
Данные социальных сетей — неисчерпаемый источник исследовательских и бизнес-возможностей. На примере Вконтакте API и языка Python мы сегодня разберем пару практических примеров, которы помогут узнать:
- азы работы с библиотекой Python — networkx;
- как обращаться к Вконтакте API из языка Python посредством стандартных библиотек, в частности, получать список друзей и членов групп;
- некоторые возможности программы Gephi.
Disclaimer: данная статья не претендует на какую-либо новизну, а лишь преследует цель помочь интересующимся собраться с силами и начать претворять свои идеи в жизнь.
(волосяной шар для привлечения внимания)
И начнем сразу же с первой задачи: построить эгоцентричный граф друзей, удалив себя самого.
import requests
import networkx
import time
import collections
def get_friends_ids(user_id):
friends_url = 'https://api.vk.com/method/friends.get?user_id={}'
# также вы можете добавить access_token в запрос, получив его через OAuth 2.0
json_response = requests.get(friends_url.format(user_id)).json()
if json_response.get('error'):
print json_response.get('error')
return list()
return json_response[u'response']
graph = {}
friend_ids = get_friends_ids(1405906) # ваш user id, для которого вы хотите построить граф друзей.
for friend_id in friend_ids:
print 'Processing id: ', friend_id
graph[friend_id] = get_friends_ids(friend_id)
g = networkx.Graph(directed=False)
for i in graph:
g.add_node(i)
for j in graph[i]:
if i != j and i in friend_ids and j in friend_ids:
g.add_edge(i, j)
pos=networkx.graphviz_layout(g,prog="neato")
networkx.draw(g, pos, node_size=30, with_labels=False, width=0.2)
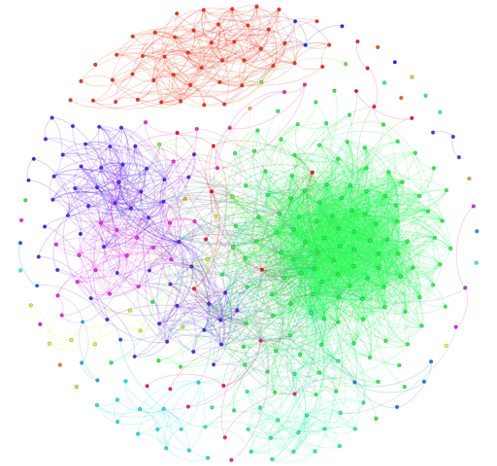
Результатом работы кода стал данный граф:
В моем случае глазами можно выделить 2 большие компоненты связанности: друзей из двух разных городов проживания.
Некоторые пользователи могут открыть ту или иную информацию только для зарегистрированных пользователей или для друзей, поэтому часть методов иногда могут требовать авторизации (передачи access токена). В таких случаях есть ограничение в виде лимитов на API. В документации VK указано, что для клиентского приложения лимит — 3rps, а для серверного приложения прогрессивная шкала в зависимости от числа установок приложения (rps/число установок): 5/<10000, 8/<100000, 20/<1000000. 35/>1000000.
Также в документации есть следующий абзац:
Помимо ограничений на частоту обращений, существуют и количественные ограничения на вызов однотипных методов. По понятным причинам, мы не предоставляем информацию о точных лимитах.
Так, к примеру, вызов метода поиска профиля users.search или метод просмотра стены пользователя wall.get при превышении некоторого лимита (но при не превышении документированных лимитов) начинает выдавать пустые результаты. Эта ситуация может породить ошибки: так, например, при поиске пользователей вы можете посчитать, что по данному поисковому запросу нет результатов, а на самом деле они отсутствуют.
Ниже приведен фрагмент кода, который поможет вам учитывать документированные лимиты, например 3 запроса в секунду.
deq = collections.deque(maxlen=4)
def trottling_request(url):
deq.appendleft(time.time())
if len(deq) == 4:
# 3 запроса в секунду, если нужно - подождем
time.sleep(max(1+deq[3]-deq[0], 0))
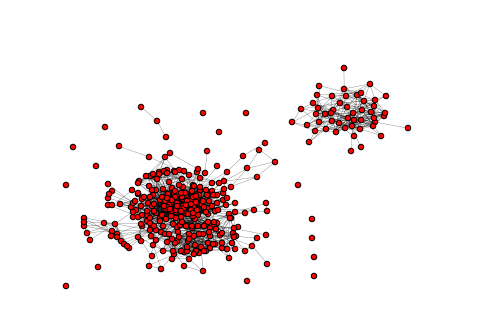
На этом же графе рассмотрим пример использования программы Gephi. Gephi — это программа с открытым исходным кодом для анализа и визуализации графов, написанная на Java, изначально разработаная студентами Технологического университета Компьеня во Франции. Gephi была выбрана для участия в Google Summer Code в 2009, 2010, 2011, 2012 и 2013 годах [wiki].
