
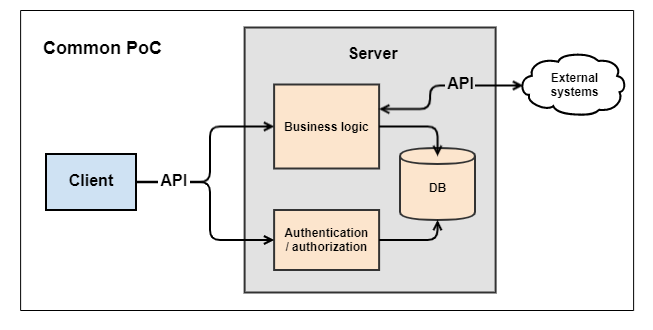
Типичный клиент-серверный проект PoC (Proof of Concept) для веба состоит из клиента с GUI, сервера c бизнес логикой и API между ними. Также используется база данных, хранящая оперативную информацию и данные пользователей. Во многих случаях необходима связь с внешними системами со своим API.
Когда у меня возникла необходимость в создании проекта PoC, и я начал разбираться в деталях, то оказалось, что порог вхождения в веб-программирование весьма высок. В крупных проектах для каждого компонента есть выделенные специалисты: front-end, back-end разработчики, UX/UI дизайнеры, архитекторы баз данных, специалисты по API и информационной безопасности, системные администраторы. В небольшом PoC надо самому во всем разобраться, выбрать подходящее техническое решение, реализовать и развернуть. Ситуацию ухудшает тот факт, что из обучающих материалов не всегда понятно, почему предлагается сделать именно так, а не иначе, есть ли альтернативы, является ли решение best practice или это частное мнение автора. Поэтому я разработал заготовку под названием «Common Test DB», отвечающую лучшим практикам. Ее можно использовать для начала любого проекта, остается только наполнить функциональным смыслом.
В статье я подробно опишу примененные best practices, расскажу про имеющиеся альтернативы и в конце размещу ссылки на исходники и работающий в сети пример.
Требования к проекту PoC
Начнем с минимальных требований к проекту PoC. В статье «Блокчейн: что нам стоит PoC построить?» я уже рассматривал из каких частей состоит универсальная информационная система. В этой статье подробно разберем состав типичного проекта PoC. Даже минимальный проект в клиент-серверной архитектуре требует значительной функциональности и технической проработки:
Клиент:
- Должен осуществлять запросы к серверу, используя REST API
- Регистрировать, авторизовать, аутентифицировать пользователей
- Принимать, разбирать и визуализировать пришедшие данные
Сервер
- Должен принимать HTTP/HTTPS запросы от клиента
- Осуществлять взаимодействие с внешними системами
- Взаимодействовать с базой данных (реализовать базовую функциональности CRUD)
- Обеспечивать безопасность данных, вызовов API и конфигурационных параметров
- Осуществлять логирование и мониторинг работоспособности
База данных
- Необходимо реализовать структуру DB
- Наполнить DB начальными значениями
Архитектура
- Проект PoC должен быть реализован с возможностью расширения функциональности
- Архитектура должна предусматривать масштабирование решения
Технологический стек
- В настоящее время для большинства веб проектов используется язык JavaScript. Над JavaScript есть надстройка TypeScript, которая обеспечивает типизацию переменных и реализацию шаблонов.
- Для полнофункциональных веб проектов есть несколько стандартных стеков технологий. Один из самых популярных: MEVN (MongoDB + Express.js + Vue.js + Node.js), мне больше нравится PEVN (PostgreSQL + Express.js + Vue.js + Node.js), т.к. RDB базы мне технологически ближе, чем NoSQL.
- Для GUI существует несколько фреймворков (Vue, React, Angular). Тут выбор, скорее, определяется традициями или личными предпочтениями, поэтому сложно говорить, что лучше, а что хуже. Сначала я выбрал Vue.js, да так на нем и остался. Этот фреймворк хорошо развивается, для него есть готовые визуальные компоненты в стиле Material Design (Vuetify), которые хорошо смотрятся даже при непрофессиональном применении. Считается, что для React порог вхождения выше, чем для Vue. В React сначала надо осознать специфичную объектную модель, которая отличается от классического веб программирования: компоненты как функции, компоненты как классы, цепочки вызовов.
- Выбор базы данных уже сложнее, чем личные предпочтения. Но для PoC, зачастую, требуется не функциональность или производительность, а простота. Поэтому в примере будем использовать самую простую в мире базу SQLite. В промышленных PoC в качестве SQL базы я использую PostgreSQL, в качестве NoSQL ее же, т.к. запас прочности у PostgreSQL огромен. Прочность, конечно, не бесконечна и когда-нибудь настанет необходимость перехода на специализированную базу, но это отдельная тема для обсуждения.
На самом деле, все современные средства разработки можно развернуть и попробовать достаточно быстро. Поэтому сейчас можно делать осознанный выбор технологий, основанный на практике.
Далее разберем подробно все требования к PoC. Начнем с сервера.
Сервер
HTTP сервер
В качестве HTTP сервера я пробовал два варианта:
Express более зрелый, Fastify, говорят, более быстрый. Есть еще варианты серверов, примеры перечислены в статье The Best 10 Node.js Frameworks. Я использовал самый популярный Express.js.
HTTPS запросы
Говоря про HTTP, я всегда подразумеваю HTTPS, т.к. без него крайне сложно построить безопасное взаимодействие между клиентом и сервером. Для поддержки HTTPS надо:
- Получить SSL (TLS) сертификат
- На сервере реализовать поддержку HTTPS протокола
- На клиенте использовать запросы к клиенту с префиксом HTTPS
Получаем сертификат
Для организации работы HTTPS протокола нужен SSL сертификат. Существуют бесплатные сертификаты Let’s Encrypt, но солидные сайты получают платные сертификаты от доверительных центров сертификации CA (Certificate Authority). Для наших тестовых целей на локальном хосте достаточно, так называемого, self-signed certificate. Он генерируется с помощью утилиты openssl:
openssl req -nodes -new -x509 -keyout server.key -out server.crtДалее отвечаем на несколько вопросов про страну, город, имя, email и т.п. В результате получаем два файла:
- server.key — ключ
- server.crt — сертификат
Их нужно будет подложить нашему Express серверу.
HTTPS сервер
С Express сервером все достаточно просто, можно взять стандартный пакет HTTPS из Node.js, и использовать официальную инструкцию: How to create an https server?
