

Upd. 04.12.2021. Наш телеграм канал
Upd 10.09.2021. Добавил ещё одну подборку Colab'ов для генерации картинок
Upd 21.09.2021. Добавил пару иллюстраций к Дюне для примера
Статья будет интересна всем любителям программирования, иностранных языков и красивых книг. Сначала мы сделаем параллельную книгу, имея на руках два обычных текста. Затем мы проиллюстрируем ее картинками в стиле pixel art на основе лишь текстовых подсказок.
Книгу можно сделать более чем на сотне языков с восстановлением и подсветкой связей между предложениями:

А теперь давайте сделаем такую книгу сами.
Как выбрать книгу
Если вы хотите улучшить навыки чтения на каком-либо языке, то ориентироваться надо прежде всего на свой вкус. Возможно, стоит взять что-то уже знакомое или прочитанное на родном языке. Также лучше начать с небольших форм, например, рассказов или очерков.
И как её найти
Как же, например, найти Стругацких на немецком или рассказы Акутагавы Рюноскэ в оригинале? Многие произведения на иностранном языке можно приобрести на площадках типа Amazon или Google Play. Можно пойти другим путем (халява, сэр) и поискать книги в не менее популярных местах, типа Флибусты или Z-library, прикрытых тонкой сетью Роскомнадзора.
Чем будем делать
Книгу мы сделаем при помощи моего хобби-проекта, который понемногу обрастает сообществом и энтузиастами. Во многом благодаря им проект получает развитие, исправления и идеи. Приглашаю и вас, — проект открытый и, я уверен, не оставит вас равнодушными.
Демо
Я записал небольшое демо с выравниванием английско-русской версии рассказа "Страж-птица" Роберта Шекли и японско-русской редакции известного рассказа Акутагавы Рюноскэ "В чаще". Там же показано как пользоваться кодом для создания иллюстраций.
Проект Lingtrain
Перейдем к практике. Как языковой энтузиаст я в виде хобби веду различного рода деятельность. Одним из ее отражений является приложение по созданию параллельных книг, про которое я ранее писал. Чтобы не повторяться, я упомяну основные моменты и расскажу про новый функционал. Из других направлений проекта есть составление параллельных корпусов редких языков нашей страны и сервис по изучению языков, так что буду рад, если кто-то заинтересуется.
Установка
Для начала запустим приложение Lingtrain Alignment Studio локально при помощи docker'а. Если вы еще не знакомы с этой технологией, то вот основное, что вам нужно знать, — приложение со всеми зависимостями уже установлено внутри некой сущности, называемой контейнером, и хранится в облаке. Вам нужно этот контейнер скачать и запустить. Docker доступен на всех популярных операционных системах и с его установкой обычно не бывает сложностей. Также приложение можно запустить из исходников, инструкция есть в репозитории проекта.
Итак, для запуска приложения у себя на компьютере нужно выполнить следующие команды:
docker pull lingtrain/aligner:v6-labse
docker run -v C:\app\data:/app/data -v C:\app\img:/app/static/img -p 80:80 lingtrain/aligner:v6-labseЗдесь папки C:\app\data и C:\app\img это папки на вашем компьютере, которые надо предварительно создать, в них будут храниться все ваши наработки.
После запуска приложение станет доступно в браузере по адресу localhost.

