
Всем привет.
Цель данной статьи и моей личной разработки - написать о том, как я придумал свой собственный и удобный формат json-журналирования специально для компании, в которой я работаю, но не нашел готовых решений для реализации, который позволит мне воплощать очень гибко и удобно некоторые вещи с единым наименованием полей, чтобы логгирование протекало быстро и асинхронно, а также: не заставляло бы меня писать много кода и обойтись одной-двумя библиотеками максимум.
Пошел искать решение в лоб: искал готовые решения в виде сторонних библиотек. Отыскал пару-тройку годных решений. Например библиотека json-logging. Всё хорошо: почитал, что делает и поставил не глядя. Данная библиотека имеет массу преимуществ:
может напрямую работать с FastAPI, Flask, Aiohttp, Sanic,
перехватывает uvicorn access log,
производит форматирование запроса в JSON формат.
Данная библиотека генерирует прекрасный лог сообщения с полями запроса, который поступил в сервис:
Код
{
"type": "request",
"written_at": "2017-12-23T16:55:37.280Z",
"written_ts": 1514048137280721000,
"component_id": "-",
"component_name": "-",
"component_instance_idx": 0,
"correlation_id": "1975a02e-e802-11e7-8971-28b2bd90b19a",
"remote_user": "user_a",
"request": "/index.html",
"referer": "-",
"x_forwarded_for": "-",
"protocol": "HTTP/1.1",
"method": "GET",
"remote_ip": "127.0.0.1",
"request_size_b": 1234,
"remote_host": "127.0.0.1",
"remote_port": 50160,
"request_received_at": "2017-12-23T16:55:37.280Z",
"response_time_ms": 0,
"response_status": 200,
"response_size_b": "122",
"response_content_type": "text/html; charset=utf-8",
"response_sent_at": "2017-12-23T16:55:37.280Z"
}Но у этой библиотеки обнаружились серьёзные недостатки:
Название полей в логе изменить нельзя без наследования Formatter и кастомизацию.
Нельзя никаким образом поставить в логирование тело ответа без написания собственного Middleware для FastAPI, который перехватит еще и тело ответа, что мы добавили в заголовки.
Логгирование перехватывало синхронный поток вывода логгера
uvicorn.access.
Я не буду писать, как я пытался закостылить исправить первые два минуса, пока не столкнулся с тем, что мне всё-таки нужен асинхронный логер. Я лучше Вам расскажу, как я решил сделать собственное решение.
Для начала я решил отказаться от этой библиотеки сразу:
pip uninstall json-loggingДалее я хотел обозначить структуру журнала. Мне очень помог Pydantic для элегантного описания данного вопроса:
from typing import Union
from pydantic import BaseModel, Field
class BaseJsonLogSchema(BaseModel):
"""
Схема основного тела лога в формате JSON
"""
thread: Union[int, str]
level: int
level_name: str
message: str
source: str
timestamp: str = Field(..., alias='@timestamp')
app_name: str
app_version: str
app_env: str
duration: int
exceptions: Union[list[str], str] = None
trace_id: str = None
span_id: str = None
parent_id: str = None
class Config:
allow_population_by_field_name = True
class RequestJsonLogSchema(BaseModel):
"""
Схема части запросов-ответов лога в формате JSON
"""
request_uri: str
request_referer: str
request_protocol: str
request_method: str
request_path: str
request_host: str
request_size: int
request_content_type: str
request_headers: str
request_body: str
request_direction: str
remote_ip: str
remote_port: str
response_status_code: int
response_size: int
response_headers: str
response_body: str
duration: intПосле того, как была сформирована структура тела запроса необходимо определить сам механизм форматирования. Формирование, что логично, производится с помощью создания класса JSONLogFormatter с наследованием от стандартного logging.Formatter.
