

Многие считают, что достаточно перенести приложение на Kubernetes (либо с помощью Helm, либо вручную) — и будет счастье. Но не всё так просто.
Команда Mail.ru Cloud Solutions перевела статью DevOps-инженера Джулиана Гинди. Он рассказывает, с какими подводными камнями его компания столкнулась в процессе миграции, чтобы вы не наступали на те же грабли.
Шаг первый: настройка запросов пода и лимитов
Начнем с настройки чистого окружения, в котором будут работать наши поды. Kubernetes великолепно справляется с планированием подов и обработкой состояний отказа. Но оказалось, что планировщик иногда не может разместить под, если затрудняется оценить, сколько ресурсов ему нужно для успешной работы. Именно здесь всплывают запросы на ресурсы и лимиты. Ведется много споров о наилучшем подходе к настройке запросов и лимитов. Иногда кажется, что это действительно скорее искусство, чем наука. Вот наш подход.
Запросы пода (pod requests) — это основное значение, используемое планировщиком для оптимального размещения пода.
Из документации Kubernetes: на шаге фильтрации определяется набор узлов, где можно запланировать под. Например, фильтр PodFitsResources проверяет, достаточно ли на узле ресурсов для удовлетворения конкретных запросов пода на ресурсы.
Запросы приложений мы используем так, чтобы по ним можно было оценить, сколько ресурсов на самом деле нужно приложению для нормальной работы. Так планировщик сможет реалистично разместить узлы. Первоначально мы хотели установить запросы с запасом, чтобы гарантировать достаточно большое количество ресурсов для каждого пода, но заметили, что время планирования значительно увеличилось, а некоторые поды так и не были полностью запланированы, словно для них не поступило никаких запросов на ресурсы.
В этом случае планировщик часто «выдавливал» поды и не мог повторно их запланировать из-за того, что плоскость управления понятия не имела, сколько ресурсов потребуется приложению, а ведь это ключевой компонент алгоритма планирования.
Лимиты пода (pod limits) — это более четкое ограничение для пода. Оно представляет собой максимальный объем ресурсов, который кластер выделит контейнеру.
Опять же, из официальной документации: если для контейнера установлен лимит памяти 4 ГиБ, то kubelet (и среда выполнения контейнера) введет его принудительно. Среда выполнения не позволяет контейнеру использовать больше заданного лимита ресурсов. Например, когда процесс в контейнере пытается использовать больше допустимого объема памяти, ядро системы завершает этот процесс с ошибкой «out of memory» (OOM).
Контейнер всегда может использовать больше ресурсов, чем указано в запросе на ресурсы, но никогда не может использовать больше, чем указано в ограничении. Это значение сложно установить правильно, но оно очень важно.
В идеале мы хотим, чтобы требования к ресурсам пода изменялись в течение жизненного цикла процесса, не вмешиваясь в другие процессы в системе — это цель установления лимитов.
К сожалению, я не могу дать конкретные указания, какие значения устанавливать, но мы сами придерживаемся следующих правил:
- Используя инструмент нагрузочного тестирования, моделируем базовый уровень трафика и наблюдаем за использованием ресурсов пода (памяти и процессора).
- Устанавливаем запросы пода на произвольно низкое значение (с ограничением ресурсов примерно в 5 раз больше значения запросов) и наблюдаем. Когда запросы на слишком низком уровне, процесс не может начаться, что часто вызывает загадочные ошибки времени выполнения Go.
Хочу отметить, что более высокие ограничения ресурсов усложняют планирование, поскольку поду нужен целевой узел с достаточным количеством доступных ресурсов.
Представьте ситуацию, когда у вас легковесный веб-сервер с очень высоким ограничением ресурсов, например 4 ГБ памяти. Вероятно, этот процесс придется масштабировать горизонтально и каждый новый модуль придется планировать на узле с доступным объемом памяти не менее 4 ГБ. Если такого узла не существует, кластер должен ввести новый узел для обработки этого пода, что может занять некоторое время. Важно добиться минимальной разницы между запросами ресурсов и лимитами, чтобы обеспечить быстрое и плавное масштабирование.
Шаг второй: настройка тестов Liveness и Readiness
Это еще одна тонкая тема, которая часто обсуждается в сообществе Kubernetes. Важно хорошо разбираться в тестах жизнеспособности (Liveness) и готовности (Readiness), поскольку они обеспечивают механизм устойчивой работы программного обеспечения и минимизируют время простоя. Однако они могут нанести серьезный удар по производительности вашего приложения, если не настроены правильно. Ниже приводится краткое изложение, что из себя представляют обе пробы.
