
Задача классификации — одна из самых известных в машинном обучении. Очень многие проблемы, решаемые с помощью ML, так или иначе сводятся к классификации — распознавание изображений, например. И все выглядит просто и понятно, когда нам нужно определить объект в один из нескольких классов. А что если у нас не плоская структура из нескольких классов, а сложная разветвленная иерархия на 683 категории? Именно о таком случае мы сегодня и поговорим. Под катом — рассказ о том, зачем в задачах классификации нужны сложные иерархии и как с ними жить.

В любой задаче классификации есть набор классов и есть модель, которая умеет предсказывать класс для новых данных. Допустим, модель бинарной классификации Спам/не спам, модель классификации настроения текста Хорошо/нейтрально/плохо. Классы обычно являются абстракцией реальности, а абстракция — это всегда упрощение.
Однако реальность может быть гораздо сложнее, ведь имеется некоторая структура, взаимосвязи между классами. Одна из часто встречаемых в жизни структур это дерево иерархии. Существует множество вещей, которые можно классифицировать по одному принципу, но на разных уровнях абстракции или обобщения. Например, известная со школы классификация животных. На первом уровне это могут быть Млекопитающие и Рептилии, на втором — Дельфины и Ящерицы. Определенный объект можно отнести к одному из классов на каждом уровне, причем все объекты, относящиеся к некоторому классу, также относятся и к родителю этого класса.
Это звучит понятно в школьном учебнике, но в контексте машинного обучения возникает множество вопросов:
Как с этим всем обращаться?
Какие классы предсказывать?
Сколько моделей тренировать для решения задачи?
Как работать с данными?
Как вносить изменения в иерархию классов и как реагировать на эти изменения с точки зрения модели?
Все эти проблемы мы разберем на примере задачи классификации, которую мы решаем в Контуре.
Постановка задачи
Мы работаем с чеками. В каждом чеке может встретиться много разных товаров, которые можно сгруппировать множеством разных способов. На данный момент нам интересно группировать эти товары с помощью дерева категорий, которое мы будем называть KPC (Khajiit Product Classification). Это здоровенное дерево, состоящее из 683 категорий.

Для этих категорий у нас есть Golden Set, наш размеченный набор данных (штрихкод — категория KPC) для обучения. В датасете почти три миллиона записей и мы постоянно работаем над его дополнением и улучшением разметки.
Именно в этом суть проблемы. Представьте — три миллиона записей, 683 класса. Иерархия очень непостоянная — одни классы добавляются, другие удаляются, а третьи обрастают дочерними категориями. Поддерживать все это в порядке очень непросто.
Давайте разберемся, как выглядят разные этапы классификации с иерархической структурой классов.
Разметка данных
Как уже упоминалось выше, вся эта огромная структура классов очень волатильна. Классы обновляются, удаляются, разрастаются в сложное дерево или превращаются в свалку из трудноопределяемых в другие категории товаров. Из-за этих постоянных изменений появилась необходимость обрабатывать разные категории по-разному.
Так появились статусы категорий. Они помогают понять, в каком состоянии категория прямо сейчас. Благодаря статусам мы можем отдельно обрабатывать только что появившиеся категории или категории, которые скоро будут удалены. На текущий момент мы выделяем четыре статуса категорий:
Активный.
Запланированный — категория, на которую мы хотим классифицировать, но пока не можем (не хватает данных или не почистили разметку).
Архивный — категория, которую решено было удалить, но товары из категории еще не переразметили.
Удаленный.
В зависимости от статуса мы решаем, что делать с конкретной категорией на каждом из этапов классификации.
Также стоит упомянуть две отдельные группы категорий:
«свалка» (например «Одежда (свалка)») — группа для логического удаления некоторых товаров, которые невозможно категоризировать. Например, у нас есть товар «Полное тестирование Тест 2 10шт», у которого из какого-то источника данных стоит категория Одежда. Наш аналитик данных понимает, что по факту категории у такого товара нет, поэтому такой товар отправляется в свалку, которая при обучении не рассматривается.
