

Цель была довольно амбициозной — в идеале сделать такую штуку, которой на вход подается программа, а дальше она ее крутит так и сяк и пытается всячески ускорить отдельные ее фрагменты без участия человека, попутно собирая себе базу для последующих оптимизаций. Сразу скажу что хотя в целом задача была решена, практической пользы я из нее извлечь не смог. Однако некоторые полученные в процессе результаты показались мне достаточно интересными чтобы ими поделиться.
Например вот такая забавная оптимизация набора арифметических инструкций (взятых из какой-то подвернувшейся под руку математической библиотеки), соответствующих формулам:
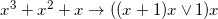 , которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.
, которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.Заняться я решил не абы какой оптимизацией, а так называемой «локальной» или peephole optimization. Это как правило последний этап через который прогоняют программы современные оптимизирующие компиляторы, и по сути он очень прост — они ищут заданные небольшие линейные последовательности инструкций и меняют их на другие, оптимальные с их точки зрения. То есть вот какая-нибудь пресловутая замена mov eax, 0 на xor eax eax — это вот как раз и есть локальная оптимизация. Самым интересным тут является то, каким именно образом эти правила замены строятся. Их могут составлять как вручную специально обученные и разбирающиеся в ассемблере люди, так и искать перебором наборов инструкций. Очевидно что первый вариант достаточно затратен (специально обученные люди наверняка захотят много денег) и малоэффективен (ну сколько таких наборов человек из головы сможет придумать и предусмотреть?), а второй — долог, особенно если пытаться перебирать длинные последовательности.
Вот тут на сцену и выходят генетические алгоритмы, позволяющие заметно сократить процесс перебора.
Про сами генетические алгоритмы я тут рассказывать не буду, надеюсь все хотя бы в общих чертах представляют что это такое, а кто не представляет — на хабре достаточно статей на эту тему, например вот. Остановлюсь только на том, как именно я их применял.
Достаточно очевидно, что особи в нашем случае — это фрагменты кода, операторы скрещивания и мутации должны каким-то образом модифицировать входящие в них инструкции, а фитнес-функция — отбирать наиболее быстрые варианты (так как оптимизировать мы будем именно скорость выполнения). Вот только как именно должно работать это самое скрещивание?
Скрещивание и мутация фрагментов кода
От идеи меняться произвольными фрагментами я отказался очень быстро. В этом случае очень велика вероятность получения невалидного кода — такого, который просто не получится запустить. В качестве своей целевой архитектуры я выбрал JVM (из-за простоты как самого байткода так и средств манипулирования им, хотя позже я уже понял что это было не самое удачное решение), а в ней достаточно строгий валидатор, который просто не даст загрузить кривой код (например вызывающий опустошение стека). Соответственно и значение фитнес-функции для него посчитать не выйдет.
Поэтому пришлось соорудить достаточно сложную систему, практически этакий мини-эмулятор JVM. Для каждой инструкции и каждой их последовательности определялись начальное и конечное состояние. Конкретные значения не вычислялись, определялись только типы операндов. То есть всегда можно было сказать сколько значений и каких типов снималось и клалось на стек в результате выполнения произвольного фрагмента кода. Затем на основе этой информации находился другой набор, которым можно заменить данный (в случае мутации он создавался случайно, в случае скрещивания — искался во второй особи), для сохранения корректности кода он должен был быть эквивалентен в плане обращения с состоянием JVM — то есть снимать со стека и класть обратно ровно то же количество и типы значений.
Это не относится к промежуточным вычислениям, то есть фрагмент внутри себя может делать со стеком что угодно, но после себя должен оставить ровно такое же состояние.
