что сегодня механизм физической репликации есть практически во всех современных СУБД.
| СУБД | Опция репликации |
|---|---|
| Oracle | Active DataGuard |
| IBM DB2 | HADR |
| Microsoft SQL Server | Log shipping/Always On |
| PostgreSQL | Log shipping/Streaming replication |
| MySQL | Alibaba physical InnoDB replication |
Опыт показывает, что если использовать сервер только для поддержания реплики в актуальном состоянии, то ему достаточно примерно 10% процессорной мощности сервера, на котором работает основная база.
Журналы СУБД не предназначены для использования вне этой платформы, их формат не документируется и может меняться без предупреждения. Отсюда совершенно естественное требование, что физическая репликация возможна только между экземплярами одной и той же версии одной той же СУБД. Отсюда же возможные ограничения на операционную систему и архитектуру процессора, которые тоже могут влиять на формат журнала.
Естественно, никаких ограничений на модели СХД физическая репликация не накладывает. Более того, файлы в базе-реплике могут располагаться совсем по-другому, чем на базе-источнике – надо лишь описать соответствие между томами, на которых лежат эти файлы.
Oracle DataGuard позволяет удалить часть файлов из базы-реплики – в этом случае изменения в журналах, относящиеся к этим файлам, будут проигнорированы.
Физическая репликация базы данных имеет множество преимуществ перед репликацией средствами СХД:
- объём передаваемых данных меньше за счёт того, что передаются только журналы, но не файлы с данными; эксперименты показывают уменьшение трафика в 5-7 раз;
- переключение на резервную базу происходит значительно быстрее: экземпляр-реплика уже поднят, поэтому при переключении ему нужно лишь откатить активные транзакции; более того, к моменту сбоя кеш реплики уже прогрет;
- на реплике можно выполнять запросы, сняв тем самым часть нагрузки с основной базы. В частности, реплику можно использовать для создания резервных копий.
Возможность читать данные с реплики появилась в 2007 году в релизе Oracle 11g – именно на это указывает эпитет «active», добавленный к названию технологии DataGuard. В других СУБД возможность чтения с реплики также есть, но в названии это никак не отражено.
Запись данных в реплику невозможна, поскольку изменения в неё приходят побайтно, и реплика не может обеспечить конкурентное исполнение своих запросов. Oracle Active DataGuard в последних релизах разрешает запись в реплику, но это не более чем «сахар»: на самом деле изменения выполняются на основной базе, а клиент ждёт, пока они докатятся до реплики.
В случае повреждения файла в основной базе можно просто скопировать соответствующий файл с реплики (прежде, чем делать такое со своей базой, внимательно изучите руководство администратора!). Файл на реплике может быть не идентичен файлу в основной базе: дело в том, что когда файл расширяется, новые блоки в целях ускорения ничем не заполняются, и их содержимое случайно. База может использовать не всё пространство блока (например, в блоке может оставаться свободное место), но содержимое использованного пространства совпадает с точностью до байта.
Физическая репликация может быть как синхронной, так и асинхронной. При асинхронной репликации всегда есть некий набор транзакций, которые завершены на основной базе, но ещё не дошли до резервной, и в случае перехода на резервную базу при сбое основной эти транзакции будут потеряны. При синхронной репликации завершение операции commit означает, что все журнальные записи, относящиеся к данной транзакции, переданы на реплику. Важно понимать, что получение репликой журнала не означает применения изменений к данным. При потере основной базы транзакции не будут потеряны, но если приложение пишет данные в основную базу и считывает их из реплики, то у него есть шанс получить старую версию этих данных.
В PostgreSQL есть возможность сконфигурировать репликацию так, чтобы commit завершался только после применения изменений к данным реплики (опция
synchronous_commit = remote_apply), а в Oracle можно сконфигурировать всю реплику или отдельные сессии, чтобы запросы выполнялись только если реплика не отстаёт от основной базы (STANDBY_MAX_DATA_DELAY=0). Однако всё же лучше проектировать приложение так, чтобы запись в основную базу и чтение из реплик выполнялись в разных модулях.При поиске ответа на вопрос, какой режим выбрать, синхронный или асинхронный, нам на помощь приходят маркетологи Oracle. DataGuard предусматривает три режима, каждый из которых максимизирует один из параметров – сохранность данных, производительность, доступность – за счёт остальных:
- Maximum performance: репликация всегда асинхронная;
- Maximum protection: репликация синхронная; если реплика не отвечает, commit на основной базе не завершается;
- Maximum availability: репликация синхронная; если реплика не отвечает, то репликация переключается в асинхронный режим и, как только связь восстанавливается, реплика догоняет основную базу и репликация снова становится синхронной.