Для начала сохраним наш граф в формат .graphml — формат описания графов на основе XML.
networkx.write_graphml(g, 'graph.graphml')
Экспортировав, загрузим в Gephi и получим примерно такой результат:

Gephi имеет большую функциональность, которая расширяется с помощью множества плагинов. Ниже приведены примеры визуализации.
Центральность (PageRank centrality, Degree centrality, Eccentricity centrality). Разным цветом отмечены разные значения центральности.



Кластеризация (Modularity сlustering, Markov сlustering, Chinese Whispers сlustering). Разным цветом отмечены разные классы выбранные алгоритмом.


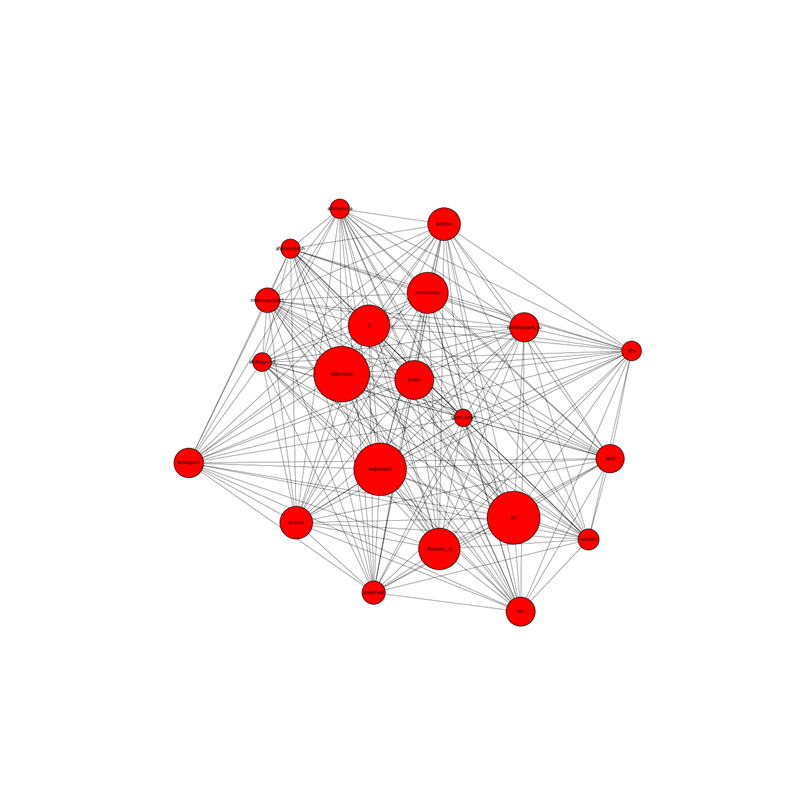
Последняя задача навеяна одной из лабораторных работ первого набора курса Специалист по Большим данным от New Professions Lab. На основе заведомо известного списка групп социальной сети Вконтакте необходимо построить граф:
- вершины — группы социальной сети;
- рёбра — наличие общих подписков;
- чем больше у данной группы подписчиков, тем больше размер вершины;
- чем больше у групп общих пописчиков, тем ближе друг к другу располагаются вершины.
В качестве примера групп будем рассматривать группы новостных изданий, при желании вы можете попробовать и другие группы.
