
В фильмах или роликах с YouTube мы наблюдаем происходящее из одной точки, нам не доступны перемещение по сцене или смещение угла зрения. Но, кажется, ситуация меняется. Так, исследователи из Политехнического университета Вирджинии и Facebook разработали новый алгоритм обработки видео. Благодаря ему, можно произвольно изменять угол просмотра уже готового видеопотока. Что примечательно — алгоритм использует кадры, которые получены при съемке на одну камеру, совмещение нескольких видеопотоков с разных камер не требуется.
В основе нового алгоритма — нейросеть NeRF (Neural Radiance Fields for Unconstrained). Эта появившаяся в прошлом году сеть умеет превращать фотографии в объемную анимацию. Однако для достижения эффекта перемещения в видео проект пришлось существенно доработать.
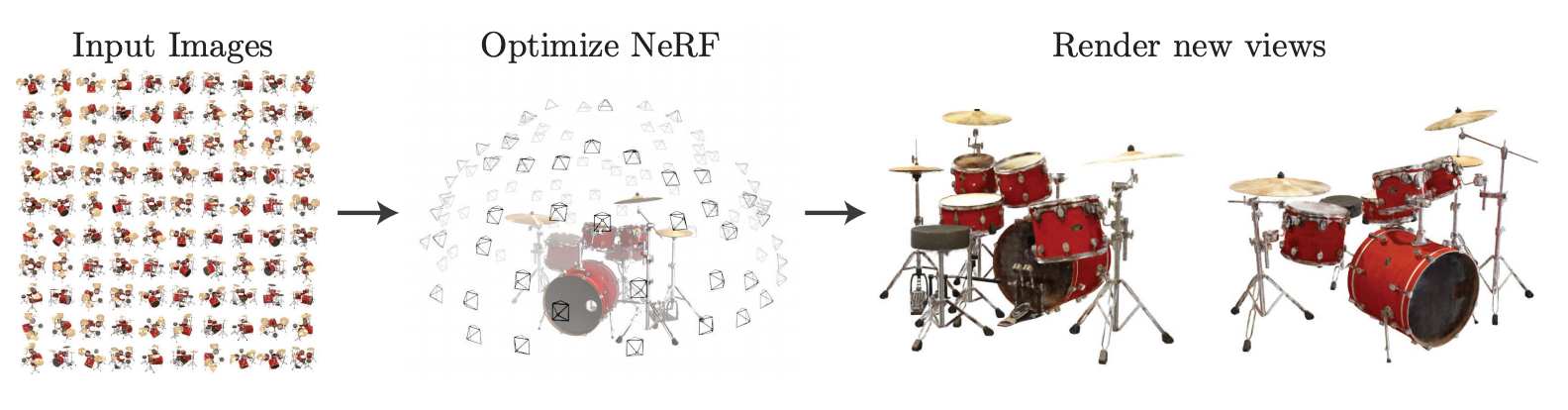
NeRF обучают на большом количестве изображений одного и того же объекта с разных ракурсов. Изначально ее научили воссоздавать объемные картинки известных архитектурных достопримечательностей и других объектов. Не все изображения идеально складывались и читались, поэтому требовалось расширить изначальные возможности.