Liveness показывает, работает ли контейнер. Если она выходит из строя, kubelet убивает контейнер, и для него включается политика перезапуска. Если контейнер не оснащен Liveness-пробой, то состоянием по умолчанию будет успех — так говорится в документации Kubernetes.
Пробы Liveness должны быть дешевыми, то есть не потреблять много ресурсов, потому что они запускаются часто и должны информировать Kubernetes, что приложение запущено.
Если вы установите параметр для запуска каждую секунду, то это добавит 1 запрос в секунду, так что примите во внимание, что для обработки этого трафика понадобятся дополнительные ресурсы.
У нас в компании тесты Liveness проверяют основные компоненты приложения, даже если данные (например, из удаленной базы данных или кэша) не полностью доступны.
Мы настроили в приложениях конечную точку «работоспособности», которая просто возвращает код ответа 200. Это показатель того, что процесс запущен и способен обрабатывать запросы (но еще не трафик).
Проба Readiness указывает, готов ли контейнер к обслуживанию запросов. Если проба готовности выходит из строя, контроллер конечных точек удаляет IP-адрес пода из конечных точек всех служб, соответствующих поду. Это также говорится в документации Kubernetes.
Пробы Readiness потребляют больше ресурсов, так как они должны попадать в бэкенд таким образом, чтобы показать готовность приложения к приему запросов.
В сообществе ведется много споров, следует ли обращаться непосредственно к базе данных. Учитывая накладные расходы (проверки выполняются часто, но их можно регулировать), мы решили, что для некоторых приложений готовность обслуживать трафик засчитывается только после проверки того, что из базы данных возвращаются записи. Хорошо продуманные пробы готовности обеспечили более высокий уровень доступности и устранили простои во время развертывания.
Если вы решите делать запрос к базе данных для проверки готовности приложения, убедитесь, что он обходится как можно дешевле. Возьмем такой запрос:
SELECT small_item FROM table LIMIT 1Вот пример, как мы настраиваем эти два значения в Kubernetes:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Можно добавить некоторые дополнительные параметры конфигурации:
initialDelaySeconds— сколько секунд пройдет между запуском контейнера и началом запуска проб.periodSeconds— интервал ожидания между запусками проб.timeoutSeconds— количество секунд, по истечении которых под считается аварийным. Обычный тайм-аут.failureThreshold— количество отказов тестов, прежде чем в под будет отправлен сигнал перезапуска.successThreshold— количество успешных проб, прежде чем под переходит в состояние готовности (после сбоя, когда под запускается или восстанавливается).
Шаг третий: настройка дефолтных сетевых политик пода
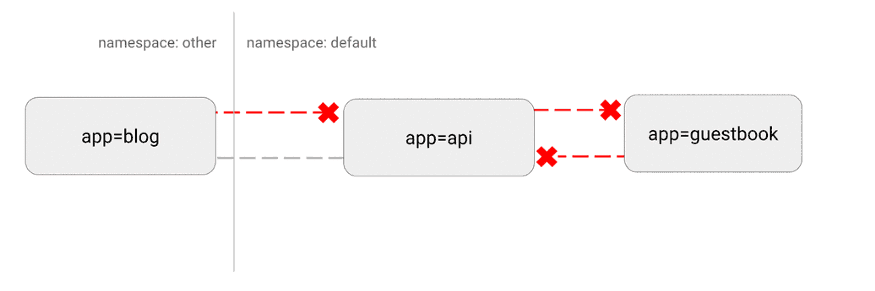
В Kubernetes «плоская» сетевая топография, по умолчанию все поды взаимодействуют друг с другом напрямую. В некоторых случаях это нежелательно.
Потенциальная проблема безопасности заключается в том, что злоумышленник может использовать единственное уязвимое приложение, чтобы отправлять трафик на все поды в сети. Как и во многих областях безопасности, здесь применим принцип наименьших привилегий. В идеале сетевые политики должны явно указывать, какие соединения между подами разрешены, а какие нет.
Например, ниже приведена простая политика, которая запрещает весь входящий трафик для конкретного пространства имен:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Визуализация этой конфигурации:
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
Более подробно здесь.
