
Хочу показать, как создать мультиязычный параллельный корпус и книги при помощи пет-проекта, которым я занимаюсь несколько лет.
Для примера возьмем 10 редакций "Мастера и Маргариты" Михаила Булгакова (ru, uk, by, en, fr, it, es, de, hu, zh). Сначала выровняем девять переводов с оригиналом, а затем выровняем все вместе. Получим параллельный корпус на 10 языках и много красивых книг.
Приложение
Lingtrain Alignment Studio — это веб-приложение, основная логика которого выполняется при помощи библиотеки lingtrain-aligner. Выравнивать можно прямиком из кода на python (пример будет ниже), либо через приложение. В приложении будет удобней разрешать конфликты и там есть редактор, позволяющий корректировать получающийся корпус плюс дополнительные опции по верстке. Код у проекта открытый, можно посмотреть как все работает внутри.
Механизм выравнивания происходит при помощи эмбеддингов мультиязычных языковых моделей и логики по их сравнению. Это тема для отдельного разговора, я лишь напомню, что эмбеддингами в машинном обучении называют сжатые векторные представления данных, несущие в себе информацию об этих данных. В нашем случае это тексты, а информация, сохраняемая в эмбеддингах, несет в себе смысл этих текстов. Можно математически измерять близость текстов по смыслу просто меряя расстояние между соответствующими векторами. В библиотеке поддерживаются модели LaBSE (100+ языков) и sentence-transformers (50+ языков).
Основная проблема выравнивания состоит в том, что в текстах разное количество предложений. Это связано как со стилем конкретного переводчика, так и с особенностями конкретного языка. Например, длинное сложное предложение с прямой речью на русском языке при переводе на китайский скорее всего будет разбито на 3-4 предложения покороче. Кроме того, переводчик легко может добавить что-нибудь от себя, привнося в текст новую информацию, может и что-то выкинуть. Один из текстов может быть купирован и тогда в нем образуется лакуна, отсутствующая в другой редакции. Все это нужно учитывать при выравнивании.
Тексты
Сначала наши тексты необходимо подготовить. Я буду показывать на примере "Мастера", вы можете взять свои тексты. Главное, чтобы в них содержалась одна и та же информация, например, оригинал художественного произведения и его перевод. Сохраним тексты в отдельные txt файлы и назовем их master_ru.txt, master_en.txt, master_de.txt и так далее.
В сырых текстах может содержаться лишняя для нас информация — номера страниц, сноски и примечания, содержание, что-нибудь про конкретное издание в начале или конце текста. Это удаляем.
Имеем следующие тексты:
Мастер и Маргарита
М. А. Булгаков.ЧАСТЬ ПЕРВАЯ
Глава 1
Никогда не разговаривайте с неизвестными
Однажды весною, в час небывало жаркого заката, в Москве, на Патриарших прудах, появились два гражданина. Первый из них, одетый в летнюю серенькую пару, был маленького роста, упитан, лыс, свою приличную шляпу пирожком нес в руке, а на хорошо выбритом лице его помещались сверхъестественных размеров очки в черной роговой оправе. Второй – плечистый, рыжеватый, вихрастый молодой человек в заломленной на затылок клетчатой кепке – был в ковбойке, жеваных белых брюках и в черных тапочках.
...
The Master and Margarita
Mikhail BulgakovBOOK ONE
CHAPTER 1
Never Talk with Strangers
At the hour of the hot spring sunset two citizens appeared at the Patriarch's Ponds.
One of them, approximately forty years old, dressed in a grey summer suit, was short, dark-haired, plump, bald, and carried his respectable fedora hat in his hand. His neatly shaven face was adorned with black horn-rimmed glasses of a supernatural size.
...
Помимо основного повествования в текстах содержится метаинформация, — это название книги и имя автора, номера глав и частей и подобные вещи. Метаинформация не является непосредственно частью текста, но это полезная вещь и мы хотим сохранить ее с учетом координат в массиве остальных предложений.
Для этого пометим ее специальной разметкой.
Метка |
Значение |
Пример |
|---|---|---|
%%%%%author. |
Автор |
Лю Ци Синь%%%%%author. |
%%%%%title. |
Название |
Задача трёх тел%%%%%title. |
%%%%%qtext. |
Цитата |
Тот, кто спасает одну жизнь, спасает весь мир.%%%%%qtext. |
%%%%%qname. |
Подпись под цитатой |
Народная мудрость%%%%%qname. |
%%%%%h1. %%%%%h2. %%%%%h3. %%%%%h4. %%%%%h5. |
Заголовоки различного размера |
Глава 1%%%%%h2. |
Теги надо проставить в конце строк. Теперь наши тексты выглядят так:
Мастер и Маргарита%%%%%title.
М. А. Булгаков%%%%%author.ЧАСТЬ ПЕРВАЯ%%%%%h1.
Глава 1%%%%%h2.
Никогда не разговаривайте с неизвестными%%%%%h2.
Однажды весною, в час небывало жаркого заката, в Москве, на Патриарших прудах, появились два гражданина. Первый из них, одетый в летнюю серенькую пару, был маленького роста, упитан, лыс, свою приличную шляпу пирожком нес в руке, а на хорошо выбритом лице его помещались сверхъестественных размеров очки в черной роговой оправе. Второй – плечистый, рыжеватый, вихрастый молодой человек в заломленной на затылок клетчатой кепке – был в ковбойке, жеваных белых брюках и в черных тапочках.
The Master and Margarita%%%%%title.
Mikhail Bulgakov%%%%%author.BOOK ONE%%%%%h1.
CHAPTER 1%%%%%h2.
Never Talk with Strangers%%%%%h2.
At the hour of the hot spring sunset two citizens appeared at the Patriarch's Ponds.
One of them, approximately forty years old, dressed in a grey summer suit, was short, dark-haired, plump, bald, and carried his respectable fedora hat in his hand. His neatly shaven face was adorned with black horn-rimmed glasses of a supernatural size.
Полные версии всех размеченных текстов можно найти здесь.
Выравнивание

