

Запустить облачные микросервисы или 12-факторные приложения в Kubernetes относительно просто. Но как насчет запуска приложений, которые явно не предназначены для работы в контейнерной среде?
Команда Kubernetes as a Service Mail.ru Cloud Solutions перевела статью об одном из самых мощных инструментов в Kubernetes — мультиконтейнерном поде. Он позволяет менять поведение приложения, не изменяя его кода. Эта функция удобна для приложений, которые изначально не предназначены для работы в контейнерах.
Итак, посмотрим на примере.
Защита HTTP
Elasticsearch разработали до того, как контейнеры стали популярны (хотя сейчас его можно запустить в Kubernetes). И его можно рассматривать в качестве замены для устаревшего Java-приложения, которое предназначено для работы на виртуальной машине.
В этой статье я буду использовать Elasticsearch в качестве примера приложения, которое нужно улучшить с помощью мультиконтейнерных подов.
Вот очень простой, но не для продакшена, деплой и сервис для Elasticsearch:
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
spec:
selector:
matchLabels:
app.kubernetes.io/name: elasticsearch
template:
metadata:
labels:
app.kubernetes.io/name: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.9.3
env:
- name: discovery.type
value: single-node
ports:
- name: http
containerPort: 9200
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
spec:
selector:
app.kubernetes.io/name: elasticsearch
ports:
- port: 9200
targetPort: 9200Примечание: переменная окружения dicsovery.type нужна, чтобы запустить одиночную реплику.
Elasticsearch слушает HTTP-порт 9200 по умолчанию.
Вы можете убедиться, что под работает, запустив в кластере другой под и подключившись к службе elasticsearch:
$ kubectl run -it --rm --image=curlimages/curl curl -- curl http://elasticsearch:9200
{
"name" : "elasticsearch-77d857c8cf-mk2dv",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "z98oL-w-SLKJBhh5KVG4kg",
"version" : {
"number" : "7.9.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868",
"build_date" : "2020-10-16T10:36:16.141335Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Теперь предположим, что вы хотите получить модель безопасности с нулевым доверием и зашифровать весь трафик в сети. Как поступить, если в приложении нет встроенной поддержки TLS?
Примечание: последние версии Elasticsearch поддерживают TLS, раньше эта функция была платной.
Первая мысль — выполнить терминацию TLS при помощи Nginx Ingress, поскольку Ingress маршрутизирует внешний трафик в кластере. Это не соответствует требованиям: трафик между подом входящего трафика и подом Elasticsearch может проходить по сети в незашифрованном виде.

Внешний трафик проходит через Ingress и направляется к подам
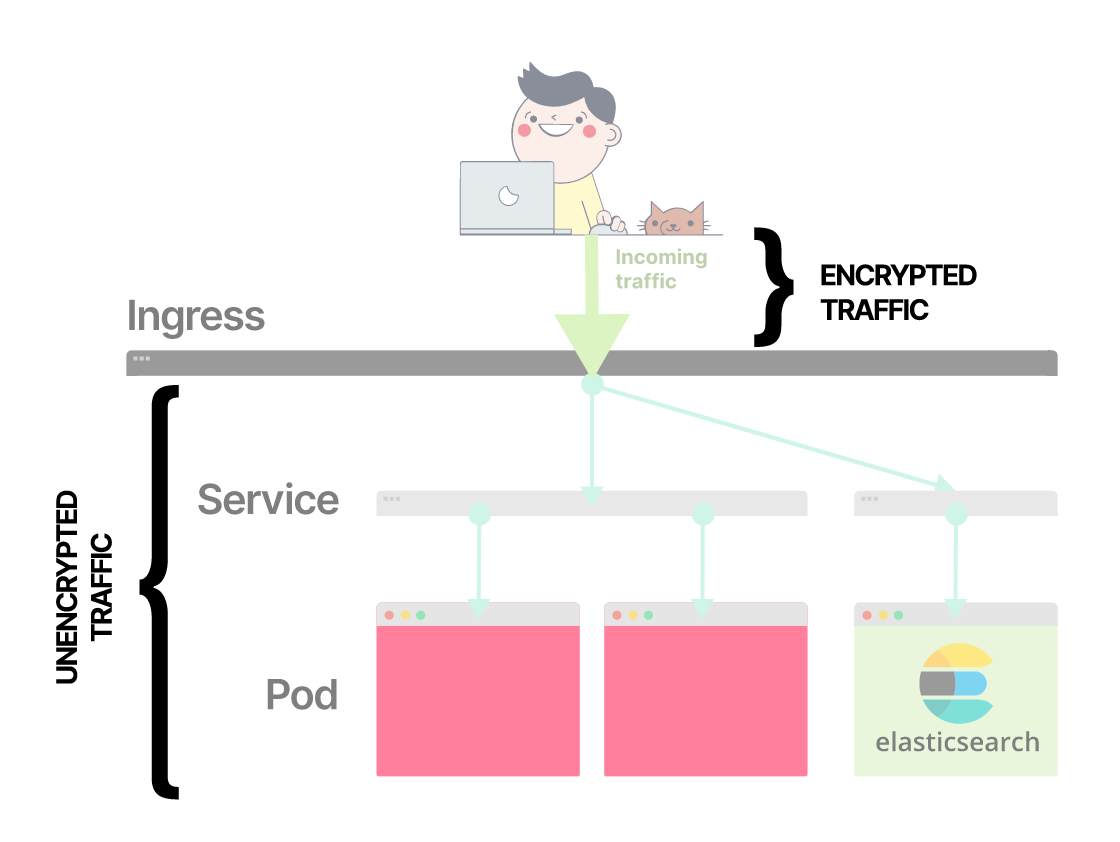
Если вы завершите TLS на входе, остальной трафик не будет зашифрован
Решение, которое соответствует требованиям, — прикрепить прокси-контейнер Nginx к поду, доступному по TLS. Тогда трафик будет зашифрован на всем пути от пользователя к поду.
