

Der proccess. Микросервисы. От модернизма Франца Кафки к постмодернизму Умберто Эко в информационных технологиях.
Микросервисы на фриварных брокерах типа Kafka — явление в банкинге? Боюсь, что это не явление, а единственный возможный путь развития ИТ-систем в современных реалиях. Почему микросервисы это необходимость, и без них на данный момент сложно обойтись современному банку? И как необходимо их правильно оценивать и правильно внедрять? Какие могут возникнуть проблемы, и какие ситуации необходимо учесть и исключить при проектировании подобных конвейеров? Давайте рассмотрим следующую аналогию, которая приходит на ум после прочтения статьи Пата Хелланда (Pat Helland) из компании Microsoft, названную «Metropolis», в которой он проводит очень интересные параллели между эволюцией информационных технологий и процессами эволюции городов и промышленности. Статья доступна по ссылке [1]. По мнению автора, уровень развития информационных технологий на данный момент соответствует уровню развития процессов урбанизации, промышленного производства и торговли примерно 80-х годов XIX-го века. В это время в сфере розничной торговли господствовали мелкие магазины, предлагающие товар, который требовалось подгонять под заказчика, поскольку не было единых стандартов. Многие промышленные изделия делались под заказ в мелких мастерских. Подобную ситуацию мы имеем в современных российских банках, сталкивающихся с еженедельным изменением ситуации, новыми требованиями Регулятора — Центрального Банка РФ, постоянно меняющимся рынком валют и ценных бумаг и настроением клиентов и бизнеса. Сегодняшняя ситуация такова, что не может единое монолитное, неповоротливое ИТ-решение полностью соответствовать текущему моменту. Авторы статьи рассуждают о том, что эта ситуация с мелкими магазинами и лавочками кардинально изменилась с появлением массового производства с применением сборочных линий и развитием сети железных дорог, что привело к бурному росту распространения стандартизованных товаров. Очевидно, делается вывод, что и в сфере ИТ нам предстоит пережить переход к новому уровню развития систем, основанному на глобальном взаимодействии стандартных компонент. В нашем случае, такими стандартными компонентами становятся банковские конвейеры. И нужно быть готовым к тому, чтобы данные конвейеры могли без особых проблем начать взаимодействовать друг с другом, используя единые интеграционные стандарты.
Давайте поподробнее рассмотрим, почему конвейер (в том числе кредитный или скоринговый) на брокере kafka и насаженных на него микросервисах — это идеальное решение для крупного банка в услових Agile. Прежде всего, kafka бесплатна и не требует специфических условий для разворачивания на сервере. Еще одним важным моментом является ее чрезвычайно высокая производительность и легкость в администрировании. И вот брокер Kafka — это находка для применения микросервисной архитектуры и побега из так называемого «монолитного ада», описанного в литературе, например тут [2]. Чем же плох «монолитный ад» для банка, и почему мы все чаще используем микросервисную архитектуру? Дело в том, чтов текущей ситуации команда разработчиков в банке, как правило, состоит из нескольких scrum-команд, каждая из которых работает над конкретной функциональной областью. Поэтому, разработка в условиях «монолитной»системы (будь то CRM или «Опердень» ) стала медленной и мучительной. Разрабатывать и развертывать код в условиях гибких методологий стало больше невозможно. Цитируя известных методологов микросервисной архитектуры Фута и Йодера, это «беспорядочно структурированные, растянутые, неряшливые, словно перемотанные на скорую руку изоляционной лентой и проводами, джунгли спагетти-кода» [3].
Однако, есть у микросервисного «модернизма» и обратная сторона. После него необходимо производить интеграцию. И вот тут, как черт из табакерки, выскакивает описанное нами ранее «семантическое безумие» [4]. И мы снова имеем эти самые «беспорядочно структурированные, растянутые и неряшливые элементы спагетти-кода», путанную документацию и недели согласований маппингов и моделей данных.Постмордернизм, как явление в науке и искусстве, всегда приходил на смену модернизму. Подразумевает он использование готовых форм. И хорошо бы поставить в противоположность психопатичному и неокончившему большинство своих романов Францу Кафке классика постмодернизма Умберто Эко. И рассуждая в духе вышеупомянутой статьи сотрудников Microsoft — мы вынуждены будем, прийти к неким паттернам, правилам и стандартам при построении «гибких» систем. Другого пути, господа, у нас нет. Иначе построенный нами Метрополис разрушится под собственной тяжестью. Данная статья рассказывет об опыте создания таких паттернов и готовых форм, применяемых компанией Accenture при создании конвейеров в банках. И мы позволили себе, в духе теорий и идей постмодернизма выделить так называемые «культурные единицы», рождающие бурные обсуждения и имеющие место при создании конвейеров в условиях «гибких методологий», и оформить наши доводы и наш опыт в форме рассуждения о них. Попытавшись. тем самым, выделить готовые формы для дальнейшего проектирования конвейеров на микросервисах.