Скрипты на питоне
Сначала покажу вам как можно выровнять тексты на python. Плюс такого подхода в том, что это можно делать в Colab'е (интерактивная среда от Google, дающая бесплатный доступ к видеокартам) с использованием GPU, это ускоряет процесс первичного выравнивания в разы, если у вас нет видеокарты на локальном компьютере. Однако для длинных текстов может понадобиться контролировать процесс выравнивания и менять параметры по ходу, а это удобней делать через веб-интерфейс. Подходы можно совместить, так как в приложении теперь поддерживается загрузка выравнивания (хранение реализовано в виде sqlite базы данных).
Вот рабочий Colab-блокнот, его можно менять, вставлять свои тексты и экспортировать результат в разные форматы.
Давайте разберем как это работает. Сначала устанавливаем библиотеку:
pip install lingtrain-aligner==0.8.7Импортируем компоненты:
from lingtrain_aligner import (
preprocessor,
splitter,
aligner,
resolver,
reader,
helper,
vis_helper,
metrics,
)Далее прочитаем наши текстовые файлы:
text1_input = "harper_lee_ru.txt"
text2_input = "harper_lee_en.txt"
with open(text1_input, "r", encoding="utf8") as input1:
text1 = input1.readlines()
with open(text2_input, "r", encoding="utf8") as input2:
text2 = input2.readlines()Определим также путь до SQLite базы данных (это хранилище со всей необходимой для выравнивания информацией) и параметрами языка lang_from и lang_to. Эти параметры очень важны, так как они влияют на правила разбиения строк на предложения:
db_path = "db/book.db"
lang_from = "ru"
lang_to = "en"
models = ["sentence_transformer_multilingual", "sentence_transformer_multilingual_labse"]
model_name = models[0]Если нужного языка в списке пока нет, но он поддерживаются моделями, то используйте код xx, тогда к тексту будут применены стандартные правила фильтрации и разбиения на предложения.
Сохраним структуру абзацев и разобъем на строки:
text1_prepared = preprocessor.mark_paragraphs(text1)
text2_prepared = preprocessor.mark_paragraphs(text2)
splitted_from = splitter.split_by_sentences_wrapper(text1_prepared , lang_from)
splitted_to = splitter.split_by_sentences_wrapper(text2_prepared , lang_to)Создадим нашу базу данных и наполним ее данными, взятыми из нашей разметки. В базе хранятся строки с координатами абзацев и глав, метаданные, маппинг выровненных строк на их изначальный состав и местоположение.
aligner.fill_db(db_path, splitted_from, splitted_to)Теперь можно выровнять документы. Процесс выравнивания идет кусками с размером batch_size, вокруг каждого куска берется дополнительное количество строк размера window, чтобы гарантированно захватить необходимые строки. Модель берет заданное количество строк первого текста и подбирает в соответствующем фрагменте второго текста лучшие соответствия, используя векторные представления. На этом основывается первоначальное выравнивание. Для того, чтобы выровнять первые четыреста строк, выполним следующую команду.
batch_ids = [0,1,2,3]
aligner.align_db(db_path, \
model_name, \
batch_size=200, \
window=30, \
batch_ids=batch_ids, \
save_pic=False,
embed_batch_size=50, \
normalize_embeddings=True, \
show_progress_bar=True
)Визуализация выравнивания
На то, что получилось можно посмотреть! Это возможно благодаря тому, что в базе мы храним изначальные номера строк для выровненного корпуса. Воспользуемся модулем vis_helper. Так как строк у нас 400, то нарисуем все на одной картинке, задав параметр batch_size=400. Если указать, например, batch_size=50, то получим 4 картинки поменьше.
vis_helper.visualize_alignment_by_db(db_path, output_path="alignment_vis.png", \
lang_name_from=lang_from, \
lang_name_to=lang_to, \
batch_size=400, \
size=(800,800), \
plt_show=True)
Посмотрим на картинку. Выравнивание предсказуемо идет от начала к концу, но есть конфликты. Основных причин две:
-
У модели было слишком много удачных вариантов.
