

Команда Mail.ru Cloud Solutions перевела полное пошаговое руководство для создания образа Docker (GPU или CPU) вместе с объяснением всех передовых методов, которые следует использовать для обслуживания любого программного обеспечения на основе машинного обучения. Далее текст от лица автора.
Обычно создание Docker-образа считается простой задачей по сравнению с разработкой других компонентов системы машинного обучения, таких как конвейер данных, обучение модели, обслуживающая инфраструктура и т. д. Но неэффективный и громоздкий Docker-образ способен сильно понизить производительность или даже положить инфраструктуру.
Эта статья посвящена сборке идеального образа, а не рассмотрению его достоинств или применяемых в образе концепций. Я исхожу из того, что у вас есть базовые знания:
Общие рекомендации по сборке Docker-образа
Есть много отличных источников информации по универсальным лучшим методикам, например официальное руководство Docker, но я хочу предложить лаконичный вариант, адаптированный под проект на основе машинного обучения.
Файл requirements.txt всегда должен содержать версию пакета Python. Никогда не пишите просто название пакета, иначе всегда будет устанавливаться последний пакет из списка, а пользы от Docker не будет никакой.
Всегда группируйте похожие команды RUN, которые оперируют на одном уровне Docker (не буду объяснять причин, это выходит за рамки статьи).
Например:
RUN apt update && apt install --no-install-recommends -y build-essential gcc curl ca-certificates python3 && apt clean && rm -rf /var/lib/apt/lists/*
Используйте с pip флаг
--no-cache-dirв качестве целевой эксплуатационной среды:
RUN pip install --no-cache-dir --user -r /req.txt
Используйте .dockerignore, чтобы избежать ненужного контекста сборки. Это работает так же, как .gitignore.
По мере возможности используйте slim-версию базового образа, например,
python:buster-slim,debian:buster-slimи так далее.
Избегайте базовых Docker-образов на основе Alpine. Звучит противоречиво, но поверьте, они плохо работают с Python. Подробнее читайте в этой публикации.
Сборка Docker-образа для любого проекта на Python (CPU)
Чаще всего системы машинного обучения делают на Python, поэтому важно эффективно создавать любые Docker-образы на основе этого языка.
Одноэтапная сборка
Во время одного общего процесса сборки будут выполнены все задачи. Последовательность действий: выберите базовый образ, установите пакеты ОС, скопируйте исходники, установите пакеты, задайте точку входа (если нужно) или другие команды.
Пример одноэтапной сборки Docker:
FROM python:3.8-slim
RUN apt update && apt install --no-install-recommends -y build-essential gcc && apt clean && rm -rf /var/lib/apt/lists/*
COPY ./req.txt /req.txt
COPY ./src /src
RUN pip3 install --no-cache-dir -r /req.txt
CMD ['python3', '/src/app.py']
EXPOSE 8080Для демонстрации я использовал эти пакеты:
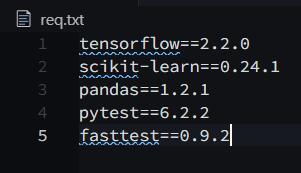
После запуска команды docker build размер образа был 1,64 Гб:

