

В Apache Cassandra 4.0 будет новое значение по умолчанию для num_tokens! Звучит как незначительное изменение в CHANGES.txt, но по факту это серьезно повлияет на работу кластера. Как новое значение num_tokens скажется на кластере и его поведении?
От редакции: 27 марта приглашаем на открытую онлайн-конференцию Cassandra Day Russia 2021. В программе доклады и воркшопы. Материалы конференции подойдут как начинающим, так и опытным специалистам.
В Apache Cassandra можно настроить очень много параметров. Один из них — num_tokens. Он находится в файле cassandra.yaml вместе с другими параметрами, но, в отличие от многих из них, у него есть дефолтное значение. Суть в том, что большинство параметров Cassandra влияют на кластер только в одном аспекте, а если изменить значение num_tokens, вместе с ним поменяется многое. Команда Apache Cassandra представила изменение CASSANDRA-13701, чтобы уменьшить дефолтное значение num_tokens с 256 до 16. Это важно. Чтобы понять последствия изменения, давайте разберемся, какую роль играет num_tokens в кластере.
Не пытайтесь повторить это в продакшене
Осторожно: никогда-никогда не меняйте параметр num_tokens на ноде после присоединения к кластеру. Как минимум, нода упадет при рестарте. У всех нод в датацентре должно быть одинаковое значение для этого параметра. Исторически так сложилось, что для гетерогенных кластеров ожидались разные значения. Случай редкий, и мы такое не советуем, но в теории можно удвоить значение num_tokens на нодах, которые аппаратно в два раза больше других. У нод в разных датацентрах обычно разные значения num_tokens. Отчасти потому, что изменить это значение в активном кластере можно с нулевым простоем. Мы не будем на этом останавливаться. Если хотите, почитайте про миграцию в новый датацентр.
Основы
Параметр num_tokens влияет на то, как Cassandra распределяет данные по нодам, как данные извлекаются и перемещаются между нодами.
Cassandra использует разметчик, чтобы решить, где в кластере будут храниться данные. Разметчик состоит из алгоритма хеширования, который сопоставляет ключ партиции (первую часть основного ключа) с токеном. Токен определяет, какие ноды будут содержать данные, связанные с этим ключом партиции. Каждой ноде в кластере назначается один или несколько уникальных токенов из кольца токенов (token ring). Говоря простым языком, каждой ноде назначается номер из кругового диапазона номеров, где номер — это хэш токена, а круговой диапазон номеров — кольцо токенов. Кольцо круглое, потому что за максимальным значением идет минимальное.
Назначенный токен определяет диапазон токенов в кольце, приписанный ноде. Диапазон токенов, за который отвечает нода, начинается с назначенного токена, который входит в диапазон. Минимальное значение, ближе всего расположенное к нему против часовой стрелки, в диапазон не входит и обычно принадлежит соседней ноде. Из-за кругового расположения в ноду могут входить одновременно минимальные и максимальные значения токенов в кольце. По крайней мере в одном случае минимальное значение токена против часовой стрелки будет располагаться за максимальным значением.
Например, на следующей схеме назначения токенов кольцо включает хэши от 0 до 99. Токен 10 принадлежит ноде 1. До ноды 1 в кластере располагается нода 5. Ноде 5 принадлежит токен 90. То есть ноде 1 приписаны токены с 91 по 10. В этом случае диапазон включает максимальное значение в кольце.

Схема выше предназначена для одной реплики данных. Дело в том, что каждому токену в кольце назначена только одна нода. Если есть несколько реплик данных, соседние ноды становятся репликами для этого токена, как показано на схеме ниже.

Разметчик определен как согласованный алгоритм хэширования, чтобы вы могли сколько угодно раз отправлять определенные входные данные и всегда получать одно и то же выходное значение. При таком подходе каждая нода (нода-координатор и остальные) всегда вычисляет одинаковый токен для данного ключа партиции. Вычисленный токен можно использовать, чтобы точно указать на ноду с нужными данными.
Следовательно, минимальное и максимальное значения для кольца токенов определяется разметчиком. Например, у дефолтного Murmur3Partitioner на основе Murmur hash минимальное и максимальное значение составляют -2^63 и +2^63 - 1 соответственно. А у прежнего RandomPartitioner (на основе хэша MD5) — от 0 до 2^127 — 1. Главный минус в том, что выбрать разметчик для кластера можно только один раз. Чтобы изменить разметчик, нужно создать новый кластер и перетащить в него данные со старого.
Подробнее о хэшировании см. в документации по Apache Cassandra.
В прежние времена…
До версии 1.2 ноде можно было вручную назначить один токен с помощью параметра initial_token в файле cassandra.yaml. Тогда дефолтным разметчиком был RandomPartitioner. Хотя токены назначались вручную, разметчик незамысловато вычислял назначенные токены при настройке кластера с нуля. Например, если у вас было три кластера, нужно было разделить 2^127 - 1 на 3, чтобы получить значение начального токена. У первой ноды initial_token был бы 0, у второй — (2^127 - 1) / 3, у третьей — (2^127 - 1) / 3 * 2. В итоге у каждой ноды были диапазоны токенов одного размера.