Код test_project.utils.json_logger.py
import datetime
import json
import logging
import traceback
from test_project.main.settings import APP_NAME, \
APP_VERSION, ENVIRONMENT
from test_project.utils.utils_schemas import BaseJsonLogSchema
class JSONLogFormatter(logging.Formatter):
"""
Кастомизированный класс-форматер для логов в формате json
"""
def format(self, record: logging.LogRecord, *args, **kwargs) -> str:
"""
Преобразование объект журнала в json
:param record: объект журнала
:return: строка журнала в JSON формате
"""
log_object: dict = self._format_log_object(record)
return json.dumps(log_object, ensure_ascii=False)
@staticmethod
def _format_log_object(record: logging.LogRecord) -> dict:
"""
Перевод записи объекта журнала
в json формат с необходимым перечнем полей
:param record: объект журнала
:return: Словарь с объектами журнала
"""
now = datetime \
.datetime \
.fromtimestamp(record.created) \
.astimezone() \
.replace(microsecond=0) \
.isoformat()
message = record.getMessage()
duration = record.duration \
if hasattr(record, 'duration') \
else record.msecs
# Инициализация тела журнала
json_log_fields = BaseJsonLogSchema(
thread=record.process,
timestamp=now,
level=record.levelno,
level_name=LEVEL_TO_NAME[record.levelno],
message=message,
source=record.name,
duration=duration,
app_name=APP_NAME,
app_version=APP_VERSION,
app_env=ENVIRONMENT,
)
if hasattr(record, 'props'):
json_log_fields.props = record.props
if record.exc_info:
json_log_fields.exceptions = \
traceback.format_exception(*record.exc_info)
elif record.exc_text:
json_log_fields.exceptions = record.exc_text
# Преобразование Pydantic объекта в словарь
json_log_object = json_log_fields.dict(
exclude_unset=True,
by_alias=True,
)
# Соединение дополнительных полей логирования
if hasattr(record, 'request_json_fields'):
json_log_object.update(record.request_json_fields)
return json_log_objectНужно заставить FastApi ловить request и response, желательно с наличием body. Я сначала пытался обратиться к dependency подходу FastApi. Но понял, что не хочу описывать в каждом методе метод логирования. Естественно, к нам на помощь приходит Middleware.
Я написал класс, который позволяет внедрить в app-объект журналирование тела запроса и ответа, а также их полей: status code, headers, remote ip, protocol, etc. Класс я назвал LoggingMiddleware и все выполнение происходит методу async def __call__()
Код test_project.utils.middlewares.py
from test_project.main.settings import PORT
from test_project.utils.json_logger import EMPTY_VALUE
from test_project.utils.utils_schemas import RequestJsonLogSchema
class LoggingMiddleware:
"""
Middleware для обработки запросов и ответов с целью журналирования
"""
@staticmethod
async def get_protocol(request: Request) -> str:
protocol = str(request.scope.get('type', ''))
http_version = str(request.scope.get('http_version', ''))
if protocol.lower() == 'http' and http_version:
return f'{protocol.upper()}/{http_version}'
return EMPTY_VALUE
@staticmethod
async def set_body(request: Request, body: bytes) -> None:
async def receive() -> Message:
return {'type': 'http.request', 'body': body}
request._receive = receive
async def get_body(self, request: Request) -> bytes:
body = await request.body()
await self.set_body(request, body)
return body
async def __call__(
self, request: Request, call_next: RequestResponseEndpoint,
*args, **kwargs
):
start_time = time.time()
exception_object = None
# Request Side
try:
raw_request_body = await request.body()
# Последующие действия нужны,
# чтобы не перезатереть тело запроса
# и не уйти в зависание event-loop'a
# при последующем получении тела ответа
await self.set_body(request, raw_request_body)
raw_request_body = await self.get_body(request)
request_body = raw_request_body.decode()
except Exception:
request_body = EMPTY_VALUE
server: tuple = request.get('server', ('localhost', PORT))
request_headers: dict = dict(request.headers.items())
# Response Side
try:
response = await call_next(request)
except Exception as ex:
response_body = bytes(
http.HTTPStatus.INTERNAL_SERVER_ERROR.phrase.encode()
)
response = Response(
content=response_body,
status_code=http.HTTPStatus.INTERNAL_SERVER_ERROR.real,
)
exception_object = ex
response_headers = {}
else:
response_headers = dict(response.headers.items())
response_body = b''
async for chunk in response.body_iterator:
response_body += chunk
response = Response(
content=response_body,
status_code=response.status_code,
headers=dict(response.headers),
media_type=response.media_type
)
duration: int = math.ceil((time.time() - start_time) * 1000)
# Инициализация и формирования полей для запроса-ответа
request_json_fields = RequestJsonLogSchema(
request_uri=str(request.url),
request_referer=request_headers.get('referer', EMPTY_VALUE),
request_protocol=await self.get_protocol(request),
request_method=request.method,
request_path=request.url.path,
request_host=f'{server[0]}:{server[1]}',
request_size=int(request_headers.get('content-length', 0)),
