
Привет! Сегодня мы поговорим с вами о том, как эволюционировала архитектура Яндекс.Афиши, а именно — как и почему мы перешли от REST на GraphQL к Node.js + Python, а потом в целях оптимизации избавились от Node.js + Python и переписали весь GraphQL на Java. Это история борьбы за производительность, скорость и удобство работы Афиши и некоторых других сервисов, которая может быть полезна тем, кто планирует оптимизировать ресурсы на своём проекте, ускорить работу запросов в БД, создать быстрый и поддерживаемый API Gateway с удобным языком запросов или разделить устаревший монолит на микросервисы.

Меня зовут Александр Поляков, я больше семи лет работаю в Медиасервисах Яндекса: руководил командой программистов в Афише, а сейчас руковожу разработкой в Яндекс Плюсе. Соавтор этой статьи — мой коллега Михаил Сурин, который руководит разработчиками в Яндекс.Афише сейчас. Теперь, когда наша роль в этой долгой и непростой истории ясна, начнём!
Прежде чем перейти к рассказу об архитектуре, я хочу напомнить, что такое Яндекс.Афиша и какие задачи она решает. Афиша — это сервис для покупки электронных билетов в кино, театры и на концерты. Он также работает на Кинопоиске и других партнёрских сайтах — через Яндекс.Афишу можно приобрести билеты на сеансы в более чем 100 городах России: от Москвы до Южно-Сахалинска.
Но так было не всегда. Сервис был запущен больше десяти лет назад и первоначально лишь помогал пользователям выбрать, куда стоит сходить. По сути он представлял собой каталог событий с расписанием. С точки зрения архитектуры всё это выглядело следующим образом: бэкенд на Python, база — очень популярная тогда MongoDB, фронтенд — Node.js.
Мы изучили рынок, посмотрели, какие технологии и подходы используются: REST, SOAP, RPC, Swagger (Open APi), GraphQL. Лучше остальных всем нашим требованиям отвечал GraphQL. Технологию разработали в Facebook в 2012 году, а в 2015-м выложили в открытый доступ.
GraphQL — язык, который описывает, как запрашивать данные. В основном он используется клиентом для загрузки данных с сервера. Назовём три его основные характеристики:
Как же всё это работает на практике? Владимир Цукур прекрасно рассказал, что такое GraphQL, какие задачи он решает и как с ним работать в своём докладе GraphQL — APIs The New Way. Посмотреть доклад можно ниже, я лишь обращу внимание на основные моменты.
Прежде всего, GraphQL — не база данных. GraphQL — это язык запросов для API и среда, в которой они выполняются.
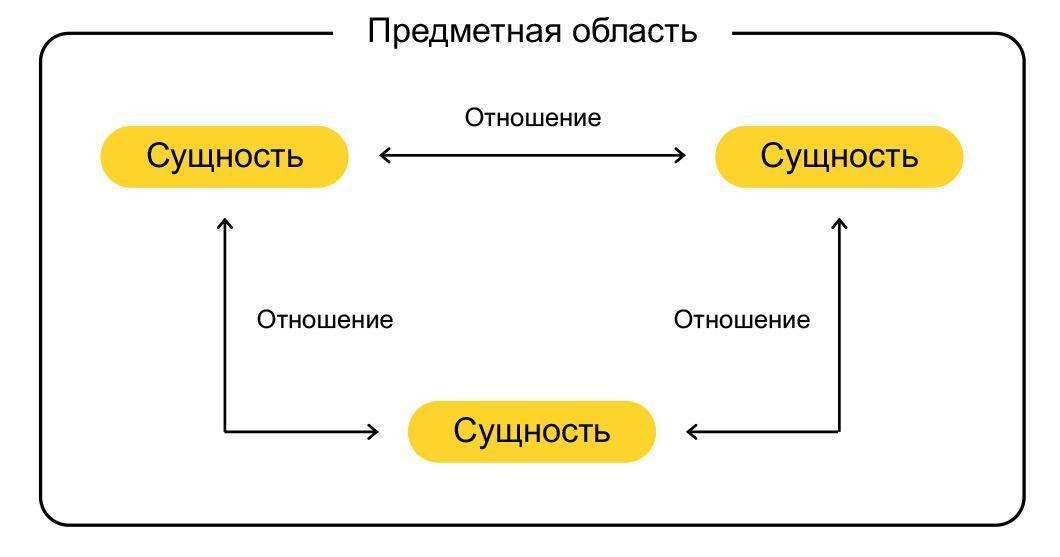
Чтобы начать работать с GraphQL, необходимо задать схему. Предположим, у нас есть социальная сеть, в которой сидят пользователи. У них есть имя, фото профиля, город и друзья, которые тоже зарегистрированы в сети. У города есть название и список жителей, являющихся пользователями. Всё это образует граф:

Теперь предположим, что нам нужно составить запрос на получение всех пользователей с именем Vladimir Unicorn и для каждого из них вывести список друзей и город:
Ответ будет выглядеть следующим образом:
Хорошо видно, что запрос и ответ выглядят очень схоже. При этом сервер вернул только те поля, которые мы у него запрашивали. Самое удивительное то, что все эти данные были отданы сервером за один запрос.
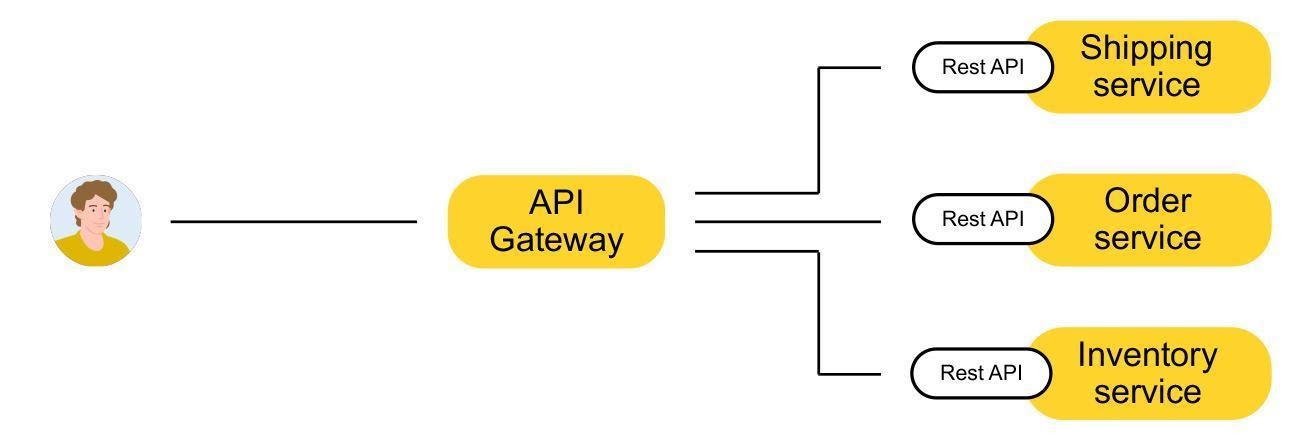
Если клиент работает с REST, ему нужно самому знать, к каким методам обращаться и как собирать ответ. В случае с GraphQL клиент ходит в один API Gateway, который инкапсулирует логику получения данных. По сути клиент пишет запросы декларативно (как, например, в SQL), и с их помощью получает данные от сервера GraphQL.

Вернёмся к Афише. Мы убедились, что GraphQL подходит для решения наших задач, и для начала реализовали GraphQL API gateway на Node.js. Теперь через API к нам стали обращаться: сайт Афиши, приложение, КиноПоиск. Сам GraphQL API посылал запросы в бэкенды Билетов и Афиши.

Параллельно в 2014 году был запущен ещё один сервис — Яндекс.Билеты. Это агрегатор билетных операторов, который позволял не только посмотреть расписание событий, но и купить билеты. Бэкенд был написан на Java, БД — снова MongoDB, фронтенд виджета покупки — Node.js.
В 2016 году мы поняли, что на самом деле Афиша и Билеты отлично дополняют друг друга и решают схожие проблемы, поэтому решили объединить сервисы.
В процессе слияния мы столкнулись со следующими проблемами:
Как мы решали эти проблемы? Сначала отказались от Python-бэкенда, так как экспертности в Java было больше — три монолита свели в один.

Переписали Node.js GraphQL API на Java, потому что в какой-то момент у нас стали сильно снижаться метрики производительности, а в Java, опять же, было много экспертности.

Решили использовать GraphQL всеми внешними фронтендами (в том числе билетным виджетом) и сервисами.
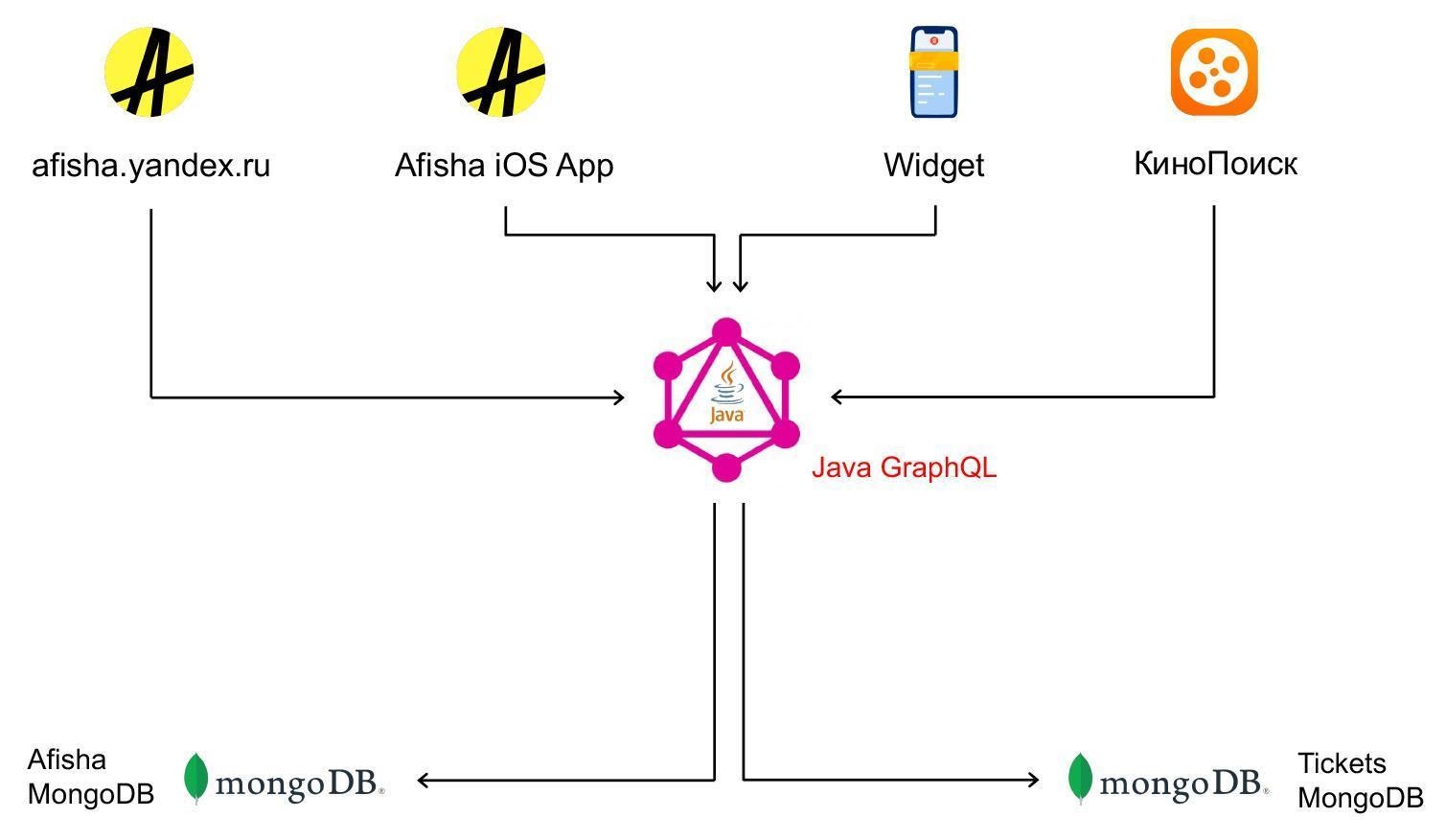
Планируем постепенно разделить получившуюся конструкцию на микросервисы, которые будут взаимодействовать через gRPC.
Все эти изменения происходили вовсе не так гладко, как хотелось бы. В первых версиях новый API работал довольно медленно — пришлось проделать ряд манипуляций, чтобы его ускорить.
В 2018 году, в рамках оптимизации расходов на поддержание многочисленных технологий API Афиши, мы решили заменить JS GraphQL API фронтенда и REST Python API бэкенда единым API, написанным на Java. Он должен был полностью соответствовать схеме JS GraphQL API и работать оптимальнее, чем REST Python API.

