

«Наука часто следует за технологией, потому что открытия дают нам новые методы осмысления мира и новые феномены, нуждающиеся в объяснениях».
Так утверждает Арам Харроу (Aram Harrow), профессор физики Массачусетского технологического института, в статье «Почему сейчас самое время для изучения квантовых вычислений» (Why now is the right time to study quantum computing).
Он считает, что научная идея энтропии не могла быть в полной мере осмыслена, пока этого не потребовала термодинамика технологии парового двигателя. Подобным образом квантовые вычисления появились из попыток симулировать квантовую механику на обычных компьютерах.
Так что же общего все это имеет с обучением машин?
Также, как и паровые двигатели, машинное обучение — это технология, предназначенная для решения конкретных классов задач. И тем не менее результаты, полученные в данной сфере, дают нам интригующие – возможно, фундаментальные – научные предположения о том, как функционирует человеческий мозг, как он воспринимает окружающий мир и учится. Технология машинного обучения дает нам новые пути для осмысления науки о человеческом мышлении… и воображении.
Не машинное распознавание, а компьютерное построение образов
Пять лет тому назад пионер глубинного обучения Джефф Хинтон (Geoff Hinton), который в настоящее время совмещает деятельность в Университете Торонто с работой в Google, опубликовал следующий ролик.
Хинтон обучил пятислойную нейросеть распознавать рукописные цифры с растровых изображений. Это была одна из форм машинного распознавания объектов, которая сделала рукописный текст пригодным для машинного считывания.
Но в отличие от предыдущих работ в той же области (в которых главной целью было просто узнавание цифр) нейросеть Хинтона могла также осуществлять процесс в обратном порядке. То есть, основываясь на понятии символа, она могла воссоздать изображение, соответствующее этому понятию.
Мы видим, как машина в буквальном смысле этого слова представляет себе изображение с понятием «8».
Магия закодирована в слоях между входами и выходами. Эти слои являются своего рода ассоциативной памятью, которая выполняет сопоставление в обоих направлениях (от изображения к понятию и наоборот) внутри одной нейронной сети.
Может ли так работать и человеческое воображение?
Но за упрощенной, созданной на основе модели человеческого мозга технологией лежит более широкий научный вопрос: так ли работает человеческое воображение (создание зрительных образов, визуализация). Если да, то это значительное открытие.
В конце концов, не это ли наш мозг делает вполне естественным образом? Когда мы видим цифру 4, мы думаем о понятии «4». И наоборот: когда кто-то говорит «8», мы можем в своем воображении представить образ цифры 8.
Не является ли все это своего рода «обратным процессом», который разум проходит от понятия к изображению (или звуку, запаху, чувству и т.д.) посредством заложенной в слоях информации? Не были ли мы свидетелями того, как эта сеть создала новые изображения – и, возможно, в усовершенствованной версии могла бы создавать и новые внутренние связи?
Понятие и созерцание
Если визуальное распознавание и воображение действительно являются лишь возвратно-поступательной связью между изображениями и понятиями, что же происходит между этими слоями? Могут ли глубокие нейронные сети осуществлять восприятие посредством созерцания или аналогичного процесса?
Давайте сначала заглянем в прошлое: 234 года тому назад была опубликована «Критика чистого разума», философский труд Иммануила Канта (Immanuel Kant), в котором он утверждает, что созерцание – это не что иное, как представление явления.

Кант выступал против идеи того, что человеческие знания могут быть следствием исключительно эмпирического и рационального мышления. Он утверждал, что необходимо учитывать познание через созерцание. Под определением «созерцание» он понимает представления, которые были получены путем чувственного восприятия, где в качестве «понятий» выступают описания эмпирических объектов или ощущения. Вместе они формируют человеческие знания.
Спустя два столетия профессор Алеша Эфрос (Alyosha Efros) из отдела компьютерных наук Калифорнийского университета в Беркли, специализацией которого является зрительное понимание, отметил: «В зрительной картине окружающего нас мира куда больше деталей, чем слов, которые есть у нас в наличии для их описания». По мнению Эфроса, использование слов для обучения моделей накладывает на наши технологии языковое ограничение. Не имеющих названия созерцаемых явлений куда больше, чем слов.
Здесь мы наблюдаем интригующее соответствие между меткой в машинном обучении и человеческим понятием, а также между кодированием в машинном обучении и человеческим созерцанием.
