

Облачные вычисления все глубже и глубже проникают в нашу жизнь и уже наверно нет ни одного человека, который хотя бы раз не пользовался какими либо облачными сервисами. Однако что же такое облако и как оно работает в большинстве своем мало кто знает даже на уровне идеи. 5G становится уже реальностью и телеком инфраструктура начинает переходить от столбовых решений к облачным решениями, как когда переходила от полностью железных решений к виртуализированным «столбам».
Сегодня поговорим о внутреннем мире облачной инфраструктуре, в частности разберем основы сетевой части.
Что такое облако? Та же виртуализация — вид в профиль?
Более чем логичный вопрос. Нет — это не виртуализация, хотя без нее не обошлось. Рассмотрим два определения:
Облачные вычисления (далее Облако) — это модель предоставления удобного для пользователя доступа к распределенным вычислительным ресурсам, которые должны быть развернуты и запущены по запросу с минимально возможной задержкой и минимальными затратами со стороны сервис провайдера (перевод определения от NIST).
Виртуализация — это возможность разделить одну физическую сущность (например сервер) на несколько виртуальных, тем самым повысив утилизацию ресурсов (например у вас было 3 сервера, загруженных на 25-30 процентов, после виртуализации вы получаете 1 сервер, загруженный на 80-90 процентов). Естественно виртуализация отъедает часть ресурсов — вам надо прокормить гипервизор, однако, как показала практика, игра стоит свеч. Идеальный пример виртуализации — это VMWare, которая отлично готовит виртуальные машины, или например KVM, который мне больше по душе, но это уже дело вкуса.
Мы используем виртуализацию сами этого не понимая, да даже железные маршрутизаторы уже используют виртуализацию — например в последних версия JunOS операционная система ставится как виртуальная машина поверх real-time linux дистрибутива (Wind River 9). Но виртуализация — это не облако, однако облако не может существовать без виртуализации.
Виртуализация — это один из кирпичиков, на котором облако строится.
Сделать облако, просто собрав несколько гипервизоров в один L2 домен, добавив пару yaml плейбуков для автоматического прописывания вланов через какой нибудь ansible и нахлобучить на это все что то типа системы оркестрации для автоматического создания виртуальных машин — не получится. Точнее получится, но полученный Франкенштейн — не то облако которое нам нужно, хотя кому как, может быть для кого то это предел мечтаний. К тому же если взять тот же Openstack — по сути еще тот еще Франкенштейн, но да ладно не будем пока об этом.
Но я понимаю что из представленного выше определения не совсем понятно, что же на самом деле можно назвать облаком.
Поэтому в документе от NIST (National Institute of Standards and Technology) приведены 5 основных характеристик, которыми должна обладать облачная инфраструктура:
Предоставление сервиса по запросу. Пользователю должен быть предоставлен свободный доступ к выделенным ему компьютерным ресурсам (таким как сети, виртуальные диски, память, ядра процессоров и т д) причем эти ресурсы должны предоставляться автоматически — то есть без вмешательства со стороны сервис провайдера.
Широкая доступность сервиса. Доступ к ресурсам должен обеспечиваться стандартными механизмами для возможности использования как стандартных ПК, так и тонких клиентов и мобильных устройств.
Объединение ресурсов в пулы. Пулы ресурсов должны обеспечивать одновременное предоставление ресурсов нескольким клиентам, обеспечивая изоляцию клиентов и отсутствие взаимного влияния между ними и конкуренции за ресурсы. В пулы включаются и сети, что говорит о возможности использования пересекающейся адресации. Пулы должны поддерживать масштабирование по запросу. Использование пулов позволяет обеспечить необходимый уровень отказоустойчивости ресурсов и абстрагирование физических и виртуальных ресурсов — получателю сервиса просто предоставляется запрошенный им набор ресурсов (где эти ресурсы расположены физически, на скольких серверах и коммутаторах — клиенту не важно). Однако надо учитывать тот факт, что провайдер должен обеспечить прозрачное резервирование данных ресурсов.
Быстрая адаптация к различным условиям. Сервисы должны быть гибкими — быстрое предоставление ресурсов, их перераспределение, добавление или сокращение ресурсов по запросу клиента, причем со стороны клиента должно складываться ощущение, что ресурсы облака бесконечны. Для простоты понимания, например, вы же не видите предупреждение о том, что у вас в Apple iCloud пропала часть дискового пространства из за того, что на сервере сломался жесткий диск, а диски то ломаются. К тому же с вашей стороны возможности этого сервиса практически безграничны — нужно вам 2 Тб — не проблема, заплатили и получили. Аналогично можно привести пример с Google.Drive или Yandex.Disk.
Возможность измерения предоставляемого сервиса. Облачные системы должны автоматически контролировать и оптимизировать потребляемые ресурсы, при этом эти механизмы должны быть прозрачны как для пользователя так и для провайдера услуг. То есть вы всегда можете проверить, сколько ресурсов вы и ваши клиенты потребляют.
Стоит учесть тот факт, что данные требования в большинстве своем являются требованиями к публичному облаку, поэтому для приватного облака (то есть облака, запущенного для внутренних нужд компании) эти требования могут быть несколько скорректированы. Однако они все же должны выполняться, иначе мы не получим всех плюсов облачных вычислений.
Зачем нам облако?
Однако любая новая или уже существующая технология, любой новый протокол создается для чего-то (ну кроме RIP-ng естественно). Протокол ради протокола — никому не нужен (ну кроме RIP-ng естественно). Логично, что Облако создается чтобы предоставить какой то сервис пользователю/клиенту. Мы все знакомы хотя бы с парой облачных сервисов, например Dropbox или Google.Docs и я так полагаю большинство успешно ими пользуется — например данная статья написана с использованием облачного сервиса Google.Docs. Но известные нам облачные сервисы это только часть возможностей облака — точнее это только сервис типа SaaS. Предоставить облачный сервис мы можем тремя путями: в виде SaaS, PaaS или IaaS. Какой сервис нужен именно вам зависит от ваших желаний и возможностей.
Рассмотрим каждый по порядку:
Software as a Service (SaaS) — это модель предоставления полноценного сервиса клиенту, например почтовый сервис типа Yandex.Mail или Gmail. В такой модели предоставления сервиса вы, как клиент по факту не делаете ничего, кроме как пользуетесь сервисов — то есть вам не надо думать о настройке сервиса, его отказоустойчивости или резервировании. Главное не скомпрометировать свой пароль, все остальное за вас сделает провайдер данного сервиса. С точки зрения провайдера сервиса — он отвечает полностью за весь сервис — начиная с серверного оборудования и хостовых операционных систем, заканчивая настройками баз данных и программного обеспечения.
Platform as a Service (PaaS) — при использовании данной модели поставщик услуг предоставляет клиенту заготовку под сервис, например возьмем Web сервер. Поставщик услуг предоставил клиенту виртуальный сервер (по факту набор ресурсов, таких как RAM/CPU/Storage/Nets и т д), и даже установил на данный сервер ОС и необходимое ПО, однако настройку всего этого добра производит сам клиент и за работоспособность сервиса уже отвечает клиент. Поставщик услуг, как и в прошлом случае отвечает за работоспособность физического оборудования, гипервизоров, самой виртуальной машины, ее сетевую доступность и т д, но сам сервис уже вне его зоны ответственности.
Infrastructure as a Service (IaaS) — данный подход уже интереснее, по факту поставщик услуг предоставляет клиенту полную виртуализированную инфраструктуру — то есть какой то набор (пул) ресурсов, таких как CPU Cores, RAM, Networks и т д. Все остальное — дело клиента — что клиент хочет сделать с этими ресурсами в рамках выделенного ему пула (квоты) — поставщику не особо важно. Хочет клиент создать свой собственный vEPC или вообще сделать мини оператора и предоставлять услуги связи — не вопрос — делай. В таком сценарии поставщик услуг отвечает за предоставление ресурсов, их отказоустойчивость и доступность, а также за ОС, позволяющую объединить данные ресурсы в пулы и предоставить их клиенту с возможность в любой момент провести увеличение или уменьшение ресурсов по запросу клиента. Все виртуальные машины и прочую мишуру клиент настраивает сам через портал самообслуживания и консоли, включая и прописание сетей (кроме внешних сетей).
Что такое OpenStack?
Во всех трех вариантах поставщику услуг нужна ОС, которая позволит создать облачную инфраструктуру. Фактически же при SaaS за весь стек данный стек технологий отвечает не одно подразделение — есть подразделение, которое отвечает за инфраструктуру — то есть предоставляет IaaS другому подразделению, это подразделение предоставляет клиенту SaaS. OpenStack является одной из облачных ОС, которая позволяет собрать кучу коммутаторов, серверов и систем хранения в единый ресурсный пул, разбивать этот общий пул на подпулы (тенанты) и предоставлять эти ресурсы клиентам через сеть.
OpenStack — это облачная операционная система которая позволяет контролировать большие пулы вычислительных ресурсов, хранилищ данных и сетевых ресурсов, провижининг и управление которыми производится через API с использованием стандартных механизмов аутентификации.
Другими словами, это комплекс проектов свободного программного обеспечения который предназначен для создания облачных сервисов, (как публичных, так и частных) — то есть набор инструментов, которые позволяют объединить серверное и коммутационное оборудование в единый пул ресурсов, управлять этими ресурсами, обеспечивая необходимый уровень отказоустойчивости.
На момент написания данного материала структура OpenStack выглядит так:

Картинка взята с openstack.org
Каждая из компонент, входящих в состав OpenStack которых выполняет какую либо определенную функцию. Такая распределенная архитектура позволяет включать в состав решения тот набор функциональных компонент, которые вам необходимы. Однако часть компонент являются корневыми компонентами и их удаление приведет к полной или частичной неработоспособности решения в целом. К таким компонентам принято относить:
- Dashboard — GUI на базе web для управления OpenStack сервисами
- Keystone — централизованный сервис идентификации, который предоставляет функциональность аутентификации и авторизации для других сервисов, а также управлять учетными данными пользователей и их ролями.
- Neutron — сетевая служба, обеспечивающая связность между интерфейсами различных служб OpenStack (включая и связность между VM и доступ их во внешний мир)
- Cinder — предоставляет доступ к блочному хранилищу для виртуальных машин
- Nova — управление жизненным циклом виртуальных машин
- Glance — репозиторий образов виртуальных машин и снапшотов
- Swift — предоставляет доступ к объектому хранилищу
- Ceilometer — служба, предоставляющая возможность сбора телеметрии и замера имеющихся и поребляющих ресурсов
- Heat — оркестрация на базе темплейтов для автоматического создания и провижининга ресурсов
Полный список всех проектов и их назначение можно посмотреть тут.
Каждая из компонент OpenStack — это служба, отвечающая за определенную функцию и обеспечивающая API для управления этой функцией и взаимодействия этой службы с другими службами облачной операционной системы в целях создания единой инфраструктуры. Например, Nova обеспечивает управления вычислительными ресурсами и API для доступа к конфигурированию данных ресурсов, Glance – управления образами и API для управления ими, Cinder – блочное хранилище и API для управления им и тд. Все функции взаимоувязаны между собой очень тесным образом.
Однако если посудить, то все сервисы, запущенные в OpenStack представляет из себя в конечном счете какую либо виртуальную машину (или контейнер), подключенную к сети. Встает вопрос — а зачем нам столько элементов?
Давайте пробежимся по алгоритму создания виртуальной машины и подключения ее к сети и постоянному хранилищу в Openstack.
- Когда вы создаете запрос на создание машины, будь то запрос через Horizon (Dashboard) или же запрос через CLI, первое что происходит — это авторизация вашего запроса на Keystone — можете ли вы создавать машину, имеет или право использовать данную сеть, хватает ли у вашего проекта квоты и т д.
- Keystone производит аутентификацию вашего запроса и генерирует в ответном сообщении auth-токен, который будет использован далее. Получив ответ от Keystone запрос отправляется в сторону Nova (nova api).
- Nova-api проверяет валидность вашего запроса, обращаясь в Keystone, используя ранее сгенерированный auth-токен
- Keystone производит аутентификацию и предоставляет на основании данного auth-токена информацию по разрешениям и ограничениям.
- Nova-api создает в nova-database запись о новой VM и передает запрос на создание машины в nova-scheduler.
- Nova-scheduler производит выбор хоста (компьют ноды), на которой VM будет развернута на основании заданных параметров, весов и зон. Запись об этом и идентификатор VM записываются в nova-database.
- Далее nova-scheduler обращается к nova-compute с запросом об развертывании инстанса. Nova-compute обращается в nova-conductor для получения информации о параметрах машины (nova-conductor является элементом nova, выполняющим роль прокси сервера между nova-database и nova-compute, ограничивая количество запросов в сторону nova-database во избежании проблем с консистентность базы данных сокращения загрузки).
- Nova-conductor получает из nova-database запрошенную информацию и передает ее nova-compute.
- Далее nova-compute обращается к glance для получения ID образа. Glace проводит валидацию запроса в Keystone и возвращает запрошенную информацию.
- Nova-compute обращается к neutron для получения информации о параметрах сети. Аналогично glance, neutron проводит валидацию запроса в Keystone, после чего создает запись в database (идентификатор порта и т д), создает запрос на создание порта и возвращает запрошенную информацию в nova-compute.
- Nova-compute обращается к cinder с запросом выделения виртуальной машине volume. Аналогично glance, cider проводит валидацию запроса в Keystone, создает запрос на создание volume и возвращает запрошенную информацию.
- Nova-compute обращается к libvirt с запросом разворачивания виртуальной машины с заданными параметрами.
По факту вроде бы простая операция по созданию простой виртуальной машины превращается в такой водоворот api коллов между элементами облачной платформы. Причем, как вы видите, даже ранее обозначенные службы — тоже состоят из более мелких компонент, между которыми происходит взаимодействие. Создание машины — это лишь малая часть того, что дает сделать облачная платформа — есть служба, отвечающая за балансировку трафика, служба, отвечающая за блочное хранилище, служба, отвечающая за DNS, служба, отвечающая за провижининг bare metal серверов и т д. Облако позволяет вам относиться к вашим виртуальным машинам как к стаду баранов (в отличии от виртуализации). Если в виртуальной среде у вас что то произошло с машиной — вы ее восстанавливаете из бекапов и т д, облачные же приложения построены таким образом, что бы виртуальная машины не играла такую важную роль — виртуальная машина «умерла» — не беда — просто создается новая машина на основании темплейта и, как говорится, отряд не заметил потери бойца. Естественно это предусматривает наличие механизмов оркестрации — используя Heat темплейты вы без особых проблем можете развернуть сложную фунцию, состоящую из десятков сетей и виртуальных машин.
Стоит всегда держать в уме то, что облачной инфраструктуры без сети не бывает — каждый элемент так или иначе взаимодействует с другими элементами через сеть. Кроме того облако имеет абсолютно не статичную сеть. Естественно underlay сеть еще более-менее статична — не каждый день добавляются новые ноды и коммутаторы, однако overlay составляющая может и неизбежно будет постоянно менять — будут добавляться или удаляться новые сети, появляться новые виртуальные машины и умирать старые. И как вы помните из определения облака, данного в самом начале статьи — ресурсы должны выделять пользователю автоматически и с наименьшим (а лучше без) вмешательством со стороны сервис провайдера. То есть тот тип предоставления ресурсов сети, который есть сейчас в виде фронтенда в виде вашего личного кабинета доступного по http/https и дежурного сетевого инженера Василия в качестве бэкэнда — это не облако, даже при наличии у Василия восьми рук.
Neutron, являясь сетевой службой, обеспечивает API для управления сетевой частью облачной инфраструктуры. Служба обеспечивает работоспособность и управление сетевой части Openstack обеспечивая уровень абстракции, называемый Network-as-a-Service (NaaS). То есть сеть является такой же виртуальной измеримой единицей, как например виртуальные ядра CPU или объем RAM.
Но перед тем как переходить к архитектуре сетевой части OpenStack, рассмотрим как в OpenStack эта сеть работает и почему сеть является важной и неотъемлемой частью облака.