Перед началом рефакторинга необходимо было выбрать метрики, по которым мы определим успешность проекта. Важнейшее условие — полностью воспроизвести функциональность текущего API (и ничего не сломать на стороне клиентов). Для этого мы получили существующую GraphQL-схему через запрос интроспекции и написали новое приложение в соответствии с этой схемой. Для оценки производительности нового API мы выбрали запрос, возвращающий информацию для главной страницы Афиши. Исходное время работы запроса составляло 500 миллисекунд.
Первая сложность, с которой мы столкнулись ещё на подготовительном этапе, до того, как начали переписывать API, заключалась в том, что JS GraphQL API был подключен как middleware на сервере, осуществляющем рендеринг страниц. Чтобы иметь возможность заменить JS на Java, сначала пришлось заменить внутренние JS-вызовы на HTTP-запросы. Это сразу же замедлило работу запроса главной страницы на 300 миллисекунд.
В феврале 2019-го начались основные работы по написанию API на Java. Главная цель — сделать всё быстро, сохранив скорость работы главной страницы по HTTP такой же, какой она была на JS, и при этом полностью воспроизвести функциональность старого API.
Через три месяца у нас был готов GraphQL API на Java, полностью аналогичный API на JS. Пришло время провести нагрузочное тестирование и порадоваться тому, как мы в разы увеличили быстродействие приложения.
Вместо этого первый же запуск заставил нас не на шутку испугаться: приложение отказывалось работать. В течение двух минут после старта оно практически не отвечало на запросы, зато потом заработало стабильно и выдержало нагрузку. Однако скорость работы запроса за данными главной страницы упала до неприличного значения — целая секунда.

На самом деле медленный старт — нормальное поведение для Java-приложений, связанное с работой JIT-компилятора. Мы заменили компилятор по умолчанию на экспериментальный GraalVM, и в результате сократили время прогрева с двух минут до 30 секунд:

Лучше, но всё ещё недостаточно для работы в продакшене. Следующим шагом стало добавление Python-скрипта для прогрева компилятора: в течение минуты мы отправляли запросы, похожие на реальные, и только после этого делали приложение доступным для внешнего мира. Такое решение полностью сняло все проблемы старта:

Разбираясь в причинах падения скорости, мы обнаружили, что в JS API часть запросов кэшировалась, и убрали это кэширование, а также добавили Redis для кэширования сложных в обработке запросов по ключу целиком. В итоге получили скорость в 500–600 миллисекунд, что примерно соответствовало уровню приложения, которое мы переписали. В июле 2019 года в продакшен вышло стабильное, поддерживаемое приложение, готовое к дальнейшей оптимизации.
Изучая ответы GraphQL-сервиса на списочные запросы, мы обнаружили, что клиенты почти не используют информацию о пагинации, довольствуясь первой страницей выдачи. Это знание вкупе с мощью GraphQL позволило нам реализовать вычисление данных пагинации только по явному требованию клиента.
Посмотреть, как это работает на практике, можно в проекте по ссылке. Это приложение, позволяющее получить информацию по топ-50 фильмам Кинопоиска.
Например, мы можем взять стандартный REST-подобный запрос списка элементов. Хотим получить 10 фильмов, нам возвращается результат и информация для пагинации — общее количество фильмов в базе. Если мы посмотрим на логи, то увидим два запроса: список элементов (counts) и отдельно запрос общего количества элементов (total).
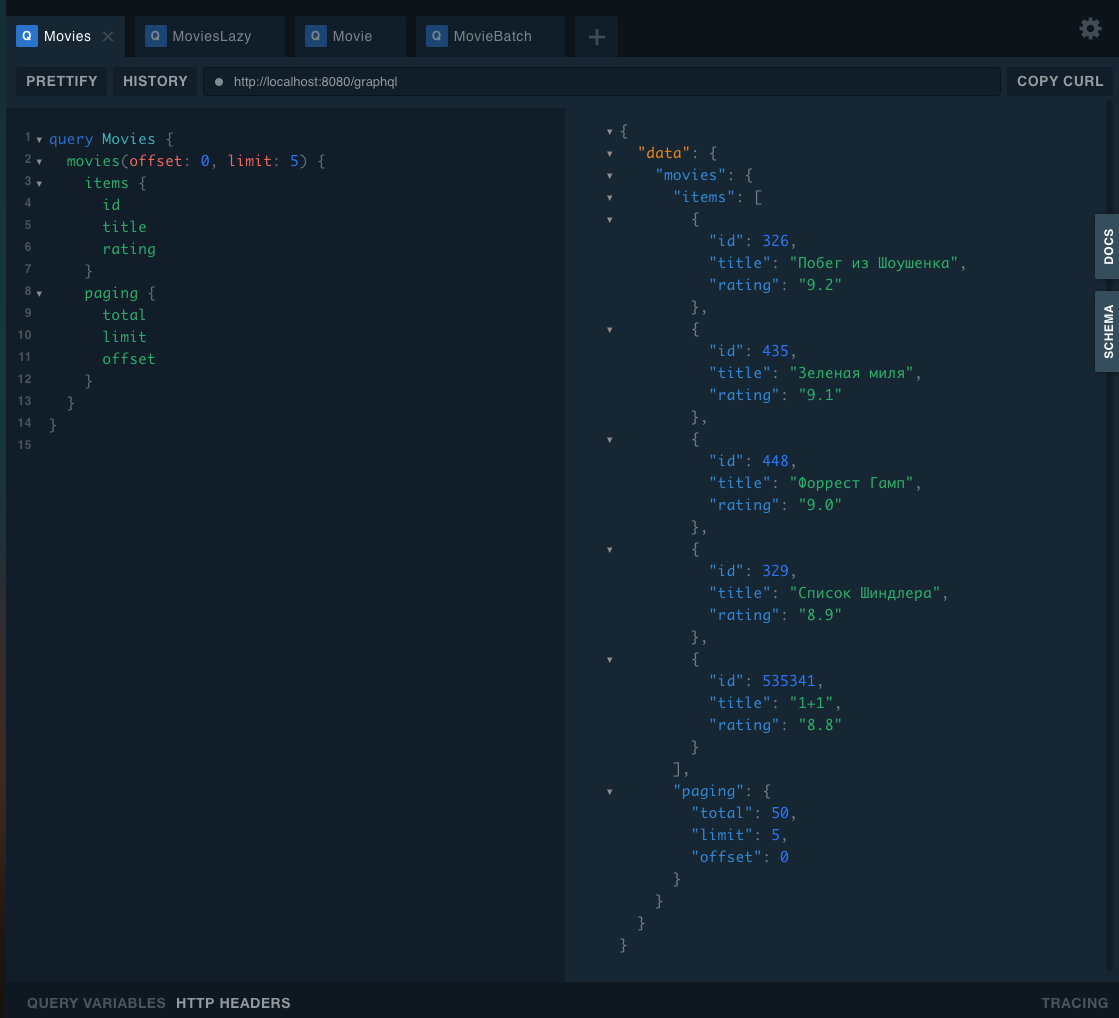

GraphQL позволяет не запрашивать total. Однако если мы его уберём, запросов в базу всё равно останется два. Это происходит, потому что total для ответа всегда вычисляется явным образом.
Перепишем код так, чтобы total вычислялся только по прямому запросу пользователя.

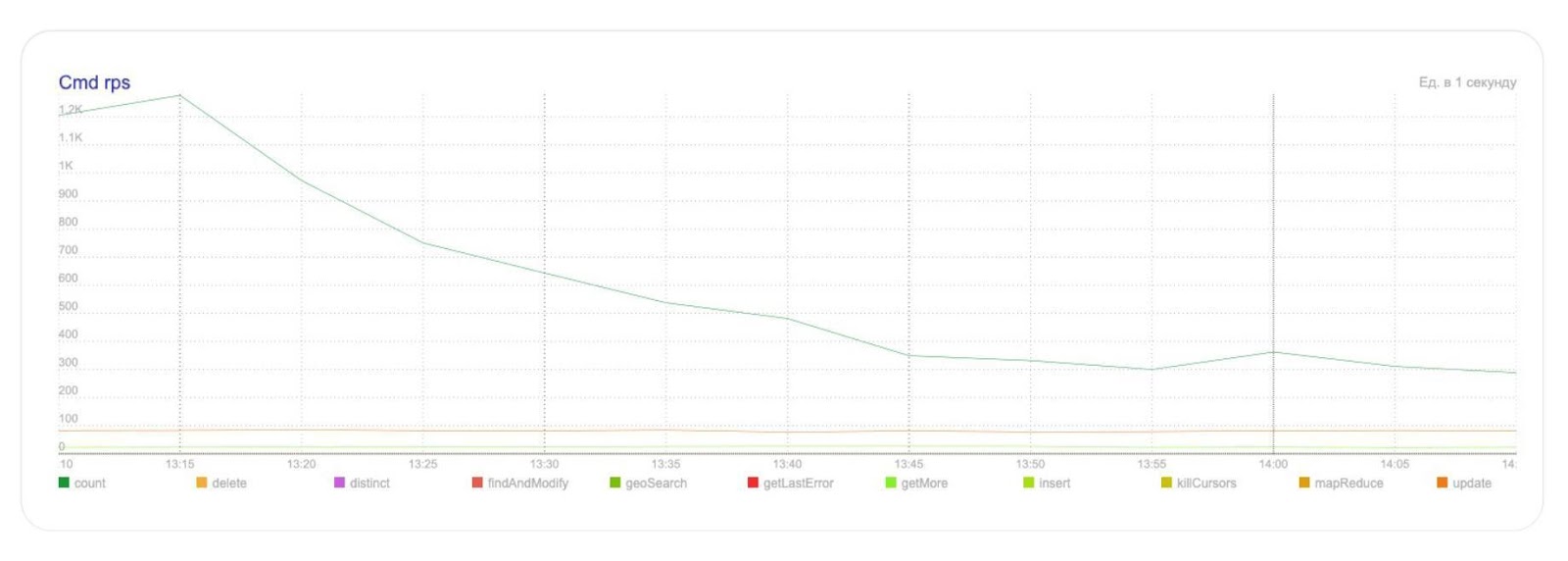
Добавим в ответ метод total, который вызывается, только если поле total запрошено в query. Итог — один запрос в базу.