Так случается, если строка короткая. Например, в тексте идет диалог, фразы в нем односложные, используются одни и те же имена.
-
У модели было слишком мало вариантов и правильного среди них нет.
У текстов разные тенденции к разделению на предложения. Один постепенно "убегает из окна" и мы не ищем правильные варианты там, где надо. Окно можно увеличить, но не слишком сильно, потому что у модели становится больше вариантов для ошибок. Нужен компромисс.
Хорошим решением мне видится регрессия на координаты строк при выравнивании батча и сдвиг окна на конец потока при выравнивании следующего. Минусом тут будет потеря возможности распараллеливания обсчета батчей, так как они станут зависимы друг от друга.
Сейчас окно сдвигается на основе отношения длин текстов. Батчи не зависимы, но есть другая проблема, — если один из текстов это только часть книги, а второй текст полный, то окно быстро убежит от правильного потока выравнивания.
Решаем конфликты
Давайте теперь разбираться с шероховатостями. Глядя на картинку, мы видим, что есть непрерывные цепочки, есть разрывы и есть выбросы. Например, для предложений 10,11,12 модель подобрала предложения 15,16,17 из второго текста. Эта цепочка хорошая. Все, что находится между цепочками назовем конфликтом. При таком определении конфликта можно измерить его размер и подобрать стратегию разрешения. Логика по решению проблем находится в модуле resolver.
Для начала давайте посмотрим на все найденные конфликты:
conflicts_to_solve, rest = resolver.get_all_conflicts(db_path, min_chain_length=2, max_conflicts_len=6)conflicts to solve: 42
total conflicts: 45При этом в переменную conflicts_to_solve попадут конфликты, которые соответствуют заданным параметрам поиска, а в переменную rest остальные.
Выведем на экран статистику:
resolver.get_statistics(conflicts_to_solve)
resolver.get_statistics(rest)('2:3', 25)
('3:3', 5)
('3:6', 2)
('3:5', 2)
('2:4', 2)
('3:4', 2)
('2:1', 1)
('3:2', 1)
('5:5', 1)
('4:5', 1)
('5:8', 1)
('5:9', 1)Видим, что чаще всего попадаются конфликты размера 2:3, это означает, что переводчик на английский часто разбивал одно предложение на два.
Посмотреть на конфликт можно следующей командой:
resolver.show_conflict(db_path, conflicts_to_solve[10])105 – Браво! – вскричал иностранец, – браво!
106 Вы полностью повторили мысль беспокойного старика Иммануила по этому поводу.
122 'Bravo!' cried the foreigner.
123 'Bravo!
124 You have perfectly repeated restless old Immanuel's thought in this regard.Видим, что строки 122 и 123 нужно бы сложить в одну, тогда правильное сопоставление выглядело бы как [105]-[122,123] и [106]-[124]. Как же научить этому программу? Так как она уже умеет выбирать лучший из предоставленных вариантов, то давайте ей их и предоставим. Конфликты у нас не очень большие, поэтому мы будем брать все возможные варианты разрешения конфликта, считать для них коэффициент похожести, суммировать и брать лучший. В данном случае это будет два варианта:
[105]-[122] // [106]-[123,124]
[105]-[122,123] // [106]-[124]Что до стратегии выравнивания, то на данный момент лучше всего себя проявила такая, — сначала ищем конфликты при минимальной длине хорошей цепочки 2 (при таком параметре конфликтов найдется больше всего) и максимальной длиной конфликта не больше 6. Разрешаем все найденные конфликты, при этом большие конфликты становятся меньше так мы их частично разрешили. Затем увеличиваем оба параметра, ищем и снова разрешаем, добивая остатки.
Выглядит это так:
steps = 3
batch_id = -1 #выровнять все доступные батчи
for i in range(steps):
conflicts, rest = resolver.get_all_conflicts(db_path, min_chain_length=2+i, max_conflicts_len=6*(i+1), batch_id=batch_id)
resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False)
vis_helper.visualize_alignment_by_db(db_path, output_path="img_test1.png", batch_size=400, size=(800,800), plt_show=True)
if len(rest) == 0:
breakРезультат после первого шага:

После второго:

Теперь у нас выравнивание, которое хранится в файле master_en_ru.db. Похожим образом выравниванием остальные книги и получаем все оставшиеся выравнивания (русский и другой язык).
На этом этапе вы уже можете сверстать книгу с подсветкой соответствующих предложений.

В блокноте есть соответствующий код, примеры различной стилизации подсветки (можно менять ее по своему желанию) и экспорт в html страничку.
Давайте посмотрим, как можно сделать то же самое при помощи веб приложения.
Веб-приложение
Для запуска приложения я оформил несколько версий Docker образов. Текущая версия 8.4. Самый большой вариант работает на модели LaBSE от Google (поддерживает более 100 языков с хорошим качеством), средняя — на модели от sentence-transformers (50 языков, такое же хорошее качество), маленькая — на модели rubert-tiny-v2 от Давида Дале (поддерживает только русский и английский языки, зато быстро работает на CPU без всяких видеокарт, если делаете русско-английскую книжку или корпус, то выбирайте ее).
Бета-версия
На этой же модели я запустил бета-версию приложения по адресу beta.lingtra.in. Сервер там не очень мощный, но можно выравнивать русско-английские тексты и экспортировать их разные форматы (html, tmx, lt (формат lingtrain) и т.д.).
Docker
Вот список образов:
lingtrain/studio:v8.4
lingtrain/studio:v8.4-labse
lingtrain/studio:v8.4-tiny
Необходимо, чтобы в вашей системе был установлен Docker. Затем нужно скачать образ командой:
docker pull lingtain/studio:v8.4Создать папки, в которых будет храниться ваш прогресс по выравниванию. Нужны две папки, для данных и для изображений (визуализации выравнивания).
Затем запустить приложение. В данном случаем используем папки E:\data и E:\img, пример для Windows. В Linux все запускается аналогично.
docker run -v E:\data:/app/data -v E:\img:/app/static/img -p 80:80 lingtrain/studio:v8.4Приложение запустится на 80-м порту и его можно будет открыть в браузере по адресу localhost.
Более подробно про интерфейс приложения я писал в этой статье и записывал видео с примером его использования.
Новый функционал
В последней версии (8.4) я добавил экспорт и импорт выравнивания (оно хранится в формате sqlite). Так что можно быстро выравнять ваши тексты в Colab'е, а затем загрузить ваше выравнивание в бета-версию Lingtrain и там его подредактировать.
Помимо этого теперь можно выравнивать ваши тексты на основе его машинного перевода. Это актуально для малоресурсных языков типа башкирского или санскрита, так как модели на них не обучались (дообучение моделей — это отдельная история). Недавно составлял по этому поводу инструкцию для активистов санскрита, обратитесь, кому интересно.
Продолжим
Войдем в приложение под любым именем, сейчас оно необходимо только для разграничения рабочего пространства.

Выберем языки (английский и русский). Затем загрузим наши размеченные тексты.