Несмотря на бесспорные преимущества репликации средствами БД над блочной репликацией, администраторы во многих компаниях, особенно со старыми традициями надёжности, до сих пор очень неохотно отказываются от блочной репликации. Причин у этого две.
Во-первых, в случае репликации средствами дискового массива трафик идёт не по сети передачи данных (LAN), а по сети хранения данных (Storage Area Network). Зачастую в инфраструктурах, построенных давно, SAN гораздо надёжнее и производительнее, чем сеть передачи данных.
Во-вторых, синхронная репликация средствами СУБД стала надёжной относительно недавно. В Oracle прорыв произошёл в релизе 11g, который вышел в 2007 году, а в других СУБД синхронная репликация появилась ещё позже. Конечно, 10 лет по меркам сферы информационных технологий – срок не такой уж маленький, но когда речь идёт о сохранности данных, некоторые администраторы до сих пор руководствуются принципом «как бы чего не вышло»…
Логическая репликация
Все изменения в базе данных происходят в результате вызовов её API – например, в результате выполнения SQL-запросов. Очень заманчивой кажется идея выполнять одну и ту же последовательность запросов на двух разных базах. Для репликации необходимо придерживаться двух правил:
- Нельзя начинать транзакцию, пока не завершены все транзакции, которые должны закончиться раньше. Так на рисунке ниже нельзя запускать транзакцию D, пока не завершены транзакции A и B.
- Нельзя завершать транзакцию, пока не начаты все транзакции, которые должны закончиться до завершения текущей транзакции. Так на рисунке ниже даже если транзакция B выполнилась мгновенно, завершить её можно только после того, как начнётся транзакция C.
Репликация команд (statement-based replication) реализована, например, в MySQL. К сожалению, эта простая схема не приводит к появлению идентичных наборов данных – тому есть две причины.
Во-первых, не все API детерминированы. Например, если в SQL-запросе встречается функция now() или sysdate(), возвращающая текущее время, то на разных серверах она вернёт разный результат – из-за того, что запросы выполняются не одновременно. Кроме того, к различиям могут привести разные состояния триггеров и хранимых функций, разные национальные настройки, влияющие на порядок сортировки, и многое другое.
Во-вторых, репликацию, основанную на параллельном исполнении команд, невозможно корректно приостановить и перезапустить.
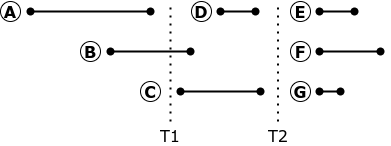
Если репликация остановлена в момент T1 транзакция B должна быть прервана и откачена. При перезапуске репликации исполнение транзакции B может привести реплику к состоянию, отличному от состояния базы-источника: на источнике транзакция B началась до того, как закончилась транзакция A, а значит, она не видела изменений, сделанных транзакцией A.
Репликация запросов может быть остановлена и перезапущена только в момент T2, когда в базе нет ни одной активной транзакции. Разумеется, на сколько-нибудь нагруженной промышленной базе таких моментов не бывает.
Обычно для логической репликации используют детерминированные запросы. Детерминированность запроса обеспечивается двумя свойствами:
- запрос обновляет (или вставляет, или удаляет) единственную запись, идентифицируя её по первичному (или уникальному) ключу;
- все параметры запроса явно заданы в самом запросе.
В отличие от репликации команд (statement-based replication) такой подход называется репликацией записей (row-based replication).
Предположим, что у нас есть таблица сотрудников со следующими данными:
| ID | Name | Dept | Salary |
|---|---|---|---|
| 3817 | Иванов Иван Иванович | 36 | 1800 |
| 2274 | Петров Пётр Петрович | 36 | 1600 |
| 4415 | Кузнецов Семён Андреевич | 41 | 2100 |
Над этой таблицей была выполнена следующая операция:
update employee set salary = salary*1.2 where dept=36;Для того, чтобы корректно реплицировать данные, в реплике будут выполнены такие запросы:
update employee set salary = 2160 where id=3817;
update employee set salary = 1920 where id=2274;Запросы приводят к тому же результату, что и на исходной базе, но при этом не эквивалентны выполненным запросам.