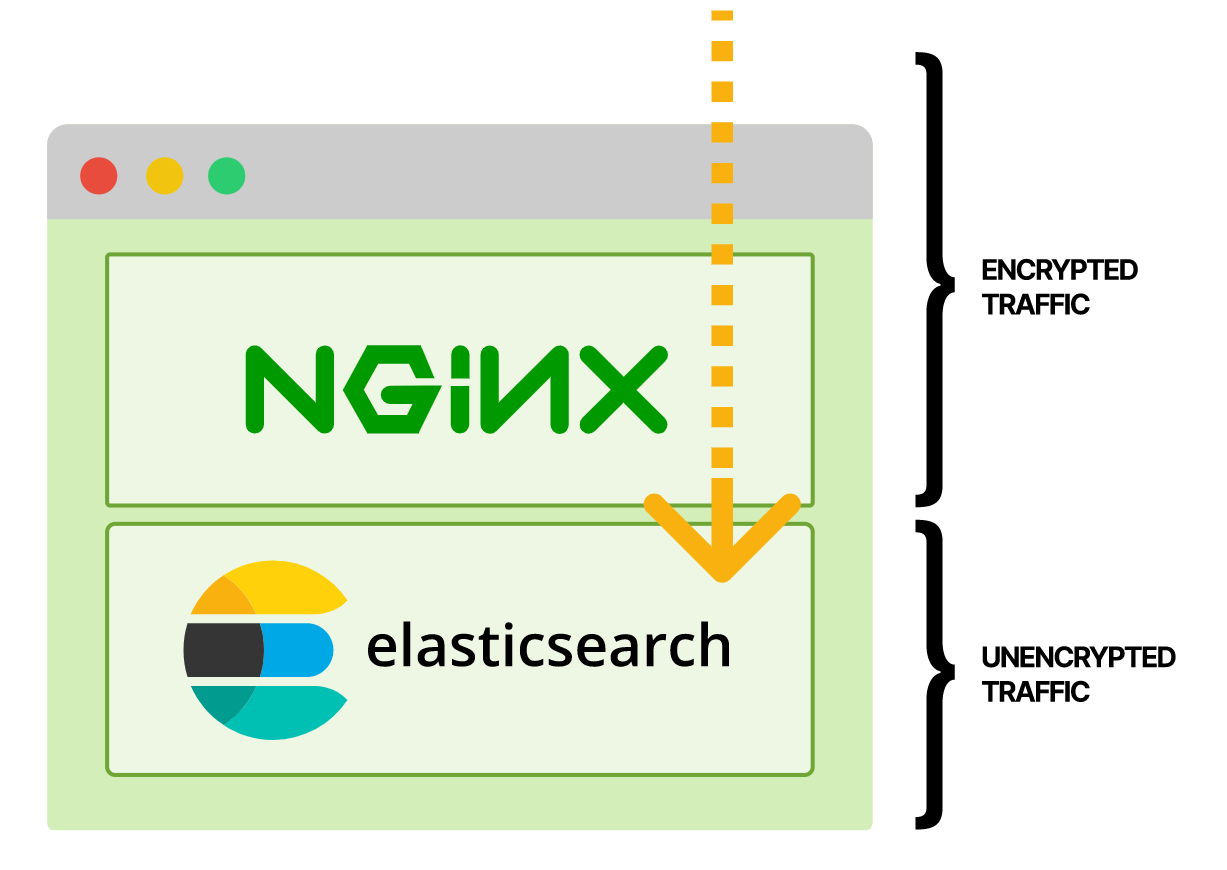
Если вы включаете прокси-контейнер в модуль, то можете завершить TLS в модуле Nginx

До контейнера Elasticsearch трафик идет в зашифрованном виде
Вот как выглядит деплоймент:
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
spec:
selector:
matchLabels:
app.kubernetes.io/name: elasticsearch
template:
metadata:
labels:
app.kubernetes.io/name: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.9.3
env:
- name: discovery.type
value: single-node
- name: network.host
value: 127.0.0.1
- name: http.port
value: '9201'
- name: nginx-proxy
image: nginx:1.19.5
volumeMounts:
- name: nginx-config
mountPath: /etc/nginx/conf.d
readOnly: true
- name: certs
mountPath: /certs
readOnly: true
ports:
- name: https
containerPort: 9200
volumes:
- name: nginx-config
configMap:
name: elasticsearch-nginx
- name: certs
secret:
secretName: elasticsearch-tls
---
apiVersion: v1
kind: ConfigMap
metadata:
name: elasticsearch-nginx
data:
elasticsearch.conf: |
server {
listen 9200 ssl;
server_name elasticsearch;
ssl_certificate /certs/tls.crt;
ssl_certificate_key /certs/tls.key;
location / {
proxy_pass http://localhost:9201;
}
}Давайте немного поясню:
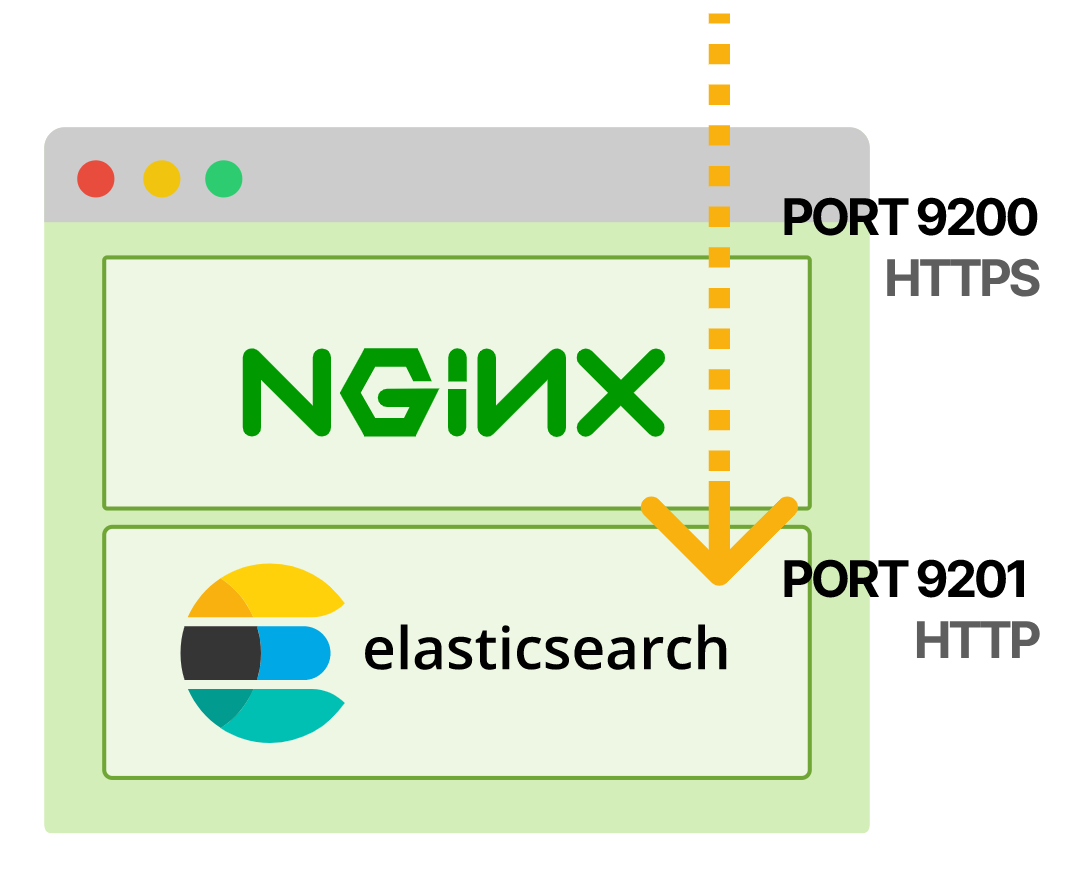
- Elasticsearch слушает
localhostна порту9201вместо значения по умолчанию0.0.0.0:9200. Для этого предусмотрены переменные средыnetwork.hostиhttp.port. - Новый контейнер
nginx-proxyслушает порт9200HTTPS и передает запросы в Elasticsearch в порт9201. Секретelasticsearch-tlsсодержит сертификат и ключ TLS, их можно сгенерировать с помощью cert-manager.