Поддержка языков
Как видно из названия образа lingtrain/aligner:v6-labse, в нем используется модель LaBSE, натренированная на 109 языках. Кроме того, родственные языки тоже должны неплохо выравниваться, башкирские коллеги успешно проверили это на местной версии "Книги джунглей" Киплинга, хотя модель на башкирском не обучалась. Помогло "знание" моделью татарского языка, близкого по лексике и грамматике. Также есть версия на другой модели от sentence-transformers, на 50+ языков, меньшей по объему и работающей быстрее.
Выбор языка в интерфейсе может влиять на предобработку текста при разбиении на предложения. Это связанно с особенностями того или иного языка. Например, это могут быть обязательные пробелы перед восклицательным и вопросительным знаками во французской пунктуации или отсутствие пробелов в языках с иероглифической письменностью. Если нужного языка в списке пока нет, то выбирайте последний пункт — General.
Подготавливаем тексты
Имея на руках два текста, надо почистить их от лишней информации — номеров страниц, сносок и т.п. Оставим только текст и метаданные — имя автора, заглавия и эпиграфы, если они есть. Чтобы эти дополнительные данные не участвовали в процессе выравнивания мы их пометим специальными метками, — так при создании выравнивания они отделятся от текстов и будут использованы при оформлении книги.
Сейчас поддерживаются следующие метки:
| Метка | Значение | Пример | Примечание |
|---|---|---|---|
| %%%%%author. | Автор | А.С. Пушкин%%%%%author. | Обязательная метка |
| %%%%%title. | Название | Капитанская дочка%%%%%title. | Обязательная метка |
| %%%%%qtext. | Цитата | Сытый конному не пеший%%%%%qtext. | Парная метка |
| %%%%%qname. | Подпись под цитатой | Народная мудрость%%%%%qname. | Парная метка |
| %%%%%image. | Изображение | https://ya.ru/image.png%%%%%image. | Парная метка |
| %%%%%h1. %%%%%h2. | Заголовки (большой и поменьше) | Глава 1%%%%%h2. | Парная метка |
| %%%%%translator. | Автор перевода | Нора Галь%%%%%translator. | |
| %%%%%divider. | Разделитель | %%%%%divider. |
Парные метки должны присутствовать в обоих текстах в одинаковом количестве (либо их не должно быть). Метку с именем переводчика можно опционально добавить в один или два текста. Метки разделителей можно в произвольном порядке расставить в одном из текстов. На этом месте появится небольшое изображение, разделяющее поток текста.
После добавления разметки у вас должен получиться примерно такой текст:
Дэн Симмонс%%%%%author.
Гиперион%%%%%title.
Посвящается Тэду%%%%%qtext.
Пролог%%%%%h1.
Консул Гегемонии сидел на балконе своего эбеново-черного космического корабля и на хорошо сохранившемся «Стейнвее» играл прелюдию до-диез минор Рахманинова, а снизу, вторя музыке, неслось мычание громадных зеленых псевдоящеров, бултыхавшихся в хлюпающей болотной жиже. С севера приближалась гроза. На фоне свинцовых туч, закрывших полнеба клубящейся девятикилометровой стеной, проступил четкий контур леса гигантских древовидных хвощей. У горизонта сверкнула молния. Возле корабля в синем тумане то и дело появлялись неясные фигуры рептилий, которые пытались проникнуть в защитное поле, но тут же с ревом исчезали. Консул сосредоточился на сложном месте прелюдии, не замечая надвигавшейся бури и сгущавшейся темноты.
Зазвонил приемник мультилинии.
...И второй:
Dan Simmons%%%%%author.
Hyperion%%%%%title.
This is for Ted%%%%%qtext.
Prologue%%%%%h1.
The Hegemony Consul sat on the balcony of his ebony spaceship and played Rachmaninoff’s Prelude in C-sharp Minor on an ancient but well-maintained Steinway while great, green, saurian things surged and bellowed in the swamps below.
A thunderstorm was brewing to the north. Bruise-black clouds silhouetted a forest of giant gymnosperms while stratocumulus towered nine kilometers high in a violent sky. Lightning rippled along the horizon. Closer to the ship, occasional vague, reptilian shapes would blunder into the interdiction field, cry out, and then crash away through indigo mists. The Consul concentrated on a difficult section of the Prelude and ignored the approach of storm and nightfall.
The fatline receiver chimed.
...Как мы видим, количество абзацев и количество предложений может различаться. В этом и изюминка приложения, — мы запомним разделение на абзацы, разобъем оба текста на предложения, выровняем и соберем все обратно в параллельную книгу.
После загрузки текстов мы увидим, как они разделились на предложения, а также все их метки, проверим, что парные метки присутствуют в одинаковом количестве и пойдем дальше.
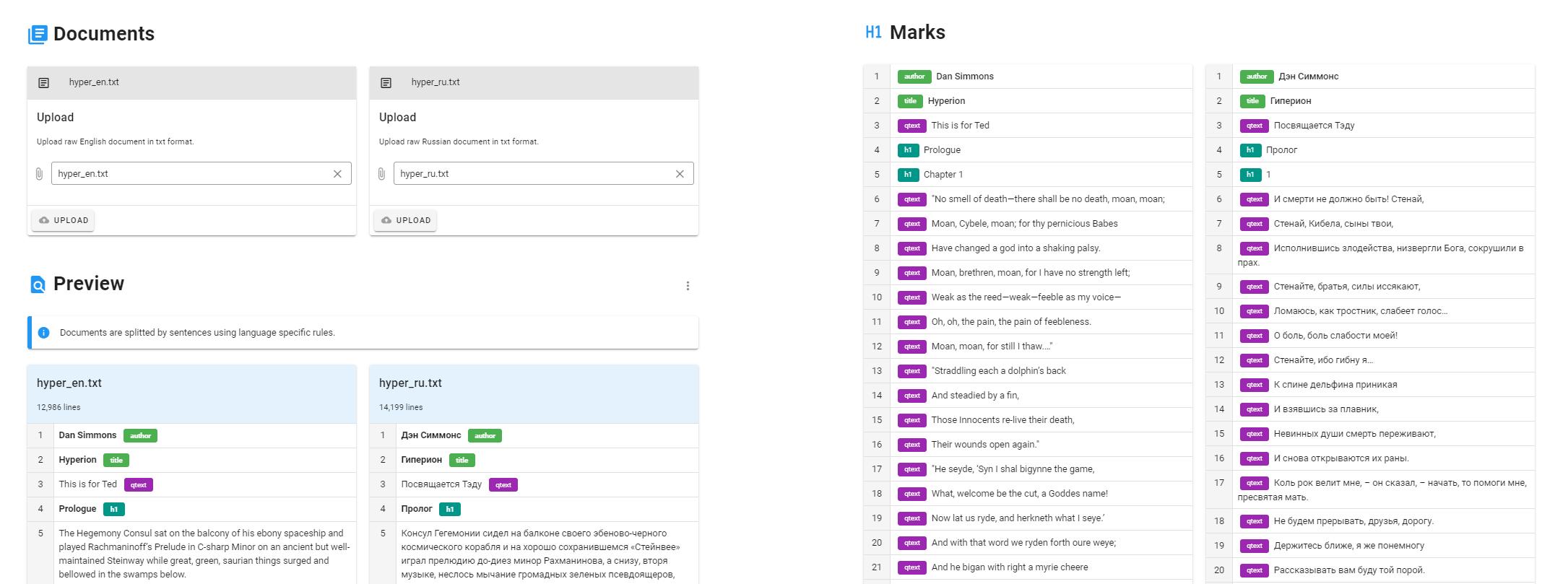
Создаем параллельный корпус
То, что мы сейчас построим, называется параллельным корпусом. У нас есть N предложений на одном языке и M на другом. Выравнивания два этих потока, мы получим какое-то количество пар текстов, это и будет корпус. Процесс разбит на три части:
-
Первичное выравнивание. Идем кусками (батчами) по текстам и подбираем к левому (расположенному слева в интерфейсе) тексту наилучшее соответствие из правого. Из-за различия количества предложений в текстах получаем последовательность хороших кусочков и конфликтов между ними.
-
Разрешение конфликтов. Система комбинирует строки между корректными цепочками между собой и выбирает наилучший вариант. На размер конфликта в этой сборке стоит ограничение в 30 строк, чтобы не повиснуть при слишком большом количестве вариантов.
-
Валидация и редактирование. После второго пункта могут остаться большие конфликты либо разрывы, если в одном из текстов не было соответствующего отрывка. На конфликт можно посмотреть и перейти к нему в редакторе по нажатию на кнопку Open in editor. В редакторе можно редактировать строки, объединять их или удалять. Большие конфликты можно довести до меньшего размера руками и разрешить автоматически.
Выберем загруженные нами тексты и перейдем к выравниванию.
Настройки

