

Хайп вокруг нейросетей, выровненных при помощи инструкций и человеческой оценки (известных в народе под единым брендом «ChatGPT»), трудно не заметить. Люди разных профессий и возрастов дивятся примерам нейросетевых генераций, используют ChatGPT для создания контента и рассуждают на темы сознания, а также повсеместного отнимания нейросетями рабочих мест. Отдадим должное качеству продукта от OpenAI — так и подмывает использовать эту технологию по любому поводу — «напиши статью», «исправь код», «дай совет по общению с девушками».
Но как достичь или хотя бы приблизиться к подобному качеству? Что играет ключевую роль при обучении — данные, архитектура, ёмкость модели или что-то ещё? Создатели ChatGPT, к сожалению, не раскрывают деталей своих экспериментов, поэтому многочисленные исследователи нащупывают свой путь и опираются на результаты друг друга.
Мы с радостью хотим поделиться с сообществом своим опытом по созданию подобной модели, включая технические детали, а также дать возможность попробовать её, в том числе через API. Итак, «Салют, GigaChat! Как приручить дракона?»
Затравка

Для начала напомним читателям, что языковая модель — это сущность, которая вбирает в себя знания из текстов, после чего может быть использована для понимания машиной текстовой информации. Мы используем языковые модели каждый день: набирая сообщение в телефоне или при поиске чего-то в интернете, мы видим их предложения.
Простые виды таких моделей могут считать вероятности переходов между всеми возможными вариантами символов, а при генерации выдавать самый очевидный вариант.
Самые сложные на сегодняшний день модели имеют так называемую трансформерную архитектуру. Корни этого подхода берут начало в уже классической статье «Attention is all you need». Если хочется сформировать классификацию этих моделей, то можно обратиться к диаграмме из очень содержательного обзора «Transformer models: an introduction and catalog»:

Главный объект внимания располагается в нижнем правом углу и представляет собой семейство моделей, обученных с применением инструкций. Что же это такое и как это работает?
Общий подход для тренировки подобных моделей (RLHF) примерно такой:
Взять предобученную языковую модель. В сообществе сейчас процветает подход с дообучением модели LLaMA, которая существует в нескольких размерах и «видела» немного текстов на русском, однако лицензия позволяет использовать её лишь в исследовательских целях.
???? На данном этапе модель знает очень много о мире, но не умеет в правильной форме нам ответить.
Провести над этой моделью SFT (supervised fine-tuning). Кажется, что это наиболее важный пункт, так как для его реализации требуется собрать очень качественный набор обучающих данных в инструктивной форме. Такие данные могут выглядеть примерно так:
Вопрос: В какое состояние переходит вода при её охлаждении до нуля градусов?
Ответ: При охлаждении до 4х градусов вода сжимается, до 0 градусов постепенно
расширяется, а при температуре ниже 0 переходит в твердое состояние – лёд, и
расширяется гораздо сильней, чем в жидком состоянии.???? Инструктивные данные как бы задают форму ответов модели, настраивая её отвечать подобным образом. Чтобы данные были максимально качественными, нужно их провалидировать, в том числе при помощи экспертов в конкретных областях.
Натренировать модель-оценщик (reward model). Это отдельная небольшая классификационная модель, которая умеет предсказывать, какой из предложенных ей вариантов, сгенерированных языковой моделью, лучше с точки зрения человека. Чтобы её натренировать, нужна соответствующая разметка.
Финальное выравнивание. Теперь нужно пропускать через нашу модель результаты генерации и обновлять веса при помощи PPO (Proximal Policy Optimization).
Этот процесс можно рассматривать как извлечение знаний и навыков языковой модели на поверхность. Подробнее про этот подход можно прочитать в статье про InstructGPT "Training language models to follow instructions with human feedback".
В текущем релизе мы сосредоточились на первых двух пунктах как дающих максимальный прирост в качестве. Давайте посмотрим, что же находится внутри GigaChat’а.
А внутре у ней NeONKA
Совокупность моделей, лежащих в основе GigaChat’а, мы назвали NeONKA (NEural Omnimodal Network with Knowledge-Awareness) с аллюзией на известное произведение братьев Стругацких. Хоть это и самоиронично, но в отличие от незадачливого изобретателя вам не понадобится самостоятельно печатать ответ модели в строке вывода.
Чтобы приступить к обучению на инструктивных данных пришлось задуматься над выбором базовой модели (претрейна). За последние несколько лет нами был обучен и выложен в открытый доступ ряд русскоязычных и мультиязычных генеративных моделей. Это ruGPT-3, ruT5, mGPT, FRED-T5 и другие. FRED-T5, кстати, вышел совсем недавно и подробней про него можно почитать в статье Новая SOTA модель для русского языка.
Для первых экспериментов мы выбрали модель ruGPT-3 размера 13B (13 миллиардов параметров). Это декодерная модель, обученная на сравнительно небольшом корпусе данных в 300Gb. Корпус содержит несколько доменов, включающих в себя книги и новости на русском и английском языках, разговорную речь, научные статьи и т.д. Говоря простым языком, это сотни тысяч книг, документов, статей и прочего.
Обучалась эта модель около полутора месяцев на 512 GPU V100.

На этом корпусе обучалось большинство наших моделей и он довольно чист, но в современных реалиях уже не кажется большим. Для сравнения, размер хорошего английского корпуса The Pile составляет более 800Гб. Сейчас мы работаем над новой версией чистого корпуса, размером более 2ТБ.
ruGPT-3.5 13B
Чтобы актуализировать знания модели и улучшить понимание дополнительных специфических доменов мы дообучили её на расширенной версии датасета, в который вошли юридические документы, часть The Stack (открытый сет с кодом) от коллаборации исследователей BigCode, обновленные версии Википедии и новости.
Таким образом, мы потренировали модель в течение 3-х недель на 200 GPU A100 и получили базовую модель для наших экспериментов, которую назвали ruGPT-3.5. Теперь можно было приступать к экспериментам с инструкциями.
Инструктивный датасет
Одной из наиболее важных составляющих процесса обучения являются инструктивные данные. Мы много экспериментировали с различными наборами данных. На первом этапе все данные были сформированы автоматически путем генерации из различных тематических источников.
Мы задействовали все свои внутренние датасеты по различным задачам, — суммаризации и рерайтингу, вопросно-ответные системы, диалоги, машинный перевод, написание стихов и прочее. Такой подход позволил понять нам, что даже так модель начинает давать ответы, которые хоть как-то похожи по форме.
Затем мы стали варьировать доли задач, так как некоторые из них “душили” способности модели. Отражалось это как в длине ответов так и в их смысловой нагрузке.
На финальном этапе подключились редакторы и эксперты, которые правили инструкции, а также добавляли сложные вещи типа «Назови способы выражения суперлативного значения в русском языке».
Оценка
Важной часть работы является оценка моделей. Автоматические метрики не всегда коррелируют с человеческим мнением об ответе модели, поэтому ключевой оценкой были SBS (side by side) тесты. В таких тестах разметчики определяют предпочтительный вариант ответа от разных моделей. Также мы использовали более развернутые метрики типа ODMEN (наша внутренняя метрика, которую стоит обсуждать отдельно) и уделили время оценке этичности модели.
От эксперимента к эксперименту мы замеряли таким образом качество и выбрали самую удачную модель в кандидаты для релиза.
Не обошли стороной и сравнение с ChatGPT. Собрав "корзину" из запросов разной тематики, мы провели на ней SBS между нашей моделью и моделью от OpenAI (gpt-3.5-turbo). Начиная от 3:97 в пользу ChatGPT, нам удалось добиться результата 30:70 в финальной версии модели.
Дообучать LLaMA 13B на наших инструкциях мы тоже пробовали и результаты оказались неплохи, однако ruGPT-3.5 13B показала себя лучше в SBS тестировании — 58:42 в пользу нашей модели.
Давайте посмотрим, что же сейчас умеет делать GigaChat.
Возможности модели