«другое/другие» (например «Молочные товары, сыры и яйцо (другое)») — группа для товаров, которые относятся к родительской категории, но не относятся (возможно, пока) ни к одной из дочерних.
А теперь давайте разберемся, как выглядит собственно обновление нашего датасета. Мы можем добавлять категории, удалять, а также разбивать уже существующие категории на несколько новых.
Добавление категории
Добавить категорию мы можем в любое время, но для того, чтобы товары начали в неё попадать, необходимо:
Добавить категорию в KPC.
Переразметить обучающую выборку в соответствии с новой категорией (если товары новой категории раньше относились к другой категории — проверить, что теперь они относятся к правильной).
Переобучить модель, чтобы она научилась классифицировать товары в новую категорию.
Удаление категории
Как можно догадаться по статусам, удаление категорий в нашем случае исключительно логическое. Мы меняем статус категории сначала на архивный, а затем на удаленный.
Для удаления категории необходимо:
Перевести категорию в статус Архивная.
Решить, что мы делаем с товарами, которые относились к удаляемой и дочерним категориям.
Заменить удаляемую категорию у товаров в Golden Set.
Указать дочерним категориям новую родительскую категорию или её отсутствие (если дочерняя категория должна стать категорией верхнего уровня).
Переобучить модель, чтобы она перестала классифицировать товары в удаляемую категорию (и начала классифицировать эти товары в новые категории).
Перевести категорию в статус Удаленная.
Разбиение категории
Если появляется необходимость разбить одну категорию на несколько новых, нужно:
Обновить категории в Golden Set, чтобы отнести товары к новым категориям.
Переобучить модель, чтобы она научилась классифицировать товары в новые категории.
Суммируя написанное выше, основные изменения при разметке — это необходимость учитывать родительские и дочерние классы. Например, при удалении мы должны смотреть, чтобы у всех дочерних категорий нашлись новые родительские.
Обучение модели
На этапе обучения все сводится к обучению одного простого классификатора и иерархичность структуры, на первый взгляд, не добавляет никаких проблем. Однако перед обучением мы должны привести наши классы в порядок, чтобы в обучающей выборке не встречались одновременно дочерние и родительские классы (например, родительская категория Молочные продукты, яйца и сыры и дочерняя категория Яйца).
Такие коллизии плохо влияют на обучение — товар может одновременно оказаться в обеих категориях и это может смутить нашу модель. Чтобы избежать таких случаев, перед обучением добавлен этап разрешения конфликтов дерева категорий (KPC collisions resolving).
Вспоминая о введенных ранее категориях хочется упомянуть, что в контексте резолвинга архивные категории обрабатываются также, как и активные, а удаленные не обрабатываются вовсе.
Алгоритм разрешения конфликтов
Для начала разберемся с тем, что такое конфликт или коллизия. Коллизией мы считаем ситуацию, когда пара категорий ребенок/родитель одновременно представлена в KPC. То есть часть товаров размечена родительской категорией, часть — дочерней. Как уже упоминалось выше, такие ситуации плохо влияют на обучение.
Для разрешения этих ситуаций мы будем маппить категории (то есть переносить все товары из одной категории в другую), а после обновлять наше дерево категорий (оставлять в рассмотрении только те категории, которые представлены в Golden set), проверяя, остались ли коллизии.
Теперь важно понять желаемый конечный результат. Выписать несколько возможных ситуаций из дерева категорий и понять, как мы хотим эти ситуации решать. Понять, какие категории в какую смаппятся, а какие категории в итоге останутся и будут учтены классификатором.
Например, на какой-то итерации работы с алгоритмом мы разбирали вот такую ситуацию. Желаемый результат разрешения конфликта здесь не очевиден и требует продуманного аналитического ответа. При некоторых очевидных решениях этот случай может быть упущен, что впоследствии приведет к неожиданному результату вроде потери категорий.
