
Сегодня мы покажем, как настроить мониторинг кластера OpenShift с помощью внешней системы на примере Zabbix. А также, как использовать при этом Prometheus, иначе говоря, собирать Prometheus-метрики по кластеру OpenShift, затем регистрировать их в Zabbix в качестве коллекций и создавать там триггеры, своевременно информирующие о проблемах.
Мониторинг инфраструктуры Openshift 4.x с помощью Zabbix Operator
Для установки агентов Zabbix на кластер Openshift Cluster будем использовать оператор Zabbix. Затем сконфигурируем их так, чтобы они отправляли собираемые данные на внешний Zabbix Server, как показано на схеме ниже.
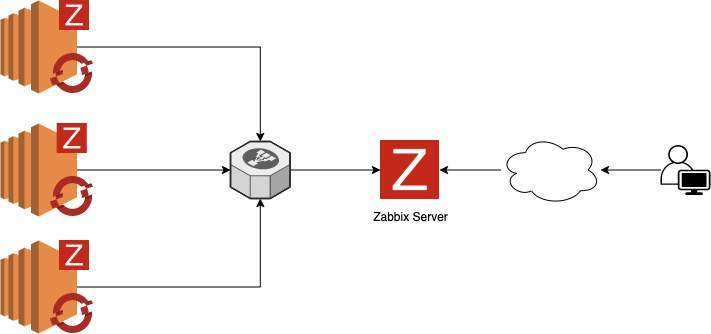
Установка Zabbix Server
? Первым делом обновим сервер и поставим httpd:
$ dnf update -y && dnf install @httpd -y
$ sed -i 's/^SELINUX=.*/SELINUX=permissive/g' /etc/selinux/config
$ systemctl enable --now httpd
$ systemctl status httpd? Затем установим и настроим СУБД MariaDB:
$ dnf -y install mariadb mariadb-server
$ systemctl start mariadb
$ mysql -u root -e "CREATE DATABASE zabbix character set utf8 collate utf8_bin;"
$ mysql -u root -e "GRANT ALL PRIVILEGES ON zabbix.* TO zabbix@'localhost' IDENTIFIED BY 'StrongPassword';"
$ mysqladmin flush-privileges
Note: If the database server is separate from the zabbix server, replace localhost with the zabbix server IP, example: zabbix@'1.2.3.4 '? Теперь ставим сам Zabbix Server:
# Install zabbix repository
$ dnf -y install https://repo.zabbix.com/zabbix/5.0/rhel/8/x86_64/zabbix-release-5.0-1.el8.noarch.rpm
# Install packages needed
$ dnf -y install zabbix-server-mysql zabbix-web-mysql zabbix-apache-conf zabbix-agent
# Restore database schema
$ zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -u zabbix -p zabbix
# Adjust the database parameters
$ vim /etc/zabbix/zabbix_server.conf
# Parameters
DBName=zabbix
DBUser=zabbix
DBPassword=StrongPassword
# Adjust timezone if necessary
$ vim /etc/php-fpm.d/zabbix.conf
# Parameters
php_value[date.timezone] = America/Sao_Paulo
# Adjust php.ini
$ vim /etc/php.ini
# Parameters
memory_limit 128M
upload_max_filesize 8M
post_max_size 16M
