
Привет, Хабр! Начинаю еще один цикл статей об устройстве PostgreSQL, на этот раз о том, как планируются и выполняются запросы.
Предыдущие циклы были посвящены индексам, изоляции и многоверсионности, журналированию и блокировкам.
В этом цикле я собираюсь рассмотреть:
этапы выполнения запросов (эта статья);
Материал перекликается с нашим учебным курсом QPT «Оптимизация запросов», но ограничивается только подробностями внутреннего устройства и не затрагивает оптимизацию как таковую. Кроме того, я ориентируюсь на еще не вышедшую версию PostgreSQL 14. А курс мы тоже скоро обновим (правда, на версию 13; приходится бежать со всех ног, чтобы только оставаться на месте).
Протокол простых запросов
Клиент-серверный протокол PostgreSQL позволяет в простом случае выполнять запросы SQL, отправляя их текст и получая в ответ сразу весь результат выполнения. Запрос, поступающий серверу на выполнение, проходит несколько этапов.
Разбор
Во-первых, текст запроса необходимо разобрать (parse), чтобы понять, что именно требуется выполнить.
Лексический и синтаксический разбор. Лексический анализатор разбирает текст запроса на лексемы (такие как ключевые слова, строковые и числовые литералы и т. п.), а синтаксический анализатор убеждается, что полученный набор лексем соответствует грамматике языка. PostgreSQL использует для разбора стандартные инструменты — утилиты Flex и Bison.
Разобранный запрос представляется в виде абстрактного синтаксического дерева.
Возьмем для примера следующий запрос:
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;Для него в памяти обслуживающего процесса будет построено дерево, показанное на рисунке в сильно упрощенном виде. Рядом с узлами дерева подписаны части запроса, которые им соответствуют:

RTE — неочевидное сокращение от Range Table Entry. Именем range table в исходном коде PostgreSQL называются таблицы, подзапросы, результаты соединений — иными словами, наборы строк, над которыми работают операторы SQL.
Семантический разбор. Задача семантического анализа — определить, есть ли в базе данных таблицы и другие объекты, на которые запрос ссылается по имени, и есть ли у пользователя право обращаться к этим объектам. Вся необходимая для семантического анализа информация хранится в системном каталоге.
Семантический анализатор получает от синтаксического анализатора дерево разбора и перестраивает его, дополняя ссылками на конкретные объекты базы данных, информацией о типах данных и т. п.
Полное дерево можно получить в журнале сообщений сервера, установив параметр debug_print_parse, хотя практического смысла в этом немного.
Трансформация
Далее запрос может трансформироваться (переписываться).
Трансформации используются ядром для нескольких целей. Одна из них — заменять в дереве разбора имя представления на поддерево, соответствующее запросу этого представления.
В примере выше pg_tables — представление, и после трансформации дерево разбора примет следующий вид:
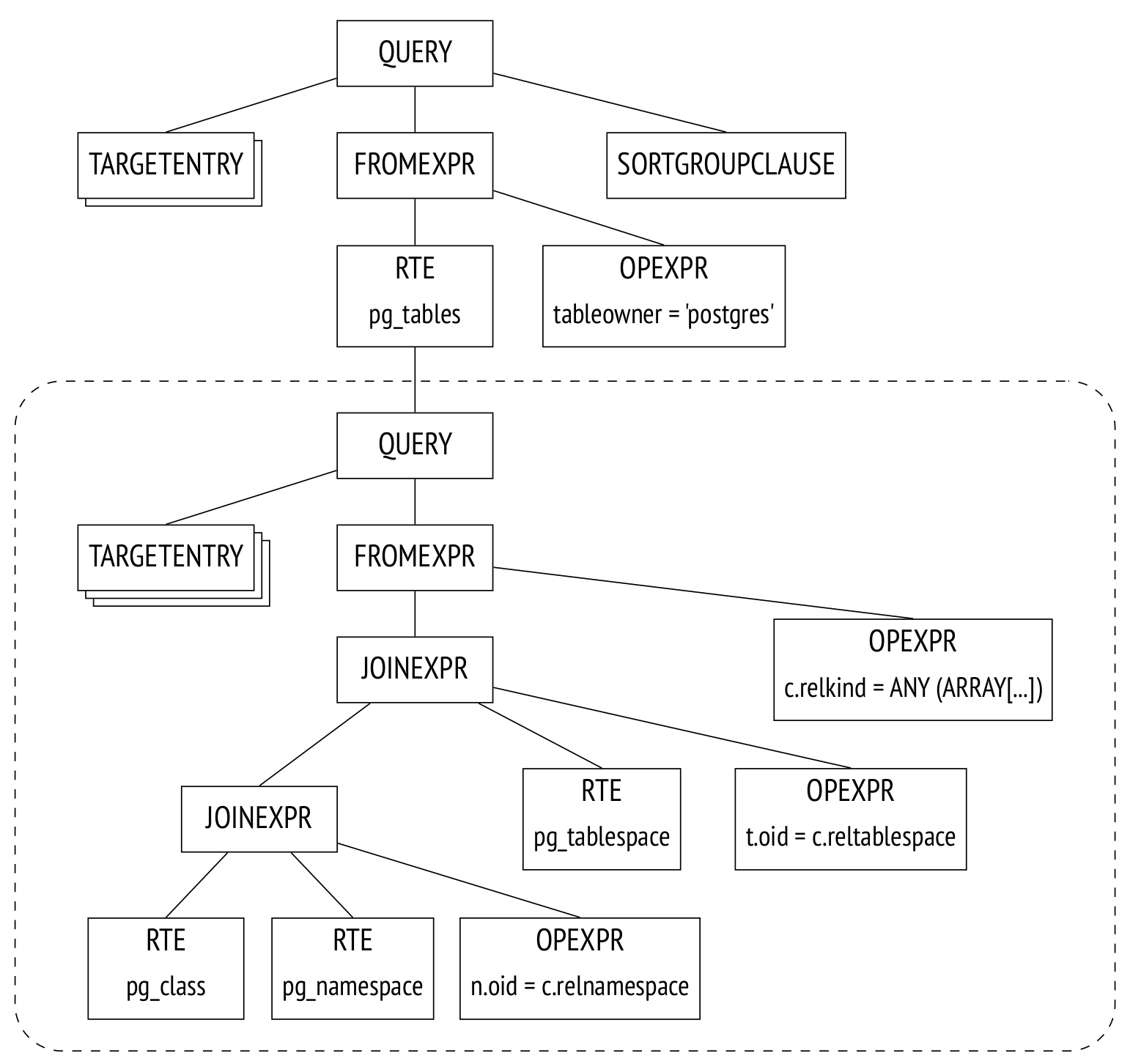
Это дерево разбора соответствует такому запросу (хотя все манипуляции производятся только над деревом, а не над текстом):
SELECT schemaname, tablename
FROM (
-- pg_tables
SELECT n.nspname AS schemaname,
c.relname AS tablename,
pg_get_userbyid(c.relowner) AS tableowner,
...