Еще раз о «семантическом безумии» в ИТ-системах
«Правильное восприятие явления и неправильное толкование того же явления никогда полностью взаимно не исключаются»Франц Кафка.«Процесс».
О «семантическом безумии» и о том, как оно возникает и к чему приводит мы писали ранее в блоге компании Accenture. Со статьёй на данную тему можно ознакомиться тут. Еще раз повторим: банк, а тем более, если речь идет о российском банке уровня ТОП-3, это не обычная компания. В банке сталкиваются сотни разных по менталитету людей, как со стороны клиентуры, так и со стороны банковских работников. И вот мы для решения какой-либо банковской задачи имеем конвейер и микросервисную архитектуру на платформе Kafka. Почему микросервисы так удобны в данном случае? Да потому что задача, раздробленная в рамках AGILE на множество подзадач, требует некоего технического решения со схожей структурой и топологией маршрутизации информации, в которой было бы наличие независимых друг от друга сервисов или, как говорят, микросервисов. Каждый микросервис — это отдельная продуктовая команда со своим scrum'ом. И, как следствие, своя модель данных. Что такое модель данных? Модель данных-это концептуальная схема, по которой данные об объектах и субъектах делового оборота перетекают в сообщения в формате JSON или XML. Можно сказать, что модель данных содержит сведения о субъектах, объектах и их атрибутах, которые применяются для отражения процессов делового оборота.
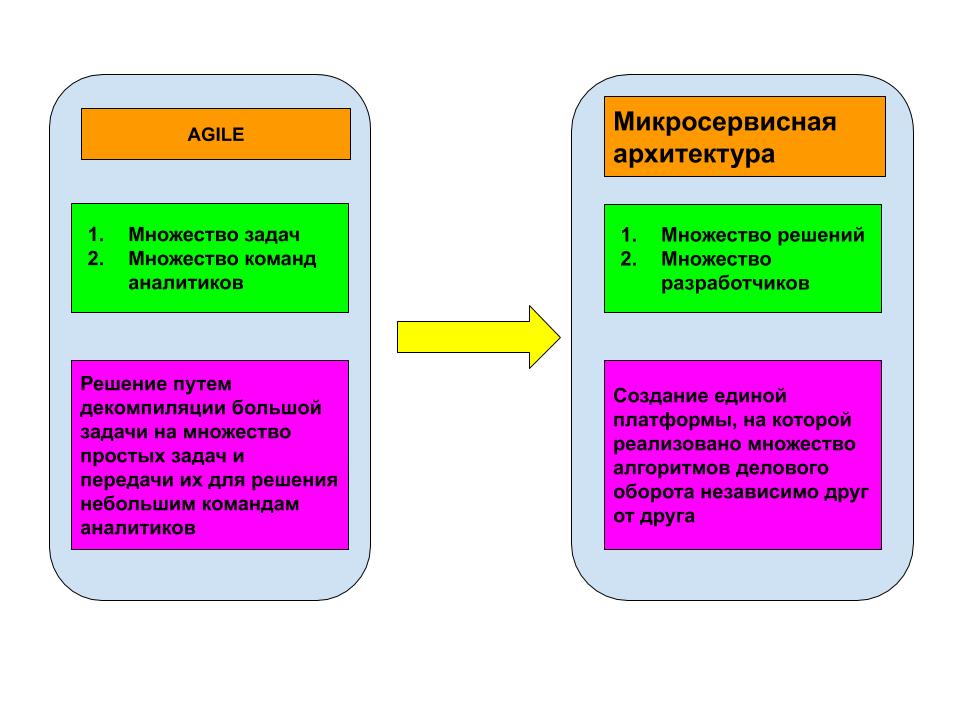 Рисунок 1. Микросервисная архитектура является производной гибких методологий разработки програмного обеспечения.
Рисунок 1. Микросервисная архитектура является производной гибких методологий разработки програмного обеспечения.