max_execution_time 300
max_input_time 300
max_input_vars 10000
# Restart and Enable Services
$ systemctl restart zabbix-server zabbix-agent httpd php-fpm mariadb
$ systemctl enable zabbix-server zabbix-agent httpd php-fpm mariadb
# Now we will access our graphical interface to complete the installation process, go to:
http://<< IP ADDRESS or FQDN >>/zabbix
# In the welcome screen, click Next step
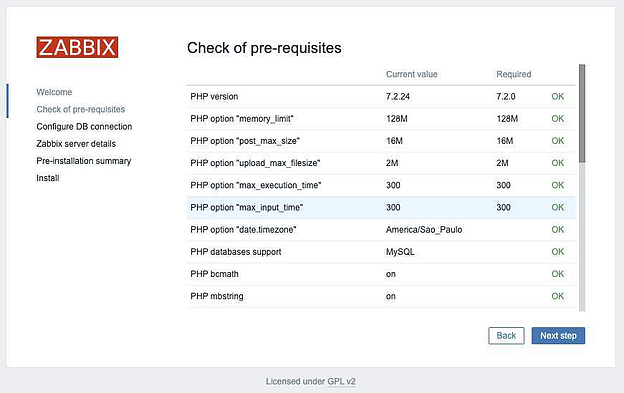
Удостоверимся, что все требования в наличии , и нажимаем Next:
Вводим учетные данные для подключения к БД и жмем Next:

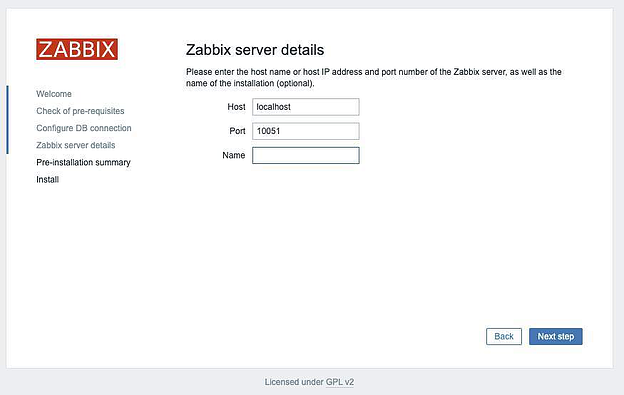
Поле Name можно не заполнять. Проверяем остальное и жмем Next:
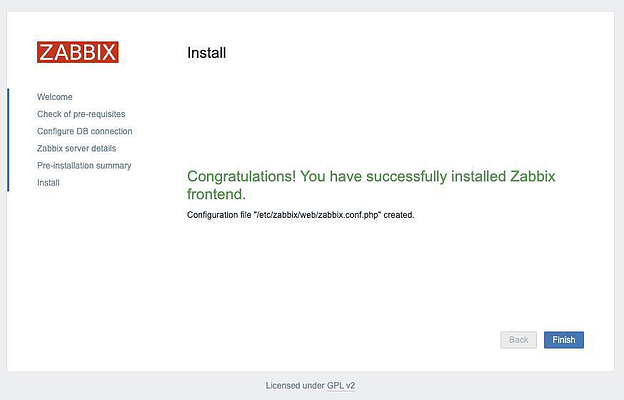
Перепроверяем, нажимаем Next, а затем Finish:
Настройка Zabbix Server
Логинимся, используя следующие учетные данные:
Username: Admin
Password: zabbix
Пароль пользователя Admin, конечно, лучше затем поменять.
Итак, мы вошли в систему и видим дашборд по умолчанию:
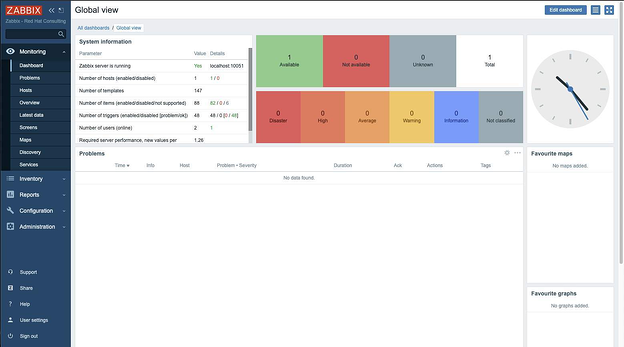
Теперь создадим группу хостов для серверов Openshift:
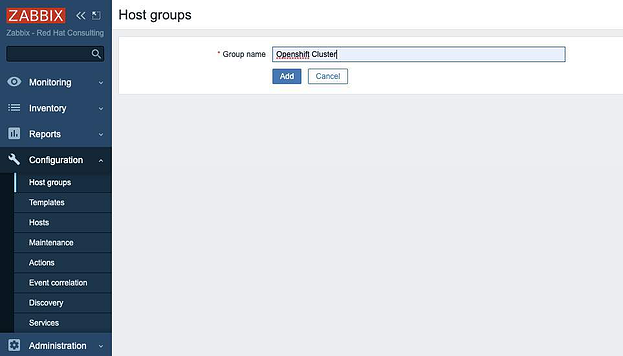
Нажимаем Configuration > Host Groups > Create host group, вводим имя группы и жмем Add:
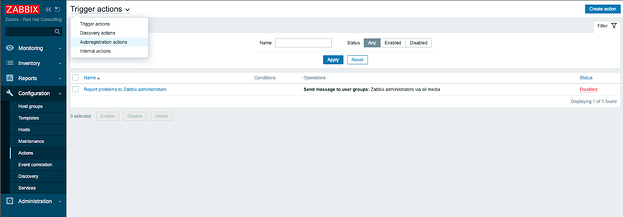
Теперь настроим саморегистрацию агентов, чтобы наши ноды регистрировались в zabbix автоматически. Для этого щелкаем в боковом меню Configuration > Actions, затем в раскрывающемся списке вверху вкладки выбираем Autoregistrion actions и щелкаем Create action:
Настраиваем action, используя следующие значения, и затем жмем Add:
Type: Host metadata
Operator: contains
Value: Linux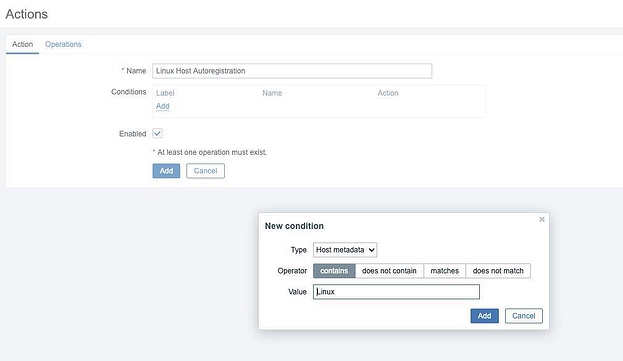
На вкладке Operations щелкаем Add и вводим следующие операции:
Operation type: Add to host group
Host groups: Name of Host Group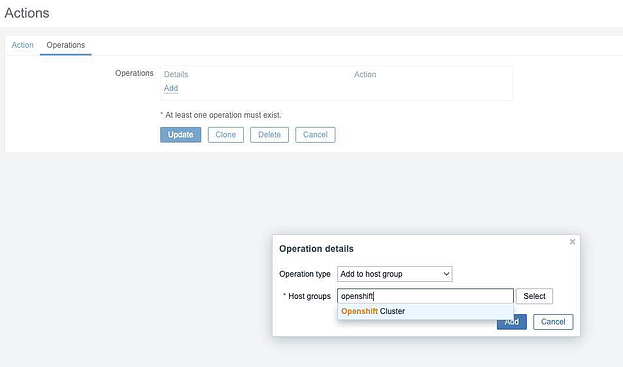
Добавляем новые операции:
Operation type: Link to template
Templates: Template OS Linux by Zabbix agent active
После такой настройки каждый новый агент будут автоматически регистрироваться в группе «OpenShift Cluster» и получать шаблон «Template OS Linux by Zabbix agent active».