Итак, у нас есть две виртуальные машины клиента RED и две виртуальные машины клиента GREEN. Предположим, что эти машины расположенные на двух гипервизорах таким образом:
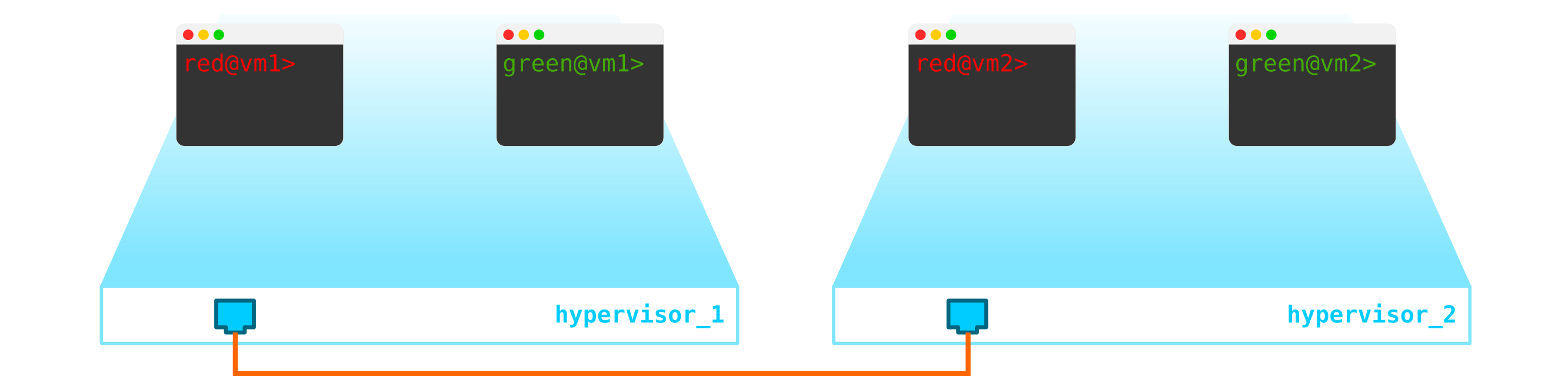
В данный момент это просто виртуализация 4-х серверов и не более того, так как пока что все что мы сделали — виртуализировали 4 сервера, раположив их на двух физических серверах. Причем пока что они даже не подключены к сети.
Чтобы получилось облако нам надо добавить несколько компонент. Во первых виртуализируем сетевую часть — нам надо эти 4 машины попарно соединить, причем клиенты хотят именно L2 соединение. Можно использовать кончено коммутатор и настроить в его сторону транк и разрулить все с помощью linux bridge ну или для более продвинутых юзеров openvswitch (к нему мы еще вернемся). Но сетей может быть очень много, да и постоянно пропихивать L2 через свич — не самая лучшая идея — так разные подразделения, сервис-деск, месяцы ожидания выполнения заявки, недели траблшутинга — в современно мире такой подход уже не работает. И чем раньше компания это понимает — тем легче ей двигаться вперед. Поэтому между гипервизорами выделим L3 сеть через которую будут общаться наши виртуальные машины, а уже поверх данной L3 сети построим виртуальные наложенные L2 (overlay) сети, где будет бегать трафик наших виртуальных машин. Как инкапсуляцию можно использовать GRE, Geneve или VxLAN. Пока остановимся на последнем, хотя это не особо важно.
Нам надо где то расположить VTEP (надеюсь все знакомы с терминологией VxLAN). Так как с серверов у нас выходит сразу L3 сеть, то нам ничего не мешает расположить VTEP на самих серверах, причем OVS (OpenvSwitch) это отлично умеет делать. В итоге мы получили вот такую конструкцию:
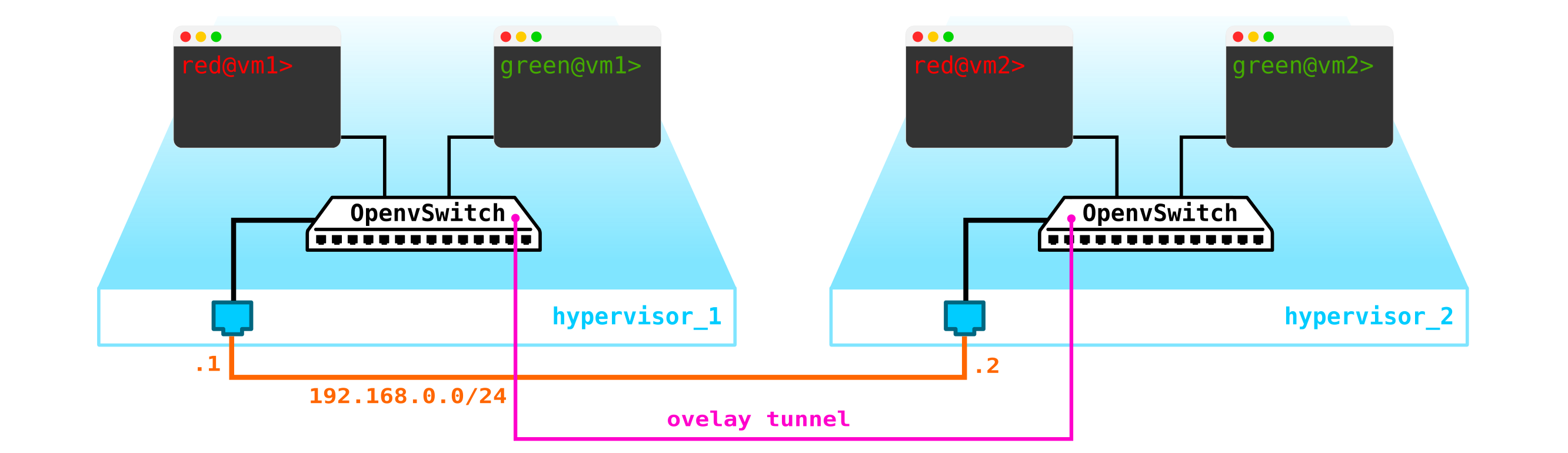
Так как трафик между VM должен быть разделен, то порты в сторону виртуальных машин будут иметь разные номера вланов. Номер тега играет роль только в пределах одного виртуального коммутатора, так как при инкапсулировании в VxLAN мы его можем беспроблемно снять, так как у нас будет VNI.

Теперь мы можем плодить наши машины и виртуальные сети для них без каких либо проблем.
Однако что если у клиента будет еще одна машина, но находится в другой сети? Нам нужен рутинг между сетями. Мы разберем простой вариант, когда используется централизованный рутинг — то есть трафик маршрутизируется через специальные выделенные network ноды (ну как правило они совмещены с control нодами, поэтому у нас будет тоже самое).
Вроде бы ничего сложного — делаем бридж интерфейс на контрольной ноде, гоним на нее трафик и оттуда маршрутизируем его куда нам надо. Но проблема в том, что клиент RED хочет использовать сеть 10.0.0.0/24, и клиент GREEN хочет использовать сеть 10.0.0.0/24. То есть у нас начинается пересечение адресных пространств. Кроме того клиенты не хотят, чтобы другие клиенты могли маршрутизироваться в их внутренние сети, что логично. Чтобы разделить сети и трафик данных клиентов мы для каждого из них выделим отдельный namespace. Namespace — это по факту копия сетевого стека Linux, то есть клиенты в namespace RED полностью изолированы от клиентов из namespace GREEN (ну либо маршрутизация между данными сетями клиентов разрешена через default namespace либо уже на вышестоящем транспортном оборудовании).
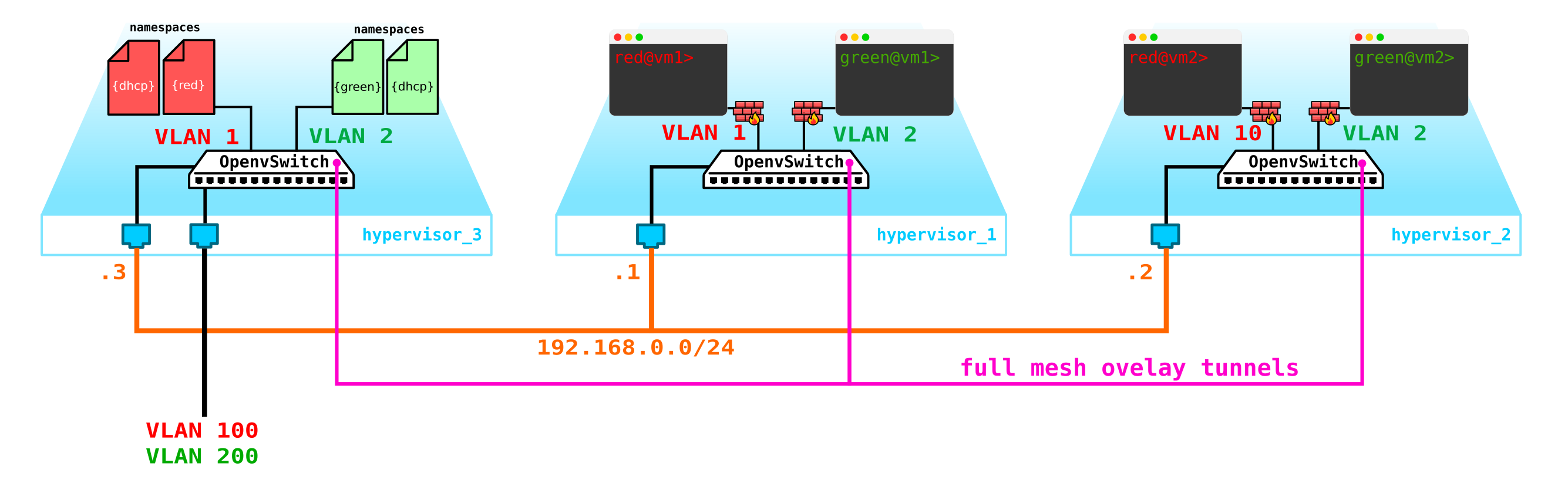
То есть получаем такую схему:
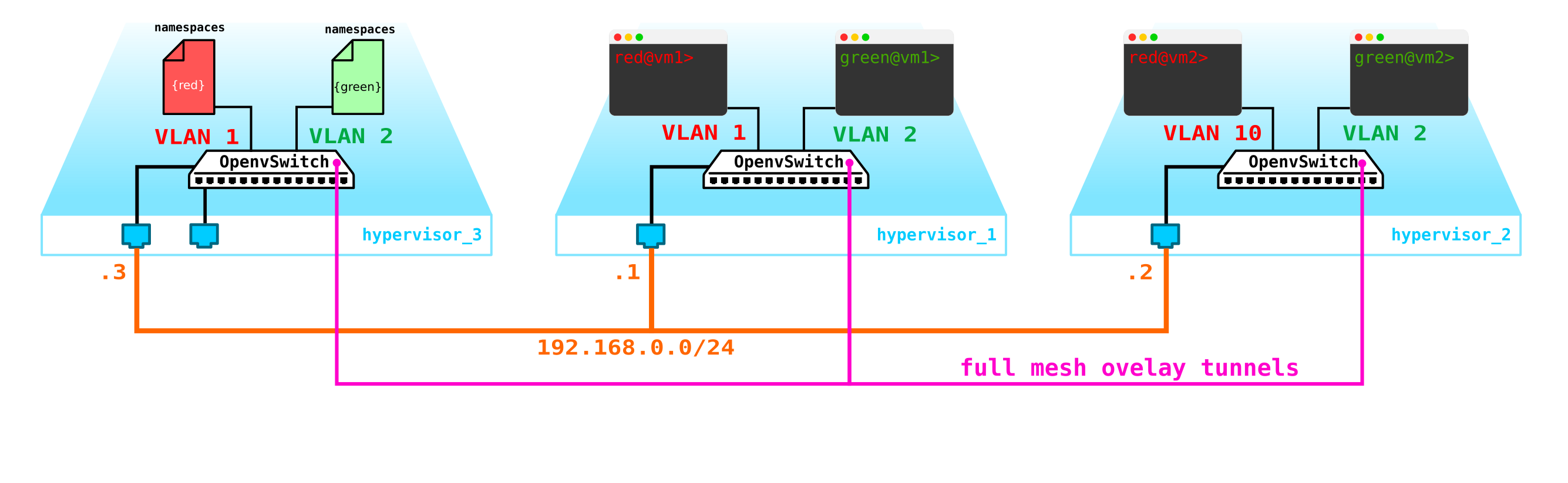
L2 тоннели сходятся со всех вычислительных нод на контрольную. ноду, где расположен L3 интерфейс для данных сетей, каждый в выделенном namespace для изоляции.
Однако мы забыли самое главное. Виртуальная машина должна предоставлять сервис клиенту, то есть она должна иметь хотя бы один внешний интерфейс, через который к ней можно достучаться. То есть нам нужно выйти во внешний мир. Тут есть разные варианты. Сделаем самый просто вариант. Добавим клиентам по одной сети, которые будут валидны в сети провайдера и не будут пересекаться с другими сетями. Сети могу быть тоже пересекающимися и смотреть в разные VRF на стороне провайдерской сети. Данные сети также будут жить в namespace каждого из клиентов. Однако выходить во внешний мир они все равно будут через один физический (или бонд, что логичнее) интерфейс. Чтобы разделить трафик клиентов трафик, выходящий наружу будет производиться тегирование VLAN тегом, выделенным клиенту.
В итоге мы получили вот такую схему:

Резонный вопрос — почему не сделать шлюзы на самих compute нодах? Большой проблемы в этом нет, более того, при включении распределенного маршрутизатора (DVR) это так и будет работать. В данном сценарии мы рассматриваем самый простой вариант с централизованным gateway, который в Openstack используется по умолчанию. Для высоконагруженных функций будут использовать как распределенный маршрутизатор, так и технологии ускорения типа SR-IOV и Passthrough, но как говорится, это уже совсем другая история. Для начала разберемся с базовой частью, а потом уйдем в детали.
Собственно наша схема уже работоспособна, однако есть пара нюансов:
- Нам надо как то защитить наши машины, то есть повесить на интерфейс свича в сторону клиента фильтр.
- Сделать возможность автоматического получения ip адреса виртуальной машиной, чтобы не пришлось каждый раз заходить в нее через консоль и прописывать адрес.
Начнем с защиты машин. Для этого можно использовать банальные iptables, почему бы и нет.