Количество батчей. Выравнивание идет по кускам размером 200 строк, можно задать количество таких кусков для обсчета в параллель. Максимально можно выровнять 5 батчей, то есть 1000 строк за раз.
Окно. При помощи размеров окна можно регулировать "нахлёст" батчей друг на друга, чтобы правильные варианты точно попадали в выравнивание.
Сдвиг. Если на каком-то участке слишком сильно отличается количество предложений между текстами, то выравнивание может не попасть в окно и модель будет выдавать случайные соответствия. Все это будет видно на визуализации и можно либо увеличить окно, либо отрегулировать поток сдвигом текста вперед или назад.
Кроме того, благодаря фидбеку от пользователей, я добавил возможность не просто выравнивать очередные батчи, а выбирать необходимый диапазон. Этот диапазон можно пересчитать с другими параметрами сдвига и окна, если выравнивание отклонилось. Это можно сделать, нажав на кнопку Customize.
Визуализация
Для каждого батча строится график, показывающий соответствие строк нашего корпуса. Так как при редактировании корпуса идентификаторы могут меняться, картинку можно обновлять. При разрешении конфликтов картинки пересчитываются автоматически.
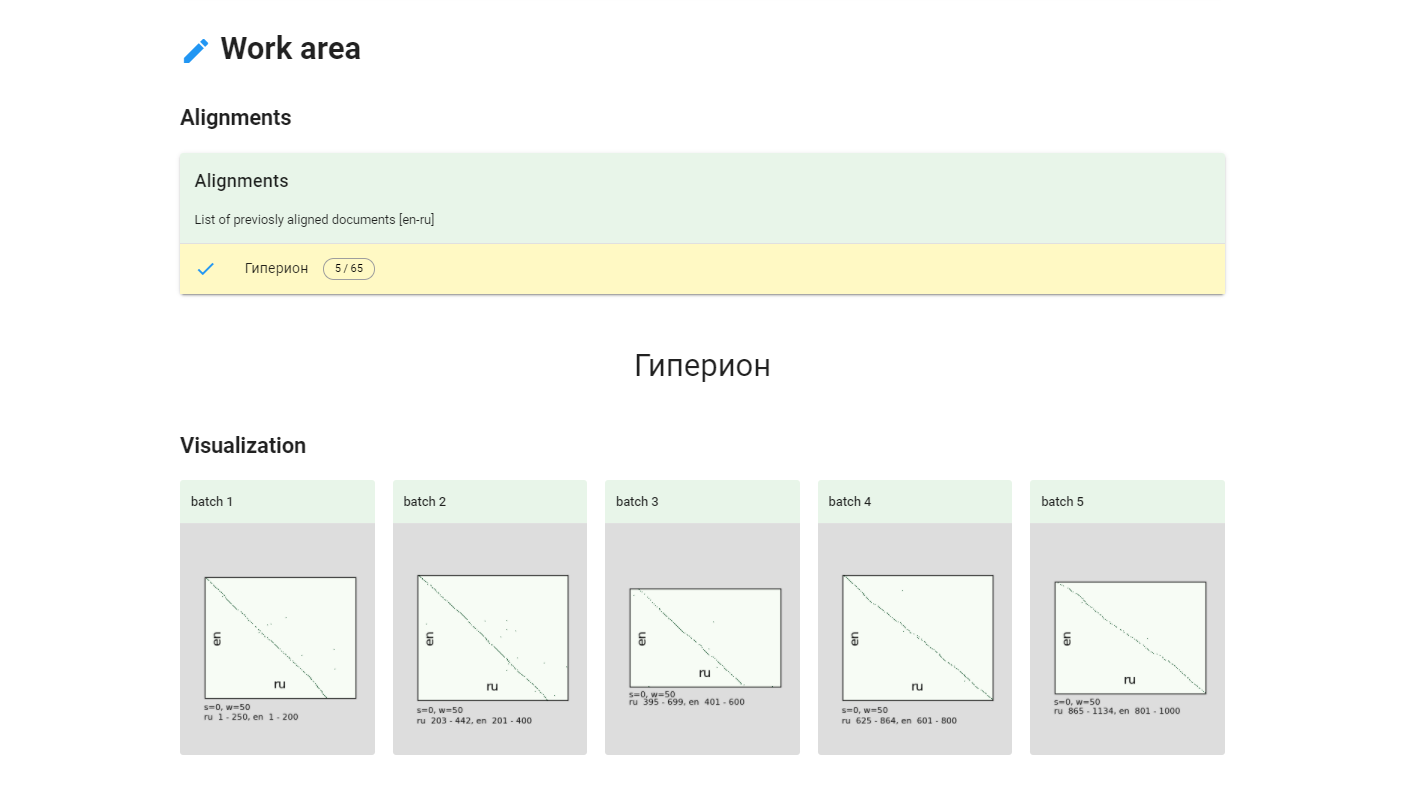
Конфликты
После первичного выравнивания все еще остается большое количество несоответствий, ведь количество предложений в текстах может различаться на сотни, сопоставления один к одному нет. Посмотреть на конкретный конфликт можно в секции Conflicts и сразу перейти к нему в редакторе.

Разрешение руками
В редакторе можно восстанавливать непопавшие в выравнивание строки.

Также можно объединять строки подкорпуса друг с другом. Важно делать это через элементы управления, а не копированием текста. Тогда система будет знать из каких исходных строк состоит элемент параллельного корпуса.