Шаг четвертый: нестандартное поведение с помощью хуков и init-контейнеров
Одной наших из главных задач было обеспечение деплоев в Kubernetes без простоя для разработчиков. Это трудно из-за того, что существует множество вариантов завершения работы приложений и освобождения ими использованных ресурсов.
Особые трудности возникли с Nginx. Мы заметили, что при последовательном развертывании этих подов активные соединения прерывались до успешного завершения.
После обширных изысканий в интернете выяснилось, что Kubernetes не ждет, пока соединения Nginx исчерпают себя, прежде чем завершить работу пода. С помощью pre-stop хука мы внедрили такую функциональность и полностью избавились от даунтайма:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
А вот
nginx-killer.sh:#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Еще одна чрезвычайно полезная парадигма — использование init-контейнеров для обработки запуска конкретных приложений. Это особенно полезно в случае, если у вас есть ресурсоемкий процесс миграции базы данных, который следует запустить до запуска приложения. Для этого процесса вы также можете указать более высокий лимит ресурсов, не устанавливая такой лимит для основного приложения.
Другой распространенной схемой является доступ к секретам в init-контейнере, который предоставляет эти учетные данные главному модулю, что предотвращает несанкционированный доступ к секретам из самого основного модуля приложения.
Как обычно, цитата из документации: init-контейнеры безопасно запускают пользовательский код или утилиты, которые иначе снизят безопасность образа контейнера приложения. Храня отдельно ненужные инструменты, вы ограничиваете поверхность атаки образа контейнера приложения.
Шаг пятый: настройка ядра
Напоследок расскажем о более продвинутой технике.
Kubernetes — исключительно гибкая платформа, которая позволяет запускать рабочие нагрузки так, как вы считаете нужным. У нас есть ряд высокоэффективных приложений, требующих чрезвычайно много ресурсов. Проведя обширное нагрузочное тестирование, мы обнаружили, что одно из приложений с трудом справляется с ожидаемой нагрузкой трафика, если действуют настройки Kubernetes по умолчанию.
Однако Kubernetes позволяет запустить привилегированный контейнер, который изменяет параметры ядра только для конкретного пода. Вот что мы использовали для изменения максимального количества открытых соединений:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
Это более продвинутая техника, которая часто не нужна. Но если ваше приложение еле справляется с большой нагрузкой, можете попробовать настроить некоторые из этих параметров. Более подробная информация об этом процессе и настройке различных значений — как всегда в официальной документации.
В заключение
Хотя Kubernetes может показаться готовым решением «из коробки», для бесперебойной работы приложений необходимо предпринять несколько ключевых шагов.
На протяжении всей миграции на Kubernetes важно следовать «циклу нагрузочного тестирования»: запускаете приложение, тестируете его под нагрузкой, наблюдаете за метриками и поведением при масштабировании, настраиваете конфигурацию на основе этих данных, затем снова повторяете этот цикл.
Реалистично оцените ожидаемый трафик и попробуйте выйти за его предел, чтобы посмотреть, какие компоненты сломаются первыми. С таким итерационным подходом для достижения успеха может хватить лишь нескольких из перечисленных рекомендаций. Либо может потребоваться более глубокая настройка.
Всегда задавайте себе такие вопросы:
- Сколько ресурсов потребляют приложения и как изменится этот объем?
- Каковы реальные требования к масштабированию? Сколько трафика в среднем будет обрабатывать приложение? А как насчет пикового трафика?
- Как часто сервису потребуется горизонтальное масштабирование? Как быстро нужно вводить в строй новые поды, чтобы принимать трафик?
- Насколько корректно завершается работа подов? Нужно ли это вообще? Можно ли добиться развертывания без даунтайма?
- Как минимизировать риски для безопасности и ограничить ущерб от любых скомпрометированных подов? Есть ли у каких-то сервисов разрешения или доступы, которые им не требуются?
Kubernetes предоставляет невероятную платформу, которая позволяет использовать лучшие практики для развертывания тысяч сервисов в кластере. Тем не менее все приложения разные. Иногда внедрение требует немного больше работы.
К счастью, Kubernetes предоставляет необходимые настройки для достижения всех технических целей. Используя комбинацию запросов ресурсов и лимитов, проб Liveness и Readiness, init-контейнеров, сетевых политик и нестандартной настройки ядра, вы можете добиться высокой производительности наряду с отказоустойчивостью и быстрой масштабируемостью.
Что еще почитать:
KOTaSYS
Хорошая статья — почерпнул что-то новое, спасибо