Таким образом, запросы извне пода поступают в Nginx через порт 9200 HTTPS, а затем попадают в Elasticsearch через порт 9201.
Вы можете проверить, что все работает, отправив HTTPS-запрос из кластера:
kubectl run -it --rm --image=curlimages/curl curl -- curl -k https://elasticsearch:9200
{
"name" : "elasticsearch-5469857795-nddbn",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "XPW9Z8XGTxa7snoUYzeqgg",
"version" : {
"number" : "7.9.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868",
"build_date" : "2020-10-16T10:36:16.141335Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Примечание: ключ -k нужен для самоподписанных сертификатов TLS. В продакшене необходимо использовать доверенный сертификат.
Беглый взгляд на логи показывает, что запрос прошел через прокси Nginx:
kubectl logs elasticsearch-5469857795-nddbn nginx-proxy | grep curl
10.88.4.127 - - [26/Nov/2020:02:37:07 +0000] "GET / HTTP/1.1" 200 559 "-" "curl/7.73.0-DEV" "-"Вы также можете убедиться: нельзя подключиться к Elasticsearch через незашифрованные соединения.
kubectl run -it --rm --image=curlimages/curl curl -- curl http://elasticsearch:9200
<html>
<head><title>400 The plain HTTP request was sent to HTTPS port</title></head>
<body>
<center><h1>400 Bad Request</h1></center>
<center>The plain HTTP request was sent to HTTPS port</center>
<hr><center>nginx/1.19.5</center>
</body>
</html>Поздравляю, вы включили TLS, не меняя кода Elasticsearch или образа в контейнере!
Практика добавления прокси-контейнера в под распространена, поэтому у нее есть свое имя — шаблон Ambassador.
Примечание: Все шаблоны в этом посте подробно описаны в отличной статье от Google.
Добавление базовой поддержки TLS — только начало. Вот еще несколько вещей, которые можно сделать с шаблоном Ambassador:
- Чтобы зашифровать весь трафик в кластере с помощью сертификата TLS, устанавливают прокси-сервер Nginx (или другой) в каждом поде кластера. Можно пойти еще дальше и использовать взаимный TLS, он гарантирует — все запросы аутентифицированы и зашифрованы. Это основной подход, в котором используют сервисные сети, например, Istio или Linkerd.
- Можно использовать прокси, он гарантирует, что центр OAuth аутентифицирует все запросы, проверяя jwt. Одним из примеров — gcp-iap-auth, он проверяет, что запросы аутентифицированы GCP Identity-Aware Proxy.
- Можно подключиться к внешней базе данных через безопасный туннель. Это особенно удобно для баз данных без встроенной поддержки TLS, например для старых версий Redis. Другой пример — Google Cloud SQL Proxy.
Принцип работы мультиконтейнерных подов
Давайте вернемся назад и посмотрим, в чем разница между подами и контейнерами в Kubernetes. Это поможет лучше понять происходящее под капотом.
Традиционный контейнер, например запущенный при помощи Docker, обеспечивает несколько форм изоляции:
- Изоляция ресурсов, например ограничение памяти.
- Изоляция процессов.
- Файловая система и изоляция монтирования.
- Сетевая изоляция.
Примечание: Docker позволяет настраивать и другие вещи, но эти — наиболее важные.
Инструменты под капотом — пространства имен Linux и контрольные группы (cgroups).
Контрольные группы — удобный способ ограничить ресурсы, которые может использовать конкретный процесс, например CPU или память. Допустим, вы указываете: процесс может использовать только 2 ГБ памяти и одно из четырех ядер CPU.
В то же время пространства имен отвечают за изоляцию процесса и ограничивают то, что он может видеть. Например, процесс может видеть только сетевые пакеты, непосредственно с ним связанные. И не может видеть все сетевые пакеты, проходящие через сетевой адаптер.
Другой пример — вы можете изолировать файловую систему и заставить процесс поверить, что у него есть доступ ко всей системе.
