

Всем привет. Меня зовут Стас, в компании Домклик я курирую разработку сервисов бек-офиса для ипотечного кредитования Сбербанка.
В последнее время во всевозможных докладах и подкастах я довольно часто стал встречать термин «Green Code». Покопавшись в интернете и изучив эту тему, я понял, что этим термином описывают комплекс приёмов в разработке и проектировании приложений, позволяющих сократить энергопотребление оборудования, на котором этот код выполняется.
Более-менее этим вопросом обычно озадачиваются разработчики мобильных приложений, в основном потому, что устройство, на котором будет выполняться их код, имеет ограниченную емкость батареи.
Тема стала достаточно «хайповой», и я решил прикинуть, как именно принципы «зеленого» могут быть отражены в WEB-разработке.
Основные принципы написания «зеленого кода»
Прочитав достаточно много докладов и статей на эту тему, я бы выделил следующие аспекты разработки приложений, которые влияют на энергопотребление:
1) Упрощение и оптимизация алгоритмов
Как уже было сказано выше, выполнение кода должно приводить к минимальному потреблению энергии. Оптимизированный код будет выполняться быстрее и, соответственно, потребует меньше затрат на его обработку и охлаждение оборудования.
Давайте попробуем посчитать разницу в энергозатратах на исполнение конкретной операции в коде — классической сортировке списка. Я специально буду утрировать ситуацию в приведенном примере, чтобы контрастнее показать разницу.
Возьмём сортировку методом пузырька. Наверное, это один из самых неоптимальных способов. Очень нам подходит. Рассчитаем сортировку списка и посмотрим, как она отразилась на энергозатратах MacBook. Для начала смоделируем массив данных и саму логику сортировки пузырьком:
from random import randint
??def bubble(array):?
for i in range(productNumber-1):?
for j in range(productNumber-i-1):
? if array[j] > array[j+1]:
? buff = array[j]
? array[j] = array[j+1]
? array[j+1] = buff??
productNumber = 60000
?products = []?
for i in range(productNumber):
? products.append(randint(1, 1000))??
bubble(products)?
print(products)
Для замера влияния исполнения кода на энергозатраты я использовал систему мониторинга iStat Menus 6 (https://bjango.com/mac/istatmenus/). Подключил MacBook к сети, закрыл все сторонние приложения, выждал определенное время для зарядки батареи, и запустил сортировку:
График энергопотребления при выполнении сортировки пузырьком:
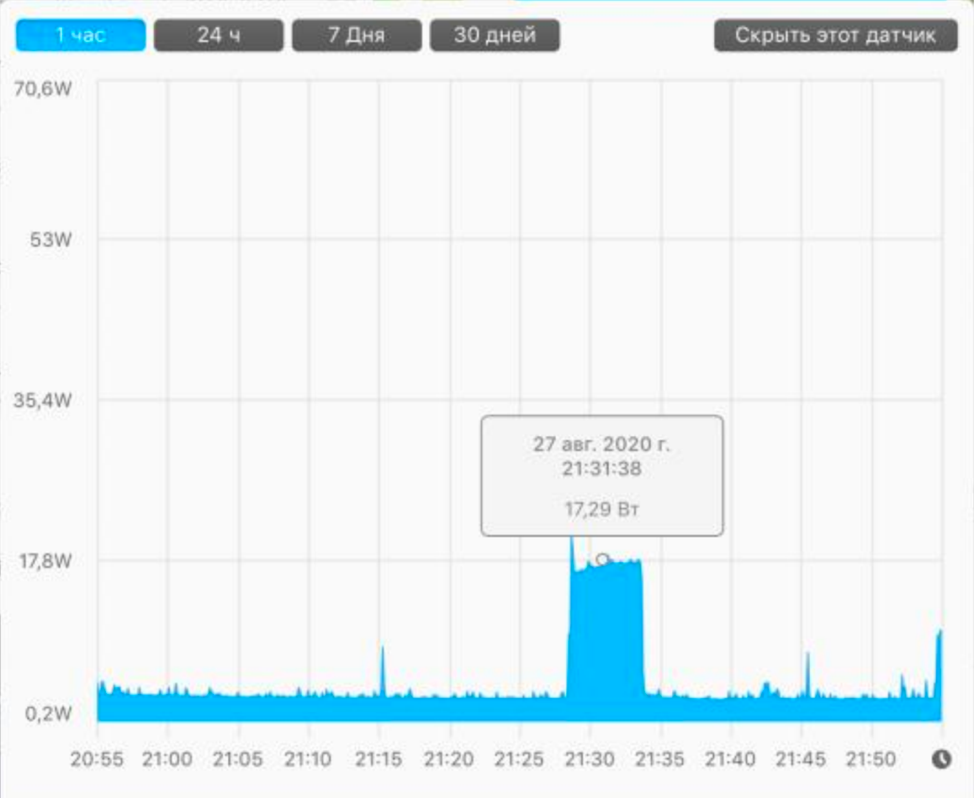
Виден ярко выраженный скачок потребления мощности длительностью в 305 секунд. Он вызван исполнением нашего неоптимального запроса. Дополнительно потраченная энергия за 5 минут (305 секунд):
P = (W2 – W1) ? 305 = (17,29 [мощность при выполнении скрипта] – 2,9 [мощность в состоянии покоя]) ? 305 = 14,39 ? 305 = 4389 Дж = 0,0012 кВт*ч .Теперь допустим, что этот код случайно попал на промышленный продуктовый сервер (примем как допущение, что дополнительные энергозатраты на сервере будут такими же, как на моем MacBook, и зависимость прямо пропорциональная) и стал выполняться с частотой 1 раз в 10 секунд. Тогда в год мы получим дополнительные энергозатраты:
365 дней ? 24 часа ? 3600 с/10 ? 0,0012 кВт*ч = 3 784,32 кВт*ч.Предположим, что ЦОД, в котором размещается сервер, получает энергоснабжение от котельной, в качестве топлива в которой используется березовая древесина. При сгорании 1 м3 березовой древесины выделяется 1900 кВт*ч/м3 энергии. Разумеется, КПД котельной не 100 %, и если принять его за 75 %, то получим:
(3 784,32 / 1900) / 0,75 = 2,66 м3.Если принять дерево за правильный цилиндр, объем которого равен
V = Pi ? R2 ? Hгде R — радиус ствола дерева, примем его за 0,12 метра (среднее значение),
H — высота ствола дерева, примем ее за 3 метра (среднее значение).
то получаем:
V = 3,14 ? 0,0144 ? 3 = 0,14 м3Значит, в одном кубометре древесины будет
1 / 0,14 = 7,14 бревна.Для обеспечения энергией работы нашего скрипта нам понадобится в год
2,66 м3 ? 7,14 = 19 берез.Для сравнения я выполнил ту же сортировку с использованием стандартного способа сортировки в Python (
.sort()).График энергопотребления при выполнении стандартной сортировки в Python:
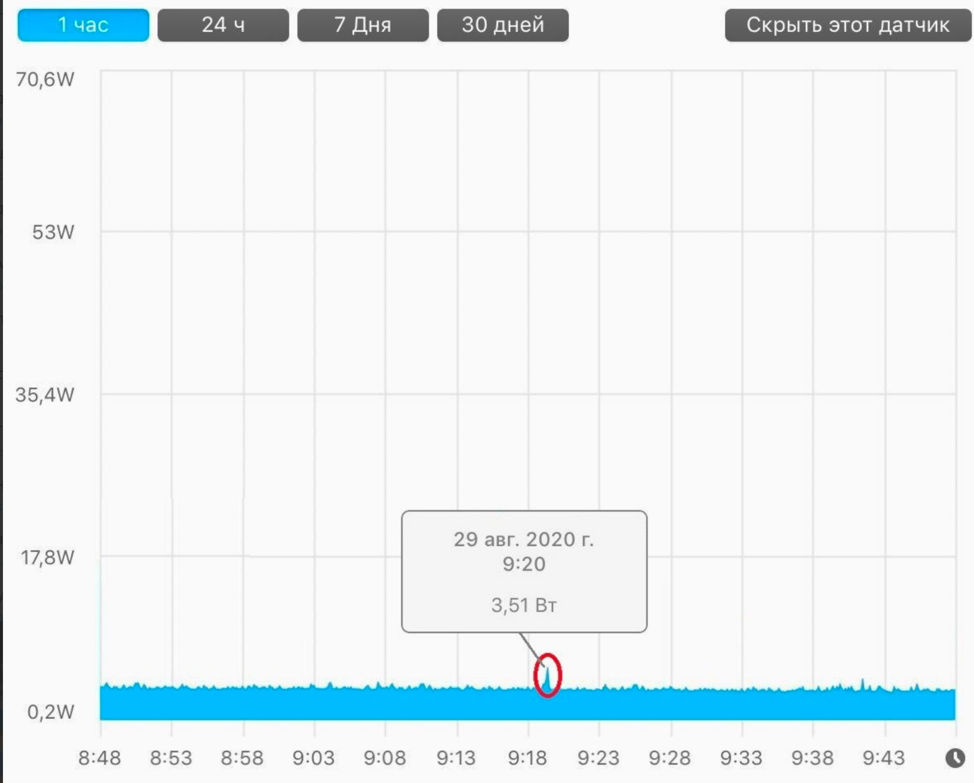
Применяя ту же логику расчета (длительность пика была 10 сек), получаем:
P = (W2 – W1) ? 10 сек = (3,51 [мощность при выполнении скрипта] – 2,9 [мощность в состоянии покоя]) ? 10 сек = 6,1 Дж = 0,0000016 кВт*чВ год получим (при условии выполнения операции 1 раз в 10 секунд)
365 дней ? 24 часа ? 3600 с/10 ? 0,0000016 кВт*ч = 5,05 кВт*чИли же:
5,05 / 1900 / 0,75 ? 7,14 = 0,025 бревна березы. Конечно, в этом примере много допущений, да и сортировку пузырьком делают достаточно редко. Но полученные числа показались мне интересными
2) Использовать событийную модель (event driven model) работы приложения там, где только можно
.Дело в том, что большинство процессоров поддерживают несколько «состояний» энергопотребления. В том случае, если ядро не занято какими-то вычислениями, операционная система переводит его в состояние «сна», при котором процессор потребляет гораздо меньше энергии.
Спектр состояний (оптимизация по энергопотреблению):
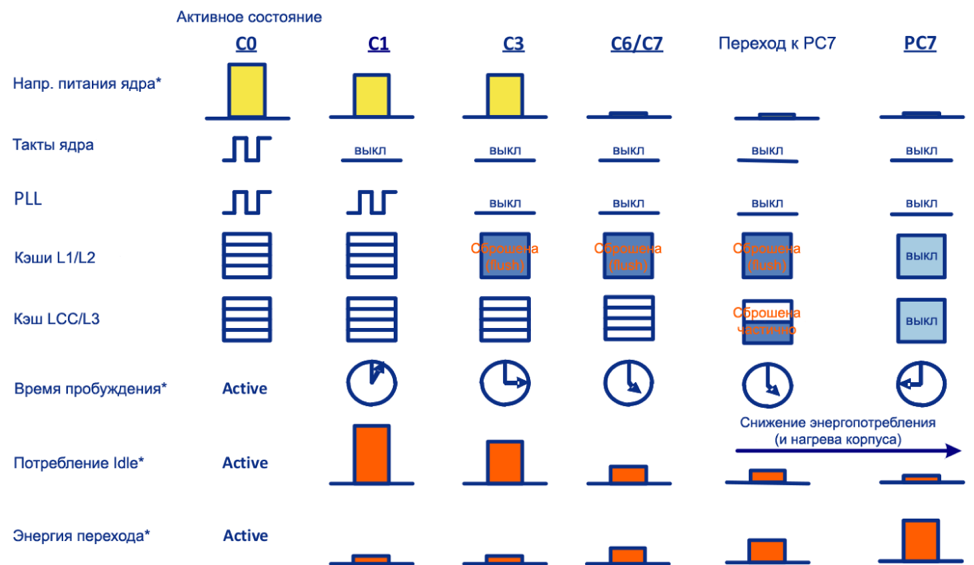
Подробнее об этом можно прочитать тут.