Установка Zabbix Operator
Теперь установим и настроим Zabbix Operator на Openshift.
В OperatorHub ищем и выбираем Zabbix, а затем щелкаем Install:
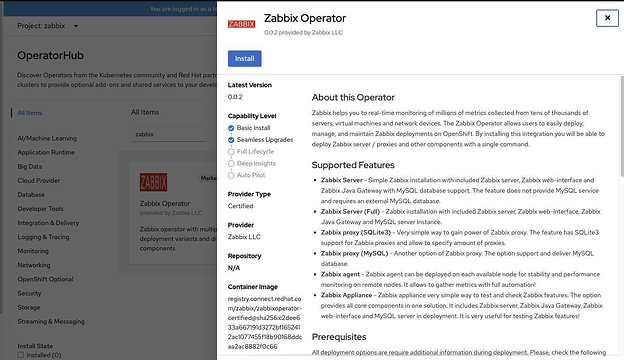
Еще раз щелкаем Install:
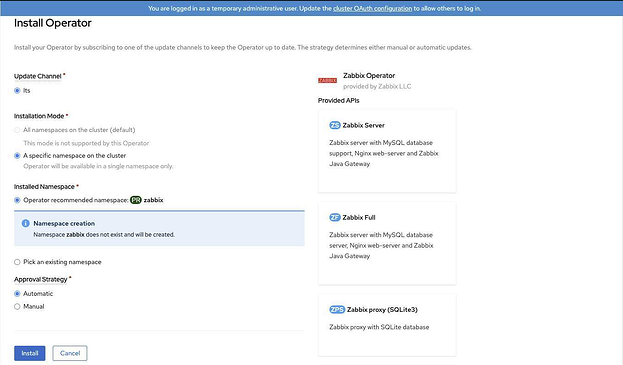
Дожидаемся завершения установки и щелкаем имя Zabbix Operator:
Ищем вкладку Zabbix Agent, щелкаем там Create ZabbixAgent > Select YAML View, задаем приведенные ниже параметры и жмем Create:
metadata_item: 'system.uname'
server_host: <IP or FQDN Zabbix Server>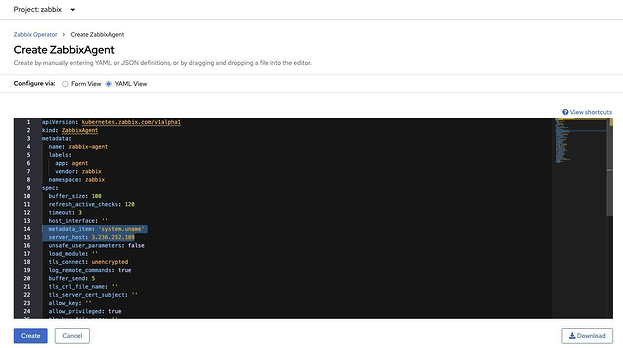
Настройка Zabbix Operator
Теперь в проекте Zabbix щелкаем Daemonset > zabbix-agent > Tolerations и добавляем Toleration с указанными ниже параметрами, чтобы создать поды на master-нодах:
KEY: node-role.kubernetes.io/master
OPERATOR: Exists
EFFECT: NoSchedule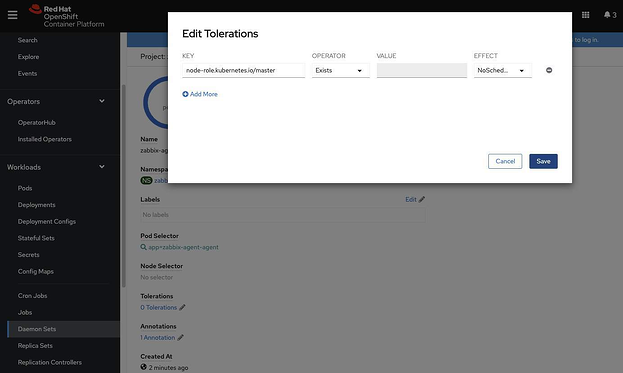
Как видим, daemonset смасшитабировался до 5 подов (3 master-а и 2 worker-а)
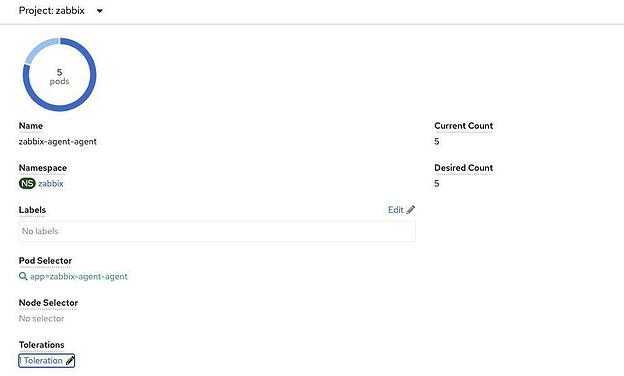
Запросим список подов, чтобы просто проверить имена и статус:
oc get pods -o wide -n zabbix
Теперь в консоли Zabbix идем в Configuration > Hosts.