После реализации HTTPS сервера используем полученные файлы server.key и server.crt и стандартный для HTTPS порт 443.
Взаимодействие с внешними системами
Самая известная библиотека для реализации HTTP/HTTPS запросов: Axios. Она используется как в сервере для вызова API внешних систем, так и в клиенте для вызова API сервера. Есть еще варианты библиотек, которые можно использовать для специфичных целей: Обзор пяти HTTP-библиотек для веб-разработки.
Взаимодействие с базой данных
Для работы с базой данных я использовал самую популярную библиотеку для Node.js: Sequelize. В ней мне больше всего нравится то, что переключиться между различными типами баз данных можно всего лишь изменив несколько настроечных параметров. При условии, конечно, что в самом коде не используется специфика определенной базы. Например, чтобы переключиться с SQLight на PostgreSQL, надо в конфигурационном файле сервера заменить:
dialect: 'sqlite'на
dialect: 'postgres'И при необходимости изменить имя базы, пользователя и хост.
В PoC я использовал базу данных SQLite, которая не требует установки. Для администрирования баз данных есть хорошо развитые GUI:
- Для SQLight: DB Browser for SQLite
- Для PostgreSQL: pgAdmin
Безопасность доступа к данным
В примере реализована следующая простейшая логика доступа к данным, которую можно расширять и изменять в зависимости от бизнес-задач:
- При регистрации каждому пользователю присваивается уникальный ID.
- Когда пользователь создает новые данные, в них добавляется его ID.
- При любом запросе к данным проверяется, что пользователь имеет на это право:
- Получить данные могут все зарегистрированные пользователи.
- Изменить и удалить данные может только владелец этих данных.
Такая модель доступа к данным называется Discretionary Access Control (DAC), по-русски: избирательное управление доступом. В этой модели владелец данных может делать с ними любые CRUD операции, а права остальных пользователей ограниченны.
Существуют несколько моделей контроля доступа к данным. Помимо Discretionary Access Control (DAC) OWASP рекомендует (Access Control Cheat Sheet) использовать следующие:
- Role-Based Access Control (RBAC)
- Mandatory Access Control (MAC)
- Permission Based Access Control
Безопасность вызовов API
В моей предыдущей статье я рассматривал все возможные угрозы: Безопасность REST API от А до ПИ. В PoC реализованы следующие механизмы:
- Cross-Site Request Forgery (CSRF) (Межсайтовая подмена запросов)
От данной угрозы реализован механизм «CSRF токенов» — когда для каждой сессии пользователя генерируется новый токен (он же SessionId) и сервер проверяет его валидность при любых запросах с клиента. Алгоритм генерации и проверки SessionId подробно описан далее в разделе «Авторизация, аутентификация пользователей».
- Cross-origin resource sharing (CORS) (Кросс-доменное использование ресурсов)
Защита реализована с помощью пакета CORS. В config файле сервера указываются адрес (origin), с которого могут поступать API запросы и список методов (methods), которые может использовать клиент. В дальнейшем сервер будет автоматически ограничивать прием запросов в соответствии с этими настройками.
Для защиты от угроз, перечисленных далее, я использовал пакет helmet, который позволяет задать значения для определенных HTTP заголовков:
- Cross-site Scripting (XSS) (Межсайтовое выполнение скриптов)
Для защиты выставляется заголовок, ограничивающий выполнение скриптов:
X-XSS-Protection: 1; mode=block- Insecure HTTP Headers
Блокируется отправка сервером заголовка, дающего дополнительную информацию злоумышленнику:
X-Powered-By: Express- Insecure HTTP Headers: HTTP Strict Transport Security (HSTS)
Используется Strict-Transport-Security заголовок, который запрещает браузеру обращаться к ресурсам по HTTP протоколу, только HTTPS:
Strict-Transport-Security: max-age=15552000; includeSubDomains- Insecure HTTP Headers: X-Frame-Options (защита от Clickjacking)
Данный заголовок позволяет защититься от атаки Clickjacking. Он разрешает использовать фреймы только в нашем домене:
X-Frame-Options: SAMEORIGIN- Insecure HTTP Headers: X-Content-Type-Options
Установка заголовка X-Content-Type-Options запрещает браузеру самому интерпретировать тип присланных файлов и принуждает использовать только тот, что был прислан в заголовке Content-Type:
X-Content-Type-Options: nosniffЗащита от DoS
Необходимо защитить сервер и от отказа в обслуживании (DoS-атаки). Например, ограничить число запросов от одного пользователя или по одному ресурсу в течении определенного времени.
Для Node.js существуют средства, позволяющие автоматически реализовывать ограничения на число запросов и сразу посылать ответ «429 Too Many Requests», не нагружая бизнес логику сервера.
В примере реализовано простейшее ограничение на число запросов от каждого пользователя в течении определенного времени по таблице Data. В промышленных системах надо защищать все запросы, т.к. даже один запрос, оставшийся без проверки может дать возможность провести атаку.
Безопасность конфигурационных параметров
Настройки для клиента и сервера хранятся в файлах config в JSON формате. Чувствительные настройки сервера нельзя хранить в config файлах, т.к. они могут стать доступны в системах версионного контроля. Для такой информации как: логины/пароли для базы данных, ключи доступа к API и т.д. надо использовать специализированные механизмы:
- Задавать эти параметры в .env файле. Файл .env прописан в gitignore и не сохраняется в системах версионного контроля, поэтому поэтому туда можно безопасно записывать чувствительную информацию.
- Использовать механизм переменных окружения (environment variables), которые устанавливаются вручную или прописываются инсталляторами.
Логирование
Стандартные требования к логированию:
- Обеспечить разный уровень логирования (Debug; Info; Warning; Error и т.д.)
- Логировать HTTP/HTTPS запросы
- Дублировать консольный вывод в файлы на диске
- Обеспечить самоочистку файлов логирования по времени и объёму
Варианты пакетов для логирования, которые я пробовал:
В проекте я использовал log4js. Пакет log4js работает интуитивно понятно и достаточно развит, чтобы реализовать все требования.
Мониторинг
Мы не будем останавливаться на внешних система мониторинга: Обзор систем мониторинга серверов, т.к. они начинают играть важную роль не на этапе PoC, а в промышленной эксплуатации.