Довольно часто бывает ситуация, когда какая-то логика приложения должна выполниться при возникновении определенного события. И чтобы узнать, что это событие произошло, заинтересованный в получении этой информации сервис зачастую периодически опрашивает сервис, хранящий факт выполнения этого события. По таймеру. Причем подавляющая часть запросов получает отрицательный ответ, то есть 99 % запросов, по сути, не нужны.
Правильно было бы транслировать соответствующее событие в очередь, и считывать факт его возникновения всем заинтересованным сервисам.?
Спектр состояний (оптимизация по энергопотреблению):

Другой пример — взаимодействие фронтенд- и бекенд-компонентов приложения. Если фронту надо поменять свое состояние в зависимости от данных в базе, иногда на бекенд периодически шлют запросы, создавая ненужную дополнительную нагрузку. Хотя можно проинформировать фронт об изменении состояния необходимых данных через сокет–сервер.
Хотя с сокетами тоже можно ошибиться, вот пример «плохого» кода:
while(true)
{
// Read data
result = recv(serverSocket, buffer, bufferLen, 0);
// Handle data
if(result != 0)
{
HandleData(buffer);
}
// Sleep and repeat
Sleep(1000);
}
Видно, что даже если данные в сокет не поступили, всё равно каждые 1000 секунд код будет выполняться, тратя драгоценную энергию.
То же самое можно написать чуть по-другому, и энергии будет тратиться меньше:
WSANETWORKEVENTS NetworkEvents;
WSAEVENT wsaSocketEvent;
wsaSocketEvent = WSACreateEvent();
WSAEventSelect(serverSocket,
wsaSocketEvent, FD_READ|FD_CLOSE);
while(true)
{
// Wait until data will be available in
the socket
WaitForSingleObject(wsaSocketEve
nt, INFINITE);
// Read data
result = recv(serverSocket, buffer,
bufferLen, 0);
// Handle data
if(result != 0)
{
HandleData(buffer);
}
}
3) UI/UX: Интерфейс пользователя не должен показывать «лишние» данные
Если данные всё же используются, но редко, то лучше их не отображать по умолчанию, а показывать только по кнопке «Показать детальную информацию».
Простой пример, иллюстрирующий этот принцип: отображение списков объектов данных (заявок, пользователей, торговых точек, складов, офисов) при условии, что сценарий использования формы всё равно предполагает поиск нужного объекта.
Пример плохого интерфейса:
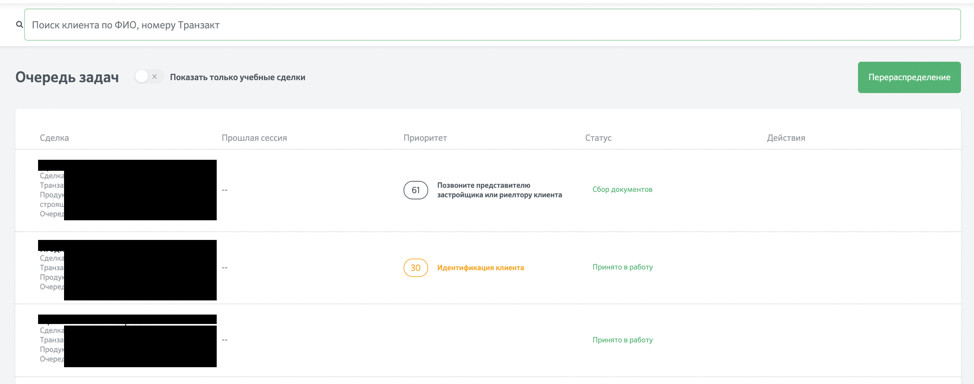
На странице отображается огромный список задач (разбитый на «страницы»), однако пользователь всё равно будет искать определенного клиента (по определенной логике у него в голове) в поисковой строке сверху. Зачем тратить ресурсы на получение списка задач?
