
Инспектор и даже где-то "толкователь", LIT или Language Interpretability Tool — мощная платформа с открытым исходным кодом для визуализации и интерпретации NLP-моделей. Платформа была представлена на EMNLP 2020 специалистами Google Research в ноябре 2020 года. LIT еще в статусе разработки, поэтому разработчики ничего не гарантируют, в том числе работу на платформе windows. Но у меня получилось, делюсь опытом.
LIT – интерактивный, расширяемый, визуальный инструмент для разработчиков и исследователей NLP-моделей, которые среди прочего хотят понять, с какими кейсами модель не справляется, почему прогноз именно таков, какие слова в тексте влияют на результат, и что будет, если заменить тот или иной токен, или даже текст целиком. LIT открытая платформа. Можно добавить свой расчет метрик, новые методы интерпретации или нестандартные инструменты визуализации. Важно, чтобы архитектура модели позволяла «вытащить» нужную информацию.
Платформа справляется с различными видами моделей и фреймворками, в том числе TensorFlow 1.x, TensorFlow 2.x, PyTorch. LIT может работать с пользовательским кодом на Python поверх нейронной сети и даже с моделями, работающими через RPC.
Два слова про архитектуру. Фронтенд – на базе TypeScript. Это одностраничное приложение, состоящие из независимых веб-компонентов. В основе бэкенда WSGI сервер. Бэкенд управляет моделями, наборами данных, метриками, генераторами и компонентами интерпретации, а также кэшем, ускоряющим манипуляции с моделями и данными, что очень важно для больших моделей. Подробнее здесь.
«Из коробки» LIT поддерживает классификацию, регрессию, генераторы текстов, в том числе seq2seq, модели с маскировкой, NER-модели и многофункциональные модели с несколькими выходными головками. Основные возможности в таблице:
Виджет | Краткое описание |
Attention | Визуализация механизма внимания по уровням (attention layers) и головкам (attention heads) в комбинации. |
Confusion Matrix | Матрица ошибок с возможностью сделать срез данных, выделив соответствующие ячейки матрицы и понять, почему так получилось. |
Counterfactual Generator | Конструктор альтернативных данных для имеющихся кейсов. |
Data Table | Таблица данных с возможностью поиска и селекции конкретного кейса. Ограничение — не более 10k кейсов. |
Datapoint Editor | Редактор кейсов. Можно удалять или добавлять слова в тексте и сразу оценивать последствия. |
Embeddings | Два варианта 3D визуализации векторного пространства: UMAP и PCA. При наведении на точку отображается часть предложения. При выборе кейса в Data Table высвечивается соответствующая точка. Можно например, выбирать точки, находящиеся на границе кластеров и пытаться понять, почему они там оказались. |
Metrics Table | Метрики — от Accuracy или Recall до BLEU и ROUGE. Рассчитываются как для всего набора данных, так и для срезов. |
Predictions | Прогноз модели для выбранного кейса. При генерации текста для выбранного токена показывает альтернативные варианты в порядке убывания вероятности. |
Salience Maps | Тепловые карты токенов. Демонстрируют какой вклад каждый токен для выбранного кейса вносит в прогноз. Используются различные техники — local gradients, LIME. |
Scalar Plot | 2D визуализация точек данных в отношении результатов работы модели. |
Slice Editor | Конструктор срезов данных. |
Установка
Есть два варианта установки — при помощи pip install или из репозитария.
Вариант с pip для Windows 10 с поддержкой GPU:
# Создаем и активируем новое окружение:
conda create -n nlp python==3.7
conda activate nlp
# Устанавливаем tensorflow-gpu и pytorch:
conda install -c anaconda tensorflow-gpu
conda install -c pytorch pytorch
# При помощи pip ставим tensorflow datasets, transformers и LIT:
pip install transformers=2.11.0
pip install tfds-nightly
pip install lit-nlpПока в релизе tensorflow datasets не починили ссылки на glue datasets, tfds нужен неофициальный. PyTorch лучше ставить в первой половине дня по Москве, вечером скорость существенно падает и процесс затягивается на несколько часов.
Определяем свободный порт. В официальной документации для примера указан 5432, но у меня на нём PostgreSQL. Посмотреть занятые порты можно командой netstat -ao. Запускаем:
python -m lit_nlp.examples.quickstart_sst_demo —port=5433. В папке <Ваш путь>\anaconda3\envs\nlp\Lib\site-packages\lit_nlp\examples есть еще несколько примеров, но quickstart_sst_demo самый наглядный и точно работает под windows. Нужно подождать несколько минут, пока выполняется тонкая настройка, примерно 5 на GPU и 20 на CPU. Затем появится ASCII-арт LIT и адрес с номером порта.