То есть теперь наша топология уже немного усложнилась:
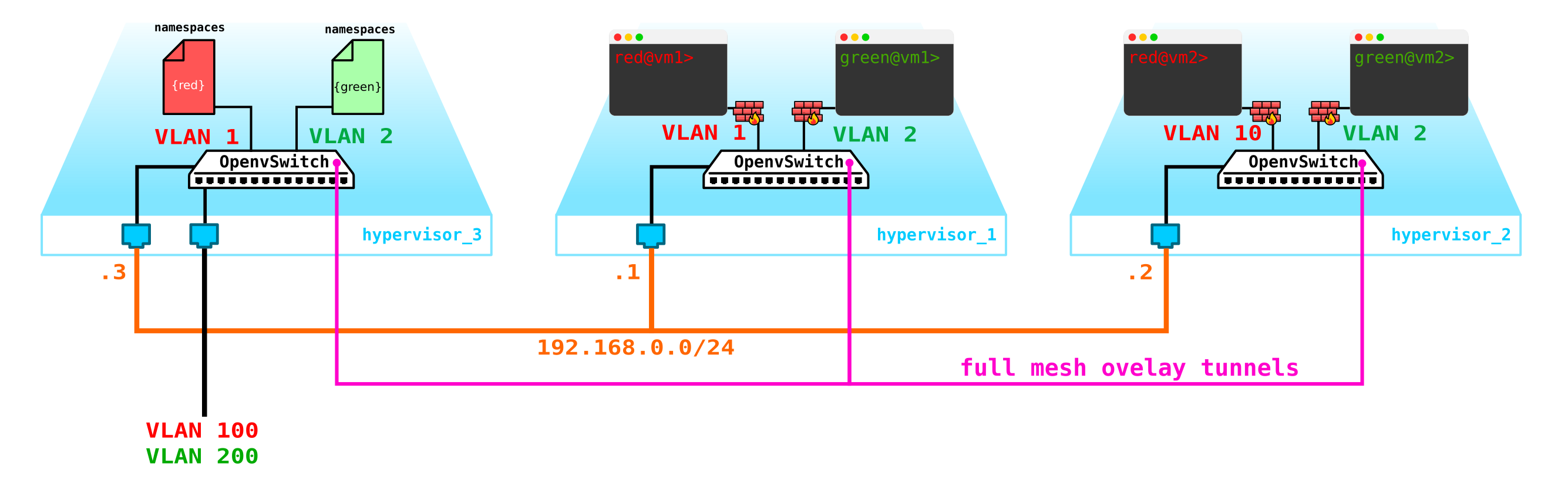
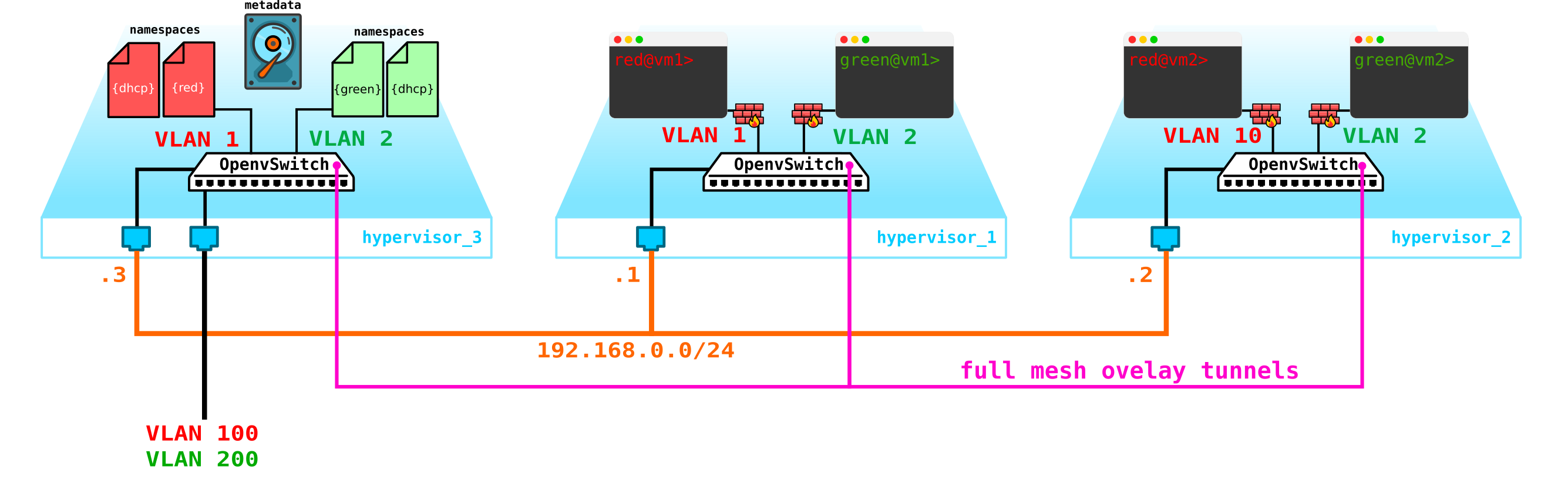
Пойдем далее. Нам надо добавить DHCP сервер. Самым идеальным местом для расположения DHCP серверов для каждого из клиентов будет уже упомянутая выше контрольная нода, где расположены namespaces:
Однако, есть небольшая проблема. Что если все перезагрузится и вся информация по аренде адресов на DHCP пропадет. Логично, что машинам будут выданы новые адреса, что не очень удобно. Выхода тут два — либо использовать доменные имена и добавить DNS сервер для каждого клиента, тогда нам адрес будет не особо важен (по аналогии с сетевой часть в k8s) — но тут есть проблема с внешними сетями, так как в них адреса также могу быть выданы по DHCP — нужна синхронизация с DNS серверов в облачной платформе и внешним DNS сервером, что на мой взгляд не очень гибко, однако вполне возможно. Либо второй вариант — использовать метаданные — то есть сохранять информацию о выданной машине адресе чтобы DHCP сервер знал, какой адрес машине выдать, если машина уже получала адрес. Второй вариант проще и гибче, так как позволяет сохранить доп информацию о машине. Теперь на схему добавим metadata агента:
Еще один вопрос который также стоит освятить — это возможность использовать одну внешнюю сеть всеми клиентами, так как внешние сети, если они должны быть валидны во всей сети, то будет сложность — надо постоянно выделять и контролировать выделение этих сетей. Возможность использования единой для всех клиентов внешней предконфигурированной сети будет очень кстати при создании публичного облака. Это упростит развертывание машин, так как нам не надо сверяться с базой данных адресов и выбирать уникальное адресное пространство для внешней сети каждого клиента. К тому же мы можем прописать внешнюю сеть заранее и в момент развертывания нам надо будет всего лишь ассоциировать внешние адреса с клиентскими машинами.
И тут на помощь нам приходит NAT — просто сделаем возможность клиентов выходить во внешний мир через default namespace с использованием NAT трансляции. Ну и тут небольшая проблема. Это хорошо, если клиентский сервер работает как клиент, а не как сервер — то есть инициирует а не принимает подключения. Но у нас то будет наоборот. В тамом случае нам надо сделать destination NAT, чтобы при получении трафика контрольная нода понимала, что данный трафик предназначен виртуальной машине А клиента А, а значит надо сделать NAT трансляцию из внешнего адреса, например 100.1.1.1 во внутренний адрес 10.0.0.1. В таком случае, хотя все клиенты будут использовать одну и ту же сеть, внутренняя изоляция полностью сохраняется. То есть нам надо на контрольной ноде сделать dNAT и sNAT. Использовать единую сеть с выделением плавающих адресов или внешние сети или же и то и то сразу — обуславливается тем, что вы хотите в облако затянуть. Мы не будем наносить на схему еще и плавающие адреса, а оставим уже добавленные ранее внешние сети — у каждого клиента есть своя внешняя сеть (на схеме обозначены как влан 100 и 200 на внешнем интерфейсе).
В итоге мы получили интересное и в то же время продуманное решение, обладающее определенной гибкость но пока что не обладающее механизмами отказоустойчивости.
Во первых у нас всего одна контрольная нода — выход ее из строя приведет к краху все системы. Для устранения данной проблемы необходимо сделать как минимум кворум из 3-х нод. Добавим это на схему:
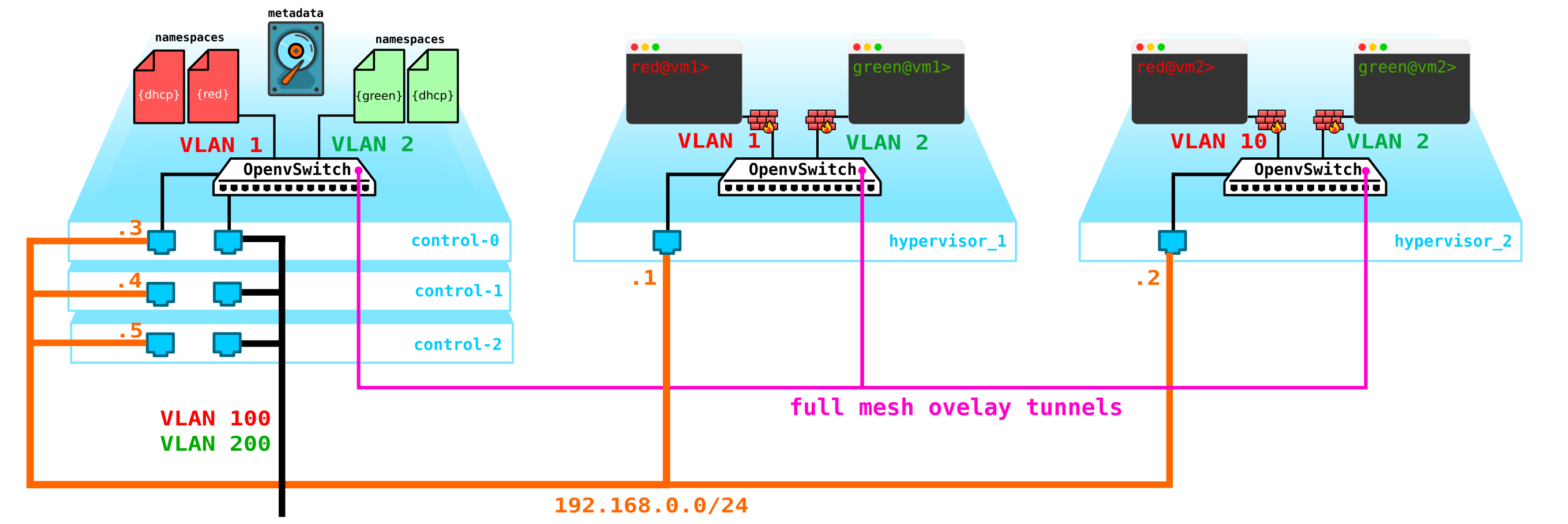
Естественно все ноды синхронизируются и при выходе активной ноды ее обязанности на себя возьмет другая нода.
Следующая проблема — диски виртуальных машин. В данный момент они хранятся на самих гипервизорах и в случае проблем с гипервизором мы теряем все данные — и наличие рейда тут никак не поможет если мы потеряем не диск, а весь сервер целиком. Для этого нам нужно сделать службу, которая будет выступать фронтэндом для какого либо хранилища. Какое это будет хранилище нам особо не важно, но оно должно защитить наши данные от выхода из строя и диска и ноды, а возможно и целого шкафа. Вариантов тут несколько — есть конечно SAN сети с Fiber Channel, но скажем честно — FC это уже пережиток прошлого — аналог E1 в транспорте — да согласен, он еще используется, но только там, где без него ну никак нельзя. Поэтому добровольно разворачивать FC сеть в 2020 году я бы не стал, зная о наличии других более более интересных альтернатив. Хотя каждому свое и возможно найдутся те, кто считает, что FC со всеми его ограничениями — все что нам надо — не буду спорить, у каждого свое мнение. Однако наиболее интересным решением на мой взгляд является использование SDS, например Ceph.
Ceph позволяет построить выскодоступное решение для хранения данных с кучей возможных вариантов резервирования, начиная с кодов с проверкой четности (аналог рейд 5 или 6) заканчивая полной репликацией данных на разные диски с учетом расположения дисков в серверах, и серверов в шкафах и т д.
Для сборки Ceph нужно еще 3 ноды. Взаимодействие с хранилищем будет производиться также через сеть с использованием служб блочного, объектного и файлового хранилищ. Добавим в схему хранилище:
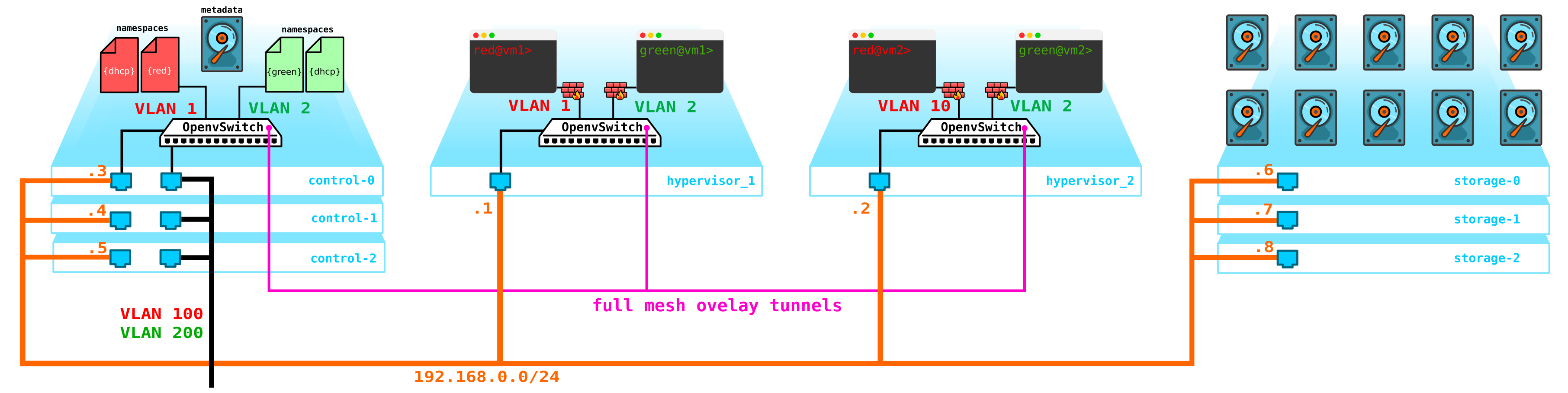
Примечание: можно делать и гиперконвергентные compute ноды — это концепция объединения нескольких функций на одной ноде — например storage+compute — не выделять специальные ноды под ceph storage. Мы получим такую же отказоустойчивую схему — так как SDS зарезервирует данные с указанным нами уровнем резервирования. Однако гиперконвергентные ноды — это всегда компромисс — так как storage нода не просто греет воздух как кажется на первый взгляд (так как на ней нет виртуальных машин) — она тратит ресурсы CPU на обслуживание SDS (по факту она в фоне делает все репликации, восстановления после сбоев нод, дисков и т д). То есть вы потеряете часть мощности compute ноды если совместите ее с storage.Всем этим добром надо как то управлять — нужно что то, через что мы можем создать машину, сеть, виртуальный маршрутизатор и т д. Для этого на контрольную ноду добавим службу, которая будет выполнять роль dashboard — клиент сможет подключиться к данному порталу через http/https и сделать все, что ему надо (ну почти).
В итоге теперь мы имеем отказоустойчивую систему. Всеми элементами данной инфраструктуры надо как то управлять. Ранее было описано, что Openstack — это набор проектов, каждый их которых обеспечивает какую то определенную функцию. Как мы видим элементов, которые надо конфигурировать и контролировать более чем достаточно. Сегодня мы поговорим о сетевой части.
Архитектура Neutron
В OpenStack именно Neutron отвечает за подключение портов виртуальных машин к общей L2 сети, обеспечение маршрутизации трафика между VM, находящимися в разных L2 сетях а также маршрутизацию наружу, предоставление таких сервисов как NAT, Floating IP, DHCP и т д.
Высокоуровнево работу сетевой службы (базовая часть) можно описать так.
При запуске VM сетевая служба:
- Создает порт для данной VM (или порты) и оповещает об этом DHCP сервис;
- Создается новый виртуальный сетевой девайс (через libvirt);
- VM подключается к созданному на 1 шаге порту (портам);
Как ни странно, но в основе работы Neutron лежат стандартные механизмы, знакомые всем, что когда либо погружался в Linux — это namespaces, iptables, linux bridges, openvswitch, conntrack и т д.
Следует сразу уточнить, что Neutron не является SDN контроллером.
