

Я много пишу об исследованиях хитрых багов — об ошибках в процессорах, багах ядра, промежуточном распределении 4-гигабайтной памяти, однако большинство ошибок не столь экзотично. Иногда для нахождения бага достаточно всего лишь взглянуть на дэшборд сервера, потратить несколько минут в профайлере или прочитать предупреждения компилятора.
В этой статье я расскажу о трёх серьёзных багах, которые я нашёл и исправил; все они совершенно не скрывались и просто ждали, когда их кто-нибудь заметит.
Сюрприз в процессоре сервера

Несколько лет назад я провёл несколько недель, изучая поведение памяти на запущенных в эксплуатацию игровых серверах. Cерверы работали под Linux в удалённых дата-центрах, поэтому большая часть времени была потрачена на получение нужных разрешений, чтобы я смог создать туннель к серверам, а также на изучение эффективной работы с perf и других диагностических инструментов Linux. Я обнаружил серию багов, из-за которых потребление памяти было в три раза больше необходимого, и устранил их:
- Я обнаружил несовпадения map ID, из-за чего для каждой игры использовалась не одна и та же копия примерно 20 МБ данных, а загружалась новая.
- Я нашёл неиспользуемую (!) глобальную переменную на 50 МБ (!!), для которой была задана нулевая memset (!!!), из-за чего она потребляла физическую ОЗУ в каждом процессе.
- Различные менее серьёзные баги.
Но наша история будет не об этом.
Уделив время изучению того, как профилировать наши игровые серверы, я понял, что можно исследовать этот вопрос немного глубже. Поэтому я запустил perf на серверах одной из наших игр. Первый серверный процесс, который я профилировал, был… странным. Наблюдая за сэмплируемыми данными процессора «в прямом эфире», я увидел, что единственная функция потребляла 100% времени CPU. Однако в этой функции выполнялось всего четырнадцать инструкций. В этом не было никакого смысла.
Сначала я предположил, что неправильно пользуюсь perf или ошибочно интерпретирую данные. Я посмотрел на некоторые другие серверные процессы и обнаружил, что примерно половина из них находилась в странном состоянии. У второй половины профили CPU выглядели более нормальными.
Интересующая нас функция проходила по связанному списку узлов навигации. Я поспрашивал у коллег и нашёл программиста, который сказал, что проблемы с точностью чисел с плавающей запятой могут приводить к тому, что игра генерирует списки навигации с петлями. Они всегда хотели ограничить максимальное количество обходимых узлов, но так и не удосужились это сделать.
Итак, загадка решена? Нестабильность вычислений с плавающей запятой вызывает петли в списках навигации, из-за чего игра бесконечно их обходит — всё, поведение объяснено.
Но… такое объяснение обозначало бы, что когда такое происходит, серверный процесс входит в бесконечный цикл, всем игрокам придётся от него отключиться, а серверный процесс будет бесконечно поглощать всё ядро процессора. Если бы такое происходило, разве бы у нас со временем не закончились ресурсы на серверах? Разве этого бы кто-нибудь не заметил?
Я поискал данные мониторинга сервера и нашёл примерно такой график:
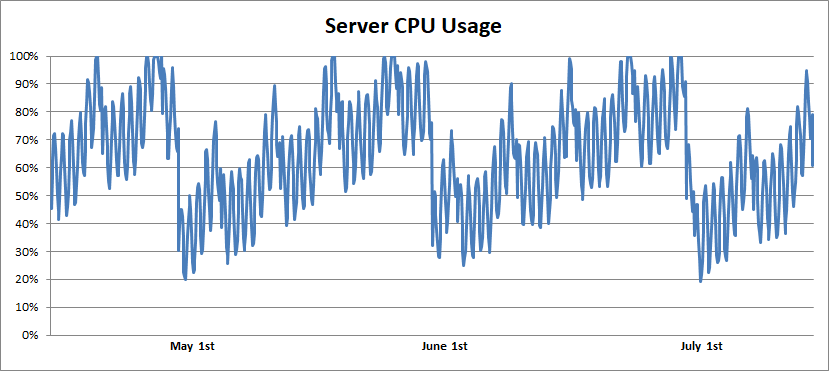
В течение всей длительности мониторинга (один-два года) я наблюдал ежедневные и еженедельные флуктуации нагрузок на сервер, на которые были наложен ежемесячный паттерн. Уровень загрузки процессора постепенно повышался, а затем падал до нуля. Ещё немного поспрашивав, я выяснил, что серверы раз в месяц перезагружали. И наконец во всём этом появилась логика:
- При каждом запуске игры существовала небольшая вероятность того, что серверный процесс застрянет в бесконечном цикле.