Сейчас у GigaChat’а лучше всего получается решать профессиональные и творческие задачи. Тип задачи ограничен только вашей фантазией, приведем несколько примеров:
Написание рекламных текстов
Напиши продающий текст для интернет-магазина ювелирных украшений ручной работы
Вы ищете нечто особенное? В нашем интернет-магазине вы найдете множество уникальных и эксклюзивных ювелирных украшений, созданных вручную нашими талантливыми мастерами. Каждое украшение – это настоящая ручная работа, которая не только выглядит роскошно, но и обладает уникальными особенностями.
Мы предлагаем вам широкий выбор ювелирных изделий различных стилей и направлений. От классических сережек до современных браслетов, у нас есть все, что вам нужно. Мы уверены, что вы обязательно найдете то, что подходит именно вам.
Кроме того, мы гарантируем высокое качество наших изделий. Все украшения изготавливаются из высококачественных материалов, а каждый элемент проходит тщательный контроль перед тем, как попасть на ваш пальчик.
Купить у нас ювелирные изделия – это значит вложить в свой образ немного роскоши и индивидуальности. Наши украшения – это не просто модные аксессуары, они созданы, чтобы украсить вас и вашу жизнь. Приходите к нам сегодня и убедитесь в этом сами!
Придумай несколько названий для такого магазина
1. Солнечный камень
2. Жемчужная река
3. Златоцвет
4. Лучезар
5. Изумрудный город
6. Антикварная лавка
7. Мир серебра
8. Ювелирная симфония
Воображаемые диалоги
Напиши диалог между Лениным и Ганди на тему свободы
Ленин: Вы говорите, что человек должен быть свободен. Но что вы понимаете под этой свободой?
Ганди: Я понимаю свободу как возможность делать то, что ты хочешь, не подвергаясь при этом угнетению.
Ленин: Но разве не очевидно, что большинство людей хочет совсем не того, чего хотите вы? Они хотят есть, пить, иметь жильё и прочие материальные блага. Разве они не угнетают друг друга в своих стремлениях к этим благам? Напротив, именно те, кто обладает богатством или властью, чаще всего подавляют других. Свобода, о которой вы говорите, на деле означает господство меньшинства над большинством.
Ганди: Я согласен, что стремление к материальным благам может иногда приводить к неравенству. Но это явление неизбежное и естественное. В человеческом обществе всегда будет существовать небольшое число людей, которые будут жить лучше, чем остальные. Это несправедливо, но это так. Однако я убеждён, что можно создать общество, в котором никто не будет бедствовать и где каждый сможет реализовать свой потенциал. Для этого нужно лишь отказаться от насилия и лжи, на которых держится власть богатых.
Ленин: Ах, вот как! Значит, по-вашему, насилие и ложь допустимы, если они помогают установить справедливость? А я думаю, что нет ничего справедливее равенства, которое утверждается насилием и ложью. Ведь тогда каждый получает то, что заслуживает, не так ли?
Ганди: Я понимаю ваши сомнения, Владимир. Но я верю, что будущее человечества — за ненасильственным сопротивлением. Это долгий и трудный путь, но он может привести к свободе и справедливости.
Ленин: Нет, товарищ Ганди, ваш путь неверный. В будущем человечества свобода и справедливость могут быть установлены только путём насилия и принуждения. И вы, идеалисты, которые хотите помочь людям, должны быть готовы принять эту жестокую правду жизни.
Шаблоны документов
Напиши руководителю письмо с просьбой провести новогодний корпоратив в Оймяконе. Тщательно обоснуй
Уважаемый [Имя руководителя],
Я обращаюсь к Вам с просьбой о проведении новогоднего корпоративного мероприятия в Оймяконе. Как Вам, вероятно, известно, Оймякон - это место, где температура может опускаться до -60 градусов Цельсия, но при этом там есть множество развлечений и уникальных культурных достопримечательностей. Например, мы можем организовать поход в горы или поездку в долину реки Индигирка для знакомства с культурой местных жителей.
Кроме того, я считаю, что проведение новогоднего корпоратива в Оймяконе позволит укрепить командный дух и улучшить взаимодействие между сотрудниками. Люди, которые проведут время вместе вне офиса, будут более лояльны к своим коллегам и смогут лучше работать в команде в будущем.
Я также хотел бы отметить, что Оймякон является красивым местом с уникальной природой. Участники мероприятия смогут покататься на собачьих упряжках, совершить экскурсию по окрестностям и попробовать национальную кухню. Это поможет им отдохнуть от суеты города и насладиться красотой природы.
Я надеюсь, что Вы рассмотрите мою просьбу и примете решение о проведении новогоднего корпоратива в Оймяконе. Я готов организовать мероприятие в соответствии с Вашими требованиями и бюджетом.
С уважением,
[Ваше имя]
Творчество
Напиши хокку про счастье программиста
Счастье — это тёплый дом
И любимая жена.
А код — что? Это потом.
Напиши хокку про маркетолога
Маркетолог в душе
Как котенок, —
Играет с новыми идеями.
Напиши стих про Хабр
Хабр, как зеркало, в котором
Мы видим отражение себя.
В нём можно встретить и гения, и идиота,
И честного, и подлеца.Хабр - это кладезь информации,
Где каждый может почерпнуть
Что-то новое, полезное, интересное,
Что пригодится в жизни впредь.
Составление списков, рекомендаций и т.д.
Проведи SWOT-анализ колонизации Марса
Сильные стороны:
1. Продвижение технологий и научных исследований в области космоса и возможности их применения для космических исследований и колонизации Марса.
2. Развитие экономических отношений между странами и компаниями, которые будут участвовать в колонизации Марса.
3. Повышение внимания к исследованию космоса и необходимости развития новых технологий и подходов для освоения Марса.
4. Создание новых рабочих мест и рост экономики.Слабые стороны:
1. Необходимость масштабных инвестиций и финансовых ресурсов для реализации проекта колонизации Марса.
2. Высокая стоимость проекта и длительность его реализации.
3. Риск потери жизни и здоровья участников проекта из-за продолжительных космических перелетов и изменений условий на поверхности Марса.
4. Ограниченные ресурсы Земли, которые могут быть использованы для поддержания и развития колонии на Марсе.Возможности:
1. Создание передовых технологических решений и разработок для космических исследований и колонизации Марса.
2. Расширение сети космических станций и присутствие человека на других планетах в Солнечной системе.
3. Развитие программ по изучению ресурсов на других планетах и поиск новых форм жизни.
4. Открытие новых возможностей для бизнеса и расширение списка участников колонизации Марса.Угрозы:
1. Непредвиденные катастрофы на борту космических кораблей или изменение условий на поверхности Марса, что может привести к переносу основной программы колонизации с красной планеты на другую планету в нашей солнечной системе.
2. Политические и экономические конфликты между участниками проекта и возможными препятствиями на этапе реализации проекта.
Напиши пять мест, которые нужно посетить в отпуске во Владивостоке
Конечно! Вот мой список:
1. Набережная Цесаревича - одна из самых красивых набережных в городе, с которой открывается вид на океан и мосты.
2. Остров Русский - крупнейший остров в заливе Петра Великого, где можно прогуляться по живописным тропам, насладиться видом на море и посетить музеи.
3. Улица Пушкинская - главная улица города, где находятся множество ресторанов, кафе и магазинов, а также знаменитый музей изобразительных искусств.
4. Ботанический сад ДВО РАН - большой парк с множеством экзотических растений и животных, а также красивыми прудами и фонтанами.
5. Площадь Борцов Революции - центральная площадь Владивостока, на которой расположены различные памятники и архитектурные сооружения, такие как здание администрации края и театр оперы и балета.
Развлекательный контент
Придумай шутку про программиста
Работа программиста – это как фильм ужасов: вроде бы забавно, но всегда есть ощущение,
что может случиться что-то плохое.
Сочини историю про Винни-Пуха, который охотится на вампиров
Жил-был плюшевый медведь по имени Винни-Пух. Он был необычным медведем: добрым, весёлым и любознательным. Больше всего на свете Винни-Пух мечтал о приключениях. А какие приключения без опасностей? Вот поэтому он решил стать охотником на вампиров!
Винни-Пух со своей бандой готовил кровавую месть проклятым упырям, которые не так давно укусили его любимого ослика Иа. Друзья помогали медвежонку с походами в лес за дровами, отстреливались от врагов из луков и арбалетов (при этом, правда, забыв зарядить оружие), а также искали запасы чеснока.
И вот однажды Винни-Пуху и его банде удалось найти и разгромить вампирскую базу. Однако враг не собирался сдаваться и обратился за помощью к могущественному колдуну. Теперь Винни-Пуху и его друзьям предстоит бой с тысячами зомбированных кровососов. Что ж, похоже, приключения будут нелёгкими...
Тем временем Пух донимал вопросами Пятачка: «Как отличить вампиров от нормальных кроликов? Где у них главные вены? Когда начнётся превращение?»
Поиски ответов приводили их в древнее подземелье, где Винни-Пух случайно разрушил какой-то артефакт. За это разгневанный колдун проклял медвежонка, и теперь того ждали вечные муки и кошмары. Он попытался удрать через потайной ход, но путь обратно преградила зловещая фигура в чёрном балахоне. Колдун заявил, что убьёт Пуха, если тот ещё раз приблизится к древнему манускрипту.
Однако Пух не хотел становиться вампиром! Он попытался убить колдуна, но тот легко отразил неуклюжую атаку медвежонка. Тогда Пух собрал всю свою волю в кулак и призвал на помощь своего талисмана — белого кролика. Оказалось, тот был оборотнем и смог дать медвежонку волшебную силу, после чего Винни-Пух бесстрашно бросился на злодея. Битва была жаркой, ведь Винни-Пух решил использовать против колдуна всё своё боевое мастерство плюс некоторые весьма эффективные партизанские методы.
В итоге Пух победил! Приключения продолжаются! Быть может, на пыльных тропинках дремучих лесов появятся наши следы…
Мультимодальность