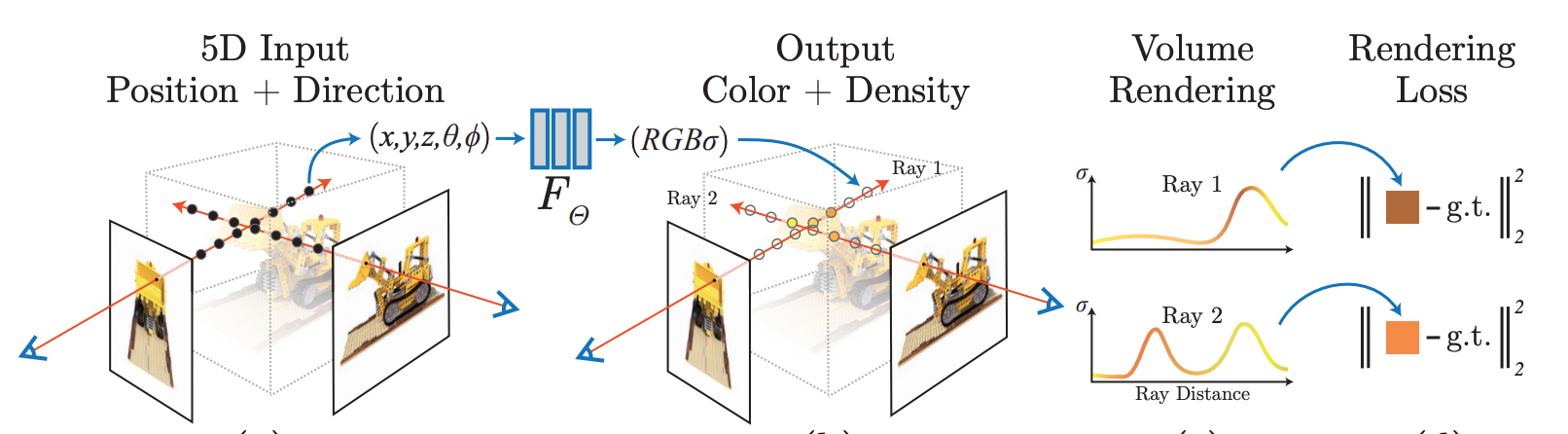
Сама по себе нейросеть умеет создавать 3D-изображение под разными углами из множества снимков. Также она может вычленять 2D-модели. Эти изображения переводят из объемных в плоскостные путем попиксельного переноса. Как именно?
Когда выбран нужный угол зрения, алгоритм начинает пропускать сквозь трехмерную сцену лучи и попиксельно создавать двухмерное изображение, используя данные о плотности и цвете каждого пикселя вдоль всего прохождения луча. Чтобы получить кадр целиком, процесс запускают несколько раз, пока не наберется необходимое количество пикселей из лучей просчитанных с разных направлений. Тем самым становится возможным генерация 2D-изображений с любого ракурса. В целом интересный и оригинальный подход к решению столь нетривиальной задачи.
Для достижения похожего эффекта для видеопотока требуются аналогичные действия. Но есть важный нюанс — в видео есть только один ракурс для каждого отдельного кадра. Чтобы справиться с задачей, исследователи решили обучить две разные модели параллельно. В итоге получились сразу 2 алгоритма: для статической и динамической частей сцены.
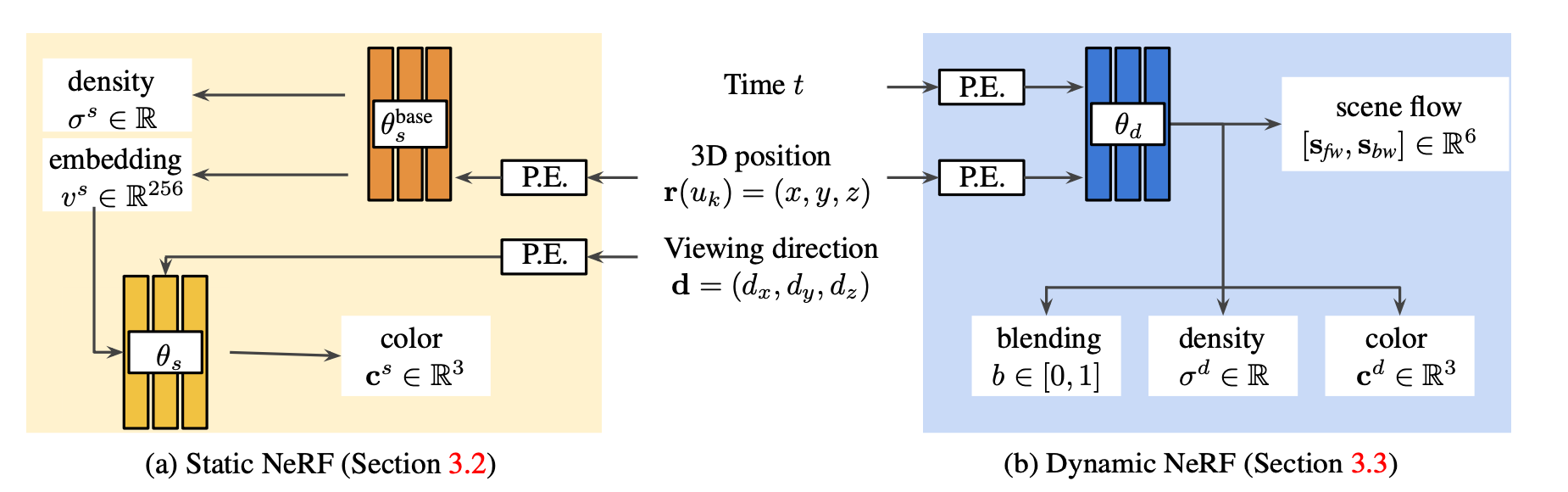
Что касается статичной модели, то она устроена по тому же принципу, что и NeRF. Есть только одно отличие — из кадра сразу удалили все движущиеся объекты.