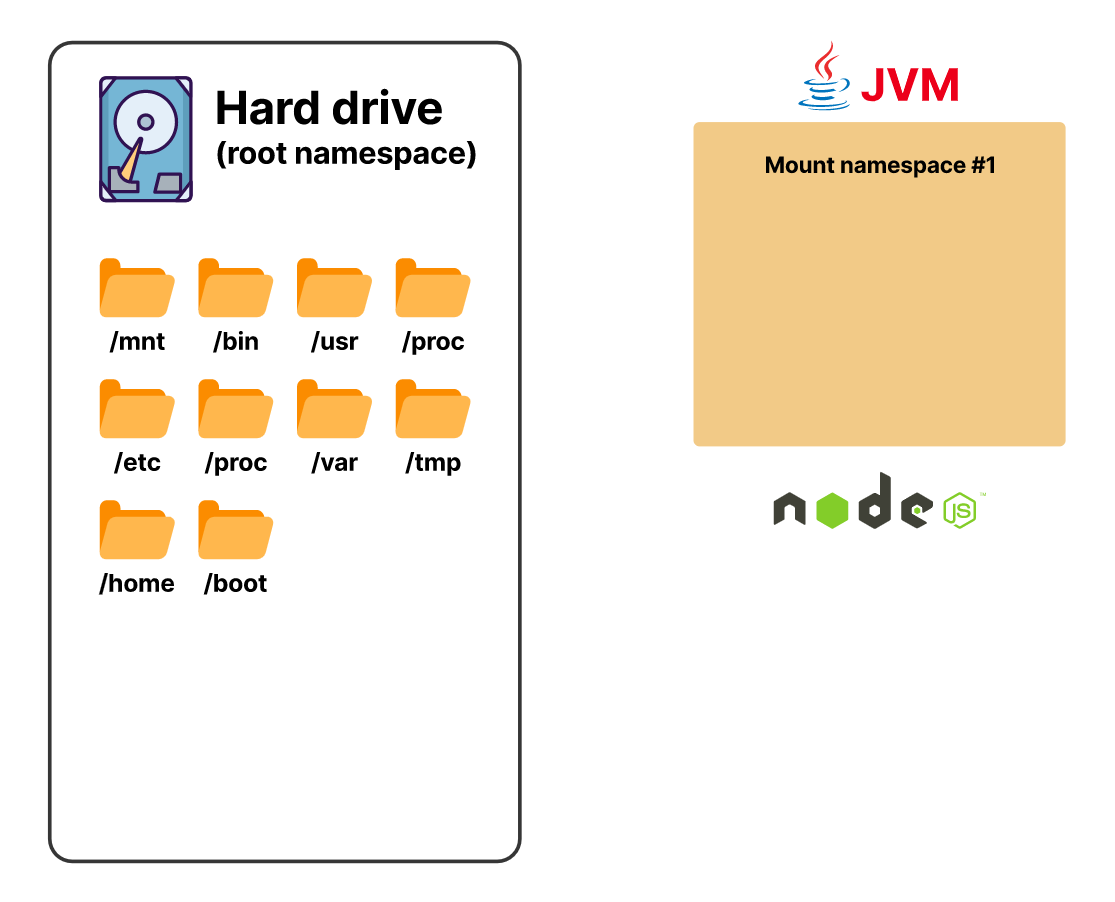
Начиная с версии ядра 5.6, есть восемь видов пространств имен, и mount — одно из них
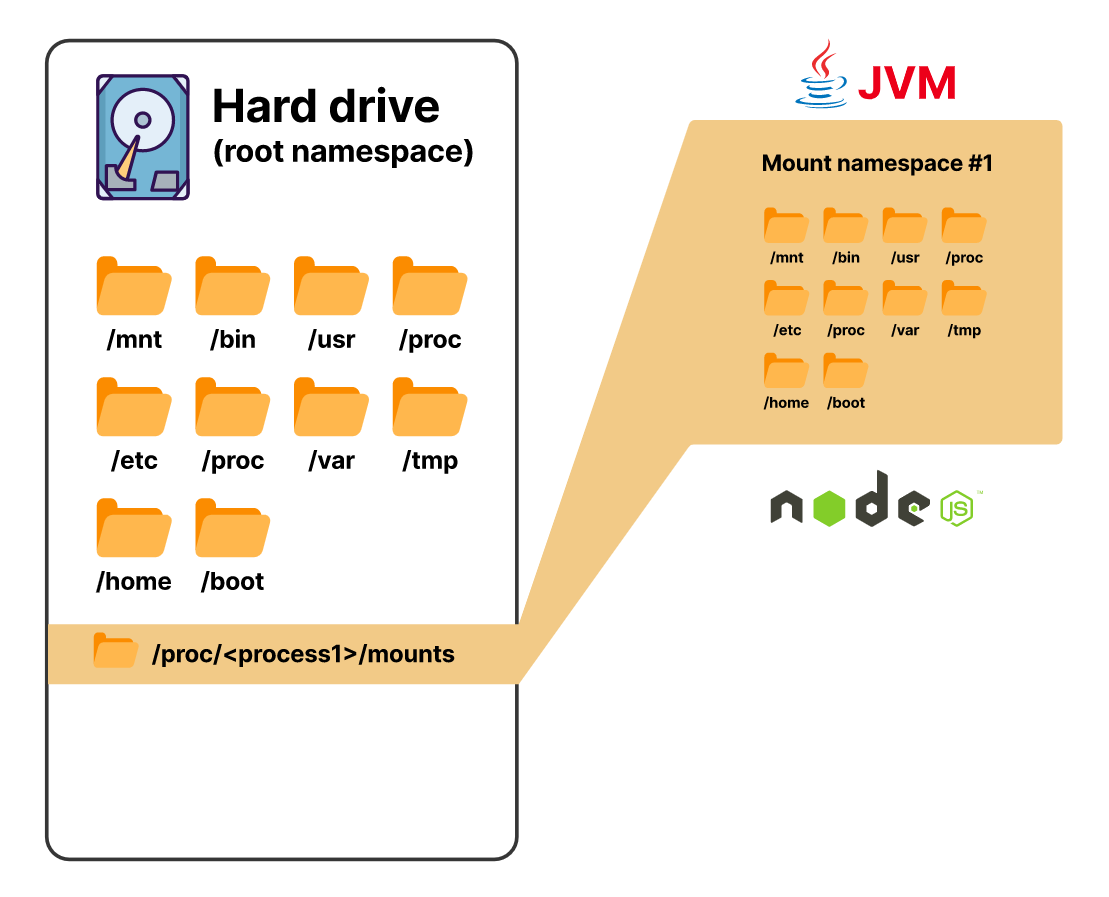
Используя пространство имен mount, вы заставляете процесс поверить, что ему доступны все каталоги на хосте, хотя это не так
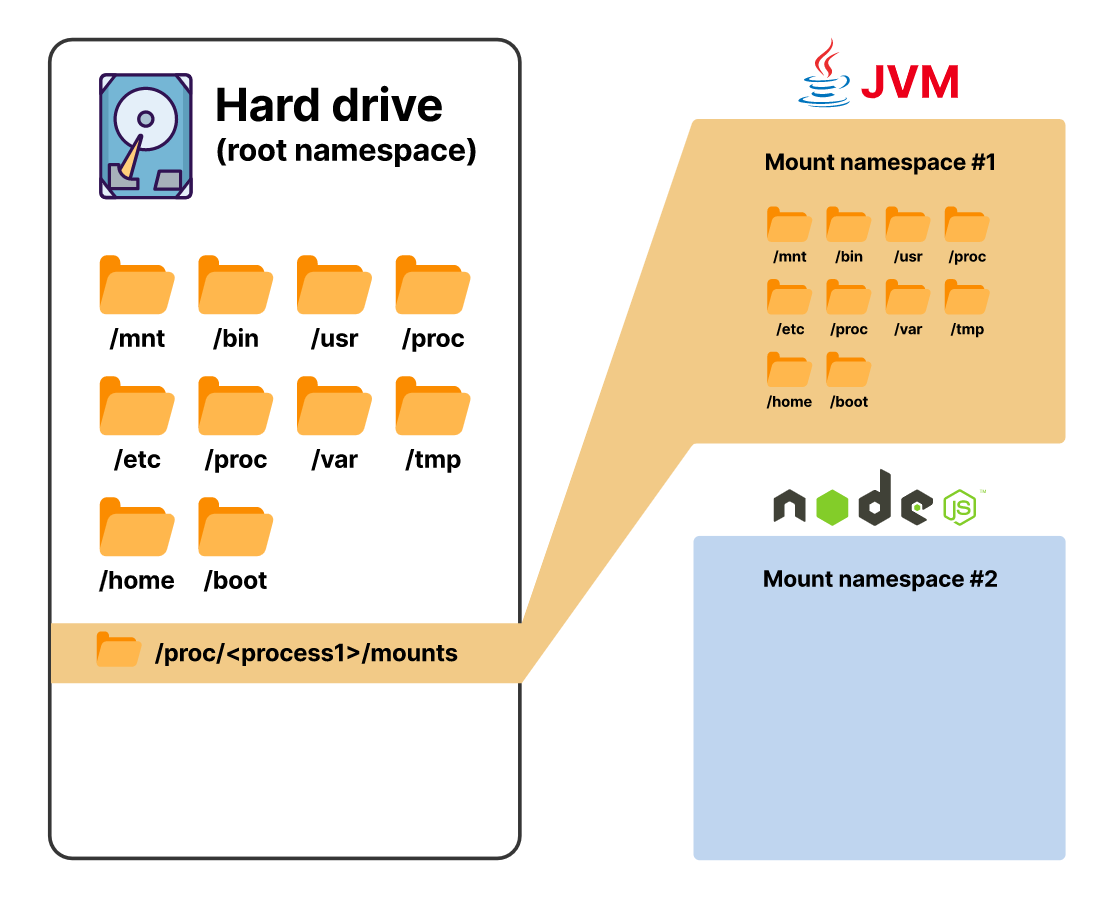
Пространство имен mount предназначено для изоляции ресурсов, в данном случае — файловой системы
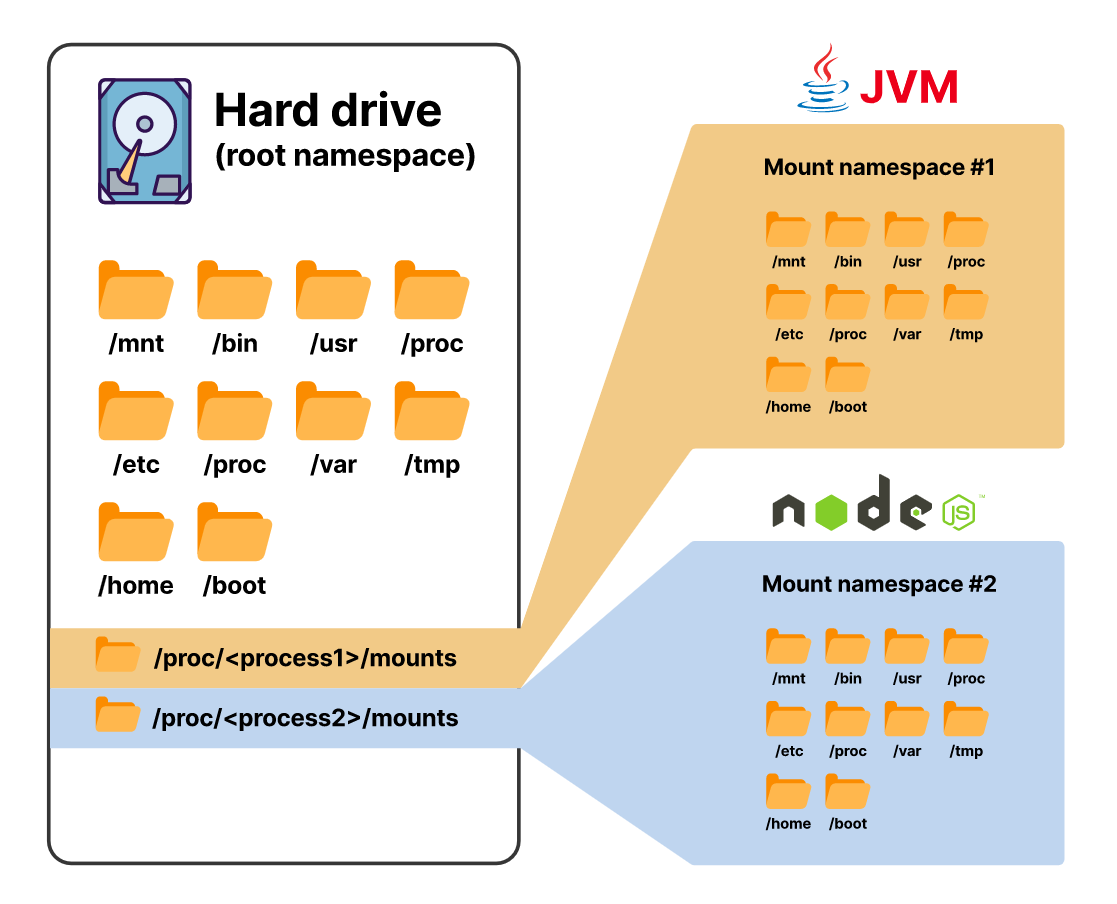
Каждый процесс видит одну и ту же файловую систему, но при этом изолирован от других
Примечание: если вам нужно освежить в памяти контрольные группы и пространства имен, то вот отличная статья, в которой рассматриваются некоторые технические детали.
В Kubernetes контейнер обеспечивает все перечисленные формы изоляции, кроме изоляции сети.
Изоляция сети происходит на уровне пода. Другими словами: у каждого контейнера в поде — своя файловая система, таблица процессов и так далее. Но все они совместно используют одно и то же сетевое пространство имен.