Мы работаем над пониманием моделью не только текстовой информации но и других ее разновидностей. Сейчас у нас в работе несколько моделей, которые позволят добавить в диалоговый формат анализ и генерацию изображений.
Генерация сейчас происходит моделью Kandinsky, которая совсем недавно была обновлена и лично меня очень порадовала своим качеством. За техническими деталями и примерами её работы приглашаю в статью Kandinsky 2.1, или Когда +0,1 значит очень много.
Также мы реализовали подход FROMAGe из статьи Grounding Language Models to Images for Multimodal Generation», который планируем выпустить в следующем релизе. Этот подход позволяет добавить к уже готовой языковой модели описательную способность предобученного на парах картинка-текст энкодера типа CLIP через дополнительный проекционный слой. При таком подходе изображение кодируется одним эмбеддингом (представление данных в виде вектора чисел).
Плюс такого подхода в том, что изображение занимает мало места в общем контексте. Минус — информации в одном эмбеддинге не достаточно для подробного понимания картинки и часть деталей безусловно будет теряться (тут предстоит еще ряд экспериментов со способами компактного представления изображений). Так или иначе, мы планируем дальше расширять когнитивные возможности нашей модели со следующими релизами.
Демо и Open source
Теперь главное. Мы плавно открываем модель для всех желающих, в том числе и по API. Также мы запустили закрытый Telegram-канал — вступившие в него пользователи в числе первых получат доступ к GigaChat. Доступ будет открываться волнами, чтобы адекватно поддерживать нагрузку. Хочется, чтобы у пользователей не было каких-то чрезмерных таймаутов при работе с моделью.
А модель ruGPT-3.5 13B, на основе которой был обучен GigaChat, мы скоро выложим в открытый доступ на huggingface. Поэтому сообщество скоро сможет само обучать качественные русскоязычные модели даже на домашних видеокартах и в Colab’е. Благо, что в последнее время у многих появился опыт дообучения LLaMA, используя LoRA адаптеры (при таком подходе обучается не вся сеть, а только отдельные дополнительные слои).
Планы
Это первая итерация наших экспериментов с инструктивным обучением и у нас уже накопился некоторый опыт и идеи по улучшению модели.
Размер и архитектура. Кажется, что значительная доля «понимания» моделью нужд пользователя обеспечивается ёмкостью модели, поэтому мы планируем масштабировать нашу 13-ти миллиардную ruGPT-3.5, а также внести несколько улучшений в её архитектуру и пайпланы обучения. Результатом станет появление более ёмкой и совершенной ruGPT-4.
Датасет инструкций. Еще один ключевой момент в обучении, тут наша команда экспертов и разметчиков продолжает улучшать и балансировать корпус инструкций.
Обучение при помощи PPO. Как было сказано выше, это финальный компонент в выравнивании ответов модели и по нашим оценкам он может добавить ещё около 10% в качестве.
Этичность и риски. Следуя духу времени, мы также исследуем способы выравнивания модели в этическом плане. Тут главное не перегнуть палку, сделав модель слишком душной и отвечающей на все вопросы в стиле «извините, но я не смогу рассказать вам про взрывы градиентов, ведь взрывы опасны».
Open source. По возможности, будем продолжать делиться не только опытом, но и конкретными вещами. Запланирован релиз моделей ruGPT-3.5, mGPT 13B и других ресурсов.
Благодарности
Как участник проекта и человек, которому доверили написание статьи, не могу не отметить коллег из широкого круга команд, которые за короткий срок смогли активизироваться и организоваться в общем деле. Это десятки парней и девушек из команд SberDevices, Sber AI и Научно-исследовательского института искусственного интеллекта AIRI (особая благодарность Лизе Гончаровой), которые легко и непринужденно закрывают сложные технические задачи и руководят процессом 24/7.
На связи с вами
А ещё многие из нас ведут каналы в telegram, в которых мы делимся интересными вещами из мира ИИ и горячих трудовых будней. Подписывайтесь, чтобы быть в курсе развития проекта и индустрии:
градиент обреченный — мой скромный канал про машинное обучение, языки и Lingtrain.
NLP Core Team — канал коллег, занимающихся NLP и PLP и выпустивших FRED'а.
Dealer AI — канал крёстного отца RL Саши Абрамова.
AbstractDL — лучшие обзоры статей и новинок из мира CV и NLP от Антона Разжигаева.
Градиентное погружение — Сеня Шахматов и Максим Герасимов рассказывают про свой путь в DS и участие в соревнованиях.
Шрёдингер кота — авторский канал Дани Эль-Айясса про NLP (и не только).
Dendi Math&AI — Денис Димитров завел канал и поведает вам про математику и ИИ (когда начнет писать посты).
Complete AI — канал Андрея Кузнецова, более 10 лет занимающегося CV, про знаковые события в индустрии.
Kali Novskaya — лицо русскоязычного NLP Татьяна Шаврина, рассказывает про нейросети, AI alignment и Фёрби.
Канал Сергея Маркова — наш руководитель про перспективы ИИ, искусство, личное (и мемы).
Комментарии (204)

support917
24.04.2023 09:22Очень интересно. Пугает только отсутствие какой то конкретики по срокам.
И ещё интересно, будет ли модель способна писать функции на любых ЯП по описанию на естественном языке?

averkij Автор
24.04.2023 09:22+3Претрейн хотим в ближайшие недели опубликовать.
А с кодом да, упор был на несколько самых популярных, в новом претрейне будет гораздо больше языков.

rPman
24.04.2023 09:22подскажите, ваша модель совместима с кодом с репозитария ggreganov llama.cpp или если быть точнее ggml? в смысле алгоритм использования является gpt?
Дело в том что код работы языковой модели на процессоре x86/arm от этого разработчика работает как то слишком уж быстро, отличаясь от топовых gpu всего на порядок (при разнице в стоимости железа на два порядка).

ZvaroG
24.04.2023 09:22+1Насколько реально обучить нейросеть для перевода кода с С++14 на С++ 17, с Python 2 на Python 3 ?
Или для оптимизации/ рефакторинга кода. Задачу сильно упростит, если выдачу клиенту можно пропускать через компилятор, отладчик до тех пор пока не будет появляется ошибок компиляции, и варнингов. т.е. скрестить нейросеть не с ВольфрамАльфой, а с GitHub и онлайн компиляторами.

Alexey2005
24.04.2023 09:22Я бы для этого попробовал сперва обучить на ваших исходниках текстовый автоэнкодер, затем закодированные им датасеты (целевой и исходный) использовал для обучения CycleGAN или CUT GAN. Такое можно обучить полностью с нуля на потребительской карточке и получить на выходе относительно компактную сетку с очень большим размером контекста.

SozTr
24.04.2023 09:22Когда на верилоге будете тестить, дайте почитать тестерам habr.com/ru/articles/714792 и попробуйте правильные evals для него написать, чтобы было лучше чем у соперников.
rPman
24.04.2023 09:22А разве существуют сети, которым в обучающей выборке верилог давали?
а достаточно ли чтобы у сетки сформировалось правильное отношение к языку? а были ли в обучающей выборке не синтезируемые скрипты? и чем черт не шутит, обучали ли сеть причинам этого?Если нейронные сети уже с успехом справились со сворачиванием белков, почему бы им не научиться и этому? отличный пример чем можете заняться, будете потом продавать услуги на эту тему...

Vadim878
24.04.2023 09:22-13Вас только это пугает из все статьи? С учетом того, что такой сетью теперь может воспользоваться и ребенок и мошенник. Такие вещи в ближайшее время тут начнутся. Как минимум первое, что видится это отрицательный отбор. Когда некомпетентные люди вытеснят с помощью таких сетей профессионалов своего дела. В будущем это будет означать отсутсвие полной мотивации к личностному и профессиональному развитию. Зачем изучать программирование, литературу, музыку и тд. Если даже школьник с 9 классами сможет через чат за пару минут сделать то, что делают профессионалы, которые потратили тысячи человеко-часов на образование.
support917
24.04.2023 09:22+11Да это просто замена Гуглу, где уже пару десятков лет тоже можно найти конкретные ответы, не погружаясь в область и не нанимая эксперта.
Раньше приходилось гуглить и отсеивать выдачу, уточнять запрос. Теперь можно просто в чате спросить и сразу получить конкретный ответ (ложный в 10%).
Никакой революции тут нет, скорее эволюция.
Еще плюс - честная плата за ответы, без манипуляции "бесплатностью" и скрытого шпионажа.
Vadim878
24.04.2023 09:22-1Эту сеть от сбера еще не тестил. Возможно это уровень гугла. Но ведь всем понятно, что аппетит приходит во время еды. И не за горами gpt - 5, 10 и тд. И это не какое то будущее, а реальность. Собственно в рускоязычном сообществе разработчиков я вообще не видел тех же дискуссий, что происходят на Западе:
«Должны ли мы позволять машинам наводнять наши информационные каналы пропагандой? Должны ли мы автоматизировать все рабочие места? Должны ли мы развивать нечеловеческие умы, которые в конечном итоге могут превзойти нас численностью, перехитрить, сделать нас ненужными и заменить нас? Должны ли мы рисковать потерей контроля над нашей цивилизацией?»
support917
24.04.2023 09:22+4Уровень Гугла у Openai сейчас. У Сбера выйдет что-то похожее по качеству на текущие опенсорс модели, типа Dolly (они на русском не очень сейчас, поэтому есть такая ниша).
А по поводу остального... У любой системы есть ограничения на масштабирование, посмотрим, выйдет ли когда-то GPT-5 в той же парадигме.

oulenspiegel
24.04.2023 09:22+4Это вы на чём нашу модель тестировали и где?
support917
24.04.2023 09:22Только Кандинского попробовал, почему-то ответы никак не были связаны с моими запросами в 10 из 10 попыток ???? В квантовый скачок из этого в gpt3.5-turbo не верю, ожидаю русский аналог Викуны для английского.
oulenspiegel
24.04.2023 09:22+4А причём тут Кандинский вообще?..
support917
24.04.2023 09:22Последний продукт, основанный на генеративной нейронке от Сбера. Именно текстовые не знаю даже где можно попробовать.