request_content_type=request_headers.get(
'content-type', EMPTY_VALUE),
request_headers=json.dumps(request_headers),
request_body=request_body,
request_direction='in',
remote_ip=request.client[0],
remote_port=request.client[1],
response_status_code=response.status_code,
response_size=int(response_headers.get('content-length', 0)),
response_headers=json.dumps(response_headers),
response_body=response_body.decode(),
duration=duration
).dict()
# Хочется на каждый запрос читать
# и понимать в сообщении самое главное,
# поэтому message мы сразу делаем типовым
message = f'{"Ошибка" if exception_object else "Ответ"} ' \
f'с кодом {response.status_code} ' \
f'на запрос {request.method} \"{str(request.url)}\", ' \
f'за {duration} мс'
logger.info(
message,
extra={
'request_json_fields': request_json_fields,
'to_mask': True,
},
exc_info=exception_object,
)
return responseУ меня есть одержимость по поводу асинхронного логирования в FastApi. Методы вывода потока в консоль, запись в файл, logstash - это тот же I/O процесс, как и сгонять по сетке в БД или в другой сервис, согласны? А так как это I/O процесс, то в асинхронном FastApi очень важно не замедлять работу такой простой штукой как логирование. Я нашел очень хорошую библиотеку, которая за одну конфигурацию перестраивает вывод в консоль в асинхронный режим (также можно провернуть и с файлами и отправкой в logstash, и другие ресурсы). Данная библиотека называется: asynclog. Настройка и установка производится очень просто. Не нужно иметь никаких классов и переопределять handler-ы: Нужно просто настроить логирование через словарь в конфигурации проекта и задать handler.
Создаем конфигурацию логера и использовать его везде. Благо, в python есть для этого конфигурация, которую можно воплотить в настройках проекта.
LOG_CONFIG = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'json': {
'()': 'test_project.utils.json_logger.JSONLogFormatter',
},
},
'handlers': {
# Используем AsyncLogDispatcher для асинхронного вывода потока.
'json': {
'formatter': 'json',
'class': 'asynclog.AsyncLogDispatcher',
'func': 'test_project.utils.json_logger.write_log',
},
},
'loggers': {
'test_project': {
'handlers': ['json'],
'level': 'DEBUG' if DEBUG else 'INFO',
'propagate': False,
},
'uvicorn': {
'handlers': ['json'],
'level': 'INFO',
'propagate': False,
},
# Не даем стандартному логгеру fastapi работать по пустякам и замедлять работу сервиса
'uvicorn.access': {
'handlers': ['json'],
'level': 'ERROR',
'propagate': False,
},
},
}Здесь у handler есть особенность в поле func, тут должна быть указана функция вывода потока. Это может быть stdout, print, write file. Что угодно, вплоть до передачи файла по сети в logstash. В нашем случае я решил просто вывести в консоль простейшим способом для примера.
Код test_project.utils.json_logger.py:
def write_log(msg):
print(msg)Настраиваем приложение на работу с данным middleware, инициализируем logging и его конфигурацию. Далее производим написание обычного route с логгированием сообщения 'Test log'.
import logging
from logging.config import dictConfig
from fastapi import FastAPI
from test_project.utils.middlewares import LoggingMiddleware
dictConfig(LOG_CONFIG)
logger = logging.getLogger(name)
app = FastAPI()
app.middleware('http')(
LoggingMiddleware()
)
router = APIRouter(
tags=['root'],
responses={404: {'description': 'Not found'}},
)
@router.get('/')
async def root(request: Request):
logger.info('Test log')
return {'foo': 'bar'}
app.include_router(router)Получаем сразу два сообщения в консоли:
Первое: как раз таки тот вывод из Middleware, который гарантирует отображение полей запроса
{
"thread": 60535,
"level": 20,
"level_name": "Information",
"message": "Ответ с кодом 200 на запрос GET \"http://localhost:8080/\", за 4 мс",
"source": "test_project.utils.middlewares",
"@timestamp": "2021-08-28T01:49:23+03:00",
"app_name": "test_project",
"app_version": "1.0.0",
"app_env": "LOCAL",
"duration": 4,
"request_uri": "http://localhost:8080/",
"request_referer": "",
"request_protocol": "HTTP/1.1",
"request_method": "GET",
"request_path": "/",
"request_host": "127.0.0.1:8080",
"request_size": 0,
"request_content_type": "",
"request_headers": "{\"host\": \"localhost:8080\"}",
"request_body": "",
"request_direction": "in",
"remote_ip": "127.0.0.1",
"remote_port": "50259",
"response_status_code": 200,
"response_size": 13,
"response_headers": "{\"content-length\": \"13\", \"content-type\": \"application/json\"}",
"response_body": "{\"foo\":\"baz\"}"
}Второе: Наше сообщение 'Test Log' вне контекста HTTP запроса, а уже в контексте работы внутри route
{
"thread": 60535,
"level": 20,
"level_name": "Information",
"message": "Test log",
"source": "test_project.main.routes",
"@timestamp": "2021-08-28T01:49:23+03:00",
"app_name": "test_project",
"app_version": "1.0.0",
"app_env": "LOCAL",
"duration": 385,
"trace_id": "3bd6f269dbbbd275d46320c7e240bfe5",
"span_id": "2417303bd1af1ee6",
"parent_id": null
}Бонус. Демонстрация производительности асинхронного вывода.