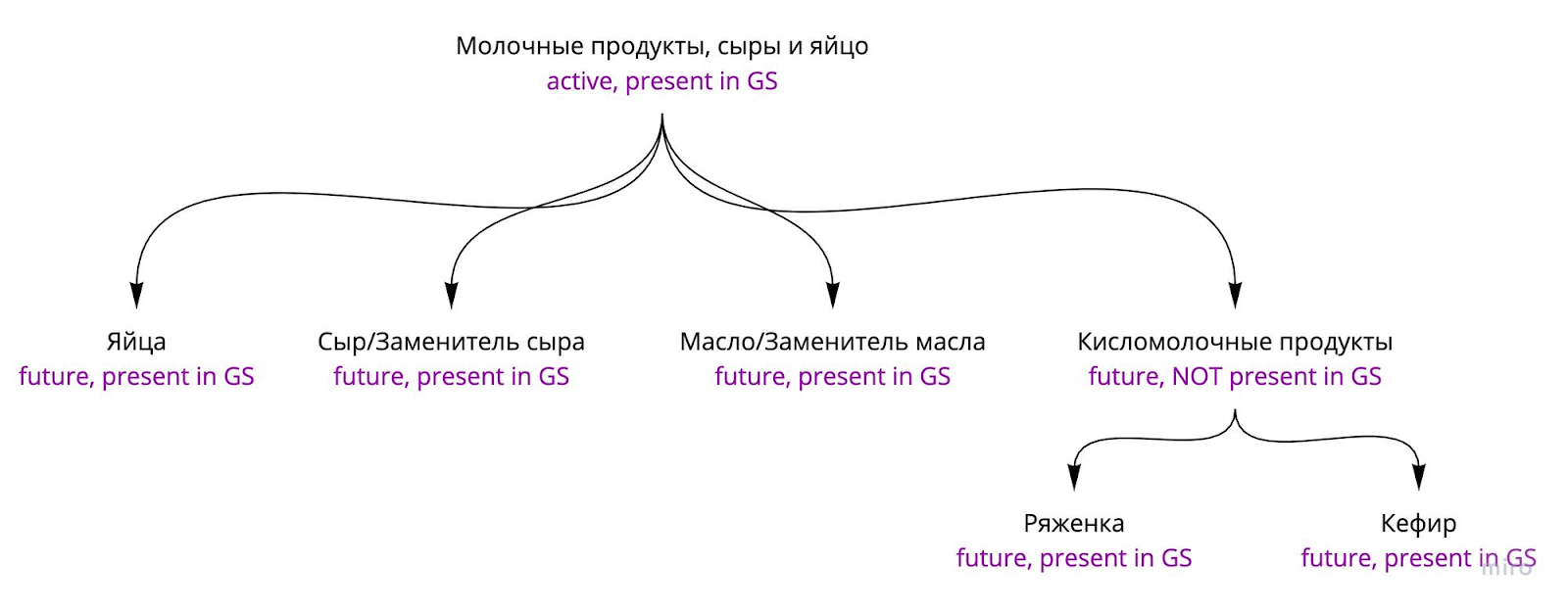
Future/Active на схеме — это статусы категорий Запланированная/Активная, а present/NOT present in GS — представлена ли категория в Golden set.
Еще один вопрос, который важно разобрать — что мы хотим делать с Запланированными категориями? И что мы хотим делать с их детьми?
Есть несколько вариантов. Мы можем:
Использовать эти категории в классификации.
Не классифицировать и выбросить категории из GS.
Переразмечать эти категории в категорию-родителя.
Переразмечать эти товары в категорию «другое/другие» (например «Молочные продукты, сыры и яйцо (другое)»)
После разбора таких случаев, ответов на архитектурные вопросы и итеративной разработки мы пришли к следующему алгоритму.
