

Как отдельная профессия Big Data Engineering появилась довольно недавно. И даже крупные компании очень часто путают, чем занимается этот специалист, каковы его компетенции и зачем он вообще в организации.
Поэтому в сегодняшней статье мы разберёмся, кто такой Big Data Engineer, чем он занимается и чем отличается от Data Analyst и Data Scientist. Этот гайд подойдёт людям, которые хотят работать с большими данными и присматриваются к профессии в целом. А также тем, кто просто хочет понять, чем занимаются инженеры данных.
Кто такой Big data engineer
Задачи, которые выполняет инженер больших данных, входят в цикл разработки машинного обучения. Его работа тесно связана с аналитикой данных и data science.
Главная задача Data engineer — построить систему хранения данных, очистить и отформатировать их, а также настроить процесс обновления и приёма данных для дальнейшей работы с ними. Помимо этого, инженер данных занимается непосредственным созданием моделей обработки информации и машинного обучения.
Инженер данных востребован в самых разных сферах: e-commerce, финансах, туризме, строительстве — в любом бизнесе, где есть поток разнообразных данных и потребность их анализировать.
К примеру, при разработке «умного» дома. Создание подобной системы требует считывания и обработки данных с IoT-сенсоров в режиме реального времени. Необходимо, чтобы данные обрабатывались с максимальной быстротой и минимальной задержкой. И даже при падении системы данные должны продолжать накапливаться, а затем и обрабатываться. Разработка системы, которая удовлетворяет этим требованиям, и есть задача инженера данных.
С технической стороны, наиболее частыми задачами инженера данных можно считать:
Разработка процессов конвейерной обработки данных. Это одна из основных задач BDE в любом проекте. Именно создание структуры процессов обработки и их реализация в контексте конкретной задачи. Эти процессы позволяют с максимальной эффективностью осуществлять ETL (extract, transform, load) — изъятие данных, их трансформирование и загрузку в другую систему для последующей обработки. В статичных и потоковых данных эти процессы значительно различаются. Для этого чаще всего используются фреймворки Kafka, Apache Spark, Storm, Flink, а также облачные сервисы Google Cloud и Azure.
Хранение данных. Разработка механизма хранения и доступа к данным — еще одна частая задача дата-инженеров. Нужно подобрать наиболее соответствующий тип баз данных — реляционные или нереляционные, а затем настроить сами процессы.
Обработка данных. Процессы структурирования, изменения типа, очищения данных и поиска аномалий во всех этих алгоритмах. Предварительная обработка может быть частью либо системы машинного обучения, либо системы конвейерной обработки данных.
Разработка инфраструктуры данных. Дата-инженер принимает участие в развёртывании и настройке существующих решений, определении необходимых ресурсных мощностей для программ и систем, построении систем сбора метрик и логов.
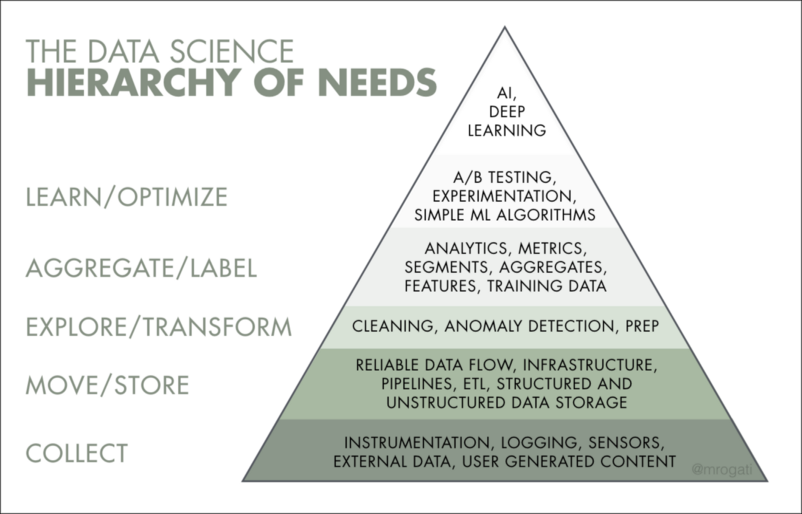
В иерархии работы над данными инженер отвечает за три нижние ступеньки: сбор, обработку и трансформацию данных.
Что должен знать Data Engineer
Структуры и алгоритмы данных;
Особенности хранения информации в SQL и NoSQL базах данных. Наиболее распространённые: MySQL, PostgreSQL, MongoDB, Oracle, HP Vertica, Amazon Redshift;
ETL-системы (BM WebSphere DataStage; Informatica PowerCenter; Oracle Data Integrator; SAP Data Services; SAS Data Integration Server);
Облачные сервисы для больших данных Amazon Web Services, Google Cloud Platform, Microsoft Azure;
Кластеры больших данных на базе Apache и SQL-движки для анализа данных;
Желательно знать языки программирования (Python, Scala, Java).
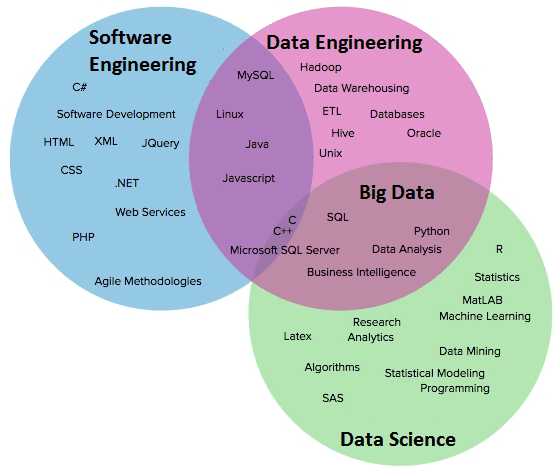
Стек умений и навыков инженера больших данных частично пересекается с дата-сайентистом, но в проектах они, скорее, дополняют друг друга.