Neutron состоит из нескольких взаимоувязанных между собой компонент:
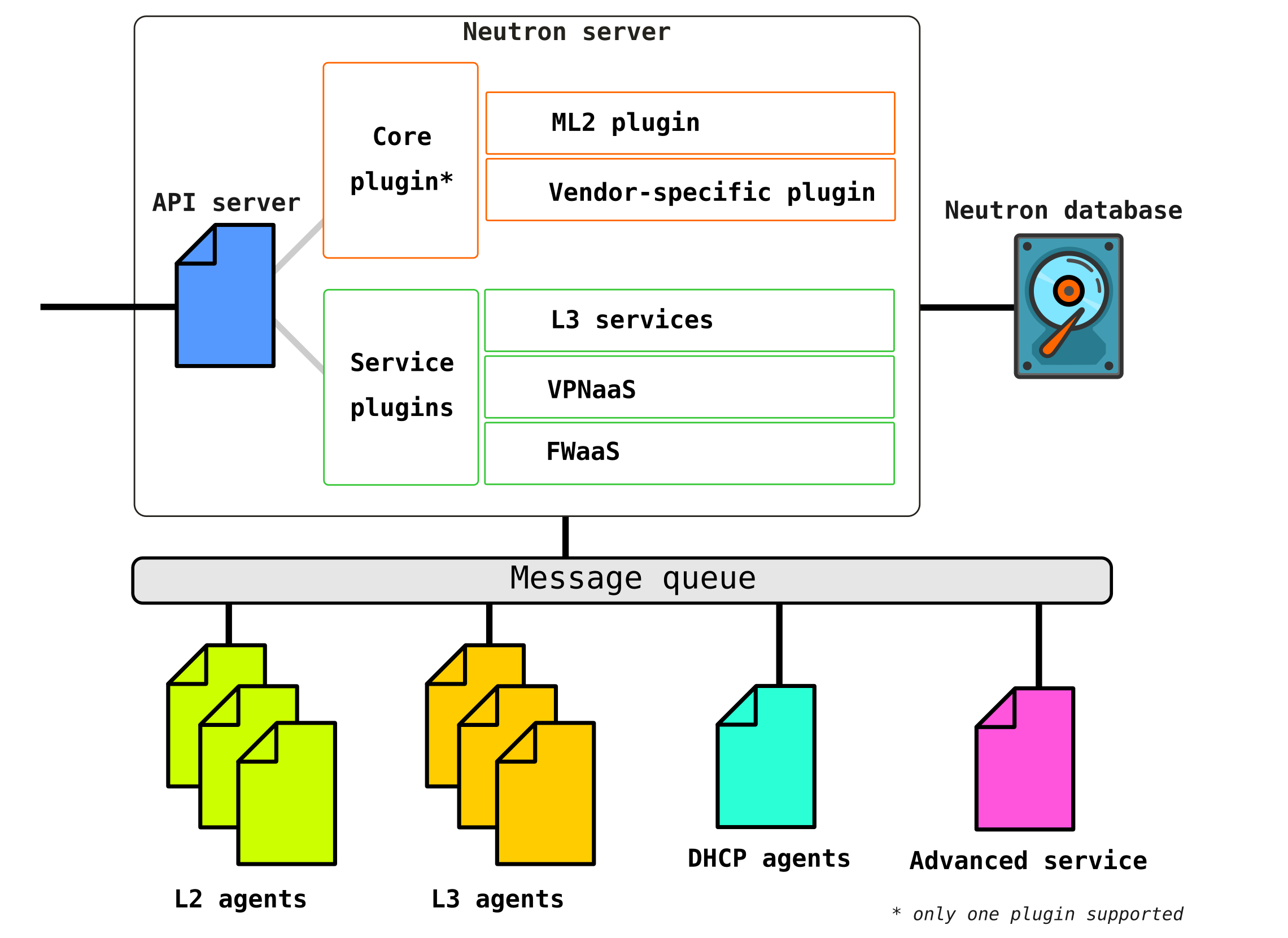
Openstack-neutron-server — это демон, который через API работает с пользовательскими запросами. Данный демон не занимается прописыванием каких либо сетевых связностей, а дает необходимую для этого информацию своим плагинам, которые далее настраивают нужный элемент сети. Neutron-агенты на узлах OpenStack регистрируются на сервере Neutron.
Neutron-server это фактически приложение, написанное на python, состоящее из двух частей:
- REST service
- Neutron Plugin (core/service)
REST сервис предназначен для приема API вызовов от остальных компонент (например запрос на предоставление какой либо информации и т.д.)
Плагины это подключаемые программные компоненты/модули которые вызываются при API запросах — то есть приписывание какого то сервиса происходит через них. Плагины делятся на два вида — сервисный и корневой. Как правило коневой плагин отвечает в основном за управление адресным пространством и L2 соединения между VM, а сервисные плагины уже обеспечивают дополнительный функционал например VPN или FW.
Список доступных на сегодня плагинов можно посмотреть например тут
Сервисных плагинов может быть несколько, однако коневой плагин может быть только один.
Openstack-neutron-ml2 — это стандартный корневой плагин Openstack. Данный плагин имеет модульную архитектуру (в отличии от своего предшественника) и через подключаемые к нему драйверы производит конфигурирование сетевого сервиса. Сам плагин рассмотрим чуть позже, так как фактически он дает ту гибкость, которой обладает OpenStack в сетевой части. Корневой плагин может быть заменен (например Contrail Networking делает такую замену).
RPC service (rabbitmq-server) — сервис, обеспечивающий управлением очередями и взаимодействие с другими службами OpenStack а также взаимодействие между агентами сетевой службы.
Network agents — агенты, которые расположены в каждой ноде, через которые и производится конфигурирование сетевых сервисов.
Агенты бывают нескольких видов.
Основной агент — это L2 agent. Эти агенты запускаются на каждом из гипервизоров включая и контрольные ноды (точнее сказать на всех узлах, которые предоставляют какой либо сервис для тенантов) и их основная функция — подключение виртуальных машин к общей L2 сети, а также генерировать оповещения при возникновении каких либо событий (например отключения/включения порта).
Следующим, не менее важным агентом является L3 agent. По умолчанию этот агент запускается исключительно на network ноде (часто network node совмещается с control node) и обеспечивает маршрутизацию между сетями тенантов (как между его сетями и сетями других тенатов, так и доступен во внешний мир, обеспечивая NAT, а также DHCP сервис). Однако при использовании DVR (распределенный маршрутизатор) необходимость в L3 плагине появляется и на compute нодах.
L3 агент использует Linux namespaces для предоставления каждому тенанту набора собственных изолированных сетей и функционал виртуальных маршрутизаторов, которые маршрутизируют трафик и предоставляют услуги шлюза для Layer 2 сетей.
Database — база данных идентификаторов сетей, подсетей, портов, пулов и т д.
Фактически Neutron принимает API запросы от на создание каких либо сетевых сущностей аутентифицирует запрос, и через RPC (если обращается к какому то плагину или агенту) или REST API (если общается в SDN) передает агентам (через плагины) инструкции, необходимые для организации запрошенного сервиса.
Теперь обратимся к тестовой инсталляции (как она развернута и что в ее составе посмотрим позже в практической части) и посмотрим где какая компонента расположена:
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$ 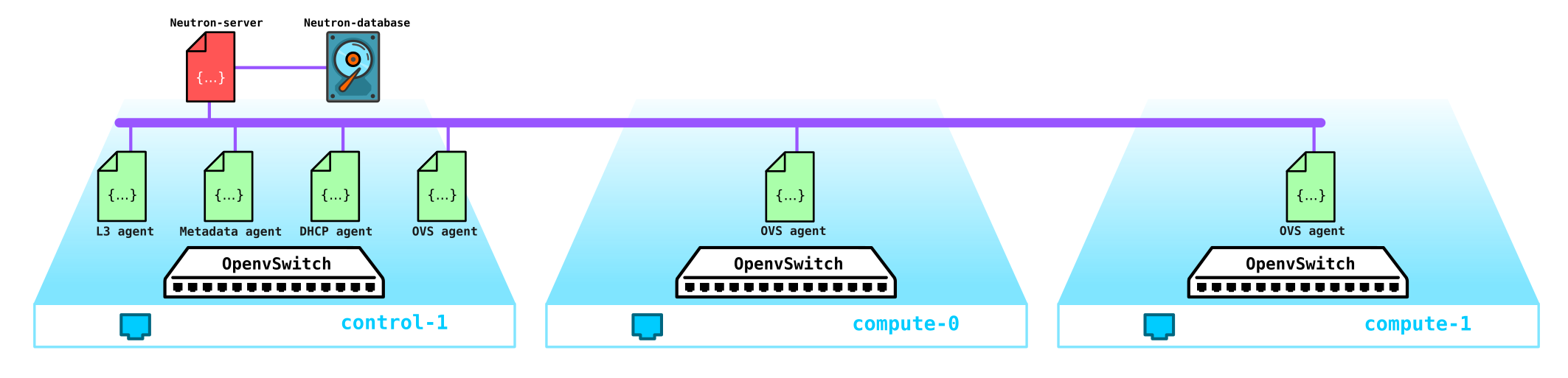
Собственно вот и вся структура Neutron. Теперь стоит уделить некоторое время ML2 плагину.
Modular Layer 2
Как уже сказано выше плагин является стандартным корневым плагином OpenStack и имеет модульную архитектуру.
Предшественник ML2 плагина имел монолитную структуру что не позволяло например использовать микс из нескольких технологий в одной инсталляции. Например вы не могли использовать и openvswitch и linuxbridge одновременно — либо первое, либо второе. По этому причине был создан ML2 плагин с его архитектурой.
ML2 имеет две составляющие — два типа драйверов: Type drivers и Mechanism drivers.
Type drivers определяют технологии, которые будут использованы для организации сетевых связностей, например VxLAN, VLAN, GRE. При этом драйвер позволяет использовать разные технологии. Стандартной технологией является VxLAN инкапсуляция для overlay сетей и vlan внешних сетей.
К Type drivers являются следующие типы сетей:
Flat — сеть без тегирования
VLAN — тегированная сеть
Local — специальный тип сети для инсталляций типа all-in-one (такие инсталляции нужны либо для разработчиков либо для обучения)
GRE — overlay сеть, использующая GRE тоннели
VxLAN — overlay сеть, использующая VxLAN тоннели
Mechanism drivers определяют средства, которые обеспечивают организацию указанных в type driver технологий — например, openvswitch, sr-iov, opendaylight, OVN и т д.
В зависимости от реализации данного драйвера будет использованы либо агенты, которые управляются Neutron, либо использоваться соединения с внешним SDN контроллером, который берет на себя все вопросы по организации L2 сетей, маршрутизации и т д.
Пример если мы используем ML2 вместе с OVS, то на каждой вычислительной ноде устанавливается L2 агент, который управляет OVS. Однако если мы используем например OVN или OpenDayLight, то управление OVS переходит под их юрисдикцию — Neutron через корневой плагин дает команды контроллеру, а он уже делает то, что ему сказали.
Освежим в памяти Open vSwitch
На данный момент одним из ключевых компонент OpenStack является Open vSwitch.
При установке OpenStack без какого либо дополнительного вендорского SDN типа Juniper Contrail или Nokia Nuage, OVS является основной сетевой компонентой облачной сети и в совокупности с iptables, conntrack, namespaces позволяет организовывать полноценный оверлейные сети с мультитенанси. Естественно данная компонента может быть заменена, например при использовании сторонних проприетарных (вендорских) SDN решений.
OVS это программный коммутатор с открытым исходным кодом, который предназначен для использования в виртуализированных средах как виртуальный форвардер трафика.
На данный момент OVS имеет очень приличный функционал, в который входят такие технологии, как QoS, LACP, VLAN, VxLAN, GENEVE, OpenFlow, DPDK и т д.
Примечание: изначально OVS не задумывался как программный коммутатор для высоконагруженных телеком функций и был больше рассчитан под менее требовательные к пропускной способности ИТ функции типа WEB сервера или почтового сервера. Однако OVS дорабатывается и текущие реализации OVS сильно улучшили его производительность и возможности что позволяет его использовать операторам связи с высоконагруженными функциями, например есть реализация OVS с поддержкой DPDK ускорения.
Существует три важных компоненты OVS, о которых необходимо знать:
- Kernel module — компонента, расположенная в kernel space, которая выполняет обработку трафик на основе полученных от управляющего элемента правил;
- vSwitch daemon (ovs-vswitchd) — это процесс, запущенный в user space, который отвечает за программирование kernel модуля — то есть представляет непосредственно логику работы коммутатора
- Database server — локальная база данных, расположенная на каждом хосте, на котором запущен OVS, в которой хранится конфигурация. Через этот модуль по протоколу OVSDB могут общаться SDN контроллеры.
К этому всему еще прилагается набор диагностических и управляющих утилит, таких как ovs-vsctl, ovs-appctl, ovs-ofctl и т д.
В настоящий момент Openstack широко используется телеком операторами для миграции в него сетевых функций, таких как EPC, SBC, HLR и т д. Часть функций может без проблем жить с OVS в том виде в котором он есть, но например EPC обрабатывает трафик абонентов — то есть пропускает через себя огромное количество трафика (сейчас объемы трафика достигают нескольких сотен гигабит в секунду). Естественно гнать такой трафик через kernel space (так как по умолчанию форвардер расположен именно там) — не самая лучшая идея. Поэтому зачастую OVS разворачивают целиком в user space с использованием технологии ускорения DPDK для проброса трафика из NIC в user space минуя kernel.
Примечание: для облака, развернутого для телеком функций возможен вариант вывода трафика с compute ноды минуя OVS напрямую в коммутационное оборудование. Для этой цели используются механизмы SR-IOV и Passthrough.
Как это работает на реальном макете?
Ну и теперь перейдем к практической части и посмотрим как это все работает на практике.
Для начала развернем простенькую Openstack инсталляцию. Так как у меня под рукой под эксперименты нет набора серверов, то собирать макет будем на одном физическом сервере из виртуальных машин. Да, естественно под коммерческие цели такое решение не подходит, но чтобы посмотреть на примере как работает сеть в Openstack такой инсталляции хватит за глаза. Причем такая инсталляция для целей обучения даже интереснее — так как можно отловить трафик и т д.
Так как нам надо увидеть только базовую часть, то мы можем не использовать несколько сетей а все поднять с использованием всего двух сетей, причем вторая сеть в данном макете будет использоваться исключительно для доступа к undercloud и dns серверу. Внешние сети мы пока затрагивать не будем — это тема для отдельной большой статьи.
Итак, начнем по порядку. Сначала немного теории. Ставить мы будем Openstack с помощью TripleO (Openstack on Openstack). Суть TripleO заключается в том, что мы устанавливаем Openstack all-in-one (то есть на одну ноду), называемый undercloud, и далее используем возможности развернутого Openstack чтобы установить Openstack, предназначенный для эксплуатации, называемый overcloud. Undercloud будет использовать заложенную в него возможность управлять физическими серверами (bare metal) — проект Ironic — для провижининга гипервизоров, которые будут выполнять роли compute, control, storage нод. То есть мы не используем никаких сторонних средств для развертывания Openstack — мы разворачиваем Openstack силами Openstack. Далее по ходу установки станет намного понятнее, поэтому не будем останавливать на этом и пойдем вперед.
Примечание: В данной статье в целях упрощения я не стал использовать сетевую изоляцию для внутренних сетей Openstack, а все развернуто с использованием только одной сети. Однако наличие или отсутствие изоляции сетей не влияет на базовую функциональность решения — все будет работать точно также, как и при использовании изоляции, но трафик будет ходить в одной сети. Для коммерческой инсталляции естественно необходимо использовать изоляцию с использованием разных вланов и интерфейсов. Например трафик управления ceph хранилищем и трафик непосредственно данных (обращения машин к дискам и т д) при изоляции используют разные подсети (Storage management и Storage) и это позволяет сделать решение более отказоустойчивым, разделив данный трафик например по разным портам, либо использовать разные QoS профили для разного трафика, чтобы трафик данных не выдавил сигнальный трафик. В нашем же случае они будут идти в одной и той же сети и по факту это нас никак не лимитирует.
Примечание: Так как мы собираемся запускать виртуальные машины в виртуальной среде, базирующейся на виртуальных машинах, то для начала надо включить nested виртуализацию.
Проверить, включена ли nested виртуализация или нет можно так:
[root@hp-gen9 bormoglotx]# cat /sys/module/kvm_intel/parameters/nested N [root@hp-gen9 bormoglotx]#
Если вы видите букву N, то включаем поддержку nested виртуализации по любому гайду, который найдете в сети, например такой .