Одноэтапная сборка очень проста и подходит для многих сценариев. Это нормальная практика, но у нее есть фундаментальные недостатки, особенно с точки зрения проектов на Python. Важно c apt использовать флаг --no-install-recommends, а с pip — флаг --no-cache-dir. Нам не надо сохранять кэш, потому что он не нужен ни для среды разработки, ни для эксплуатационной среды. Если вы используете какую-нибудь CI/CD-платформу (вроде Github action) с ограниченным размером хранилища, то она будет работать только при таком методе.
Библиотеки Python из коробки не работают, сначала их нужно скомпилировать на С. Нас интересует лишь скомпилированная часть библиотек, остальное не нужно. При выполнении pip install все библиотеки сначала скачиваются, а затем компилируются.
Нужно удалить все промежуточные и дополнительные компоненты, созданные при установке библиотек. Для этого можно использовать bash-команды. Если сделать неправильно, то будет много неприятностей или даже сломается библиотека. Это довольно сложно, многие стараются этого избежать и пускают в эксплуатацию более громоздкие образы. Но нам на помощь приходит многоэтапная сборка образа (Docker multi-stage builds).
Многоэтапная сборка
Это один из самых эффективных методов оптимизации, сохраняющий удобство чтения и сопровождения образов. Чтобы создать действительно эффективный Dockerfile, нужно применять ухищрения с оболочкой и прочую логику, чтобы уровни оставались как можно меньше и чтобы на каждом уровне были только те артефакты, которые нужны ему от предыдущего уровня.
При многоэтапной сборке вы применяете в Dockerfile выражения FROM. Каждая такая инструкция может использовать другую основу, и каждая начинает новый этап сборки. Вы можете выборочно копировать артефакты из одного этапа в другой, отбрасывая все, что вам не нужно в конечном образе.
Давайте посмотрим на примере:
# Stage 1: Builder/Compiler
FROM python:3.7-slim as builder
RUN apt update && apt install --no-install-recommends -y build-essential gcc
COPY req.txt /req.txt
RUN pip install --no-cache-dir --user -r /req.txt
# Stage 2: Runtime
FROM debian:buster-slim
RUN apt update && apt install --no-install-recommends -y build-essential python3 && apt clean && rm -rf /var/lib/apt/lists/*
COPY --from=builder /root/.local/lib/python3.7/site-packages /usr/local/lib/python3.7/dist-packages
COPY ./src /src
CMD ['python3', '/src/app.py']
EXPOSE 8080
При таком способе размер Docker-образа стал 1,61 Гб вместо 1,64. Вроде бы разница невелика, но на самом деле отличий много. Пробежимся по ним.
Строки с 1 по 5 относятся к первому этапу — компилированию, когда мы устанавливаем библиотеки Python: они сначала скачиваются, а затем компилируются на С, поэтому мы даже установили gcc. Затем мы просто копируем скомпилированные библиотеки из первого этапа во второй (runtime) с помощью этой команды:
COPY --from=<stage 1> stage1/src stage2/destinationНо, как видно на скриншоте, размер уменьшился не сильно. С другими языками разница будет огромной, но у Python есть несколько фокусов в запасе:
Сейчас многие библиотеки распространяются в виде предварительно скомпилированных .whl-файлов, это формат wheel из PyPi, поэтому компилировать их не требуется.
То есть многоэтапной сборке негде развернуться в случае с проектами на Python? Совершенно верно! Однако не каждый пакет из PyPi предварительно скомпилирован в .whl, многие поставляются в устаревшем формате tar.gz (сжатые с помощью tarballs), и их нужно сначала скомпилировать. Здесь многоэтапная сборка будет работать по-своему.
Кроме того, многоэтапность применима, если вы собираете Python-пакет из исходника, либо с помощью setup.py используете локальный пакет, поскольку опять же их нужно компилировать.
Настаиваю, чтобы вы прочитали эту статью, в которой объясняется формат wheels в Python.

В файле req.txt, который я использовал для демонстрации, только вышеприведенные пакеты представлены не в формате wheel, а также они очень малы. Но если какой-то пакет не скомпилирован предварительно и занимает много места, то вы потеряете много места на диске.
Сборка Docker-образа для любого проекта на Python (GPU)
Собирать Docker-образ для CPU нетрудно, чего не скажешь о сборке образа для GPU. Если ошибиться, то размер будет огромный. Я сосредоточусь на практической реализации и не буду касаться теории (думаю, это выходит за рамки статьи).
Необходимые условия
TensorFlow и Pytorch используют видеодрайверы Nvidia CUDA. Поэтому сначала нужно установить на хостовую машину свежие драйверы Nvidia и CUDA, а также соответствующую cuDNN (не буду здесь это описывать).
После этого нужно установить nvidia-docker2, позволяющий движку Docker обращаться к видеодрайверам Nvidia.
Самое важное — выбрать правильную версию/тег CUDA, cuDNN для Nvidia-Docker-образа, а также записать туда TensorFlow/Pytorch. Тогда система машинного обучения сможет использовать видеокарту. Поверьте, это может быть очень неприятной задачей, так что дам советы:
- Всегда используйте в Docker-образе те же версии CUDA и cuDNN, что и на хостовой машине.
- Не устанавливайте бездумно самую свежую версию библиотеки TensorFlow/Pytorch из PyPi. Это заблуждение, что любая версия этих пакетов будет работать с любой версией CUDA и cuDNN. На самом деле может быть несовместимость последних версий TensorFlow/Pytorch и CUDA/cuDNN. Всегда проверяйте это в среде разработки.
- Самое важное: в Docker-хабе Nvidia есть много образов, так что разберитесь в их тегах и выберите правильный образ.
Описание официального Docker-хаба Nvidia:

Нас интересует только основа и runtime, а не среда разработки, потому что мы сосредоточены на среде эксплуатации. Как выбрать нужный тег? Читайте ниже.
Одноэтапная сборка
Для выбора тега есть эмпирическое правило, которому я следую.
Шаг 1: проверьте версию CUDA и cuDNN на хостовой машине.

