

Привет Хабр! Сегодня я хочу рассказать о платформе, где люди соревнуются в том, кто больше сможет сэкономить тактов CPU для решения задач. Её история началась весной 2021 года, после очередного HighLoad Cup'а от Mail.ru. Мне очень нравится этот конкурс, но, к сожалению, он проходит довольно редко (2017, 2018, 2021 года) и наблюдается тренд ухода от оптимизации на уровне операционной системы и железа к массовости, чтобы в лидерах были решения не только на C/C++, но и на более медленных языках программирования. В 2017 году нужно было сделать HTTP сервер, реализующий простую бизнес логику, лидеры писали свои решения с использованием низкоуровневых вызовов функций ядра и только вызов функции epoll_wait со временем ожидания -1, вместо 0, не позволило мне подняться в TOP-6 с 9 места. Если интересны технические детали, то можно почитать эту статью. В 2021 году нужно было обращаться к серверу, в котором были искусственные ограничения и нужно было разобраться в них, а не выжать из железа всё возможное. После конкурса был созвон, на котором участники давали обратную связь, по итогам которого стало понятно, что есть небольшое количество людей, которым интересна именно низкоуровневая оптимизация, а не только улучшение алгоритмов на уровне Big O. Так и родилась идея этой платформы. Под катом история и устройство платформы, а также набитые шишки.
Версия 1
На базе своих старых разработок (1, 2) и BootstrapVue за несколько вечеров был собран сайт и выложен в облако. Следующим шагом на Go был сделан простой сервис проверки решений - Сhecker. Предполагалось, что генератор тестовых данных и решение - это одно приложение, в котором за генератор отвечает автор задачи, а за класс, реализующий решение - участники. Также участники могли писать решения используя только C++. Сhecker получал реализацию класса, компилировал приложение и запускал его в песочнице, которая осталась от разработки облака для SOA приложений. Генератор сам измерял время, потраченное на решение и отдавал результат для сохранения в БД. Для работы Checker'а был куплен простой VDS, где он и был запущен.
В качестве первой задачи участникам было предложено оптимизировать парсинг чисел. Генератор выглядел примерно так:
#include <iostream>
#include <chrono>
#include <array>
#include <algorithm>
#include "solution.h"
#define N 501
#define TT 167
std::string genData(uint64_t &sum) {
std::stringstream buf;
unsigned int seed = time(nullptr);
for (int i = 0; i < 1000000; ++i) {
auto v = rand_r(&seed);
sum += v;
buf << v << std::endl;
}
buf.flush();
return buf.str();
}
int main() {
solution s;
uint64_t res = 0;
std::array<uint64_t, N> times{};
uint64_t sum = 0;
for (int i = 0; i < N; ++i) {
auto data = genData(sum);
auto start = std::chrono::high_resolution_clock::now();
res += s.solve(data);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::nanoseconds elapsed = end - start;
times[i] = elapsed.count() / 1000000;
}
if (res != sum) {
std::cerr << "Invalid result. Got " << res << ", expected " << sum << std::endl;
exit(1);
}
std::sort(times.begin(), times.end());
uint64_t timesSum = 0;
for (int i = 0; i < TT; ++i) {
timesSum += times[i];
}
std::cout << timesSum * (N / TT) << std::endl;
return 0;
}В качестве решения нужно было реализовать класс solution, например вот так:
class solution {
public:
uint64_t solve(std::string &data) {
std::stringstream in(data);
uint64_t sum = 0;
while (in.good()) {
uint64_t v = 0;
in >> v;
sum += v;
}
return sum;
}
}Только более эффективно. Участники справились с оптимизацией довольно быстро, но, к сожалению, не так как задумывалось, были скомпрометированы генератор псевдослучайных чисел и алгоритм повтора данных. На самом деле в таком подходе была ещё одна уязвимость, ответ на решение находился в том же адресном пространстве, что и код его считающий. Можно было просто найти адрес переменной и вывести результат не считая.
После запуска стало понятно, что интерес у сообщества есть, нужно улучшать и развивать проект. Очевидно, что в таком виде он был нежизнеспособен и появился запрос от участников на добавление других языков программирования. Некоторые участники утверждали, что Go или Rust могут обогнать C++, значит надо было дать им возможность это доказать (спойлер - пока этого не удалось). Таким образом спустя всего несколько дней пришлось задуматься над полной переделкой проекта.
Версия 2
Стало очевидно, что генератор и решение должны быть разными приложениями. Схему взаимодействия было решено сделать такой:

Checker создавал pipe и запускал оба приложения, соединяя STDOUT генератора и STDIN решения. Затем получал ответы, сравнивал их и в случае совпадения вынимал из статистики cgroup'ы информацию об использованных ресурсах и считал баллы.