Если все работает, то увидим здесь список созданных хостов:

Для большей наглядности щелкнем имя хоста и добавим к OpenShift-имени (поле Host name) еще и понятное имя в поле Visible name, а затем нажмем Update:

Чтобы понять, отправляют ли уже наши хосты данные на Zabbix Server, щелкнем Monitoring > Latest data.
На этом экране отображается список уже собранных элементов вместе со значениями, а также дата и время последнего сбора данных:
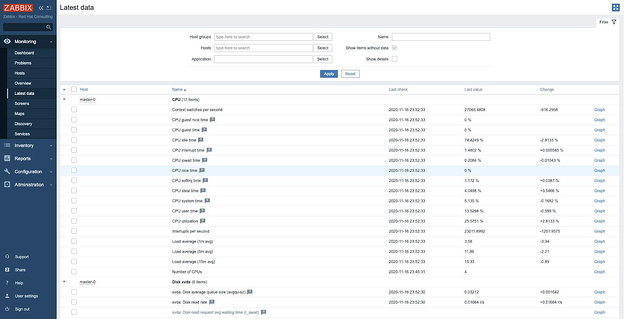
Итак, теперь Zabbix ведет мониторинг нашего кластера:
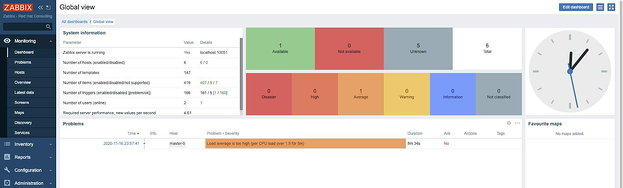
ак, мы показали, как мониторить неизменную инфраструктуру Openshift с помощью Zabbix Operator. Собирая данные по использованию ресурсов (cpu, нагрузка, память, сеть, дисковое пространство), затем можно создавать оповещения и задавать пороги предупреждений, чтобы упреждать критическое развитие ситуации с ресурсами.
Мониторинг Openshift 4.x через Zabbix с использованием Prometheus
Теперь покажем, как мониторить кластер Openshift с помощью Zabbix и Prometheus, то есть собирать Prometheus-метрики мониторинга по нашему кластеру OpenShift, затем регистрировать их в качестве коллекций и создавать триггеры, своевременно информирующие о проблемах.
Для этого мы будем использовать следующие функции Zabbix:
http agent – отвечает за сбор наших метрик.
LLD (low level discovery) – отвечает за автоматическое обнаружение объектов и позволяет создавать собственные элементы и триггеры.
Используя элементы типа http agent, мы создадим объекты конечная точка/metrics, которые будут собирать данные из целевого списка Prometheus (target list) и сохранять эти коллекции по адресу \metric в выводе Zabbix.
Затем, используя LLD, мы будем парсить этот вывод, потом обрабатывать и фильтровать метрики, которые нас интересуют, и наконец, сформируем правило для автоматического создания элементов и триггеров.
Итак, начнем.
1. Берем Prometheus-овский url и обращаемся к context/targets, чтобы посмотреть, какие цели мы можем мониторить с помощью Zabbix:
oc get routes -n openshift-monitoring | grep prometheus-k8s2. Идентифицировав Prometheus-овский url, заходим через браузер и ищем конечные точки по IP-адресам в том же диапазоне, что и ноды openshift, в нашем примере это 10.36.250.x:
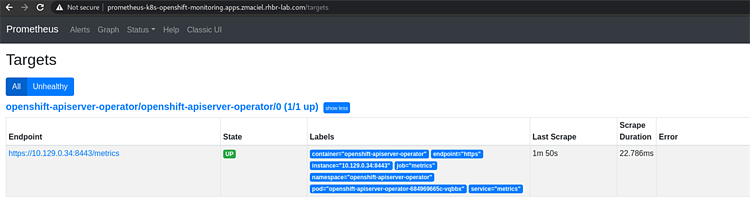
Здесь мы будем мониторить статус Cluster Operators, для чего будем использовать вот эту конечную точку:

3. При обращении к url целевого элемента cluster-operator-version видим несколько метрик, относящихся к операторам. Но мы будем использовать только метрику cluster_operator_up, которая выдает 1, когда оператор в порядке, и 0, когда есть проблемы.