Пример:
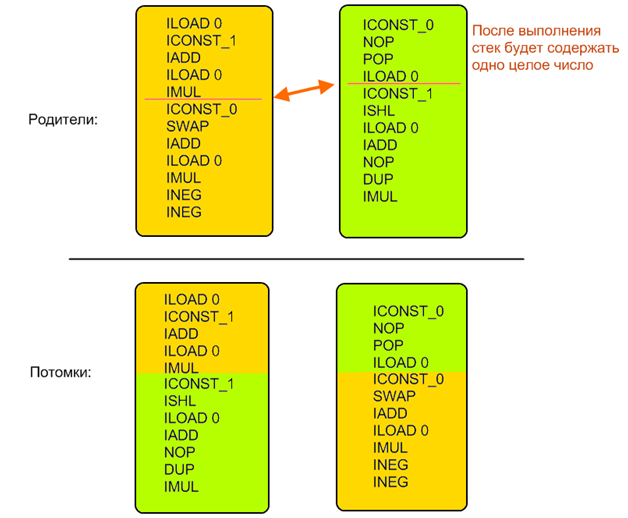
Начальное поколение создавалось по этим же правилам — оно должно было изменять состояние JVM таким же образом как и исходная последовательность инструкций. Таким образом всегда поддерживалась корректность особей и их сравнимость: поскольку все особи после своей работы всегда оставляли одинаковое состояние (значения одних и тех же типов на стеке в одном и том же порядке) то легко было сравнивать похожесть получаемых результатов с референсными: достаточно было просто посчитать разность двух многомерных векторов, в которых каждое значение — это один регистр или элемент стека (я тут периодически использую как джавовскую так и не-джавовскую терминологию так как в принципе алгоритм применим к любому виду вычислительной машины, и я сам его проверял на нескольких целях).
Фитнес-функция
Что же нам нужно от наших особей? А нужно нам чтобы они во-первых считали те же самые результаты, а во-вторых — делали это быстрее исходной. А чтобы это проверить — нам их надо запустить.
У нас уже есть посчитанные состояния VM на каждом шаге выполнения наших особей. В частности это дает нам необходимый набор входных данных — то есть то, какие регистры надо заполнить и сколько и каких элементов на стек положить чтобы все сработало как надо. Отлично, дописываем к началу каждой особи один и тот же код, который будет эти данные создавать, а к концу — который будет записывать результаты куда нам надо. Итоговое значение фитнес-функции составим из расстояния между векторами результатов и коэффициента ускорения по сравнению с оригиналом.
По ходу исследований выяснилось, что «лобовая» реализация приводит к быстрому вырождению популяции, которая забивается очень короткими (и очень быстрыми) особями, которые не делают ничего полезного (то есть вместо вычислений, например, просто опустошают стек до нужной глубины) но при этом выигрывают за счет длины и скорости. Поэтому пришлось сделать так, что скорость начинает учитываться только после того, как вычисленные результаты становятся достаточно близкими к референсным.
Помимо скорости работы и эквивалентности результатов оказалось необходимым дополнительно контролировать длину особей. Без такого контроля в популяции достаточно быстро (примерно за 50 поколений) начинается рост средней длины особи, вплоть до 10-20 длин исходного фрагмента кода. Появление таких длинных особей сильно замедляет генетический процесс, так как во-первых увеличивается время анализа кода, необходимого для проверок корректности (растет время каждой итерации), а во-вторых для получения решения необходимо избавиться от большого числа ненужных инструкций в особи, что может занимать значительное число поколений (растет общее число итераций).
Поскольку в данной работе исследуется оптимизация скорости выполнения, а не размера набора инструкций, коэффициент длины используется только для отсева слишком длинных кандидатов и применяется к формуле только если особь, для которой вычисляется фитнес-функция, длиннее исходной.
Итоговый вид фитнес-функции:
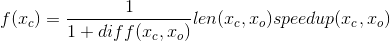
Здесь Xc — тестируемая особь, Xo — оригинальный фрагмент, diff — разность векторов результатов, len — отношение длинн, speedup — отношение времени выполнения.
speedup приравнивается к единице если diff больше некоторой константы, то есть скорость начинает учитываться только для считающей почти правильные значения особи.