Метки автоматически разделят тексты и метаинформацию друг от друга. В разделе Marks нужно убедиться, что в текстах одинаковый набор меток.

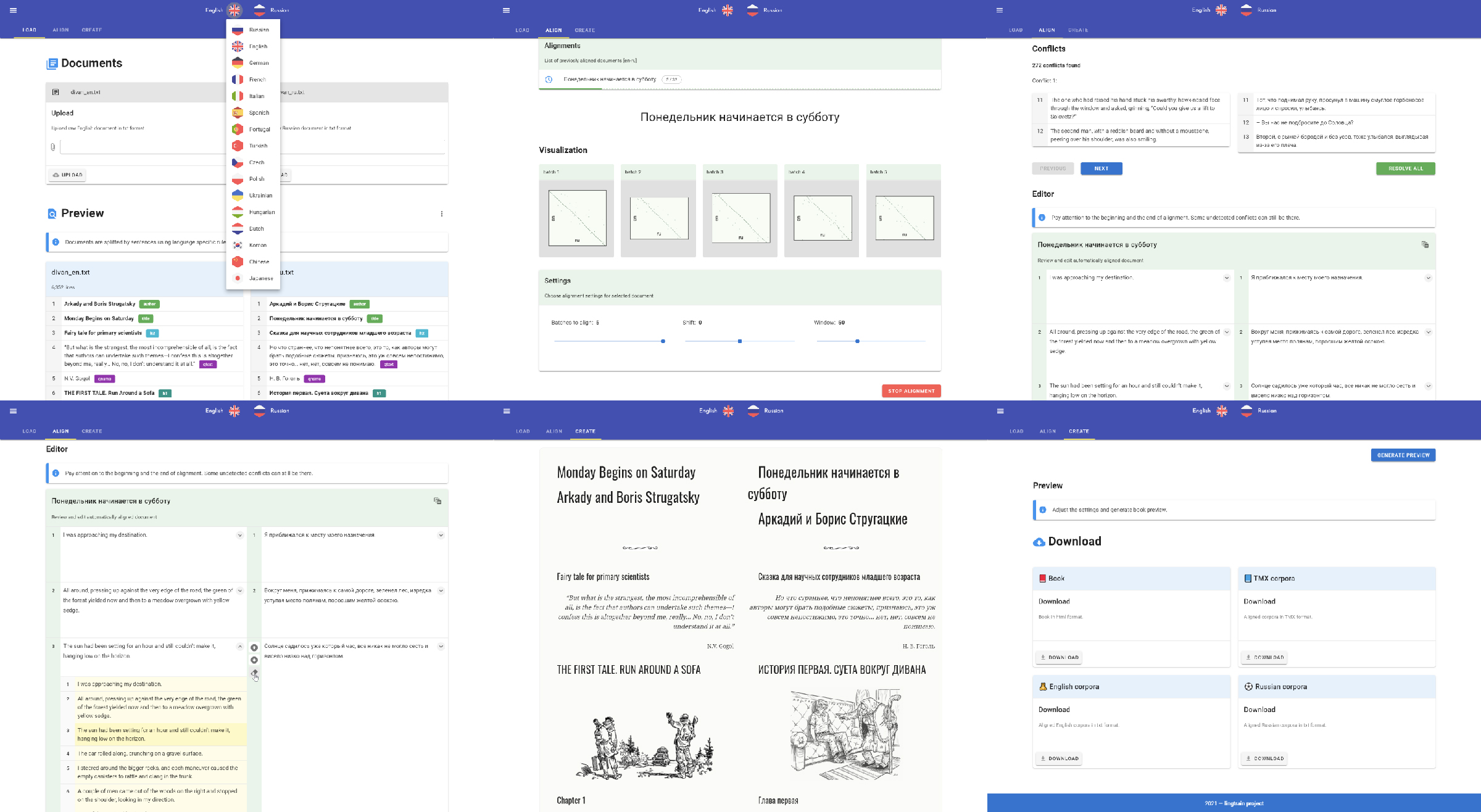
Переходим на вкладку Align, выбираем наши документы и создаем проект выравнивания:

На этой же вкладке можно сразу загрузить ранее созданное в другом месте выравнивание в формате lt. Это то самое выравнивание en_ru_master.db, которое мы делали в секции про питон (оно в формате db, чтобы показать, что это база данных). Можно переименовать его в *.lt и загрузить.