У меня CUDA 10.1 и cuDNN 7.5
Шаг 2: в зависимости от шага 1 выберите версию Docker-образа. В моем случае это
nvidia/cuda:10.1-cudnn7-runtime. Почему runtime? Потому что в нем есть и CUDA, и cuDNN.
Шаг 3: выберите правильную версию TensorFlow/Pytorch, которая совместима с вашей версией CUDA и cuDNN. В моем случае это TensorFlow 2.20.
Обратите внимание: Docker-образ от Nvidia может быть старше Ubuntu (18.04 или 16.04), и тогда будет установлен Python 3.6. Поэтому проверьте совместимость версии Python со своим проектом и внешними пакетами. Потом можно будет установить нужную версию.
Пример одноэтапной сборки Docker-образа (GPU):
FROM nvidia/cuda:10.1-cudnn7-runtime
RUN apt update && apt install --no-install-recommends -y build-essential software-properties-common && add-apt-repository -y ppa:deadsnakes/ppa && apt install --no-install-recommends -y python3.8 python3-pip python3-setuptools python3-distutils && apt clean && rm -rf /var/lib/apt/lists/*
COPY req.txt /req.txt
COPY ./src /src
RUN python3.8 -m pip install --upgrade pip && python3.8 -m pip install --no-cache-dir -r /req.txt
CMD ['python3', '/src/app.py']
EXPOSE 8080Примечание: в основе Docker-образа от Nvidia лежит Ubuntu 18.04, мне пришлось внести правку и установить TensorFlow 2.2.0.
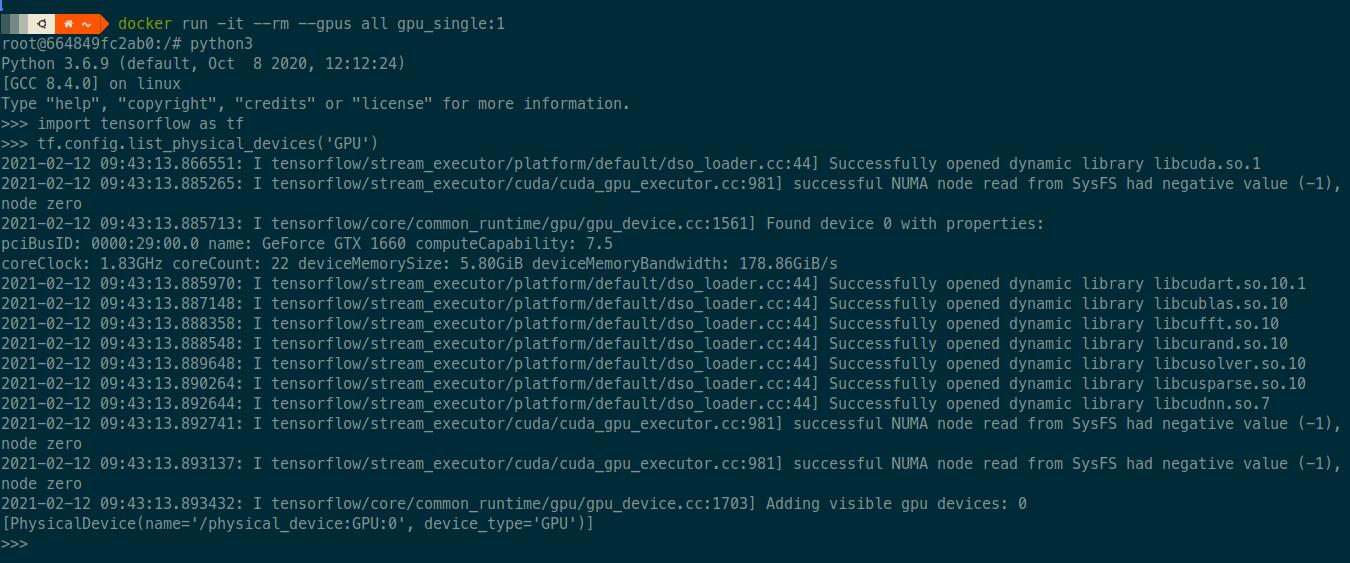
Проверяем, что TensorFlow может использовать видеокарту