- Когда такое происходило, игроки отключались и серверный процесс оставался в этом цикле, пока машины не перезагружали в конце месяца.
- Дэшборд мониторинга CPU чётко демонстрировал, что этот баг в среднем снижал мощность примерно на 50%.
- Никто и никогда не смотрел на дэшборд мониторинга.
Баг устранили добавлением нескольких строк кода, которые останавливали обход списка спустя двадцать узлов навигации, предположительно сэкономив несколько миллионов долларов на затратах на сервер и питание. Я не обнаружил этот баг, изучая графики мониторинга, но любой, кто на них смотрел, мог бы это сделать.
Мне нравится то, что частота возникновения бага идеально совпала с максимизацией затрат на него; в то же время он никогда не доставлял достаточно серьёзных проблем, чтобы его могли найти. Это похоже на действие вируса, который эволюционирует, чтобы заставлять людей чихать, а не убивать их.
Медленная загрузка
Продуктивность разработчика ПО тесно связана со скоростью цикла «редактирование/компиляция/компоновка/отладка». Иными словами, зависит от того, сколько времени после внесения изменения в файл исходников потребуется для запуска нового двоичного файла с внесённым изменением. На протяжении долгих лет я проделал большую работу по снижению времени компиляции/компоновки, но важно ещё и время загрузки. Некоторые игры при каждом запуске выполняют огромный объём работы. Я нетерпелив и поэтому часто становлюсь первым, кто тратит несколько часов или дней на то, чтобы загрузка игры происходила на несколько секунд быстрее.
В этом случае я запустил свой любимый профилировщик и посмотрел на график использования CPU на этапе первоначальной загрузки игры. Наиболее многообещающим выглядел один этап: примерно десять секунд тратилось на инициализацию каких-то данных освещения. Я надеялся, что можно найти какой-нибудь способ ускорить эти вычисления, сэкономив на этапе запуска секунд пять. Прежде чем углубляться в изучение, я проконсультировался со специалистом по графике. Он сказал:
«Мы не используем эти данные освещения в игре. Просто удали этот вызов».
О. Отлично. Это было просто.
Потратив полчаса на профилирование и изменив одну строку, я смог вдвое уменьшить время загрузки основного меню, и для этого не понадобились никакие экстраординарные усилия.
Несвоевременный вылет
Из-за произвольного количества аргументов в форматировании
printf очень легко получить ошибку несоответствия типов. На практике результаты могут сильно варьироваться:- printf(“0x%08lx”, p); // Печать указателя как int – усечение или что похуже на 64 битах
- printf(“%d, %f”, f, i); // Смена мест float и int – может выводить бессмыслицу, а может и сработать (!)
- printf(“%s %d”, i, s); // Смена порядка string и int – скорее всего, приведёт к вылету
В стандарте говорится, что подобные несовпадения типов являются неопределённым поведением, а некоторые компиляторы генерируют код, который намеренно приводит к вылетанию при любом из этих несовпадений, однако выше перечислены наиболее вероятные результаты (примечание: вопрос, почему второй пункт часто выводит нужные результаты — это хорошая задачка на знание ABI).