Если продолжить рассуждения в том же ключе, то работа аналитика заключается в так называемой разметке предметного поля. Что означает разметить предметное поле? Это значит, что нужно определить субъекты, объекты делового оборота, связи между ними, а также снабдить их достаточным для отображения бизнес-сути атрибутами. После чего составляется модель данных, в которой отображаются и состав объектов и их топология и атрибутивный состав. Если мы говорим о построении некой целостной системы на основе микросервисов, то аналитикам необходимо делать маппинги. То есть, создавать таблицы, на основании которых данные будут перводиться из одной модели данных в другую. И вот тут-то и возникает «семантическое безумие». Аналитика банковских ИТ на 60% времени связана с уяснением семантики передаваемых данных. Возникает одна очень интересная проблема. Часто разные команды называют одну и туже сущность по-разному и, наоборот, разными словами говорят об одной и той же сущности. Чем «семантическое безумие плохо»? В момент интеграции между банковскими системами сталкиваются два аналитика, которые начинают уяснять сущность передаваемых данных, составляя так называемый маппинг. Маппинг нужен для, того чтобы сделать адаптер — то есть точку интеграции, через которую необходимо передать данные из одной системы в другую, не потеряв их изначальной бизнес-сути. И вот как не потерять бизнес-суть в условиях наличия множества моделей данных, субъектов, объектов и атрибутов, суть которых зачастую плохо описана и смутно понятна?
Культурная единица номер один – Адаптеры, как точки интеграции микросервисов.
Давайте рассмотрим подробнее, что же такое эта самая интеграция. Интеграция это процесс обеспечения совместной работы ИТ-сервисов. Интеграция это всегда работа с построением адаптеров. Что такое адаптер? Адаптер это так называемая «точка интеграции». Адаптер это сервис, в котором происходит конвертация данных от одного сервиса для использования их другим микросервисом. Вообще говоря, ESB (интеграционная шина банка) в её строгом определении также можно назвать адаптером. Но все же мы говорим о микросервисах. Конвертация в адаптере может происходить путем XSLT преобразования, в случае, если мы используем XML, или любого другого (как правило, речь идем о преобразовании одного JAVA класса в другой JAVA класс) в случае других форматов (я говорю о JSON). И вот представьте: любое изменение в модели данных — доработка адаптера. Любой запрос на изменение, это в первую очередь работа с адаптерами. Нагрузка на адаптеры определяет производительность конвейера в целом. Попробуйте дать на разработанный в рамках Agile конвейер с неконтролируемым количеством адаптеров нагрузку соотвествующую банку из списка ТОП-3? Как думаете, справится он или нет с ней? Естественно предположить, что чем больше у нас на конвейере моделей данных, тем больше самих адаптеров, и соответственно, больше нагрузка на них и на конвейер в целом.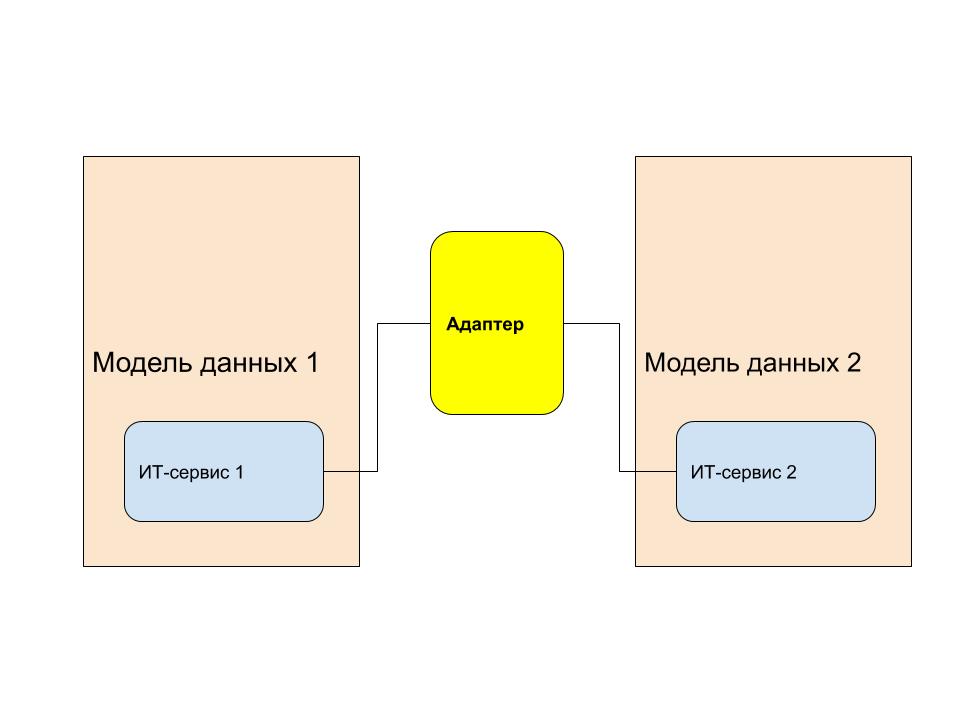 Рисунок 2. Адаптер — сервис, в котором происходит трансформация данных из одной модели в другую.