Почему я так сильно хотел асинхронный вывод журнала? Сейчас будет представлено нагрузочное тестирование на обычном примере одного и того же запроса, с одними и теми же конфигурациями сервера.
Количество воркеров: 10
Количество одновременно-подключенных клиентов: 200
Таймаут: 15 секунд.
Время выполнения теста: 15 секунд (больше и не надо)
Логгирование одного и того же сообщения: test.
Formatter не менял свой код.
Команда запуска нагрузочного тестирования:
wrk -c200 -t1 -d15s http://localhost:8080/users/public/ --timeout 15Результат нагрузочного тестирования синхронного логгирования:

Результат нагрузочного тестирования асинхронного логгирования:
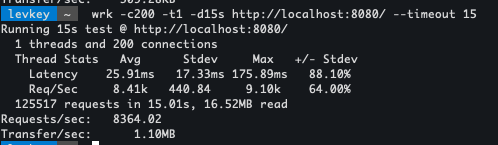
Как можно заметить, что синхронный вариант вывода дал 2294 rps, а асинхронный вариант вывода выдал целых 8364 rps. Получается, разница производительности целого сложного веб-сервиса увеличилась в 3.64 раза благодаря простому переходу и подходу к логгированию.
Вывод
Никогда не стоит соглашаться на сторонние библиотеки, если чувствуете, что они не могут удовлетворить ваших потребностей. Наследоваться от сторонних библиотек может обернуться плохой шуткой и лучше сразу не полениться и попробовать написать что-то своё. Да, это решение вряд-ли подойдет 99.99% пользователям, есть моменты, которые бы улучшил, оптимизировал и сделал бы более гибкими. Как раз про это я бы хотел почитать в комментариях, обсудить, как можно улучшить данный подход.
Пока что данная реализация находится в закрытой разработке одного из моих проектов, но я обещаю, что дополню эту статью ссылкой на гитхаб, либо подготовлю уже PyPi решение для вас, дорогие читатели данной статьи.
Telegram: @Lev_key
Комментарии (23)

vagon333
31.08.2021 06:37+1Больная тема. Спасибо что поделились.
Насколько сложно расширить вывод?
Например, критические ошибки мы сбрасываем в закрытый телеграм канал.
Если подключать ваш логгер, хорошо быть иметь возможность расширения вывода.
LEVLLN Автор
31.08.2021 08:49Я рад, что статья Вам помогла. Отвечу про расширение вывода. Расширение вывода делается очень просто, я описал это в месте, где конфигурирование handler, у которого есть поле func. Вот, эта функция как реализует вывод журнала в нужное место. На примере у меня указан обычный print, но в Вашем случае это может быть отправка в телеграм-канал.
Спасибо за Вашу обратную связь.

stepalxser
31.08.2021 12:29Функция ведь по идее должна быть асинхронной?
LEVLLN Автор
31.08.2021 12:33+1Таки нет, потому что стандартный logging в Python - синхронный. Асинхронность библиотеки достигается очередями через Queue, запуском в asyncio результата по очереди. То есть, если функцию логгирования сделать асинхронной - упадет ошибка о том, что мы вызываем асинхронное в синхронном коде логгера в очереди. Опять же: моя цель была не качать без всякой нужды асинхронные библиотеки, которые есть в pypi, ибо они все имеют свою экосистему и не используют стандартный logging, там запись определения бы была такая: logger = libname_logging(). А вызов через await logger.info(“message”). Не все функции в проекте могут быть асинхронными и это бы привело к неоднородности логеров в проекте. И второе: было бы несколько точек конфигурирования логеров, а мы этого делать не хотим, когда у питона из коробки свой собственный и даже лучший способ это сделать.