Обратимся к внутренним системам, которые позволяют наглядно посмотреть, что сейчас происходит с сервером, например пакет express-status-monitor. Если его установить, то по endpoint
/monitorможно наглядно мониторить простейшие параметры работы сервера, такие как загрузка CPU, потребление памяти, http нагрузку и т.п. Приведу скриншот из нашего примера. На скриншоте горит красная плашка Failed и может показаться, что что-то не так. Но, на самом деле, все в порядке, т.к. вызов API сознательно делается на несуществующий endpoint:
/wrongRoutePath
База данных
Структура базы данных
В нашем примере реализованы две таблицы с говорящими именами:
- Users
- Data
Лучшие практики говорят, что все проверки надо по максимуму отдавать базе данных. Поэтому в схеме базы данных аккуратно определяем все типы данных, добавляем ограничения (constraints) и внешние ключи. Для пакета sequelize данная функциональность подробно описана в стандартной документации.
В нашем пример сделан один внешний ключ UserId в таблице Data для того, чтобы гарантировать, что у каждой записи в таблице Data будет определенный владелец User. Это позволит при изменении или удалении записи в Data реализовать проверку пользователя, т.к. по нашей логике данные может удалять только их владелец.
Еще одна особенность нашей схемы в том, что один столбец таблицы Data задан в формате JSON. Такой формат удобно использовать, если внешняя система возвращает данные в JSON. В этом случае можно просто записать полученные данные, не тратя усилия на парсинг, а потом делать SQL запросы, используя расширенный синтаксис. Описание работы со столбцами JSON можно найти в официальной документации баз данных. В качестве независимого описания мне понравилась статья на Хабре, в которой описаны все варианты запросов: "JSONB запросы в PostgreSQL.
Формальная схема DB
Cхема таблицы Users:
Схема таблицы Data:
- «id» INTEGER PRIMARY KEY AUTOINCREMENT — уникальный ID
- «uuid» UUID NOT NULL UNIQUE — уникальный UUID, по нему идет связь с данными этого пользователя в таблице Data
- «email» VARCHAR(255) NOT NULL UNIQUE
- «password» VARCHAR(64)
- «ddosFirstRequest» DATETIME
- «ddosLastRequest» DATETIME
- «ddosRequestsNumber» DECIMAL
- «lastLogin» DATETIME
- «loginState» VARCHAR(255) NOT NULL
- «sessionId» VARCHAR(1024)
- «commonToken» VARCHAR(1024)
- «googleToken» VARCHAR(1024)
- «googleAccessToken» VARCHAR(1024)
- «googleRefreshToken» VARCHAR(1024)
- «createdAt» DATETIME NOT NULL
- «updatedAt» DATETIME NOT NULL
Схема таблицы Data:
- «id» INTEGER PRIMARY KEY AUTOINCREMENT
- «uuid» UUID NOT NULL UNIQUE
- «ownerUuid» UUID NOT NULL
- «data» JSON NOT NULL
- «UserId» INTEGER REFERENCES «Users» («id») ON DELETE CASCADE ON UPDATE CASCADE,
- «createdAt» DATETIME NOT NULL
- «updatedAt» DATETIME NOT NULL
Начальные значения
- В таблице Users задан один пользователь user@example.com с паролем password.
- В таблице Data записано несколько предопределенных значений, которые можно получить из GUI.
Далее перейдем к клиенту.
Клиент
HTTPS запросы
Для безопасной передачи информации клиент использует HTTPS протокол. Для запросов используется та же библиотека, что и на сервере для вызова API внешних систем: Axios.
RESTful API
REST API лучше реализовывать, используя стандартные средства, чтобы было проще тестировать и документировать, например SwaggerHub
Наше REST API сформировано по правилам Open API и использует стандартные HTTP методы для манипуляции объектами из таблиц Users и Data. В схеме нашего API не все сделано по чистым правилам REST, но главное соблюдена общая концепция.
Хорошей практикой является ограничение объёма возвращаемых данных. Для этого используются параметры в запросе: фильтр (filter), ограничение (limit) и смещение (offset). В примере этого нет, но в промышленных системах эта функциональность должна быть реализована. Но даже если реализованы ограничивающие механизмы на клиенте, должна осуществляться дополнительная проверка на сервере на максимальные значения. В нашем примере в конфигурации сервера реализован ограничитель на максимальное число возвращаемых строк из базы, который подставляется в SELECT запросы: limit: 1000
YAML файл с Open API описанием
---
swagger: "2.0"
info:
description: "This is a common-test-db API. You can find out more about common-test-db \ at \nhttps://github.com/AlexeySushkov/common-test-db\n"
version: "2.0.0"
title: "common-test-db"
contact:
email: "alexey.p.sushkov@gmail.com"
license:
name: "MIT License"
url: "https://github.com/AlexeySushkov/common-test-db/blob/main/LICENSE"
host: "localhost:443"
basePath: "/commontest/v1"
tags:
- name: "data"
description: "Everything about Data"
externalDocs:
description: "Find out more"
url: "https://github.com/AlexeySushkov/common-test-db/"
- name: "users"
description: "Everything about Users"
externalDocs:
description: "Find out more"
url: "https://github.com/AlexeySushkov/common-test-db/"
schemes:
- "https"
paths:
/data:
get:
tags:
- "data"
summary: "Gets all data"
description: "Gets all data"
operationId: "getData"
produces:
- "application/json"
parameters: []
responses:
"200":
description: "successful operation"
schema:
type: "array"
items:
$ref: "#/definitions/Data"
"400":
description: "Invalid status value"
x-swagger-router-controller: "Data"
post:
tags:
- "data"
summary: "Add a new data to the db"