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT JOIN pg_tablespace t ON t.oid = c.reltablespace
WHERE c.relkind = ANY (ARRAY['r'::char, 'p'::char])
)
WHERE tableowner = 'postgres'
ORDER BY tablename;Дерево разбора отражает синтаксическую структуру запроса, но ничего не говорит о том, в каком порядке будут выполнены операции.
Разграничение доступа на уровне строк (row-level security) реализовано на этапе трансформации.
Еще один пример использования трансформаций ядром системы — реализация предложений SEARCH и CYCLE для рекурсивных запросов в версии 14.
PostgreSQL дает пользователю возможность написать свои собственные трансформации. Для этого используется система правил перезаписи (rules).
Поддержка правил была заявлена как одна из целей разработки Postgres, так что правила существовали изначально и неоднократно переосмысливались на начальном этапе университетского проекта. Это мощный, но сложный в отладке и понимании механизм. Поступало даже предложение убрать правила из PostgreSQL, но оно не нашло общей поддержки. В большинстве случаев вместо правил удобнее и безопаснее использовать триггеры.
Полное дерево разбора после трансформации можно получить в журнале сообщений сервера, установив параметр debug_print_rewritten.
Планирование
SQL — декларативный язык: запрос определяет, какие данные надо получить, но не говорит, как именно их получать.
Любой запрос можно выполнить разными способами. Для каждой операции, представленной в дереве разбора, могут существовать разные способы ее выполнения: например, данные из таблицы можно получить, прочитав всю таблицу (и отбросив ненужное), а можно найти подходящие строки с помощью индекса. Наборы данных всегда соединяются попарно, что приводит к огромному количеству вариантов, отличающихся порядком соединений. Кроме того, существуют разные способы выполнить соединение двух наборов строк: например, можно перебирать строки одного набора и находить для них соответствие во втором наборе, а можно предварительно отсортировать оба набора и затем слить их вместе. Разные способы показывают себя лучше в одних ситуациях и хуже — в других.
Разница во времени выполнения между неоптимальным и оптимальным планами может составлять многие и многие порядки, поэтому планировщик, выполняющий оптимизацию разобранного запроса, является одним из самых сложных компонентов системы.
Дерево плана. План выполнения также представляется в виде дерева, но его узлы содержат не логические, а физические операции над данными.
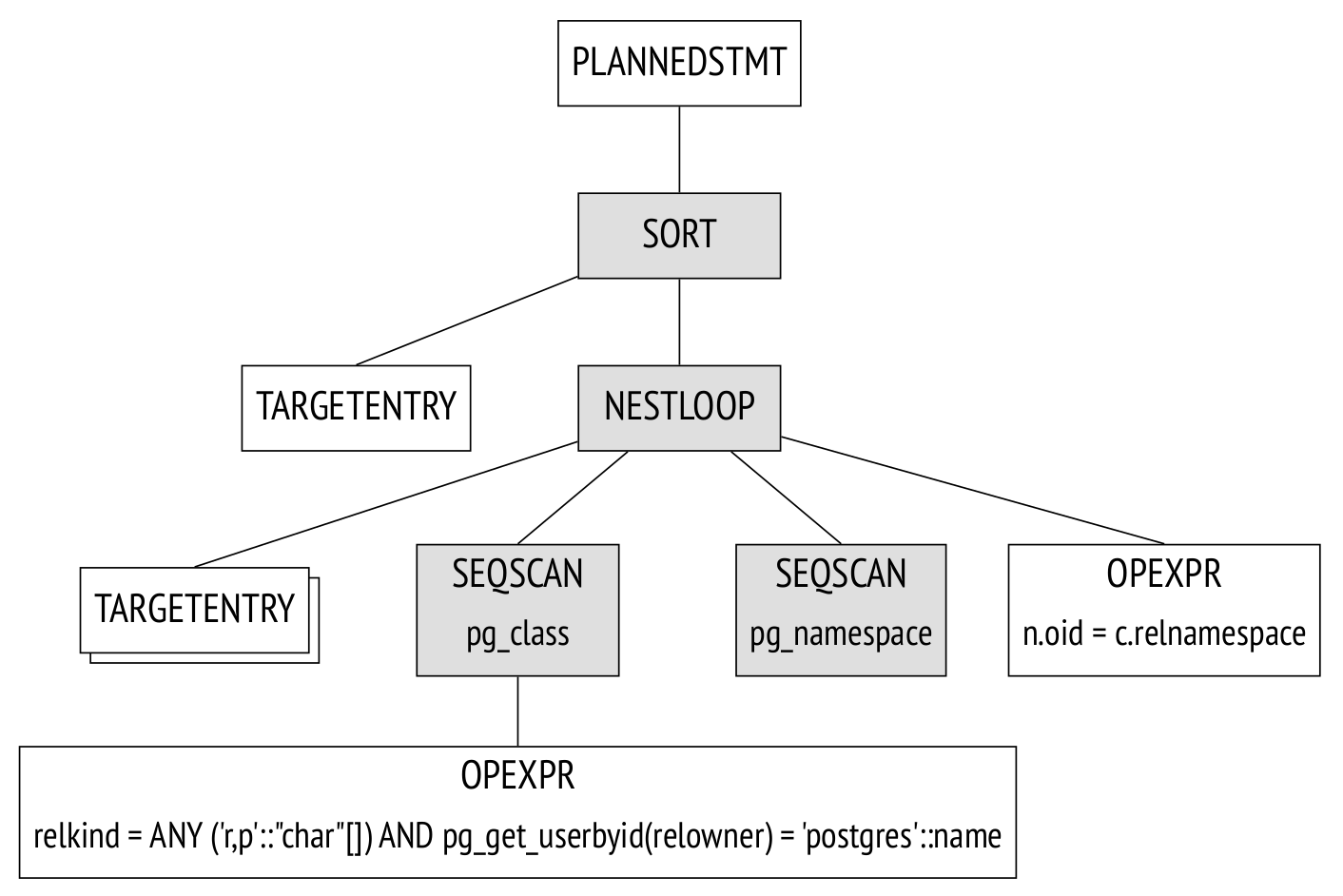
Для исследовательских целей полное дерево плана можно получить в журнале сообщений сервера, установив параметр debug_print_plan. А на практике текстовое представление плана выводит команда EXPLAIN:
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=21.03..21.04 rows=1 width=128)
Sort Key: c.relname