База-реплика открыта и доступна не только на чтение, но и на запись. Это позволяет использовать реплику для выполнения части запросов, в том числе для построения отчётов, требующих создания дополнительных таблиц или индексов.
Важно понимать, что логическая реплика будет эквивалентна исходной базе только в том случае, если в неё не вносится никаких дополнительных изменений. Например, если в примере выше в реплике добавить в 36 отдел Сидорова, то он повышения не получит, а если Иванова перевести из 36 отдела, то он получит повышение, несмотря ни на что.
Логическая репликация предоставляет ряд возможностей, отсутствующих в других видах репликации:
- настройка набора реплицируемых данных на уровне таблиц (при физической репликации – на уровне файлов и табличных пространств, при блочной репликации – на уровне томов);
- построение сложных топологий репликации – например, консолидация нескольких баз в одной или двунаправленная репликация;
- уменьшение объёма передаваемых данных;
- репликация между разными версиями СУБД или даже между СУБД разных производителей;
- обработка данных при репликации, в том числе изменение структуры, обогащение, сохранение истории.
Есть и недостатки, которые не позволяют логической репликации вытеснить физическую:
- все реплицируемые данные обязаны иметь первичные ключи;
- логическая репликация поддерживает не все типы данных – например, возможны проблемы с BLOB’ами.
- логическая репликация на практике не бывает полностью синхронной: время от получения изменений до их применения слишком велико, чтобы основная база могла ждать;
- логическая репликация создаёт большую нагрузку на реплику;
- при переключении приложение должно иметь возможность убедиться, что все изменения с основной базы, применены на реплике – СУБД зачастую сама не может этого определить, так как для неё режимы реплики и основной базы эквивалентны.
Два последних недостатка существенно ограничивают использование логической реплики как средства отказоустойчивости. Если один запрос в основной базе изменяет сразу много строк, реплика может существенно отставать. А возможность смены ролей требует недюжинных усилий как со стороны разработчиков, так и со стороны администраторов.
Есть несколько способов реализации логической репликации, и каждый из этих способов реализует одну часть возможностей и не реализует другую:
- репликация триггерами;
- использование журналов СУБД;
- использование программного обеспечения класса CDC (change data capture);
- прикладная репликация.
Репликация триггерами
Триггер – хранимая процедура, которая исполняется автоматически при каком-либо действии по модификации данных. Триггеру, который вызывается при изменении каждой записи, доступны ключ этой записи, а также старые и новые значения полей. При необходимости триггер может сохранять новые значения строк в специальную таблицу, откуда специальный процесс на стороне реплики будет их вычитывать. Объём кода в триггерах велик, поэтому существуют специальное программное обеспечение, генерирующее такие триггеры, например, «Репликация слиянием» (merge replication) – компонент Microsoft SQL Server или Slony-I – отдельный продукт для репликации PostgreSQL.
Сильные стороны репликации триггерами:
- независимость от версий основной базы и реплики;
- широкие возможности преобразования данных.
Недостатки:
- нагрузка на основную базу;
- большая задержка при репликации.
Использование журналов СУБД
Сами СУБД также могут предоставлять возможности логической репликации. Источником данных, как и для физической репликации, являются журналы. К информации о побайтовом изменении добавляется также информация об изменённых полях (supplemental logging в Oracle,
wal_level = logical в PostgreSQL), а также значение уникального ключа, даже если он не меняется. В результате объём журналов БД увеличивается – по разным оценкам от 10 до 15%.Возможности репликации зависят от реализации в конкретной СУБД – если в Oracle можно построить logical standby, то в PostgreSQL или Microsoft SQL Server встроенными средствами платформы можно развернуть сложную систему взаимных подписок и публикаций. Кроме того, СУБД предоставляет встроенные средства мониторинга и управления репликацией.
К недостаткам данного подхода можно отнести увеличение объёма журналов и возможное увеличение трафика между узлами.