Автоматическое разрешение
Для разрешения конфликтов в автоматическом режиме нужно нажать на кнопку Resolve all. Этот процесс может занять некоторое время и по его окончании останутся либо неразрешимые (слишком широкие) конфликты и конфликты по краям корпуса, либо все пройдет гладко и мы получим готовый корпус.
Подстрочник
Есть возможность добавить автоматический машинный перевод для нужного корпуса. Наличие таких подсказок очень сильно сокращает процесс редактирования.
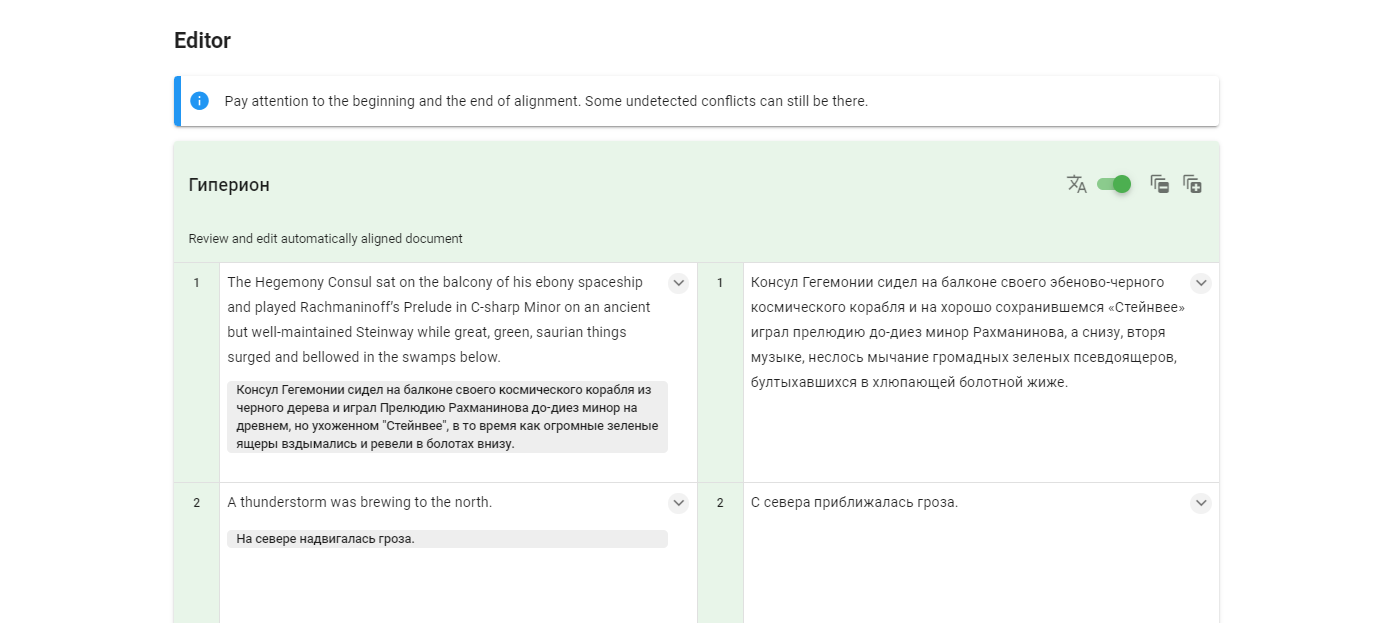
Чтобы добавить такой перевод, надо скачать корпус, либо открыть его в браузере. Это можно сделать в секции Subscript. При открытии в Chrome есть полезная функция по автоматическому переводу. Причем объем текста может быть довольно большим, что лично меня очень радует. Текст на несколько тысяч строк переводится за несколько секунд.
Переведенный текст надо сохранить в файл и загрузить обратно в той же секции.
Потерянные строки
В секции Unused strings можно убедиться, что никакие строки не потеряны. Такое может быть на концах текстов, так как при разрешении конфликтов мы опираемся на хорошие кусочки, а на краях текста их может не быть.
Делаем книгу
Удостоверившись, что корпус хорошего качества и никакие строки не потеряны, перейдем на вкладку Create.
Если вам нужен только параллельный корпус, то его можно скачать в нужном формате (tmx или txt) в секции Download и на этом закончить.
Мы же продолжим дальше и сгенерируем html с нашей книгой. Как мы видели ранее, структура абзацев у двух текстов разная. При создании выравнивания мы запомнили обе и теперь можем выбрать на основе какой из них группировать предложения.
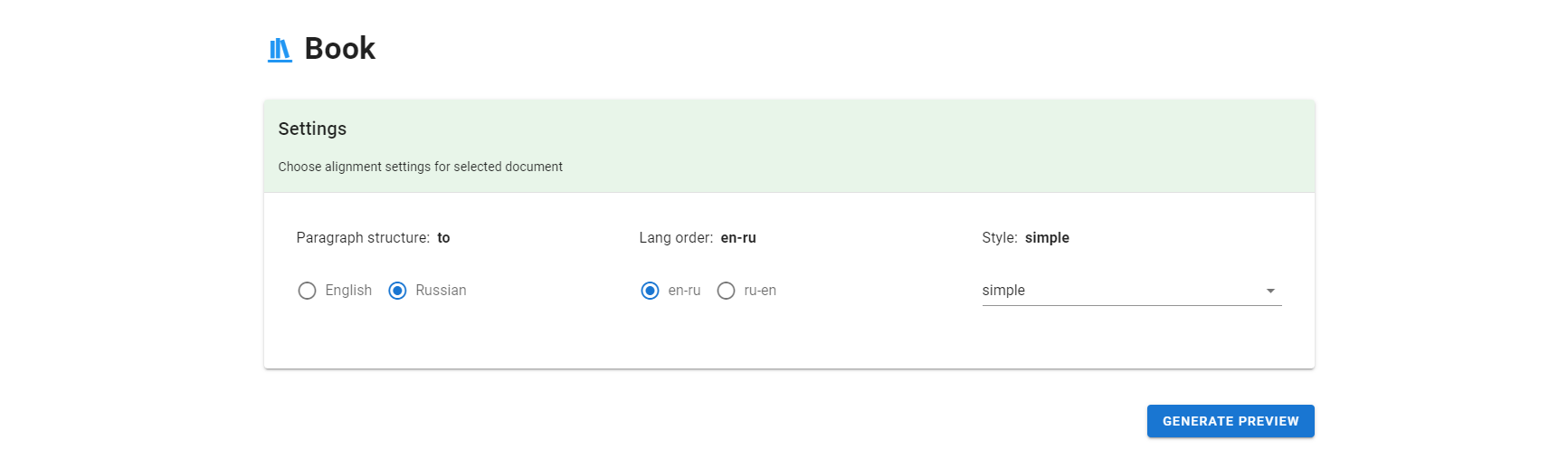
Для подсветки соответствий между предложениями нужно выбрать один из стилей pastel_fill или pastel_start. Сгенерируем начало книги и посмотрим на результат:

Скачаем всю книгу в секции Download, при наведении курсора на абзац с текстом мы увидим его порядковый номер. Книгу мы сделали, осталось добавить в нее обещанные иллюстрации.
За отображение иллюстраций отвечает метка %%%%%image. Добавить ее можно либо на первом этапе, либо сейчас, при создании книги. В секции Edit marks можно увидеть все метки, подредактировать и добавить новые. Картинки можно вставлять в виде URL по одной или же пачками. При добавлении метки нужно указать номер абзаца в котором она будет отображаться.
Добавление картинок пачками я сделал, чтобы нагенерировать много изображений и разом вставить их в книгу. Этим и займемся.
Добавляем картинки
Не буду растекаться мыслью по древу по поводу современных подходов в генерации изображений, напомню главные моменты и покажу примеры того, что и как сейчас можно делать.
Основные моменты
OpenAI придумала вещь под названием CLIP, которая представляет из себя способ обучения двух моделей, одна из которых принимает на вход текст, а другая — картинки. В процессе обучения сеть учится определять насколько близки картинка и текст. В паре с этой сетью можно использовать другие, — генераторы изображений. Про CLIP можно почитать, например, вот эту статью.
Примеры картинок
По сети гуляет множество различных Colab ноутбуков, которые постоянно дорабатываются сообществом. Поигравшись с ними, у меня получилось нагенерировать довольно качественные картинки. Далее будет табличка с ноутбуками, при помощи которых они были созданы, и пара советов по улучшению качества. Рядом с картинкой указаны подсказки, на основе которых создавались изображения.
Мне нравятся сети, предобученные на картинах художников. Добавляя к ним имя того или иного автора можно получить изображение в его стиле. Заметьте, это не перенос стиля на фотографию, а создание нового изображения. При различных начальных условиях (параметр seed в блокнотах) будут сгенерированы разные картинки.
| Картинка | Подсказка |
|---|---|
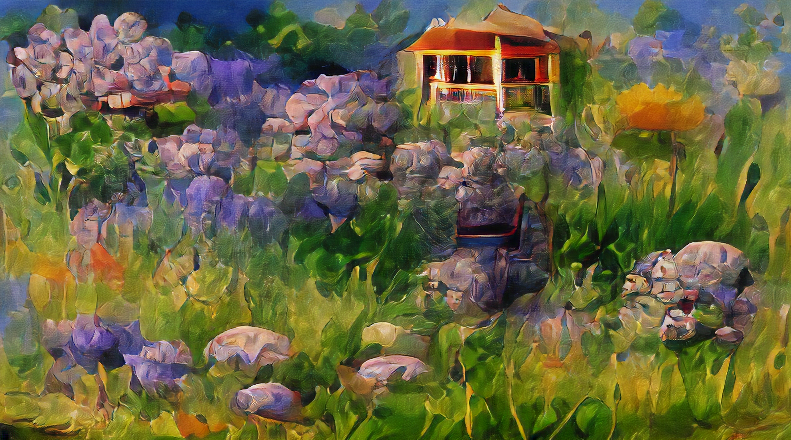 |
Little house in the meadow with flowers by Claude Monet |
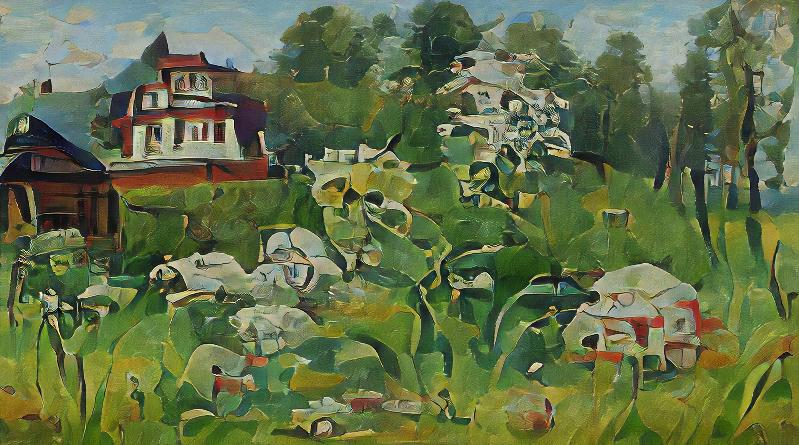 |
Little house in the meadow with flowers by Vasnetsov |
 |
Little house in the meadow with flowers by Van Gogh |
 |
Center of the Moscow city by Van Gogh |
 |
Center of the Moscow city by Picasso |
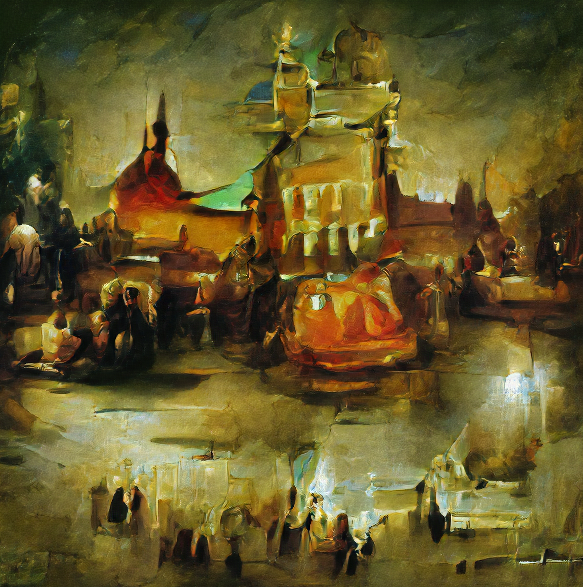 |
Center of the Moscow city by Rembrandt |
Также есть возможность подать в качестве подсказки не только текст, но и отправное изображение. Тогда можно получить перенос стиля на это изображение. Главное тут вовремя остановиться и не делать слишком много итераций.
| Оригинал | Картинка | Подсказка |
|---|---|---|
 |
 |
Oil painting + [photo of a cat] |
При помощи подхода CLIP + Guided diffusion можно создавать фотореалистичные изображения несуществующих миров. Но тут потребуется изрядный cherry-pick (делаем много, выбираем лучшее), поэтому вот картинки от автора:
| Картинка | Подсказка |
|---|---|
 |
a beautiful fantasy land forest, trending on ArtStation |
 |
the transhuman condition by Rene Magritte |
 |
a church in the style of cyberpunk noir |
А еще среди появившихся идей есть генерирование картинок в стиле pixel art от пользователя dribnet и его доработанной версией, в которой можно задать картинке цветовую палитру. Этот подход пришелся мне по душе, поэтому его я и выбрал в качестве основного. Посмотрим на примеры:
| Картинка | Подсказка |
|---|---|
 |
Game of thrones |
 |
Master and Margarita by Bulgakov |
 |
Three comrades by Remarque |
 |
Roadside picnic |
Эксперименты
Попробуйте сами на досуге:
| Название | Ссылка на Colab | Источник |
|---|---|---|
| VQGAN+CLIP_(z+quantize_method) | Colab | EleutherAI |
| Semantic_Style_Transfer_withCLIP+VQGAN(Gumbel_VQGAN) | Colab | EleutherAI |
| CLIP_Guided_Diffusion | Colab | EleutherAI |
| CLIP_Guided_Diffusion_HQ_512x512 | Colab | EleutherAI |
| CLIP_Decision_Transformer | Colab | EleutherAI |
| VQGAN+CLIP (with pooling) | Colab | эй ай ньюз |
| Text2PixelArt — Mishin Learning Resolution Mod | Colab | Мишин Лернинг |
| [Forked by Denis Sexy IT] Text2PixelArt | Colab | Denis Sexy IT |
| CLIPIT PixelDraw by dribnet + palette enforcement by altsoph | Colab | altsoph |
Upd. Ещё одна отличная подборка.
Upd. Илюстрации к Дюне:
Шаи-Хулуд (Shai-Hulud):