−> Nested Loop Left Join (cost=0.00..21.02 rows=1 width=128)
Join Filter: (n.oid = c.relnamespace)
−> Seq Scan on pg_class c (cost=0.00..19.93 rows=1 width=72)
Filter: ((relkind = ANY ('{r,p}'::"char"[])) AND (pg_g...
−> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 wid...
(7 rows)На рисунке выделены основные узлы дерева. В выводе команды EXPLAIN они отмечены стрелочками.
Узел Seq Scan в плане запроса соответствует чтению таблиц, а узел Nested Loop — соединению. Пока стоит обратить внимание на два момента:
из трех таблиц запроса в дереве осталось только две: планировщик понял, что одна из таблиц не нужна для получения результата и ее можно удалить из дерева плана;
каждый узел дерева снабжен информацией о предполагаемом числе обрабатываемых строк (rows) и о стоимости (cost).
Перебор планов. PostgreSQL использует стоимостной оптимизатор. Оптимизатор рассматривает всевозможные планы и оценивает предполагаемое количество ресурсов, необходимых для выполнения (таких как операции ввода-вывода и такты процессора). Такая оценка, приведенная к числовому виду, называется стоимостью плана. Из всех просмотренных планов выбирается план с наименьшей стоимостью.
Проблема в том, что количество возможных планов экспоненциально зависит от количества соединяемых таблиц, и просто перебрать один за другим все возможные варианты невозможно даже для относительно простых запросов. Для сокращения пространства перебора традиционно используется алгоритм динамического программирования в сочетании с некоторыми эвристиками. Это позволяет увеличить количество таблиц в запросе, для которых может быть найдено математически точное решение за приемлемое время.
Точное решение задачи оптимизации не гарантирует, что найденный план действительно будет лучшим, поскольку планировщик использует упрощенные математические модели и может действовать на основе не вполне точной входной информации.
Управление порядком соединений. Автор запроса может в известной степени сократить количество вариантов для перебора (взяв на себя ответственность за возможность упустить оптимальный план).
Общие табличные выражения обычно оптимизируются отдельно от основного запроса; в версии 12 такое поведение гарантирует предложение MATERIALIZE.
Запросы внутри функций, написанных на любом языке, кроме SQL, оптимизируются отдельно от основного запроса. (Тело функции на SQL в некоторых случаях может подставляться в запрос.)
Значение параметра join_collapse_limit в сочетании с явными предложениями JOIN, а также значение параметра from_collapse_limit в сочетании с подзапросами могут зафиксировать порядок некоторых соединений в соответствии с синтаксической структурой запроса.
Последний пункт нуждается в пояснении. Рассмотрим запрос, в котором таблицы перечислены через запятую в предложении FROM без явного указания JOIN:
SELECT ...