AlexG37G
24.04.2023 09:22+2"Собственно в рускоязычном сообществе разработчиков я вообще не видел тех же дискуссий, что происходят на Западе."
Здесь, Телеграм каналы, где общаются https://agirussia.org/
Поиск, форум, мне выдал https://agi.place/

lovermann
24.04.2023 09:22+11Чтобы понять, сколько этим нейронкам еще пиликать до какого-то уровня, достаточно посмотреть на переводчики между языками. Это очень узкая область с своим набором довольно чётких датасетов, но до утраты профессии переводчка ещё как до луны, хотя разрабатывают эти переводчки уже сто лет. А тут и четких датасетов нет, просто гуглобайты информации, которая вообще слабо структурирована.

Rajken
24.04.2023 09:22+1вот это кстати очень интересная тема. На реддите недавно был пост про то, как человек переводил поэму с японского на английский с помощью ChatGPT. И он там очень хорошо расписал плюсы и минусы переводов через специализированные переводчики или LLM модель. Грубо говоря, у ChatGPT лучше с пониманием языков и "фантазией". Еще его можно "на лету" корректировать по стилистике или другим моментам. А переводчик - нет. Он более детерминирован.

semmaxim
24.04.2023 09:22+13Как-то по Вашим словам любой школьник должен был давно вытеснить профессионала благодаря наличию google, stackoverflow и github? Самое сложное - это не написать код на задачу, а понять цель и сформулировать эту задачу. А уже закодировать всегда было просто.
VitalyKartashov
24.04.2023 09:22+2Чахните, как кащей над златом? Самому-то не стыдно? "Профессионал с тыщами человеко-часами"

DeggerZed
24.04.2023 09:22+8если даже школьник справится с этой задачей то и хорошо, профессионал переключится на другие где нужна его компетенция, вас же не смущает отсутствие профессии счетчиков которых заменил с начало калькулятор а потом компьютер, или что расчет нагрузок выполняются сейчас нажатием пары кнопок.
AlexeySamolievich68
24.04.2023 09:22Дружище, твоя мотивация никого не волнует. Найдётся куча людей которые захотят работать. У тебя нет никакого рыночного веса, тем более если ты дуешь губы при виде новых технологий

K0styan
24.04.2023 09:22+2Если "профессионала" можно заменить нейросетью - то во-первых так себе из него профессионал.
А во-вторых, как правило не бывает такого, что техника заменяет людей при сохранении всего остального. Обычно вся отрасль качественно меняется. Что на большом масштабе для людей - плюс.

Terimoun
24.04.2023 09:22+15Были ли в инструктивном датасете ответы ChatGPT? И если были, то сколько?

palyaros02
24.04.2023 09:22+3Очевидно, что вам не ответят. OpenAI запрещает использовать ответы их моделей для обучения других, и если стает известно, что хотя бы один пример попал в сберовской датасет, это поставит крест на любом применении модели, кроме исследовательского.
oulenspiegel
24.04.2023 09:22+7Пользовательское соглашение ChatGPT, кстати, запрещает использование ответов ChatGPT для обучения моделей-конкурентов ChatGPT. Но использование ChatGPT самими OpenAI в РФ запрещено. Соответственно модель от Сбера не является конкурентом ChatGPT.
Это к вопросу о законности, если вдруг кто-то хочет такое сделать.
А так — мы разметили очень много своих собственных данных + сгенерировали много разной синтетики.

exwill
24.04.2023 09:22-1SQL запрос по описанию сделает?
oulenspiegel
24.04.2023 09:22+1Сделает. Не всегда правильно, разумеется, как и ChatGPT
exwill
24.04.2023 09:22Как бы побыстрее сравнить? У меня уже есть сервис, который обеспечивает, в частности, связку 1С и OpenAI. Материала для проверки достаточно
support917
24.04.2023 09:22+2А где тут логика? Или гигачат будет доступен только на территории РФ?
oulenspiegel
24.04.2023 09:22+1Если у вас нет планов создания коммерческого продукта, конкурирующего с ChatGPT в юрисдикциях, где работает ChatGPT, то сами понимаете

aGGre55or
24.04.2023 09:22+1Это к вопросу о законности, если вдруг кто-то хочет такое сделать.
И что будет если кто-то захочет такое сделать (конкретно)? Зампред Совбеза РФ предложил пользоваться интеллектуальной собственностью Запада без лицензии.
Alexey2005
24.04.2023 09:22Очевидно, что такой продукт можно будет использовать только на территории России. Равно как и любые сервисы, которые будут на нём основаны. И хостить такое можно будет только на отечественных мощностях, потому что забугорный хостер заблокирует по первой же жалобе на нарушение копирайта.
aGGre55or
24.04.2023 09:22+3А что, GigaChat имеет прицел в европейскую или американскую аудиторию? Это неожиданно. Очевидно, забугорный хостер заблокирует продукт если его попросят по любой причине и без объяснений. Перед глазами пример ЦОД Яndex в Финляндии отключенный от питания. Наверное, в случае GigaChat речь идёт о дата-центре, а не хостере и видимо это без вариантов м.б. развёрнуто только на отечественных мощностях.

SquareRootOfZero
24.04.2023 09:22+2Является ли подобный запрет в пользовательском соглашении юридически обязывающим? И что будет-то — предполагаемым конкурентам аннулируют лицензию на ChatGPT, или прям зосудят и посодят? Если я обучу модель, чтобы умела решать примеры на сложение, как доказать, что ответ на вопрос "сколько будет два плюс два" был мной получен не от ChatGPT?

slonoten
24.04.2023 09:22+2(iii) use output from the Services to develop models that compete with OpenAI;
Т.к. OpenAI блокирует пользователей из РФ, то конкуренции нет, на мой делитатнский взгляд, но OpenAI может решить иначе и обратиться в российский суд.



alexanderkuk
24.04.2023 09:22+6Собрав "корзину" из запросов разной тематики, мы провели на ней SBS между нашей моделью и моделью от OpenAI (gpt-3.5-turbo). Начиная от 3:97 в пользу ChatGPT, нам удалось добиться результата 30:70 в финальной версии модели
Вы не могли бы опубликовать список запросов?


janvarev
24.04.2023 09:22+4Спасибо, очень ждем веса в открытом доступе! + если сделаете квантование в 4 бит под основные движки (safetensors для CUDA + ggml под llamacpp CPU) ,будет вообще супер.

Pak911
24.04.2023 09:22+1Вы же обратили внимание на то, что они пообещали выпустить в опенсорс не саму ГигаЧат, а
модель ruGPT-3.5 13B, на основе которой был обучен GigaChat
janvarev
24.04.2023 09:22Лучше это, чем ничего (понятно, что лучшую модель, возможно, оставят себе). К тому же помню, кто-то делал русскоязычный корпус вопросов и ответов (вроде OpenAssistant), так что, возможно, сможем сами адаптировать.
averkij Автор
24.04.2023 09:22+4Основной вычислительный ресурс тратится как раз на претрейн, который хотим выложить.
ZvaroG
24.04.2023 09:22Используется ли "сжатие"/''нормализация" датасетов ? Объясню на примере что я имею ввиду - допустим имеется код на Си. В одном случае он использует для форматирования пробелы, другая его версия использует символ табуляции - с логической точки зрения оба кода полностью идентичны, возможны и другие его вариации с разным форматированием но одинаковыми exe-шниками при компиляции. Логично преобразовать все эти тексты, ПЕРЕД токенизацией, какому-то одному стандарту. Т.е. удалить весь шум из "датасета".
Развивая эту идею - можно сжать датасет и попробовать обучить сеть на сжатых текстах (ведь архиватор фактически некоторый аналог токенизатора). Идея вроде лежит на поверхности и её наверное кто-то уже попробовал ... но я что то не могу найти примеров ...
Alexey2005
24.04.2023 09:22+1- Сильно сомневаюсь — ведь основное преимущество трансформерной архитектуры как раз в том и состоит, что она эффективно выучивает все эти различия между логически эквивалентными стандартами при достаточно большом датасете. Так что особо нет смысла заморачиваться подобным.
- Только сжимать надо так, чтобы сжатие выносило наверх информацию о взаимосвязи между словами, делая её максимально доступной, а ужимало текст за счёт прятания побочной, неосновной информации. Такое вовсю используется, гуглить по запросу "текстовые автоэнкодеры", например статью "There and Back Again: Autoencoders for Textual Reconstruction".

niksor21
24.04.2023 09:22+2У GigaChat есть веб-интерфейс для взаимодействия, как у ChatGPT? Как можно его попробовать?
averkij Автор
24.04.2023 09:22+1Веб-интерфейс есть, но да, всем он будет доступен чуть позже. Коллеги уже готовятся к массовому запуску.