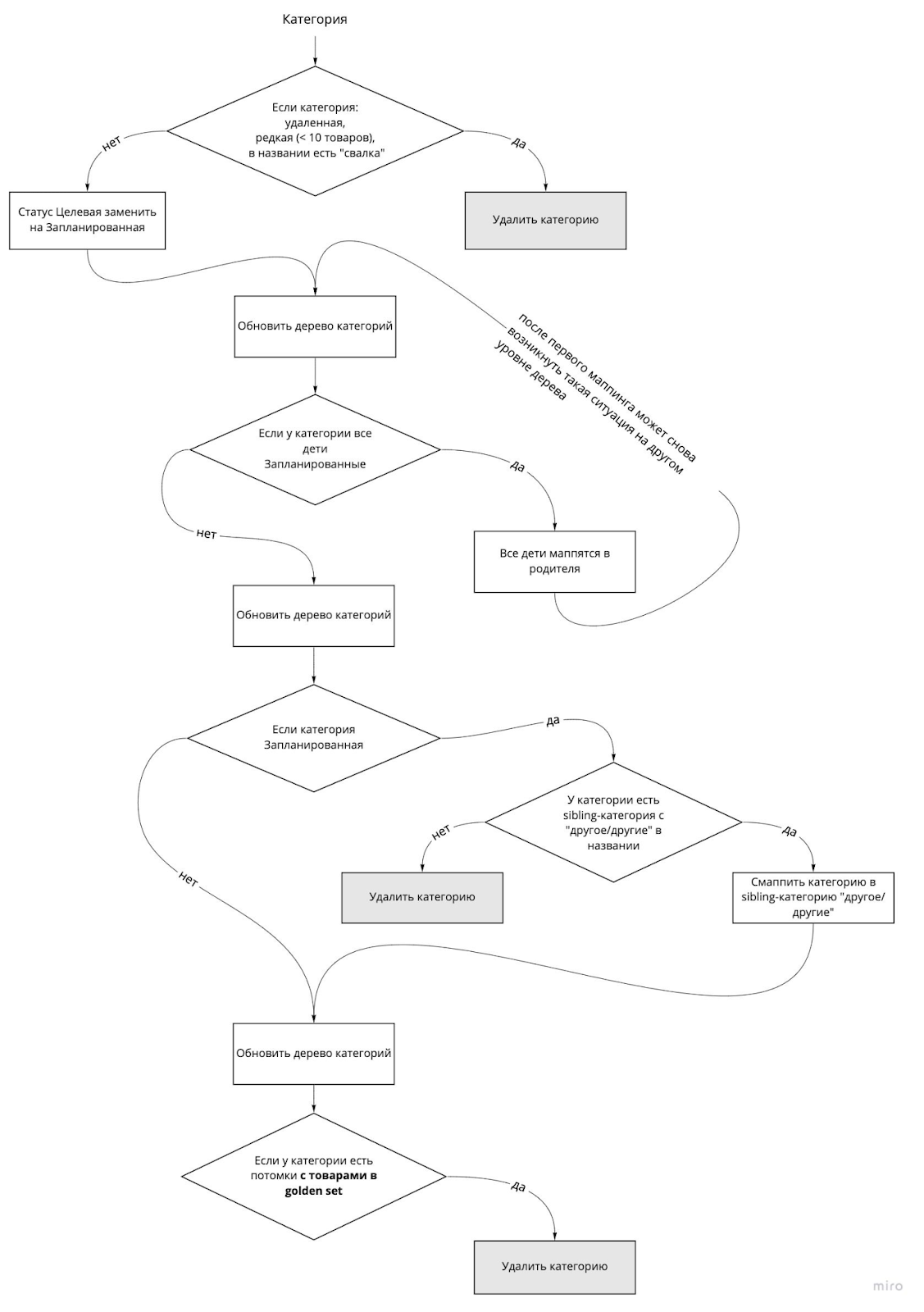
Убрать удаленные, редко встречающиеся (меньше 10 товаров в golden set) и те категории, у которых в названии есть «свалка».
Если все дети категории в статусе «Запланированный», то дочерние категории маппятся в родителя. Это происходит итеративно, так как после первого маппинга может возникнуть аналогичная ситуация на другом уровне дерева.
Смаппить запланированные категории в sibling-категорию с «другое/другие» в названии, если такая есть.
Удалить из Golden Set категории, у которых есть категории-потомки с товарами в Golden Set. Здесь происходит то самое разрешение конфликтов.
На каждом этапе мы рассматриваем уже обновленное дерево категорий. Важность этого пункта вытекла из разбора неочевидных ситуаций. Например, если не обновлять дерево (не убирать категории без товаров в GS и без потомков с товарами), то правило Смаппить всех Запланированных детей к родителю может не сработать из-за пустого, но активного ребенка.