FROM a, b, c, d, e
WHERE ...Ему соответствует следующий (схематично показанный) фрагмент дерева разбора:
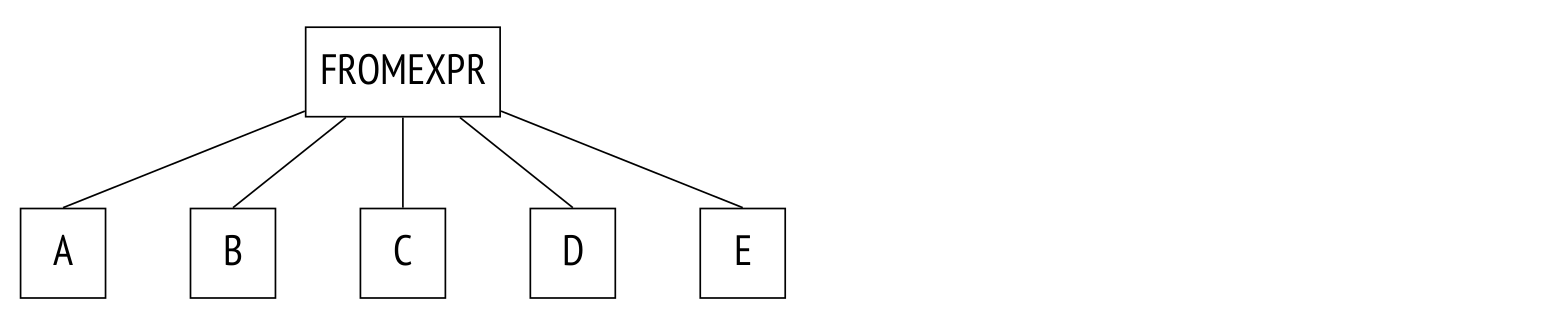
Для такого запроса планировщик будет рассматривать все возможные порядки соединения.
В другом примере соединения имеют определенную структуру, определяемую предложением JOIN:
SELECT ...
FROM a, b JOIN c ON ..., d, e
WHERE ...Дерево разбора отражает эту структуру:
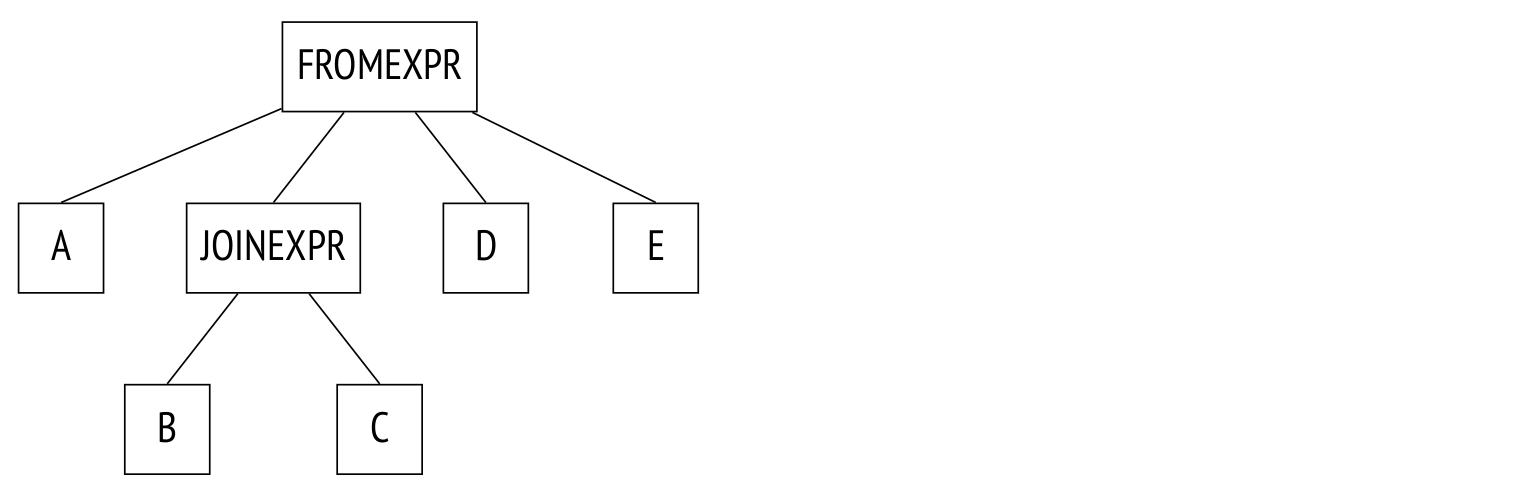
Обычно планировщик уплощает дерево соединений, преобразуя его к тому же виду, что в первом примере. Алгоритм рекурсивно обходит дерево, заменяя узлы JOINEXPR плоским списком низлежащих элементов.
Но уплощение выполняется только если оно не приведет к появлению в плоском списке более join_collapse_limit элементов (значение параметра по умолчанию — 8). В данном примере при любых значениях параметра, меньших 5, узел JOINEXPR не будет уплощен. Для планировщика это означает, что
таблица B должна быть соединена с таблицей C (или наоборот, C с B — ограничение не накладывается на порядок соединения в паре),
таблицы A, D, E и результат соединения B с C могут быть соединены в любом порядке.
При значении параметра join_collapse_limit, равном 1, порядок любых явных соединений JOIN будет сохранен.
Кроме того, операция FULL OUTER JOIN никогда не уплощается независимо от значения параметра join_collapse_limit.
Точно так же и параметр from_collapse_limit (с тем же значеним 8 по умолчанию) ограничивает уплощение подзапросов. Хотя внешне подзапросы не похожи на соединения JOIN, но на уровне дерева разбора аналогия становится очевидной.
Вот пример запроса:
SELECT ...