operationId: "addData"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- in: "body"
name: "body"
description: "Data object that needs to be added to the db"
required: true
schema:
$ref: "#/definitions/Data"
responses:
"500":
description: "Create data error"
x-swagger-router-controller: "Data"
put:
tags:
- "data"
summary: "Update an existing data"
operationId: "updateData"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- in: "body"
name: "body"
description: "Data information that needs to be changed"
required: true
schema:
$ref: "#/definitions/Data"
responses:
"400":
description: "Invalid uuid"
"404":
description: "User not found"
"500":
description: "Update data error"
x-swagger-router-controller: "Data"
delete:
tags:
- "data"
summary: "Delete an existing data"
operationId: "deleteData"
consumes:
- "application/x-www-form-urlencoded"
- "application/json"
produces:
- "application/json"
parameters:
- name: "uuid"
in: "formData"
description: "uuid"
required: true
type: "string"
responses:
"400":
description: "Invalid uuid"
"404":
description: "User not found"
"500":
description: "Delete data error"
x-swagger-router-controller: "Data"
/users:
post:
tags:
- "users"
summary: "Register new user"
operationId: "userRegister"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- in: "body"
name: "body"
description: "User that needs to be deleted"
required: true
schema:
$ref: "#/definitions/User"
responses:
"500":
description: "Register user error"
x-swagger-router-controller: "Users"
put:
tags:
- "users"
summary: "Update existing user"
operationId: "userUpdate"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- in: "body"
name: "body"
description: "User information that needs to be changed"
required: true
schema:
$ref: "#/definitions/User"
responses:
"404":
description: "User not found"
"500":
description: "Delete user error"
x-swagger-router-controller: "Users"
delete:
tags:
- "users"
summary: "Delete user"
operationId: "userDelete"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- in: "body"
name: "body"
description: "User that needs to be added to the db"
required: true
schema:
$ref: "#/definitions/User"
responses:
"404":
description: "User not found"
"500":
description: "Delete user error"
x-swagger-router-controller: "Users"
/users/login:
post:
tags:
- "users"
summary: "Login"
operationId: "userLogin"
consumes:
- "application/json"
produces:
- "application/json"
parameters:
- in: "body"
name: "body"
description: "User that needs to be added to the db"
required: true
schema:
$ref: "#/definitions/User"
responses:
"404":
description: "User not found"
"500":
description: "Login user error"
x-swagger-router-controller: "Users"
definitions:
Data:
type: "object"
required:
- "Counter1"
- "Counter2"
properties:
Counter1:
type: "integer"
format: "int64"
Counter2:
type: "integer"
format: "int64"
example:
Counter1: 10
Counter2: 20
User:
type: "object"
required:
- "email"
- "password"
properties:
email:
type: "string"
password:
type: "string"
example:
password: "password"
email: "email"
ApiResponse:
type: "object"
properties:
status:
type: "string"
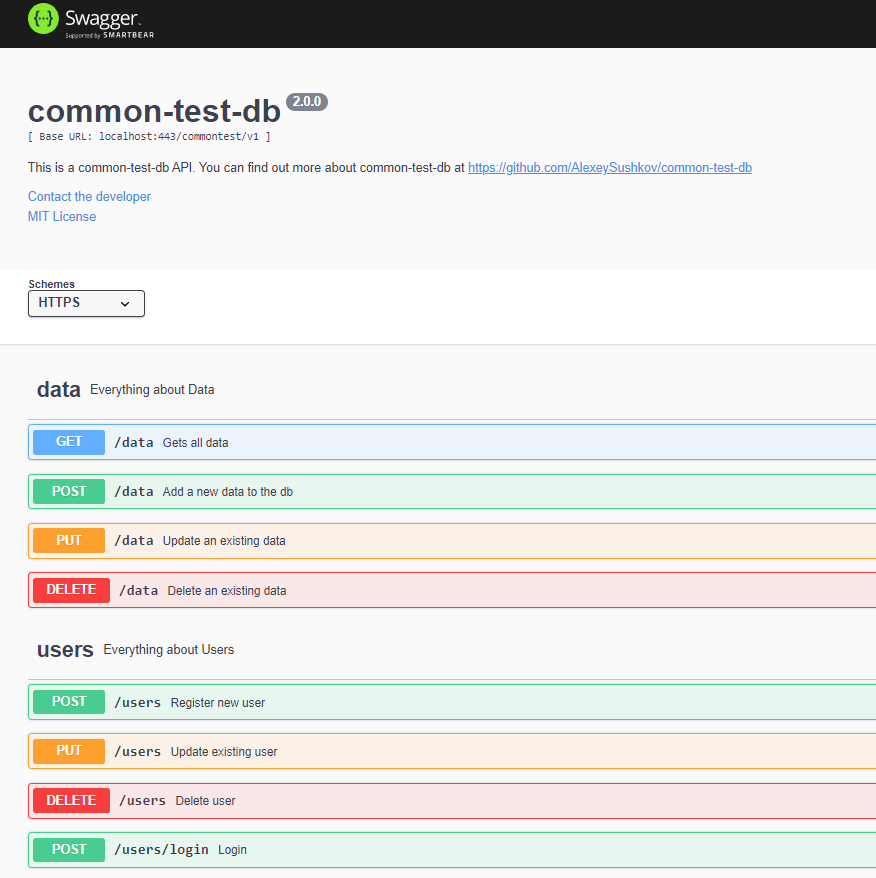
Интересная возможность — встроить Swagger прямо в сервер, далее подложить ему YAML, реализующий API и по endpoint:
/api-docsполучить стандартную Swagger панель управления и осуществлять тестирование и просмотр документации. Скриншот Swagger, встроенного в наш сервер:
GraphQL
Существуют и альтернативы REST API, например GraphQL. Данный стандарт разработан Facebook и позволяет избавиться от недостатков REST:
- В REST API взаимодействие происходит с использованием многочисленные endpoints. В GraphQL — одна.
- В REST API для получения данных от разных endpoints необходимо осуществить множественные запросы. В GraphQL все необходимые данные можно получить одним запросом.
- В REST API клиент не может контролировать объём и содержимое данных в ответе. В GraphQL набор возвращаемых данных предсказуем, т.к. задается в запросе. Это сразу избавляет от угрозы: Excessive Data Exposure (Разглашение конфиденциальных данных)
- В REST API отсутствует обязательность формальной схемы. В GpaphQL создание схемы API с определенными типами данных — обязательно, при этом автоматически получается документация и сервер для тестирования (самодокументироваемость и самотестируемость).
- Клиент всегда может запросить схему API с сервера, тем самым синхронизировать формат своих запросов
- Из коробки работают подписки, реализованные на технологии WebSockets
Какое API использовать, решается в зависимости от бизнес задач. REST API практически безальтернативно используется в промышленных системах и задачах интеграции между ними. Но для проектов, не требующих взаимодействия со сторонними системами вполне можно использовать более продвинутый GraphQL.
Регистрация, аутентификация и авторизация пользователей
Если приложение доступно из Интернета, то в форме регистрации имеет смысл использовать функциональность reCaptсha от Google для защиты от ботов и DoS атак. В нашем примере я использую пакет vue-recaptcha.
Для использования reCaptсha нужно на сайте Google зарегистрировать приложение, получить sitekey и прописать его в настройках клиента. После этого на форме появится, известный всем, вопрос про робота:

В примере реализована регистрация пользователей с помощью логина/пароля и с использованием Google Account.