Чтобы лучше понять, как все работает, давайте поиграемся с простым подом, состоящим из нескольких контейнеров:
apiVersion: v1
kind: Pod
metadata:
name: podtest
spec:
containers:
- name: c1
image: busybox
command: ['sleep', '5000']
volumeMounts:
- name: shared
mountPath: /shared
- name: c2
image: busybox
command: ['sleep', '5000']
volumeMounts:
- name: shared
mountPath: /shared
volumes:
- name: shared
emptyDir: {}Немного разберем:
- Есть два контейнера, какое-то время оба просто спят.
- Есть том
emptyDir, по сути, это временный локальный том, он действует в течение всего срока службы пода. - Том
emptyDirмонтируется в каждом контейнере в каталоге/shared.
Вы можете убедиться, что том смонтирован в первом контейнере, используя kubectl exec:
$ kubectl exec -it podtest --container c1 -- shКоманда подключает терминальный сеанс к контейнеру c1 в поде podtest. Вы можете проверить прикрепленные тома с1 с помощью команды:
$ mount | grep shared
/dev/vda1 on /shared type ext4 (rw,relatime)Как видите, том смонтирован на /shared — общем томе, который мы создали ранее. Теперь создадим несколько файлов:
$ echo "foo" > /tmp/foo
$ echo "bar" > /shared/barПроверим те же файлы из второго контейнера. Сначала подключимся к нему с помощью команды:
$ kubectl exec -it podtest --container c2 -- sh$ cat /shared/bar
bar
cat /tmp/foo
cat: can't open '/tmp/foo': No such file or directoryКак видите, файл, созданный в общем каталоге, доступен в обоих контейнерах, а файл в /tmp — нет. Так случилось, поскольку за исключением тома, файловые системы контейнеров полностью изолированы друг от друга.
Теперь посмотрим на сеть и изоляцию процессов. Простой способ понять, как настроена сеть, — использовать команду ip link, она показывает сетевые устройства системы Linux.
Выполним команду в первом контейнере:
$ kubectl exec -it podtest -c c1 -- ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
178: eth0@if179: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 46:4c:58:6c:da:37 brd ff:ff:ff:ff:ff:ffА теперь ту же команду в другом контейнере:
$ kubectl exec -it podtest -c c2 -- ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
178: eth0@if179: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 46:4c:58:6c:da:37 brd ff:ff:ff:ff:ff:ffВы можете видеть, что в обоих контейнерах есть:
- Один и тот же девайс
eth0. - Один и тот же MAC-адрес
46:4c:58:6c:da:37.
Предполагается, что MAC-адреса глобально уникальны, значит, это явный признак того, что модули используют одно и то же устройство.
Теперь давайте посмотрим на совместное использование сети в действии. Подключимся к первому контейнеру с помощью команды:
$ kubectl exec -it podtest -c c1 -- shЗапустим очень простой сетевой листенер nc:
$ nc -lk -p 5000 127.0.0.1 -e 'date'Команда запускает листенер на локальном хосте на порту 5000 и показывает дату любому подключенному TCP-клиенту. Может ли к нему подключиться второй контейнер? Откроем терминал во втором контейнере с помощью команды:
$ kubectl exec -it podtest -c c2 -- shПосмотрите сами — второй контейнер может подключиться к сетевому порту, но не видит процесс nc:
$ telnet localhost 5000
Connected to localhost
Sun Nov 29 00:57:37 UTC 2020
Connection closed by foreign host
$ ps aux
PID USER TIME COMMAND
1 root 0:00 sleep 5000
73 root 0:00 sh
81 root 0:00 ps auxПодключившись через telnet, вы можете увидеть дату, это доказывает, что листенер nc работает. Но ps aux, показывающий все процессы в контейнере, вообще не отображает nc. Это связано с тем, что у контейнеров внутри модуля есть изоляция процессов, но нет изоляции сети.
И это объясняет, как работает паттерн Ambassador:
- Поскольку все контейнеры используют одно и то же сетевое пространство имен, то один контейнер может прослушивать все подключения — даже внешние.
- Остальные контейнеры принимают соединения только от localhost, отклоняя любые внешние соединения.
Контейнер, который получает внешний трафик, называют Ambassador — отсюда и название шаблона.
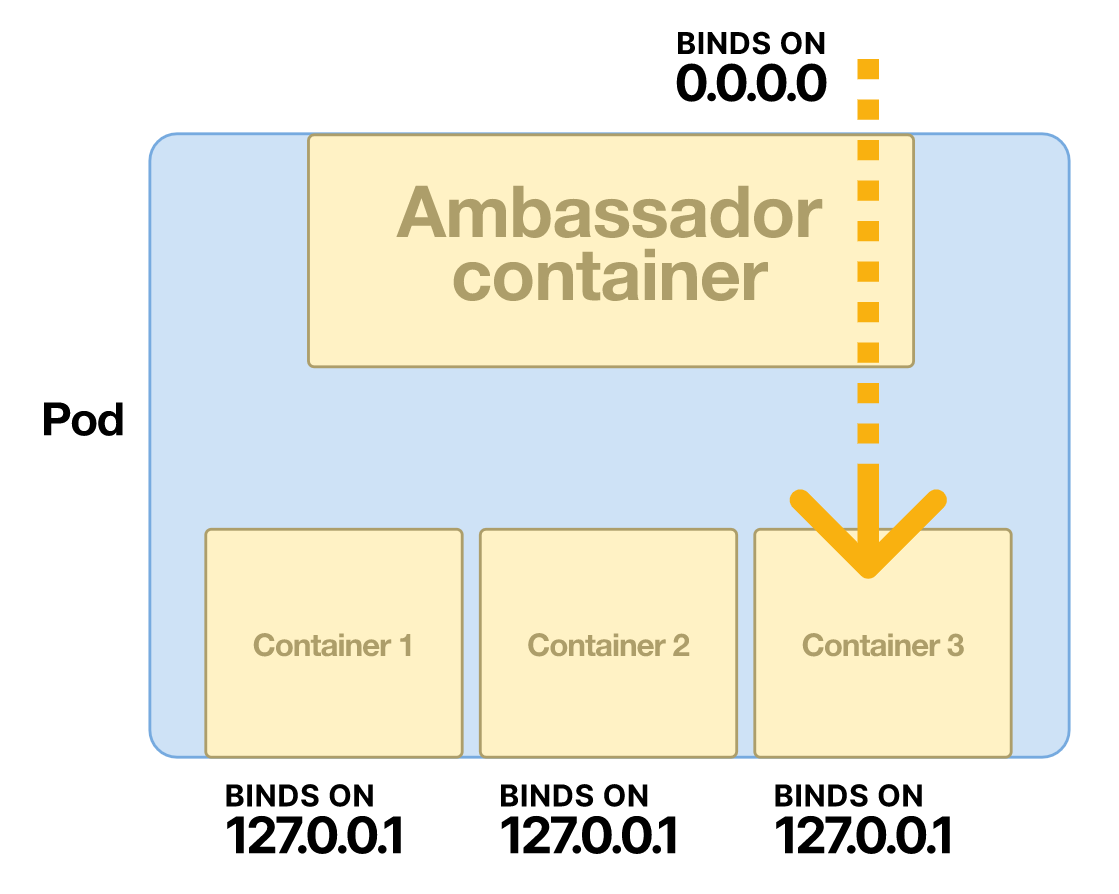
Примечание: поскольку сетевое пространство имен общее, то несколько контейнеров в поде не могут прослушивать один и тот же порт!