FROM a, (SELECT ... FROM b, c WHERE ...) bc, d, e
WHERE ...Ему соответствует дерево соединений:
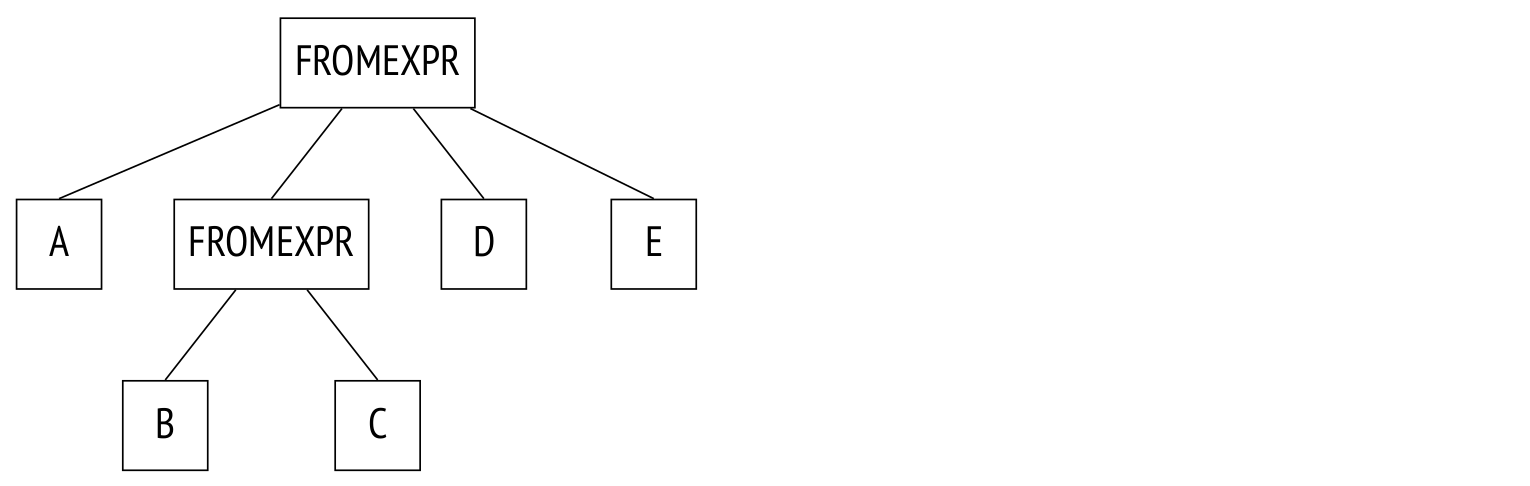
По сути, разница только в том, что вместо узла JOINEXPR стоит узел FROMEXPR (отсюда и не совсем очевидное название параметра).
Генетический алгоритм. Если в дереве соединений (после процедуры уплощения) на одном уровне оказывается слишком много элементов — таблиц или результатов соединений, которые оптимизируются отдельно, — планирование может занять слишком много времени. При включенном (по умолчанию) параметре geqo PostgreSQL переключается на использование генетического алоритма1 при числе элементов, большем или равном значению параметра geqo_threshold (значение по умолчанию — 12).
Генетический алгоритм работает существенно быстрее алгоритма динамического программирования, но не гарантирует нахождение оптимального плана. Алгоритм имеет ряд настроек, которые я не буду рассматривать.
Выбор лучшего плана. Для клиента оптимальность плана зависит от того, как предполагается использовать результат. Если результат нужен целиком (например, для построения отчета), то план должен оптимизировать получения всех строк выборки. Если же важно как можно быстрее получить первые строки (например, для вывода на экран), то оптимальный план может оказаться совсем другим.
PostgreSQL решает эту задачу, вычисляя две компоненты стоимости. В плане запроса два эти числа следуют за словом cost, как в этой строке:
Sort (cost=21.03..21.04 rows=1 width=128)Первая компонента (начальная стоимость, startup cost) представляет затраты, которые требуется понести для подготовки к началу выполнения узла, а вторая (полная стоимость, total cost) — полные затраты на выполнение узла.
Чтобы решить, каким планам отдавать предпочтение, планировщик смотрит, используется ли курсор (команда SQL DECLARE или явное объявление курсора в PL/pgSQL). Если нет, то предполагается немедленное получение всех результирующих строк клиентом, и из просмотренных планов оптимизатор выбирает план с наименьшей полной стоимостью.
Для запроса, который выполняется с помощью курсора, выбирается план, оптимизирующий получение не всех строк, а только доли, равной значению параметра cursor_tuple_fraction (значение по умолчанию — 0.1). Говоря точнее, выбирается план с наименьшим значением выражения
startup cost + cursor_tuple_fraction (total cost − startup cost).
Общая схема вычисления оценки. Чтобы получить общую оценку плана, необходимо оценить каждый из его узлов. Стоимость узла зависит от типа этого узла (очевидно, что стоимость чтения данных из таблицы и стоимость сортировки отличаются) и от объема обрабатываемых этим узлом данных (обычно чем меньше, тем дешевле). Тип узла известен, а для оценки объема данных необходимо оценить кардинальность (количество строк) входных наборов данных и селективность (долю строк, которая останется на выходе) данного узла. А для этого надо иметь статистическую информацию о данных: размер таблиц, распределение данных по столбцам.
Таким образом, оптимизация зависит от корректной статистики, собираемой и обновляемой процессом автоанализа.