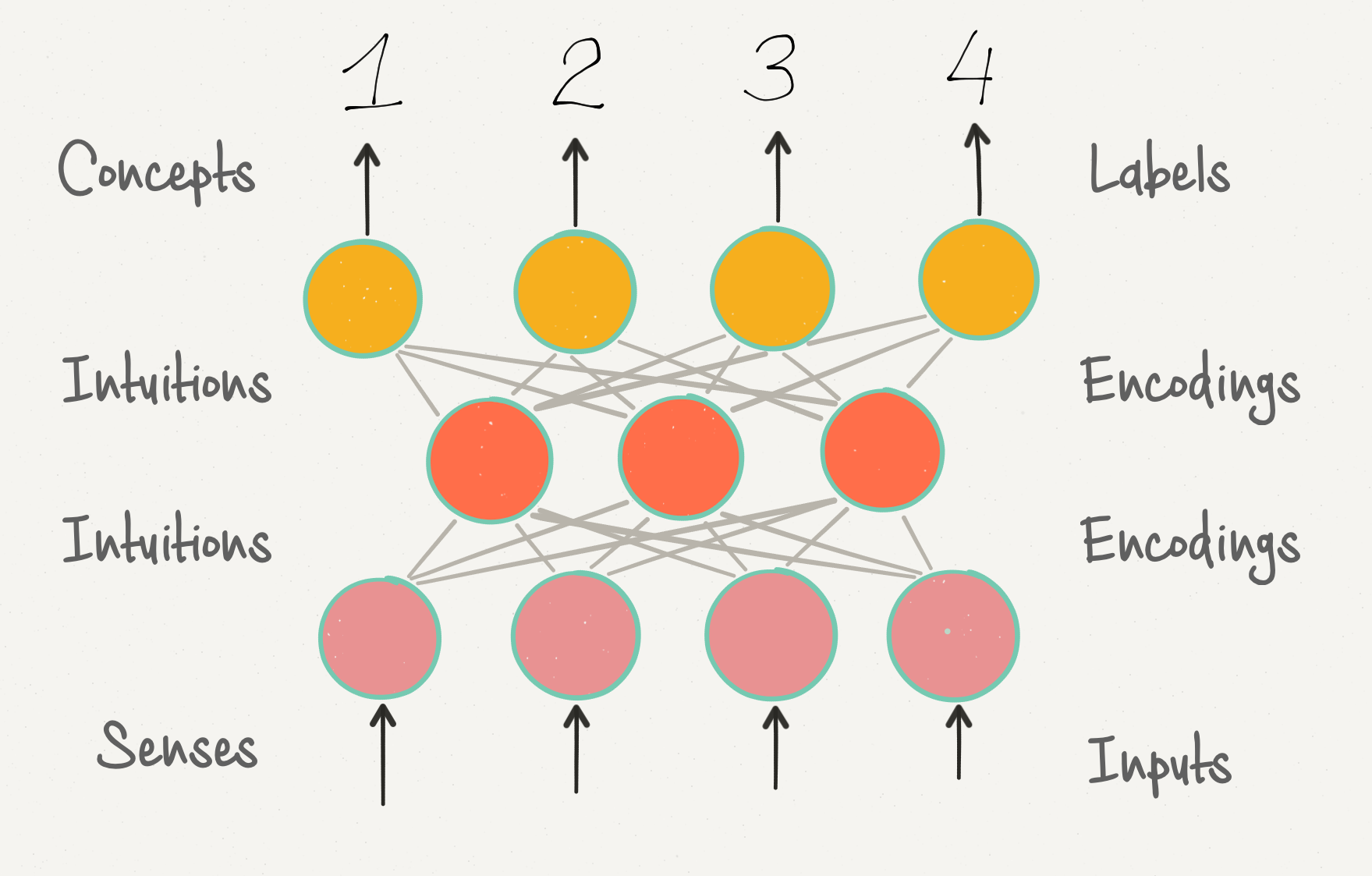
В обучении глубоких сетей мы обнаруживаем, что активации в последовательных слоях распространяются от более низких понятийных уровней мышления к более высоким, что показало исследование по «распознаванию котов» под руководством Куока Ле (Quoc Le), работающего в Google и Стэндфордском университете. Распознающая изображения сеть кодирует растровые изображения в самом нижнем слое, затем в следующем слое кодируются видимые углы и края, а простые формы – в последующем слое, и т.д. Эти промежуточные слои не обязаны иметь каких-либо активаций, соответствующим понятиям высокого уровня (например, такие как «кот» или «собака»), но все же они кодируют распределенное представление входной сенсорной информации. Только последний выходной слой имеет соответствие заданным человеком меткам, так как он подчинен ограничениям, в соответствии с которыми должен соответствовать этим меткам.
Не является ли это созерцанием?
Следовательно, рассмотренные выше кодирование и метки, похоже, являются тем же, что Кант называл «созерцанием» и «понятиями».
Это еще один пример того, как технология машинного обучения помогает понять принципы мышления человека. Представленная выше схема сети заставляет задуматься о том, не является она в значительной мере упрощенной архитектурой созерцания.
Полемика вокруг концепции Сепира-Уорфа
Эфрос отметил: если в мире существует куда больше явлений, чем слов для их описания, тогда ограничиваются ли словами наши мысли? Этот вопрос находится в центре гипотезы лингвистической относительность Сепира-Уорфа и полемики относительно того, полностью ли язык определяет границы нашего познания, или мы естественным образом способны осмыслить любые явления вне зависимости от языка, на котором говорим.