Валидация модели
На этапе валидации возникает еще один важный вопрос. Как сравнивать разные версии модели, если они обучались на разных наборах классов и разных наборах данных? Какие категории нуждаются в развитии? Как оценить проделанную работу по обогащению, чистке или уточнению категории?
В первую очередь мы сравниваем базовые метрики — accuracy (по всем классам) и accuracy/coverage. Необходимо следить за тем, чтобы баланс покрытия и точности не нарушался, а также за возможностью подобрать threshold для новой модели, при котором этот баланс соответствует нашим требованиям.
Во вторую очередь будем смотреть на метрики отдельно по каждому классу. Сначала на те, с которыми модель непосредственно знакома. Затем на родительские классы, путем агрегации (взвешенное среднее).
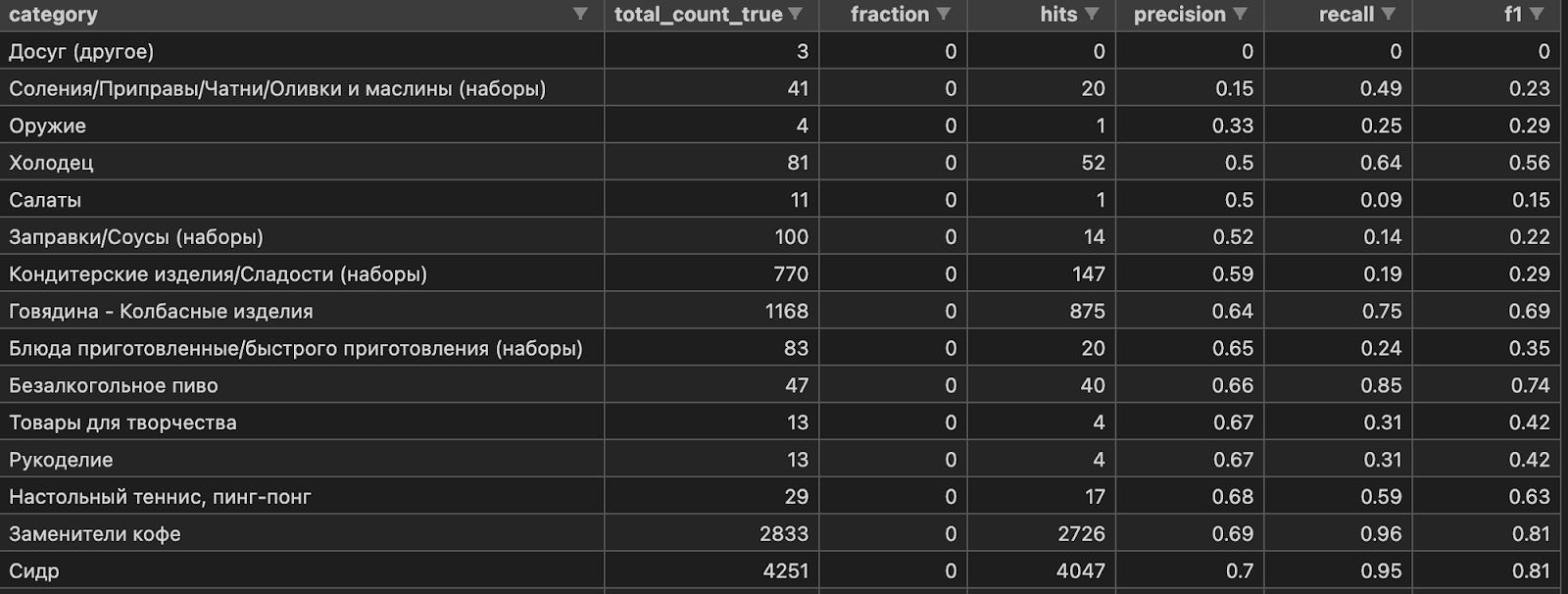
Таким образом, мы сможем сравнить качество по любому классу, даже если новая модель уже его не классифицирует, а, например, классифицирует его детей.