Нетрудно убедиться что данная функция обладает следующими свойствами:
- Она близка к нулю для начальных случайных фрагментов кода (велика разница результатов)
- Она приближается к единице по мере схождения вычисляемых результатов с референсными
- Она равна единице для исходного фрагмента
- Все варианты с фитнес-функцией большей единицы — потенциальные результаты работы нашего алгоритма, это те особи которые считают что надо и при этом быстрее/короче
Верификация
По ходу работы алгоритма каждая особь проверялась на соответствие результатов тем, что давал исходный фрагмент на нескольких десятках тестовых примеров. Это быстрая и достаточно эффективная проверка, но она явно недостаточна для строгого доказательства эквивалентности полученной оптимизированной последовательности и исходной. Чтобы такое доказательство получить использовалась формальная верификация.
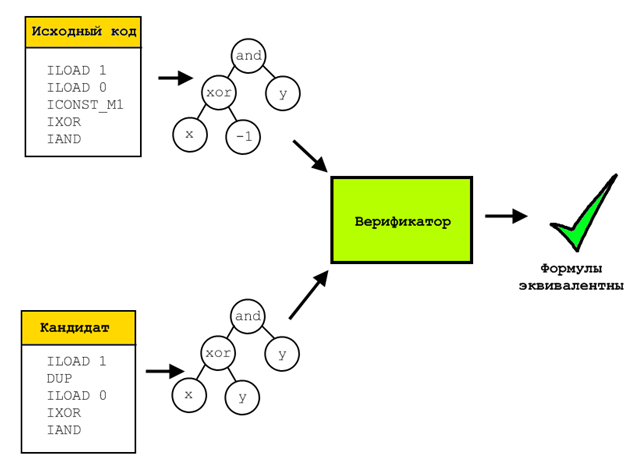
Для этого для верифицируемой и исходной особей все их операции представлялись в символьном виде, то есть после прогона через специальный эмулятор в каждом регистре/ячейке стека лежало символьное представление вычисленной и записанной в него формулы. Затем все эти формулы сравнивались с помощью решателя SMT-выражений Z3. Такой решатель способен доказать, что не существует набора входных параметров, на которых две проверяемые формулы дадут разный результат. Если же такой набор существует, то он будет построен и предъявлен.
Поскольку верификация эта достаточно длительный процесс (могла занимать десятки минут для одной особи и пары простейших математических выражений) то подвергались ей только кандидаты в окончательное решение, то есть особи с фитнес-функцией большей 1.
Впрочем стоит отметить что в ходе исследований не встретился ни один кандидат, который бы вычислял все правильно на тестовых наборах данных но отсеивался бы на этапе верификации.
Примеры
Генетические алгоритмы, как и любая наверное отрасль машинного обучения — удивительная вещь, периодически заставляющая программиста хвататься за голову и кричать «как, как он это сделал?». Пикантности тут добавляло то, что в моем случае с моей помощью компьютер фактически улучшает сам свои программы каким-то неведомым образом, придумывая такие штуки до которых я сам сходу додуматься бы не смог.
В общем я иногда ощущал себя героем этого и подобных комиксов:

Ну вот мы прогнали наших особей через скрещивания и эмуляции, проверифицировали эквивалентность результатов и что же мы получили? Приведу пару примеров найденных мной оптимизаций.
Сворачивание констант и прочие стандартные штуки
Во-первых алгоритм достаточно хорошо находит всякие стандартные вещи на синтетических тестах, типа удаления неиспользуемых вычислений или свертывания констант, хотя под это специально я его не затачивал. Например довольно быстро он понял что x + 1 — 2 можно сократить до x — 1:
Было:
ILOAD 0
ICONST_1
IADD
ICONST_2
ICONST_M1
IMUL
IADD
Стало:
ILOAD 0
ICONST_1
ISUB
Все остальные примеры взяты из реального кода, была написана специальная тулза которая парсила скомпилированные классы и искала в них подходящие последовательности для оптимизации (то есть не содержащие ветвлений и неподдерживаемых инструкций).