4. В Zabbix идем в Configuration > Host > Create Host и добавляем новый хост, задаем для него понятное имя, затем выбираем для него соответствующую группу и нажимаем Add:
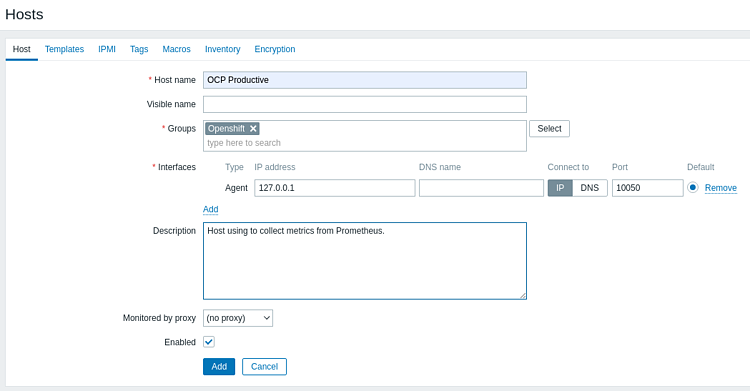
5. Теперь щелкаем только что добавленный хост, затем щелкаем Items > Create Item, задаем указанные ниже поля и жмем Add:
Поле | Значение |
Name | Prometheus Metrics Operators |
Type | HTTP agent |
Key | prom_operators |
URL | https://{{ IP ADDRESS }}:9099/metrics |
Request type | GET |
Request body type | Raw data |
Type of Information | Text |
Update Interval | 30s |
Значения Name, Key и Update Interval можно настраивать.

6. Теперь создадим правило Discovery rule, для этого идем в Configuration > Hosts > щелкаем созданный выше хост > Discovery rules > Create discovery rule
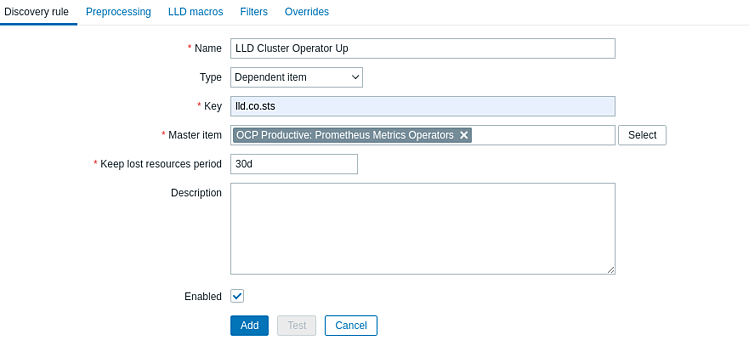
Поле | Значение |
Name | LLD Cluster Operator Up |
Type | Dependent item |
Key | lld.co.sts |
Master item | Prometheus Metrics Operators |
В поле Name задаем понятное имя, в поле Type указываем Dependent item, поскольку этот LLD зависит от нашего элемента http agent, созданного на предыдущем шаге. В Master item, выбираем нашу коллекцию Prometheus Metrics Operators
7. На этом же экране щелкаем Preprocessing, затем Add, выбираем Prometheus to JSON и в поле Parameters добавляем одну из коллекций, которые хотим добавить, например:
cluster_operator_up {name = "authentication", version = "4.7.3"}Поскольку мы хотим добиться автоматического обнаружения, то меняем Name и Version следующим образом:
cluster_operator_up{name=~".*",version=~".*"}
На этом шаге наша коллекция метрик, заданная как plain text, будет преобразована в json. Чтобы проверить и идентифицировать нужные поля, воспользуемся опцией тестирования:
Щелкаем расположенную справа надпись Test, в поле Value копируем какую-нибудь метрику из тех, что собираются в Prometheus, затем щелкаем Test и потом щелкаем результат, чтобы получить нашу метрику в формате json. Теперь мы знаем, какие поля нам понадобятся, когда будем делать сопоставление (mapping) на следующем шаге.
