


В этой статье авторы из Google Research хотели исследовать вопрос, могут ли CNN-архитектуры конкурировать с трансформерами (Transformers) в задачах NLP. Оказывается, что предварительно обученные модели CNN (convolutional neural network — сверточная нейронная сеть) все-таки превосходят предварительно обученных трансформеров в некоторых задачах; они также обучаются быстрее и лучше масштабируются под длинные последовательности.
По словам авторов, ранее не публиковались серьезные работы с проведением научных экспериментов по предварительному обучению и настройке CNN для работы с текстами.
Возможные преимущества CNN:
из-за отсутствия self-attention требуется меньше памяти;
они работают локально и поэтому не нуждаются в positional embedding’ах.
С другой стороны, CNN не предполагают доступ к глобальной информации; например, они не способны на что-то вроде cross-attention между несколькими последовательностями.
Подход к моделированию
Используются depthwise separable convolutions;
Предварительное обучение Seq2Seq на основе диапазона (span-based): они маскируют диапазон длиной L, и модель пытается его предсказать;
Потеря кросс-энтропии и усиление учителем;
Архитектура
Авторы не раскрывают нам точные архитектуры, но вот общее представление о них:
Архитектура Seq2Seq, но вместо
multi-head attentionсверточные блоки;
Проекции закрытого линейного блока (gated linear unit) вместо
query-key-valueтрансформаций;
В различных экспериментах испытываются легкие, динамические и расширенные свертки;
Каждый подмодуль обернут остаточными связями (residual connections) и нормой слоя (layer norm);
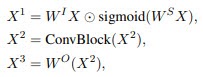

Вопросы
Авторы исследования задают пять вопросов, на которые они собираются ответить:
Вопрос 1: Польза сверток от предварительного обучения такая же, как и для трансформеров? [Да]
Вопрос 2: Могут ли сверточные модели, предварительно обученные или нет, конкурировать с трансформер-моделями? В каких случаях они хорошо себя показывают? [Да; превосходят в шести задачах]
Вопрос 3: Каковы преимущества (если таковые имеются) использования предварительно обученных моделей сверток по сравнению с предварительно обученными трансформерами? Являются ли свертки более быстрой альтернативой трансформерам с self-attention? [Да, они быстрее]
Вопрос 4: Каковы типы отказов, подводные камни и причины не использовать предварительно обученные свертки?
Вопрос 5: Какие варианты сверток лучше? [Расширенные и динамические лучше, чем легковесные]
Эксперименты
Авторы используют 8 наборов данных на различных задачах: двоичная и мультиклассовая классификация, генерация семантического представления.

Модели аналогичны базовому BERT: 12 слоев в кодировщике и декодере, размерность 3072 в слоях с прямой связью, размерность модели 768 и 12 голов. Они не настраивают параметры сверточных блоков; они используют размер окна 7 и 2 фильтра глубины. Для расширенных моделей размеры фильтров [4, 4, 7, 7, 15, 15, 15, 15, 31, 31, 31]. [Интересно, как они выбирали значения, если они не оптимизировали гиперпараметры]
Модель трансформера похожа на Т5.
Предварительное обучение
Авторы обучают как сверточные, так и модели-трансформеры за 524 тысячи шагов с размером батча 128. Цель предварительного обучения описана выше, размер диапазона (span size) - 3, уровень искажения - 15%. Они используют оптимизатор Adafactor [я никогда не слышал о нем раньше] с планировщиком скорости обучения с обратным квадратным корнем. Предварительное обучение проводилось на 16 TPU в течение 12 часов.
Результаты

В моделях CNN отсутствует cross-attention, и поэтому они хуже работают с задачами, которые подразумевают моделирование отношений между последовательностями. Эксперименты с SQuAD и MultiNLI показывают, что трансформеры намного лучше справляются с этими задачами. Но если мы добавим перекрестное внимание (cross-attention) к моделям CNN, они достигают почти той же производительности, что и модели-трансформеры.
Модели CNN имеют лучшую скорость обучения и лучше масштабируются для более длинных последовательностей.
Модели CNN более эффективны с точки зрения FLOP


Авторы дополнительно указывают на следующий вывод: в NLP предварительное обучение обычно выполнялось только для моделей-трансформеров, но оказывается, что предварительное обучение может приносить пользу и для других архитектур. Они надеются, что эта статья поможет открыть новые возможности для исследователей.
Материал подготовлен в рамках курса «Deep Learning. Basic».
На практике дата саентисты часто сталкиваются с недостатком данных для обучения. Классический выход из положения — провести transfer learning при помощи finetuning — обладает досадным свойством катастрофического забывания. На открытом уроке «Transfer learning при помощи перемежающейся тренировки» рассмотрим метод перемежающейся тренировки, позволяющий избежать переобучения на маленьком датасете.
→ РЕГИСТРАЦИЯ