Упрощение математических выражений и вынесение за скобки
Пример из начала статьи сократился с 11 до 9 инструкций:
. На первый взгляд выражение вообще неправильное, и получив его я бросился искать ошибку в коде эмулятора. Ан нет, все верно, так как выражение (x + 1)x всегда четное и неотрицательное, то есть младший бит у него всегда ноль, а в таком случае сложение с единицей эквивалентно xor с ней же, а работает видимо на какие-то доли быстрее. Правда только в отсутствии JIT, если его включить то на первое место выходит вполне ожидаемое ((x + 1)x + 1)x. Уж не знаю почему вариант с OR (или с XOR) работал быстрее, но этот результат был регулярно воспроизводим, в том числе на разных версиях джавы и на разных компьютерахВообще JIT в случае с джавой принес очень много головной боли, и я даже пожалел что выбрал эту платформу. Никогда нельзя было быть уверенным на все сто, это твоя оптимизация увеличила скорость, или это чертова джава-машина внутри себя что-то там провернула. Я конечно изучил всякие полезны статьи типа Анатомия некорректных микротестов оценки производительности, но все равно намучался с ней изрядно. Очень раздражало последовательное улучшение кода, зависящее от числа запусков. Запустил фрагмент сто раз — он работает в режиме интерпретатора и дает один результат, запустил тысячу — включился JIT, перевел в нативный код но особо не оптимизировал, запустил десять тысяч — JIT принялся что-то ковырять в этом нативном коде, в итоге скорости выполнения меняются на порядки и все это приходится учитывать.
Логические операторы
Впрочем кое-где мне даже JIT удалось обскакать. Например выражение (x XOR -1)AND y Достаточно очевидной оптимизацией для него будет !x and y, и это именно то что сгенерирует для него вам компилятор С++. Но в байткоде джавы нет операции побитового однооперандного не, так что оптимальным вариантом здесь будет (x XOR y) AND y. При этом JIT до такого уже не додумывается (проверялось включением дебажного вывода на server JVM 1.6), что позволяет немного выиграть по скорости.
Хитрая особенность сдвига влево
Был еще один забавный результат с оператором сдвига. Где-то в недрах BigInteger было найдено выражение 1 << (x & 31), оптимизированной версией которого алгоритм выдал 1 << x.
Опять хватание за голову, опять поиски бага — очевидно ведь что алгоритм взял и выкинул целый значимый кусок кода. Пока я не додумался повнимательнее перечитать спецификацию операторов, в частности оказалось что оператор << использует только 5 младших бит своего второго операнда. Поэтому явный &31 в общем-то не нужен, оператор сделает это за тебя (я так понял что в байткоде библиотечных классов принудительный & оставлен для совместимости со старыми версиями, так как эта фишка появилась не в самой первой джаве).
Проблемы и заключение
Получив свои результаты я начал думать что с ними делать дальше. И вот тут как раз ничего и не придумалось. Оптимизации мои в случае с джавой слишком малы и незаметны чтобы оказать существенное влияние на скорость работы программы в целом, во всяком случае для тех программ на которых я мог все это тестировать (может какие-нибудь глубоконаучные вычисления и выиграют заметно от замещения пары инстркций и сокращения времени одного такта на пару наносекунд). К тому же эффект значительно съедается самой структурой джава-машины, виртуальностью и JIT.
Я попробовал перейти на другие архитектуры. Сперва на x86, получил первую работающую версию, но ассемблер там слишком сложный и написать требующийся для его верификации код оказалось мне не под силу. Затем я попробовал ткнуться в сторону шейдеров, благо работал тогда в геймдеве, и добавил поддержку для пиксельного шейдерного ассемблера. Но там я просто не смог найти ни одного подходящего шейдера, содержащего хороший пример последовательности инструкций.
В общем так и не придумал куда это дело прикрутить. Хотя ощущение от того, когда компьютер оказывается умнее тебя и находит такую оптимизаци, которую ты даже не сразу сам можешь понять как она работает, я запомнил надолго.
Комментарии (34)

middle
04.09.2015 14:11+1> оператор << использует только 5 младших бит своего первого операнда
Эээ… Второго?
JediPhilosopher
04.09.2015 14:33+2Да, действительно, перепутал порядок, так как со стека они в обратном порядке достаются. Исправил, спасибо.

Pavel_Osipov
04.09.2015 14:51+1В принципе это всё более-менее основы Генетического программирования, странно что Вы в статье не упоминали этого.
И да, в этой тематике как раз есть где развернуться при написании диплома
meldo
04.09.2015 15:41Возможно будет полезно для какого-нибудь из существующих супероптимизаторов.
en.wikipedia.org/wiki/SuperoptimizationJediPhilosopher
04.09.2015 16:47Не совсем. Они там ищут совсем-совсем оптимальные последовательности, как я понял. Генетика же, как и любой вероятностный метод, строго говоря не гарантирует оптимальность решения. Можно найти что-то что будет лучше оригинала, но будет ли оно наилучшим вообще — совершенно не факт.

ClusterM
04.09.2015 15:56Мне для программирования под NES и ромхакинга наверное очень пригодилось бы. Ассемблер у 6502 процессора очень простой, а скорость работы очень важна. Иногда игры начинают глючить из-за добавления всего нескольких инструкций — не успевают выполняться. Например, из-за этого у меня не получается портировать принца Персии на MMC3 маппер.
michael_vostrikov
04.09.2015 18:31Мне как-то пришла в голову похожая, но немного другая мысль. Написание кода автоматически с помощью перебора вариантов. Например, задаем для функции вход и выход, как в юнит-тестах. Объявленные классы, методы, переменные, и операторы языка — единицы перебора. После завершения перебора выбираем наиболее подходящий вариант. В принципе, это возможно, только наверно много времени будет занимать.
JediPhilosopher
04.09.2015 18:54Ну в каком-то смысле это похоже на мою идею. Но с функциями общего вида есть свои проблемы, например проблема останова — невозможно определить, она вообще завершится когда-нибудь или просто зависла, непонятно как это верифицировать, в случае с ветвлениями — нет гарантий что мимо всех тестов не просочилась какая-нибудь хитрая ветка условий, нарушающих спецификацию.
У меня в этом смысле более простой вариант, так как локальная оптимизация не имеет дела с ветвлениями и условиями, только линейный код.

Ant0ha
04.09.2015 21:02+3Прекратите копать в эту сторону! Сами себя без работы оставите!

mapron
05.09.2015 09:50+1Вы молодые, шутливые вам все легко. Это не то. Не чикатило и не архивы спецслужб :D
А вообще я думаю, вряд ли такая опимизация способна оставить без работы программиста. Вряд ли она способна соптимизировать сортировку пузырьком до сортировки Шелла, либо сделать более читаемый и менее связный код.
Тем более уже вариантов для нескольких сотен инструкций будет столько, что не одна машина до конца жизни Вселенной с перебором не справится.Ant0ha
29.09.2015 18:18Многое казалось невозможным, пока не стали работать над этим.

KvanTTT
29.09.2015 23:29Для того, чтобы делать высокоуровневые оптимизации, нужен всеобъемлющий ИИ. Многие над этим работают, у некоторых, скорее всего, есть неплохой прогресс. Но все равно это не стало мейнстримом пока что.

Godless
04.09.2015 23:41напишите плагин для OllyDbg чтоб в памяти инструкции парсил и патчил скажем до ret или jmp/jxx например. или даже не патчил, а показывал до чего можно упростить…
будет большой плюсег в карму и стопицот к ЧСВ ;-)JediPhilosopher
05.09.2015 00:48x86 архитектуру я толком не смог осилить. Реализовал только несколько простейших инструкций и застрял — слишком сложные как инструкции, так и общее состояние процессора (куча регистров, стек, память — все это надо отслеживать для поддержания корректности особей).

dprotopopov
05.09.2015 10:51А Вы как нибудь данные идеи в какой-нибудь более-менее стабильный продукт оформляли?
Посмотреть бы коды.
Может синтаксис какой изобрели удобный для описания задач?
С удовольствием парочку интересных идей украл бы.JediPhilosopher
05.09.2015 14:26Есть репозиторий на битбакете.
bitbucket.org/e_smirnov/gp_optimizer
Например чтобы запустить оптимизацию джавовского примера из статьи надо написать что-то типа:
GPOptimizer jvmOptimizer = new GPOptimizer(new JavaTargetArchitecture()); InstructionSequence sequence = new InstructionSequence(); sequence.add(new JVMInstruction(JavaOpcodes.ICONST_M1)); sequence.add(new JVMInstruction(JavaOpcodes.IXOR)); sequence.add(new JVMInstruction(JavaOpcodes.ILOAD, new LocalVariableSlot(10))); sequence.add(new JVMInstruction(JavaOpcodes.IAND)); InstructionSequence rz = jvmOptimizer.optimize(sequence, 550);
После выполнения данного кода rz будет содержать наилучший из найденных и прошедших верификацию результатов.
Есть бекенды для JVM, x86 (там очень маленький набор поддержанных инструкций) и пиксельных шейдеров. Примеры использования можно увидеть в main.java
Для работы нужен верификатор Z3 майкрософтовский
Для оптимизации шейдеров — консольная тулза NvShaderPerf которая считает их производительность.
Помимо такого вида запуска я там даже запилил целый сервер, который с помощью библиотечки распределенных вычислений JPPF может принимать и раскидывать задачи оптимизации по вычисляющим серверам. И клиент, который парсит заданные jar-файлы, ищет в них подходящие последовательности инструкций и шлет их на сервер, ждет ответа а потом если пришел ответ с найденными оптимизациями — патчит джарники оптимизированными инструкциями. Можно эту инфраструктуру всю попробовать поднять (JPPF там правда старый какой-то типа 2 версии).
Правда, как я уже писал, глазами результатов ее работы увы не видно. Слишком маленькие оптимизации. Поэтому я и забросил это дело, слегка в нем разочаровавшись.dprotopopov
05.09.2015 15:02Спасибо
Обязательно повнимательней посмотрю — эта тема мне тоже интереснаdprotopopov
05.09.2015 15:09Да и в случае любой оптимизации кода — как пел Дуремар в фильме Буратино — я готов унизится, чтоб потом возвысится.
А вы не пробовали делать алгоритм, но который не только старается всё улучшить, но и ухудшить. только вероятность улучшения больше вероятности ухудшения. и погонять.
средний шаг всё равно остаётся положительным, а вот итоговые результаты лучше должны быть.
и проанализировать зависимость от разности.JediPhilosopher
05.09.2015 15:47Ухудшение скорости? Увы, если не предпринимать особых мер то это приведет к быстрому заполнению популяции очень длинными особями. Они будут считать то же самое, но медленнее, при этом за счет своей длины будут очень сильно тормозить сам генетический процесс. Средняя длина особи без ограничений начинает расти очень быстро, для исходной особи в 10 инструкций через сотню поколений средняя длина особи в популяции может превысить 50 инструкций. И все становится до невозможности медленным.
KvanTTT
05.09.2015 12:22В свое время тоже занимался оптимизациями на уровне VM только под .NET. Только у меня было без генетических алгоритмов, а просто был перебор. Хотя вся обработка в основном проводилась на более высоком уровне: Математические выражения в .NET.
dprotopopov
05.09.2015 14:01Я могу Вас успокоить — задача оптимизации произвольного взятого выражения является задачей равной сложности полного перебора.
Доказательство этого факта просто и очевидно.
Рассмотрим произвольную булеву функцию нескольких переменных.
Оценка сложности приведения этой булевой функции к дистрибутивной минимальной форме равна сложности полного перебора — это доказываться ещё на первом курсе института. Таким образом…JediPhilosopher
05.09.2015 14:12Это если мы ищем самую-самую оптимальную (тавтология, но как мне кажется более понятное определение) последовательность инструкций. Этим занимаются так называемые Супероптимизаторы, о которых выше в комментах уже писали.
Но для прикладных задач нам достаточно найти просто какой-нибудь вариант который будет быстрее исходного. Будет ли он наилучшим вообще или просто «более хорошим» — нас любой вариант устроит. И вот тут генетика дает как раз невероятное преимущество перед перебором.
Процесс у меня обычно сходился за ~200 поколений по 100 особей, то есть всего за 20к исполнений кода. А всего же возможных его вариантов (если рассматривать пример из начала статьи — последовательность из 11 инструкций, пара десятков возможных разных инструкций) — миллиарды раз надо запустить будет сгенерированные фрагменты.
Поэтому например во всех статьях о супероптимизации рассматриваются обычно последовательности не более 3-4 инструкций длиной. Генетика же, как показано тут, отлично справляется с 10+ инструкциями. Можно бы даже еще длиннее, но тут уже сложно искать подходящие кандидаты для проверки. Синтетические тесты не очень интересны, а в реальных приложениях я своим кравлером не смог найти последовательностей длиннее, они всегда прерывались ветвлениями всякими.
KvanTTT
05.09.2015 16:27Ну никто не спорит, что это задача полного перебора. У меня конечно же тоже был не полный перебор, а алгоритм был простой (насколько я помню): если после раскрытия скобок слагаемых/множителей стало меньше, то раскрываем скобки. В противном случае оставляем все как есть. Генетические алгоритмы и другие методы, основанные на случайном переборе, конечно же, тоже можно использовать. Но добиться оптимальных по скорости и качеству результатов, скорее всего, можно с помощью комбинирования «умных» методов и случайности.
dprotopopov
05.09.2015 16:31Вы абсолютно правы
с помощью комбинирования «умных» методов и случайности
собственно что такое эволюция по дарвину?KvanTTT
05.09.2015 16:54В эволюции на мой взгляд как раз таки умных методов (влияния извне) не было в самом начале (если учитывать, что бога нет), просто эволюция проходила очень продолжительное время, за которое была создана жизнь в текущем ее состоянии (и не без большого количества косяков, кстати).
Однако в течении эволюции «умные» методы (естественный отбор) сформировались самостоятельно.
dprotopopov
05.09.2015 14:27Оценка сложности приведения этой булевой функции к дистрибутивной минимальной форме равна сложности полного перебора — это доказываться ещё на первом курсе института.
С удовольствием парочку интересных идей украл бы.
Вы абсолютно правы

ENargit
06.09.2015 01:04Не смог прочитать формулы в статье. Везде вместо них картинки Codecogs Equation Quota Exceeded. В принципе, и без них статья весьма интересная, но лучше исправьте, пожалуйста
JediPhilosopher
06.09.2015 01:45Исправил. Печально что на хабре нет встроенной возможности вставлять формулы, конвертировать их в картинки вручную как-то очень мучительно, а посторонние сервисы вот не выдерживают хабраэффекта.

Sykoku
07.09.2015 15:06(x + 1)x всегда четное и неотрицательное
Только если х целое. При |х|<1 это не выполняется. Пример: -0.5JediPhilosopher
07.09.2015 17:17Да, это так, но рассматриваемый пример оперировал именно целыми числами и соответствующими инструкциями. А логические побитовые операции с вещественными числами обычно не встречаются, так что я не стал отдельно это упоминать.
zelyony
можно сунуться в LLVM Passes
http://llvm.org/docs/WritingAnLLVMPass.html
нет хардварного ассемблера, а есть достаточно простой LLVM IR (а уж JIT сама его преобразует в машинный код для конкретных архитектур)
в любом случае проект достаточно большой и известный, и он в сфере ваших наработок
JediPhilosopher
Спасибо за идею. Про LLVM я уже думал, но изначально решил взяться за то что мне более знакомо (диплом же, сроки горят как всегда, хотя начал я его писать практически с начала магистратуры), в итоге слегка обломался.
Хотя конечно любой лишний уровень абстракции и промежуточных представлений кода вносит свои проблемы и непредсказуемость поведения.
meldo
Можно сунуться и в LLVM MachinePasses. Если по ссылке указан способ написания прохода уровня «платформо-независимого» оптимизатора (LLVM opt), то MachinePasses — это уже уровень кодогенерации и соответственно целевой платформы (LLVM llc). Может быть, в итоге можно будет улучшить что-то в Instruction Selection.