Тот же самый сценарий, реализованный по-другому:
Пример «зеленого» интерфейса:
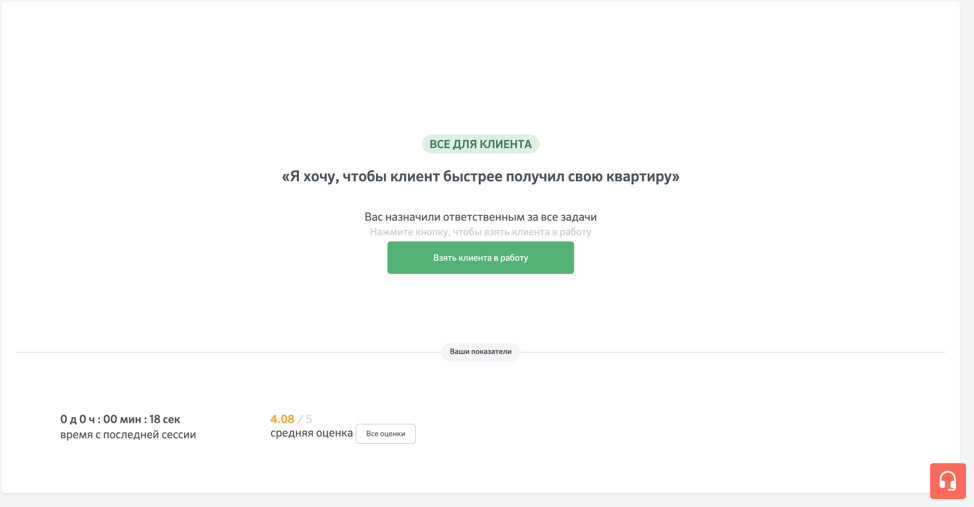
Логика выбора клиента перенесена в систему, по умолчанию не запрашивается лишних данных «по привычке». Этому варианту, помимо экологов, и кибербезопасность будет люто аплодировать.
4) Рефакторинг
Рефакторинг полезен почти всегда. Но в этом контексте он нужен для одной простой цели: выкинуть ненужный (мусорный) код или упростить существующий, чтобы снизить энергопотребление.
Многие приложения, развивающиеся более трёх лет, накапливают в себе сотни строк неиспользуемого или непрогнозируемо работающего кода, оставшегося от ранее реализованных (и уже, возможно, выпиленных) функций. Иногда этот код даже исполняется, но результат его работы не востребован.
Периодический аудит и рефакторинг снизят количество такого кода, хотя, вероятно, избавиться от него до конца не получится.
К примеру, регулярно рефакторя один из наших сервисов (в рамках технической квоты рабочего времени), мы обнаружили вот такое:
Пример рефакторинга:
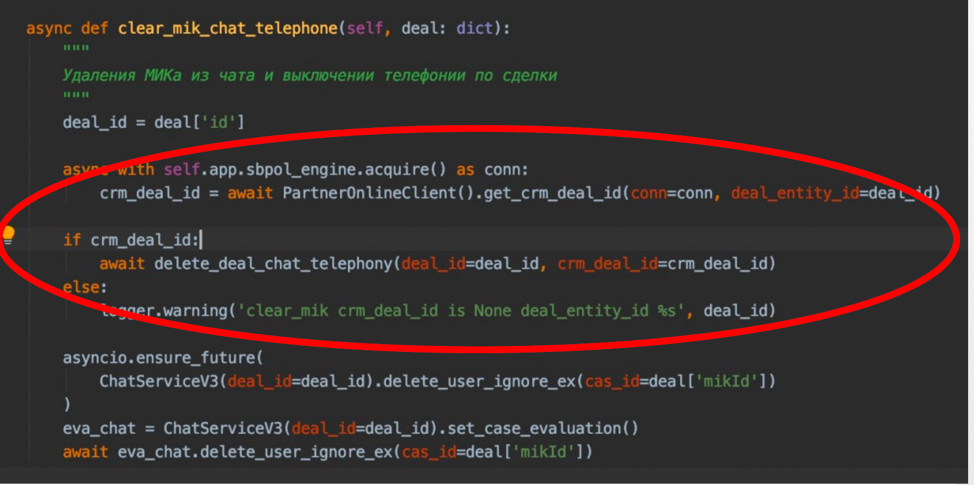
crm_deal_id — идентификатор ипотечной сделки в старой системе. Сейчас он уже не нужен, но в коде осталась проверка на его получение и вызов дополнительной функции delete_deal_chat_telephony, которая выполняет еще кучу действий.Всё это можно убрать без потери функциональности.