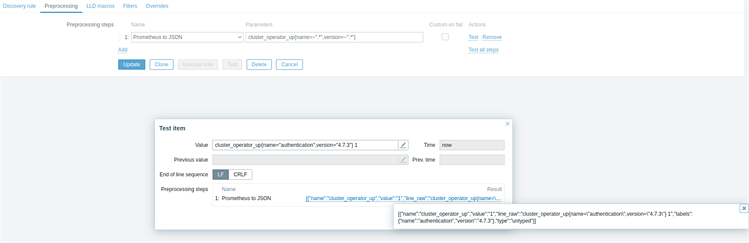
Наша метрика имеет следующую структуру в формате json:
[
{
"name":"cluster_operator_up",
"value":"1",
"line_raw":"cluster_operator_up{name=\"authentication\",version=\"4.7.3\"} 1",
"labels":{
"name":"authentication",
"version":"4.7.3"
},
"type":"untyped"
}
]8. Теперь щелкаем LLD macros. На этом шаге сопоставим поля нашего json-а и создадим макросы, то есть переменные для Zabbix. Имена, определенные в столбце LLD macro, при необходимости можно настроить, всегда сохраняя стандарт {#NAME}. JSONPath прописываем в соответствии с нашим json, используя стандартные $ ['name'] и $ .labels ['name']. И в конце нажимаем Add.
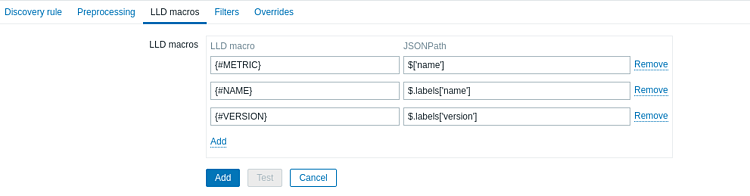
9. Итак, LLD создан. Теперь надо, чтобы он автоматически создавал элементы нашей коллекции, то есть, создавал элемент для каждого оператора на основе нашего правила LLD. Для этого идем в Item prototypes > Create item prototype:

Поле | Значение |
Name | {#METRIC} on {#NAME} |
Type | Dependent item |
Key | ocp.co.stats[{#NAME}] |
Master item | OCP Productive: Prometheus Metrics Operators |
Type of Information | Numeric(unsigned) |
New Application / Applications | Operators |
Description | {#METRIC} on {#NAME} |
В полях Name, Key и Description используем только что созданные макросы/переменные. Для настройки/персонализации создания наших элементов значение поля Key можно настроить по своему усмотрению, однако важно использовать макрос с уникальным значением, чтобы при создании не было дублирования.
Опция New Application позволяет организовать созданные элементы в соответствии с типом коллекции. Так как эта коллекция относится к операторам, мы создадим приложение под названием Operators.
Важно отметить, что время сбора данных для этих элементов (collection time) будет таким же, как и время сбора, заданное для коллекции с типом http agent, которая была создана на шаге 5.
10. Не покидая эту страницу, где мы создаем прототип элемента, щелкаем Preprocessing, в разделе Preprocessing steps щелкаем Add, выбираем Prometheus Pattern и в Parameters пишем следующий синтаксис:
{#METRIC}{name="{#NAME}",version="{#VERSION}"}
Используя этот синтаксис, воспроизведем формат нашей метрики, но используя макросы/переменные, созданные на шаге 8. Затем нажмем Add (или Update, если до этого уже нажали Add, когда закончили создавать прототипа элемента).
11. Теперь проверим, работает ли наш LLD. Для этого идем в Monitoring > Latest data > и используя фильтры для облегчения поиска, выбираем группу хостов, хост и приложение, а затем жмем Apply:
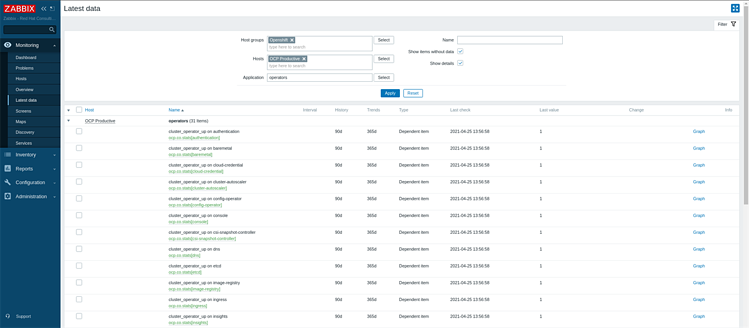
Если все правильно, то увидим наши элементы с указанием соответствующей коллекции. Чтобы проверить, что метрика была создана верно, щелкаем нужный элемент и затем щелкаем Preprocessing:

Проверяем поле Parameters, которое автоматически заполнилось средствами LLD.
12. Теперь, когда мы настроили сбор данных для наших элементов, остается создать триггер, который будет информировать о проблемах с любым из наших операторов. Для этого идем в Configuration > Hosts > щелкаем созданный нами Host > Discovery rules > щелкаем созданный LLD > Trigger prototypes > Create trigger prototype
Задаем критичность своего триггера с помощью Severity. Затем в разделе Expression нажимаем Add>. В открывшемся окне справа от поля Item нажимаем Select prototype и выбираем наш прототип элемента. В Function оставляем last (), а Result задаем как «< 1».
Если помните для статуса метрик 1 – это OK, 0 – это не_OK.
Щелкаем Insert, затем Add.