На графике видно, что таким нехитрым способом мы сократили количество запросов для подсчёта размера коллекции в БД в четыре раза:
Для GraphQL всегда актуальна проблема N+1 запросов, и нас она тоже не обошла стороной. Мы занялись оптимизацией запросов по идентификаторам — это когда мы получаем из базы список элементов по ID, и хотим по тем же ID получить более полные данные.
В коде это выглядит примерно так: видим два отдельных запроса на два фильма по ID 326 и 435. Если мы посмотрим на них, то увидим, что ID 326 — это «Побег из Шоушенка», а ID 435 — «Зелёная миля».
Для оптимизации в подобных ситуациях придуман подход с даталоадерами — это специальные классы, позволяющие объединять запросы объектов по ID и отправлять их в источники данных батчами. Схема работы даталоадера проста: сначала сбор списка идентификаторов, затем получение по списку ID самих элементов и составление словаря. Всё это делается в асинхронной манере. По результатам работы исполняемый код может получить искомый элемент из словаря и вернуть его пользователю.
Итак, теперь у нас есть запрос, возвращающий элементы по ID, который отправляет запросы в базу батчами. Если мы запустим его, то увидим тот же ответ, что и без оптимизации, но в базу будет направлен только один запрос.
Даталоадеры работают в асинхронном режиме, библиотека GraphQL также идеально подходит для асинхронной работы. Мы обсудили возможную оптимизацию с клиентами и по итогу переписали уже непосредственно сами запросы. Query были изменены так, чтобы мы могли получать больше данных параллельно, благодаря чему скорость работы некоторых сложных запросов увеличилась в разы.
На графике — пример запроса с тремя вложенными подзапросами, который мы ускорили в два раза. Время запроса главной страницы сократилось до 250 миллисекунд.

Результатом нашей работы стал быстрый и поддерживаемый API Gateway с удобным для клиентов языком запросов. Если к вам регулярно обращаются с просьбой реализовать новый эндпоинт в API, аналогичный уже существующему, но немного лучше — задумайтесь, возможно, GraphQL — ваш выбор.
Теперь мы можем изменять внутреннее устройство бэкенда без необходимости оповещать клиентов, так как поддерживаем совместимую схему. Благодаря этому стало легче разбивать старые монолитные приложения на микросервисы и оптимизировать использование ресурсов. Если у вас возникают проблемы с монолитом, новый API на GraphQL поможет упростить переход на микросервисную архитектуру.
Благодаря даталоадерам всё общение с источниками данных в Афише сводится к двум типам запросов: список ID объектов по фильтру и запрос за объектами по списку ID. Это прекрасное подспорье на пути создания микросервисов, поставляющих данные. Опять же кажется, что это хороший паттерн проектирования, позволяющий ускорить переезд.
Надеемся, что у вас получилось вынести что-то ценное для себя из многолетнего опыта Яндекс.Афиши и ждём ваши вопросы в комментариях — с радостью на них ответим.
Меня зовут Александр Поляков, я больше семи лет работаю в Медиасервисах Яндекса: руководил командой программистов в Афише, а сейчас руковожу разработкой в Яндекс Плюсе. Соавтор этой статьи — мой коллега Михаил Сурин, который руководит разработчиками в Яндекс.Афише сейчас. Теперь, когда наша роль в этой долгой и непростой истории ясна, начнём!
История изменений в сервисе
Прежде чем перейти к рассказу об архитектуре, я хочу напомнить, что такое Яндекс.Афиша и какие задачи она решает. Афиша — это сервис для покупки электронных билетов в кино, театры и на концерты. Он также работает на Кинопоиске и других партнёрских сайтах — через Яндекс.Афишу можно приобрести билеты на сеансы в более чем 100 городах России: от Москвы до Южно-Сахалинска.
Но так было не всегда. Сервис был запущен больше десяти лет назад и первоначально лишь помогал пользователям выбрать, куда стоит сходить. По сути он представлял собой каталог событий с расписанием. С точки зрения архитектуры всё это выглядело следующим образом: бэкенд на Python, база — очень популярная тогда MongoDB, фронтенд — Node.js.
Какие проблемы у нас возникли
- Не было понятного универсального языка, с помощью которого тестировщики, менеджеры и разработчики могли бы описывать предметную область и формулировать запросы.
- С ростом числа сервисов, отвечающих за функциональность Афиши, нам стало не хватать единой и при этом гибкой модели данных, с помощью которой все они могли бы общаться друг с другом.
- Также потребовалась единая точка входа в сервис — API Gateway, с которым можно общаться в терминах той самой единой модели данных.
- Мы устали писать всё новые и новые методы под каждое требование клиентов. Систему стало сложно поддерживать и развивать. На картинке видно, что только для сущности «Место» мы реализовали шесть методов. А для сущности «Событие» — семь.

- Ответы REST часто содержали либо слишком много данных, либо недостаточно, из-за чего появлялась необходимость в дополнительных запросах. Всё это создавало лишний трафик, который мог быть критичным для устройств, подключенных, например, по 3G, и увеличивало нагрузку на наши сервера.