Data Engineer сильнее в программировании, чем дата-сайентист. А тот, в свою очередь, сильнее в статистике. Сайентист способен разработать модель-прототип обработки данных, а инженер — качественно воплотить её в реальность и превратить код в продукт, который затем будет решать конкретные задачи.
Инженеру не нужны знания в Business Intelligence, а вот опыт разработки программного обеспечения и администрирования кластеров придётся как раз кстати.
Но, несмотря на то что Data Engineer и Data Scientist должны работать в команде, у них бывают конфликты. Ведь сайентист — это по сути потребитель данных, которые предоставляет инженер. И грамотно налаженная коммуникация между ними — залог успешности проекта в целом.
Плюсы и минусы профессии инженера больших данных
Плюсы:
Отрасль в целом и специальность в частности ещё очень молоды. Особенно в России и странах СНГ. Востребованность специалистов по BDE стабильно растёт, появляется всё больше проектов, для которых нужен именно инженер больших данных. На hh.ru, по состоянию на начало апреля, имеется 768 вакансий.
Пока что конкуренция на позиции Big Data Engineer в разы ниже, чем у Data Scientist. Для специалистов с опытом в разработке сейчас наиболее благоприятное время, чтобы перейти в специальность. Для изучения профессии с нуля или почти с нуля — тоже вполне хорошо (при должном старании). Тенденция роста рынка в целом будет продолжаться ближайшие несколько лет, и всё это время будет дефицит хороших спецов.
Задачи довольно разнообразные — рутина здесь есть, но её довольно немного. В большинстве случаев придётся проявлять изобретательность и применять творческий подход. Любителям экспериментировать тут настоящее раздолье.
Минусы
Большое многообразие инструментов и фреймворков. Действительно очень большое — и при подготовке к выполнению задачи приходится серьёзно анализировать преимущества и недостатки в каждом конкретном случае. А для этого нужно довольно глубоко знать возможности каждого из них. Да-да, именно каждого, а не одного или нескольких.
Уже сейчас есть целых шесть платформ, которые распространены в большинстве проектов.
Spark — популярный инструмент с богатой экосистемой и либами, для распределенных вычислений, который может использоваться для пакетных и потоковых приложений.
Flink — альтернатива Spark с унифицированным подходом к потоковым/пакетным вычислениям, получила широкую известность в сообществе разработчиков данных.
Kafka — сейчас уже полноценная потоковая платформа, способная выполнять аналитику в реальном времени и обрабатывать данные с высокой пропускной способностью. ElasticSearch — распределенный поисковый движок, построенный на основе Apache Lucene.
PostgreSQL — популярная бд с открытым исходным кодом.
Redshift — аналитическое решение для баз/хранилищ данных от AWS.Без бэкграунда в разработке ворваться в BD Engineering сложно. Подобные кейсы есть, но основу профессии составляют спецы с опытом разработки от 1–2 лет. Да и уверенное владение Python или Scala уже на старте — это мастхэв.
Работа такого инженера во многом невидима. Его решения лежат в основе работы других специалистов, но при этом не направлены прямо на потребителя. Их потребитель — это Data Scientist и Data Analyst, из-за чего бывает, что инженера недооценивают. А уж изменить реальное и объективное влияние на конечный продукт и вовсе практически невозможно. Но это вполне компенсируется высокой зарплатой.
Как стать Data Engineer и куда расти
Профессия дата-инженера довольно требовательна к бэкграунду. Костяк профессии составляют разработчики на Python и Scala, которые решили уйти в Big Data. В русскоговорящих странах, к примеру, процент использования этих языков в работе с большими данными примерно 50/50. Если знаете Java — тоже хорошо.
Хорошее знание SQL тоже важно. Поэтому в Data Engineer часто попадают специалисты, которые уже ранее работали с данными: Data Analyst, Business Analyst, Data Scientist. Дата-сайентисту с опытом от 1–2 лет будет проще всего войти в специальность.
Фреймворками можно овладевать в процессе работы, но хотя бы несколько важно знать на хорошем уровне уже в самом начале.
Дальнейшее развитие для специалистов Big Data Engineers тоже довольно разнообразное. Можно уйти в смежные Data Science или Data Analytics, в архитектуру данных, Devops-специальности. Можно также уйти в чистую разработку на Python или Scala, но так делает довольно малый процент спецов.
Перспективы у профессии просто колоссальные. Согласно данным Dice Tech Job Report 2020, Data Engineering показывает невероятные темпы роста — в 2019 году рынок профессии увеличился на 50 %. Для сравнения: стандартным ростом считается 3–5 %.
В 2020 году темпы замедлились, но всё равно они многократно опережают другие отрасли. Спрос на специальность вырос ещё на 24,8 %. И подобные темпы сохранятся еще на протяжении минимум пяти лет.
Так что сейчас как раз просто шикарный момент, чтобы войти в профессию Data Engineering с нашим курсом Data Engineering и стать востребованным специалистом в любом серьёзном Data Science проекте. Пока рынок растёт настолько быстро, то возможность найти хорошую работу, есть даже у новичков.

Узнайте, как прокачаться и в других областях работы с данными или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