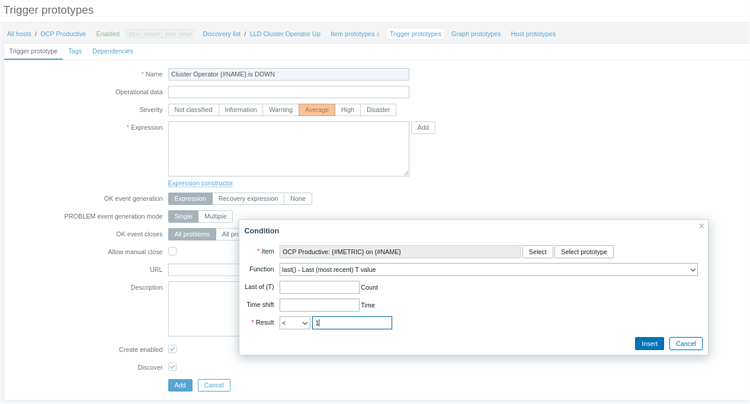
Теперь триггер создан.
13. Чтобы просмотреть наши оповещения, идем в Monitoring > Dashboard и видим здесь наши триггеры, если таковые имеются.
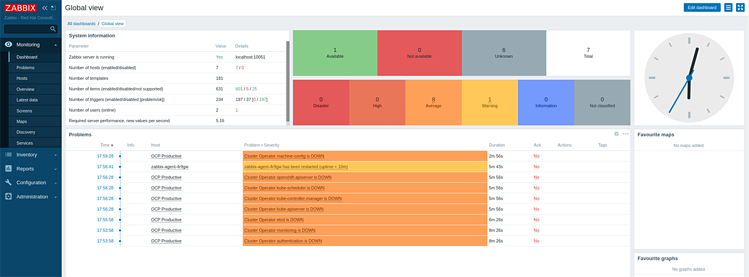
Чтобы проверить, всё ли верно, открываем адрес наша_конечная_точка/metrics и смотрим, какие метрики мы добавили в наш LLD:

14. Теперь посмотрим, что будет, когда конечная точка, с который собираются метрики, требует аутентификации, например, kube-apiserver (мониторинг данных API):

Обращаемся к ней через браузер или через Curl, чтобы проверить, возникает ли ошибка аутентификации:
$ curl -k https://10.36.250.77:6443/metrics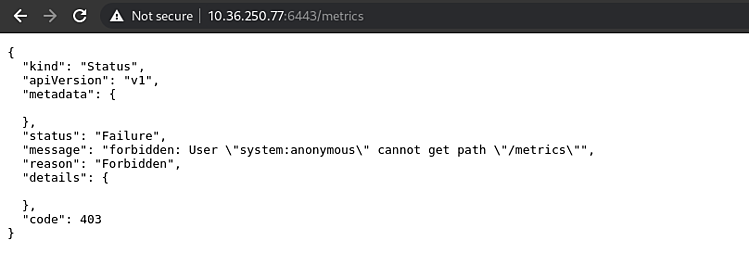
15. Теперь в openshift выведем список наших serviceaccounts в проекте zabbix:
$ oc project zabbix
$ oc get saПредоставим привилегии cluster-reader нашему serviceaccount-у zabbix-agent для аутентификации на этой конечной точке:
$ oc adm policy add-cluster-role-to-user cluster-reader -z zabbix-agentПроверим, что наш сервис теперь может проходить аутентификацию. Для будем использовать Curl и передадим токен через Bearer-авторизацию:
$ TOKEN=`oc sa get-token zabbix-agent`
$ curl -Ik -H "Authorization: Bearer $TOKEN" https://10.36.250.77:6443/metrics
HTTP/2 200
audit-id: 6d3ff3b6-b687-494c-ae04-ec46e813aea1
cache-control: no-cache, private
content-type: text/plain; version=0.0.4; charset=utf-8
x-kubernetes-pf-flowschema-uid: 3a22c354-288e-4c16-ac53-f828d6e66303
x-kubernetes-pf-prioritylevel-uid: a4bc8a8e-784c-45ab-b68b-1620bfb48ef5
date: Sun, 25 Apr 2021 21:25:34 GMT16. Теперь в Zabbix зарегистрируем наш элемент коллекции метрик. Для этого идем в Configuration > Hosts > созданный нами хост > Items > Create item
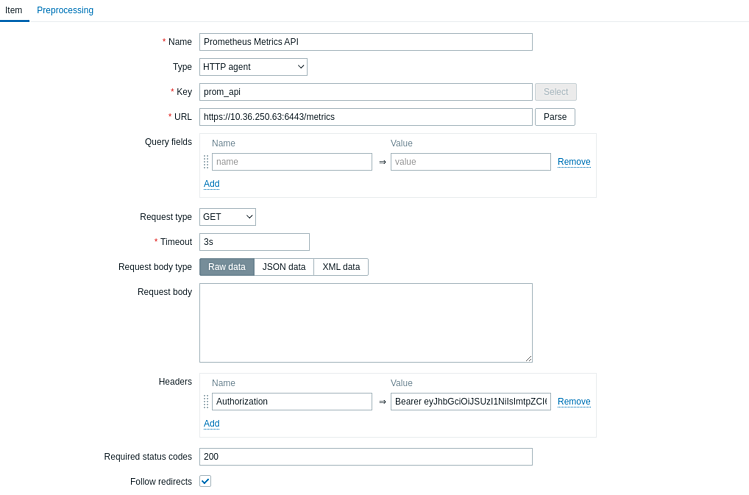
Для аутентификации путем передачи bearer-токена через заголовок, добавим наш токен в раздел Headers. Для этого в поле Name напишем Authorization, а поле Value напишем «Bearer» и сам токен, как показано ниже:
Authorization | Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
Теперь повторим шаги 6-12 для всех конечных точек и метрик, которые нужны для мониторинга нашей среды, чтобы внести их в Zabbix.