Пол Атрейдес верхом на черве:


Пол и фримены с голубыми глазами:



Делаем иллюстрации
Для автоматического иллюстрирования я собрал Colab, который сделает нам картинки на основе подсказок из книги. Переходим в него по ссылке.

Если у вас текст на английском языке, то качаем его разбитую по абзацам версию из секции Download нашего приложения. Далее выбираем количество пар иллюстраций (на основе каждой текстовой подсказки мы сделаем по две картинки). Простенький NLP подход надергает нам подсказок в переменную prompts_list вместе с номерами соответствующих абзацев. Получится примерно так:
prompts_list = [('Hyperion by Dan Simmons #pixelart', 2)
('Silenus seemed ninety fifties #pixelart', 115)
('You said warship #pixelart', 230)
('poet said two sign #pixelart', 345)
('I felt sort #pixelart', 460)
('It rains afternoon #pixelart', 575)]Первая подсказка формируется из имени автора и произведения. Так как метод для извлечения ключевых слов довольно простой, подсказки лучше доработать или придумать свои на основе соответствующих абзацев. Так же поступаем в случае исходного текста не на английском языке — формируем сами массив prompts_list с подсказками и номерами абзацев. Предложений из четырех-пяти слов будет достаточно.
Далее запускаем процесс генерации картинок по получившимся подсказкам. Дело это не быстрое, даже с учетом того, что обсчет происходит на colab'овской видеокарте. Десяток картинок генерируется около часа.
Все сохраненные картинки автоматически выгружаются на хостинг изображений. Первый хостинг, который я нашел, — imgbb.com, — удобен тем, что можно получить токен и с ним выгружать картинки через API. В ноутбуке я оставил свой, поэтому, если он перестанет работать, зарегистрируйте себе бесплатный аккаунт и используйте его. Либо загрузите картинки ручками в любое другое облако, например, habrastorage. Картинки можно найти в папке content.

После загрузки появится примерно такой текст:
https://i.ibb.co/82PrGmh/40d7ba3dcf1e.png, 2, Watchbird by Robert Sheckley #pixelart
https://i.ibb.co/n8qvXWB/3723ee7a9931.png, 2, Watchbird by Robert Sheckley #pixelart
https://i.ibb.co/L6WFzf4/fc52d007abf4.png, 48, scientists know one machine #pixelart
https://i.ibb.co/6HshZ7C/faeca08b4bbe.png, 48, scientists know one machine #pixelart
https://i.ibb.co/NC5TfHK/195b90eb5e29.png, 96, Macintyre grinned lot #pixelart
https://i.ibb.co/6mxFmTj/d547cec128fa.png, 96, Macintyre grinned lot #pixelart
https://i.ibb.co/HzdSq0X/96e540de5cc0.png, 144, hint came morning #pixelart
https://i.ibb.co/NNSv81j/bbfad7acc786.png, 144, hint came morning #pixelart
https://i.ibb.co/9cyVLKp/dc69e4737aef.png, 192, He put telephone #pixelart
https://i.ibb.co/kmpysR7/32e6028b7bfd.png, 192, He put telephone #pixelartЧисло — это номер абзаца, перед которым картинка должна будет появиться в книге. Если вы хотите взять другие абзацы, например, начало каждой главы, то создайте подходящие им подсказки руками, и не забудьте номера их абзацев. Номера видны после генерации книги и после добавления других меток не меняются.
Полученный текст мы вставляем в секции Edit marks и жмем Save.