Благодаря равномерному распределению было меньше рисков перегрузки отдельных нод (если ноды на одинаковом железе, а данные так же равномерно распределены по кластеру). Неравномерное распределение токенов может приводить к появлению «горячих точек», в которых нода перегружена, потому что обслуживает больше запросов или содержит больше данных, чем другие ноды.
Хотя кластеры с назначением одного токена настраиваются вручную, деплоймент происходит в обычном режиме. Это особенно важно для очень больших кластеров Cassandra, где нод бывает больше тысячи. Одно из преимуществ такого подхода — равномерное распределение токенов.
С другой стороны, кластер с назначением одного токена гораздо сложнее расширять. Если добавить одну ноду в наш кластер из трех нод, у двух из четырех нод диапазон токенов будет меньше. Чтобы исправить эту проблему и восстановить равновесие, нужно запустить nodetool move и перераспределить токены по всем узлам. Это очень затратная операция, требующая масштабной передачи данных по всему кластеру. Альтернатива — удваивать размер кластера при каждом расширении. Правда, при этом придется задействовать больше оборудования, чем нужно. Чтобы поддерживать равномерное распределение диапазонов по нодам в таком кластере, требуется время и усилия. Или продуманная автоматизация.
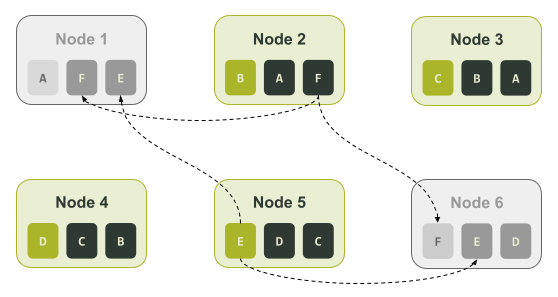
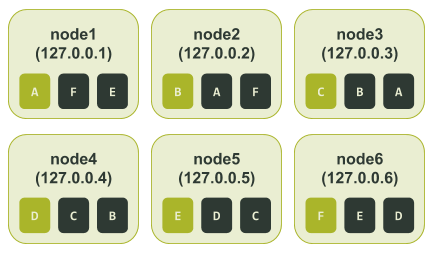
Масштабирование — это только половина проблемы. Иногда это сказывается на восстановлении. Допустим, у вас есть кластер из шести нод с тремя репликами данных в одном датацентре (коэффициент репликации = 3). Реплики могут находиться на ноде 1 и 4, ноде 2 и 5 и, наконец, на ноде 3 и 6. В этом сценарии каждая нода ответственна за одну шестую каждой из трех реплик.

На схеме выше мы назначили токенам буквы, чтобы было проще отслеживать их назначение. Если в кластере возникает сбой и ноды 1 и 6 недоступны, для восстановления недостающих данных можно использовать только ноды 2 и 5: только на ноде 2 есть диапазон F и только на ноде 5 есть диапазон E, как показано на схеме ниже.
Виртуальные ноды спешат на помощь
Чтобы исправить недостатки единого назначения токенов, в Cassandra 1.2 добавлена возможность назначать ноде несколько диапазонов токенов. Эта функция в Cassandra называется виртуальная нода, или vnode. Виртуальные ноды представлены через CASSANDRA-4119. Исходя из описания тикета, виртуальные ноды:
- Упрощают масштабирование.
- Ускоряют восстановление при сбое.
- Равномерно распределяют влияние нагрузки в случае сбоя.
- Равномерно распределяют влияние стриминговых операций.
- Лучше поддерживают однородность оборудования.
С этой функцией в файле cassandra.yaml появился параметр num_tokens. Он определяет число виртуальных нод (диапазон токенов), назначенных ноде. Чем больше это число, тем меньше диапазон. Это связано с тем, что кольцо содержит ограниченное количество токенов. Чем больше диапазонов, тем короче каждый из них.
Чтобы сохранить обратную совместимость с кластерами в версиях до 1.x, num_tokens по умолчанию имеет значение 1. Более того, параметр отключен в ванильной установке, это значение в cassandra.yaml закомментировано. Закомментированная строка и предыдущие коммиты позволяют получить представление о том, как все должно было быть.
Как уже было описано в файле cassandra.yaml и истории коммитов в git, в версии Cassandra 2.0 виртуальные узлы были включены по умолчанию. Строка num_tokens уже не была закомментирована, а дефолтное значение в ванильной установке составляло 256. Таким образом мы вошли в новую эру кластеров с относительно равномерным распределением токенов, которые легко расширять.
Благодаря дополнительным функциям и наличию 256 виртуальных нод на каждой ноде, расширять кластеры стало сплошным удовольствием. Можно было просто вставить новую ноду в кластер, и Cassandra рассчитывала и назначала токены автоматически. Значения токенов вычислялись случайным образом, поэтому по мере добавления новых нод кластер приходил в сбалансированное состояние. Благодаря этим механизмам больше не нужно было тратить часы на вычисления и операции nodetool move, чтобы расширить кластер. Тем не менее, и этот вариант по-прежнему был доступен. Если у вас был очень большой кластер или особые требования, можно было использовать параметр initial_token, закомментированный в Cassandra 2.0. В этом случае все равно надо было задавать для num_tokens число токенов, вручную определенное в параметре initial_token.