Нам надо собрать вот такую схему из виртуальных машин:

В моем случае для связности виртуальных машин, входящих в состав будущей инсталляции (а их у меня получилось 7 штук, но можно обойтись 4, если у вас не много ресурсов) я использовал OpenvSwitch. Я создал один ovs бридж и подключил к нему виртуальные машины черезе port-groups. Для этого создал xml файл следующего вида:
[root@hp-gen9 ~]# virsh net-dumpxml ovs-network-1
<network>
<name>ovs-network-1</name>
<uuid>7a2e7de7-fc16-4e00-b1ed-4d190133af67</uuid>
<forward mode='bridge'/>
<bridge name='ovs-br1'/>
<virtualport type='openvswitch'/>
<portgroup name='trunk-1'>
<vlan trunk='yes'>
<tag id='100'/>
<tag id='101'/>
<tag id='102'/>
</vlan>
</portgroup>
<portgroup name='access-100'>
<vlan>
<tag id='100'/>
</vlan>
</portgroup>
<portgroup name='access-101'>
<vlan>
<tag id='101'/>
</vlan>
</portgroup>
</network>Тут объявлены три порт группы — две access и одна trunk (последняя нужна была для DNS сервера, но можно обойтись и без него, либо поднять его на хостовой машине — это как вам удобнее). Далее с помощью данного шаблона объявляем нашу есть через virsh net-define:
virsh net-define ovs-network-1.xml
virsh net-start ovs-network-1
virsh net-autostart ovs-network-1 Теперь правим конфигурации портов гипервизора:
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens1f0
TYPE=Ethernet
NAME=ens1f0
DEVICE=ens1f0
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=ovs-br1
ONBOOT=yes
OVS_OPTIONS="trunk=100,101,102"
[root@hp-gen9 ~]
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ovs-br1
DEVICE=ovs-br1
DEVICETYPE=ovs
TYPE=OVSBridge
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.255.200
PREFIX=24
[root@hp-gen9 ~]# Примечание: в данном сценарии адрес на порту ovs-br1 не будет доступен, так как он не имеет влан тега. Чтобы это поправить надо дать команду sudo ovs-vsctl set port ovs-br1 tag=100. Однако после перезагрузки данный тег пропадет (если кто знает как заставить его остаться на месте — буду очень благодарен). Но это не столь важно, ибо данный адрес нам понадобится только на время инсталляции и будет не нужен, когда Openstack будет полностью развернут.Далее создаем undercloud машину:
virt-install -n undercloud --description "undercloud" --os-type=Linux --os-variant=centos7.0 --ram=8192 --vcpus=8 --disk path=/var/lib/libvirt/images/undercloud.qcow2,bus=virtio,size=40,format=qcow2 --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=access-101 --graphics none --location /var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso --extra-args console=ttyS0В ходе установки выставляете все нужные параметры, такие как имя машины, пароли, пользователи, ntp серверы и т д, можно сразу настроить и порты, но мне лично проще после установки зайти в машину через консоль и подправить нужные файлы. Если у вас уже есть готовый образ, то можете использовать его, либо поступить как я — скачать минимальный образ Centos 7 и использовать его для установки VM.
После успешной установки у вас должна появиться виртуальная машина на которую можно будет ставить undercloud
[root@hp-gen9 bormoglotx]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
62 undercloud runningСначала ставим необходимые в процессе установки инструменты:
sudo yum update -y
sudo yum install -y net-tools
sudo yum install -y wget
sudo yum install -y ipmitool
Установка Undercloud
Создаем юзера stack, задаем пароль, добавляем в sudoer и даем ему возможность выполнять root команды через sudo без необходимости ввода пароля:
useradd stack
passwd stack
echo “stack ALL=(root) NOPASSWD:ALL” > /etc/sudoers.d/stack
chmod 0440 /etc/sudoers.d/stackТеперь указываем в файле hosts полное имя undercloud:
vi /etc/hosts
127.0.0.1 undercloud.openstack.rnd localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6Далее добавляем репозитории и ставим нужный нам софт:
sudo yum install -y https://trunk.rdoproject.org/centos7/current/python2-tripleo-repos-0.0.1-0.20200409224957.8bac392.el7.noarch.rpm
sudo -E tripleo-repos -b queens current
sudo -E tripleo-repos -b queens current ceph
sudo yum install -y python-tripleoclient
sudo yum install -y ceph-ansibleПримечание: если вы не планируете ставить ceph, то команды, относящиеся к ceph вводить не надо. Я использовал релиз Queens, но вы можете использовать любой другой, который вам понравится.Далее копируем файл конфигурации undercloud в домашнюю директорию юзера stack:
cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.confТеперь необходимо поправить данный файл, подстроив его под нашу инсталляцию.
В начало файла надо добавить данные строки:
vi undercloud.conf
[DEFAULT]
undercloud_hostname = undercloud.openstack.rnd
local_ip = 192.168.255.1/24
network_gateway = 192.168.255.1
undercloud_public_host = 192.168.255.2
undercloud_admin_host = 192.168.255.3
undercloud_nameservers = 192.168.255.253
generate_service_certificate = false
local_interface = eth0
local_mtu = 1450
network_cidr = 192.168.255.0/24
masquerade = true
masquerade_network = 192.168.255.0/24
dhcp_start = 192.168.255.11
dhcp_end = 192.168.255.50
inspection_iprange = 192.168.255.51,192.168.255.100
scheduler_max_attempts = 10Итак, пройдем по настройкам:
undercloud_hostname — полное имя undercloud сервера, должно совпадать с записью на DNS сервере
local_ip — локальный адрес undercloud в сторону провиженинг сети
network_gateway — этот же локальный адрес, который будет выступать в качестве gateway для доступа во внешний мир во время установки overcloud нод, тоже совпадает с local ip
undercloud_public_host — адрес внешнего API, назначается любой свободный адрес из провижининг сети
undercloud_admin_host адрес внутреннего API, назначается любой свободный адрес из провижининг сети
undercloud_nameservers — DNS сервер
generate_service_certificate — данная строка очень важна в текущем примере, так как если ее не установить в значение false вы получите ошибку при установке, проблема описана на багтрекер Red Hat
local_interface интерфейс в провижининг сети. Данный интерфейс будет переконфигурирован во время разворачивания undercloud, поэтому на undercloud необходимо иметь два интерфейса — один для доступа до него, второй для провижининга
local_mtu — MTU. Так как у нас тестовая лаборатория и MTU у меня 1500 на портах OVS свича, то необходимо выставить в значение 1450, что бы прошли инкапсулированные в VxLAN пакеты
network_cidr — провижининг сеть
masquerade — использование NAT для доступа во внешнюю сеть
masquerade_network — сеть, которая будет NAT-ся
dhcp_start — начальный адрес пула адресов, из которого будут назначаться адреса нодам во время деплоя overcloud
dhcp_end — конечный адрес пула адресов, из которого будут назначаться адреса нодам во время деплоя overcloud
inspection_iprange — пул адресов, необходимых для проведения интроспекции (не должен пересекаться с вышеобозначенным пулом)
scheduler_max_attempts — максимальное количество попыток установки overcloud (должно быть больше или равно количеству нод)
После того, как файл описан, можно дать команду на деплой undercloud:
openstack undercloud install
Процедура занимает от 10 до 30 минут в зависимости от вашего железа. В конечном счете вы должны увидеть такой вывод:
vi undercloud.conf
2020-08-13 23:13:12,668 INFO:
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and should be
secured.
#############################################################################Данный вывод говорит, что вы успешно установили undercloud и теперь можно проверить состояние undercloud и переходить к установке overcloud.
Если посмотреть вывод ifconfig, то вы увидите, что появился новый бридж интерфейс
[stack@undercloud ~]$ ifconfig
br-ctlplane: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.1 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe2c:89e prefixlen 64 scopeid 0x20<link>
ether 52:54:00:2c:08:9e txqueuelen 1000 (Ethernet)
RX packets 14 bytes 1095 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1292 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Через данный интерфейс теперь будет производиться работа по развертыванию overcloud.
Из вывода ниже видно, что все сервисы у нас на одной ноде:
(undercloud) [stack@undercloud ~]$ openstack host list
+--------------------------+-----------+----------+
| Host Name | Service | Zone |
+--------------------------+-----------+----------+
| undercloud.openstack.rnd | conductor | internal |
| undercloud.openstack.rnd | scheduler | internal |
| undercloud.openstack.rnd | compute | nova |
+--------------------------+-----------+----------+Ниже показана конфигурация сетевой части undercloud:
(undercloud) [stack@undercloud ~]$ python -m json.tool /etc/os-net-config/config.json
{
"network_config": [
{
"addresses": [
{
"ip_netmask": "192.168.255.1/24"
}
],
"members": [
{
"dns_servers": [
"192.168.255.253"
],
"mtu": 1450,
"name": "eth0",
"primary": "true",
"type": "interface"
}
],
"mtu": 1450,
"name": "br-ctlplane",
"ovs_extra": [
"br-set-external-id br-ctlplane bridge-id br-ctlplane"
],
"routes": [],
"type": "ovs_bridge"
}
]
}
(undercloud) [stack@undercloud ~]$Установка overcloud
На данный момент у нас есть только undercloud, и нам не хватает нод, из которых будет собираться overcloud. Поэтому первым делом развернем нужные нам виртуальные машины. В ходе деплоя undercloud сам поставит ОС и нужный софт на overcloud машины — то есть нам не нужно полностью разворачивать машину, а только создать для нее диск (или диски) и определить ее параметры — то есть по факту получаем голый сервер без установленной на него ОС.
Переходим в папку с дисками наших виртуальных машин и создадим диски нужного объема:
cd /var/lib/libvirt/images/
qemu-img create -f qcow2 -o preallocation=metadata control-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-2.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata storage-1.qcow2 160G
qemu-img create -f qcow2 -o preallocation=metadata storage-2.qcow2 160GТак как действуем мы от рута, то нам надо изменить владельца этих дисков чтобы не получить проблему с правами:
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:07 undercloud.qcow2
[root@hp-gen9 images]#
[root@hp-gen9 images]#
[root@hp-gen9 images]# chown qemu:qemu /var/lib/libvirt/images/*qcow2
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:08 undercloud.qcow2
[root@hp-gen9 images]# Примечание: если вы планируете ставить ceph в целях его изучения, то создавайте как минимум 3 ноды с минимум двумя дисками, а в темплейте укажите, что будут использоваться виртуальные диски vda, vdb и т д.Отлично, теперь нам надо все эти машины определить:
virt-install --name control-1 --ram 32768 --vcpus 8 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/control-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=trunk-1 --dry-run --print-xml > /tmp/control-1.xml
virt-install --name storage-1 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-1.xml
virt-install --name storage-2 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-2.xml
virt-install --name compute-1 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-1.xml
virt-install --name compute-2 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-2.xml В конце есть команды --print-xml > /tmp/storage-1.xml, которая создает xml файл с описанием каждой машине в папке /tmp/, если ее не добавить, то не сможете определить виртуальные машины.
Теперь нам надо все эти машины определить в virsh:
virsh define --file /tmp/control-1.xml
virsh define --file /tmp/compute-1.xml
virsh define --file /tmp/compute-2.xml
virsh define --file /tmp/storage-1.xml
virsh define --file /tmp/storage-2.xml
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#Теперь небольшой нюанс — tripleO использует IPMI для того, чтобы управлять серверами во время установки и интроспекции.
Интроспекция — это процесс инспекции аппратной части в целях получения ее параметров, необходимых для дальнешего провижининга нод. Интроспекция производится с помошью ironic — службы, предназначенной для работы с bare metal серверами.
Но вот тут проблема — если у железных серверов IPMI это отдельный порт (или shared порт, но это не принципиально), то у виртуальных машин таких портов нет. Тут нам на помощь приходит костыль под названием vbmc — утилита, которая позволяет эмулировать IPMI порт. На этот нюанс стоит обратить внимание особенно тем, кто захочет поднять такую лабораторию на ESXI гипервизоре — еслич естно, не знаю есть ли в нем аналог vbmc, поэтому стоит озадачиться этим вопросом перед тем как все разворачивать.
Устанавливаем vbmc:
yum install yum install python2-virtualbmcЕсли ваша ОС не может найти пакет, то добавьте репозиторий:
yum install -y https://www.rdoproject.org/repos/rdo-release.rpmТеперь настраиваем утилиту. Тут все банально до безобразия. Сейчас логично, что в списке vbmc нет никаких серверов
[root@hp-gen9 ~]# vbmc list
[root@hp-gen9 ~]# Чтобы они появились их необходимо вручную объявить таким образом:
[root@hp-gen9 ~]# vbmc add control-1 --port 7001 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-1 --port 7002 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-2 --port 7003 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-1 --port 7004 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-2 --port 7005 --username admin --password admin
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+--------+---------+------+
| Domain name | Status | Address | Port |
+-------------+--------+---------+------+
| compute-1 | down | :: | 7004 |
| compute-2 | down | :: | 7005 |
| control-1 | down | :: | 7001 |
| storage-1 | down | :: | 7002 |
| storage-2 | down | :: | 7003 |
+-------------+--------+---------+------+
[root@hp-gen9 ~]#Думаю синтаксис команды понятен и без объяснений. Однако пока что все наши сессии в статусе DOWN. Чтобы они перешли в статус UP, необходимо их включить:
[root@hp-gen9 ~]# vbmc start control-1
2020-08-14 03:15:57,826.826 13149 INFO VirtualBMC [-] Started vBMC instance for domain control-1
[root@hp-gen9 ~]# vbmc start storage-1
2020-08-14 03:15:58,316.316 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-1
[root@hp-gen9 ~]# vbmc start storage-2
2020-08-14 03:15:58,851.851 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-2
[root@hp-gen9 ~]# vbmc start compute-1
2020-08-14 03:15:59,307.307 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-1
[root@hp-gen9 ~]# vbmc start compute-2
2020-08-14 03:15:59,712.712 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-2
[root@hp-gen9 ~]#
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+---------+---------+------+
| Domain name | Status | Address | Port |
+-------------+---------+---------+------+
| compute-1 | running | :: | 7004 |
| compute-2 | running | :: | 7005 |
| control-1 | running | :: | 7001 |
| storage-1 | running | :: | 7002 |
| storage-2 | running | :: | 7003 |
+-------------+---------+---------+------+
[root@hp-gen9 ~]#И последний штрих — необходимо поправить правила фаервола (ну либо отключить его совсем):
firewall-cmd --zone=public --add-port=7001/udp --permanent
firewall-cmd --zone=public --add-port=7002/udp --permanent
firewall-cmd --zone=public --add-port=7003/udp --permanent
firewall-cmd --zone=public --add-port=7004/udp --permanent
firewall-cmd --zone=public --add-port=7005/udp --permanent
firewall-cmd --reload
Теперь зайдем в undercloud и проверим что все работает. Адрес хостовой машины — 192.168.255.200, на undercloud мы добавили нужный пакет ipmitool во время подготовки к деплою:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power on
Chassis Power Control: Up/On
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
65 control-1 runningКак видите, мы успешно запустили control ноду через vbmc. Теперь выключим ее и пойдем дальше:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power off
Chassis Power Control: Down/Off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#Следующий шаг — это интроспекция нод, на которые будет ставиться overcloud. Для этого нам надо подготовить json файл с описанием наших нод. Обратите внимание, что в отличии от установки на голые серверы в файле указан порт, на котором запущен vbmc для каждой из машин.
[root@hp-gen9 ~]# virsh domiflist --domain control-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:20:a2:2f
- network ovs-network-1 virtio 52:54:00:3f:87:9f
[root@hp-gen9 ~]# virsh domiflist --domain compute-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:98:e9:d6
[root@hp-gen9 ~]# virsh domiflist --domain compute-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:6a:ea:be
[root@hp-gen9 ~]# virsh domiflist --domain storage-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:79:0b:cb
[root@hp-gen9 ~]# virsh domiflist --domain storage-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:a7:fe:27Примечание: на контрольной ноде два интерфейса, но в данном случае это не важно, в данной инсталляции нам хватит и одного.Теперь готовим json файл. Нам надо указать мак адрес порта, через который будет производиться провижининг, параметры нод, задать им имена и указать как попасть на ipmi:
{
"nodes":[
{
"mac":[
"52:54:00:20:a2:2f"
],
"cpu":"8",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"control-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7001"
},
{
"mac":[
"52:54:00:79:0b:cb"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7002"
},
{
"mac":[
"52:54:00:a7:fe:27"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7003"
},
{
"mac":[
"52:54:00:98:e9:d6"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7004"
},
{
"mac":[
"52:54:00:6a:ea:be"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7005"
}
]
}Теперь нам надо подготовить образы для ironic. Для этого скачиваем их через wget и устанавливаем:
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/overcloud-full.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/ironic-python-agent.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ ls -lh
total 1.9G
-rw-r--r--. 1 stack stack 447M Aug 14 10:26 ironic-python-agent.tar
-rw-r--r--. 1 stack stack 1.5G Aug 14 10:26 overcloud-full.tar
-rw-------. 1 stack stack 916 Aug 13 23:10 stackrc
-rw-r--r--. 1 stack stack 15K Aug 13 22:50 undercloud.conf
-rw-------. 1 stack stack 2.0K Aug 13 22:50 undercloud-passwords.conf
(undercloud) [stack@undercloud ~]$ mkdir images/
(undercloud) [stack@undercloud ~]$ tar -xpvf ironic-python-agent.tar -C ~/images/
ironic-python-agent.initramfs
ironic-python-agent.kernel
(undercloud) [stack@undercloud ~]$ tar -xpvf overcloud-full.tar -C ~/images/
overcloud-full.qcow2
overcloud-full.initrd
overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ ls -lh images/
total 1.9G
-rw-rw-r--. 1 stack stack 441M Aug 12 17:24 ironic-python-agent.initramfs
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:24 ironic-python-agent.kernel
-rw-r--r--. 1 stack stack 53M Aug 12 17:14 overcloud-full.initrd
-rw-r--r--. 1 stack stack 1.4G Aug 12 17:18 overcloud-full.qcow2
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:14 overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$Загружаем образы в undercloud:
(undercloud) [stack@undercloud ~]$ openstack overcloud image upload --image-path ~/images/
Image "overcloud-full-vmlinuz" was uploaded.