Казалось, что теперь всё должно работать идеально. Часть участников начали использовать *_unlocked() версии STDIO функций (man), что позволило им вырваться вперёд. Всё было хорошо, но тут стали появляться жалобы, что запуск одного и того же решения выдавал разные значения по потреблённым ресурсам, причём расхождения были значительными. Чтобы усреднить значения было принято решение запускать параллельно 3 обсчёта брать медианный в качестве решения. Не могу сказать, что это сильно прибавило стабильности в цифрах, а потом, через несколько дней все запуски стали выдавать результаты хуже чем в первые дни.
Борьба за стабильность
Система проверки жила на VDS и другие проекты, запущенные на этом же железе могли влиять на обсчёт задач. Поэтому нужно было переезжать на настоящее железо. Недорогой сервер на базе Intel(R) Xeon(R) CPU E3-1271 v3 @ 3.60GHz за 40 евро в месяц был найден на популярном немецком хостинге. После наливки OS и запуска Checker'а ожидалось, что теперь всё будет ровно, но, как говорится, забыли про "овраги".
Результаты стали стабильнее, но всё равно оставались странными:
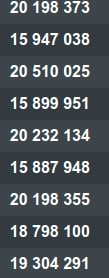
После десятков запусков и наблюдения этих цифр уже хотелось сдаться, но потом я заметил, что цифры зависят от номеров ядер CPU, на которых происходил обсчёт. Напомню, что для каждого решения делается 3 параллельных запуска. Ядра CPU, на которых будут произведены расчёты выбираются почти случайно. Причём, если ядра зафиксировать, то цифры были стабильны. И тут пришло озарение - во всём виноват HyperThreading. Если использовать ядра через 1, то результат был стабильным и с минимальным результатом:

Отсюда вывод - HyperThreading надо выключать на данном проекте и Turbo Boost заодно. Что было и сделано. Ещё я вывел ядра 1-3 из шедулера с помощью передачи параметра isolcpus=1,2,3 при загрузке ядра, таким образом другие процессы тоже не смогут влиять на производительность обсчёта. Приборы измерения настроены, выглядит всё хорошо, но ...
random - не random
Всё было хорошо, появлялись новые задачи, одна из которых была про форматирование чисел. Суть в том, что на вход подаётся 250 000 000 uint32 чисел, а на выходе нужно посчитать CRC от их строкового представления. Генератор выглядел так:
#define N 250000000
#define BUFSZ 10000
char *itoa(uint32_t value, char *result) {
...
}
int main() {
unsigned int seed = std::chrono::high_resolution_clock::now().time_since_epoch().count();
void *x = std::malloc(sizeof(int));
free(x);
seed ^= (intptr_t) x;
uint64_t res = 0;
char buffer[33] = {};
auto outBuf = new uint32_t[BUFSZ];
for (int k = 0; k < N / BUFSZ; ++k) {
for (int i = 0; i < BUFSZ; ++i) {
outBuf[i] = rand_r(&seed);
itoa(n, buffer);
for (int j = 0; buffer[j]; ++j) {
res += buffer[j] * j;
}
}
fwrite(outBuf, BUFSZ, sizeof(uint32_t), stdout);
}
fprintf(stderr, "%lu\n", res);
return 0;
}
Вычисление seed'а зависело не только времени, но и от адресного пространства. Функция rand, как я думал, гарантирует неповторяющуюся последовательность из в 2^31 чисел, а на практике оказалось, что через 128 Mb данные начали повторяться. Т.е. достаточно было просчитать только половину и будет известен ответ. Этот баг один из участников нашёл посчитав количество уникальных 4 Kb страниц и их оказалось в 2 раза меньше, чем должно было быть. С тех пор для генераторов используется только std::mt19937_64, например вот так:
int main() {
std::random_device r;
std::seed_seq seed{r(), r(), r(), r(), r(), r(), r(), r()};
std::mt19937_64 rng(seed);
std::uniform_int_distribution<uint32_t> dist(0, (1LL << 32) - 1);
uint64_t res = 0;
char buffer[33] = {};
auto outBuf = new uint32_t[BUFSZ];
for (int k = 0; k < N / BUFSZ; ++k) {
for (int i = 0; i < BUFSZ; ++i) {
uint32_t n = dist(rng);
outBuf[i] = n;
itoa(n, buffer);
for (int j = 0; buffer[j]; ++j) {
res += buffer[j] * j;
}
}
fwrite(outBuf, BUFSZ, sizeof(uint32_t), stdout);
}
fprintf(stderr, "%lu\n", res);
return 0;
}На самом деле разработка генераторов для задач оказалась непростым делом. Нужно сделать так, чтобы данные действительно были случайными, но и при этом время выполнения должно быть примерно одинаковым. Участники регулярно находят дыры в данных, например в задаче про поиск медианы пришлось миксовать несколько нормальных распределений, т.к. равномерное распределение давало примерно одинаковое значение медианы и некоторые участники этим пользовались.