Давайте посмотрим на другие варианты использования многоконтейнерных подов.
Предоставление метрик по стандартному интерфейсу
Допустим, вы используете Prometheus для мониторинга всех сервисов в вашем кластере Kubernetes. Но есть приложения, которые изначально не экспортируют метрики Prometheus, например Elasticsearch.
Можете ли вы добавить метрики Prometheus в свои поды, не меняя код приложения? Можете, если используете шаблон адаптера.
В примере с Elasticsearch давайте добавим в под контейнер «экспортер», он предоставляет метрики Elasticsearch в формате Prometheus. Это легко сделать, поскольку для Elasticsearch есть экспортер с открытым исходным кодом (вам нужно добавить соответствующий порт в сервис).
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
spec:
selector:
matchLabels:
app.kubernetes.io/name: elasticsearch
template:
metadata:
labels:
app.kubernetes.io/name: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.9.3
env:
- name: discovery.type
value: single-node
ports:
- name: http
containerPort: 9200
- name: prometheus-exporter
image: justwatch/elasticsearch_exporter:1.1.0
args:
- '--es.uri=http://localhost:9200'
ports:
- name: http-prometheus
containerPort: 9114
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
spec:
selector:
app.kubernetes.io/name: elasticsearch
ports:
- name: http
port: 9200
targetPort: http
- name: http-prometheus
port: 9114
targetPort: http-prometheusКак только вы примените этот манифест, метрики станут доступны на порту 9114.
$ kubectl run -it --rm --image=curlimages/curl curl -- curl -s elasticsearch:9114/metrics | head
# HELP elasticsearch_breakers_estimated_size_bytes Estimated size in bytes of breaker
# TYPE elasticsearch_breakers_estimated_size_bytes gauge
elasticsearch_breakers_estimated_size_bytes{breaker="accounting",name="elasticsearch-ss86j"} 0
elasticsearch_breakers_estimated_size_bytes{breaker="fielddata",name="elasticsearch-ss86j"} 0
elasticsearch_breakers_estimated_size_bytes{breaker="in_flight_requests",name="elasticsearch-ss86j"} 0
elasticsearch_breakers_estimated_size_bytes{breaker="model_inference",name="elasticsearch-ss86j"} 0
elasticsearch_breakers_estimated_size_bytes{breaker="parent",name="elasticsearch-ss86j"} 1.61106136e+08
elasticsearch_breakers_estimated_size_bytes{breaker="request",name="elasticsearch-ss86j"} 16440
# HELP elasticsearch_breakers_limit_size_bytes Limit size in bytes for breaker
# TYPE elasticsearch_breakers_limit_size_bytes gaugeЕще раз — вы можете изменить поведение приложения, фактически не меняя код или образы контейнеров. В данном случае мы предоставили стандартизированные метрики Prometheus, которые используют кластерные инструменты (такие, как оператор Prometheus). И таким образом добились хорошего разделения между приложением и базовой инфраструктурой.
Просмотр логов
Давайте посмотрим на паттерн Sidecar, с его помощью в под добавляют улучшающий приложение контейнер.
Шаблон Sidecar — общий и применяется в различных вариантах использования. Так, вы можете услышать, что любые контейнеры в модуле, кроме первого, называют «sidecars».
Сначала рассмотрим один из классических вариантов использования — log tailing sidecar.
В контейнерной среде рекомендуют всегда писать в стандартный вывод, чтобы собирать и агрегировать журналы логов централизованно. Но многие старые приложения разработаны для логирования в файлы, и изменить это иногда нетривиальная задача. Благодаря log tailing sidecar вам, возможно, не придется ничего менять!
Вернемся к примеру с Elasticsearch. Он немного надуманный, поскольку контейнер Elasticsearch по умолчанию ведет журнал в стандартном режиме, и нетривиально заставить его писать в файл.
Вот как выглядит деплой:
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
labels:
app.kubernetes.io/name: elasticsearch
spec:
selector:
matchLabels:
app.kubernetes.io/name: elasticsearch
template:
metadata:
labels:
app.kubernetes.io/name: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.9.3
env:
- name: discovery.type
value: single-node
- name: path.logs
value: /var/log/elasticsearch
volumeMounts:
- name: logs
mountPath: /var/log/elasticsearch
- name: logging-config
mountPath: /usr/share/elasticsearch/config/log4j2.properties
subPath: log4j2.properties
readOnly: true
ports:
- name: http
containerPort: 9200
- name: logs
image: alpine:3.12
command:
- tail
- -f
- /logs/docker-cluster_server.json
volumeMounts:
- name: logs
mountPath: /logs
readOnly: true
volumes:
- name: logging-config
configMap:
name: elasticsearch-logging
- name: logs
emptyDir: {}Примечание: Файл конфигурации ведения журнала логов — отдельный файл ConfigMap, он слишком большой, чтобы включать его сюда.
У обоих контейнеров есть общий том с именем logs. Контейнер Elasticsearch записывает журналы на этот том, а контейнер журналов логов — читает из соответствующего файла и выводит его в стандартный формат.
Вы можете получить поток журнала логов, указав нужный контейнер в kubectl logs:
$ kubectl logs elasticsearch-6f88d74475-jxdhl logs | head
{
"type": "server",
"timestamp": "2020-11-29T23:01:42,849Z",
"level": "INFO",
"component": "o.e.n.Node",
"cluster.name": "docker-cluster",
"node.name": "elasticsearch-6f88d74475-jxdhl",
"message": "version[7.9.3], pid[7], OS[Linux/5.4.0-52-generic/amd64], JVM"
}
{
"type": "server",
"timestamp": "2020-11-29T23:01:42,855Z",
"level": "INFO",
"component": "o.e.n.Node",
"cluster.name": "docker-cluster",
"node.name": "elasticsearch-6f88d74475-jxdhl",
"message": "JVM home [/usr/share/elasticsearch/jdk]"
}
{
"type": "server",
"timestamp": "2020-11-29T23:01:42,856Z",
"level": "INFO",
"component": "o.e.n.Node",
"cluster.name": "docker-cluster",
"node.name": "elasticsearch-6f88d74475-jxdhl",
"message": "JVM arguments [...]"