+--------------------------------------+------------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------------+-------------+---------+--------+
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aki | 6761064 | active |
+--------------------------------------+------------------------+-------------+---------+--------+
Image "overcloud-full-initrd" was uploaded.
+--------------------------------------+-----------------------+-------------+----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-----------------------+-------------+----------+--------+
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | ari | 55183045 | active |
+--------------------------------------+-----------------------+-------------+----------+--------+
Image "overcloud-full" was uploaded.
+--------------------------------------+----------------+-------------+------------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+----------------+-------------+------------+--------+
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | qcow2 | 1487475712 | active |
+--------------------------------------+----------------+-------------+------------+--------+
Image "bm-deploy-kernel" was uploaded.
+--------------------------------------+------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------+-------------+---------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aki | 6761064 | active |
+--------------------------------------+------------------+-------------+---------+--------+
Image "bm-deploy-ramdisk" was uploaded.
+--------------------------------------+-------------------+-------------+-----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-------------------+-------------+-----------+--------+
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | ari | 461759376 | active |
+--------------------------------------+-------------------+-------------+-----------+--------+
(undercloud) [stack@undercloud ~]$Проверяем, что все образы загрузились
(undercloud) [stack@undercloud ~]$ openstack image list
+--------------------------------------+------------------------+--------+
| ID | Name | Status |
+--------------------------------------+------------------------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | active |
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | active |
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | active |
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | active |
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | active |
+--------------------------------------+------------------------+--------+
(undercloud) [stack@undercloud ~]$Еще один штрих — надо добавить dns сервер:
(undercloud) [stack@undercloud ~]$ openstack subnet list
+--------------------------------------+-----------------+--------------------------------------+------------------+
| ID | Name | Network | Subnet |
+--------------------------------------+-----------------+--------------------------------------+------------------+
| f45dea46-4066-42aa-a3c4-6f84b8120cab | ctlplane-subnet | 6ca013dc-41c2-42d8-9d69-542afad53392 | 192.168.255.0/24 |
+--------------------------------------+-----------------+--------------------------------------+------------------+
(undercloud) [stack@undercloud ~]$ openstack subnet show f45dea46-4066-42aa-a3c4-6f84b8120cab
+-------------------+-----------------------------------------------------------+
| Field | Value |
+-------------------+-----------------------------------------------------------+
| allocation_pools | 192.168.255.11-192.168.255.50 |
| cidr | 192.168.255.0/24 |
| created_at | 2020-08-13T20:10:37Z |
| description | |
| dns_nameservers | |
| enable_dhcp | True |
| gateway_ip | 192.168.255.1 |
| host_routes | destination='169.254.169.254/32', gateway='192.168.255.1' |
| id | f45dea46-4066-42aa-a3c4-6f84b8120cab |
| ip_version | 4 |
| ipv6_address_mode | None |
| ipv6_ra_mode | None |
| name | ctlplane-subnet |
| network_id | 6ca013dc-41c2-42d8-9d69-542afad53392 |
| prefix_length | None |
| project_id | a844ccfcdb2745b198dde3e1b28c40a3 |
| revision_number | 0 |
| segment_id | None |
| service_types | |
| subnetpool_id | None |
| tags | |
| updated_at | 2020-08-13T20:10:37Z |
+-------------------+-----------------------------------------------------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ neutron subnet-update f45dea46-4066-42aa-a3c4-6f84b8120cab --dns-nameserver 192.168.255.253
neutron CLI is deprecated and will be removed in the future. Use openstack CLI instead.
Updated subnet: f45dea46-4066-42aa-a3c4-6f84b8120cab
(undercloud) [stack@undercloud ~]$Теперь мы можем дать команду на интроспекцию:
(undercloud) [stack@undercloud ~]$ openstack overcloud node import --introspect --provide inspection.json
Started Mistral Workflow tripleo.baremetal.v1.register_or_update. Execution ID: d57456a3-d8ed-479c-9a90-dff7c752d0ec
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "manageable" state.
Successfully registered node UUID b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
Successfully registered node UUID b89a72a3-6bb7-429a-93bc-48393d225838
Successfully registered node UUID 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
Successfully registered node UUID bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
Successfully registered node UUID 766ab623-464c-423d-a529-d9afb69d1167
Waiting for introspection to finish...
Started Mistral Workflow tripleo.baremetal.v1.introspect. Execution ID: 6b4d08ae-94c3-4a10-ab63-7634ec198a79
Waiting for messages on queue 'tripleo' with no timeout.
Introspection of node b89a72a3-6bb7-429a-93bc-48393d225838 completed. Status:SUCCESS. Errors:None
Introspection of node 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e completed. Status:SUCCESS. Errors:None
Introspection of node bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 completed. Status:SUCCESS. Errors:None
Introspection of node 766ab623-464c-423d-a529-d9afb69d1167 completed. Status:SUCCESS. Errors:None
Introspection of node b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 completed. Status:SUCCESS. Errors:None
Successfully introspected 5 node(s).
Started Mistral Workflow tripleo.baremetal.v1.provide. Execution ID: f5594736-edcf-4927-a8a0-2a7bf806a59a
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "available" state.
(undercloud) [stack@undercloud ~]$Как видно из вывода все завершилось без ошибок. Проверим, что все ноды в состоянии available:
(undercloud) [stack@undercloud ~]$ openstack baremetal node list
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | None | power off | available | False |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | None | power off | available | False |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | None | power off | available | False |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | None | power off | available | False |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | None | power off | available | False |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
(undercloud) [stack@undercloud ~]$ Если ноды будут в другом состоянии, как правило manageable, то что то пошло не так и надо смотреть лог, разбираться, почему так получилось. Имейте ввиду, что в данном сценарии мы используем виртуализацию и могут быть баги связанные с использованием виртуальных машин или vbmc.
Далее нам надо указать какая нода какую функцию будет выполнять — то есть указать профиль, с которым нода будет деплоиться:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | None | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | None | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | None | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | None | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | None | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$ openstack flavor list
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| 168af640-7f40-42c7-91b2-989abc5c5d8f | swift-storage | 4096 | 40 | 0 | 1 | True |
| 52148d1b-492e-48b4-b5fc-772849dd1b78 | baremetal | 4096 | 40 | 0 | 1 | True |
| 56e66542-ae60-416d-863e-0cb192d01b09 | control | 4096 | 40 | 0 | 1 | True |
| af6796e1-d0c4-4bfe-898c-532be194f7ac | block-storage | 4096 | 40 | 0 | 1 | True |
| e4d50fdd-0034-446b-b72c-9da19b16c2df | compute | 4096 | 40 | 0 | 1 | True |
| fc2e3acf-7fca-4901-9eee-4a4d6ef0265d | ceph-storage | 4096 | 40 | 0 | 1 | True |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
(undercloud) [stack@undercloud ~]$Указываем профиль для каждой ноды:
openstack baremetal node set --property capabilities='profile:control,boot_option:local' b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' b89a72a3-6bb7-429a-93bc-48393d225838
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 766ab623-464c-423d-a529-d9afb69d1167Проверяем, что мы сделали все корректно:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | control | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | ceph-storage | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | ceph-storage | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | compute | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | compute | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$Если все верно, даем команду на деплой overcloud:
openstack overcloud deploy --templates --control-scale 1 --compute-scale 2 --ceph-storage-scale 2 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --libvirt-type qemuВ реальной инсталляции естественно будут использовать кастомизированные темплейты, в нашем случае это очень сильно усложнит процесс, так как надо будет объяснить каждую правку в шаблоне. Как было написано ранее — даже простой инсталляции нам будет достаточно, чтобы посмотреть, как это работает.
Примечание: переменная --libvirt-type qemu в данном случае необходима, так как мы будем использовать nested виртуализаци. В противном случае у вас не будут запускать виртуальные машины.
Теперь у вас есть около часа, а может и больше (зависит от возможностей железа) и вам остается надеяться, что по истечению этого времени вы увидите такую надпись:
2020-08-14 08:39:21Z [overcloud]: CREATE_COMPLETE Stack CREATE completed successfully
Stack overcloud CREATE_COMPLETE
Host 192.168.255.21 not found in /home/stack/.ssh/known_hosts
Started Mistral Workflow tripleo.deployment.v1.get_horizon_url. Execution ID: fcb996cd-6a19-482b-b755-2ca0c08069a9
Overcloud Endpoint: http://192.168.255.21:5000/
Overcloud Horizon Dashboard URL: http://192.168.255.21:80/dashboard
Overcloud rc file: /home/stack/overcloudrc
Overcloud Deployed
(undercloud) [stack@undercloud ~]$Теперь у вас есть почти полноценная версия опенстак, на которой вы можете учиться, ставить опыты и т д.
Проверим что все нормально работает. В домашней директории юзера stack есть два файла — один stackrc (для управления undercloud) и второй overcloudrc (для управления overcloud). Эти файлы необходимо указать как source, так как в них содержится необходимая для аутентификации информация.
(undercloud) [stack@undercloud ~]$ openstack server list
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| fd7d36f4-ce87-4b9a-93b0-add2957792de | overcloud-controller-0 | ACTIVE | ctlplane=192.168.255.15 | overcloud-full | control |
| edc77778-8972-475e-a541-ff40eb944197 | overcloud-novacompute-1 | ACTIVE | ctlplane=192.168.255.26 | overcloud-full | compute |
| 5448ce01-f05f-47ca-950a-ced14892c0d4 | overcloud-cephstorage-1 | ACTIVE | ctlplane=192.168.255.34 | overcloud-full | ceph-storage |
| ce6d862f-4bdf-4ba3-b711-7217915364d7 | overcloud-novacompute-0 | ACTIVE | ctlplane=192.168.255.19 | overcloud-full | compute |
| e4507bd5-6f96-4b12-9cc0-6924709da59e | overcloud-cephstorage-0 | ACTIVE | ctlplane=192.168.255.44 | overcloud-full | ceph-storage |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ source overcloudrc
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack project list
+----------------------------------+---------+
| ID | Name |
+----------------------------------+---------+
| 4eed7d0f06544625857d51cd77c5bd4c | admin |
| ee1c68758bde41eaa9912c81dc67dad8 | service |
+----------------------------------+---------+
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$В моей инсталляции еще требуется один небольшой штрих — добавить маршрут на контроллере, так как машина, с которой я работаю находится в другой сети. Для этого зайдем на control-1 под учеткой heat-admin и пропишем маршрут
(undercloud) [stack@undercloud ~]$ ssh heat-admin@192.168.255.15
Last login: Fri Aug 14 09:47:40 2020 from 192.168.255.1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ip route add 10.169.0.0/16 via 192.168.255.254Ну и теперь вы можете зайти в горизонт. Вся информация — адреса, логин и пароль — лежат в файле /home/stack/overcloudrc. Итоговая схема выглядит следующим образом:

К слову говоря, в нашей инсталляции адреса машин выдавались через DHCP и как видите, они выдаются “как попало”. Вы можете в темплейте жестко задать, какой адрес какой машине нужно прикрепить во время деплоя, если вам это необходимо.
Как же ходит трафик между виртуальными машинами?
В данной статье мы рассмотрим три варианта прохождения трафик
- Две машины на одном гипервизоре в одной L2 сети
- Две машины на разных гипервизорах в одной L2 сети
- Две машины в разных сетях (рутинг между сетями)
Кейсы с выходом в внешний мир через external сеть, с использованием плавающих адресов, а также распределенную маршрутизацию рассмотрим в следующий раз, пока что остановимся на внутреннем трафике.
Для проверки соберем такую схему:
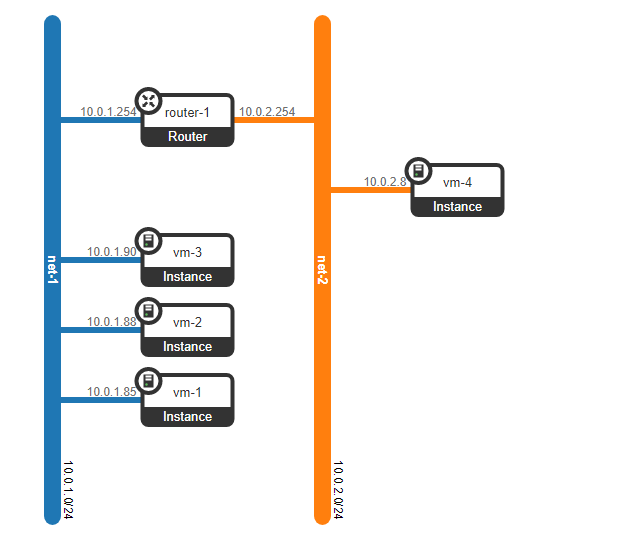
У нас создано 4 виртуальные машины — 3 в одной L2 сети — net-1, и ещё 1 в сети net-2
(overcloud) [stack@undercloud ~]$ nova list --tenant 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| ID | Name | Tenant ID | Status | Task State | Power State | Networks |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| f53b37b5-2204-46cc-aef0-dba84bf970c0 | vm-1 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.85 |
| fc8b6722-0231-49b0-b2fa-041115bef34a | vm-2 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.88 |
| 3cd74455-b9b7-467a-abe3-bd6ff765c83c | vm-3 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.90 |
| 7e836338-6772-46b0-9950-f7f06dbe91a8 | vm-4 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-2=10.0.2.8 |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
(overcloud) [stack@undercloud ~]$ Посмотрим, на каких гипервизорах расположены созданные машины:
(overcloud) [stack@undercloud ~]$ nova show f53b37b5-2204-46cc-aef0-dba84bf970c0 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-1 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000001 |(overcloud) [stack@undercloud ~]$ nova show fc8b6722-0231-49b0-b2fa-041115bef34a | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-2 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000002 |(overcloud) [stack@undercloud ~]$ nova show 3cd74455-b9b7-467a-abe3-bd6ff765c83c | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-3 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000003 |(overcloud) [stack@undercloud ~]$ nova show 7e836338-6772-46b0-9950-f7f06dbe91a8 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-4 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000004 |(overcloud) [stack@undercloud ~]$
Машины vm-1 и vm-3 расположены на compute-0, машины vm-2 и vm-4 расположены на ноде compute-1.
Кроме того создан виртуальный маршрутизатор для возможности маршрутизации между указанными сетями:
(overcloud) [stack@undercloud ~]$ openstack router list --project 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| ID | Name | Status | State | Distributed | HA | Project |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | router-1 | ACTIVE | UP | False | False | 5e18ce8ec9594e00b155485f19895e6c |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
(overcloud) [stack@undercloud ~]$ У маршрутизатора два виртуальных порта, который выполняют роль шлюзов для сетей:
(overcloud) [stack@undercloud ~]$ openstack router show 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | grep interface
| interfaces_info | [{"subnet_id": "2529ad1a-6b97-49cd-8515-cbdcbe5e3daa", "ip_address": "10.0.1.254", "port_id": "0c52b15f-8fcc-4801-bf52-7dacc72a5201"}, {"subnet_id": "335552dd-b35b-456b-9df0-5aac36a3ca13", "ip_address": "10.0.2.254", "port_id": "92fa49b5-5406-499f-ab8d-ddf28cc1a76c"}] |
(overcloud) [stack@undercloud ~]$ Но перед тем как смотреть, как ходит трафик, давайте рассмотрим, что мы имеем на данный момент на контрольной ноде (которая по совместительству и network нода) и на compute ноду. Начнем с compute ноды.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-vsctl show
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:3 missed:3
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$В данный момент на ноде три ovs бриджа — br-int, br-tun, br-ex. Между ними, как мы видим есть набор интерфейсов. Для простоты восприятия нанесем все данные интерфейсы на схему и посмотрим, что получится.