Такие ошибки сделать очень просто, поэтому все современные компиляторы имеют возможность предупреждать разработчиков, что возникло несовпадение. В gcc и clang есть аннотации для функций в стиле printf и они могут предупреждать о несовпадениях (однако, к сожалению, аннотации не работают с функциями в стиле wprintf). VC++ имеет аннотации (к сожалению, другие), которые /analyze может использовать для предупреждения о несовпадениях, но если вы не используете /analyze, то он будет предупреждать только об определённых в CRT функциях в стиле printf/wprintf, но не о ваших пользовательских функциях.
Компания, в которой я работал, аннотировала свои функции в стиле printf, чтобы gcc/clang выдавал предупреждения, но позже решила игнорировать предупреждения. Это странное решение, ведь такие предупреждения являются совершенно точными индикаторами багов — соотношение «сигнал-шум» равно бесконечности.
Я решил начать подчищать эти баги с помощью аннотаций VC++ и /analyze, чтобы точно найти все баги. Я проработал большинство ошибок и создал одно большое изменение, ожидавшее проверки кода перед его отправкой.

В те выходные в дата-центре произошло отключение питания, и все наши серверы вырубились (вероятно, виноваты были ошибки в конфигурировании питания). Аварийный персонал помчался всё восстанавливать и исправлять, прежде чем будет потеряно слишком много денег.
Забавный аспект багов printf заключается в том, что ведут себя неправильно в 100% случаев запуска. То есть если они собираются выводить неверные данные или привести к вылету программы, то это происходит каждый раз. Поэтому они могут остаться в программе, только если находятся в коде логгинга, который никогда не читают, или в коде обработки ошибок, который редко выполняется.
Оказалось, что событие «одновременный перезапуск всех серверов» заставило код двинуться по путям, которые в обычных ситуациях не выполнялись. Запускающиеся серверы начинали искать другие серверы, не могли их найти, и выводили примерно такое сообщение:
fprintf(log, “Can’t find server %s. Error code %d.\n”, err, server_name);
Упс. Несовпадение типов произвольного количества аргументов. И вылет.
У аварийников появилась дополнительная проблема. Серверы нужно было перезагрузить, но этого нельзя было сделать, прежде чем не будут исследованы аварийные дампы, не обнаружен баг, не пересобраны двоичные файлы серверов и не введена в эксплуатацию новая сборка. Это был довольно быстрый процесс — кажется, не более нескольких часов, но его вполне можно было избежать.
Мне показалось, что эта история идеально демонстрирует, почему нам следует тратить время на устранение причин этих предупреждений — зачем игнорировать предупреждения, которые сообщают, что код точно завершится аварийно или будет плохо себя вести при выполнении? Однако никого не беспокоило то, что устранение подобного класса предупреждений могло бы сэкономить нам несколько часов даунтайма. На самом деле, культуру компании, похоже не интересовало ни одно из этих исправлений. Но именно этот последний баг заставил меня понять, что пора переходить в другую компанию.
Какие уроки можно из этого извлечь?
Если все, участвующие в проекте, упорно трудятся над функциями продукта и устранением хорошо известных багов, то, вероятно, существуют очень простые баги, находящиеся на всеобщем обозрении. Потратьте немного времени на изучение логов, подчистку предупреждений компилятора (хотя, на самом деле, если у вас есть предупреждения компилятора, то, вероятно, стоит переосмыслить решения, которые вы приняли в жизни), на несколько минут запустите профилировщик. Вы получите дополнительные баллы, если добавите собственную систему логирования, включите новые предупреждения или используете профилировщик, которым никто, кроме вас, не пользуется.
Если же вы вносите превосходные исправления, улучшающие использование памяти/процессора или повышающие стабильность, а никого это не волнует, то найдите компанию, которая это оценит.
Обсуждение на Hacker News — здесь, обсуждение на Reddit — здесь, обсуждение в Twitter — здесь.
На правах рекламы
Надёжный сервер в аренду и правильный выбор тарифного плана позволят меньше отвлекаться на неприятные уведомления мониторинга — всё будет работать без сбоев и с очень высоким uptime!