Размер Docker-образа при одноэтапной сборке
Многоэтапная сборка
Можно использовать тот же механизм, который описан в главе 2.2. Сначала скачаем и скомпилируем пакеты Python, они будут скопированы во второй этап (runtime). Также нужно воспользоваться всеми советами из главы 3.2.
Пример многоэтапной сборки Docker-образа (GPU):
# Stage 1: Builder/Compiler
FROM python:3.8-slim as builder
RUN apt update && apt install --no-install-recommends -y build-essential gcc
COPY req.txt /req.txt
RUN pip install --no-cache-dir --user -r /req.txt
# Stage 2: Runtime
FROM nvidia/cuda:10.1-cudnn7-runtime
RUN apt update && apt install --no-install-recommends -y build-essential software-properties-common && add-apt-repository -y ppa:deadsnakes/ppa && apt install --no-install-recommends -y python3.8 python3-distutils && update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.6 1 && update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 2 && apt clean && rm -rf /var/lib/apt/lists/*
COPY --from=builder /root/.local/lib/python3.8/site-packages /usr/local/lib/python3.8/dist-packages
COPY ./src /src
CMD ['python3', '/src/app.py']
EXPOSE 8080Примечание: чтобы по умолчанию использовать Python 3.8, я добавил кое-какой код. Если вам это не нужно, то пропустите.
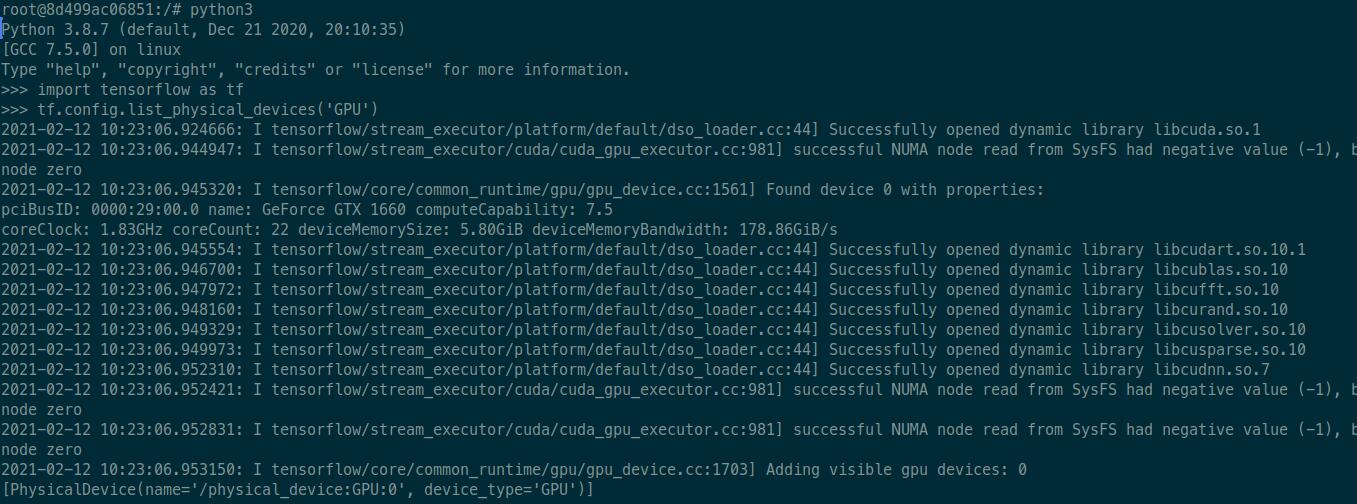
Проверяем, что TensorFlow может использовать видеокарту

Размер Docker-образа при многоэтапной сборке
Снова разница в размерах невелика, причины те же, что и в главе 2.2. Очень рекомендую всегда применять многоэтапную сборку, она в любом случае улучшает удобочитаемость.
Исследуем Docker-образ с помощью Dive
Даже после сборки с соблюдением всех правил и советов нужно исследовать образ на возможность дополнительных улучшений.
Dive — прекрасный инструмент на основе командной строки для исследования образа, содержимого слоев и поиска способов уменьшить размер Docker/OCI-образа. У него на GitHub больше 24 тыс. звезд. К тому же он очень прост в использовании.
У Dive есть две очень полезные метрики:
- возможная трата места на диске,
- оценка эффективности образа.
Но его лучшая возможность — интеграция с любым CI-инструментом. Для обеих метрик можно указать условие, и если оно не выполняется, то и CI-задача тоже не выполняется. Поэтому мы всегда можем доверять Docker-образу, созданному с помощью CI-задачи.
Заключение
Наша главная цель — добиться минимального размера Docker-образа, потому что любой образ для системы машинного обучения и так будет большим. Всегда нужно следовать лучшим методикам, особенно применять многоэтапную сборку и версионирование пакетов. И наконец, для образов под видеокарты необходимо проверять конфигурацию в среде разработки.
Что еще почитать по теме:


Max1mka1