Cykooz
31.08.2021 11:26+2У вашего решения есть заметные недостатки:
Ваша миделвара полностью вычитывает тело запроса ещё до того как основной код примет решение о том нужно ли ему вообще это тело. Например приложение может вообще прервать обработку запроса (и не вычитывать его тело) из-за того, что он не прошёл проверку авторизации.
А если клиент отправил 100500 МБ данных в теле? У вас это всё загрузится в память и пользователь вашей библиотеки даже не может на это повлиять. Ну и кроме того это ломает обработку заголовка запроса Expect: 100-continueАналогичная проблема с телом ответа - вы без всяких проверок вычитываете его в память полностью. А там может быть очень много данных. Не просто так тело ответа реализовано как итератор - это позволяет реализовать возврат большого тела без необходимости его полной загрузки в память. Ваша миделвара ломает это стандартное поведение.
Когда я делал подобное логирование тела запроса и ответа, то я во первых проверял Content-Type, что бы он имел какое-то определённое значение. Например application/json, т.к. в контексте приложения нет смысла логировать что-то другое. И так же проверял Content-Length запроса и ответа, что бы он не превышал определённого лимита (а ещё его вообще может не быть, если тело передаётся чанками). Ну и тело запроса я достаю уже после того как запрос был обработан приложением.
LEVLLN Автор
31.08.2021 12:38Да, Вы верно подметили этот недочет. На самом деле, тут оставляется выбор за разработчиком уже достраивать новые ограничения на контент, на формат данных с помощью pydantic, на то, как будет мидлварь сплитить и декомпозировать отдельные части запроса и ответа. Совет с content-type - очень крутой, возьму на заметку. Спасибо за Ваш комментарий!

Scrloll
31.08.2021 12:34Было бы интересно посмотреть на результаты нагрузочного тестирования в сравнении с библиотекой loguru. Рассматривали ее как альтернативу?
LEVLLN Автор
31.08.2021 12:36Logguru отдал такой же результат, как и приведенный в примере синхронный вариант, не больше 3000 rps. Потому что механизм синхронный в logguru. Но logguru тоже хорошее и гибкое решение, но слишком громоздкое для нашей задачи.

AlexSpaizNet
31.08.2021 13:12Давно не писал на питоне, тем более с async/await поэтому возможно мой вопрос не в тему. Здесь имеется ввиду что асинхронный код не блокирует тред /процесс питона (GIL и все такое) или же логгер вообще будет сам по себе где то буферизировать логи и пушить их в какой-то стрим?
Я клоню к тому, что не случится ли ситуация когда нагрузка очень большая и код отрабатывает быстрее чем логи пушатся наружу, и какой-нибудь внутренний буфер/очередь забьется и начнет делать проблемы?
LEVLLN Автор
31.08.2021 13:24Никак нет. Как я уже пометил в этом комментарии https://habr.com/ru/post/575454/#comment_23431790 - асинхронная библиотека логирования реализована на принципе очереди Queue стандартного logging в питоне. То есть, есть шанс, что можно набить этот буфер очень быстро, но при 860 rps полет был нормальный. Да, есть эффект того, что код отрабатывает быстрее, а логи уже потом за ним поспевают, это нормально для асинхронного мира в других языках программирования, например в Котлине такой же эффект с корутинами.
AlexSpaizNet
31.08.2021 17:35Это важно. При тех же RPS при большом пейлоаде или сложной структурой данных, время сериализации может увеличиться.
А что если канал куда логи отправляются тормозит? Память то не резиновая. Обычно в таких случаях explicitly указывают размер очереди и поведение при заполнении. Например что логи будут дропаться если очередь слишком большая.
А то можно сильно удивиться когда что-то начнет падать по OOM или что канал будет забиваться... или CPU подскочить на сериализации в 3 часа ночи.
И кстати, такой проблемы нет?user = { name: "alex" }
logger("my name", { user, }; ->> ушло в очередь
user.name = "ahmed"Что уйдет в лог?
LEVLLN Автор
31.08.2021 18:34Решение проблемы со слишком большим объёмом данных из комментаторов предложена очень корректно: ограничение по чанкам, ограничение по content lenght. Также я планирую доработать мидлварь для бан-листа для формирования бинарников(если content length - binary), также ограничивать определенные endpoints.