С динамической моделью все намного интереснее. Для ее обработки не хватало кадров. Тогда нейросеть научили предсказывать кадры для объемного потока. Точнее кадры к каждому конкретному моменту времени t. Эти моменты условно назвали t-1 и t+1. Суть 3D-потока сводится к оптическому потоку, только в этом случае его строят для объемных объектов.
Также ученым удалось избавиться от помех и обеспечить согласованность кадров. В итоге новая нейросеть воссоздает достаточно стройный видеоряд с разных ракурсов. На предоставленном разработчиками видео виден эффект, похожий на тот, что многие из нас помнят из «Матрицы». В кинематографе его называют Bullet time, когда зрителя погружают внутрь изображения.
Сами разработчики считают свой проект более удачной версией NeRF, благодаря стройным и плавным переходам.

В основе нового алгоритма — нейросеть NeRF (Neural Radiance Fields for Unconstrained). Эта появившаяся в прошлом году сеть умеет превращать фотографии в объемную анимацию. Однако для достижения эффекта перемещения в видео проект пришлось существенно доработать.
Что именно умеет NeRF?
NeRF обучают на большом количестве изображений одного и того же объекта с разных ракурсов. Изначально ее научили воссоздавать объемные картинки известных архитектурных достопримечательностей и других объектов. Не все изображения идеально складывались и читались, поэтому требовалось расширить изначальные возможности.
Сама по себе нейросеть умеет создавать 3D-изображение под разными углами из множества снимков. Также она может вычленять 2D-модели. Эти изображения переводят из объемных в плоскостные путем попиксельного переноса. Как именно?
Когда выбран нужный угол зрения, алгоритм начинает пропускать сквозь трехмерную сцену лучи и попиксельно создавать двухмерное изображение, используя данные о плотности и цвете каждого пикселя вдоль всего прохождения луча. Чтобы получить кадр целиком, процесс запускают несколько раз, пока не наберется необходимое количество пикселей из лучей просчитанных с разных направлений. Тем самым становится возможным генерация 2D-изображений с любого ракурса. В целом интересный и оригинальный подход к решению столь нетривиальной задачи.
Видеопоток с эффектом
Для достижения похожего эффекта для видеопотока требуются аналогичные действия. Но есть важный нюанс — в видео есть только один ракурс для каждого отдельного кадра. Чтобы справиться с задачей, исследователи решили обучить две разные модели параллельно. В итоге получились сразу 2 алгоритма: для статической и динамической частей сцены.
Что касается статичной модели, то она устроена по тому же принципу, что и NeRF. Есть только одно отличие — из кадра сразу удалили все движущиеся объекты.
С динамической моделью все намного интереснее. Для ее обработки не хватало кадров. Тогда нейросеть научили предсказывать кадры для объемного потока. Точнее кадры к каждому конкретному моменту времени t. Эти моменты условно назвали t-1 и t+1. Суть 3D-потока сводится к оптическому потоку, только в этом случае его строят для объемных объектов.
Также ученым удалось избавиться от помех и обеспечить согласованность кадров. В итоге новая нейросеть воссоздает достаточно стройный видеоряд с разных ракурсов. На предоставленном разработчиками видео виден эффект, похожий на тот, что многие из нас помнят из «Матрицы». В кинематографе его называют Bullet time, когда зрителя погружают внутрь изображения.