Если в каждом узле плана кардинальность оценена правильно, то и стоимость обычно адекватно отражает реальные затраты. Основные ошибки планировщика связаны именно с неправильной оценкой кардинальностей и селективностей. Это может происходить из-за некорректной или устаревшей статистики, невозможности ее использования или — в меньшей степени — из-за несовершенства моделей, лежащих в основе планировщика.
Оценка кардинальности. Оценка кардинальности — рекурсивный процесс. Чтобы оценить кардинальность узла плана, надо:
оценить кардинальности дочерних узлов и получить количество строк, поступающих узлу на вход;
оценить селективность самого узла, то есть долю входящих строк, которая останется на выходе.
Произведение одного на другое и даст кардинальность узла.
Селективность представляется числом от 0 до 1. Селективность, близкая к нулю, называется высокой, а близкая к единице — низкой. Это может показаться нелогичным, но селективность здесь понимается как избирательность: условие, выбирающее малую долю строк, обладает высокой селективностью (избирательностью), а условие, оставляющее почти все строки — низкой.
Сначала рассчитываются кардинальности листовых узлов, в которых находятся методы доступа к данным. Для этого используется статистика, в частности, общий размер таблицы.
Селективность условий, наложенных на таблицу, зависит от вида этих условий. В простейшем случае можно принять за селективность какую-то константу, хотя, конечно, планировщик старается использовать всю доступную информацию для уточнения оценки. Достаточно уметь оценивать селективность только простых условий, а селективность условий, составленных с помощью логических операций, рассчитывается по простым формулам:
selx and y= selx sely
selx or y= 1−(1−selx)(1−sely) = selx + sely − selx sely.
К сожалению, эти формулы предполагают независимость предикатов x и y. В случае коррелированных предикатов такая оценка будет неточной.
Для оценки кардинальности соединений вычисляется кардинальность декартова произведения (равная произведению кардинальностей двух наборов данных) и оценивается селективность условий соединения, которая опять же зависит от типа условий.
Аналогично оценивается кардинальность и других узлов, таких как сортировка или агрегация.
Важно отметить, что ошибка расчета кардинальности, возникшая в нижних узлах плана, распространяется выше, приводя в итоге к неверной оценке и выбору неудачного плана. Этот неприятный эффект усугубляется тем, что планировщик располагает статистической информацией только о таблицах, но не о результатах соединений.
Оценка стоимости. Процесс оценки стоимости также рекурсивен. Чтобы рассчитать стоимость поддерева плана, надо рассчитать стоимости дочерних узлов, сложить их, и добавить стоимость самого узла.
Стоимость работы узла рассчитывается на основе математической модели операции, которую выполняет данный узел. Входными данными для оценки служит кардинальность, которая уже рассчитана. Отдельно оцениваются начальная и полная стоимость.
Некоторые операции не требуют никакой подготовки и начинают выполняться немедленно; у таких узлов начальная стоимость будет равна нулю.
Некоторые операции, наоборот, требуют выполнения предварительных действий. Например, узел сортировки обычно должен получить от дочернего узла все данные, чтобы начать работу. У таких узлов начальная стоимость будет отлична от нуля — эту цену придется заплатить, даже если вышестоящему узлу (или клиенту) потребуется только одна строка из всей результирующей выборки.
Стоимость отражает оценку планировщика и, если планировщик ошибается, может не коррелировать с реальным временем выполнения. Стоимость нужна лишь для того, чтобы планировщик мог сравнивать разные планы одного и того же запроса в одних и тех же условиях. В остальных случаях сравнивать запросы (тем более разные) по стоимости — неправильно и бессмысленно. Например, стоимость могла быть недооценена из-за неправильной статистики; после актуализации статистики стоимость может вырасти, но стать более адекватной, и план на самом деле улучшится.
Выполнение
Оптимизированный запрос выполняется в соответствии с планом.
В памяти обслуживающего процесса создается портал — объект, хранящий состояние выполняющегося запроса. Состояние представляется в виде дерева, повторяющего структуру дерева плана.
Фактически узлы дерева работают как конвейер, запрашивая и передавая друг другу строки.

Выполнение начинается с корня. Корневой узел (в примере это операция сортировки SORT) обращается за данными к дочернему узлу. Получив все строки, узел выполняет сортировку и отдает данные выше, то есть клиенту.
Некоторые узлы (как NESTLOOP на рисунке) соединяют данные, полученные из разных источников. Такой узел обращается за данными к двум дочерним узлам. Получив две строки, удовлетворяющие условию соединения, узел сразу же передает результирующую строку наверх (в отличие от сортировки, которая сначала вынуждена получить все строки). На этом выполнение узла прерывается до тех пор, пока вышестоящий узел не затребует следующую строку. Таким образом, если нужен только частичный результат (например, из-за ограничения LIMIT), то операция не будет выполняться полностью.
Два листовых узла дерева SEQSCAN представляют обращение к таблицам. Когда вышестоящий узел обращается за данными, листовой узел читает очередную строку из соответствующей таблицы и возвращает ее.
Таким образом, часть узлов не хранит строки, а немедленно передает их выше и тут же забывает, но некоторым узлам (например, сортировке) требуется сохранять потенциально большой объем данных. Для этого в памяти обслуживающего процесса выделяется фрагмент размером work_mem (значение по умолчанию очень консервативно — 4MB); если этой памяти не хватает, данные сбрасываются на диск во временный файл.
В одном плане может быть несколько узлов, которым необходимо хранилище данных, поэтому для запроса может быть выделено несколько фрагментов памяти, каждый размером work_mem. Общий объем оперативной памяти, который может задействовать запрос, никак не ограничен.