Мы изучили рынок, посмотрели, какие технологии и подходы используются: REST, SOAP, RPC, Swagger (Open APi), GraphQL. Лучше остальных всем нашим требованиям отвечал GraphQL. Технологию разработали в Facebook в 2012 году, а в 2015-м выложили в открытый доступ.
GraphQL — язык, который описывает, как запрашивать данные. В основном он используется клиентом для загрузки данных с сервера. Назовём три его основные характеристики:
- Позволяет клиенту точно указать, какие данные ему нужны.
{ user(name: "John Smith") { friends { name } city { name population } } } - Облегчает агрегацию данных из нескольких источников.

- Использует систему типов для описания данных.

Как же всё это работает на практике? Владимир Цукур прекрасно рассказал, что такое GraphQL, какие задачи он решает и как с ним работать в своём докладе GraphQL — APIs The New Way. Посмотреть доклад можно ниже, я лишь обращу внимание на основные моменты.
Доклад целиком
Прежде всего, GraphQL — не база данных. GraphQL — это язык запросов для API и среда, в которой они выполняются.
Чтобы начать работать с GraphQL, необходимо задать схему. Предположим, у нас есть социальная сеть, в которой сидят пользователи. У них есть имя, фото профиля, город и друзья, которые тоже зарегистрированы в сети. У города есть название и список жителей, являющихся пользователями. Всё это образует граф:
Теперь предположим, что нам нужно составить запрос на получение всех пользователей с именем Vladimir Unicorn и для каждого из них вывести список друзей и город:
{
user(name: "John Smith") {
friends {
name
}
city {
name
population
}
}
}Ответ будет выглядеть следующим образом:
{
"data": {
"user": {
"friends": [
{ "name": "Janis" },
{ "name": "Anna" },
]
"city" {
"name" : "Anna"
"population”: 641423
}
}
}Хорошо видно, что запрос и ответ выглядят очень схоже. При этом сервер вернул только те поля, которые мы у него запрашивали. Самое удивительное то, что все эти данные были отданы сервером за один запрос.
Первый переезд: GraphQL vs REST
Если клиент работает с REST, ему нужно самому знать, к каким методам обращаться и как собирать ответ. В случае с GraphQL клиент ходит в один API Gateway, который инкапсулирует логику получения данных. По сути клиент пишет запросы декларативно (как, например, в SQL), и с их помощью получает данные от сервера GraphQL.
Вернёмся к Афише. Мы убедились, что GraphQL подходит для решения наших задач, и для начала реализовали GraphQL API gateway на Node.js. Теперь через API к нам стали обращаться: сайт Афиши, приложение, КиноПоиск. Сам GraphQL API посылал запросы в бэкенды Билетов и Афиши.
Слияние сервисов
Параллельно в 2014 году был запущен ещё один сервис — Яндекс.Билеты. Это агрегатор билетных операторов, который позволял не только посмотреть расписание событий, но и купить билеты. Бэкенд был написан на Java, БД — снова MongoDB, фронтенд виджета покупки — Node.js.
В 2016 году мы поняли, что на самом деле Афиша и Билеты отлично дополняют друг друга и решают схожие проблемы, поэтому решили объединить сервисы.
В процессе слияния мы столкнулись со следующими проблемами:
- Дублирование. Многие компоненты систем, написанные разными командами в разное время, повторяли друг друга, например: импорты событий, расписаний, проклейка, админки.
- «Зоопарк» технологий, инструментов и решений: Python и Java на бэкенде, БЭМ и React на фронтенде.
- Хранение данных. Две разные базы данных, синхронизация и переимпорты отнимают много времени.
Как мы решали эти проблемы? Сначала отказались от Python-бэкенда, так как экспертности в Java было больше — три монолита свели в один.
Переписали Node.js GraphQL API на Java, потому что в какой-то момент у нас стали сильно снижаться метрики производительности, а в Java, опять же, было много экспертности.
Решили использовать GraphQL всеми внешними фронтендами (в том числе билетным виджетом) и сервисами.
Планируем постепенно разделить получившуюся конструкцию на микросервисы, которые будут взаимодействовать через gRPC.
Все эти изменения происходили вовсе не так гладко, как хотелось бы. В первых версиях новый API работал довольно медленно — пришлось проделать ряд манипуляций, чтобы его ускорить.
Второй переезд: оптимизация и рефакторинг
В 2018 году, в рамках оптимизации расходов на поддержание многочисленных технологий API Афиши, мы решили заменить JS GraphQL API фронтенда и REST Python API бэкенда единым API, написанным на Java. Он должен был полностью соответствовать схеме JS GraphQL API и работать оптимальнее, чем REST Python API.
Перед началом рефакторинга необходимо было выбрать метрики, по которым мы определим успешность проекта. Важнейшее условие — полностью воспроизвести функциональность текущего API (и ничего не сломать на стороне клиентов). Для этого мы получили существующую GraphQL-схему через запрос интроспекции и написали новое приложение в соответствии с этой схемой. Для оценки производительности нового API мы выбрали запрос, возвращающий информацию для главной страницы Афиши. Исходное время работы запроса составляло 500 миллисекунд.
Первая сложность, с которой мы столкнулись ещё на подготовительном этапе, до того, как начали переписывать API, заключалась в том, что JS GraphQL API был подключен как middleware на сервере, осуществляющем рендеринг страниц. Чтобы иметь возможность заменить JS на Java, сначала пришлось заменить внутренние JS-вызовы на HTTP-запросы. Это сразу же замедлило работу запроса главной страницы на 300 миллисекунд.
Проблема медленного старта
В феврале 2019-го начались основные работы по написанию API на Java. Главная цель — сделать всё быстро, сохранив скорость работы главной страницы по HTTP такой же, какой она была на JS, и при этом полностью воспроизвести функциональность старого API.