- При регистрации по логин/пароль пароли в базе данных, разумеется, не хранятся в виде текста, а хранится только хеш. Для его генерации используется библиотека bcrypt, которая реализует алгоритм хеширвания Blowfish. Сейчас уже есть мнение, что надо использовать более надежные алгоритмы: Password Hashing: Scrypt, Bcrypt and ARGON2.
- При регистрации с помощью Google Account организация хранения аутентификационных данных проще, т.к. в базу записывается только token, полученный от Google.
Для реализации различных схем аутентификации есть библиотека Passport, которая упрощает работу и скрывает детали. Но чтобы понять как работают алгоритмы, в примере все сделано в соответствии со стандартами, которые я уже описывал в своей статье: Современные стандарты идентификации: OAuth 2.0, OpenID Connect, WebAuthn.
Далее в статье разберем практическую реализацию.
Аутентификация по логину/паролю (Basic Authentication)
Тут все достаточно просто. При получении запроса на логин сервер проверяет, что пользователь с присланным email существует и что хеш полученного пароля совпадает с хешом из базы.
Далее:
- Сервер формирует SessionId в формате UUID и Token в формате JWT (JSON Web Token)
- Токену присваиватся время жизни, которое определяется бизнес задачами. Например, Google устанавливет своим токенам время жизни 1 час.
- Для формирования токена используется пакет jsonwebtoken
- В JWT помещается email пользователя, который подписывается ключом сервера. Ключ — это текстовая строка, которая хранится, как конфигурационный параметр на сервере. Содержимое токена кодируется Base64
- SessionId сохраняется в базе и отправляется клиенту в заголовке X-CSRF-Token
- Token сохраняется в базе и отправляется клиенту в теле HTTP ответа
- Получив SessionId клиент сохраняет SessionId в sessionStorage браузера
- Token записывается в localStorage или Сookies браузера для реализации возможности «запомнить меня на этом устройстве»
- В дальнейшем клиент будет присылать SessionId в HTTP заголовке X-CSRF-Token:
X-CSRF-Token: 69e530cf-b641-445e-9866-b23c492ddbab- Token будет присылаться в заголовке HTTP Authorization с префиксом Bearer:
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJlbWFpbCI6InRlc3RAdGVzdC5jb20iLCJpYXQiOjE2MDYxNTY3MTUsImV4cCI6MTYwNjc2MTUxNX0.h3br5wRYUhKIFs3SMN2ZPvMcwBxKn7GMIjJDzCLm_Bw
- Сервер каждый раз проверяет SessionId на то, что сессия существует и связана с пользователем. Таким образом, гарантируется, что запрос приходит от залогиненного клиента, а не стороннего сайта злоумышленника.
- Сервер при каждом запросе будет проверять присланный Token на валидность:
- Токен подписан сервером;
- Пользователь с email существует;
- Время жизни токена не истекло. Если же оно истекло, то при выполнении предыдущих условий автоматически формируется новый токен.
В общем случае излишне генерировать и SessionId и Token. В нашем PoC для примера реализованы оба механизма. Посмотрим внимательней на наш JWT. Пример закодированного JWT токена из заголовка:
Authorization: yJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJlbWFpbCI6InRlc3RAdGVzdC5jb20iLCJpYXQiOjE2MDYxNTY3MTUsImV4cCI6MTYwNjc2MTUxNX0.h3br5wRYUhKIFs3SMN2ZPvMcwBxKn7GMIjJDzCLm_Bw
Раскодируем его открытыми средствами. Например самый простой способ загрузить на сайт https://jwt.io.
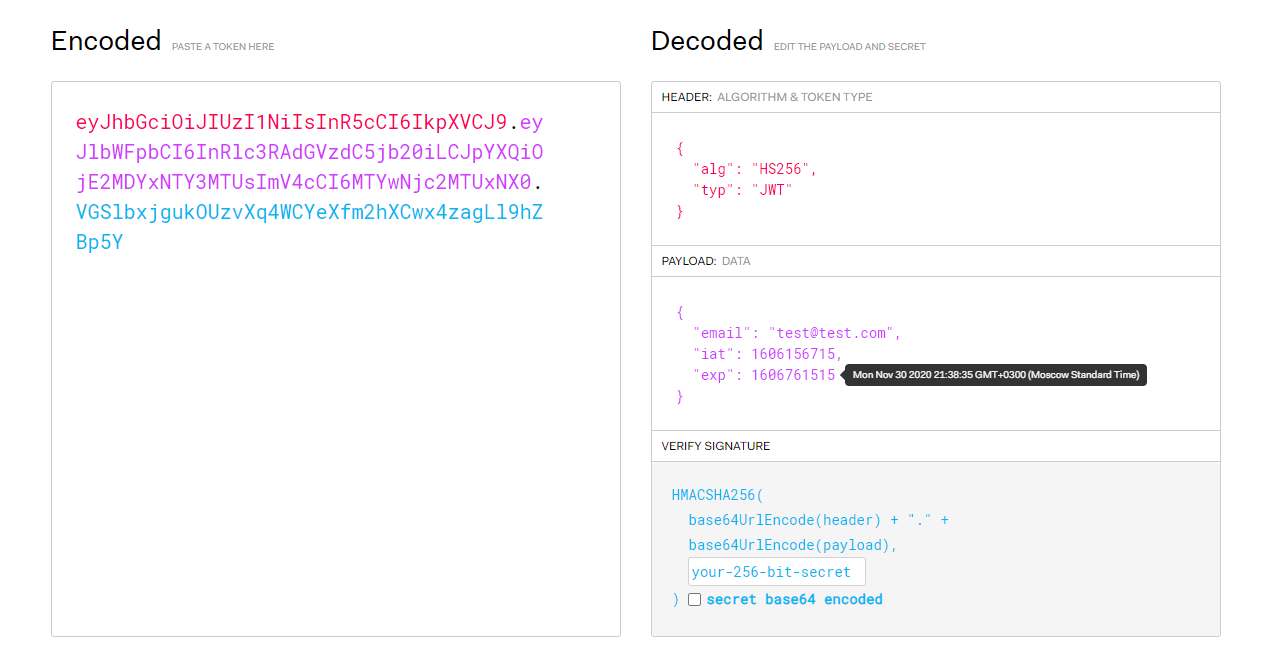
Мы видим, что информация, помещенная в JWT не зашифрована, а только подписана ключом сервера и туда нельзя помещать чувствительные к разглашению данные!