Использование CDC
Существует целый класс программного обеспечения, предназначенного для организации логической репликации. Это ПО называется CDC, change data capture. Вот список наиболее известных платформ этого класса:
- Oracle GoldenGate (компания GoldenGate приобретена в 2009 году);
- IBM InfoSphere Data Replication (ранее – InfoSphere CDC; ещё ранее – DataMirror Transformation Server, компания DataMirror приобретена в 2007 году);
- VisionSolutions DoubleTake/MIMIX (ранее – Vision Replicate1);
- Qlik Data Integration Platform (ранее – Attunity);
- Informatica PowerExchange CDC;
- Debezium;
- StreamSets Data Collector...
В задачу платформы входит чтение журналов базы данных, преобразование информации, передача информации на реплику и применение. Как и в случае репликации средствами самой СУБД, журнал должен содержать информацию об изменённых полях. Использование дополнительного приложения позволяет «на лету» выполнять сложные преобразования реплицируемых данных и строить достаточно сложные топологии репликации.
Сильные стороны:
- возможность репликации между разными СУБД, в том числе загрузка данных в отчётные системы;
- широчайшие возможности обработки и преобразования данных;
- минимальный трафик между узлами – платформа отсекает ненужные данные и может сжимать трафик;
- встроенные возможности мониторинга состояния репликации.
Недостатков не так много:
- увеличение объёма журналов, как при логической репликации средствами СУБД;
- новое ПО – сложное в настройке и/или с дорогими лицензиями.
Именно CDC-платформы традиционно используются для обновления корпоративных хранилищ данных в режиме, близком к реальному времени.
Прикладная репликация
Наконец, ещё один способ репликации – формирование векторов изменений непосредственно на стороне клиента. Клиент должен формировать детерминированные запросы, затрагивающие единственную запись. Добиться этого можно, используя специальную библиотеку работы с базой данных, например, Borland Database Engine (BDE) или Hibernate ORM.
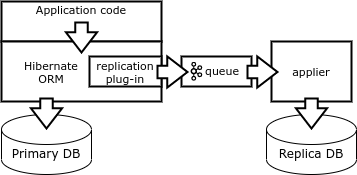
Когда приложение завершает транзакцию, подключаемый модуль Hibernate ORM записывает вектор изменений в очередь и выполняет транзакцию в базе данных. Специальный процесс-репликатор вычитывает векторы из очереди и выполняет транзакции в базе-реплике.
Этот механизм хорош для обновления отчётных систем. Может он использоваться и для обеспечения отказоустойчивости, но в этом случае в приложении должен быть реализован контроль состояния репликации.
Традиционно – сильные и слабые стороны данного подхода:
- возможность репликации между разными СУБД, в том числе загрузка данных в отчётные системы;
- возможность обработки и преобразования данных, мониторинга состояния и т. д.;
- минимальный трафик между узлами – платформа отсекает ненужные данные и может сжимать трафик;
- полная независимость от базы данных – как от формата, так и от внутренних механизмов.
Достоинства этого способа бесспорны, однако есть два очень серьёзных недостатка:
- ограничения на архитектуру приложения;
- огромный объём собственного кода, обеспечивающего репликацию.
Так что же лучше?
Однозначного ответа на этот вопрос, как и на многие другие, не существует. Но надеюсь, что таблица ниже поможет сделать правильный выбор для каждой конкретной задачи:
| Блочная репликация СХД | Блочная репликация агентом | Физическая репликация | Логическая репликация СУБД | Репликация триггерами | CDC | Прикладная репликация |
|
|---|---|---|---|---|---|---|---|
| Воспроизведение источника | Побайтно | Побайтно | Побайтно | Логически | Логически | Логически | Логически |
| Выборочная репликация | На уровне томов | На уровне томов | На уровне файлов | На уровне таблиц и строк | На уровне таблиц и строк | На уровне таблиц и строк | На уровне таблиц и строк |
| Объём трафика | X | X | X/7..X/5 | X/7..X/5 | ?X/10 | ?X/10 | ?X/10 |
| Скорость переключения | 5 мин… часы | 5 мин… часы | 1..10 мин | 1..10 мин | 1..2 мин | 1..2 мин | 1..2 мин |
| Гарантия переключения | + | + | +++ | + | ? | ? | ? |
| Доступность реплики | ? | ? | RO | R/W | R/W | R/W | R/W |
| Топология репликации | точка-точка | точка-точка broadcast |
точка-точка broadcast каскад |
точка-точка broadcast каскад встречная* p2p* |
точка-точка broadcast каскад встречная* p2p* слияние |
точка-точка broadcast каскад встречная* p2p* слияние |
точка-точка broadcast каскад встречная* p2p* слияние |
| Нагрузка на источник | ? | ? | – | – – | – – – | – – | ? |
| Простота настройки | + + + | + + | + + | + + | – | + | – – – |
| Стоимость дополнительного ПО | – – | – – | – | – | ? | – – – | ? |
| Гетерогенные среды | ? | + | + + | + + | + + | + + + | + + + |
- Блочная репликация имеет смысл, когда других способов репликации нет; для баз данных её лучше не использовать.