Рисунок 2. Адаптер — сервис, в котором происходит трансформация данных из одной модели в другую.
Наша идея заключается в том, чтобы бы минимизировать количество таких адаптеров, использовав общепринятые на конвейере стандарты и шаблоны формирования сообщений. А в существующих уже адаптеров сделать нечто, что позволяло бы с лёгкостью вносить изменения, и желательно одними руками, не играя в испорченный телефон между заказчиком, аналитиком, технологом и разработчиком. Поэтому мы реализовываем два основных принципа:
1. Обеспечиваем единую точку входа на конвейер. Единая точка входа это единственный микросервис, который принимает данные из вне и осуществляет их конвертацию в модель данных, используемую внутри разрабатываемого нами конвейера. Таким образом, он является единственным адаптером, на котором, в ряду всего прочего, осуществляется маршрутизация сообщений. При этом, конвертация данных между микросервисами в рамках одной платформы запрещается.
2. Используем модель данных, на основе глобальных бизнес-объектов, которые по своей идее должны устраивать всех участников интеграционного процесса, имея исчерпывающий набор атрибутов. При этом, модель данных должна быть постоянно бесконечно открыта для внесения новых элементов.
Культурная единица номер два. Маршрутизация сообщений на конвейере. Центральный микросервис, как единая точка входа и единственный оркестратор платформы.
Когда-то в военно-морском флоте Советского Союза создали принципиально новую подводную лодку проекта «Лира». Помимо титанового корпуса и реакторов с натриевым охлаждением, в данном проекте было применен новаторский новый подход по организации информационного обмена между боевыми подразделениями корабля, а именно – все технические элементы управления, все командиры боевых частей находились в одном отсеке и могли общаться и обмениваться информацией не используя систему корабельной трансляции. В аварийной обстановке, глубоко под водой, подводники не тратили время на поиск и вызов ответственного и оперативно реагировали на все нештатные ситуации. И как следствие – минимум аварий за 30 лет службы. Хм..., собрать всех главных в одной точке это хорошая идея, для того чтобы применить её в ИТ-системе банка.
Многих специалистов в области микросервисов покоробит эта схема (см. Рисунок 3). Нас неоднократно критиковали за концепцию «единого окна входа» на конвейер. Но… да, в нашей работе мы использовали центральный микросервис, как единую точку входа, на которой осуществлялась валидация данных, пришедших из ESB банка и дальнейшая маршрутизация между микросервисами. Иногда, мы в своей работе называем этот центральный микросервис – единственным оркестратором. Что значит оркестратор? Это означает, что не только прием и отправка сообщений из вне осуществляется через него, но и весь информационный обмен между микросервисами, маршрутизация, валидация данных осуществляется через него.
Какие преимущества дает концепция центрального микросервиса, как единого оркестратора? Прежде всего это нахождение «таблиц маршрутизации» в единственном месте, под контролем одной команды. Второе преимущество это тот факт, что валидация данных из вне, их преобразование, присвоение суррогатных идентификаторов сущностям, для их хранения в базах данных на ковейере также осуществляется в одном месте. И если, необходимы изменения, то аналитик обращается в одну команду за документацией и артефактами.  Рисунок 3. Микросервисная архитектура с центральным микросервсиом, являющимся единой точкой входа на платформу и осуществляющим маршрутизацию между остальными микросервисами, является наиболее оптимальным решением.
Рисунок 3. Микросервисная архитектура с центральным микросервсиом, являющимся единой точкой входа на платформу и осуществляющим маршрутизацию между остальными микросервисами, является наиболее оптимальным решением.
Центральный микросервис осуществляет конвертацию данных, пришедших из вне в схему (XSD или JSONSchema), которую используют микросервисы внутри конвейера. По этой же схеме генерируется классы в JAVA, если это необходимо. Вообще, все сообщения формируются в дальнейшем по этой самой единой схеме. Микросервисы обмениваются друг с другом сообщениями, через данный микросервис. Основные его роли таковы:
1. Прием и отправка данных во внешние системы
2. Ковертация данных
3. Валидация данных
4. Маршрутизация информационных потоков внутри конвейера.
Культрурная единица номер три. Формирование сообщений и передача смысла. Глобальные бизнес-объекты – элементы конструктора для сборки сообщения.