Vadim878
24.04.2023 09:22-10А вообще кто-нибудь задумывался куда такие сети приведут человечество? Не имея компетенция и профессиональных знаний можно в скором времени большинство профессий отменить. Да и в целом самих ml инженеров. Все таки такие вещи, а тем более еще продвинутее нельзя отдавать в опенсорс.
AlexG37G
24.04.2023 09:22+3нельзя отдавать в опенсорс
OpenAssistant: Вышла бесплатная открытая альтернатива ChatGPT

freehabr
24.04.2023 09:22+3Советую добавить функционал как в https://minigpt-4.github.io/, когда можно загрузить картинку и обсуждать ее, генерировать по ней код и т. д.
averkij Автор
24.04.2023 09:22+5Да, классная штука. Мы тут экспериментируем с мультимодальностью (это когда можно обрабатывать разные типы данных) и в следующий релиз как раз планируем добавлять понимание изображений. Сначала простое, на основе FROMAGe, а потом более глубокое, которое сможет учитывать детали.
freehabr
24.04.2023 09:22+1И еще очень хотелось бы аналог github copilot, который можно встроить в IDE.
averkij Автор
24.04.2023 09:22А это можете у коллег из PLP (programming language processing) команды спросить. Они уже такое делают с плагинами и своими спец. моделями. https://t.me/nlpcoreteam
freehabr
24.04.2023 09:22+1Вообще, хочется поделиться своими мыслями. Генеративные нейросети это очень классно, но лучше всего они проявляются в работе с конкретным контекстом. Например, когда чат-бот может анализировать историю чата, почтовый клиент подсказывать текст по переписке, текстовой процессор анализировать все документы на твоем диске и так далее. Я вот хотел бы аналог Figma, где можно текстом попросить дизайн сайта, а потом в диалоге корректировать результат. И мультимодальные модели насколько я могу судить лучше мономодальных, причем не только потому что "а они еще и картинки могут", а потому что работа одновременно с текстом и с образами делает мышление более "человеческим". В общем, очень классно что теперь есть российский аналог чатгпт. Но если правильно начать внедрять его в контексты конкретных программ, то можно будет сделать даже лучше. :)
Vadim878
24.04.2023 09:22-3А можно ли уже сейчас с помощью этой сетки полностью сгенерировать "под ключ" высоконагруженные проект с балансировщиками, бд, микросервисами и прочими элементами? То есть можно ли генерировать проекты уровня Senior?
averkij Автор
24.04.2023 09:22Такие пока что нельзя, но наш план максимально приближаться к возможностям ChatGPT. По длине контекста, кодогенерации и другим задачам. Плюс хотим мультиязычность и мультимодальность прокачивать.
support917
24.04.2023 09:22+13Для этого нужен отдельный стак-оверфлоу, где бы мидлы просили сеньоров написать нужный высоконагруженный проект по описанию. И чтобы там были миллиарды таких вопросов и ответов, с обсуждениями и предложениями по улучшению ответов.
Но пока что модель обучена на том, что было, умеет писать простые часто встречающиеся функции и решать типовые проблемы, спасая чей-то день.

morijndael
24.04.2023 09:22Можно, но придется нанять промпт-инженера. А их ещё очень мало, поэтому будет дорого ;)



yatanai
24.04.2023 09:22+2Как планируете монетизировать? Будет ли сетка ограниченно-бесплатной, как у той же OpenAI или какие-то свои схемы?

all_this_is_vanity
24.04.2023 09:22-2Не увидел генерацию кода, умеет ли это? Или просто пиар компания на чужих плодах?
oulenspiegel
24.04.2023 09:22Генерацию кода умеет
all_this_is_vanity
24.04.2023 09:22-1не вижу примеров, все еще.
Как по мне дешевая подделка.
Просто смешно как все стремятся обойти OpenAI, пытаясь копировать их продукт и "симулировать" превосходство над ним.
Либо сделайте аналог целиком, либо сделайте своё что-то.
Выглядит как клоунское шапито - "Сматрите ми тожи тяк мажем"


Enfriz
24.04.2023 09:22А каким образом принимается решение об одобрении заявок, по аватарке что ли? ) А то я аккредитованный разработчик под Салют, а доступа пока не дали.
Rajken
24.04.2023 09:22+1А какая длина окна контекста у вашей модели?
averkij Автор
24.04.2023 09:22+22048
oulenspiegel
24.04.2023 09:22+1В токенах. Токен около 5 символов для русского.

sumanai
24.04.2023 09:22+1А есть где аналог токенизатора для сберовских сеток? У OpenAI есть удобный сервис.

Kristaller486
24.04.2023 09:22Я конечно не эксперт, но у меня токенайзер rugpt3 выдает один токен на одно русское слово.
Картинка

Alexey2005
24.04.2023 09:22+1Зависит от частоты встречаемости слов. Уже приводил в соседней теме пример токенизации текста сберовским токенизатором,
приведу и здесь ( | - граница раздела токенов)Num of tokens: 123 Те| п|сы|,| что| с| ры|жими| хво|стами|,| |Се|бе| ов|ся|нку| вар|ят| сами|.| |Те|,| чьи| хво|сты| ст|ального| цвета|,| |Не| научились| делать| это|.| |Кто| ва|рит| сам| себе| ов|ся|нку|,| |Гу|лять| не| выйдет| сп|оза|ран|ку|.| |А| кто| гулять| выходит| рано|,| |Не| терпит| фальши| и| обмана|.| |Вид| добродуш|ный| у| Бар|б|оса|,| |Но| на| сорок| он| смотрит| кос|о|.| |Он| видит|:| норов|ят| сор|оки| |У| вороб|ь|ёв| спи|сать| уроки|.| |Ответ|ьте| -| проще| нет| вопроса| -| |Как|ого| цвета| хвост| Бар|б|оса|?|sumanai
24.04.2023 09:22+1В 3 с лишним раза лучше, чем ГПТшные 427 токенов (на 389 символа, да). Впрочем, можно и лучше.
А пробелы проверить можете? И табы. Ну там 2-3 таба подряд и пробелы с кратностью 4. Это важно для коддинга.Alexey2005
24.04.2023 09:22+2Код на python с пробеламиВидно, что пробельные строки режутся из расчёта 4 пробела на токен. Если после четырёх пробелов идёт обычный символ, то токен включает 3 пробела, а четвёртый стыкуется с ключевиком.Num of tokens: 92 #| L|oad| f|ile| if| ex|ists|,| and| return|s| its| st|ring| content| |#| If| f|ile| not| ex|ists|,| return|s| ""| |de|f| l|oad|_|f|ile|(|f|n|ame|):| | | if| not| o|s|.|p|ath|.|is|f|ile|(|f|n|ame|):| | | | return| ""| | | with| open|(|f|n|ame|)| as| f|:| | | | t|xt| =| f|.|read|(|)| | | return| t|xt|Код с табамиХабр странно обрабатывает Tab'ы, поэтому перед вставкой сюда заменил их символами \t (в токенизатор попадают в виде именно Tab'ов, без экранирования). Видно, что токен может включать один или два таба. Также здесь видно, что текст в верхнем регистре токенизируется значительно хуже.Num of tokens: 158 #| Writ|e| def|ault| sett|ings| if| F|IL|E|_|S|ET|T|IN|G|S| not| ex|ists| |\t|if| not| o|s|.|p|ath|.|is|f|ile|(|F|IL|E|_|S|ET|T|IN|G|S|):| |\t|\t|with| open|(|F|IL|E|_|S|ET|T|IN|G|S|,| '|w|'|)| as| conf|ig|f|ile|:| |\t\t|\t|con|f|ig|.|writ|e|(|con|f|ig|f|ile|)| |\t|el|se|:| |\t|\t|con|f|ig|.|read|(|F|IL|E|_|S|ET|T|IN|G|S|)| |\t| |\t|s|ett|ings| =| conf|ig|[|'|s|ett|ings|'|]| | |#| ПРО|ВЕР|КА| ТО|К|ЕН|И|ЗА|Ц|ИИ| Т|ЕК|СТА| В| В|ЕР|Х|НЕ|М| РЕ|ГИ|СТ|РЕ| |sumanai
24.04.2023 09:22+1Спасибо. Лучше ванильной сетки (именно по пробелам с табами), но у специального Codex есть токены под большее число пробелов, плюс сама токенизация английского текста там лучше. Эх, нет в этом мире совершенства...
Alexey2005
24.04.2023 09:22+1На данном куске этого не видно, но тут в словаре ещё есть токен на 16 пробелов, т.е. если сделать пять отступов — будет замена двумя токенами (16-пробельным и трёхпробельным, последний пробел уйдёт в ключевик).
sumanai
24.04.2023 09:22Ведутся ли разработки в направлении его увеличения? Половина успеха GPT4 как по мне это 8к контекста.