Через три месяца у нас был готов GraphQL API на Java, полностью аналогичный API на JS. Пришло время провести нагрузочное тестирование и порадоваться тому, как мы в разы увеличили быстродействие приложения.
Вместо этого первый же запуск заставил нас не на шутку испугаться: приложение отказывалось работать. В течение двух минут после старта оно практически не отвечало на запросы, зато потом заработало стабильно и выдержало нагрузку. Однако скорость работы запроса за данными главной страницы упала до неприличного значения — целая секунда.
На самом деле медленный старт — нормальное поведение для Java-приложений, связанное с работой JIT-компилятора. Мы заменили компилятор по умолчанию на экспериментальный GraalVM, и в результате сократили время прогрева с двух минут до 30 секунд:
Лучше, но всё ещё недостаточно для работы в продакшене. Следующим шагом стало добавление Python-скрипта для прогрева компилятора: в течение минуты мы отправляли запросы, похожие на реальные, и только после этого делали приложение доступным для внешнего мира. Такое решение полностью сняло все проблемы старта:
Разбираясь в причинах падения скорости, мы обнаружили, что в JS API часть запросов кэшировалась, и убрали это кэширование, а также добавили Redis для кэширования сложных в обработке запросов по ключу целиком. В итоге получили скорость в 500–600 миллисекунд, что примерно соответствовало уровню приложения, которое мы переписали. В июле 2019 года в продакшен вышло стабильное, поддерживаемое приложение, готовое к дальнейшей оптимизации.
GraphQL для оптимизации запросов
Оптимизация списочных запросов
Изучая ответы GraphQL-сервиса на списочные запросы, мы обнаружили, что клиенты почти не используют информацию о пагинации, довольствуясь первой страницей выдачи. Это знание вкупе с мощью GraphQL позволило нам реализовать вычисление данных пагинации только по явному требованию клиента.
Посмотреть, как это работает на практике, можно в проекте по ссылке. Это приложение, позволяющее получить информацию по топ-50 фильмам Кинопоиска.
Например, мы можем взять стандартный REST-подобный запрос списка элементов. Хотим получить 10 фильмов, нам возвращается результат и информация для пагинации — общее количество фильмов в базе. Если мы посмотрим на логи, то увидим два запроса: список элементов (counts) и отдельно запрос общего количества элементов (total).
GraphQL позволяет не запрашивать total. Однако если мы его уберём, запросов в базу всё равно останется два. Это происходит, потому что total для ответа всегда вычисляется явным образом.
Перепишем код так, чтобы total вычислялся только по прямому запросу пользователя.
Добавим в ответ метод total, который вызывается, только если поле total запрошено в query. Итог — один запрос в базу.
На графике видно, что таким нехитрым способом мы сократили количество запросов для подсчёта размера коллекции в БД в четыре раза:
Оптимизация получения объектов по ID
Для GraphQL всегда актуальна проблема N+1 запросов, и нас она тоже не обошла стороной. Мы занялись оптимизацией запросов по идентификаторам — это когда мы получаем из базы список элементов по ID, и хотим по тем же ID получить более полные данные.
В коде это выглядит примерно так: видим два отдельных запроса на два фильма по ID 326 и 435. Если мы посмотрим на них, то увидим, что ID 326 — это «Побег из Шоушенка», а ID 435 — «Зелёная миля».
Для оптимизации в подобных ситуациях придуман подход с даталоадерами — это специальные классы, позволяющие объединять запросы объектов по ID и отправлять их в источники данных батчами. Схема работы даталоадера проста: сначала сбор списка идентификаторов, затем получение по списку ID самих элементов и составление словаря. Всё это делается в асинхронной манере. По результатам работы исполняемый код может получить искомый элемент из словаря и вернуть его пользователю.
Итак, теперь у нас есть запрос, возвращающий элементы по ID, который отправляет запросы в базу батчами. Если мы запустим его, то увидим тот же ответ, что и без оптимизации, но в базу будет направлен только один запрос.
Даталоадеры работают в асинхронном режиме, библиотека GraphQL также идеально подходит для асинхронной работы. Мы обсудили возможную оптимизацию с клиентами и по итогу переписали уже непосредственно сами запросы. Query были изменены так, чтобы мы могли получать больше данных параллельно, благодаря чему скорость работы некоторых сложных запросов увеличилась в разы.
На графике — пример запроса с тремя вложенными подзапросами, который мы ускорили в два раза. Время запроса главной страницы сократилось до 250 миллисекунд.
Заключение
Результатом нашей работы стал быстрый и поддерживаемый API Gateway с удобным для клиентов языком запросов. Если к вам регулярно обращаются с просьбой реализовать новый эндпоинт в API, аналогичный уже существующему, но немного лучше — задумайтесь, возможно, GraphQL — ваш выбор.
Теперь мы можем изменять внутреннее устройство бэкенда без необходимости оповещать клиентов, так как поддерживаем совместимую схему. Благодаря этому стало легче разбивать старые монолитные приложения на микросервисы и оптимизировать использование ресурсов. Если у вас возникают проблемы с монолитом, новый API на GraphQL поможет упростить переход на микросервисную архитектуру.
Благодаря даталоадерам всё общение с источниками данных в Афише сводится к двум типам запросов: список ID объектов по фильтру и запрос за объектами по списку ID. Это прекрасное подспорье на пути создания микросервисов, поставляющих данные. Опять же кажется, что это хороший паттерн проектирования, позволяющий ускорить переезд.
Надеемся, что у вас получилось вынести что-то ценное для себя из многолетнего опыта Яндекс.Афиши и ждём ваши вопросы в комментариях — с радостью на них ответим.