Итак, чем меньше адаптеров, тем быстрее работает платформа. А что если адаптеров вообще не будет?И вот мы подошли к самому главному выводу. Если мы хотим, чтобы платформа работала эффективно и запросы на изменения удовлетворялись наиболее быстрым способом, нам нужна единственная модель данных для всех микросервисов. И вот, как в условии работы различных продуктовых команд, гибкой методологии и различных вендоров это сделать?Ко всем моделям данных, что были у нас на конвейере мы применили описанный ранее алгоритм Jerdella, основанный на векторизации комментариев в маппингах. и получили кластеры атрибутов, которые после визуализации через теорию графов стали отчетливо видны.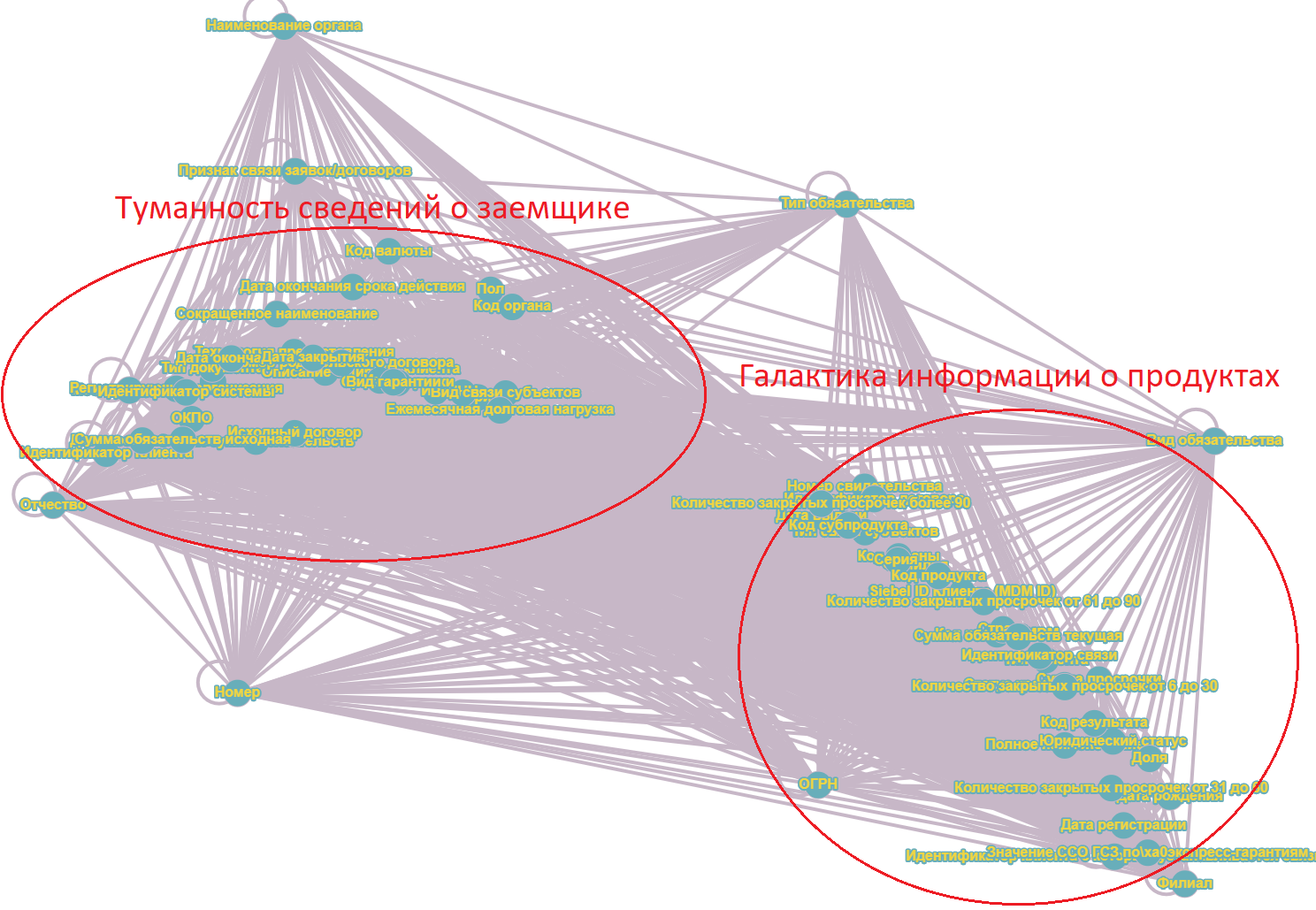 Рисунок 4. Результат работы алгоритма Jerdella. Построение графа взаимосвязи атрибутов, расчитанной путем векторизации комментариев, отнормированного по весам.