Аутентификация с помощью Google Account (Token-Based Authentication)
Тут посложнее, поэтому нарисую диаграмму:
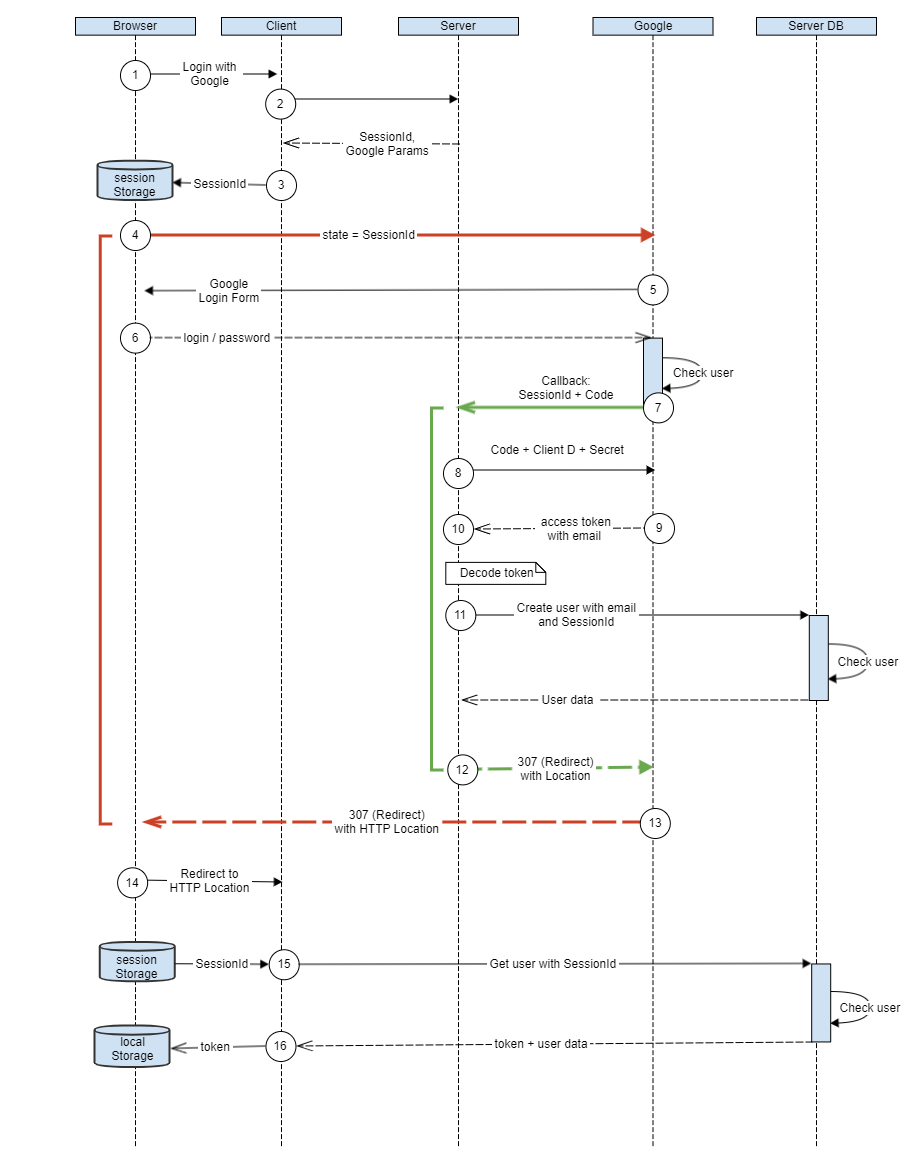
1. Пользователь заходит на GUI PoC, выбирает “Login with Google".
2. Клиент запрашивает у сервера SessionId и настройки Google. Настройки надо предварительно получить с сайта Google, например, по инструкции из моей статьи: Современные стандарты идентификации: OAuth 2.0, OpenID Connect, WebAuthn.
3. Клиент сохраняет SessionId в sessionStorage браузера.
4. Из браузера формируется GET запрос на Google Authorization Server (красная стрелка). Для понимания алгоритма, надо обратить внимание, что ответ на этот запрос браузер получит от Google только в самом конце call flow на шаге 13 и это будет 307 (Redirect).
Формат GET запроса:
https://accounts.google.com/o/oauth2/v2/auth?response_type=code&client_id=918876437901-g312pqdhg5bcju4hpr3efknv.apps.googleusercontent.com&scope=openid+email&redirect_uri=http://localhost:8081/redirect&access_type=offline&state=450c2fd9-0a5e-47d2-8ed5-dd1ff4670b58
В этом запросе:
- accounts.google.com/o/oauth2/v2/auth — endpoint для начала аутентификации. У Google есть, кстати, адрес, по которому можно посмотреть актуальный список всех Google API endpoints: https://accounts.google.com/.well-known/openid-configuration
- response_type=code — параметр говорит, что ожидаем получить в ответ “Authorization Code”
- client_id — Client ID, выданный при регистрации приложения на Google (в примере указан не настоящий)
- scope=openid email — к каким данным пользователя мы хотим получить доступ
- redirect_uri = localhost:8081/redirect Callback адрес, заданный при регистрации приложения. В нашем случае — это адрес на нашем сервере, который получит запрос от Google
- state = SessionId, который передается между клиентом, Google и сервером для защиты от вмешательства внешнего злоумышленника
5. Google Authorization Server показывает стандартную Google форму логина.
6. Пользователь вводит свои логин/пароль от Google аккаунта.