}Самое прекрасное в Sidecar: потоковая передача в стандартный вывод — не единственный вариант. Если нужно переключиться на настраиваемую службу агрегации журналов логов, то можно просто изменить контейнер Sidecar, ничего не меняя в приложении.
Другие примеры использования Sidecars
Есть множество вариантов использования Sidecars, контейнер логов — только один и довольно простой пример.
Вот еще несколько вариантов, которые могут вам пригодиться:
- Перезагрузка ConfigMaps в реальном времени без перезапуска модуля.
- Внедрение секретов из Hashicorp Vault в ваше приложение.
- Добавление локального экземпляра Redis в приложение для кэширования в памяти с малой задержкой.
Подготовка пода к запуску
Во всех примерах многоконтейнерных подов, которые мы рассмотрели выше, несколько контейнеров работают одновременно.
Еще в Kubernetes можно запускать контейнеры инициализации — контейнеры, которые выполняются и завершаются до запуска «обычных» контейнеров. Это позволяет запустить сценарий инициализации до того, как под запустится полностью.
Почему иногда нужно выполнять инициализацию в отдельном контейнере, а не, допустим, добавлять инициализацию в сценарий точки входа вашего контейнера?
Давайте посмотрим на примере Elasticsearch. В документации Elasticsearch рекомендуют устанавливать параметр sysctl vm.max_map_count в продакшен развертываниях. В контейнерных средах это проблематично — для sysctl нет изоляции на уровне контейнера, и любые изменения происходят на уровне узла.
Что делать с этим, если вы не можете настраивать узлы Kubernetes? Один из способов — запустить Elasticsearch в привилегированном контейнере. Это позволяет Elasticsearch изменять системные настройки на своем хост-узле и сценарий точки входа для добавления sysctl.
Но это чрезвычайно опасно с точки зрения безопасности! Если служба Elasticsearch будет скомпрометирована, то злоумышленник получил бы root-доступ к своему хост-узлу.
Чтобы снизить этот риск, можно использовать контейнер инициализации:
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
spec:
selector:
matchLabels:
app.kubernetes.io/name: elasticsearch
template:
metadata:
labels:
app.kubernetes.io/name: elasticsearch
spec:
initContainers:
- name: update-sysctl
image: alpine:3.12
command: ['/bin/sh']
args:
- -c
- |
sysctl -w vm.max_map_count=262144
securityContext:
privileged: true
containers:
- name: elasticsearch
image: elasticsearch:7.9.3
env:
- name: discovery.type
value: single-node
ports:
- name: http
containerPort: 9200Под устанавливает sysctl в привилегированном контейнере инициализации, после чего контейнер Elasticsearch запускается, как и ожидалось. Вы по-прежнему используете привилегированный контейнер, что не идеально. Но он, по крайней мере, маленький и работает недолго, так что поверхность атаки намного ниже.
Примечание: этот подход рекомендуют в Elastic Cloud Operator.
Использование привилегированного контейнера инициализации для подготовки узла к запуску пода — распространенный шаблон. Например, Istio использует контейнеры инициализации для настройки правил iptables при каждом запуске пода.
Еще одна причина использовать контейнер инициализации — подготовить файловую систему пода. Один из распространенных вариантов использования — управление секретами.
Еще варианты использования контейнера инициализации
Если для управления секретами вместо секретов Kubernetes вы используете что-то вроде HashicCorp Vault, то можете получить секреты в контейнере инициализации и сохранить их на общем томе emptyDir.
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
labels:
app.kubernetes.io/name: myapp
spec:
selector:
matchLabels:
app.kubernetes.io/name: myapp
template:
metadata:
labels:
app.kubernetes.io/name: myapp
spec:
initContainers:
- name: get-secret
image: vault
volumeMounts:
- name: secrets
mountPath: /secrets
command: ['/bin/sh']
args:
- -c
- |
vault read secret/my-secret > /secrets/my-secret
containers:
- name: myapp
image: myapp
volumeMounts:
- name: secrets
mountPath: /secrets
volumes:
- name: secrets
emptyDir: {}Теперь секрет secret/my-secret доступен в файловой системе для контейнера myapp.
Это основная идея того, как работают системы вроде инжектора Sidecar Vault Agent. Однако на практике они намного сложнее: комбинируют изменяющие веб-хуки, контейнеры инициализации и вспомогательные Sidecar.
Вот еще несколько причин использовать контейнер инициализации:
- Вы хотите, чтобы сценарий миграции базы данных запускался перед вашим приложением. Обычно это можно сделать в сценарии точки входа, но с помощью специального контейнера иногда проще.
- Вы хотите получить большой файл из S3 или GCS, от которого зависит ваше приложение. В данному случае контейнер инициализации помогает избежать раздувания контейнера вашего приложения.
Заключение
Мы рассмотрели много вариантов, так что вот таблица с шаблонами использования. В ней перечислены основные шаблоны и варианты их использования:
Обязательно прочтите официальную документацию и исходный документ с дизайном контейнеров, если хотите разобраться в теме.
| Вариант использования | Ambassador | Adapter | Sidecar | Init |
|---|---|---|---|---|
| Шифрование и/или аутентификация входящих запросов | ? | |||
| Подключение к внешним ресурсам через безопасный туннель | ? | |||
| Предоставление метрик в стандартизированном формате, например в Prometheus | ? | |||
| Потоковая передача логов из файла в агрегатор логов | ? | |||
| Добавление локального кэша Redis в свой под | ? | |||
| Мониторинг и перезагрузка ConfigMaps в реальном времени | ? | |||
| Вставка в приложение секретов из Vault | ? | ? | ||
| Изменение настроек уровня узла с помощью привилегированного контейнера | ? | |||
| Получение файлов из S3 до запуска приложения | ? |
Новым пользователям платформы мы дарим 3000 бонусов после полной верификации аккаунта. Вы сможете попробовать Kubernetes aaS или другие наши сервисы на реальных проектах.
Что еще почитать: