

«УРАЛХИМ» делает удобрения. № 1 в России — по производству аммиачной селитры, например, входит в топ-3 отечественных производителей аммиака, карбамида, азотных удобрений. Выпускаются серные кислоты, двух-трёхкомпонентные удобрения, фосфаты и многое другое. Это всё создаёт агрессивные среды, в которых выходят из строя датчики.
Мы строили Data Lake и заодно охотились на те датчики, которые замерзают, выходят из строя, начинают давать ложные данные и вообще ведут себя не так, как должны себя вести источники информации. А «фишка» в том, что невозможно строить матмодели и цифровые двойники на базе «плохих» данных: они просто не будут правильно решать задачу и давать бизнес-эффект.
Но современным производствам нужны Data Lake'и для дата-сайентистов. В 95 % случаев «сырые» данные никак не собираются, а учитываются только агрегаты в АСУТП, которые хранятся два месяца и сохраняются точки «изменения динамики» показателя, которые вычисляются специально заложенным алгоритмом, что для дата-сайентистов снижает качество данных, т. к., возможно, может пропустить «всплески» показателя… Собственно, примерно так и было на «УРАЛХИМЕ». Нужно было создать хранилище производственных данных, подцепиться к источникам в цехах и в MES/ERP-системах. В первую очередь это нужно для того, чтобы начать собирать историю для дата-сайенса. Во вторую очередь — чтобы дата-сайентисты имели площадку для своих расчётов и песочницу для проверки гипотез, а не нагружали ту же самую, где крутится АСУ ТП. Дата-сайентисты пробовали сделать анализ имеющихся данных, но этого не хватило. Данные хранились прореженные, с потерями, часто неконсистентные с датчиком. Взять датасет быстро не было возможности, и работать с ним тоже было особо негде.
Теперь вернёмся к тому, что делать, если датчик «гонит».
Когда ты строишь озеро
Мало просто построить что-то подобное:
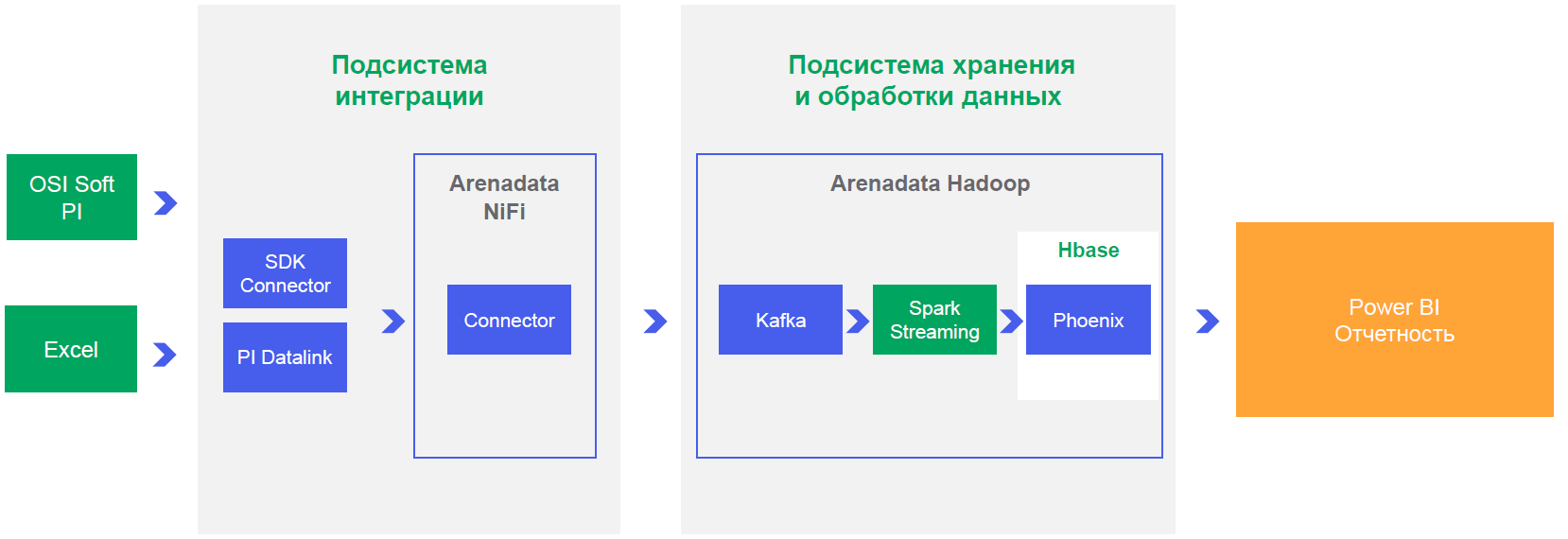
Нужно ещё доказать бизнесу, что это всё работает, и показать пример одного законченного проекта. Понятно, что делать один проект на таком комбайне, — это примерно как строить коммунизм в отдельно взятой стране, но условия именно таковы. Берём микроскоп и доказываем, что им можно забить гвоздь.
Глобально у «УРАЛХИМА» стоит задача провести цифровизацию производства. В рамках всего этого действа в первую очередь сделать песочницу для проверки гипотез, повысить эффективность производственного процесса, а также разработать предиктивные модели отказов оборудования, системы поддержки принятия решения и тем самым снизить количество простоев и повысить качество производственных процессов. Это когда вы заранее знаете, что что-то готово выйти из строя, и можете отремонтировать его за неделю до того, как станок начнёт разносить всё вокруг. Выгода — в снижении затрат на выпуск продукции и повышении качества продукции.
Так появились критерии для платформы и основные требования к пилоту: хранение большого объёма информации, оперативный доступ к данным из систем бизнес-аналитики, расчёты близко к реальному времени, чтобы выдавать как можно быстрее рекомендации или нотификации.
Проработали варианты интеграции и поняли, что для быстродействия и работы в режиме NRT необходимо работать только через свой коннектор, который будет складывать данные в Kafka (горизонтально масштабируемый брокер сообщений, который как раз и позволяет «подписываться на событие» изменения показания датчика, и на основе этого события на лету делать расчёты и формировать нотификации). К слову, во многом нам помог Артур Хисматуллин, руководитель отдела развития производственных систем, филиал «ОЦО» АО «ОХК «УРАЛХИМ».
Что нужно, чтобы, например, сделать предиктивную модель выхода оборудования из строя?
Для этого нужна телеметрия с каждого узла в реальном времени или в нарезке, близкой к нему. То есть не раз в час общий статус, а прямо конкретные показания всех датчиков за каждую секунду.
Эти данные никто не собирает и не хранит. Более того, нам нужны исторические данные хотя бы за полгода, а в АСУТП, как я уже говорил, они хранятся максимум последние три месяца. То есть нужно начать с того, что данные будут откуда-то собираться, куда-то писаться и где-то храниться. Данных примерно по 10 Гб на узел в год.
Дальше с этими данными нужно будет как-то работать. Для этого нужна инсталляция, которая позволяет нормально делать выборки из базы данных. И желательно так, чтобы на сложных join'ах всё не вставало на сутки. Особенно позже, когда производство начнёт докручивать туда ещё задачи предсказания брака. Ну и для предиктивных ремонтов тоже вечерний отчёт о том, что станок, возможно, сломается, когда он сломался полчаса назад — так себе кейс.
В итоге озеро нужно для дата-сайентистов.
В отличие от других подобных решений у нас ещё стояла задача реалтайма на Hadoop. Потому что следующие большие задачи — данные о матсоставе, анализ качества веществ, материалоёмкость производства.
Собственно, когда мы построили саму платформу, следующее, чего бизнес от нас захотел, — это чтобы мы собрали данные по выходу датчиков из строя и построили такую систему, которая позволяет отправлять рабочих их менять или обслуживать. И заодно отмечает показания с них как ошибочные в истории.
Датчики
На производстве — агрессивная среда, датчики работают сложно и достаточно часто выходят из строя. В идеале нужна система предиктивного мониторинга ещё и датчиков, но для начала — хотя бы оценки того, какие врут, а какие — нет.
Оказалось, что даже простая модель определения, что там с датчиком, критична ещё для одной задачи — построения матбаланса. Правильное планирование процесса — сколько и чего нужно положить, как греть, как обрабатывать: если спланировать неверно, то непонятно, сколько нужно сырья. Будет произведено недостаточно продукции — предприятие не получит прибыли. Если больше нужного — опять убыток, потому что надо хранить. Правильный матбаланс можно получить только с правильной информации с датчиков.
Итак, в рамках нашего пилотного проекта был выбран мониторинг качества производственных данных.
Сели с технологами за «сырые» данные, посмотрели подтверждённые выходы из строя оборудования. Первые две причины очень простые.
Вот датчик неожиданно начинает показывать данные, которых в принципе не должно быть:
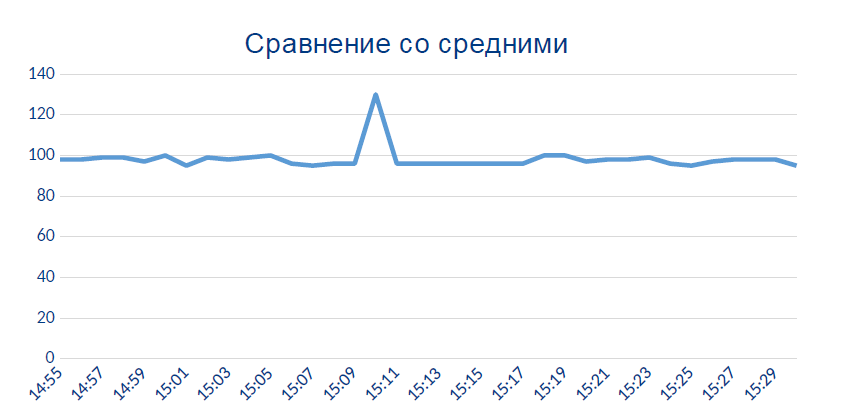
Скорее всего, этот локальный пик — момент, когда датчику стало термически или химически плохо.
Ещё бывает выход за допустимые границы измерения (когда есть физическая величина вроде температуры воды от 0 до 100). При нуле вода не двигается по системе, а при 200 — это пар, и мы бы заметили этот факт по отсутствию крыши над цехом.
Второй случай — тоже почти тривиальный:
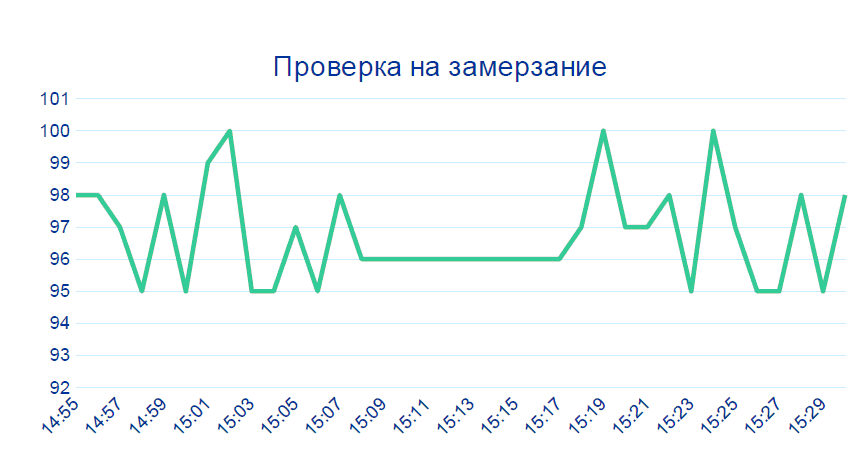
Данные с датчика не меняются несколько минут подряд — так на живом производстве не бывает. Скорее всего, что-то с устройством.
80 % проблем закрывается отслеживанием этих закономерностей без каких-либо Big Data, корреляций и истории данных. Но для точности выше 99 % нужно добавить ещё сравнение с другими датчиками на соседних узлах, в частности, до и после участка, откуда идёт сомнительная телеметрия:
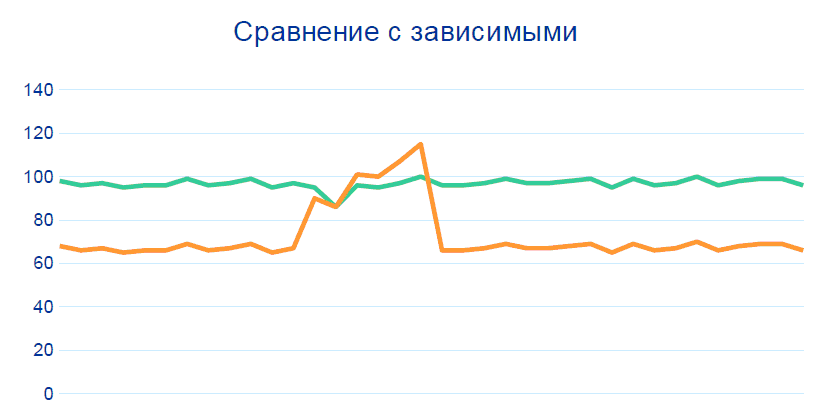
Производство — сбалансированная система: если один показатель меняется, то другой тоже должен поменяться. В рамках проекта были сформированы правила по взаимосвязи показателей, и эти взаимосвязи были «пронормированы» технологами. На основе этих нормативов система на базе Hadoop может выявлять потенциально неработающие датчики.
Операторы установок были рады, что датчики выявляются верно, так как это значило, что можно быстро отправить ремонтника или просто очистить нужный датчик.
Собственно, пилот кончился тем, что мы перечислили потенциально неработающие датчики в цеху, которые показывают некорректную информацию.
Возможно, вы спросите, как же до этого была реализована реакция на аварийные и предаварийные состояния и как стало после проекта. Отвечу, что на аварию реакция не замедляется, потому что при такой ситуации показывают проблему сразу несколько датчиков.
За эффективность работы установки (и действия при авариях) отвечают или технолог, или руководитель отделения. Они прекрасно понимают, что и как происходит с их техникой, и умеют игнорировать часть датчиков. За качество же данных отвечают АСУ ТП, которые сопровождают работу установки. В обычной ситуации, когда датчик повреждается, он не переводится в режим нерабочего. Для технолога он остаётся рабочим, технолог должен реагировать. Технолог проверяет событие и узнаёт, что ничего не произошло. Выглядит это так: «Анализируем только динамику, на абсолют не смотрим, знаем, что они некорректные, надо регулировать датчик». Мы «подсвечиваем» специалистам АСУ ТП, что датчик ошибается и где он ошибается. Теперь он вместо планового формального обхода сначала адресно ремонтирует конкретные устройства, а потом уже делает обходы, не доверяя технике.
Чтобы было понятнее, сколько времени занимает плановый обход, просто скажу, что на каждой из площадок — от трёх до пяти тысяч датчиков. Мы же дали комплексный инструмент аналитики, который даёт обработанные данные, на основе которых спецу нужно принять решение о проверке. На основе его опыта мы «подсвечиваем» именно то, что необходимо. Больше не нужно вручную проверять каждый датчик, да и вероятность того, что что-нибудь будет упущено, снижается.
Что в итоге
Получили бизнесовое подтверждение, что стек может быть использован для решения производственных задач. Храним и обрабатываем данные площадки. Бизнес теперь должен выбрать следующие процессы для работы дата-сайентистов. Пока они назначают ответственного за контроль качества данных, пишут для него регламент и внедряют это в свой производственный процесс.
Так мы реализовывали этот кейс:
Дашборды выглядят примерно так:
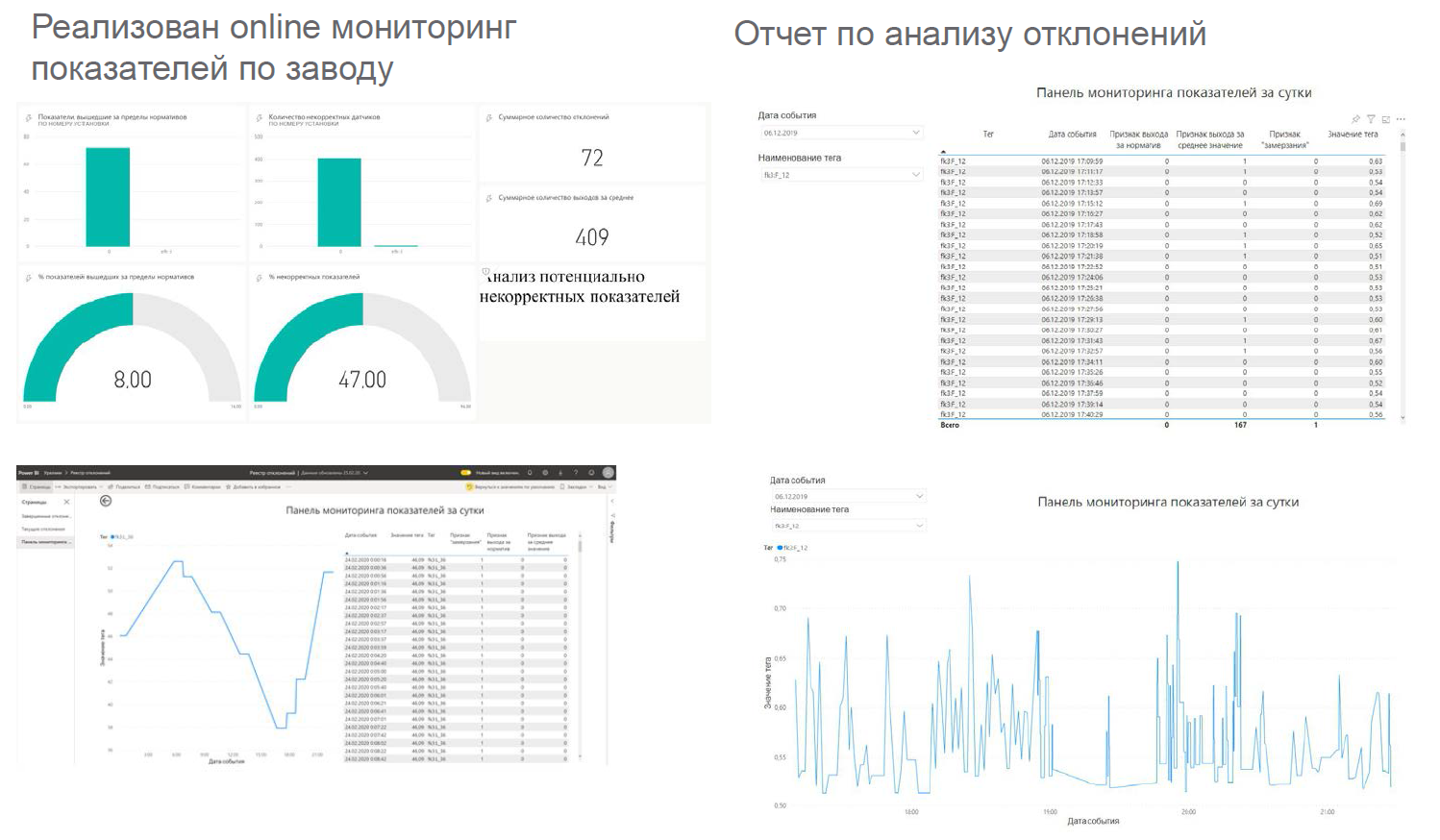
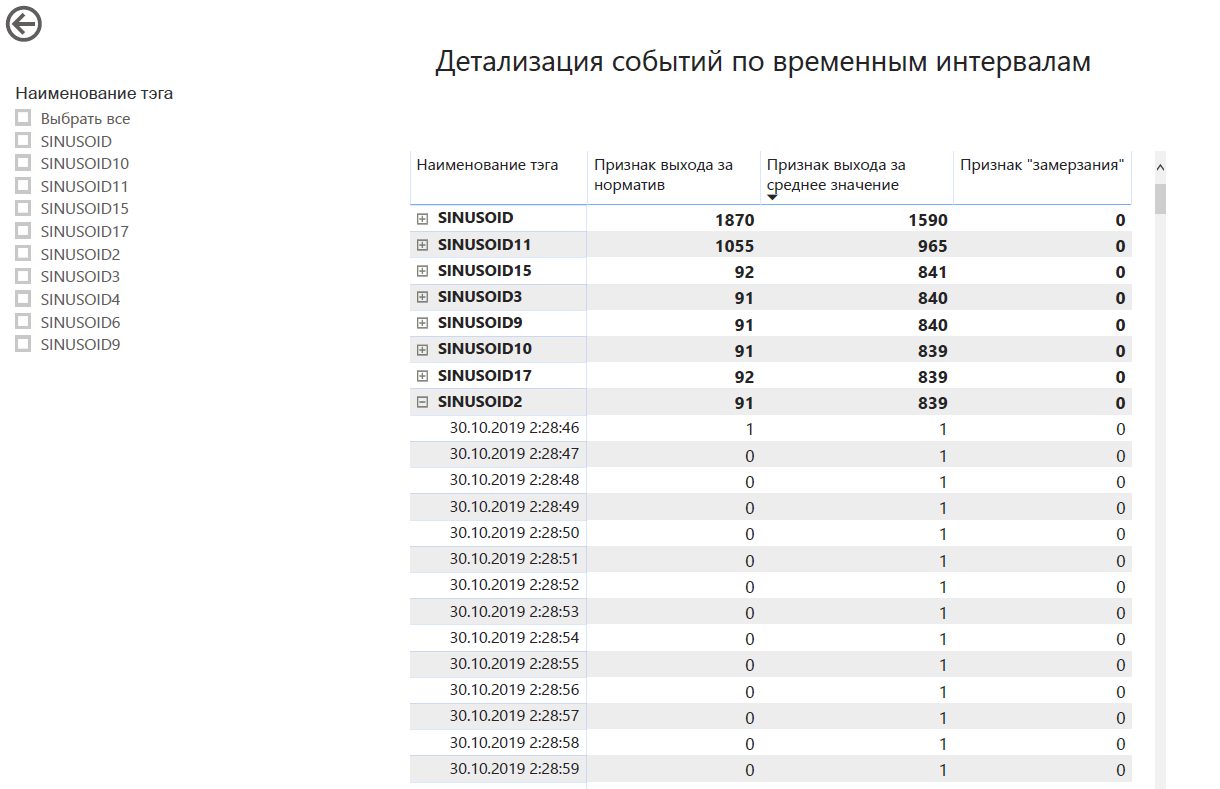
Выводятся вот в таких местах:

Что имеем:
- создано информационное пространство на технологическом уровне для работы с показаниями c датчиков оборудования;
- проверена возможность хранить и обрабатывать данные на базе технологии Big Data;
- проверена возможность работы систем бизнес-аналитики (например, Power BI) с озером данных, построенным на платформе Arenadata Hadoop;
- внедрено единое аналитическое хранилище для сбора производственной информации с датчиков оборудования с возможностью длительного хранения информации (планируемый объём накопленных данных за год — порядка двух терабайтов);
- разработаны механизмы и способы получения данных в режиме, близком к реальному (Nearreal-time);
- разработан алгоритм определения отклонений и некорректной работы датчиков в режиме Near real time (расчёт — раз в минуту);
- проведены испытания работы системы и возможность построения отчётов в BI-инструменте.
Сухой остаток в том, что мы решили вполне производственную задачу — автоматизировали рутинный процесс. Выдали инструмент прогнозирования и высвободили в перспективе технологам время для решения более интеллектуальных задач.
А если остались вопросы не для комментариев, то вот почта — chemistry@croc.ru




teology
В АСУТП можно реализовать, грубо говоря, 50% описанной диагностики сигналов с датчиков. И систему оповещения персонала.
В чем интеллект?
Gengenid
Почему 50? Все 100 можно.
Просто, "цифровизация" это особая тема, она имеет малое отношение к реальной эффективности
Martsial
«Цифровая трансформация» — это нынче модно, и за это дают деньги на развитие, но да, там больше половины — PR. Предлагаю с этим просто смириться.
eteh
По поводу ИИ — есть разные типы диагностических моделей применяемых в АСУ. Одна из них является моделью на нейросетях. В любом случае можно собрать оптимальную модель синтезированную из нескольких. Наличие или отсутствие нейросетки не является каким-то критическим — можно достаточно достоверно настроить эту же экспертную систему диагностики. Ну а мониторинг в реальном времени, это и есть часть системы диагностики.
eteh
Не понимаю смысл минуса — есть диагностические модели, даже беглым взглядом видны карты Шьюхарта, есть и другие совмещенные тут) Ну наберутся модели метода граф, ну окей, ну привет фильтр Калмана (его нет), ну, окей, расписывать дальше — а смысл?)
PavelEgorov Автор
Совершенно верно, что в целом проверки на нормативы (уставки) можно осуществлять на базе АСУТП. Но в рамках данной активности цель была построить аналитическую платформу для сбора, обработки, аналитики данных не для конкретного кейса, а для реализации большого количества кейсов, направленных на повышение эффективности производственного процесса. Конечно в рамках развития платформы в т.ч. кейса по диагностики датчиков возможно внедрения алгоритмов ИИ в т.ч. на базе нейросетей.
Также хороший вопрос зачем строить отдельное озеро данных, если можно внедрить алгоритмы в системы АСУТП? Аналитика предполагает с большими объемами «исторической» информации, как и для построения аналитической отчетности, так и для разработки математических моделей. Вот здесь начинается «самое» интересное – как показывает практика в производственной системе данные хранятся где-то за последние 3 месяца, что конечно крайне мало для обучения мат. моделей, да и в целом для возможностей аналитики работы оборудования. Также такие запросы дают большую нагрузку на систему – выполняются крайне «долго», возможно в целом негативное влияние на работу пользователей системы. В целом это справедливо для всех транзакционных систем, основная цель которых обеспечить оперативное управление производством.
Подводя итоги, когда есть цель внедрять аналитические инструменты, строить мат. модели на производственных данных (данные с датчиков и MES систем), объединять производственные данные с бизнес данными (в ERP системе – например, планы по производству, KPI и др.) для построения аналитической отчетности и тех мат. моделей и Вы хотите построить не 1 отчет и не 1 конкретную модель, а как минимум планируете сделать несколько десятков отчетов и моделей и хотите, чтоб это работало в режиме near real time то тогда к вам придет на помощь технологии бигдата и озера данных, которые специально созданы для решения таких задач, а возможность их горизонтального масштабирования позволит расширять скоуп решаемых задач (количество предметных областей для аналитики и соответственно количество и сложность используемых мат. моделей).