Картинки добавятся в наше выравнивание, можно перегенерировать книгу и посмотреть на финальный результат.

Итог
Надеюсь, что этот рассказ был небесполезным и у вас появилось желание начать изучать иностранный язык или углубиться в тему программирования.
Буду рад, если этот проект поможет создать вам параллельную книгу для себя или учеников. Буду не менее рад, если вы используете его для извлечения параллельных корпусов и другой полезной активности.
Проект открытый и его можно поддержать, скинув в копилку на кофе. Если остались вопросы или вам просто близка эта тема, то добавляйтесь в нашу телеграм-группу, там же можно найти уже выровненные книги на различных языках.
В планах стоит доработка приложения под нагрузку для развертывания в облаке, оптимизация моделей под скорость и возможность дообучения под малые языки.
Ссылки
Комментарии (56)

EugeneH
03.09.2021 11:10+2Большое спасибо за статью! И за ссылки на блокноты отдельно. Вроде бы только недавно синтез изображения по текстовой подсказке был чем-то недосягаемым. Теперь же все делается в 2 клика. Страшно представить, к чему это придет через 10 лет. Синтез фильма по краткому описанию сюжета?

diogen4212
03.09.2021 12:09+1Лелею мечту о продолжении или альтернативном сюжете любимых книг, написанных с помощью нейросети, обученной на оригинальном тексте, может быть, на основе моего краткого описания. Например, полностью каноничное продолжение Гарри Поттера на основе оригинальных книг, в некотором роде идеальный фанфик.

averkij Автор
03.09.2021 13:29Рад, что понравилось! Можете тоже поиграть, получите массу удовольствия.







Alexey2005
03.09.2021 16:05+1Тот же самый CLIP, соединённый с vqgan, позволяет генерировать довольно качественные полноразмерные обоины абстрактного содержания. Правда, степень понимания языка всё ещё оставляет желать лучшего, и как ни формулируй запрос, на выходе никогда не получается в точности то, что хочется.
Вот напримерLyra-shaped crystal cave #Unreal Engine
Модель «не понимает», что в пещере деревья обычно не растут, да и пожелание сделать планировку пещеры в форме указанного музыкального инструмента реализовать не удалось даже после нескольких модификаций текста запроса.averkij Автор
03.09.2021 16:26Для улучшения качества можно добавлять различного рода подсказки, — fine details, high resolution, professional photo of, ultra settings, ray tracing.
averkij Автор
03.09.2021 18:45А какие изображения лучше получаются, на какую тему?
Alexey2005
03.09.2021 18:54+1Лучше всего абстрактные вещи. Пещеры, горы, леса, парусник в море и т.д.
В общем, разного рода фоновые вещи. Людей, особенно крупным планом, оно обрабатывает так себе (в pixelart-варианте это не слишком видно, но если делать FullHD, то ужас-ужас).
И совсем паршиво обрабатываются мифические животные, например гарпии, грифоны, драконы или (особенно) русалки. Сгенерировать нормальный русалочий хвост в FullHD так и не удалось. Похоже, нужно тюнить модель или использовать её как feature extractor, набросив сверху два дополнительных слоя, чтобы генерировать мифических животных.averkij Автор
03.09.2021 19:31А вы какие модели используте, которые в сети гуляют (натренированные на Imagenet'ах, WikiArt, Flickr и т.д.)? Я вот на этих пробовал:

Но вот, действительно, точного выполнения от них не получается. Лица в принципе генерируются, но страшненькие. Вот картины довольно неплохо заходят.Alexey2005
03.09.2021 19:53+1Да, эти плюс vqgan_gumbel_f8, которая даёт достаточно интересные результаты.
averkij Автор
03.09.2021 19:58Вот в этом канале девушка очень крутые картинки генерирует
https://twitter.com/RiversHaveWings






Alexey2005
04.09.2021 23:36Забавно выходит, если скармливать сетке разные абстрактные вещи. Например,
Linux vs FreeBSD

averkij Автор
05.09.2021 13:17Двери в осень, зиму, весну и лето
Alexey2005
05.09.2021 14:49В моём случае дверь в осень получается всегда без людей и результат напоминает
скрин из какой-то компьютерной игрушки времён DOS
averkij Автор
05.09.2021 17:11Круто, а поделитесь кодом для такой генерации?
Alexey2005
05.09.2021 18:25+1Вверху уже поделился инструкцией — нужно в этих Colab'ах отключить diffvg, вместо этого используя vqgan.
Ну, и если запускать локально, то там намного больше возможностей и параметров для настройки. Я использовал такой вариант запуска:python generate.py -p "the door into autumn #pixelart" -i 600 -qua "normal" --num_cuts 15 --output "result/output" -s 416 224 -lr 0.1 --save_every 10 --pixelize_every 50 --out_unpix "unpix/output"






averkij Автор
10.09.2021 09:05Нашел еще одну подборку Colab'ов:
github.com/tg-bomze/collection-of-notebooks



Alexey2005
29.09.2021 17:32+1На Хабре опубликовали статью со ссылкой на апскейл-нейронку, которая на удивление неплохо обрабатывает пиксельарт.
Так что можно взять «выхлоп» CLIP, уменьшить так, чтобы каждый пиксельный кадратик изображения занимал ровно 1 реальный пиксель, после чего увеличить с помощью этой нейронки.Результаты




{kind=link}
Meklon
Пиксель-арт прекрасен
averkij Автор
Не могу наиграться. Вот «the door into summer»:


Meklon
Кажется, я знаю, как буду иллюстрировать корпоративную Wiki
averkij Автор
Если будете сегодня это делать, то вот:



Meklon
averkij Автор
Colab не всегда дает годную видеокарту, надо перезапустить сеанс и посмотреть какая видеокарта подключилась в ячейке **!nvidia-smi**. Надо, чтобы была хотя бы T4, возможно и P4 хватит, но точно не K80.
Meklon
Опять та же фигня. Не вижу где посмотреть видеокарту
averkij Автор
Надо запустить верхнюю ячейку (на картинке — Tesla T4).