PerlPower
Часто вижу этот аргумент, но почему нельзя выносить такие запросы в условный /v1/optimized/events/*? Где будут выдавать именно структуры данных только с нужными полями. На большом количестве специальных запросов это становится проблемой, потому что на сервере начинается дублирование кода или частичное переизобретение GraphQL. Но, например, в случае если схожести у запросов мало, то даже на количестве оных в пару десятков все смотрится нормально. Каков по вашему критерий когда стоит перестать дописывать REST и переходить на GraphQL?
Вы имеете в виду на сервер будет отправлен только один запрос, или GraphQL может действительно собирать запросы к базе в один?
Dogrtt
GraphQL либы, как я понял, ничего не умеют сами по себе (да и не должны, этож просто способ). Если надо получить список друзей пользователя, то придётся писать самому резолвер поля модели, который уже дёрнет нужный сервис (REST, RPC, etc.) или напрямую достанет из базы. Единственное, если не ошибаюсь, GraphQL клиенты сами маршализируют (вроде так называется) тела ответов согласно пришедшей схеме запроса.
Carduelis
По факту это лишь инструмент подачи агрегированной информации. Того же самого можно добиться используя REST. Все те же идеи встраивания дополнительных сущностей в те или иные запросы, уменьшая их количество.
Однако самая проблема касается как раз построения этого графа/связей на бекенде.
avpuser Автор
В этом случае вам придется писать всё новые и новые методы под каждое требование клиентов. Систему в итоге станет сложно поддерживать и развивать. А главное, что вы становитесь заложником клиентов, а их может быть очень много. При этом каждое изменение будет требовать разработки, тестирования и выкладки в продакшн.
Все сильно зависит то того, сколько различных типов клиентов будет/есть у вашего REST и насколько часто они просят вас делать "специальные" методы для их нужд. Еще стоит обратить внимание, что существует довольно много клиентских реализаций для работы с GraphQL. И, согласно нашему опыту, общаться с API через них сильно проще, чем писать кастомный код про REST методы.
Да, все верно. Технология GraphQL позволяет на сервере собирать сложные ответы в одном запросе. Работает это следующим образом. У вас в проекте может быть несколько простых REST микросервисов, которые должны реализовывать следующие типы методы:
получить объект по ID;
получить список объектов по списку ID;
отыскать список ID по заданным критериям.
Далее в самом GraphQL применяется подход с даталоадерами, специальными классами, которые позволяют объединять запросы объектов по ID и отправлять их в источники данных батчами.
PerlPower
А насколько просто писать резолверы хотя бы просто для классических SQL баз? Можно ли полностью полагаться на иструменты типа join-monster?
Kwisatz
А мутации вы оставили согласно спецификации graphQL? Тоже перехожу на нее но не с REST а с JsonRPC и мне прям сильно не нравится спека мутаций, может конечно не докурил чего то.
Antimony
Мутации выглядят громоздко, тут должен согласиться. Но во-первых большинство клиентов будут использовать фреймворки (Apollo для js по словам наших фронтенд разработчиков очень удобен для разработки приложений на react например), во-вторых даже без фреймворков в итоге всё равно всё сводится к написанию объектов для запросов в JSON, так же как в JSON-RPC по сути. Мутации потребуют небольшую обвязку, которая будет написана в одном классе-построителе запросов
Kwisatz
Дело не только в громозlкости, мне сам подход не нравится настолько что почти готов его перепроектировать
Ну вот взять из доки пример:
И сравнить с JsonRPC с передачей объекта параметром (на вскидку)
во втором случае мне, как разработчику помнить имя метода совершенно ни к чему. Плюс мене громоздко, более читаемо и серверный код под такие методы проще и красивее.
Про обвязку не совсем понял, каким образом один класс избавит нас от гобального неймспейса имен мутаций и описаний ради описаний?
Antimony
Такого вида мутацию генерирует как раз библиотека, если то же самое писать руками, то оно может выглядеть так
то есть по сути тот же запрос как и в JSON-RPC, только вместо reviews.add мутация createReview. Можно договорённостями это решить, пусть называется не createReview а addReview, тогда тоже помнить ничего не надо.
Про обвязку я имел ввиду что часть запроса с mutation и именем запроса можно вынести в общий код (если договориться о нейминге мутаций заранее). Из ответа можно только id всегда возвращать например, тогда и часть с query уйдёт в общую библиотеку, останется только параметры подсовывать верные.
Kwisatz
Хм, вот тот факт что наименование запроса на мутацию не есть обязательно я как то упустил. Думаю может попробовать имена мутаций в стиле «mutations.add», так сказать ужика с ежиком. В принципе переписать анализатор запроса не есть проблема, заодно и избавлюсь от столь раздражающего глобального неймспеса.
ЗЫ раз у вас опыта поболе, не подскажете: в спецификации не вижу ничего о блоке с метаинформацией присущей запросу, плохо смотрю? У нас сейчас любой ответ от сервера отдает блок meta с токеном(ами) и пагинацией и прочими query-specific данными, это очень удобно.
Antimony
По спецификации GraphQL в ответе на запрос есть следующие поля: data, для собственно ответа, errors для ошибок обработки внутренних запросов и extensions для служебной информации. Туда например складывается информация по трейсингу работы каждого подзапроса, если доступно. Мне кажется это самое лучшее место для того чтобы там передавать метаданные которые вас нужны для обработки ответа.
Kwisatz
Да я видел эту секцию в описании, но с гуглом не подружился на тему «туда ли класть сессионые ключи и итд».
Спасибо, посмотрю пристальней
DavidNadejdin
GraphQL позволяет, одним запросом к серверу, отправить несколько запросов или мутаций. Касаясь вопроса кол-ва запрос к базе, нужно помнить что GrapqhQL сам по себе лишь спецификация и конкретное поведение, зависит только от конкретной реализации