По адресам, на которые подняты VxLAN тоннели видно, что один тоннель поднят на compute-1 (192.168.255.26), второй тоннель смотрит на control-1 (192.168.255.15). Но наиболее интересно то, что br-ex нет физических интерфейсов, а если посмотреть, какие флоу настроены, то видно, что данный бридж в данный момент может только дропать трафик.
[heat-admin@overcloud-novacompute-0 ~]$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.19 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe6a:eabe prefixlen 64 scopeid 0x20<link>
ether 52:54:00:6a:ea:be txqueuelen 1000 (Ethernet)
RX packets 2909669 bytes 4608201000 (4.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1821057 bytes 349198520 (333.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-novacompute-0 ~]$ Как видно из вывода адрес прикручен напрямую на физический порт, а не на виртуальный бридж интерфейс.
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-ex
cookie=0x9169eae8f7fe5bb2, duration=216686.864s, table=0, n_packets=303, n_bytes=26035, priority=2,in_port="phy-br-ex" actions=drop
cookie=0x9169eae8f7fe5bb2, duration=216686.887s, table=0, n_packets=0, n_bytes=0, priority=0 actions=NORMAL
[heat-admin@overcloud-novacompute-0 ~]$ Согласно первому правило, все что пришло из порта phy-br-ex необходимо отбросить.
Собственно в данный бридж пока что больше неоткуда взяться трафику, кроме как из данного интерфейса (стык с br-int), и судя по дропам в бридж уже прилетал BUM трафик.
То есть с данной ноды трафик может уйти только через VxLAN тоннель и никак больше. Однако если включить DVR ситуация изменится, но с этим разберемся в другой раз. При использовании изоляции сетей например с помощью вланов, у вас будет не один L3 интерфейс в 0-вом влане, а несколько интерфейсов. Однако VxLAN трафик будет выходить с ноды точно так же, но инкапсулированный еще и в какой то выделенный влан.
С compute нодой разобрались, переходим к control ноде.
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl dpif/show
system@ovs-system: hit:930491 missed:825
br-ex:
br-ex 65534/1: (internal)
eth0 1/2: (system)
phy-br-ex 2/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/3: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/4: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff13 3/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.19)
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$По факту можно сказать, что все тоже самое, однако ip адрес уже находится не на физическом интерфейсе а на виртуальном бридже. Это сделано из-за того, что данный порт является портом, через который будет выходить трафик во внешний мир.
[heat-admin@overcloud-controller-0 ~]$ ifconfig br-ex
br-ex: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.15 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe20:a22f prefixlen 64 scopeid 0x20<link>
ether 52:54:00:20:a2:2f txqueuelen 1000 (Ethernet)
RX packets 803859 bytes 1732616116 (1.6 GiB)
RX errors 0 dropped 63 overruns 0 frame 0
TX packets 808475 bytes 121652156 (116.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
3 100 28:c0:da:00:4d:d3 35
1 0 28:c0:da:00:4d:d3 35
1 0 52:54:00:98:e9:d6 0
LOCAL 0 52:54:00:20:a2:2f 0
1 0 52:54:00:2c:08:9e 0
3 100 52:54:00:20:a2:2f 0
1 0 52:54:00:6a:ea:be 0
[heat-admin@overcloud-controller-0 ~]$ Данный порт привязан к бриджу br-ex и так как на нем нет никаких влан тегов, то данный порт является транковым портом на котором разрешены все вланы, сейчас трафик выходит наружу без тега, о чем говорит vlan-id 0 в выводе выше.
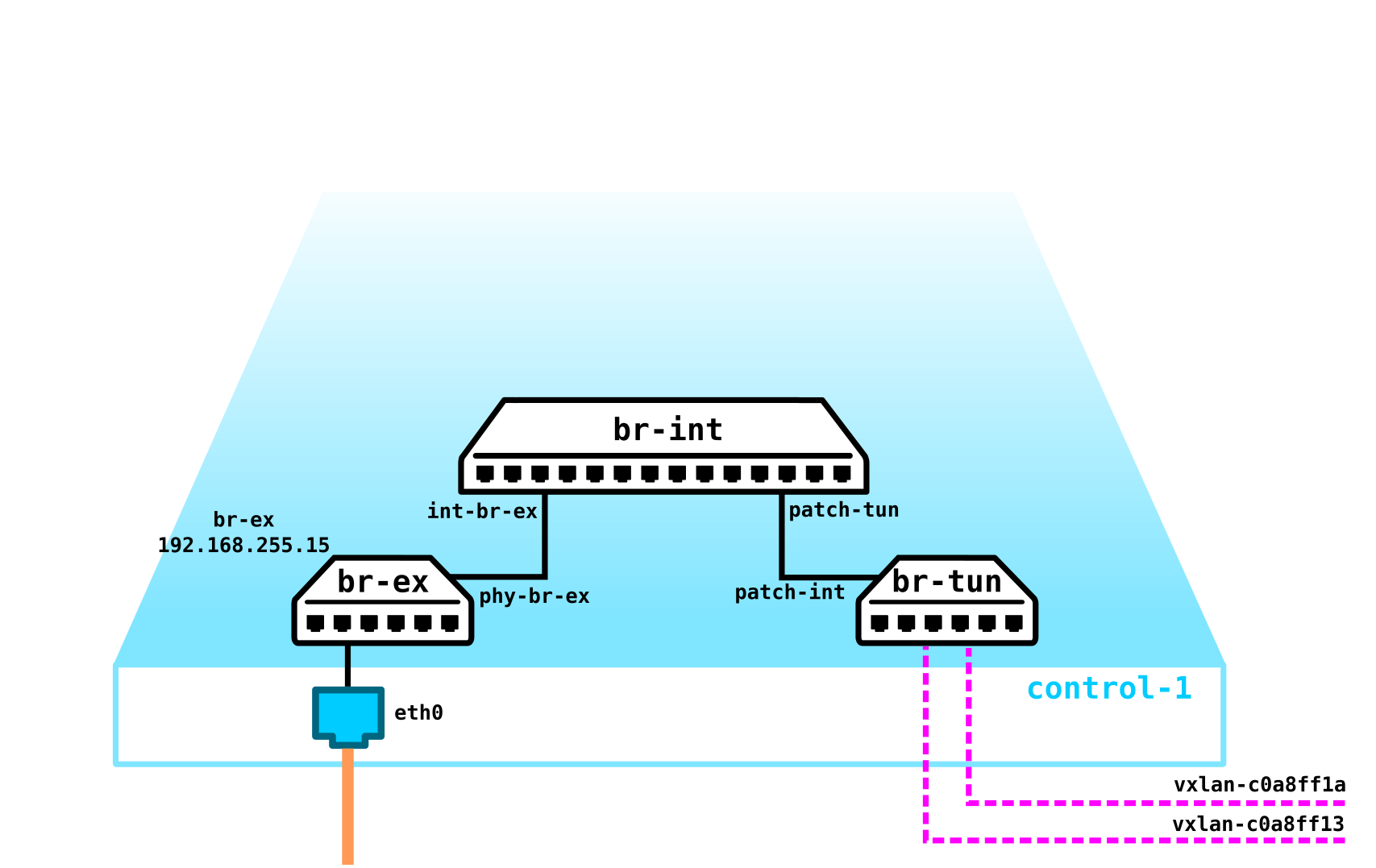
Все остальное в данный момент аналогично compute ноде — те же бриджи, те же тоннели, идущие на две compute ноды.
Storage ноды мы рассматривать в данной статье не будем, но для понимания необходимо сказать, что сетевая часть данных нод банальна до безобразия. В нашем случае там всего один физический порт (eth0) с навешенным на него ip адресом и все. Там нет никаких VxLAN тоннелей, тоннельных бриджей и т д — там нет ovs вообще, так как нет от него смысла. При использовании изоляции сетей — на данной ноде будет два интерфейса (физических порта, бодны, или просто два влана — это не важно — зависит от того, что вы хотите) — один под управление, второй под трафик (запись на диск VM, чтение с диска и т д).
Разобрались что у нас есть на нодах в отсутствии каких либо сервисов. Теперь запустим 4 виртуальные машины и посмотрим, как изменится описанная выше схема — у нас должны появиться порты, виртуальные роутеры и т д.
Пока что наша сеть выглядит вот так:
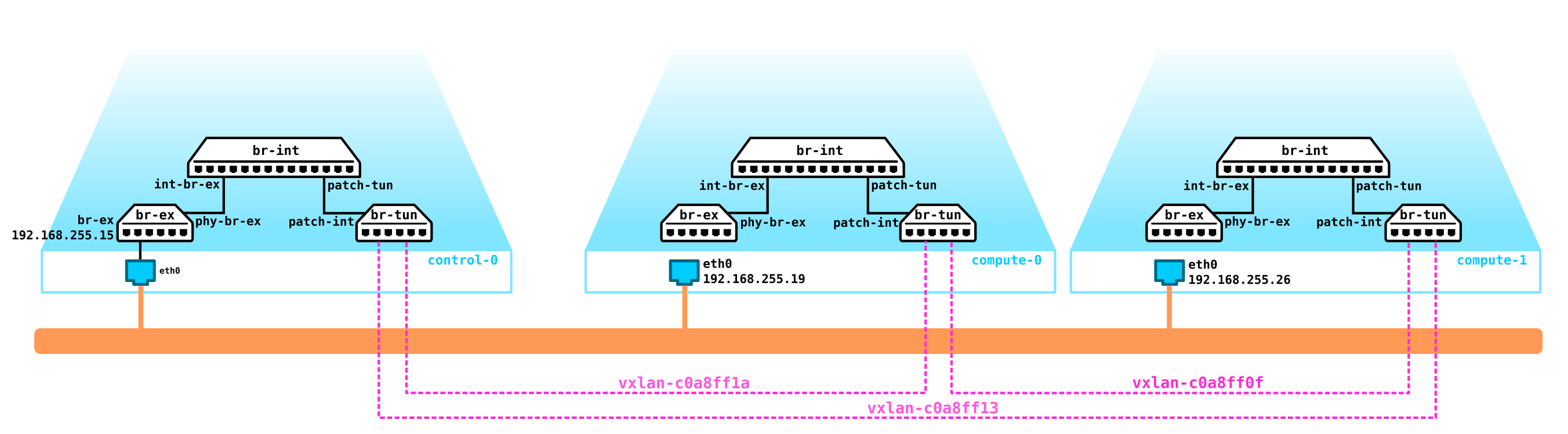
У нас по две виртуальные машины на каждой компьют ноде. На примере compute-0 посмотрим, как все включено.
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh list
Id Name State
----------------------------------------------------
1 instance-00000001 running
3 instance-00000003 running
[heat-admin@overcloud-novacompute-0 ~]$ У машины всего один виртуальный интерфейс — tap95d96a75-a0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
Данный интерфейс смотрит в linux bridge:
[heat-admin@overcloud-novacompute-0 ~]$ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242904c92a8 no
qbr5bd37136-47 8000.5e4e05841423 no qvb5bd37136-47
tap5bd37136-47
qbr95d96a75-a0 8000.de076cb850f6 no qvb95d96a75-a0
tap95d96a75-a0
[heat-admin@overcloud-novacompute-0 ~]$ Как видно из вывода в брижде всего два интерфейса — tap95d96a75-a0 и qvb95d96a75-a0.
Тут стоит немного остановиться на типах виртуальных сетевых устройства в OpenStack:Как вы понимаете, если у нас в брижде есть qvb95d96a75-a0 порт, который является vEth парой, то где то есть его ответная сторона, которая логично должна называться qvo95d96a75-a0. Смотрим, какие порты есть на OVS.
vtap — виртуальный интерфейс, присоединенный к инстансу (ВМ)
qbr — Linux bridge
qvb и qvo — vEth пара, подключенная к Linux bridge и Open vSwitch bridge
br-int, br-tun, br-vlan — Open vSwitch bridges
patch-, int-br-, phy-br- — Open vSwitch patch-интерфейсы, соединяющие bridges
qg, qr, ha, fg, sg — порты Open vSwitch, используемые виртуальными устройствами для подключения к OVS
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:526 missed:91
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
qvo5bd37136-47 6/6: (system)
qvo95d96a75-a0 3/5: (system)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$ Как мы видим порт находится в br-int. Br-int выполняет роль коммутатора, терминирующего порты виртуальных машин. Помимо qvo95d96a75-a0 в выводе виден порт qvo5bd37136-47. Это порт во вторую виртуальную машину. В итоге наша схема теперь выглядит так:

Вопрос, который должен сразу заинтересовать внимательного читателя — на кой linux bridge между портом виртуальной машины и портом OVS? Дело в том, что для защиты машины используются security groups, которые есть не что иное как iptables. OVS не работает с iptables, поэтому был придуман такой “костыль”. Однако он отживает свое — ему на смену приходит conntrack в новых релизах.
То есть в конечном счете схема выглядит так:

Две машины на одном гипервизоре в одной L2 сети
Так как две данные VM находятся в одной и той же L2 сети и на одном и том же гипервизоре, то трафик между ними будет логично ходить локально через br-int, так как обе машины будут в одном и том же VLAN:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000003
Interface Type Source Model MAC
-------------------------------------------------------
tap5bd37136-47 bridge qbr5bd37136-47 virtio fa:16:3e:83:ad:a4
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int
port VLAN MAC Age
6 1 fa:16:3e:83:ad:a4 0
3 1 fa:16:3e:44:98:20 0
[heat-admin@overcloud-novacompute-0 ~]$ Две машины на разных гипервизорах в одной L2 сети
Теперь посмотрим, как пойдет трафик между двумя машинами в одной L2 сети, но расположенными на разных гипервизорах. Если быть честным, то особо сильно ничего не поменяется, просто трафик между гипервизорами пойдет через vxlan тоннель. Посмотрим на примере.
Адреса виртуальных машин, между которыми будем смотреть трафик:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000002
Interface Type Source Model MAC
-------------------------------------------------------
tape7e23f1b-07 bridge qbre7e23f1b-07 virtio fa:16:3e:72:ad:53
[heat-admin@overcloud-novacompute-1 ~]$ Смотрим таблицу форвардинга в br-int на compute-0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:72:ad:53
2 1 fa:16:3e:72:ad:53 1
[heat-admin@overcloud-novacompute-0 ~]Трафик должен уйти в порт 2 — смотрим что это за порт:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$Это patch-tun — то есть интерфейс в br-tun. Смотрим, что происходит с пакетом на br-tun:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:72:ad:53
cookie=0x8759a56536b67a8e, duration=1387.959s, table=20, n_packets=1460, n_bytes=138880, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:72:ad:53 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-novacompute-0 ~]$ Пакет упаковывается в VxLAN и отправляется в порт 2. Смотрим, куда ведет порт 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:b2:d1:f8:21:96:66
2(vxlan-c0a8ff1a): addr:be:64:1f:75:78:a7
3(vxlan-c0a8ff0f): addr:76:6f:b9:3c:3f:1c
LOCAL(br-tun): addr:a2:5b:6d:4f:94:47
[heat-admin@overcloud-novacompute-0 ~]$Это vxlan тоннель на compute-1:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl dpif/show | egrep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$Идем на compute-1 и смотрим, что дальше происходит с пакетом:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:44:98:20
2 1 fa:16:3e:44:98:20 1
[heat-admin@overcloud-novacompute-1 ~]$ Мак есть в таблице форвардинга br-int на compute-1, и как видно из вывода выше виден он через порт 2, который является портов в сторону br-tun:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46Ну и далее смотрим, что в br-int на compute-1 есть мак назначения:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:72:ad:53
3 1 fa:16:3e:72:ad:53 0
[heat-admin@overcloud-novacompute-1 ~]$ То есть полученный пакет улетит в порт 3, за которым уже находится виртуальная машина instance-00000003.