%matplotlib inline
import networkx
import requests
import json
def getVKMembers(group_id, count=1000, offset=0):
# http://vk.com/dev/groups.getMembers
host = 'http://api.vk.com/method'
if count > 1000:
raise Exception('Bad params: max of count = 1000')
response = requests.get('{host}/groups.getMembers?group_id={group_id}&count={count}&offset={offset}'
.format(host=host, group_id=group_id, count=count, offset=offset))
if not response.ok:
raise Exception('Bad response code')
return response.json()
def allCountOffset(func, func_id):
set_members_id = set()
count_members = -1
offset = 0
while count_members != len(set_members_id): # posible endless loop for real vk api
response = func(func_id, offset=offset)['response']
if count_members != response['count']:
count_members = response['count']
new_members_id = response['users']
offset += len(new_members_id)
if set_members_id | set(new_members_id) == set_members_id != set(): # without new members
print 'WARNING: break loop', count_members, len(set_members_id)
break
set_members_id = set_members_id.union(new_members_id)
return set_members_id
groups = ['http://vk.com/meduzaproject',
'http://vk.com/tj',
'http://vk.com/smmrussia',
'http://vk.com/vedomosti',
'http://vk.com/kommersant_ru',
'http://vk.com/kfm',
'http://vk.com/oldlentach',
'http://vk.com/lentaru',
'http://vk.com/lentasport',
'http://vk.com/fastslon',
'http://vk.com/tvrain',
'http://vk.com/sport.tvrain',
'http://vk.com/silverrain',
'http://vk.com/afishagorod',
'http://vk.com/afishavozduh',
'http://vk.com/afishavolna',
'http://vk.com/1tv',
'http://vk.com/russiatv',
'http://vk.com/vesti',
'http://vk.com/ntv',
'http://vk.com/lifenews_ru']
members = {}
for g in groups:
name = g.split('http://vk.com/')[1]
print name
members[name] = allCountOffset(getVKMembers, name)
matrix = {}
for i in members:
for j in members:
if i != j:
matrix[i+j] = len(members[i] & members[j]) * 1.0/ min(len(members[i]), len(members[j]))
max_matrix = max(matrix.values())
min_matrix = min(matrix.values())
for i in matrix:
matrix[i] = (matrix[i] - min_matrix) / (max_matrix - min_matrix)
g = networkx.Graph(directed=False)
for i in members:
for j in members:
if i != j:
g.add_edge(i, j, weight=matrix[i+j])
members_count = {x:len(members[x]) for x in members}
max_value = max(members_count.values()) * 1.0
size = []
max_size = 900
min_size = 100
for node in g.nodes():
size.append(((members_count[node]/max_value)*max_size + min_size)*10)
import matplotlib.pyplot as plt
pos=networkx.spring_layout(g)
plt.figure(figsize=(20,20))
networkx.draw_networkx(g, pos, node_size=size, width=0.5, font_size=8)
plt.axis('off')
plt.show()
Результатом будет данный граф:
Конечно, представленные тут задачи лишь демонстрируют простоту и доступность работы с социальными сетями. На деле же приходится решать более сложные задачи. Так, к примеру, данные социального профиля могут обогатить данные DMP систем (возраст, интересы, социальная группа): главной задачей будет найти и поставить в соответствие пользователю DMP-системы его социальный профиль. Также появилось много стартапов, которые используют социальные сети как источник для создания резюме: amazinghiring, entelo, profiscope, gild и др. Главными задачами здесь будет: найти одного и того же пользователя в разных социальных сетях и на основе данных, полученных из социальных сетей, создать резюме пользователя, так как большинство социальных сетей, кроме, разве что, linkedin, не имеют достаточного количества подходящей для резюме информации.
Комментарии (9)

Zames
08.09.2015 11:48Есть ли примеры работающих надстроек, которые бы показывали демографию и географию тех, кто ушел из сообщества/отписался от новостей?
egorsmkv
Через 10 дней выходит версия 3.5, а код еще на второй?
altspam
Да хоть на PHP, какая разница ) Суть статьи не в этом.
extensionsapp
asm0dey
А зачем вы в конце тэг закрыли? Интерпретатор же сам его в конце файла закрывает вроде?
Pinsky
Это мог быть лишь участок страницы.
egorsmkv
Я сделал замечание по версии Python, а не по содержанию статьи.
Сейчас все курсы по Python строятся на третьей версии, а тут показывается вторая.
mukizu
Я таки сильно сомневаюсь, что похороны 2й версии запланированы на туже дату
Pinsky
Мне кажется, третьему пайтону нужно получить отдельное название.
Или что-то в духе Python++.
Не думаю, что, в принципе, второй Python будет замещен третьим, как C не замещен плюсами.