Гугл в зависимости от загруженности может разные карты подсовывать. Можно еще оформить Colab Pro подписку, тогда будет карты помощнее давать.
Meklon
Мы точно про один и тот же блокнот?
https://colab.research.google.com/drive/1MDin_3_XE21f7XcnFw_alc1YZIuKkD15#scrollTo=qQOvOhnKQ-Tu
averkij Автор
Я про свой:
https://colab.research.google.com/drive/1B6FLBZmHCSZmCI-kmQRzPqy0PeicO0PG
Добавьте в вашем блокноте ячейку и выполните в ней !nvidia-smi, покажет текущую видеокарту.
Meklon
Отдает всегда Tesla K80
averkij Автор
Вы только выбирайте не «перезапустить среду выполнения», а в управлении сеансами ее тушите. Потом заново подключайтесь.

Если все время k80 дает, то надо подождать, значит нет свободных. Вообще должен в итоге хотя бы P4 выдать.
Либо же раскошелиться на подписку.
Meklon
Видимо нет. Я раз 20 пересоздавал машину.
Meklon
Сейчас доступ к Colab Pro есть только в Бразилии, Великобритании, Германии, Индии, Канаде, США, Таиланде, Франции и Японии.
А локально не вариант то же самое запустить? У меня RTX 2060 Super
Alexey2005
Да, это возможно, карточка тянет и 6Гб VRAM достаточно для запуска (при условии, что на вашем PC есть минимум 8Гб оперативки и минимум 11 свободных Гб на диске).
Проблема в том, что синтез пиксель арта здесь основан на diffvg, который придётся собирать из исходников на локальной машине, что не вполне тривиально.
Если у вас что-то вроде Debian или Ubuntu с установленными драйверами NVIDIA, CUDA Toolkit 10.2, и Python 3.7+, то могу написать небольшой гайд, как запустить эту нейронку локально. А вот под винду так даже и не соображу, что и как настраивать.
averkij Автор
Colab Pro в России тоже можно, можете указать Америку и zip код отсюда
stackoverflow.com/questions/60240863/i-am-from-pakistan-can-i-buy-google-colab-pro-for-experiments
Meklon
Так.
Oops: runtime error: CUDA out of memory. Tried to allocate 48.00 MiB (GPU 0; 7.43 GiB total capacity; 5.83 GiB already allocated; 32.81 MiB free; 5.95 GiB reserved in total by PyTorch) Try reducing --num-cuts to save memory
Сколько ему надо ресурсов? Никак зарезать нельзя?
Alexey2005
От 4Гб и до бесконечности — зависит от разрешения, выставленного качества, набора используемых моделей и аугментаций.
добавить строку:В Colab'е очень часто выделяют меньше VRAM, чем есть на GPU. Издержки облака…
Можете попробовать в ячейке "III. Generate images" нажать на «Show code» и там, где задаются параметры, скажем после строчки
Это очень сильно уменьшит потребление памяти.
Meklon
Отлично, спасибо. Жаль опять Tesla K80 теперь только выпадает. На ней этот код вообще почему-то не взлетает. Даже медленно.
averkij Автор
Да, в неё модель не поместится

Alexey2005
Там проблема не в Tesla K80, а в том, что гугловцы положили в этот контейнер кривую сборку pytorch. Но можно сделать финт ушами и, если не получается выкрутить ничего кроме K80, заменить diffvg на vqgan — тогда будет работать даже в таких условиях, хотя такого замечательного пиксель арта и не выйдет (но поиграться можно, а результат всё же будет довольно неплох).
заменить на (иначе модель не влезет в память). Кроме того, после этой строчки добавить:Для этого можно, к примеру, воспользоваться этим Colab'ом. Там после установки всего нужного и перезапуска runtime'а:
1. Устанавливаем scale в 1.
2. Снимаем галочку use_pixeldraw (теперь у нас вместо diffvg будет vqgan).
3. Показать код (Show code) в этой ячейке и там:
Тем самым мы запрашиваем генерацию квадратного изображения 256x256 пикселей (размеры должны быть кратны 16, чтобы сеть переварила).
Всё, можно запускать, не забывая указывать в запросе тип рендеринга (скажем, #Unreal Engine или #pixelart):
Meklon
Спасибо. Я уже думаю, что проще на своей RTX 2060S завести.
Meklon
А из PyPi не получится более корректную версию PyTorch вытащить в процессе сетапа?
Alexey2005
Вряд ли, скорее всего кастомный билд собирать придётся. Но вы можете попробовать перебрать официальные билды — вдруг на чём-то запустится? (Хотя шансы невелики).
averkij Автор
Можно --num-cuts параметр меньше указать. В блокноте раскройте ячейку с настройками и добавьте строку

clipit.add_settings(num_cuts=96)
Alexey2005
96 в 7Гб VRAM вряд ли влезет. Я бы начинал с совсем низких значений, а поднять всегда можно успеть.
averkij Автор
Согласен, тут надо поиграться.
Meklon
Добавил в код:
Выдал:
/device:GPU:0
averkij Автор