5) Использовать низкоуровневые языки программирования для высоконагруженных приложений
Очевидно, что в большинстве случаев приложения, написанные на низкоуровневых языках, более энергоэффективны. Нагруженный сервис на Python (если он выполняет простую операцию) имеет смысл переписать на C/C+. Будет быстрее и «зеленее».
Правда, часто у нас нет нужных знаний для написания логики на таких языках.
6) Группировать I/O-операции
Системы хранения, как и процессоры, также имеют различные состояния энергопотребления.
В режиме «сна» потребляется гораздо меньше энергии, чем в рабочем «прогретом» состоянии. Особенно это характерно для систем хранения/жестких дисков.
Если в работе приложения можно группировать данные, записываемые на диск, и обращаться к диску не постоянно, а в определенные периоды времени, то это будет энергоэффективнее, поскольку в период «простоя» операционная система отправит диск в «спячку».
7) Использование менее энергоемких систем хранения для логов
Хорошей практикой будет использовать «горячее» и «холодное» хранение. Например, логи за последнюю неделю имеет смысл хранить в индексированном виде «горячего» приготовления, поскольку вероятность обращения к ним будет достаточно высока. Логи за более длительный период можно хранить в более дешевых и менее энергозатратных системах хранения.
А как в промышленном масштабе?
Выше мы рассмотрели основные приемы работы с кодом для обеспечения его энергоэффективности. Но даже соблюдение большинства этих правил даст весьма скромную экономию, которую сложно будет визуализировать. Конечно, если в проде не сортировать списки методом пузырька
Гораздо больший эффект даст целенаправленная разработка функциональности по внедрению электронного документооборота.
Одним из направлений деятельности команд Домклик является оптимизация и упрощение процесса получения ипотеки. И в этом ипотечном процессе на финальной стадии готовится достаточно много документов на бумаге. Причем в нескольких экземплярах. Один экземпляр для продавца, один для покупателя, один для архива банка.
Мне приятно осознавать, что Домклик тратит много усилий для изничтожения этой порочной практики и перевода всего документооборота в электронный формат. В этом году значительная часть ипотечных сделок была уже полностью оцифрована (печаталась только одна бумага: заявление на выпуск УКЭП, усиленной криптографической электронной подписи). Все остальные документы подписывались уже этим УКЭП и бумага на них не тратилось.
Благодаря этой инициативе было сэкономлено уже более 67 491 108 листов бумаги. В березках это примерно 23 000 деревьев!
Берегите природу!
Ссылки для интересующихся:
- Green IT — available data and guidelines for reducing energy consumption in IT Systems / Ardito L.; Morisio M… — In: SUSTAINABLE COMPUTING. — ISSN 2210-5379. — STAMPA
- Understanding Green Software Development: A conceptual Framework /Luca Ardito, Giuseppe Procaccianti, Marco Torchiano, Antonio Vetro
- Green SW Engineering:Ideas for including Energy Efficiency into your Softwar Projects/Gerald Kaefer




k41n
После этой статьи в кафе где собираются стартаперы началась драка.

Твоё лицо когда узнал что фронтендеры запускают webpack --watch чуть более чем всегда