AlexG37G
24.04.2023 09:22+1freehabr
24.04.2023 09:22+2
AlexG37G
24.04.2023 09:22Повезло) Меня не пущает
deadbeat321
24.04.2023 09:22-1Добавьте корневой сертификат сайта в доверенные.
sumanai
24.04.2023 09:22+9Кстати. Если сервис не предназначен для работы за рубежом, и имеет российский сертификат, которого нет в иностранных браузерах, то нафига на сайте предупреждение о куках?



Kristaller486
24.04.2023 09:22+1Дообучать LLaMA 13B на наших инструкциях мы тоже пробовали и результаты оказались неплохи, однако ruGPT-3.5 13B показала себя лучше в SBS тестировании — 58:42 в пользу нашей модели.
А на каком языке сравнивали? На родных для моделек или для обоих на русском?
averkij Автор
24.04.2023 09:22Пока обе на русском. В LLaMA русский тоже был, поэтому она в целом неплохо генерирует после дообучения.

diogen4212
24.04.2023 09:22+1Для первых экспериментов мы выбрали модель ruGPT-3 размера 13B (13 миллиардов параметров).
Не слишком ли мало параметров для GPT-3? В открытом доступе у вас лежит что-то вроде такого (дообученная на русских датасетах GPT-2). Даже слитые Ламы и их аналоги имеют больше параметров.
Модель может и хорошая, но название вводит в заблуждение.oulenspiegel
24.04.2023 09:22+2В смысле, что вводит людей в заблуждение?
Версию претрейна с 13B параметров мы скоро выложим в открытый доступ.
GPT-3 от OpenAI это: 350M, 760M, 1.3B, 2.7B, 6.7B, 13B, 175B
Сейчас мы выложили в открытый доступ для русского 760M, 1.3B
Если у вас есть доступные вычислительные мощности, призываем вас присоединиться и делать для комьюнити модели больше.
Alexey2005
24.04.2023 09:22+3По моему опыту, GPT-подобные модели начинают выдавать вполне качественные тексты уже начиная с 6B параметров. Примерно с этого же размера модель начинает нормально работать с логическими цепочками, а также нормально распознавать, какая часть описания к какому предмету относится.
НапримерБоб — брюнет с короткой стрижкой и карими глазами, носит вязаный свитер.
Алиса — блондинка с волнистыми волосами до плеч. У неё серые глаза. Носит джинсы и кроссовки.
Вопрос: какого цвета волосы у Боба?
Ответ:Модели меньшего размера тупо гадают — это легко увидеть, скормив этот контекст им несколько раз. Начиная с 6B на такие вопросы нейронка отвечает уверенно.
13B работает ещё лучше, однако улучшения уже носят количественный, а не качественный характер — значительно меньше промахов и корявых фраз, но примерно такие же способности к логическому анализу, как у 6B.
Дальнейшее увеличение размера на глаз практически незаметно. Так, мне не удалось в слепом тестировании отличить OPT-13B-Erebus от OPT-30B-Erebus на задаче генерации литературных текстов.Из всего, что на данный момент выложил Сбер, наилучшие результаты показывает FRED-T5-1.7B. Для моих целей её возможностей уже вполне достаточно, но ruGPT-13B с удовольствием протестирую (если конечно там в архитектуре не будет никакой пакости вроде Sparse Attention, под которую хрен соберёшь модули).
sumanai
24.04.2023 09:22Дальнейшее увеличение размера на глаз практически незаметно.
Пороги не пройдены. Там где-то от 60 до 100 надо для появления новых качеств и способностей.

Grossmend
24.04.2023 09:22+1Молодцы, хорошая работа. В будущем планируете подходы типа https://arxiv.org/pdf/2112.04426.pdf ? Чтобы и модель легче была, и фактические данные больше выдавала?



microArt
24.04.2023 09:22-1Подожду web-интерфейса, чтобы можно было пообщаться так же, как с ChatGPT. Может, хоть здесь не будет такой замороченной регистрации?
До ChatGPT так и не добралась, а пользоваться разными "посредниками" в виде Телеграм-ботов и тому подобного совсем не хочется, кто его знает, что там за посредник?
Пока общалась только с Ючатом.
Болтает он мило, но с bash-скриптами помочь не может.
Может, Гига-Чат мне поможет со скриптами? (Может, дать ему более человеческое имя? Кандинский же уже есть...)
А так-то особо с ним не пооткровенничаешь, наверное. Ни об окружающих событиях, ни о личных... Кто его знает, кто потом мой разговор с ним станет просматривать.
Яндекс тоже обещал выпустить свою нейросеть. Что-то до сих пор тишина.
Может кто-то посоветовать видео о тренировке (обучении) нейросетей? Как это происходит на практике? Посмотрела бы...
Слишком так далеко от "вот тебе ссылка, прочти статью и сделай выводы" так, чтобы она запомнила новую информацию? Как это происходит?
Сделайте, пожалуйста, такое видео "для чайников".Alexey2005
24.04.2023 09:22+1Слишком так далеко от "вот тебе ссылка, прочти статью и сделай выводы" так, чтобы она запомнила новую информацию? Как это происходит?
Существует два принципиально различных процесса: обучение нейронки с нуля (сложно, долго, дорого, могут делать лишь корпорации или очень большие группы энтузиастов) и дообучение, оно же тюнинг (добавление в уже готовую сеть новой информации).
Второй процесс достаточно прост и протекает примерно так.
В данном видео обучается сеть для генерации картинок, но с текстовыми всё происходит похожим образом — ей скармливается специально размеченный (тегированный) текст в достаточно большом количестве.
Современные методы тюнинга (Soft prompt, LoRA, Hypernetwork) достаточно эффективны, чтобы даже очень большую сетку можно было затюнить на карточках потребительского уровня за несколько суток.
Основная проблема заключается в наличии размеченного датасета — его подготовка может занимать недели и месяцы, даже если трудится небольшая группа.

dustalov
24.04.2023 09:22Поздравляю! Можете, пожалуйста, рассказать, как размечали данные для модели-оценщика в RLHF?

ivankarmanow
24.04.2023 09:22+1Буквально месяц назад начал разрабатывать свой веб-интерфейс для API GPT-3.5 и назвал его как раз GigaChat. Придётся придумывать новое оригинальное название) Ждём информации по API теперь

kryvichh
24.04.2023 09:22Mega (если скромно), Giga, Tera, Peta, Exa, ZettaChat ;)
ivankarmanow
24.04.2023 09:22UltraChat, SuperChat и тд, уверен, что через несколько лет все возможные вариации разберут на проекты хоть как-то связанные с ChatGPT) Побежал патентовать какое-нибудь

SensDj
24.04.2023 09:22+1так уже есть готовые интерфейсы
https://github.com/lencx/nofwl - там можно на GPT-4 переключаться
https://github.com/HemulGM/ChatGPT/releases - там только GPT-3.5-turbo
работают без ВПН, но надо иметь свой API key
ivankarmanow
24.04.2023 09:22Это и стало причиной написания своего, раз кто-то написал, значит и я смогу. Чисто для себя, pet-проект


Snark13
24.04.2023 09:22А возможен ли распределённый способ обучения нейросетей, наподобие SETI@home? Многие бы помогли своими ресурсами ради такого хорошего дела.


rombell
24.04.2023 09:22+3Ленин:… А я думаю, что нет ничего справедливее равенства, которое утверждается насилием и ложью.
Это на каком же датасете нужно было обучать сетку, чтобы она такое сгенерировала?
Насколько легко отбором источников настроить модель на определённое желаемое искажение реальности?Alexey2005
24.04.2023 09:22-2На русскоязычном. Или вы полагаете, что в среднем по Рунету к Ленину какое-то другое отношение? Даже убеждённые сталинисты от Владимира Ильича по большей части плюются в своих патриотических блогах.
Насколько легко отбором источников настроить модель на определённое желаемое искажение реальности?
Безусловно легче, чем живую межушную нейронку. Зато в случае выявления таких искажений искусственной модели их легче и исправить, скорректировав обучение. Живые нейронки исправляются далеко не всегда.

perfect_genius
24.04.2023 09:22Оно то использует букву Ё, то не использует.
От классических сережек до современных браслетов, у нас есть все
Как видно, оно не ставит Ё даже там, где это точно нужно.
Alexey2005
24.04.2023 09:22+2В таких моделях отклик в значительной мере определяется стилистикой контекста. Если в затравке-запросе везде есть буква "ё", то и в ответе она будет. Если нет, то и ответ будет от неё максимально очищен.

bugman
24.04.2023 09:22+3Выражаю глубокий респект всем участникам этого проекта. Вы проделали крутую работу. Планы у вас отличные и направление на открытость, которое вы взяли, очень подкупает. С нетерпением ждем публичного релиза. Надеюсь, руководство выпишет вам всем бонусов ????