И кстати, такой проблемы нет?
user = { name: "alex" }
logger("my name", { user, }; ->> ушло в очередь
user.name = "ahmed"Что уйдет в лог?
уйдет в лог “alex”, потому что мы сразу ставим record объект в очередь логгера, а его результат записи стрима уже будет работать в asyncio. То есть CPU bound задача с форматированием сработает синхронно, а вывод стрима (I/O) - отработает асинхронно. В этом вся прелесть предложенного мной подхода. И да, Мистер “ahmed” останется ждать своего часа побывать в логгере.

savostin
31.08.2021 13:34А все же, почему не tsv? Это ж на каждую запись дублируется структура, да еще и с такими длинными именами. Я понимаю, если структура в каждой записи меняется, но здесь вроде бы нет.
Да и раз уже JSON, то давайте вложенность:
{"request" : {"uri" : "", "referer": "", "protocol": "" }, "response": {}}А это вообще странно выглядит:
"response_headers": "{\"content-length\": \"13\", \"content-type\": \"application/json\"}", "response_body": "{\"foo\":\"baz\"}"LEVLLN Автор
31.08.2021 13:50Формат специфичный и дело уже разработчика подстраивать формат: я это описал в части, где инициализировал pydantic структуру. Вот, по сути этой структурой можно сделать что угодно в части формата. Тело ответа и заголовки строкой в связи со спецификациями проектов в компании, требования архитекторов и девопсов для однообразия. Решения придумывались совместно над типом данных некоторых полей, они также изменяемы, как видно в коде примеров. Суть статьи была показать, как заставить все механизмы вместе: нативное логирование, асинхронность, форматирование в удобный кастомный формат, который нужен только автору, а можно еще и под ECS это подбить, также показать это дело со стороны веба(аналогичное можно на http-клиентах сделать, могу показать, как это было реализовано на примере httpx библиотеки).
savostin
31.08.2021 13:54А JSON зачем же?
LEVLLN Автор
31.08.2021 14:141) JSON для кастомно-настроенного логстэша. Какие никакие, а поля (я убрал из примеров, но были поля еще трассировки OpenTelemetry, посчитал, что для статьи это неважно)
2) тело и заголовки в строке, потому что эксплуатация хочет это в таком виде читать, копировать, использовать для своих нужд, а также оптимизация для разработчиков на других языках программирования: тут формат вышел из попытки подстроиться под текущие и устоявшиеся стандарты скорее, чем какое-то ноу хау. Поэтому я заложил возможность менять форматы как угодно и где угодно, чтобы это не было головной болью для разработчиков.

baldr
12.09.2021 16:58Судя по всему, asynclog использует потоки. В таком случае о какой асинхронности мы можем говорить здесь? В случайные моменты времени поток переключается и синхронно пишет в файл, блокируя loop.
Еще он может использовать celery, но это примерно то же самое - запись в брокер будет тоже идти синхронно для всего процесса.
Буду рад если окажется что я ошибаюсь.
LEVLLN Автор
14.09.2021 09:57Не используются потоки. Используется обычный класс, который наследуется от QueueHandler, если внимательно попрыгать по исходникам этой либы.
baldr
14.09.2021 10:25Либо мы про разные библиотеки говорим, либо у вас вообще ссылка не на ту библиотеку стоит.
https://github.com/unpluggedcoder/asynclog/blob/master/asynclog/handler.py - вот единственный файл на 85 строк, там явно идет использование
futures.ThreadPoolExecutor.И где вообще происходит вывод в файл? Средствами logging? Но он синхронный!
Как вообще вы относитесь к тому факту что asyncio не поддерживает асинхронный io для файлов? Есть aiofiles, который, в свою очередь, тоже использует потоки чтобы эмулировать асинхронность.
PaulIsh
А если имеются планы потом собирать этот лог в elastic желательно сразу называть поля в журнале согласно ECS (https://www.elastic.co/guide/en/ecs/current/ecs-field-reference.html).
LEVLLN Автор
Добрый день! На совете разработчиков из разных команд была большая война за нейминг полей и они согласовывались с болью. Поэтому ECS формат был неудобен. Но спасибо Вам, пусть этот комментарий будет советом многим: кастомизировать не обязательно, если в этом нет необходимости и можно прибегнуть к стандартам, которые уже придумали разные люди.