Рисунок 4. Результат работы алгоритма Jerdella. Построение графа взаимосвязи атрибутов, расчитанной путем векторизации комментариев, отнормированного по весам.
Дальше, алгоритм был следующий: мы проанализировали «галактики и туманности» и сформировали «столбовые сущности» — то есть сущности, вокруг которых «кучкуются» атрибуты и дополнили их всеми попавшими в пределы «семантической орбиты» атрибутами. Абсолютно понятно, что имеющийся набор атрибутов устроил не всех. Ну и славно, пусть каждый дополнит «столбовые сущности» теми атрибутами, что необходимы, а мы всем имеющимся атрибутам поставим в обязательность false. 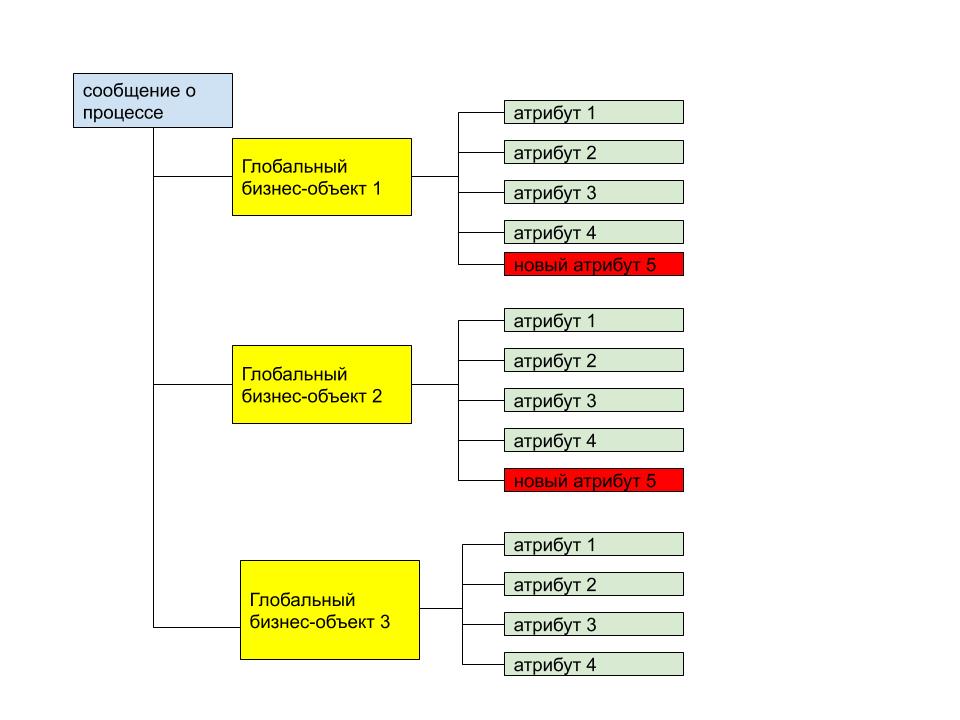 Рисунок 5. Иллюстрация концепции сипользования глобальных бизнес-объектов для набора сообщений. Новые атрибуты глобальных бизнес-сущностей добавляются в конец. Всем атрибутам присваивается обязательность false.
Рисунок 5. Иллюстрация концепции сипользования глобальных бизнес-объектов для набора сообщений. Новые атрибуты глобальных бизнес-сущностей добавляются в конец. Всем атрибутам присваивается обязательность false.
Итак, мы договорились набирать сообщения внутри конвейера только из этих «столбовых сущностей». И столкнулись с проблемой, как заставить всех участников пользоваться только лишь этими атрибутами?
Культурная единица номер четыре. Модель данных. JSONschema и XSD для ведения модели данных.
Генерировать сообщения внутри конвейера нужно по схеме. Точно так же, как когда-то князю Владимиру сказали, что доступ к торговле с Константинополем лежит только через поклонение Единому Богу, мы всем командам мы сказали — хотите что-то делать на нашем конвейере — используйте наши схемы. Для хранения полученных глобальных бизнес-сущностей мы использовали схемы XSD (XML формат) и JSONschema (JSON — форомат). Почему так нужно делать? Да просто концепция схем:
1. Дисциплинирует и заставляет работать в рамках единой модели данных, подразумевающей использование единых сущностей и единого набора атрибутов
2. Уменьшает количество ошибок при внесении изменений. Ошибки делает только лишь аналитик, создающий схему. Разработчик же «прикручивает» данную аналитиком схему к JAVA механизму и вообще не задумывается о сущностях и атрибутах. Потому что, все классы и подклассы у него генерируются по схеме. Обратится к какому-либо атрибуту можно используя xpath для XML и JsonPath для JSON. Поэтому в маппингах чрезвычайно важно прописывать все «пути» для топологии каждого атрибута каждой бизнес-сущности.