Читаем мелкий шрифт
В итоге у нас было что-то вроде персонального devops-ассистента. Мы давали ему ноду и просили добавить ее в кластер, а некоторое время спустя ей назначались токены. Но за дополнительные удобства приходится платить…
Мы получаем более равномерное распределение токенов благодаря 256 узлам, но доступность начинает снижаться раньше. По иронии судьбы, чем короче диапазон токенов, тем быстрее возникает проблема недоступности данных. Если виртуальных нод мало, то есть меньше 32, возникает проблема неравномерного распределения. Cassandra распределяет токены рандомно, но эта стратегия плохо работает с маленьким числом виртуальных нод. Дело в том, что токенов слишком мало, чтобы уравновесить большую разницу в диапазонах.
Пруф или не было
Продемонстрировать проблемы с доступностью и дисбалансом диапазонов токенов можно на тестовом кластере. Настроим кластер с шестью нодами и назначением одного диапазона с помощью ccm. После вычисления токенов, настройки и запуска тестового кластера получаем следующую картину:
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 71.17 KiB 1 33.3% 8d483ae7-e7fa-4c06-9c68-22e71b78e91f rack1
UN 127.0.0.2 65.99 KiB 1 33.3% cc15803b-2b93-40f7-825f-4e7bdda327f8 rack1
UN 127.0.0.3 85.3 KiB 1 33.3% d2dd4acb-b765-4b9e-a5ac-a49ec155f666 rack1
UN 127.0.0.4 104.58 KiB 1 33.3% ad11be76-b65a-486a-8b78-ccf911db4aeb rack1
UN 127.0.0.5 71.19 KiB 1 33.3% 76234ece-bf24-426a-8def-355239e8f17b rack1
UN 127.0.0.6 30.45 KiB 1 33.3% cca81c64-d3b9-47b8-ba03-46356133401b rack1
Создаем тестовое пространство ключей (keyspace) и заполняем его с помощью cqlsh.
$ ccm node1 cqlsh
Connected to SINGLETOKEN at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.11.9 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE test_keyspace WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 };
cqlsh> CREATE TABLE test_keyspace.test_table (
... id int,
... value text,
... PRIMARY KEY (id));
cqlsh> CONSISTENCY LOCAL_QUORUM;
Consistency level set to LOCAL_QUORUM.
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (1, 'foo');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (2, 'bar');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (3, 'net');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (4, 'moo');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (5, 'car');
cqlsh> INSERT INTO test_keyspace.test_table (id, value) VALUES (6, 'set');Чтобы проверить идеальную сбалансированность кластера, проверяем кольцо токенов.
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token
6148914691236517202
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202В столбце Owns видно, что все ноды несут 50% ответственности за данные. Чтобы упростить пример, вручную добавим буквенное обозначение токенов. Получаем:
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
6148914691236517202 F
127.0.0.1 rack1 Up Normal 125.64 KiB 50.00% -9223372036854775808 A
127.0.0.2 rack1 Up Normal 125.31 KiB 50.00% -6148914691236517206 B
127.0.0.3 rack1 Up Normal 124.1 KiB 50.00% -3074457345618258604 C
127.0.0.4 rack1 Up Normal 104.01 KiB 50.00% -2 D
127.0.0.5 rack1 Up Normal 126.05 KiB 50.00% 3074457345618258600 E
127.0.0.6 rack1 Up Normal 120.76 KiB 50.00% 6148914691236517202 FБерем выходные данные ccm node1 nodetool describering test_keyspace и меняем номера токенов на буквы.
$ ccm node1 nodetool describering test_keyspace
Schema Version:6256fe3f-a41e-34ac-ad76-82dba04d92c3
TokenRange:
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:F, end_token:A, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])По выходным данным, особенно по значению end_token, можно определить все диапазоны токенов, назначенные каждой ноде. Как мы уже говорили, диапазон токенов определяется значениями после предыдущего токена (start_token) вплоть до назначенного токена включительно (end_token). Нодам назначены следующие диапазоны:
Если ноды 3 и 6 будут недоступны, мы потеряем целую реплику. Даже если в приложении настроен уровень согласованности LOCAL_QUORUM, все данные доступны. У нас остается две реплики на оставшихся четырех нодах.
Рассмотрим случай, когда кластер использует виртуальные ноды. Для примера установим число num_tokens — 3. Так будет проще понять, что происходит. Настраиваем и запускаем ноды в ccm. Тестовый кластер выглядит так.
Если в продакшене у кластера меньше 500 нод, для num_tokens лучше выбрать число побольше. См. рекомендации по продакшену для Apache Cassandra.