Сами разработчики считают свой проект более удачной версией NeRF, благодаря стройным и плавным переходам.
lab412
где примеры видео работы нейросети? научили, заставили, не важно что… где результат чтобы оценить что вышло? а то может там фигня полная и не стоит затраченных сил
кстати, процесс описанный в статье, называется «фотограметрия». и уже давно используется. зачем везде нейросети пихать когда довольно простые безмозглые алгоритмы делают это отлично и что самое главное — давно
tmplts
Спасибо авторам, хотя, похоже, что публикация на скорую руку, чтобы за КДПВ собрать лайки))
qwertyforce
www.youtube.com/watch?v=j8CUzIR0f8M
Nick_Shl
40 секунда и далее — колено прозрачное. И что-то мне подсказывает, что исправить будет не так-то просто.
algotrader2013
Все равно достойно, как для PoC
Да и, думаю, как фильтр для снапчата или тиктока и так сойдет вполне)
HOMPAIN
Прикольно. На 40вой секунде отражения в полу правильно двигаются с камерой, а не приклеены к полу, вот это прям удивило.
uzverkms
Большая часть примеров это не изменение ракурсов, а долли-зум
Nick_Shl
Кстати о Dolly Zoom — так снималась "трансформация" корабля в фильме "Полёт Навигатора":
masai
К сожалению, статья несколько вводит в заблуждение, поэтому может сложиться впечатление, что это фотограмметрия в чистом виде, но это не совсем так. NeRF можно использовать для фотограмметрии (и есть такие статьи), но тут есть небольшое отличие. Обычно фотограмметрия пытается извлечь информацию об реальных объектах, а тут строится оптическая модель всей среды. Да, это это практически то же самое, но тут больше про изображения, чем про объекты. Мы строи модель не для получения информации об объектах, а чтоб на основе нескольких ракурсов получать изображения с других ракурсов. В общем, отличие не очень большое, но всё же. :)
Жаль, что в статье почти не описана сама идея NeRF (это кстати, скорее семейство методов, а не какая-то одна модель), она достаточно простая и наглядная. Изложу-ка я её для других читателей на всякий случай.
Допустим, у нас есть две фотографии одной сцены с разных ракурсов и мы хотим найти кадр с какого-то промежуточного ракурса. Мы могли бы использовать оценку оптического потока, восстановить модель видимой поверхности или что-то ещё, но эти методы либо работают только для близких ракурсов, либо имеют сложную и многостадийную схему, требующую много памяти.
Поэтому можно сделать следующее. Вместо того, чтоб моделировать частное (проекции сцены), давайте смоделируем сцену целиком. Вот буквально возьмём и для каждой точки сцены найдём её оптические характеристики. В упрощённом виде — цвет и прозрачность.
Но тут возникает вопрос — а как эти характеристики моделировать. Если использовать воксели, то либо разрешение низкое, либо память будет есть как не в себя. Да и скорость тоже будет не очень.
И тут на сцену выходят нейронные сети. Причём тут не используются свёртки или какие-то традиционные для компьютерного зрения модели, а обычный персептрон. Используем тот факт, что персептрон — это условный аппроксиматор. То есть, если подобрать параметры, он может аппроксимировать любую функцию. Так давайте создадим модель, которая на входе получает три координаты, а выдаёт те самые оптические характеристики.
Чтобы эту модель использовать, мы используем трассировку лучей (не ту что в компьютерной графике) — мы для каждого пикселя экрана, расположенного под некоторым углом к сцене, выпускаем луч и интегрируем характеристики сцены вдоль этого луча. Это самое обычное численное интегрирование трёхмерной функции. В итоге мы получаем цвет пикселя.
На фотографиях с известных ракурсов мы восстанавливаем параметры модели, а потом уже используем её для получения изображений под новыми углами.
Это кратко основная идея. Конечно, её потом дополняли, было много последующих статей, но по-моему здорово, что такая простая схема даёт хорошие результаты
По поводу того, что нейронные сети активно используются. Да действительно их часто применяют не к месту, но в целом это мощный инструмент. Некоторые задачи компьютерного зрения без них очень плохо решаются. Сравните, скажем, DeepLab для сегментации и grab cut. Да, оба алгоритма могут решать одну и ту же задачу, но нейронная сеть будет намного точнее, и бессетевого решения с подобной точностью просто нет.
Это не значит, что сети нужно использовать везде и для всего, но и не значит, что нужно от них отказываться.
stakper
Так что, получается, если долго снимать Луну, то в скором времени мы сможем посмотреть, что у неё на той стороне??)