7. Google проверяет пользователя и делает GET запрос на адрес Callback с результатом аутентификации, “Authorization Code” в параметре code и нашем SessionId в параметре state:
- state: '450c2fd9-0a5e-47d2-8ed5-dd1ff4670b58',
- code: '4/0AY0e-g4pg_vSL1PwUWhfDYj3gpiVPUg20qMkTY93JYhmrjttedYwbH376D_BvzZGmjFdmQ',
- scope: 'email openid www.googleapis.com/auth/userinfo.email',
- authuser: '1',
- prompt: 'consent'
8. Сервер, не отправляя пока ответ на GET, формирует POST запрос с “Authorization Code”, Client ID и Client Secret:
POST https://oauth2.googleapis.com/token?code=4/0AY0e-g4pg_vSL1PwUWhfDYj3gpiVPUg20qMkTY93JYhmrjttedYwbH376D_BvzZGmjFdmQ&client_id=918876437901-g312pqdhg5bcju4hpr3efknv.apps.googleusercontent.com&client_secret=SUmydv3-7ZDTIh8аНК85chTOt&grant_type=authorization_code&redirect_uri=http://localhost:8081/redirect- oauth2.googleapis.com/token — это endpoint для получения token
- code — только что присланный code
- client_id — Client ID, выданный при регистрации приложения на Google (в примере указан не настоящий)
- client_secret — Client Secret, выданный при регистрации приложения на Google (в примере указан не настоящий)
- grant_type=authorization_code — единственно возможное значение из стандарта
9. Google проверяет присланные данные и формирует “access token” в формате JWT (JSON Web Token), подписанный своим приватным ключом. В этом же JWT может содержаться и “refresh token”, c помощью которого возможно продолжение сессии после ее окончания:
- access_token: 'ya29.a0AfH6SMBH70l6wUe1i_UKfjJ6JCudA_PsIIKXroYvzm_xZjQrCK-7PUPC_U-3sV06g9q7OEWcDWYTFPxoB1StTpqZueraUYVEWisBg46m1kQAtIqhEPodC-USBnKFIztGWxzxXFX47Aag',
- expires_in: 3599,
- refresh_token: '1//0cAa_PK6AlemYCgYIARAAGAwSNwF-L9IrdUt1gzglxh5_L4b_PwoseFlQA1XDhqte7VMzDtg',
- scope: 'openid www.googleapis.com/auth/userinfo.email',
- token_type: 'Bearer',
- id_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImRlZGMwMTJkMDdmNTJhZWRmZDVmOTc3ODRlMWJjYmUyM2MxOTcfobDCf2VrxXb6CCxoL_dZq1WnlEjBZx_Sf6Rg_tn3x4gWtusO1oe_bJx_gvlSLxtvSOdO_kPB2uGGQHr3xzF_Evr-S-BiGS8zMuIkslyN6fU7P7BdNVyOYAIYFvHikyIpAoesV2Fd2yBSngBwGmWfrHL7Z2415UrnlCG4H1Nw'
10. На сервере необходимо провалидировать пришедший id_token:
- Проверяем, что id_token подписан Google. Для этого нужен открытый ключ от Google. Google хранит актуальную аутентификационную информацию по стандартному адресу: https://accounts.google.com/.well-known/openid-configuration. Адрес сертификатов находится в параметре «jwks_uri».
- В токене параметр iss должен содержать адрес Google: accounts.google.com
- Параметр aud должен быть равен Client ID нашего приложения, который получен раннее на сайте Google.
- Параметр exp содержит время окончания действия токена, оно должно быть не просрочено.
После валидации можем использовать информацию, пришедшую в id_token. Для нас самое главное — это подтвержденный email пользователя:
decodedIdToken: {
iss: 'https://accounts.google.com',
azp: '918962537901-gi8oji3qk312pqdhg5.apps.googleusercontent.com',
aud: '918962537901-gi8oji3qk312pqdhg5.apps.googleusercontent.com',
sub: '101987547227421522632',
email: 'work.test.mail.222@gmail.com',
email_verified: true,
at_hash: 'wmbkGMnAKOnfAKtGQFpXQw',
iat: 1606220748,
exp: 1606224348
}11. Проверяем, что email пользователя существует, или создаём нового пользователя c email из токена. При этом SessionId и полученные от Google токены сохраняются в базе.
12. Только теперь отвечаем Google HTTP кодом 307 (Redirect) и заголовком Location c адресом на клиенте:
HTTP Location: http://localhost:8080/googleLogin13. И только теперь Google отвечает браузеру с тем же кодом 307 (Redirect) и заголовком Location с заданным нами адресом
14. Браузер переходит на адрес, указанный в Location и клиент определяет, что произошла успешная аутентификация пользователя с помощью Google аккаунта
15. Клиент, по сохраненному в sessionStorage SessionId, получает на сервере токен и данные пользователя
16. Клиент сохраняет токен в localStorage браузера
На этом процедура аутентификации с помощью Google аккаунта завершена и можно переходить к штатной работе приложения.
Прием, обработка и визуализация данных
Сделаем стандартный вид приложения, как рекомендует Google:
- Drawer (navigation-drawer) в левой стороне
- Меню сверху (v-app-bar)
- Footer внизу (v-footer)