Протокол расширенных запросов
При использовании протокола простых запросов каждая команда, даже если она повторяется из раза в раз, проходит все перечисленные выше этапы:
разбор;
трансформацию;
планирование;
выполнение.
Но нет никакого смысла разбирать один и тот же запрос заново. Нет смысла разбирать и запросы, отличающиеся только константами: структура дерева разбора не изменится.
Еще одно неудобство простого способа выполнения запросов состоит в том, что клиент получает всю выборку сразу, сколько бы строк она не содержала.
В принципе, оба ограничения можно преодолеть, используя команды SQL: первое — подготавливая запрос командой PREPARE и выполняя с помощью EXECUTE, второе – создавая курсор командой DECLARE с последующей выборкой с помощью FETCH. Но для клиента это означает заботу об именовании создаваемых объектов, а для сервера — лишнюю работу по разбору дополнительных команд.
Поэтому расширенный клиент-серверный протокол позволяет детально управлять отдельными этапами выполнения операторов на уровне команд самого протокола.
Подготовка
На этапе подготовки запрос разбирается и трансформируется обычным образом, но полученное дерево разбора сохраняется в памяти обслуживающего процесса.
В PostgreSQL отсутствует глобальный кеш разобранных запросов. Поэтому даже если запрос уже был разобран одним обслуживающим процессом, другой будет вынужден разобрать его заново. Но у такого решения есть и плюсы. Под нагрузкой кеш в общей памяти легко становится узким местом из-за необходимости блокировок, и один клиент, выполняющий множество мелких команд, может повлиять на производительность всего экземпляра. В PostgreSQL разбор запросов обходится дешево и не влияет на другие процессы.
При подготовке запроса его можно параметризовать. Вот простой пример на уровне SQL-команд (повторюсь, что это не совсем то же самое, что подготовка на уровне команд протокола, но в конечном счете эффект тот же):
PREPARE plane(text) AS
SELECT * FROM aircrafts WHERE aircraft_code = $1;Почти все примеры в этой серии статей используют демобазу «Авиаперевозки».
Посмотреть именованные подготовленные операторы можно в представлении:
SELECT name, statement, parameter_types
FROM pg_prepared_statements \gx−[ RECORD 1 ]−−−+−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
name | plane
statement | PREPARE plane(text) AS +
| SELECT * FROM aircrafts WHERE aircraft_code = $1;
parameter_types | {text}Увидеть таким образом безымянные операторы (которые использует расширенный протокол или PL/pgSQL) не получится. И, конечно, сеанс может увидеть только собственные подготовленные операторы; заглянуть в память другого сеанса невозможно.
Привязка параметров
Перед выполнением подготовленного запроса выполняется привязка фактических значений параметров.
EXECUTE plane('733'); aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
733 | Боинг 737−300 | 4200
(1 row)Преимущество параметров подготовленных операторов перед конкатенацией литералов со строкой запроса — принципиальная невозможность внедрения SQL-кода, поскольку любое значение параметра не сможет изменить уже построенное дерево разбора. Чтобы достичь того же уровня безопасности без подготовленных операторов, требуется аккуратно экранировать каждое значение, полученное из ненадежного источника.
Планирование и выполнение
Когда дело доходит до выполнения подготовленного оператора, происходит планирование с учетом значений фактических параметров, после чего план передается на выполнение.
Учитывать значения параметров важно, поскольку оптимальные планы для разных значений могут не совпадать. Например, поиск очень дорогих бронирований использует индекс (о чем говорят слова Index Scan), поскольку планировщик предполагает, что подходящих строк не очень много (rows):
CREATE INDEX ON bookings(total_amount);
EXPLAIN SELECT * FROM bookings WHERE total_amount > 1000000; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Bitmap Heap Scan on bookings (cost=86.38..9227.74 rows=4380 wid...
Recheck Cond: (total_amount > '1000000'::numeric)
−> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00....
Index Cond: (total_amount > '1000000'::numeric)
(4 rows)Однако под следующее условие попадают вообще все бронирования, поэтому индекс бесполезен и таблица просматривается целиком (Seq Scan):
EXPLAIN SELECT * FROM bookings WHERE total_amount > 100; QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on bookings (cost=0.00..39835.88 rows=2111110 width=21)
Filter: (total_amount > '100'::numeric)
(2 rows)В некоторых случаях планировщик запоминает не только дерево разбора, но и план запроса, чтобы не выполнять планирование повторно. Такой план, построенный без учета значения параметров, называется общим планом (в отличие от частного плана, учитывающего фактические значения). Очевидный случай, когда можно перейти на общий план без ущерба для эффективности —запрос без параметров.
Подготовленные операторы с параметрами первые 4 раза всегда оптимизируются с учетом фактических значений; при этом вычисляется средняя стоимость получающихся планов. Начиная с пятого раза, если общий план оказывается в среднем дешевле, чем частные (с учетом того, что частные планы необходимо каждый раз строить заново), планировщик запоминает общий план и дальше использует его, уже не повторяя оптимизацию.