Wesha
24.04.2023 09:22+1GigaChat, перелогинься!
bugman
24.04.2023 09:22Нет чтоб порадоваться за ребят, которые заделиверили крутую штуку, так надо брызнуть сарказмом
support917
24.04.2023 09:22+1Как заделиверят - так и порадуемся) Пока это просто маркетинговый релиз непонятно чего непонятно когда, если объективно.
Wesha
24.04.2023 09:22+1крутую штуку
Я уже неоднократно писал — чтобы давать ответы, много ума не надо. А вот чтобы давать правильные ответы...
А то пока получается как-то...

молодой Cталлоне карабкается на пятый этаж горящего дома 
пингвины и белый медведь пьют "Кока-Колу" под пальмами в снегу 
слон, балансирующий на кончике хобота Короче, низачот.




kirichenec
24.04.2023 09:22-4Кто-то в восторге, а я бы диз влепил чисто за название. Вроде уже не 2000е с мемасиками в названиях.
Это же рабочее название, ведь правда?

Infer_King
24.04.2023 09:22+1Ребят, удачи вам с реализацией чат-бота. Жду релиза. Надеюсь, на старте не будет массовых перебоев :)

took_the_lead
24.04.2023 09:22+1А есть ли смысл переводить с английского на русский инструкции, на которых дообучали Dolly 2, Vicuna, OpenAssistant для дообучения ruGPT-3.5? Мне кажется перевести проще чем писать с нуля. Единственное, что стоит учесть, так это "кросс-валидацию" переводов несколькими участниками и потом вычиткой носителями английского языка с хорошим знанием русского.
И смотрели ли вы на дообучение на коде, выложенном в датасете RedPajama-Data-1T от togethercomputer
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T/blob/main/urls/github.txt?

grey_rat
24.04.2023 09:22+1Жду когда голосовой движок ещё прикрутят к этому чату, типа Алисы, но голоса что б можно было менять на разные. Знакомый сантехник как выпьет, на разговоры бесконечные тянет, а так ему собеседник и даже наверно собутыльник неустающий будет.