3. Первичное тестирование выполняется аналитиком. Схема позволяет проверить валидацию сообщения в формате XML или JSON по сущностям, реально пришедшим со стороны бизнеса. Схемы позволяют устанавливать типы полей, длины строк, максимальные и минимальные значения, вводить правила, устанавливать обязательность и прочее.
Схемы это действительно находка для хранения моделей данных. Причем, в наших предыдущих работах мы говорили, что формат JSON может генерироваться по схеме. Так вот, вынуждены признать — схема для JSON существует. А подробнее о схемах в формате JSON можно почитать тут. Конечно, JSONschema находится на данный момент в своей развитии на том уровне, на котором XSD находилось в 2001 году (стандарт XSD 1.0), на все же, можно сказать, что JSON отчаянно копирует все фишки и стек технологий XML и мы все ждем, когда XSLT сможет преобразовывать JSON формат. И да! Есть предложение добавить обработку JSON в XSLT и эта версия XSLT 4.0 еще не выпущена. А пока способности JSONschema очень примитивны. Про XSD отдельно писать в блоге компании я не вижу смысла, это и так всем известно.
Как работать со схемами? Для этого есть целый стек технологий. Современные языки программирования имеют библиотеки. В python например есть библиотека jsonschema.Кто не знаком или по каким-то причинам не хочет использовать скрипты, тот может использовать следующие продукты — AltovaXMLSpy, LiquidStudio2020 или OxigenXMLEditor. Лучше всего, конечно использовать продукт Altova — он генирует сообщения, визуализирует и все в нем красиво и понятно. Но он платный и не всем компаниям по карману. Набирающий оборот LiquidStudio не станет генерировать сообщения по схемам и визуализировать схему после 15 дневного пробного периода. Однако, он станет работать, как редактор схем через и сможет валидировать схемы, что станет солидным подспорьем. Oxigen в данном случае удобнее всего. У него есть academical версия, в которой доступны все функции. Конечно, он не так круто визуализирует JSON схемы, однако в нем есть возможность осуществлять их трансформацию, генерировать по схемам JAVA классы и все фишки платной версии сохраняются.
Культурная единица номер пять. Единый источник актуальной модели данных. Хранилище модели данныхна основе GIT. Новая роль в «процессе» — Комендант Модели Данных
Комендант это тот, кто следит за порядком в крепости. Часто чистоту модели данных требуется оборонять как крепость от лишних сущностей и атрибутов. Модели данных нужен комендант.
Модель данных должна храниться в мастер-ветке на GIT (в прочем можно использовать какую-либо другую системы с поддержкой версионности) и быть доступной всем командам, участвующим в разработке системы. Аналитик каждой продуктовой команды вносит изменения в модель внутри своей ветки, по мере надобности. После чего, он отправляет pull request для слияния с мастер-веткой. Pull request'ы рассматривает архитектор модели данных. Он либо принимает изменения, либо отклоняет.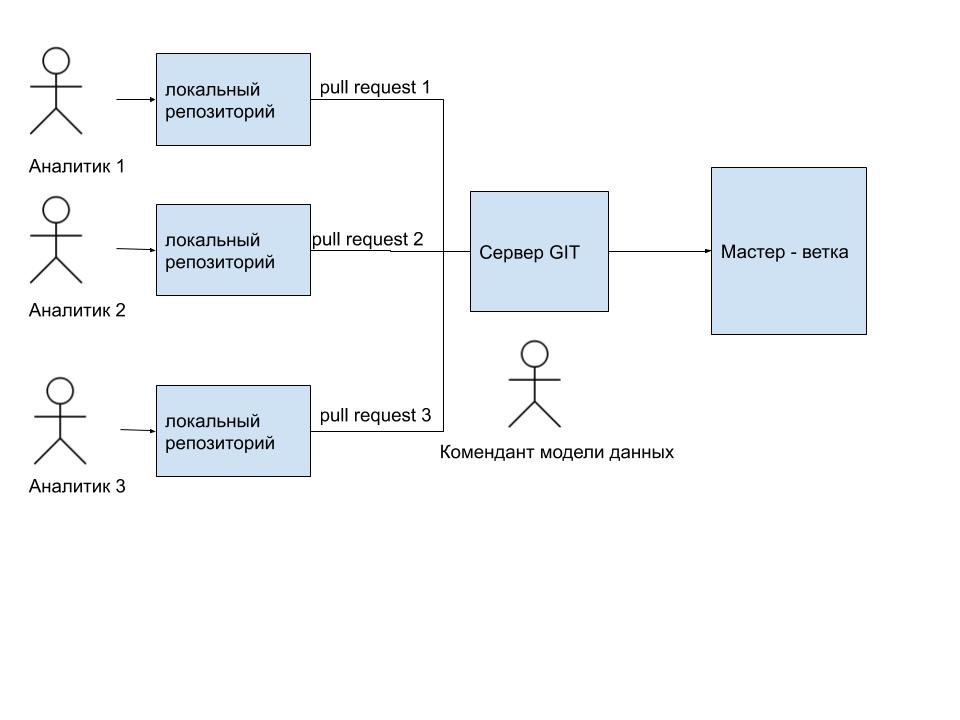 Рисунок 6. Все изменения в сборке схем проходят через архитектора модели данных, который принимает их или отклоняет.