В третью очередь мы строим confusion matrix для всех категорий, чтобы понять между какими классами больше всего путается модель. Эти классы помогают задавать направление для дальнейшего развития.
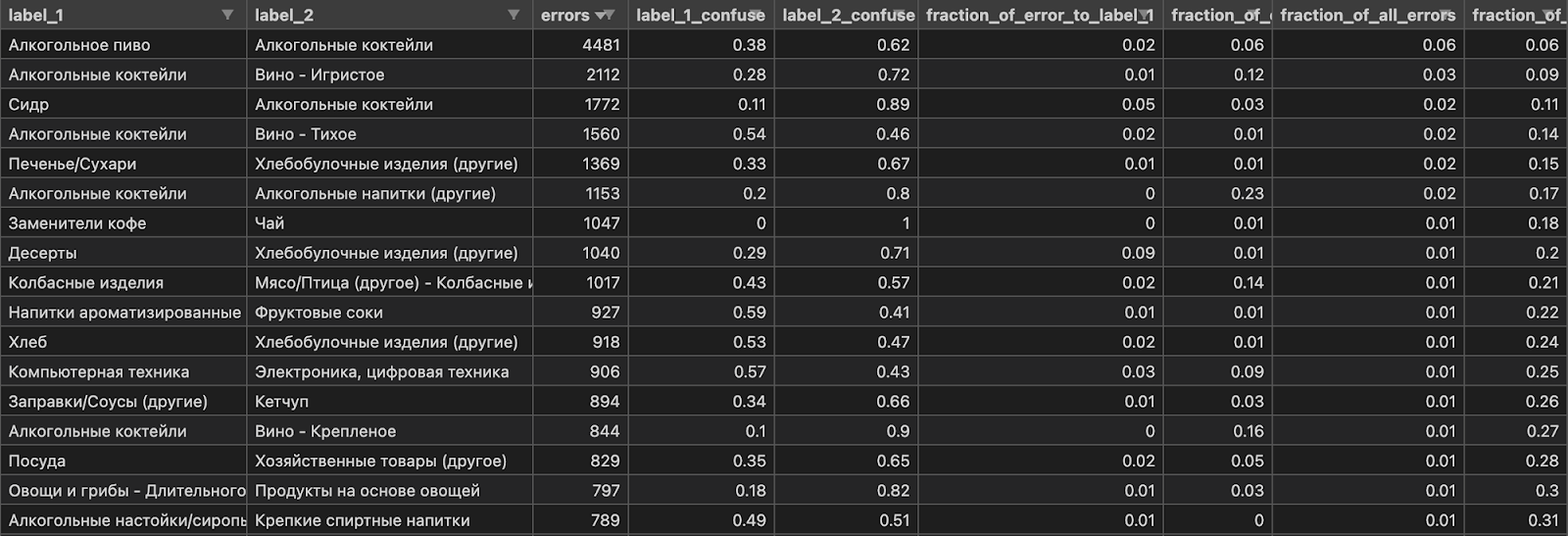
'errors' - sum of errors of confusing two labels,
'label_1_confuse' - count(true=label_1, pred=label_2) / 'errors',
'label_2_confuse' - count(true=label_2, pred=label_1) / 'errors',
'fraction_of_error_to_label_1' - count(true=label_1, pred=label_2) / total_label_1,
'fraction_of_error_to_label_2' - count(true=label_2, pred=label_1) / total_label_2,
'fraction_of_all_errors' - 'errors' / total_errors,
'fraction_of_all_errors_cumulative'
Выводы
Для удобной итеративной работы с деревом категорий полезно ввести статусы категорий. Такие статусы позволят обрабатывать категории в разном состоянии разными способами.
При валидации стоит агрегировать метрики для родительских категорий, чтобы иметь возможность сравнить две модели с разными наборами классов.
Важно следить, чтобы в обучающей выборке не смешивались сэмплы из родительского и из дочернего классов. Также важно продумать желаемый результат разрешения таких конфликтов в разных конфигурациях дерева, статусов и состояния разметки категорий.
IvanStrazov
Спасибо, было полезно!