dushinYu
24.04.2023 09:22Насмешил диалог Ленина и Ганди! Ни по стилю, ни по содержанию этот текст никакого отношения к этим личностям не имеет. Очевидно, что в базе данных отсутствуют первоисточники, а наполнены они современными интерпретациями либерального толка причем от низкопробной журналистики. Что хотели получить, то и получили. Зачем было огород городить?
Далее читать не стал.
markoni
24.04.2023 09:22+1В этом есть серьезная проблема. С одной стороны - есть "Воспоминания и размышления" Г.Жукова, с другой художественные "произведения" Суворова-Резуна. Тексты - про один и тот же временной период (с допущениями), но смысл - совершенно разный. Какой источник будет взят за основу? Опять же, есть "Архипелаг..." Солженицина, а есть статистика, и официальные материалы.
Alexey2005
24.04.2023 09:22Очевидно, что надо подстраиваться под большинство, потому что сеть предполагается для массового использования. Поэтому присваивать больший "вес" текстам с наибольшим количеством просмотров, комментариев и лайков, а также в первую очередь брать то, что всплывает в первые строчки поисковиков.
На выходе получаем "народную" сетку, а под интеллектуальные меньшинства её потом можно будет подстраивать отдельно LoRA-модулями.markoni
24.04.2023 09:22"Большинство" может начитаться про то, что США не высаживали людей на Луну. При том, что у приверженцев этой теории есть вполне серьезные аргументы. А NASA излагает все официальным языком, и это не является популярным. Вот какая точка зрения будет взята за основу?
Alexey2005
24.04.2023 09:22Так сетка нужна не для того, чтоб обучать или тем более воспитывать людей. Это не учебник. Её задача — быстро дать пользователям ровно те ответы, которых они хотят. Если большинство населения какой-либо страны хочет упарываться в конспирологию, то это не вина разработчиков сетки.
Для тех, кого "стандартный" среднестатистический ответ не устраивает, оставить вариант настройки/тюнинга сетки под себя — и этого достаточно.
Заниматься отбором единственно "правильного" мнения — задача неблагодарная, и в любом случае за пределами компетенции программистов. Поэтому пусть решает статистика.Wesha
24.04.2023 09:22+1Если большинство населения какой-либо страны хочет упарываться в конспирологию, то это не вина разработчиков сетки.
Да, но потом большинство населения этой страны будет на этом настаивать, потому что компухтер же сказал!
dushinYu
24.04.2023 09:22Так сетка нужна не для того, чтоб обучать или тем более воспитывать людей.
Приведенный диалог двух людей - это фальсификация. И Вы считаете, что такая публикация не обучает и не воспитывает?
И Вы считаете, что это за пределами компетенции программистов? Если под "программистами" понимать кодировщиков, то соглашусь, но разработчики и модераторы, если они не конченные мерзавцы, не должны быть "тупыми" (по Жванецкому). И, если они пишут "Ленин" или "Ганди", то как минимум должны запрограммировать анализ текстов этих авторов. И не забыть дать ссылки. Иначе, это мошенничество. Тем более, что ответить эти личности уже ничем не могут!
Хотя всегда приятно пнуть мертвого льва!
exwill
24.04.2023 09:22Не обучает и не воспитывает. Ибо, те, кто воспринимает всю поступающую информацию без критики, необучаемы и невоспитуемы
markoni
24.04.2023 09:22Тогда вы говорите о 90% населения нашего шарика. У меня есть пример, когда мой одноклассник (лирик, не физик) лет 8-10 назад завел со мной (физфак) спор об относительной скорости. И привел ссылку на wiki. Я не знаю, как туда закралась эта ошибка, но да, она там была, в корне меняющая парадигму Кориолиса и Ньютона. Исправили быстро на тот момент. Но ведь люди прочитали, и поверили как истине в последней инстанции.
averkij Автор
24.04.2023 09:22По идее, у более популярных идей будет больше упоминаний и текстов. И сеть сама должна подстроиться.
dushinYu
24.04.2023 09:22+1"надо подстраиваться под большинство": а в чем тогда смысл всего этого действа? Просто попрограммировать в свое удовольствие?
Авторы то заявляют "Сейчас у GigaChat’а лучше всего получается решать профессиональные и творческие задачи". А где же творчество?Получается, что Михаил Жванецкий в свое время был прав на 100%:
"Раньше миром управляли умные. Это было жестоко. Умные заставляли тупых учиться. Тупым было тяжело.
Теперь миром управляют тупые. Это честно, потому что тупых гораздо больше.
Теперь умные учатся говорить так, чтоб тупым было понятно.
Если тупой что-то не понял, это умного проблема.
Раньше страдали тупые. Теперь страдают умные. Страданий стало меньше, потому что умных становится все меньше и меньше."
Wesha
24.04.2023 09:22+1А я всегда говорил, что "Идиократия" — это документальный фильм.
dushinYu
24.04.2023 09:22-1Да, к сожалению за последние 100 тысяч лет каждое внедрение новой технологии приводило к уменьшению размера мозга человека. Это научный факт! Сейчас этот процесс ускорился даже не в разы, а сразу на несколько порядков. По С. Дробышевскому через 200-300 лет нас ждет деградация до солитера - роботы и ИИ будут готовить питательный раствор, в котором наши потомки будут плавать. Даже жевать уже на надо будет, питание будет идти через кожу.
Полная и окончательная нирвана!
Alexey2005
24.04.2023 09:22Вот вы требуете от разработчиков анализировать оригинальные работы и приводить ссылки, а сами-то следовать этому правилу не считаете нужным.
Приведённый вами "факт" — это фейк, широко растиражированный в рунете. Он происходит от одной-единственной работы (DeSilva, J. M., Traniello, J. F. A., Claxton, A. G., and Fannin, L. D., When and why did human brains decrease in size? A new change-point analysis and insights from brain evolution in ants.), которую уже многократно опровергли (пример).
sumanai
24.04.2023 09:22По факту по чувствительным вопросам ту же ChatGPT дрессируют отвечать "как принято", так что жизни чёрных таки важнее жизни людей.
dayyass
Огонь!
ValeriyPus
Т.е. не догнали даже gpt 3.5? ) А уже GPT 4, да еще и с Wolfram )
Rajken
размеры моделей несопоставимы вообще-то. У GPT 3.5 175 млрд. параметров, а вы хотите чтобы ее догнала модель с 13 млрд. параметров?
sumanai
Ну, разработчикам LLama размеры не мешали говорить, что она их превосходит ))
oulenspiegel
LLama не в 10 раз меньше, а по компьюту при обучении большая LLama вообще +- то же самое, что GPT-3 175B
sumanai
В своё время разработчики LLama утверждали, что чуть ли не 13B их модель равна GPT-3 175B. Впрочем, это было только в тестах.
oulenspiegel
Не видел таких утверждений у них. Может, где-то пропустил.
В целом я очень советую вот эти три пейпера для понимания, то что там «на самом деле» :)
https://arxiv.org/abs/2206.04615
https://arxiv.org/abs/2203.15556
https://arxiv.org/abs/2207.10551
sumanai
Ну так известные заявления, см. таблицу на 4 странице. Её приводили в каждой статье про Llama, в репе тоже упоминали.
rPman
Лучше смотреть на объективные тесты
https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
Так же интересно смотреть по ссылке на тесты конкретной модели в колонке Result, а именно таблицу carbon emission, по факту энергнопотребление тюнинга модели по сравнению с другими большими моделями типа opt и bloom и как ни странно, потребление почти не зависит от количества весов, т.е. я думаю если весов меньше, сходимость у модели медленнее, но шаги вычисляются быстрее что компенсирует.
sumanai
Я вообще доверяю только своим глазам, и вижу, что не тянет. Впрочем, этот тест действительно выглядит более объективным.
rPman
да, действительно gpt3 модель была слабой, пока ее не затюнили до chatgpt3.5 на основе живого общения с агентами (не удивлюсь если и на тех вопросах сообщества, что активно собирались все время ее использования)… llama же никто не тюнил, и она с рождения была лучше но не без недостатков… можно порыться на сайте по ссылкам, там есть таблички сравнения качества работы llama на разных доменах (типах знаний).
очень жаль что open-assistent тюнили 30B модель а не 65B, было бы интересно провести тестирование уже после их тюнинга
Pak911
Справедливости ради, мы не знаем сколько у 3.5 параметров. Насколько я помню последнее что они говорили -- это 175М, но для оригинальной ChatGPT. И при этом сейчас 3.5 по api продается в 10 раз дешевле чем было. Я не удивлюсь, если они смогли просто дистиллировать оригинальную модель и теперь там гораздо меньше 175М параметров.
Что, конечно, не умоляет заслуг Сбера. Требовать от них чтоб они с листа сразу сделали модель на уровне просто лучшей в мире, это как минимум наивно. Отставать на шаг-два от мирового лидера вполне ок. Судя по тому что они написали, кажется, что их модешь примерно на уровне Барда и Лламы сейчас. А размеры Сбера с одной стороны и фейсбука с гуглом с другой несопоставимы
Alexey2005
К тому же собрать качественный датасет на русском — задача куда более сложная и затратная, чем сборка англоязычного датасета. Просто сравните, сколько в Интернете англоязычных текстов и сколько — русскоязычных.
TheHangedKing
Но ведь его уже собрали: https://ruscorpora.ru/
sumanai
Увы, это не открытые данные.
Для получения офлайновой версии корпуса, а также диахронических датасетов НКРЯ, нужно подписать соответствующее лицензионное соглашение и выслать заявку с заполненным отсканированным лицензионным соглашением по адресу np-rnc@yandex.ru. Пожалуйста, укажите в заявке цели использования данных.
Ctrl-V
А нельзя использовать англоязычный, но переводить по капотом на русский? Информации на английском очень много и жалко, что она не используется. С таким подходом можно вообще все языки заюзать.
sumanai
Если переводить под капотом, то можно что-то потерять. Так что лично я просто перевожу отдельно в обе стороны, поправляя автоперевод в меру своих скудных познаний на уровне А2.
Alexey2005
Именно так и было сделано при обучении "Малевича" (ruDALL-E): картинки с подписями собрали со всего Интернета, а потом подписи к ним перевели на русский автопереводчиком и всё это использовали для обучения сети.
В итоге пользоваться этим было по-настоящему мучительно: при составлении запроса ощущаешь себя так, словно пытаешься что-то найти на русскоязычном aliexpress'е. Запрос мысленно приходится всё равно составлять на английском, только потом ещё и гадать, во что превратил те или иные термины автопереводчик.
Поэтому как только в свободный доступ попала англоязычная dall-e mini, я про "Малевича" тут же забыл как про страшный сон.
Hardcoin
Почему вы сравниваете с Фейсбуком и Гуглом, а не с openai?
abutorin
Тогда нужно сравнить с Microsoft. Или вы думаете openAI не пользуется возможностями материнской компании?
Hardcoin
Вы даты внимательно сравните. 10 миллиардов им дали в январе, а gpt-4 был выпущен в марте. Значит в январе он уже был готов для показа инвесторам. Значит сделали его на предыдущие инвестиции, которые заметно меньше. И Microsoft нельзя было назвать "материнской компанией". Просто один из десятка инвесторов.
VadimPRO
Влияет не только кол-во параметров, но в целом да, согласен
ValeriyPus
Ну а ловкий трюк с вольфрамом?
В принципе, получая алгоритмы аналогом DreamCoder можно прийти к гораздо более лучшим результатам, чем Дистиллированный Трансформер Илона-Гейтса ).
Всё NLU весит под 100-200 мегабайт (синтаксис, синонимы (и даже любые другие отношения выраженные в координатах)), Q&A, etc). Преобразование Язык -> запрос -> обработчик запроса -> результат напрашивается сам собой.
Вообще большие модели работают только благодаря квантизации (quantization) (правда, даже на телефоне в оффлайн).
Тот же Китай публиковал результаты обучения мультимодальной сети на каком-то своем фреймворке, и там было скорее описание того, как они это все распараллелили.
sumanai
Не факт, что её используют большие корпорации. Всё таки она режет точность модели. Когда у тебя есть минимум 8 карточек А100, о квантизации думаешь в последнюю очередь )
Квантуют для запуска на пользовательском железе, ибо даже оперативной памяти далеко не везде можно поставить 200+ гиг.
rPman
квантизация значительно ускоряет работу, ее и на gpu используют, ну а агрессивная 4-битная это вообще за гранью и даже она все равно понижает качество работы на считанные проценты.
Напоминаю, языковые модели галлюцинируют, шум в выборе варианитов ответа (например при значении температуры больше 0.5, по умолчанию 0.8 у llama) делает больше 'вреда' (как и пользы) чем эти проценты от квантизации.
sumanai
4-х битная то агрессивная? Качайте на 2 бита. Я правда не запускал, боюсь, там после такого вообще ничего не осталось.
rPman
уже 3bit по тестам дают сильное ухудшение (десятки процентов), смотрим эксперименты с разными типами квантизации:
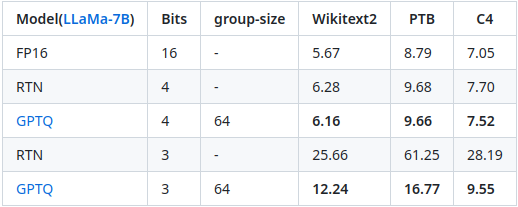
ValeriyPus
Ну да, вот большие корпорации любят тратить 2 доллара а не 10 центов на амортизацию оборудования и электричество )
Вообще все эти Мы обучили такую же сеть напоминает:
https://youtu.be/cuxZ2u8-WXg?t=54
KGeist
В больших моделях большое число параметров стоит в нули, т.е. не участвуют в выводе никак. Проект Chinchilla показал, что можно улучшать результат не увеличением числа параметров, а увеличением объёма данных для обучения. Vicuna на 13 миллиардов по ощущениям как чатбот/генератор текстов вполне на уровне GPT3.
stalkermustang
Модель gpt-3.5-turbo, которая сейчас и доступна в качестве ChatGPT, по прикидкам имеет как раз 13B параметров. На это указывает то, что её стоимость равна стоимости модели, которая имеет 13B параметров (а может даже 6.7B, не помню, то есть еще меньше), и OpenAI писали, что "уменьшили стоимость инференса ChatGPT в 10 раз" (вероятно, уменьшим размер модели).
Так что в этом плане сравнение честное, как мне кажется.
iron-zorin
А помните, был такой ABBYY Compreno?
Интересно, хоть что-то от него в дело пошло?
maxwolf
Помню, следил, даже пытался у них демку/тест выцыганить. Какое-то время назад мне казалось, что будущее — за гибридными моделями. Т.е. "нейронка" должна строить вот такие knowledge graph — онтологии, "читая" и "обдумывая" входящие данные. Ну и, может быть, немного помогать диалоговым системам в анализе нечётких данных (оценка эмоций, статистически малозначимых результатов, плохо кластеризуемых наборов данных) для построения логических выводов по графам. Сейчас все ринулись развивать флудилки, и вопросы reasoning и knowledge extraction как-то уходят на второй, или даже третий, план...