- Физическая репликация хороша, когда требуется обеспечение отказоустойчивости инфраструктуры или перенос части читающих приложений на реплики.
- Логическая репликация подходит для обеспечения отказоустойчивости только в том случае, если приложение знает об этой репликации и умеет в случае аварии ждать синхронизации реплик.
- Логическая репликация идеальна для всевозможных отчётных баз.
- Репликация триггерами имеет смысл в том случае, если база сильно нагружена, а реплицировать нужно крайне ограниченное количество информации.
- Платформы CDC хороши, если у вас большое количество реплицируемых баз и/или есть необходимость сложных преобразований данных.
- Разработка прикладной репликации оправдана только в случае разработки собственной платформы или фреймворка.



youROCK
(комментарий ниже это мое личное мнение)
У физической репликации (не важно, реплицируется диск целиком или только журнал базы) есть один существенный минус, о котором, к примеру, было упомянуто в статье Uber о найденных ими недостатках PostgreSQL: https://eng.uber.com/postgres-to-mysql-migration/. Если кратко, то любая ошибка при записи на диск, или при проигрывании журнала, добавленная в новой версии СУБД приведет к порче данных и на мастере и на реплике, поскольку у них одинаковый код. В случае с логической репликацией и обновлению сначала реплики, а потом мастера, такой проблемы не возникнет, ну и обновляться можно без downtime, поскольку формат журнала изменений в случае с логической репликацией несложно сделать обратно-совместимым и, в том же MySQL, он на практике тоже является обратно совместим.
Репликация средствами СХД подвержена тем же проблемам: любые систематические ошибки работы с диском будут точно также отреплицированы с ошибками на другие новые диски. Плюс есть дополнительный риск из-за того, что у одних и тех же производителей (или самих дисков) будут одни и те же программные баги в их прошивке и соответственно либо портить данные они будут одинаково, либо выходить из строя примерно одновременно.
Более того, все рассмотренные виды репликации интересны, но некоторые режимы ухудшают доступность, как например режим, где мастер фейлит транзакцию, если не удалось записать в реплику: если либо мастер либо реплика упадут, то запись остановится, и это примерно в два раза вероятнее, чем если если выйдет из строя только мастер, если считать события выхода из строя серверов независимыми. Переход на асинхронную репликацию в случае недоступности реплики так и вообще равноценен репликации Шредингера: Вы никогда не можете быть уверены, что данные куда-то реплицируются.
Намного лучше такой репликации в плане сохранности данных и доступности системы мне видится кворумная запись с автоматическим leader election. То есть, при записи мы ждём не только ответа от лидера, но и ответа от кворума ([N+1]/2 участников, оно должно быть нечётным). Репликация всё ещё может быть и логической и физической, но, насколько я знаю, физическую никто не выбирает. В кворум могут входить сервера разных производителей и архитектур, если хочется максимальной надёжности.
hard_sign Автор
Как раз это очень важно, потому что «запись на диск» и «проигрывание журнала» – это разные вещи. Вы правы, чем ниже уровень репликации, тем выше вероятность переноса ошибки на реплику. Но в случае с репликацией средствами БД эта вероятность существенно меньше.
Технология репликации и топология кластера – это два совершенно отдельных вопроса. Никто не мешает сделать две синхронных реплики и успешно фиксировать транзакцию, когда ответила хотя бы одна из них.
Вас обманули :))
У MySQL действительно нет общедоступного средства физической репликации, поэтому выбирать не из чего. Но у всех промышленных экземпляров «взрослых» СУБД – Oracle, MS SQL, PostgreSQL, DB2 – есть физическая реплика, она же standby.