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 71.21 KiB 3 46.2% 7d30cbd4-8356-4189-8c94-0abe8e4d4d73 rack1
UN 127.0.0.2 66.04 KiB 3 37.5% 16bb0b37-2260-440c-ae2a-08cbf9192f85 rack1
UN 127.0.0.3 90.48 KiB 3 28.9% dc8c9dfd-cf5b-470c-836d-8391941a5a7e rack1
UN 127.0.0.4 104.64 KiB 3 20.7% 3eecfe2f-65c4-4f41-bbe4-4236bcdf5bd2 rack1
UN 127.0.0.5 66.09 KiB 3 36.1% 4d5adf9f-fe0d-49a0-8ab3-e1f5f9f8e0a2 rack1
UN 127.0.0.6 71.23 KiB 3 30.6% b41496e6-f391-471c-b3c4-6f56ed4442d6 rack1Мы сразу видим признаки несбалансированности в кластере. Как и в примере с назначением одного токена, здесь мы создаем тестовое keyspace и заполняем его с помощью cqlsh. Смотрим, как распределено кольцо токенов (здесь тоже добавим буквенное обозначение).
$ ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8828652533728408318 R
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% -7586808982694641609 A
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -6737339388913371534 B
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -5657740186656828604 C
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% -3714593062517416200 D
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% -2697218374613409116 E
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% -1044956249817882006 F
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% -877178609551551982 G
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% -852432543207202252 H
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 117262867395611452 I
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 762725591397791743 J
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 1416289897444876127 K
127.0.0.1 rack1 Up Normal 126.49 KiB 64.03% 3730403440915368492 L
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 4190414744358754863 M
127.0.0.2 rack1 Up Normal 126.04 KiB 66.60% 6904945895761639194 N
127.0.0.5 rack1 Up Normal 121.09 KiB 41.44% 7117770953638238964 O
127.0.0.4 rack1 Up Normal 110.22 KiB 47.96% 7764578023697676989 P
127.0.0.3 rack1 Up Normal 135.71 KiB 39.89% 8123167640761197831 Q
127.0.0.6 rack1 Up Normal 126.58 KiB 40.07% 8828652533728408318 RВ столбце Owns видим дисбаланс. У ноды 127.0.0.3 самая маленькая доля — 39.89%, а у ноды 127.0.0.2 — самая большая (66.6%). Разница в 26%!
Снова берем выходные данные ccm node1 nodetool describering test_keyspace и меняем номера токенов на буквы.
$ ccm node1 nodetool describering test_keyspace
Schema Version:4b2dc440-2e7c-33a4-aac6-ffea86cb0e21
TokenRange:
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.4, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.6, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.1, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.2, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.6, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.5, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.6], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack1)])Наконец, смотрим, как диапазоны токенов распределены по нодам. Нодам назначены следующие диапазоны:

Что будет, если и здесь ноды 3 и 6 будут недоступны? Ноды 3 и 6 отвечают за токены C, D, I, J, P и Q. Выходит, что данные, связанные с этим токенами, будут недоступны, если приложение использует уровень согласованности LOCAL_QUORUM. Иными словами, в отличие от кластера с назначением одного токена, мы потеряем доступ к 33,3% данных.
Добавляем стойки
Опытный пользователь Cassandra заметит, что мы тестили распределение токенов в кластерах только в одной стойке. Давайте добавим стойки, чтобы повысить доступность при использовании виртуальных нод. Если стоек несколько, Cassandra попытается распределить реплики по ним, чтобы в одной стойке не было двух одинаковых диапазонов.
Надо настроить кластер таким образом, чтобы в одном датацентре число стоек совпадало с коэффициентом репликации.
Возьмем предыдущий пример, где для параметра num_tokens мы выбрали значение 3, только на этот раз определим в тестовом кластере три стойки. Настраиваем и запускаем ноды в ccm. Тестовый кластер выглядит так:
$ ccm node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 127.0.0.1 71.08 KiB 3 31.8% 49df615d-bfe5-46ce-a8dd-4748c086f639 rack1
UN 127.0.0.2 71.04 KiB 3 34.4% 3fef187e-00f5-476d-b31f-7aa03e9d813c rack2
UN 127.0.0.3 66.04 KiB 3 37.3% c6a0a5f4-91f8-4bd1-b814-1efc3dae208f rack3
UN 127.0.0.4 109.79 KiB 3 52.9% 74ac0727-c03b-476b-8f52-38c154cfc759 rack1
UN 127.0.0.5 66.09 KiB 3 18.7% 5153bad4-07d7-4a24-8066-0189084bbc80 rack2
UN 127.0.0.6 66.09 KiB 3 25.0% 6693214b-a599-4f58-b1b4-a6cf0dd684ba rack3Кластер все равно не сбалансирован. Это не так важно. Главное, мы видим, что теперь у нас три стойки и на каждой по две ноды. Снова создаем тестовое keyspace и заполняем его с помощью cqlsh. Смотрим, как распределено кольцо токенов (опять добавляем буквенное обозначение).
ccm node1 nodetool ring test_keyspace
Datacenter: datacenter1
==========
Address Rack Status State Load Owns Token Token Letter
8993942771016137629 R
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% -8459555739932651620 A
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -8458588239787937390 B
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% -8347996802899210689 C
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% -5712162437894176338 D
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% -2744262056092270718 E
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% -2132400046698162304 F
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% -1232974565497331829 G
127.0.0.4 rack1 Up Normal 111.07 KiB 53.84% 1026323925278501795 H
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3093888090255198737 I
127.0.0.2 rack2 Up Normal 121.42 KiB 65.35% 3596129656253861692 J
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 3674189467337391158 K
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 3846303495312788195 L
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 4699181476441710984 M
127.0.0.1 rack1 Up Normal 121.31 KiB 46.16% 6795515568417945696 N
127.0.0.3 rack3 Up Normal 116.12 KiB 60.72% 7964270297230943708 O
127.0.0.5 rack2 Up Normal 122.42 KiB 34.65% 8105847793464083809 P
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8813162133522758143 Q
127.0.0.6 rack3 Up Normal 122.39 KiB 39.28% 8993942771016137629 RСнова берем выходные данные ccm node1 nodetool describering test_keyspace и меняем номера токенов на буквы.
$ ccm node1 nodetool describering test_keyspace
Schema Version:aff03498-f4c1-3be1-b133-25503becf208
TokenRange:
TokenRange(start_token:B, end_token:C, endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], rpc_endpoints:[127.0.0.3, 127.0.0.1, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:L, end_token:M, endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], rpc_endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:N, end_token:O, endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:P, end_token:Q, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:K, end_token:L, endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.1, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:R, end_token:A, endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.5, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:I, end_token:J, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:Q, end_token:R, endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.5, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:E, end_token:F, endpoints:[127.0.0.6, 127.0.0.2, 127.0.0.4], rpc_endpoints:[127.0.0.6, 127.0.0.2, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:H, end_token:I, endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], rpc_endpoints:[127.0.0.2, 127.0.0.3, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:D, end_token:E, endpoints:[127.0.0.4, 127.0.0.6, 127.0.0.2], rpc_endpoints:[127.0.0.4, 127.0.0.6, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:A, end_token:B, endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.2], rpc_endpoints:[127.0.0.4, 127.0.0.3, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:C, end_token:D, endpoints:[127.0.0.1, 127.0.0.6, 127.0.0.2], rpc_endpoints:[127.0.0.1, 127.0.0.6, 127.0.0.2], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2)])
TokenRange(start_token:F, end_token:G, endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.3], rpc_endpoints:[127.0.0.2, 127.0.0.4, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:O, end_token:P, endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.4], rpc_endpoints:[127.0.0.5, 127.0.0.6, 127.0.0.4], endpoint_details:[EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.6, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:J, end_token:K, endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.1], rpc_endpoints:[127.0.0.3, 127.0.0.5, 127.0.0.1], endpoint_details:[EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1)])
TokenRange(start_token:G, end_token:H, endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.3], rpc_endpoints:[127.0.0.4, 127.0.0.2, 127.0.0.3], endpoint_details:[EndpointDetails(host:127.0.0.4, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.2, datacenter:datacenter1, rack:rack2), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3)])
TokenRange(start_token:M, end_token:N, endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], rpc_endpoints:[127.0.0.1, 127.0.0.3, 127.0.0.5], endpoint_details:[EndpointDetails(host:127.0.0.1, datacenter:datacenter1, rack:rack1), EndpointDetails(host:127.0.0.3, datacenter:datacenter1, rack:rack3), EndpointDetails(host:127.0.0.5, datacenter:datacenter1, rack:rack2)])Наконец, смотрим, как диапазоны токенов распределены по нодам:

Судя по назначению токенов, теперь у нас есть полная реплика данных, распределенная по двум узлам в каждой из трех стоек. Если ноды 3 и 6 упадут, мы все равно сможем обслуживать запросы с уровнем согласованности LOCAL_QUORUM. Здесь бросается в глаза нода 3, у которой гораздо больше токенов, чем у других. Ее сосед по стойке, нода 6, наоборот, содержит меньше всего токенов.
Не переборщите с виртуальными нодами
Если при небольшом числе виртуальных нод возникают проблемы распределения, логично предположить, что лучше выбирать число побольше. Но кроме риска потерять доступ к данным при сбое нескольких нод, мы получаем снижение производительности при передаче данных. Чтобы восстановить данные на ноде, Cassandra запускает по одному сеансу восстановления на виртуальную ноду. Сеансы обрабатываются последовательно. Чем больше виртуальных нод, тем больше времени и ресурсов на это уйдет.
Чтобы ускорить восстановление при большом количестве виртуальных нод, в версии 3.0 представлено изменение CASSANDRA-5220. Благодаря этому Cassandra объединяет несколько диапазонов для набора нод в один сеанс восстановления. Сеанс выполняется дольше, зато их стало меньше.
Давайте проверим влияние виртуальных нод на восстановление, проведя простой тест на кластере на реальном оборудовании. Для этого создадим кластер с единичным назначением токенов и запустим восстановление. Затем создадим такой же кластер, но с 256 виртуальными нодами, и снова запустим восстановление. Используем tlp-cluster, чтобы создать кластер Cassandra в AWS со следующими свойствами.
- Размер инстанса: i3.2xlarge
- Число нод: 12
- Число стоек: 3 (по 4 ноды на стойку)
- Версия Cassandra: 3.11.9
Команды для сборки кластера:
$ tlp-cluster init --azs a,b,c --cassandra 12 --instance i3.2xlarge --stress 1 TLP BLOG "Blogpost repair testing"
$ tlp-cluster up
$ tlp-cluster use --config "cluster_name:SingleToken" --config "num_tokens:1" 3.11.9
$ tlp-cluster installВыделив оборудование, задаем свойство initial_token для каждой ноды по отдельности. Вычисляем начальные токены для каждой ноды простой командой Python.
Python 2.7.16 (default, Nov 23 2020, 08:01:20)
[GCC Apple LLVM 12.0.0 (clang-1200.0.30.4) [+internal-os, ptrauth-isa=sign+stri on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> num_tokens = 1
>>> num_nodes = 12
>>> print("\n".join(['[Node {}] initial_token: {}'.format(n + 1, ','.join([str(((2**64 / (num_tokens * num_nodes)) * (t * num_nodes + n)) - 2**63) for t in range(num_tokens)])) for n in range(num_nodes)]))
[Node 1] initial_token: -9223372036854775808
[Node 2] initial_token: -7686143364045646507
[Node 3] initial_token: -6148914691236517206
[Node 4] initial_token: -4611686018427387905
[Node 5] initial_token: -3074457345618258604
[Node 6] initial_token: -1537228672809129303
[Node 7] initial_token: -2
[Node 8] initial_token: 1537228672809129299
[Node 9] initial_token: 3074457345618258600
[Node 10] initial_token: 4611686018427387901
[Node 11] initial_token: 6148914691236517202
[Node 12] initial_token: 7686143364045646503После запуска Cassandra на всех нодах можно загрузить около 3 ГБ данных на ноду с помощью команды tlp-stress. В этой команде мы задаем для keyspace коэффициент репликации 3, а для gc_grace_seconds устанавливаем 0. Срок действия хинтов будет истекать сразу после создания, то есть они никогда не попадут на целевую ноду.
ubuntu@ip-172-31-19-180:~$ tlp-stress run KeyValue --replication "{'class': 'NetworkTopologyStrategy', 'us-west-2':3 }" --cql "ALTER TABLE tlp_stress.keyvalue WITH gc_grace_seconds = 0" --reads 1 --partitions 100M --populate 100M --iterations 1
После загрузки данных статус кластера выглядит так:
ubuntu@ip-172-31-30-95:~$ nodetool status
Datacenter: us-west-2
=====================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.31.30.95 2.78 GiB 1 25.0% 6640c7b9-c026-4496-9001-9d79bea7e8e5 2a
UN 172.31.31.106 2.79 GiB 1 25.0% ceaf9d56-3a62-40be-bfeb-79a7f7ade402 2a
UN 172.31.2.74 2.78 GiB 1 25.0% 4a90b071-830e-4dfe-9d9d-ab4674be3507 2c
UN 172.31.39.56 2.79 GiB 1 25.0% 37fd3fe0-598b-428f-a84b-c27fc65ee7d5 2b
UN 172.31.31.184 2.78 GiB 1 25.0% 40b4e538-476a-4f20-a012-022b10f257e9 2a
UN 172.31.10.87 2.79 GiB 1 25.0% fdccabef-53a9-475b-9131-b73c9f08a180 2c
UN 172.31.18.118 2.79 GiB 1 25.0% b41ab8fe-45e7-4628-94f0-a4ec3d21f8d0 2a
UN 172.31.35.4 2.79 GiB 1 25.0% 246bf6d8-8deb-42fe-bd11-05cca8f880d7 2b
UN 172.31.40.147 2.79 GiB 1 25.0% bdd3dd61-bb6a-4849-a7a6-b60a2b8499f6 2b
UN 172.31.13.226 2.79 GiB 1 25.0% d0389979-c38f-41e5-9836-5a7539b3d757 2c
UN 172.31.5.192 2.79 GiB 1 25.0% b0031ef9-de9f-4044-a530-ffc67288ebb6 2c
UN 172.31.33.0 2.79 GiB 1 25.0% da612776-4018-4cb7-afd5-79758a7b9cf8 2bЗапускаем полное восстановление на каждой ноде:
$ source env.sh
$ c_all "nodetool repair -full tlp_stress"Время восстановления для каждой ноды:
[2021-01-22 20:20:13,952] Repair command #1 finished in 3 minutes 55 seconds
[2021-01-22 20:23:57,053] Repair command #1 finished in 3 minutes 36 seconds
[2021-01-22 20:27:42,123] Repair command #1 finished in 3 minutes 32 seconds
[2021-01-22 20:30:57,654] Repair command #1 finished in 3 minutes 21 seconds
[2021-01-22 20:34:27,740] Repair command #1 finished in 3 minutes 17 seconds
[2021-01-22 20:37:40,449] Repair command #1 finished in 3 minutes 23 seconds
[2021-01-22 20:41:32,391] Repair command #1 finished in 3 minutes 36 seconds
[2021-01-22 20:44:52,917] Repair command #1 finished in 3 minutes 25 seconds
[2021-01-22 20:47:57,729] Repair command #1 finished in 2 minutes 58 seconds
[2021-01-22 20:49:58,868] Repair command #1 finished in 1 minute 58 seconds
[2021-01-22 20:51:58,724] Repair command #1 finished in 1 minute 53 seconds
[2021-01-22 20:54:01,100] Repair command #1 finished in 1 minute 50 secondsПонадобилось 36 минут 44 секунды.
На этом же кластере можно измерить время восстановления, когда используется 256 нод. Делаем следующее.
- Завершаем работу Cassandra на всех нодах.
- Удаляем содержимое каждого каталога data, commitlog, hints и saved_caches (они находятся в /var/lib/cassandra/ на каждой ноде).
- Задаем для параметра num_tokens в файле конфигурации cassandra.yaml значение 256 и удаляем параметр initial_token.
- Запускаем Cassandra на всех нодах.
После заполнения кластера данными статус выглядит так:
ubuntu@ip-172-31-30-95:~$ nodetool status
Datacenter: us-west-2
=====================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 172.31.30.95 2.79 GiB 256 24.3% 10b0a8b5-aaa6-4528-9d14-65887a9b0b9c 2a
UN 172.31.2.74 2.81 GiB 256 24.4% a748964d-0460-4f86-907d-a78edae2a2cb 2c
UN 172.31.31.106 3.1 GiB 256 26.4% 1fc68fbd-335d-4689-83b9-d62cca25c88a 2a
UN 172.31.31.184 2.78 GiB 256 23.9% 8a1b25e7-d2d8-4471-aa76-941c2556cc30 2a
UN 172.31.39.56 2.73 GiB 256 23.5% 3642a964-5d21-44f9-b330-74c03e017943 2b
UN 172.31.10.87 2.95 GiB 256 25.4% 540a38f5-ad05-4636-8768-241d85d88107 2c
UN 172.31.18.118 2.99 GiB 256 25.4% 41b9f16e-6e71-4631-9794-9321a6e875bd 2a
UN 172.31.35.4 2.96 GiB 256 25.6% 7f62d7fd-b9c2-46cf-89a1-83155feebb70 2b
UN 172.31.40.147 3.26 GiB 256 27.4% e17fd867-2221-4fb5-99ec-5b33981a05ef 2b
UN 172.31.13.226 2.91 GiB 256 25.0% 4ef69969-d9fe-4336-9618-359877c4b570 2c
UN 172.31.33.0 2.74 GiB 256 23.6% 298ab053-0c29-44ab-8a0a-8dde03b4f125 2b
UN 172.31.5.192 2.93 GiB 256 25.2% 7c690640-24df-4345-aef3-dacd6643d6c0 2cЗапускаем тот же тест восстановления, что и раньше:
[2021-01-22 22:45:56,689] Repair command #1 finished in 4 minutes 40 seconds
[2021-01-22 22:50:09,170] Repair command #1 finished in 4 minutes 6 seconds
[2021-01-22 22:54:04,820] Repair command #1 finished in 3 minutes 43 seconds
[2021-01-22 22:57:26,193] Repair command #1 finished in 3 minutes 27 seconds
[2021-01-22 23:01:23,554] Repair command #1 finished in 3 minutes 44 seconds
[2021-01-22 23:04:40,523] Repair command #1 finished in 3 minutes 27 seconds
[2021-01-22 23:08:20,231] Repair command #1 finished in 3 minutes 23 seconds
[2021-01-22 23:11:01,230] Repair command #1 finished in 2 minutes 45 seconds
[2021-01-22 23:13:48,682] Repair command #1 finished in 2 minutes 40 seconds
[2021-01-22 23:16:23,630] Repair command #1 finished in 2 minutes 32 seconds
[2021-01-22 23:18:56,786] Repair command #1 finished in 2 minutes 26 seconds
[2021-01-22 23:21:38,961] Repair command #1 finished in 2 minutes 30 secondsИтого — 39 минут 23 секунды.
Для 3 ГБ данных на ноду разница терпимая (где-то по 45 секунд на ноду), но мы понимаем, что отставание будет существенным, если на каждой ноде будут сотни гигабайт.
К сожалению, такие операции, как инициализация и ребилд датацентра, тоже пострадают от большого числа виртуальных нод. Когда нода передает данные на другую ноду, сеанс передачи открывается для каждого диапазона токенов на ноде. Это приводит к слишком большим издержкам, поскольку данные передаются через JVM.
Проблемы со вторичными индексами
Мало того, большое число виртуальных нод влияет на вторичные индексы. Это связано с тем, как устроен путь чтения.
Когда нода-координатор получает от клиента запрос со вторичным индексом, она рассылает его по всем нодам в кластере или датацентре, в зависимости от уровня согласованности. Каждая нода проверяет SSTables для каждого диапазона токенов, назначенного ей, в поисках соответствия этому запросу. Соответствия возвращаются на ноду-координатор.