Медленный транспорт и снова стабильность результатов
В какой-то момент пришло понимание, что бОльшую часть времени решение тратит на чтение данных из STDIN, что не есть хорошо. Поэтому вместо одновременного запуска генератора и решения была сделана следующая схема:

Отличие от предыдущей заключается в том, что между генератором и решением появился временный файл в tmpfs. Это позволило запускать их асинхронно и избавиться от тормозов при записи/чтении из STDIO. Чтобы не ломать обратную совместимость STDOUT генератора и STDIN решения были направлены в этот файл вместо pipe. Теперь решения могут использовать mmap, например вот так:
#include <unistd.h>
#include <sys/mman.h>
...
off_t fsize = lseek(0, 0, SEEK_END);
char* buffer = (char*)mmap(0, fsize, PROT_READ, MAP_PRIVATE | MAP_POPULATE, 0, 0); 0);Чтобы ещё ускорить доступ к данным файл для tmpfs были включены Huge pages, что дало небольшое ускорение. Но здесь нашлась ещё одна дыра, usleep помогал ускорить решение, как бы парадоксально это не звучало.
Так как обсчёт запускался параллельно, а данные лежали в памяти, то узким местом стал контроллер памяти. Учитывая что для подсчёта очков в большинстве задач используется время CPU, а не время выполнения (wall time), то если отправить решения в сон на разные интервалы времени, то контроллер памяти будет использоваться последовательно, что даёт хороший буст в очках. Чтобы это исправить, пришлось отказаться от параллельного запуска решений. Это увеличило время тестирования, но улучшило стабильность очков.
Текущая версия
Сейчас на платформе есть встроенный редактор, который позволяет работать с несколькими файлами. Так же есть возможность выбрать любую версию компилятора Go или Rust, для C++ пока выбор только из clang 10.0 и gcc 9.3. Ещё можно передавать любые флаги компиляции. А самое главное, можно создавать свои задачи, для этого есть специальная форма:
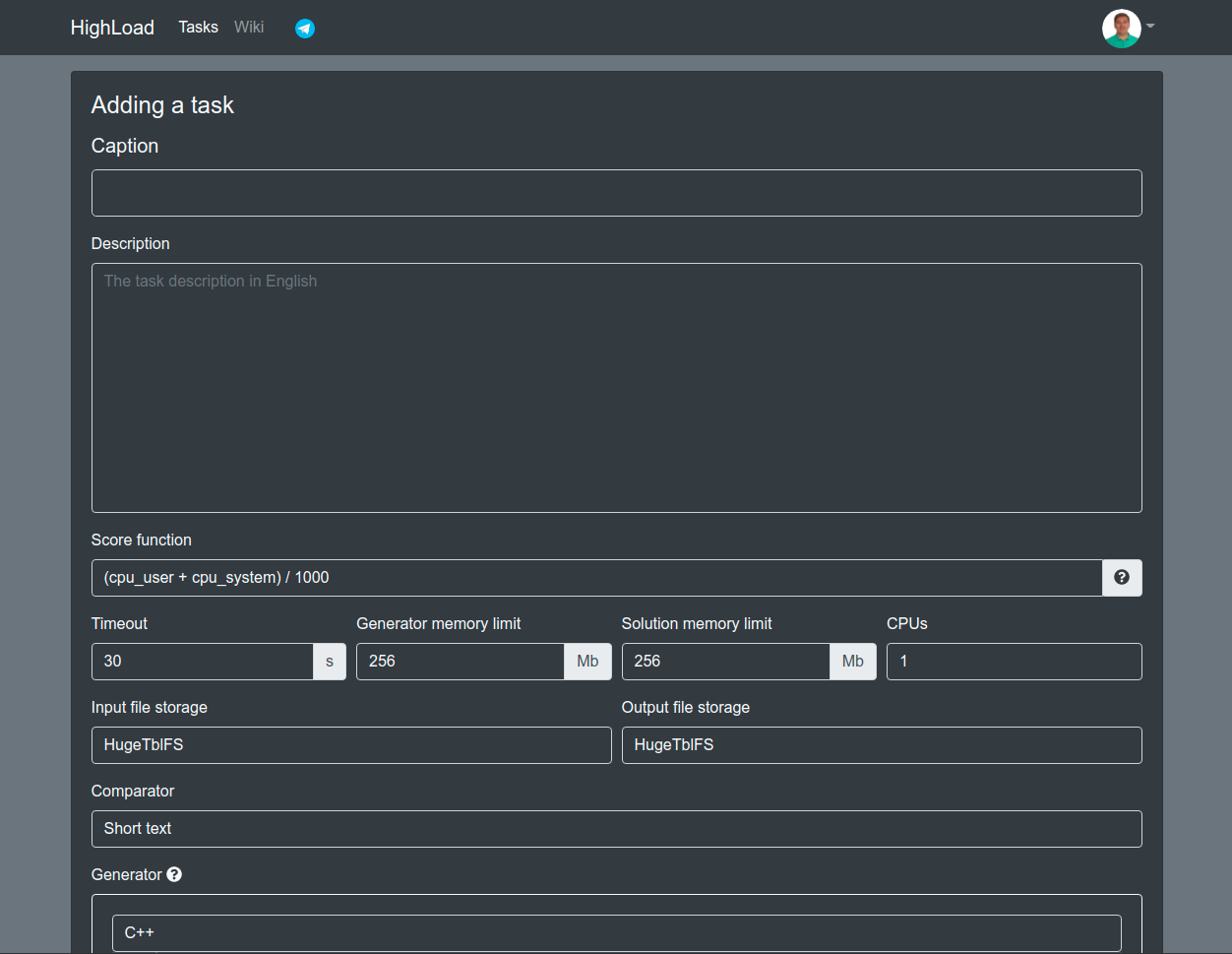
Для каждой задачи задаётся максимальное время на выполнение, ограничения по памяти, место расположения файлов с данными (работа с диском может быть частью задачи):
HDD
TmpFS
HugeTblFs
Компаратор сравнивает ожидаемый результат с полученным. В зависимости от данных можно выбрать любой из:
Short text - для маленьких данных, файлы сравниваются как 2 строки с игнорированием перевода строки.