В своей сильной форме эта гипотеза утверждает, что структура и лексика языка влияют на восприятие и осмысление человеком мира.
Одни из наиболее впечатляющих результатов можно получить благодаря представленному здесь цветовому тексту. Наиболее впечатляющие результаты дает тест классификации по цвету. Если попросить найти квадрат, оттенок которого отличается от всех остальных, представителей народности химба из северной Намибии, в языке которых есть четкие названия этих двух оттенков, то они практически сразу же его находят.

В то же время все остальные из нас испытывают с этим трудности.
Теория такова, что при наличии слов, описывающих разные оттенки, наш мозг сам обучится тому, чтобы их различать, поэтому со временем эти различия станут более «очевидными». В зрительном восприятии с помощью нашего мозга, а не с помощью наших глаз, язык определяет наше восприятие.
Мы видим с помощью нашего мозга, а не глаз.
В машинном обучении мы наблюдаем нечто подобное. При обучении с учителем, мы обучаем наши модели, чтобы они как можно точнее определяли соответствующие метки или категории изображениям (или другим элементам – тексту, звуку и т. д.). По определению, эти модели обучаются куда более эффективно различать категории с метками, чем другие категории, для которых метки не были предусмотрены. При взгляде с точки зрения машинного контролируемого обучения это следствие не кажется удивительным. Так что, возможно, нам также не стоит слишком удивляться результатам рассмотренного выше теста. Язык действительно влияет на наше восприятие окружающего мира так же, как метки при машинном контролируемом обучении влияют на способность модели различать категории.
Но при этом мы знаем, что метки не являются обязательным условием для умения различать категории. В проекте компании Google по «распознаванию котов» нейронная сеть в конце концов абсолютно самостоятельно обнаруживает понятия «кот», «собака» и т. д. без обучения алгоритма меткам. После такого обучения без должного контроля всякий раз, когда сеть получает изображение из определенной категории (например, «коты»), активируется один и тот же соответствующий набор нейронов. Просмотрев большое количество обучающих изображений, эта сеть обнаружила характерные для каждой категории признаки – так же, как и различия между разными категориями.
Таким же образом младенец, которому многократно показывали бумажный стаканчик, в скором времени сможет узнавать его визуальный образ даже до того, как выучит слова «бумажный стаканчик», чтобы связать образ с названием. В этом смысле сильная форма гипотезы Сепира-Уорфа не является в полной мере справедливой, ведь мы можем формировать понятия без слов для их описания, что мы и делаем.
Машинное обучение под контролем и без него оказались двумя сторонами одной медали в этой полемике. И если мы их таковыми признаем, то концепция Сепира-Уорфа не будет предметом спора, а скорее отражением человеческого обучения с учителем и без него.
Я нахожу эту аналогию невероятно увлекательной – и мы только начали понимать что-то в данном вопросе. Философы, психологи, лингвисты и нейрофизиологи уже давно занимаются изучением этой темы. При обработке огромного количества текста, изображений или аудио новейшие архитектуры глубинного обучения демонстрируют сравнимые с человеческими или лучшие результаты классификации изображений, языкового перевода и распознавания речи.
Каждое новое открытие в области машинного обучения дает нам возможность узнать что-то новое о процессах, происходящих в человеческом мозге. Говоря о собственном разуме, мы получаем все больше и больше оснований для того, чтобы ссылаться на машинное обучение.
P.S. А вы видите, какой квадрат отличается от остальных? Пишите свою версию в комментариях, используя чистый рисунок для «осознания» и картинку ниже для определения номера квадрата:
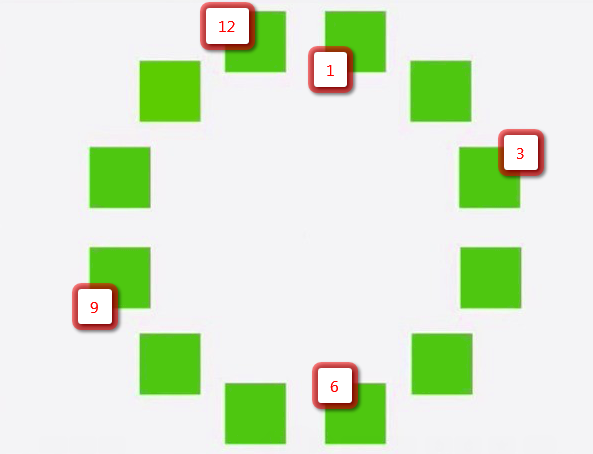
P.P.S. Есть версия, что разные мониторы визуально могут «указать» на разный квадрат, и я (переводчик) с ней согласен. Для наиболее пытливых умов напомню, что существуют сугубо технические средства проверки своих предположений.


lostpassword
По-моему, N11.