Поэтому чем больше виртуальных нод, тем медленнее отклик для такого запроса. Более того, ухудшение производительности для вторичных индексов резко возрастает при увеличении числа реплик на кластере. Если в нескольких датацентрах есть ноды, использующие много виртуальных нод, вторичные индексы становятся еще менее эффективными.
Новая надежда
Итак, в Cassandra есть свойство, которое существенно упрощает изменение размера кластера. К сожалению, за это приходится платить несбалансированными диапазонами токенов и снижением производительности операций. Но это еще не вся история.
Все уже прекрасно знают, что в Apache Cassandra большое число виртуальных нод имеет побочные эффекты. Чтобы решить эту проблему, изобретательные участники сообщества добавили в версию 3.0 CASSANDRA-7032 — алгоритм распределения токенов, учитывающий реплики, чтобы можно было использовать небольшое значение для num_tokens при сохранении относительно равномерного распределения диапазонов. Сюда входит добавление параметра allocate_tokens_for_keyspace в файл cassandra.yaml. Новый алгоритм используется вместо случайного распределителя токенов. Он назначает существующему пользовательскому keyspace параметр allocate_tokens_for_keyspace.
Cassandra, на основе коэффициента репликации для keyspace, рассчитывает значения токенов для ноды при ее добавлении в кластер. В отличие от случайного генератора токенов, генератор, учитывающий реплики, похож на опытного музыканта симфонического оркестра, играющего в унисон с коллегами. До такой степени, что при генерации диапазонов токенов он:
- Создает начальное состояние кольца токенов.
- Вычисляет кандидатов для новых токенов, разделяя все существующие диапазоны посредине.
- Оценивает ожидаемые улучшения от всех кандидатов, формируя приоритетную очередь.
- Проверяет всех кандидатов в очереди и выбирает лучшую комбинацию.
- Во время выбора токенов пересматривает улучшения кандидатов в очереди.
Для Cassandra это был большой прогресс, но не обошлось и без подводных камней. Во-первых, алгоритм работает только с разметчиком Murmur3Partitioner. Если у вас в кластере используется другой разметчик, например, RandomPartitioner, и вы проапгрейдились до 3.0, эта функция не будет работать. Вторая, более распространенная сложность в том, что для использования этой функции при создании кластера с нуля придется постараться. Есть отдельный пост о том, как использовать новый алгоритм распределения токенов с учетом реплик для настройки нового кластера с равномерным распределением токенов.
Как видите, в Cassandra 3.0 была предпринята честная попытка сгладить острые углы виртуальных нод. В релизе Cassandra 4.0 появились новые улучшения в этой сфере. Например, в файл cassandra.yaml добавлен новый параметр allocate_tokens_for_local_replication_factorчерез CASSANDRA-15260. Как и его двоюродный брат allocate_tokens_for_keyspace, он активирует алгоритм распределения токенов с учетом реплик, если указать для него значение.
Но использовать его гораздо проще и приятнее, потому что с ним создание сбалансированного кластера с нуля не требует столько усилий. В простейшем случае достаточно задать значение для allocate_tokens_for_local_replication_factor, а потом просто добавлять ноды. Продвинутые пользователи все еще могут вручную назначать токены для начальных нод, чтобы сохранить желаемый коэффициент репликации. Последующие ноды можно добавлять со значением коэффициента репликации, назначенным параметру allocate_tokens_for_local_replication_factor.
Пожалуй, самым ожидаемым и важным изменением в Cassandra 4.0 стало изменение дефолтного значения для параметра num_tokens. Как мы уже говорили, благодаря изменению CASSANDRA-13701 в Cassandra 4.0 в файле cassandra.yaml для num_tokens установлено значение 16. Кроме того, параметр allocate_tokens_for_local_replication_factor включен по умолчанию и имеет значение 3.
Эти дефолтные параметры гораздо лучше. В ванильной установке Cassandra 4.0 алгоритм распределения токенов с учетом реплик начинает работать, как только появляется достаточно хостов, чтобы соблюсти коэффициент репликации 3. В результате имеем равномерное распределение диапазонов токенов для новых нод со всеми преимуществами, которое дает малое число виртуальных нод.
Заключение
Согласованное хэширование и распределение токенов — это основа Cassandra. Благодаря виртуальным нодам с этими важными функциями не придется работать наугад, в частности, изменять размер кластера можно гораздо быстрее и проще. Как правило, чем меньше виртуальных нод, тем менее равномерным будет распределение, поэтому на некоторые ноды ляжет больше нагрузки. Чем больше виртуальных нод, тем больше времени потребуется на операции, охватывающие весь кластер, и тем выше вероятность, что данные будут недоступны при сбое нескольких узлов одновременно. Функции в версии 3.0 и улучшения этих функций в 4.0 позволяют использовать в Cassandra меньше виртуальных нод, но при этом добиться относительно равномерного распределения токенов. В конце концов, новым пользователям будет гораздо удобнее использовать ванильную установку Cassandra 4.0 без дополнительной настройки.