LLD для операторов со статусом degraded и LLD Objects Etcd:

Etcd-элементы, созданные из LLD и со статусом, отражающим самое последнее значение:
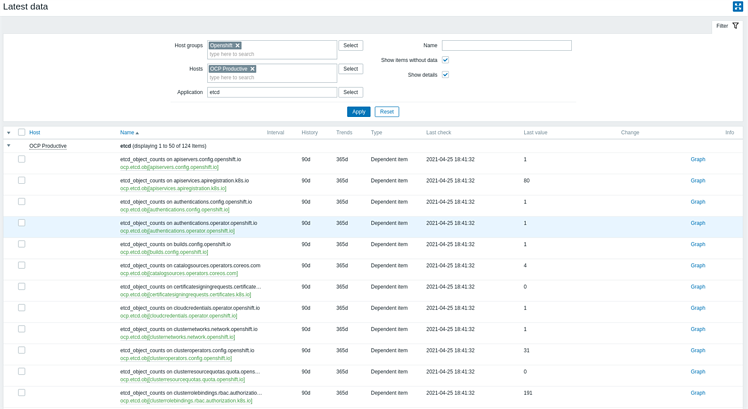
После создания всех необходимых коллекций и триггеров создадим графы для некоторых индикаторов состояния нашей среды:
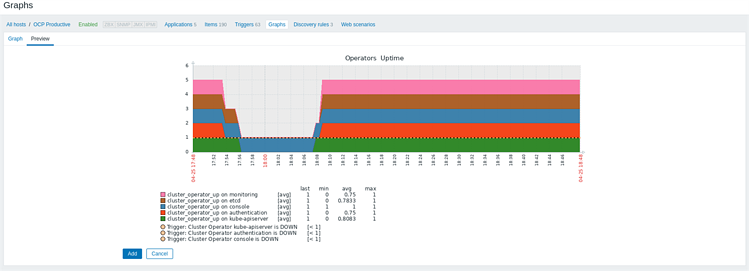
Итак, мы показали, как использовать Zabbix для сбора Prometheus-метрик в рамках проекта мониторинга OpenShift, и создали графики для централизованного мониторинга.
Сегодня мы покажем, как настроить мониторинг кластера OpenShift с помощью внешней системы на примере Zabbix. А также, как использовать при этом Prometheus, иначе говоря, собирать Prometheus-метрики по кластеру OpenShift, затем регистрировать их в Zabbix в качестве коллекций и создавать там триггеры, своевременно информирующие о проблемах.
osipov_dv
sed -i 's/^SELINUX=.*/SELINUX=permissive/g' /etc/selinux/configСерьезно, и это в блоге RedHat?
in_heb
недавно пытался воткнуть заббикс с selinux, того что поставляется самим zabbix-ом недостаточно, находил какие-то профили в разных репозиториях, кто ставит zabbix через ansible, но опять же, насколько они минимальные и там не выключено лишнего - непонятно, это надо исследовать
на самом деле ваш вопрос отражает всю суть selinux, в 99% манах про то как установить что-то на rhel первым шагом отключается selinux, потому что авторы ПО, выпускающие rpm-пакеты самостоятельно (как это делает Zabbix LLL), тупо забивают на попытки рабоать с невыключенным selinux
osipov_dv
все прекрасно работает с включенным selinux. надо сделать буквально 2-3 настройки (в основном booleans). Никакие политики для selinux не поставляются с zabbix, все уже идет вместе с системой.
https://www.zabbix.com/documentation/current/ru/manual/installation/install_from_packages/rhel_centos
Настройка SELinux
При включенном статусе SELinux в принудительном режиме, выполните следующие команды, чтобы предоставить веб-интерфейсу Zabbix разрешение на соединение с сервером:
RHEL 7 и новее:
Если база данных доступна по сети (включая 'localhost' в случае PostgreSQL), нужно также предоставить веб-интерфейсу Zabbix разрешение на соединение с базой данных:
RHEL до версии 7:
После настройки веб-интерфейса и SELinux, перезапустите веб-сервер Apache:
PS: судя по тому что нет команд по настройке firewalld, его тоже отключили :)))