Вся прелесть развертывания Openstack для изучения на виртуальной инфраструктуре в том, что мы можем без проблем отловить трафик между гипервизорами и посмотреть, что происходит с ним. Это мы сейчас и сделаем, запустим tcpdump на vnet порту в сторону compute-0:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet3
tcpdump: listening on vnet3, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:39:04.583459 IP (tos 0x0, ttl 64, id 16868, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.39096 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 8012, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.1.88: ICMP echo request, id 5634, seq 16, length 64
04:39:04.584449 IP (tos 0x0, ttl 64, id 35181, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.speedtrace-disc > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 59124, offset 0, flags [none], proto ICMP (1), length 84)
10.0.1.88 > 10.0.1.85: ICMP echo reply, id 5634, seq 16, length 64
*****************omitted*******************Первая строка показывает, что патек с адрес 10.0.1.85 идет на адрес 10.0.1.88 (ICMP трафик), причем он завернут в VxLAN пакет с vni 22 и пакет идет с хоста 192.168.255.19 (compute-0) на хост 192.168.255.26 (compute-1). Можем проверить, что VNI соответствует тому, который указан в ovs.
Вернемся к этой строке actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:2. 0х16 — это vni в 16-ричной системе счисления. Переведем это число в 10-ю систему:
16 = 6*16^0+1*16^1 = 6+16 = 22То есть vni соответствует действительности.
Вторая строка показывает обратный трафик, ну его пояснять нет смысла там и так все ясно.
Две машины в разных сетях (маршрутизация между сетями)
Последний кейс на сегодня — это маршрутизация между сетями внутри одного проекта с использованием виртуального маршрутизатора. Мы рассматриваем случай без DVR (его рассмотрим в другой статье), поэтому маршрутизация происходит на network ноде. В нашем случае network нода не вынесена в отдельную сущность и расположена на control ноде.
Для начала посмотрим, что маршрутизация работает:
$ ping 10.0.2.8
PING 10.0.2.8 (10.0.2.8): 56 data bytes
64 bytes from 10.0.2.8: seq=0 ttl=63 time=7.727 ms
64 bytes from 10.0.2.8: seq=1 ttl=63 time=3.832 ms
^C
--- 10.0.2.8 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 3.832/5.779/7.727 msТак как в даннам случае пакет должен уйти на шлюз и там смашрутизирован, нам надо узнать мак адрес шлюза, для чего посмотрим ARP таблицу в инстансе:
$ arp
host-10-0-1-254.openstacklocal (10.0.1.254) at fa:16:3e:c4:64:70 [ether] on eth0
host-10-0-1-1.openstacklocal (10.0.1.1) at fa:16:3e:e6:2c:5c [ether] on eth0
host-10-0-1-90.openstacklocal (10.0.1.90) at fa:16:3e:83:ad:a4 [ether] on eth0
host-10-0-1-88.openstacklocal (10.0.1.88) at fa:16:3e:72:ad:53 [ether] on eth0Теперь посмотрим, куда должен быть отправлен трафик с назначением (10.0.1.254) fa:16:3e:c4:64:70:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:c4:64:70
2 1 fa:16:3e:c4:64:70 0
[heat-admin@overcloud-novacompute-0 ~]$ Смотрим куда ведет порт 2:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$ Все логично, трафик уходит в br-tun. Посмотрим, в какой vxlan тоннель он будет завернут:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:c4:64:70
cookie=0x8759a56536b67a8e, duration=3514.566s, table=20, n_packets=3368, n_bytes=317072, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:c4:64:70 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3
[heat-admin@overcloud-novacompute-0 ~]$ Третий порт — это vxlan тоннель:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$ Который смотрит на control ноду:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ Трафик долетел до control ноды, поэтому нам надо перейти на нее и посмотреть, как будет происходить маршрутизация.
Как вы помните, контрольная нода внутри выглядела точно также как и compute нода — те же три бриджа, только у br-ex был физический порт, через который нода могла слать трафик наружу. Создание инстансов изменило конфигурацию на compute нодах — добавились linux bridge, iptables и интерфейсы в ноды. Создание сетей и виртуального маршрутизатора также оставило свой отпечаток на конфигурации control ноды.
Итак, очевидно, что мак адрес gateway должен быть в таблице форвардинга br-int на control ноде. Проверим, что он там есть и куда он смотрит:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:c4:64:70
5 1 fa:16:3e:c4:64:70 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Мак виден из порта qr-0c52b15f-8f. Если вернуться обратно к списку виртуальных портов в Openstack, то этот тип порта используется для подключения к OVS различных виртуальных устройств. Если быть точнее qr — это порт в сторону виртуального маршрутизатора, который представлена в виде namespace.
Посмотрима, какие namespace есть на сервере:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Целых три экземпляра. Но судя по именам можно догадаться о назначении каждого их них. К инстансам с ID 0 и 1 мы вернемся позже, сейчас нам интересен namespace qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ip route
10.0.1.0/24 dev qr-0c52b15f-8f proto kernel scope link src 10.0.1.254
10.0.2.0/24 dev qr-92fa49b5-54 proto kernel scope link src 10.0.2.254
[heat-admin@overcloud-controller-0 ~]$ В данном namespace две внутренние, которые были нами созданы ранее. Оба виртуальных порта добавлены в br-int. Проверим мас адрес порта qr-0c52b15f-8f, так как трафик, судя по мак адресу назначения шел именно в этот интерфейс.
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ifconfig qr-0c52b15f-8f
qr-0c52b15f-8f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.254 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fec4:6470 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:c4:64:70 txqueuelen 1000 (Ethernet)
RX packets 5356 bytes 427305 (417.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5195 bytes 490603 (479.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$ То есть в данном случае все работает по законам стандартной маршрутизации. Так как трафик предназначен хосту 10.0.2.8, то он должен выйти через второй интерфейс qr-92fa49b5-54 и уйти через vxlan тоннель на compute ноду:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe arp
Address HWtype HWaddress Flags Mask Iface
10.0.1.88 ether fa:16:3e:72:ad:53 C qr-0c52b15f-8f
10.0.1.90 ether fa:16:3e:83:ad:a4 C qr-0c52b15f-8f
10.0.2.8 ether fa:16:3e:6c:ad:9c C qr-92fa49b5-54
10.0.2.42 ether fa:16:3e:f5:0b:29 C qr-92fa49b5-54
10.0.1.85 ether fa:16:3e:44:98:20 C qr-0c52b15f-8f
[heat-admin@overcloud-controller-0 ~]$ Все логично, никаких сюрпризов. Смотрим откуда виден мак адрес хоста 10.0.2.8 в br-int:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
2 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ Как положено, трафик идет в br-tun, посмотрим, в какой тоннель трафик пойдет дальше:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:6c:ad:9c
cookie=0x2ab04bf27114410e, duration=5346.829s, table=20, n_packets=5248, n_bytes=498512, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0002/0x0fff,dl_dst=fa:16:3e:6c:ad:9c actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ Трафик уходит в тоннель до compute-1. Ну и на compute-1 все просто — из br-tun пакет попадает в br-int и оттуда в интерфейс виртуальной машины:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
4 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46
[heat-admin@overcloud-novacompute-1 ~]$ Проверим, что это действительно верный интерфейс:
[heat-admin@overcloud-novacompute-1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02429c001e1c no
qbr3210e8ec-c0 8000.ea27f45358be no qvb3210e8ec-c0
tap3210e8ec-c0
qbre7e23f1b-07 8000.b26ac0eded8a no qvbe7e23f1b-07
tape7e23f1b-07
[heat-admin@overcloud-novacompute-1 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000004
Interface Type Source Model MAC
-------------------------------------------------------
tap3210e8ec-c0 bridge qbr3210e8ec-c0 virtio fa:16:3e:6c:ad:9c
[heat-admin@overcloud-novacompute-1 ~]$Собственно мы прошли весь путь пакета. Думаю вы заметили, что трафик шел через разные vxlan тоннели и выходил с разными VNI. Давайте посмотрим, какие это VNI, после чего соберем дамп на порту control ноды и удостоверимся, что трафик ходит именно так, как описано выше.
Итак, тоннель до compute-0 имеет следующий actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3. Переведем 0x16 в десятичную систему счисления:
0x16 = 6*16^0+1*16^1 = 6+16 = 22Тоннель до compute-1 имеет следующий VNI:actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2. Переведем 0x63 в десятичную систему счисления:
0x63 = 3*16^0+6*16^1 = 3+96 = 99Ну и теперь посмотрим дамп:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet4
tcpdump: listening on vnet4, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:35:18.709949 IP (tos 0x0, ttl 64, id 48650, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.41591 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.710159 IP (tos 0x0, ttl 64, id 23360, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 63, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.711292 IP (tos 0x0, ttl 64, id 43596, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.42588 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 64, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
04:35:18.711531 IP (tos 0x0, ttl 64, id 8555, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 63, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
*****************omitted*******************Первый пакет — это vxlan пакет с хоста 192.168.255.19 (compute-0) на хост 192.168.255.15 (control-1) с vni 22, внутри которого упакован ICMP пакет с хоста 10.0.1.85 на хост 10.0.2.8. Как мы посчитали выше, vni соответствует тому, что мы видели в выводах.
Второй пакет — это vxlan пакет с хоста 192.168.255.15 (control-1) на хост 192.168.255.26 (compute-1) с vni 99, внутри которого упакован ICMP пакет с хоста 10.0.1.85 на хост 10.0.2.8. Как мы посчитали выше, vni соответствует тому, что мы видели в выводах.
Два следующих пакета — это обратный трафик с 10.0.2.8 не 10.0.1.85.
То есть в итоге у нас получилась такая схема control ноды:

Вроде все? Мы забыли про два namespace:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ Как мы говорили про архитектура облачной платформы — было бы хорошо, чтобы машины получали адреса автоматом от DHCP сервера. Это и есть два DHCP сервера на наши две сети 10.0.1.0/24 и 10.0.2.0/24.
Проверим, что это так. В данном namespace только один адрес — 10.0.1.1 — адрес самого DHCP сервера, и он так же включен в br-int:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1 bytes 28 (28.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1 bytes 28 (28.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tapca25a97e-64: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.1 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fee6:2c5c prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:e6:2c:5c txqueuelen 1000 (Ethernet)
RX packets 129 bytes 9372 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 6154 (6.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Посмотрим, если процессы содержащие в своем названии qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 на control ноде:
[heat-admin@overcloud-controller-0 ~]$ ps -aux | egrep qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
root 640420 0.0 0.0 4220 348 ? Ss 11:31 0:00 dumb-init --single-child -- ip netns exec qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 /usr/sbin/dnsmasq -k --no-hosts --no-resolv --pid-file=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/pid --dhcp-hostsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/host --addn-hosts=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/addn_hosts --dhcp-optsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/opts --dhcp-leasefile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases --dhcp-match=set:ipxe,175 --local-service --bind-dynamic --dhcp-range=set:subnet-335552dd-b35b-456b-9df0-5aac36a3ca13,10.0.2.0,static,255.255.255.0,86400s --dhcp-option-force=option:mtu,1450 --dhcp-lease-max=256 --conf-file= --domain=openstacklocal
heat-ad+ 951620 0.0 0.0 112944 980 pts/0 S+ 18:50 0:00 grep -E --color=auto qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
[heat-admin@overcloud-controller-0 ~]$ Есть такой процесс и исходя из информации, представленной в выводе выше мы можем например посмотреть, что у нас в аренде в настоящий момент:
[heat-admin@overcloud-controller-0 ~]$ cat /var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases
1597492111 fa:16:3e:6c:ad:9c 10.0.2.8 host-10-0-2-8 01:fa:16:3e:6c:ad:9c
1597491115 fa:16:3e:76:c2:11 10.0.2.1 host-10-0-2-1 *
[heat-admin@overcloud-controller-0 ~]$В итоге мы получаем вот такой набор сервисов на control ноде:

Ну и имейте ввиду — это всего лишь — 4 машины, 2 внутренние сети и один виртуальный маршрутизатор… У нас тут нет сейчас внешних сетей, кучи разных проектов, каждый со своими сетями (пересекающимися), и у нас выключен распределенный маршрутизатор, да в конце концов в тестовом стенде была всего одна control нода (для отказоустойчивости должен быть кворум из трех нод). Логично, что в коммерции все “немного” сложнее, но на данном простом примере мы понимаем, как это должно работать — будет у вас 3 или 300 namespace конечно важно, но с точки зрения работы всей конструкции — особо ничего не поменяется… правда пока вы не воткнете какой нибудь вендорский SDN. Но это уже совсем другая история.
Надеюсь было интересно. Если есть замечания/дополнения ну или где то я откровенно соврал (я человек и мое мнение всегда будет субъективно) — пишите что надо поправить/добавить — все поправим/добавим.
В заключении хотелось бы сказать пару слов о сравнении Openstack (как ванильного, так и вендорских) с облачным решением от компании VMWare — слишком часть мне задавали этот вопрос последние пару лет и я уже чесно говоря от него устал, но все же. На мой взгляд эти два решения сравнить очень сложно, но можно однозначно сказать что минусы есть в обоих решениях и выбирая какое то одно решение надо взвесить все за и против.
Если OpenStack являетя community-driven решением, то VMWare вправе делать только то, что она хочет (читайте — то что ей выгодно) и это логично — ибо это коммерческая компания, которая привыкла зарабатывать деньги на своих клиентах. Но тут есть одно большое и жирное НО — вы можете слезть с OpenStack например от Nokia и малой кровью перейти на решение от например Juniper (Contrail Cloud), но слезть с VMWare у вас врядли получится. Для меня эти два решения выглядят так — Openstack (вендорский) это простая клетка, в которую вас сажают, но у вас есть ключ и вы можете выйти в любой момент. VMWare — это золотая клетка, ключ от клетки у хозяина и обойдется он вам очень дорого.
Я не агитирую ни за первый продукт ни за второй — вы выбираете то, что вам надо. Но если бы мне предстоял такой выбор то я бы выбрал оба решения — VMWare для IT облака (малые нагрузки, удобное управление), OpenStack от какого нибудь вендора (Nokia и Juniper предоставляют очень неплихие решения под ключ) — для Телеком облака. Я бы не стал использовать Openstack для чистого IT — это как стрелять из пушки по воробьям, но противопоказаний использовать его, кроме как избыточность — я не вижу. Однако использовать VMWare в телекоме — как возить щебень на Ford Raptor- красиво со стороны, но водителю приходится делать 10 рейсов вместо одного.
На мой взгляд самым большим недостатком VMWare является ее полная закрытость — компания вам не выдаст никакой информации о том, как у нее устроен например vSAN или что там в ядре гипервизора — ей это просто не выгодно — то есть вы никогда не станете экспертом в VMWare — без поддержки вендора вы обречены (очень часть встречаю экспертов по VMWare которых ставят в тупик банальные вопросы). Для меня VMWare — это покупка машины с закрытым на замок капотом — да, возможно у вас есть специалисты, которые могут поменять ремень ГРМ, но открыть капот сможет только тот, кто продал вам это решение. Лично я не люблю решения, в которые не могу влезть. Вы скажете, что вам возможно не придется лезть под капот. Да такое возможно, но я посмотрю на вас когда вам надо будет собрать в облаке большую функцию из 20-30 виртуальных машин, 40-50 сетей, половина из которых хочет выйти наружу, а вторая половина просит SR-IOV ускорения иначе вам надо будет еще пару десяток таких машин — иначе перфоманса не хватит.
Существуют и другие точки зрения, поэтому только вам решать что выбирать и самое главное — вам же за ваш выбор потом отвечать. Это всего лишь мое мнение — человека который видел и трогал руками как минимум 4 продукта — Nokia, Juniper, Red Hat и VMWare. То есть мне есть с чем сравнить.






eucariot
Начал было читать с мыслью «О, интересненькое на ночь», но решил посмотреть объём и сохранил вкладку :)