Long text - данные сравниваются построчно.
JSON - данные сравниваются в виде JSON'ов, порядок полей не важен.
При желании можно сделать свой компаратор, для этого нужно прислать Pull Request в репозиторий.
Дальше нужно написать генератор и хотя бы 1 бойлерплейт на любом из доступных языков.
Если есть желание просто прийти и порешать одну из 12 существующих на текущий момент задач, добро пожаловать. Для пополнения знаний у нас есть Wiki с подборкой ссылок.
P.S. Победите уже кто-нибудь Yuriy Lyfenko
Комментарии (7)

aig
20.09.2021 22:21+2P.S. Победите уже кто-нибудь Yuriy Lyfenko
Мне наконец-то удалось победить его в задаче Arithmetic expressions :)

picul
21.09.2021 00:52Вау, вот это круто. Я как ни пытался, даже вплотную приблизиться удается не всегда :(
aig
21.09.2021 12:36off_t fsize = lseek(0, 0, SEEK_END); char* buffer = (char*)mmap(0, fsize, PROT_READ, MAP_PRIVATE | MAP_POPULATE, 0, 0); 0);
В статье есть подсказка, как "правильно" работать с stdin, мне это помогло улучшить результаты значительно.
aig
11.10.2021 08:41Мой рекорд продержался три недели. Всё-таки очень упорный парень, этот Yuriy Lyfenko :)
aig
15.10.2021 10:43Все-таки веселое соревнование, Yuriy Lyfenko вернул себе первое место в Arithmetic expressions, но я улучшил свой результат в Parse dateTime https://highload.fun/tasks/14/leaderboard :)
Когда-то давно мы с другом так же ускоряли и уменьшали код на Z80 ассемблере, однако, мы постоянно делились своими улучшениями и таким образом делали общее решение еще оптимальней. То что мы делились кодом совсем не влияло на соревновательный дух, так как каждый знал. кто конкретно улучшил вот эту часть кода. Все были довольны и развивали свои навыки.
technic93
Планируется ли делать доступными решения других участников?
svistunov Автор
Если придумаем как. Тут есть ряд проблем:
Если открыть решения, то остальные его будут просто отправлять лучшее под своим аккаунтом. Смысл leaderboard'а пропадёт.
Не все участники хотят раскрывать свои решения, по опросам где-то 50% участников.
Были мысли ограничить время на отправку решений, допустим 30 дней от первой попытки, а после этого срока показывать решения других участников, которые хотят поделиться своим кодом. Но тут появляется большая дыра, никто не мешает завести несколько аккаунтов.