Подготовленный оператор plane уже был один раз выполнен. После еще двух выполнений по-прежнему используются частные планы, что видно по значению параметра в плане запроса:
EXECUTE plane('763');
EXECUTE plane('773');
EXPLAIN EXECUTE plane('319'); QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '319'::text)
(2 rows)После еще одного, четвертого, выполнения планировщик переключится на использование общего плана — он совпадает с частными планами, имеет ту же стоимость, и поэтому предпочтителен. Команда EXPLAIN показывает теперь не значение параметра, а его номер:
EXECUTE plane('320');
EXPLAIN EXECUTE plane('321'); QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '$1'::text)
(2 rows)Несложно представить ситуацию, в которой по неудачному стечению обстоятельств первые несколько частных планов будут более дорогими, чем общий план, а последующие оказались бы эффективнее общего — но планировщик уже не будет их рассматривать. Кроме того, планировщик сравнивает оценки стоимостей, а не фактические ресурсы, и это также может служить источником ошибок.
Поэтому (начиная с версии 12) при неправильном автоматическом решении можно принудиительно выбрать общий либо частный план, установив значение параметра plan_cache_mode:
SET plan_cache_mode = 'force_custom_plan';
EXPLAIN EXECUTE plane('CN1'); QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = 'CN1'::text)
(2 rows)Начиная с версии 14 представление pg_prepared_statements показывает в том числе и статистику выборов планов:
SELECT name, generic_plans, custom_plans
FROM pg_prepared_statements; name | generic_plans | custom_plans
−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−
plane | 1 | 6
(1 row)Получение результатов
Протокол расширенных запросов позволяет клиенту получать не все результирующие строки сразу, а выбирать данные по несколько строк за раз. Почти тот же эффект дает использование SQL-курсоров (за исключением лишней работы для сервера и того факта, что планировщик оптимизирует получение не всей выборки, а первых cursor_tuple_fraction строк):
BEGIN;
DECLARE cur CURSOR FOR
SELECT * FROM aircrafts ORDER BY aircraft_code;
FETCH 3 FROM cur; aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−−−−+−−−−−−−
319 | Аэробус A319−100 | 6700
320 | Аэробус A320−200 | 5700
321 | Аэробус A321−200 | 5600
(3 rows)FETCH 2 FROM cur; aircraft_code | model | range
−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−
733 | Боинг 737−300 | 4200
763 | Боинг 767−300 | 7900
(2 rows)COMMIT;Если запрос возвращает много строк, и клиенту они нужны все, то огромное значение для скорости передачи данных играет размер выборки, получаемой за один раз. Чем больше выборка, тем меньше коммуникационных издержек на обращение к серверу и получение ответа. Но с ростом выборки эффект сокращения издержек уменьшается: разница между одной строкой и десятью может быть колоссальной, а между сотней и тысячей уже почти незаметной.
Комментарии (11)

PrinceKorwin
26.08.2021 12:07Спасибо огромное за ваши статьи! Они отличный источник вдохновения!
Вы не подскажете где можно подсмотреть на общую архитектуру PostgreSQL?
Что-то типо такого наверное:
[ connection management layer ]
[ session management layer ]
[ query parsing / processing layer ]
[ query cache ]
[ query execution layer ]
[ statistics mgmt] [ query analyzer ] [locking mgmt ]
[ persistence layer ]
[ data cache ] [ block cache ] [ locking mgmt]
[ WAL mgmt] [ .. ]
В академических целях люблю ковыряться в разных БД и делать свои велосипеды :)

erogov Автор
26.08.2021 14:17+1Рад, что вдохновляетесь!
Насчет архитектуры. В документации, к сожалению, нет внятного короткого описания. Мы пытались что-то изобразить в DBA1 в темах 4-10. Попробуйте еще посмотреть Вову Бородина (видео https://www.youtube.com/watch?v=ejLzS6rVpkk, слайды https://www.slideshare.net/yandex/postgre-sql-41754731).

lesovsky
28.08.2021 07:57Но уплощение выполняется только если оно не приведет к появлению в плоском списке более join_collapse_limit элементов (значение параметра по умолчанию — 8). В данном примере при любых значениях параметра, меньших 5, узел JOINEXPR не будет уплощен.
Несколько раз перечитал, мне кажется что первое предложение противоречит второму.
То есть первое предложение говорит "уплощать пока итоговое значение в списке меньше 8".
Второе говорит наоборот "НЕ уплощать пока итоговое значение меньше 5+3"
Все ли верно в цитате? или таки в первом предложении есть лишняя частица "не"?erogov Автор
28.08.2021 11:52Алексей, вроде все верно. Во втором предложении «меньше пяти» относится не длине списка, а к значению параметра. А длина там ровно 5, столько узлов в примере.
Но согласен, написал я не очень. Подумаю, как это переформулировать почетче.

bigtrot
05.10.2021 03:36Вы сказали, что
В PostgreSQL разбор запросов обходится дешево и не влияет на другие процессы.
Какова практическая ценность подготавливать запросы, кроме как защита от sql - инъекций?
erogov Автор
05.10.2021 19:32Сокращение времени выполнения запросов за счёт того, что часть действий происходит при подготовке. Чем чаще запрос повторяется в одном сеансе, и чем запрос короче, тем сильнее эффект.
BrennendeHerz
Новая версия курса также будет в открытом доступе? Когда примерно можно ожидать обновления курсов?
И еще интересна информация о сертификации. Сейчас она соответствует курсу по PostgreSQL 10, для подготовки также рекомендуется изучать документацию по этой версии. Ранее проскакивала информация что будет переход на версию 12. Планируется ли также ее обновление на версию 13 вместо 12?
erogov Автор
Новая версия будет в открытом доступе, как и все остальные курсы. Когда - надеемся, что в этом году, но без гарантий.
Сертификация будет по версии 13, чтобы соответствовать курсам. (Да, сначала мы думали про 12-ю, но поезд уже ушел.)