- Для визуализации полученных данных используем карточки (Data Cards)
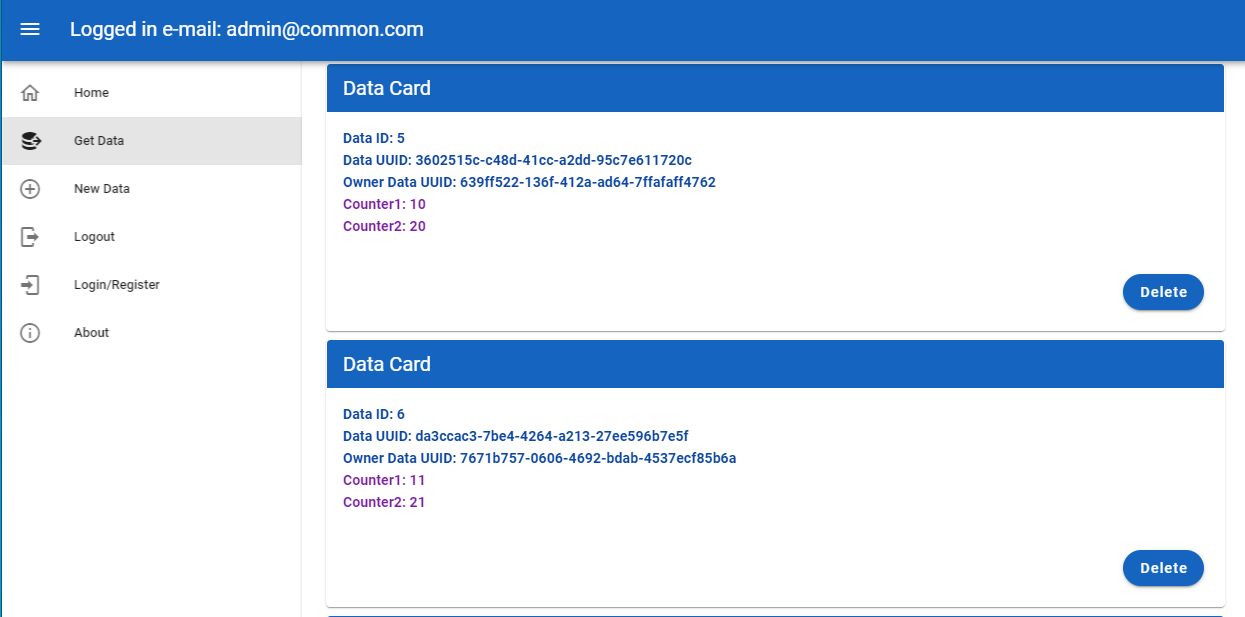
Для создания новых данных используется простая форма ввода:
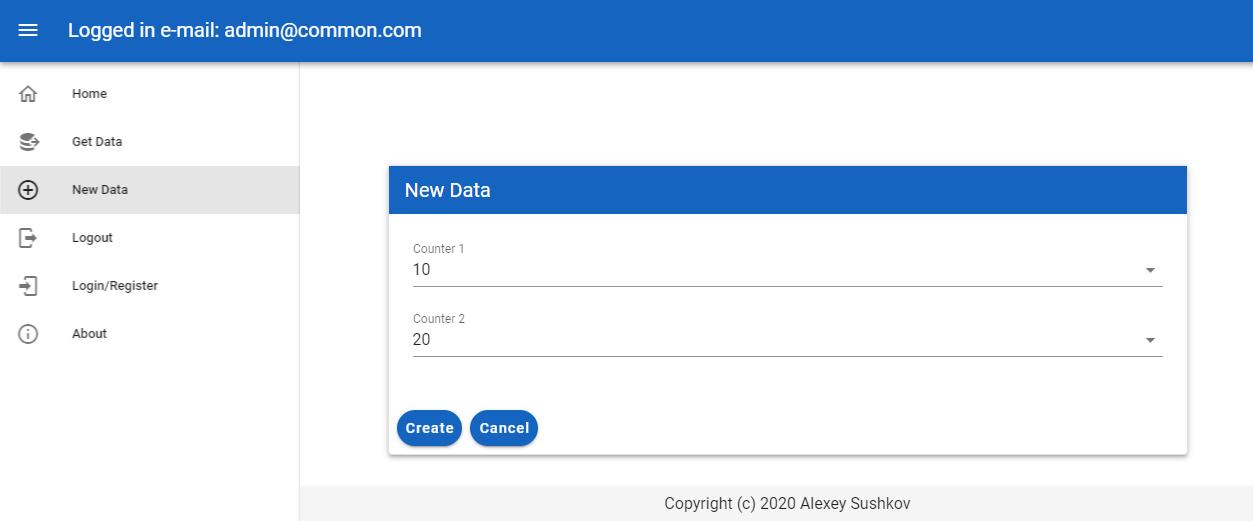
- При переходах между страницами необходимо проверять, что пользователь залогинен и в зависимости от этого отображать или не отображать определенные формы.
- В приложениях, в которых используется больше одной страницы, необходимо передавать данные между формами и элементами интерфейса. Для простых случаев можно записывать данные в localStorage. Для более сложных удобнее использовать специализированные библиотеки, реализующие концепции управления состояниями:
- Для Vue есть библиотека Vuex, реализующая state management pattern.
- Есть универсальная библиотека Redux основанная на Flux от Facebook. Она реализует концепцию состояний, используя понятия action, state, view.
- В примере я использовал Vuex.
- Также необходим Router для реализации переходов между страницами.
Мой опыт показывает, что для создания стандартных графических интерфейсов подходят стандартные средства, позволяющие делать приличные интерфейсы, даже без наличия дизайнерских навыков.
Архитектура
Архитектура — это отдельная большая тема. В данной статье скажу только, что для PoC обычно не требуются архитектурные практики, применяемые в крупных проектах и не всякий PoC станет промышленной системой. Но думать о возможном расширении функциональности, эксплуатации и масштабируемости надо с самого начала.
Заключение
- Мы рассмотрели типичной проект PoC в архитектуре клиент-сервер для использования в вебе.
- Поняли, что даже минимальный проект требует обширных знаний и значительных усилий для реализации.
- В результате получили заготовку, которую можно использовать для начала любых проектов:
Исходники на Github: https://github.com/AlexeySushkov/common-test-db
Пример запущен в облаке Amazon, можно посмотреть, как он выглядит вживую: http://globalid.tech/
Остается только в канун Нового Года пожелать, чтобы сбылись все ваши самые заветные PoC!
It's only the beginning!


lair
Что, простите? Вы вообще в курсе, что такое PoC?
AlexeySushkov Автор
В статье рассматривается PoC, построенный на веб технологиях в архитектуре клиент-сервер. Перечисленный набор компонентов является стандартным для данного класса PoC.
lair
Вы меня извините, но набор компонентов "клиент и сервер" "является стандартным" для "класса архитектур клиент-сервер", при чем тут PoC?
PoC обычно делается как раз чтобы обкатать тот или иной выбор, а вы свой выбор навязали заранее, в чем тут PoC?
AlexeySushkov Автор
Согласен, что из введения не очень понятны ответы на ваши вопросы. Описанное в статье техническое решение, конечно, не PoC, а стандартное веб-приложение. И я предлагаю не PoC, а стандартную основу или заготовку для реализации любых PoC, которые планируется реализовать в клиент-серверной архитектуре с использованием веб-технологий. Чтобы эта заготовка стала настоящим PoC в какой-нибудь области (IoT, телеком, финансы, медицина) к ней, надо прикрутить функциональность взаимодействия с внешними системами.
lair
Эмм… Ну вот мне ваша "стандартная заготовка" вообще не подойдет, даже если я буду делать что-то для веб, потому что у меня полностью другой стек. Ну и какой смысл тогда?
Не говоря о том, что обычно все мои PoC — это проверка технологии, поэтому мне это дважды не сдалось.
AlexeySushkov Автор
Сама заготовка сделана на конкретном стеке технологий: SQLite + Express.js + Vue.js + Node.js. Но статья больше не про технологии, а лучшие практики. Ведь не важно, какой стек технологий используются, в любом случае, нужно обеспечивать безопасность API, реализовывать аутентификацию пользователей, делать структуру базы данных, защищаться от DoS, логировать, мониторить и т.д.
lair
В этом вы как раз не правы. Весь смысл PoC в том, чтобы проверить конкретное предположение. Вам может быть не нужна безопасность, или мониторинг, или аутентификация, или еще что-то.
При этом ваши "лучшие практики", во-первых, спорно реализованы, и во-вторых, полностью зависят от ваших технологий. Если бы я делал PoC для веб-приложения, я бы забил и на DoS, и на мониторинг внутри приложения, потому что для этого есть прекрасный инструментарий снаружи. А приложение пусть бизнесом занимается.