Скриншот

Теперь вводим в браузере http://127.0.0.1:5433/ и ждем еще минуту, пока не загрузится проекция векторного пространства.
Установка из репозитария
Основные шаги установки описаны здесь.
git clone https://github.com/PAIR-code/lit.git ~/lit
# Установка окружения
cd ~/lit
conda env create -f environment.yml
conda activate lit-nlp
conda install cudnn cupti # необязательно, нужны для поддержки GPU
conda install -c pytorch pytorch
# Сборка фронтенда
pushd lit_nlp; yarn && yarn build; popdЯ пробовал устанавливать на образ continuumio/anaconda3 с докером под WSL2. Дело это не быстрое и хлопотное. В environment.yml нужно заменить tensorflow-datasets на tfds-nightly. Перед тем как создавать окружение нужно установить gcc и g++. Дальше всё по шагам вплоть до yarn. Ни в коем случае не устанавливать yarn через apt-get, это не тот yarn! Рабочий вариант — выполнить последовательность команд:
curl https://deb.nodesource.com/setup_12.x | bash
curl https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add -
echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list
apt-get update && apt-get install -y nodejs yarn postgresql-client
yarn && yarn buildПодготовка
Примеры с англоязычным NLP и использование моделей с поддержкой русского языка, как говорят, две большие разницы. Процедура «прикручивания» собственной модели в LIT описана одним абзацем текста, но зато есть примеры и я выбрал самый интересный quickstart_sst_demo, решив переделать его с сентимент-анализа на классификацию.
Данные:
Известный набор новостных текстов Lenta.Ru, он есть на Kaggle. Выбрал три топика: Экономика, Наука и техника, и Культура. Отфильтровал по количеству слов от 70 до 150. Получилось чуть более 50k кейсов.
Модель:
Как и в исходном примере, нужен был BERT. Вариантов с поддержкой русского языка немного. RuBert от DeepPavlov наверное самый популярный, модель есть в репозитарии huggingface.co. У неё 180 млн. параметров. Я подумал, что она не поместится в память моего 8Гб GPU. Так в начале и вышло, но удалось подобрать настройки. В частности, на использование памяти влияет max_seq_length, 128 токенов не помещается, а вот 64 вполне.
Для того чтобы запустить LIT со своей моделью нужно подготовить три скрипта:
скрипт данных, скрипт модели и основной скрипт для запуска, datasets/lenta.py, models/lenta_models.py и examples/quickstart_lenta.py соответственно. За основу — файлы из quickstart_sst_demo. Отредактированные скрипты можно посмотреть и скачать из репозитария. Строки с изменениями в коде я пометил комментарием EDIT.
Изменения в коде
datasets/lenta.py: Переписал загрузчик чтобы данные загружались не из tfds, как в примере, а из файла с разделителями.
models/lenta_models.py: Поменял название модели на «DeepPavlov/rubert-base-cased» и отредактировал конфигурацию: сократил max_seq_length до 64 токенов, размеры пакетов — с 32 до 16.
examples/quickstart_lenta.py: Отредактировал импорт модулей, поменял название модели и инициализацию переменных.
Запуск:
python -m lit_nlp.examples.quickstart_lenta —port=5433Тест
RuBert – предобученная модель. Чтобы использовать её для классификации текстов нужна тонкая настройка на новых данных. Объем дообучения задается в скрипте lenta_models параметром num_epochs (функции train). Посчитал, что пары эпох будет достаточно. Для 50k текстов это немногим более 3000 шагов. На RTX2070 процесс занимает 25 минут.
После запуска:

здесь крупнее.
{kind=link}
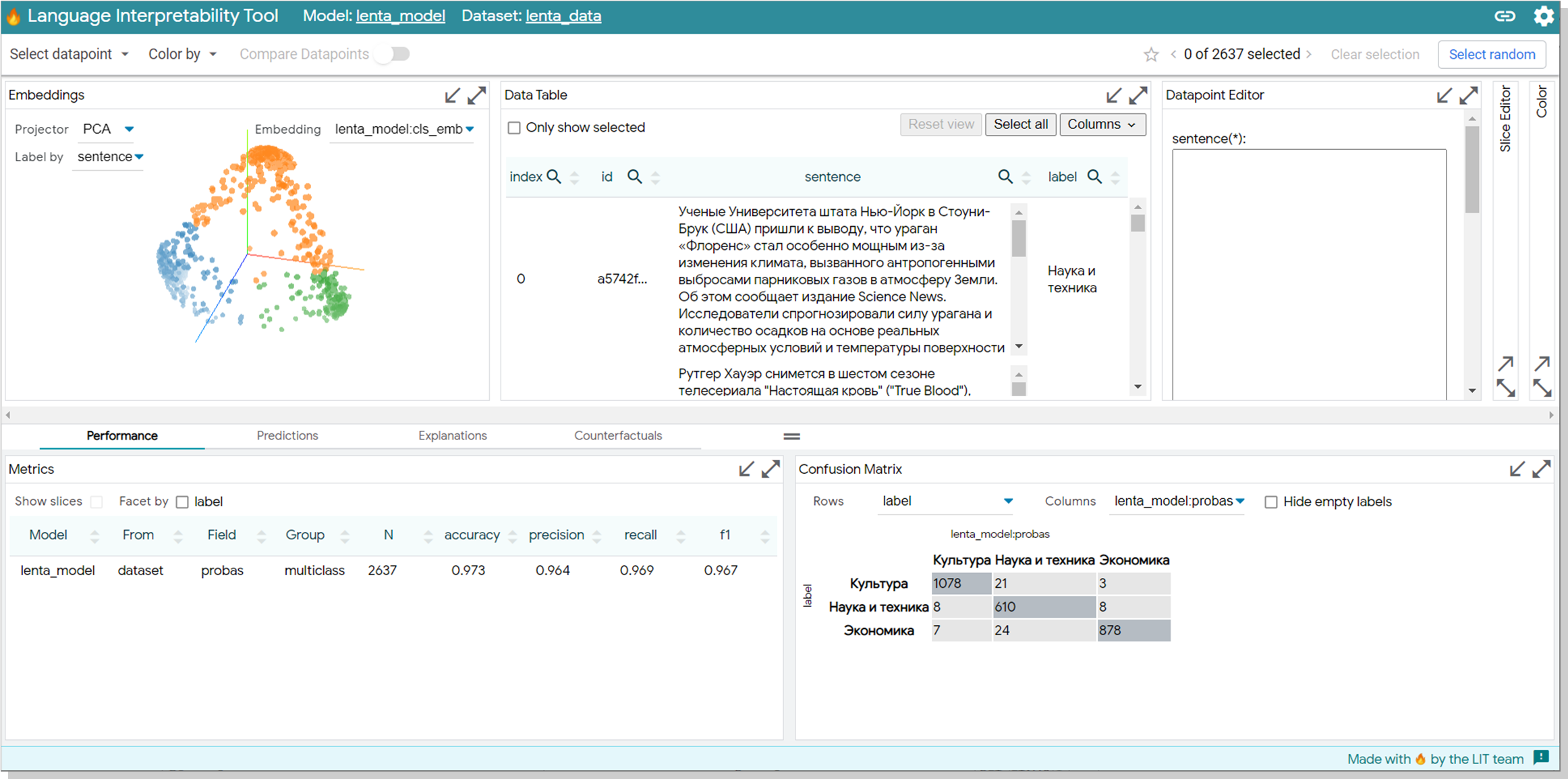
Смотрим на метрики. Всё очень неплохо, но всё же модель ошибается.

По матрице ошибок видно, что есть 21 кейс, каждый из которых относится к Культуре, но модель классифицирует их как, относящиеся к Науке и технике.
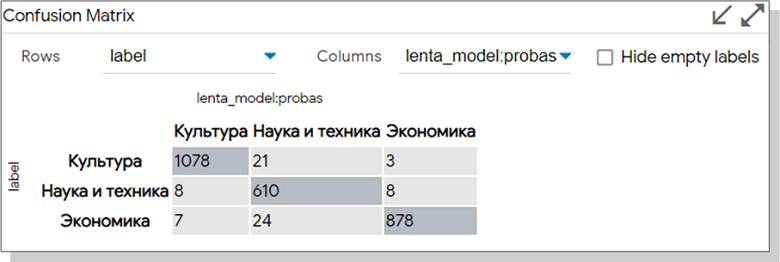
Выделяем сегмент матрицы с ошибками. В виджете Data Table устанавливаем флажок «Only show selected». Наши неудачные кейсы высветились на Embedding.
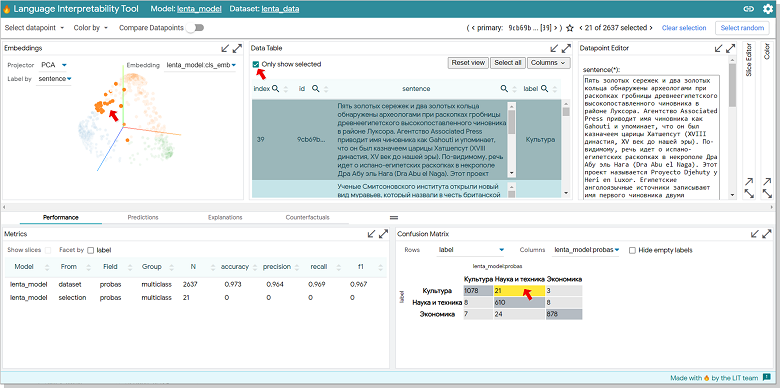
В Data Table выбираем какой-нибудь кейс и переходим на вкладку Explanation. Мне понравилась новость про Митьков и нанотехнологии. Модель на 32% уверена, что это Культура и на 68, что Наука и техника. В виджете Silence Maps выбираем grad_dot_input. Токены, которые "играют в плюс" при классификации выделены зеленым цветом, в минус — красным.
крупнее здесь.
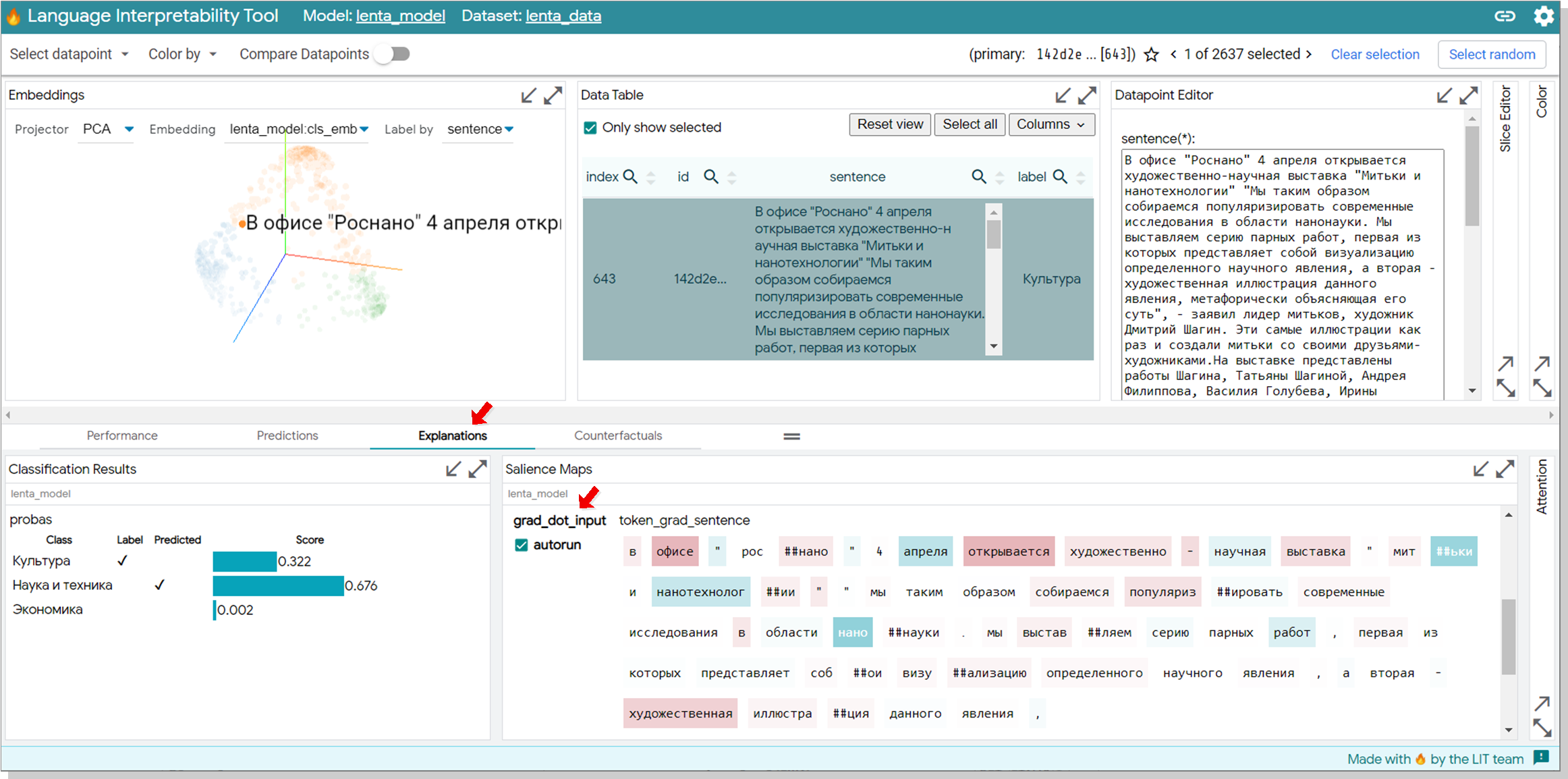{kind=link}
В Datapoint Editor заменяем сочетание «художественно-научная» на художественная, прокручиваем скроллбар и нажимаем «Analyze new datapoint» (кнопка под текстом).
До редактирования:

После:

Загадочный виджет Scalar. Так и не понял, что по оси Y. В документации написано, что можно использовать различные скалярные величины, в том числе метрики типа ROUGE. Обязательно попробую с генерацией текстов.
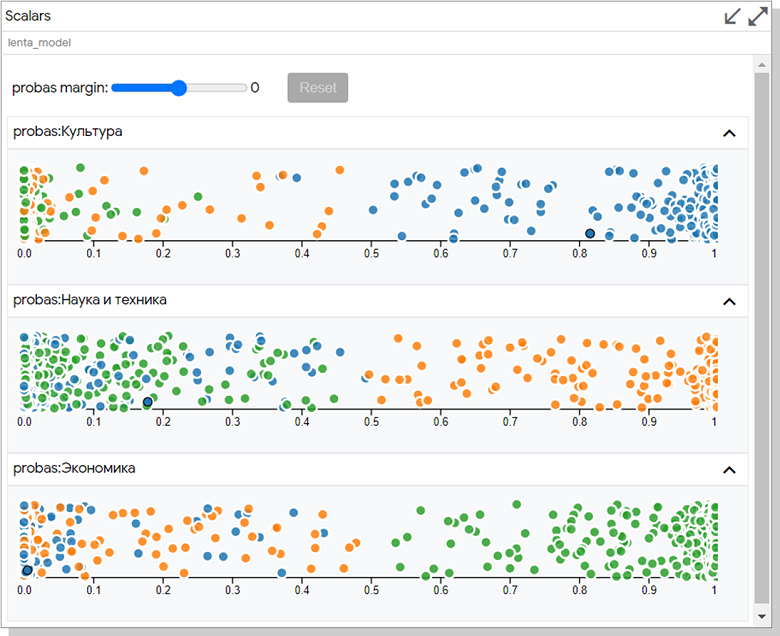
Общие впечатления:
С моделью RuBert интерфейс LIT немного притормаживает, в том числе при изменении размеров виджетов. Полагаю, что причина в почти полностью занятой видеопамяти. Еще из недостатков пожалуй только скудная документация. Slinece Maps и Embeddings показались крайне удобными штуками, прежде всего из-за интерактивной связи с набором данных.
Чтобы поэкспериментировать с LIT, необязательно его устанавливать. Есть онлайн демо, но загружается не всегда или очень медленно. Там четыре примера:
Классификация и регрессия
Гендерный дисбаланс в кореферентных отношениях можно попробовать
BERT заполняет пропуски в тексте
Генерация текста на T5
Весьма полезной выглядит возможность оценивать вероятность токенов и видеть альтернативные варианты при генерации текста в последнем примере. Такую модель локально я еще не пробовал, но не могу не поделиться скриншотом из демо:
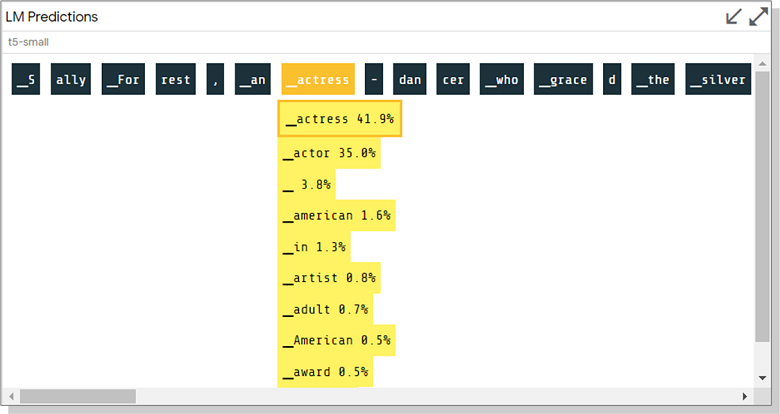
Искренне желаю всем интересных экспериментов с LIT и доли терпения в процессе!
Ссылки
Публикация The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models для EMNLP 2020
Форум на github с обсуждением проблем и ошибок в LIT