
Полное руководство по развертыванию, логированию, распределенной трассировке, производительности и мониторингу метрик, включая состояние кластера.
Привет, Хабр. В рамках курса "Microservice Architecture" подготовили для вас перевод материала.
Также приглашаем на открытый вебинар по теме «Распределенные очереди сообщений на примере кафки».

Вам нужны наблюдаемые микросервисы, но вы еще не знаете, как их реализовать с помощью Kubernetes? Ну что ж… возможно это именно та статья, которую вы искали.
Во-первых, давайте разберемся, что такое наблюдаемость. Этот термин возник в инженерии систем управления и был определен как «мера того, насколько хорошо могут быть определены внутренние состояния системы на основе информации о ее внешних выводах». Проще говоря, наблюдаемость подразумевает адекватное понимание системы, способствующее корректирующим действиям.
Наблюдаемость зиждется на трех столпах:
Логи (журналы) событий: запись событий, произошедших в системе. События (events) дискретны и содержат метаданные о системе на тот момент, когда они происходили.
Трассировка (трейсинг): система обычно состоит из множества частей/компонентов, которые согласованно работают для выполнения определенных важных функций. Отслеживание потока запросов и ответов через распределенные компоненты критически важно для эффективной отладки/устранения неполадок конкретной функциональности.
Метрики: производительность системы, измеряемая на протяжении определенного периода времени. Они отражают качество обслуживания системы.
Теперь к насущному вопросу — как все это реализовать для наших микросервисов в кластере Kubernetes?
Микросервисы — Kubernetes-приложение
Ниже приведен пример, который может служить руководством для создания вашего собственного приложения на основе микросервисов.
Давайте рассмотрим микросервисное приложение, которое предоставляет информацию о погоде для конкретного города.

Weather-front: компонент, который состоит из фронтенда с интерфейсом для ввода названия города и просмотра информации о погоде. Смотрите скриншот выше.
Weather-services: компонент, который в качестве входных данных принимает название города и вызывает внешний погодный API для получения сведений о погоде.
Weather-db: это компонент с базой данных Maria, в которой хранятся данные о погоде, которые извлекаются для отслеживаемого города в фоновом режиме.
Указанные выше микросервисы развертываются с помощью объекта развертывания (Deployment object) Kubernetes, а ниже — результат выполнения команды kubectl get deploy.

Ниже приведены фрагменты кода, которые будут использоваться для развертывания микросервисов.
Weather-front:
- image: brainupgrade/weather:microservices-front
imagePullPolicy: Always
name: weather-frontWeather-services:
- image: brainupgrade/weather-services:2.0.0
imagePullPolicy: Always
name: weather-servicesWeather-db:
- image: mariadb:10.3
name: mariadb
ports:
- containerPort: 3306
name: mariadbНаблюдаемость — Столп первый — Логи событий
Чтобы реализовать первый столп наблюдаемости, нам нужно установить стек EFK: Elasticsearch, Fluentd и Kibana. Ниже приведены несложные шаги по установке.
Elasticsearch и Kibana:
helm repo add elastic https://helm.elastic.co
helm repo update
helm install --name elasticsearch elastic/elasticsearch --set replicas=1 --namespace elasticsearch
helm install --name kibana elastic/kibanaFluentd:
containers:
- name: fluentd
imagePullPolicy: "Always"
image: fluent/fluentd-kubernetes-daemonset:v1.12.0-debian-elasticsearch7-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch-master.elasticsearch.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"После установки вы можете запустить дашборд Kibana, который будет выглядеть как на скриншоте ниже:

При запуске Fluentd вы увидите следующее (Fluentd запускается как Daemonset - скриншот 4):

Вскоре логи начнут помещаться в Elasticsearch. Их можно будет просмотреть в Kibana:
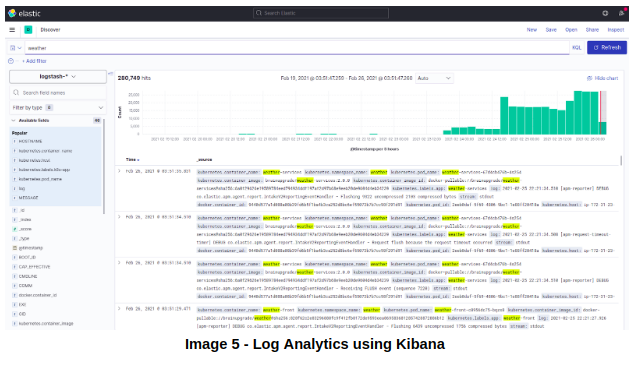
Первый «столп» наблюдаемости реализован, поэтому давайте сосредоточимся на следующем — распределенной трассировке.
Наблюдаемость — Столп второй — (распределенная) трассировка
Для распределенной трассировки (distributed tracing) у нас есть несколько альтернатив — Java-приложения, такие как Zipkin, Jaeger, Elasticsesarch APM и т. д.
Поскольку у нас уже есть стек EFK, давайте воспользуемся APM, предоставляемым Elasticsearch. Во-первых, давайте запустим сервер APM как Kubernetes Deployment.
Код развертывания сервера Elastic APM:
containers:
- name: apm-server
image: docker.elastic.co/apm/apm-server:7.5.0
ports:
- containerPort: 8200
name: apm-portКак только сервер APM запущен, нам следует неинвазивно добавить агента APM в наши микросервисы. Смотрите приведенный ниже фрагмент кода, используемый для микросервиса weather-front. Аналогичный код следует использовать и для компонента weather-services.
Код агента APM для микросервиса weather-front:
initContainers:
- name: elastic-java-agent
image: docker.elastic.co/observability/apm-agent-java:1.12.0
volumeMounts:
- mountPath: /elastic/apm/agent
name: elastic-apm-agent
command: ['cp', '-v', '/usr/agent/elastic-apm-agent.jar', '/elastic/apm/agent']
containers:
- image: brainupgrade/weather:microservices-front
imagePullPolicy: Always
name: weather-front
volumeMounts:
- mountPath: /elastic/apm/agent
name: elastic-apm-agent
env:
- name: ELASTIC_APM_SERVER_URL
value: "http://apm-server.elasticsearch.svc.cluster.local:8200"
- name: ELASTIC_APM_SERVICE_NAME
value: "weather-front"
- name: ELASTIC_APM_APPLICATION_PACKAGES
value: "in.brainupgrade"
- name: ELASTIC_APM_ENVIRONMENT
value: prod
- name: ELASTIC_APM_LOG_LEVEL
value: DEBUG
- name: JAVA_TOOL_OPTIONS
value: -javaagent:/elastic/apm/agent/elastic-apm-agent.jarПосле повторного развертывания компонентов микросервисов, вы можете перейти в Observability -> APM console в Kibana, чтобы наблюдать, как появляются сервисы (смотрите на скриншот 6).

После того, как вы кликните на сервис weather-front, вы сможете увидеть транзакции:

Кликните на любую из транзакций, и вы увидите детализированное представление с более подробной информацией о транзакции, которая включает задержку, пропускную способность, фрагмент трассировки (trace Sample) и т. д.


На приведенном выше скриншоте показана распределенная трассировка, на которой четко проиллюстрирована взаимосвязь микросервисов weather-front и weather-services. Кликнув по Trace Sample, вы перейдете к сведениям транзакции (transaction details).

Раскрывающийся список Actions в сведениях о транзакции предоставляет возможность просматривать логи для этой конкретной транзакции.

Что ж, на данный момент мы рассмотрели два «столпа» наблюдаемости из трех.
Наблюдаемость — Столп третий — Метрики
Для реализации третьего «столпа», то есть метрик, мы можем использовать дашборд служб APM, где фиксируются задержка (Latency), пропускная способность (Throughput) и процент ошибок (Error rate).

Кроме того, мы можем использовать плагин Spring Boot Prometheus Actuator для сбора данных метрик. Для этого сначала установите Prometheus и Grafana, используя следующие простые команды:
Prometheus и Grafana:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install --name prometheus prometheus-community/prometheus
helm install --name grafana grafana/grafanaПосле того как Prometheus и Grafana заработают, вам нужно добавить код приведенный ниже в микросервисы и совершить повторное развертывание:
template:
metadata:
labels:
app: weather-services
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8888"
prometheus.io/path: /actuator/prometheus
containers:
- image: brainupgrade/weather-services:2.0.0
imagePullPolicy: Always
name: weather-services
volumeMounts:
- mountPath: /elastic/apm/agent
name: elastic-apm-agent
env:
- name: management.endpoints.web.exposure.include
value: "*"
- name: spring.application.name
value: weather-services
- name: management.server.port
value: "8888"
- name: management.metrics.web.server.request.autotime.enabled
value: "true"
- name: management.metrics.tags.application
value: weather-servicesПосле повторного развертывания микросервисов откройте Grafana, импортируйте дашборд с id 12685 и выберите микросервис, метрики которого вы хотите увидеть. На скриншоте ниже приведен weather-front:
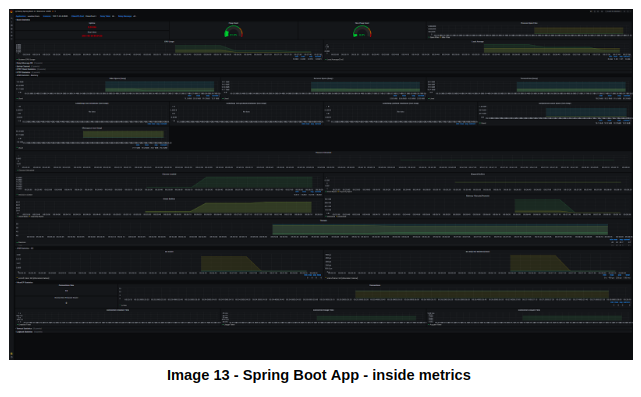
И чтобы увидеть метрики всего кластера, импортируйте дашборд Grafana с id 6417, и вы увидите что-то вроде:
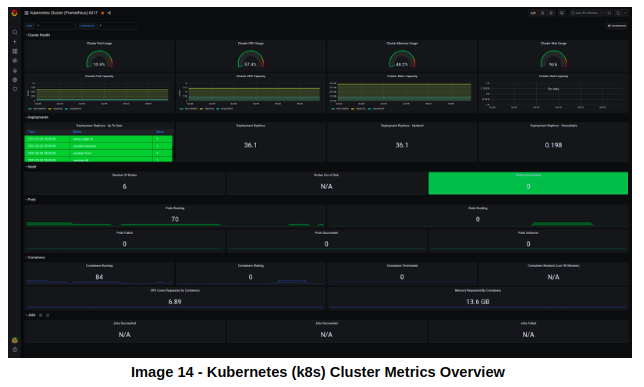
Узнать подробнее о курсе "Microservice Architecture".
Смотреть открытый вебинар по теме «Распределенные очереди сообщений на примере кафки».
gecube
Разворачиваются?
Попадать? Они ж не сами, а флюент их туда «пушит» (доставляет)
Сорри, на этом мой поисковый движок («search engine») допустил невыполнимую операцию и был закрыт… спасибо, что вы есть с нами )