Рисунок 6. Все изменения в сборке схем проходят через архитектора модели данных, который принимает их или отклоняет.
Для изменения модели данных существуют следующие правила:
1. Все атрибуты бизнес-сущностей должны иметь обязательность false. Данное обстоятельство обезопасит от возможности получить ошибку при незаполнении какого-то из них.
2. Никакие существующие атрибуты бизнес-сущностей нельзя удалять. Тут все ясно — если атрибут есть, значит он кем-то уже используется.
3. Новые атрибуты всегда добавляются в конец существующих. Очень просто — так удобнее «мержить» и отслеживать изменения средствами Git.
Сложности и профиты возникающие при использовании данного подхода.
Разве целый год процесса ничему не научил меня? Франц Кафка. «Процесс».
Конечно, данная работа вызовет море вопросов. И мы к ним готовы. Какие основные трудности, с которыми мы столкнулись?
Прежде всего, как бы банально это не звучало, но чрезвычайно трудно дать всем командам доступ на git. Связано это с получением паролей, назначением ролей и прочем в банковском контуре. Команда заходящая на проект часто очень долго ждет и не может получить доступ к мастер ветке и пользуется неактуальной версией, которая зачастую может обносляться ежедневно.
Вторая проблема, о которой хочется сказать, это плохое знание модели участниками процесса. Часто аналитики не вникают в суть уже имеющихся сущностенй и атрибутов и пытаются добавлять новые, которые по свеому смыслу в схемах уже существуют. Если архитектор модели данных не проявит должной внимательности, то мы получим тоже самое «семантическое безумие» в схемах. Конечно, от подобной ситуации спасет ведение какой-либо wiki-системы, типа Confluence или тому прочего, в которой подробно будут описаны сущности и их атрибуты.И тем не менее, описанные в данной статье новшества (хотя вовсем и не новшества, во многих командах и проектах, так или иначе, их применяли и применяют, ибо все описанное взять из предыдущего опыта) позволили сократить время разработки конвейера на 40%. Немаловажным фактом стало также облегчение поиска «артефактов» для оформления документации и предъявления её заказчику. Кстати, по поводу оформления документации в условиях применения «гибких методологий», возможно, будет наша следующая статья.
А пока, хочется сказать спасибо моим друзьям и коллегам за бесценную критику и полезные дискуссии: Ивану Мирохину (банк «Ренессанс»), Сереже Амосову (банк «Центр-Инвест»), Вадиму Карпенко (ПАО «Росбанк»), Андрею Петровскому (Accenture), Эльвире Самигулиной (Accenture), Наталье Сумцовой (Accenture), Антону Ягодинскому (Accenture), Дмитрию Кузину (Accenture), Егору Слесаренко (Accenture), Александру Орешкину (Luxsoft), Екатерине Кошкаровой (DBI), Ирине Блажиной.
Отдельно хотелось бы поблагодарить организаторов аналитических марафонов (https://ux-marafon.ru/) Максима и Александру Хлопониных, за предоставленную возможность оформить вышенаписаное в единую концепцию, выступить и подискутировать со специалистами в области аналитики банковских информационных систем.
Я благодарен следующим авторам за труды, без которых не было бы данной работы:
[1] Pat Helland. Metropolis. Microsoft Corporation. April 2004
[2] Нархид Ния, Шапира Гвен, Палино Тодд. Apache Kafka. Потоковая обработка и анализ данных. – СПб.: Питер, 2020.
[3] Ричардсон Крис. Микросервисы. Паттерны разработки и рефракторинга. – СПб.: Питер, 2020.