После создания проекта можно начать выравнивать:

Один батч — 200 строк левого текста и пропорциональное количество строк правого. В нашем случае в английской редакции примерно 10 тысяч строк, поэтому батчей получается 49.

Жмем на Align next и запускаем первичное выравнивание. После этого мы увидим текущую визуализацию выравнивания по батчам:

Так как количество предложений в текстах отличается очень сильно, то, хоть мы и берем батчи с пересечением, в какой-то момент можем выходить за рамки правильных вариантов (посмотрите на 5 батч):

Для этого мы можем кликнуть на конкретный батч и пересчитать его с учетом сдвига:

Чтобы пересчитать сразу много последовательных батчей со сдвигом надо задать параметр shift и выбрать нужные батчи, нажав кнопку Customize:


Главное тут, чтобы на визуализации просматривалась диагональ выравнивания:

Если на всех картинках видна такая диагональ, то переходм к конфликтам.
Конфликты
Мы можем посмотреть сколько на текущий момент несоответствий в выравнивании и как они выглядят:

Параметры Handle start и Handle finish определяют конфликты на концах выравнивания. Жмем на Resolve all.
После этого шага могут остаться очень длинные конфликты, когда отрезку в 20+ предложений нужно сопоставить такое же большое количество других. Это ограничение добавленно, так как вариантов в этом случае слишком много и лучше просто сократить такой конфликт в ручном режиме в редакторе (об этом ниже), а потом уже добаить конфликт автоматически.

Редактор
Самая насыщенная UI часть приложения, так как возился с ней дольше всего.

В редакторе можно не только изменять тексты, но и добавлять в ячейки другие строки с учетом их позиции в оригинальном тексте.

Можно добавить к тексту машинный перевод в секции Subscript. Нужно скачать или открыть текст в этой секции (если открыть, то можно сразу перевести за счет браузера), перевести его, сохранить его в файл и загрузить обратно.


Тогда в редакторе можно будет выранивать тексты даже не зная языка, если вы, например, не владеете венгерским, но хотите сделать русско-венгерскую книгу.

Выравнивание через перевод
Если вы загрузили машинный перевод, то станет доступна опция выравнивания через него. Это может увеличить качество, если модель не была обучена на целевом языке.

Экспорт
После окончания выравнивания (проверяем, что не осталось конфликтов, смотрим на результат в редакторе, правим, если нужно) переходим на последнюю вкладку — Create.
На этом этапе мы имеем выравнивание, которое можно преобразовать в различные форматы.

Книга
Мы можем настроить внешний вид книги и посмотреть как она будет выглядеть:


Скачать ее можно в html формате. При помощи внешних скриптов можно сверстать ее в еще более красивый вариант с обложкой, содержанием и т.д. Об этом писал здесь.
TMX
Можно скачать выравнивание в формате TMX.

Database
Среди вариантов экспорта нам сейчас нужно выбрать формат базы данных (Database). Нажав на кнопку Download мы скачаем файл в формате lt.
6b773d7aebd045e399c57d033b00460c.ltЕсли мы выравнивали русско-английскую книгу, то давайте переименуем файл в master_en_ru.lt.
Собираем все вместе
Как говорилось ранее, чтобы сделать мультиязычный параллельный корпус или книгу, нам понадобятся 9 файлов с выравниваниями:
master_by_ru.lt
master_de_ru.lt
master_en_ru.lt
master_es_ru.lt
master_fr_ru.lt
master_hu_ru.lt
master_it_ru.lt
master_uk_ru.lt
master_zh_ru.ltИх можно скачать тут.
Чтобы выравнять их между собой, воспользуемся методом из библиотеки lingtran-aligner. Положим выравнивания в папку db и запустим небольшой python скрипт.
from lingtrain_aligner import reader, saver, preprocessor
from operator import itemgetter
import json
db_path1 = "db/master_en_ru.lt"
db_path2 = "db/master_de_ru.lt"
db_path3 = "db/master_zh_ru.lt"
db_path4 = "db/master_by_ru.lt"
db_path5 = "db/master_uk_ru.lt"
db_path6 = "db/master_hu_ru.lt"
db_path7 = "db/master_it_ru.lt"
db_path8 = "db/master_fr_ru.lt"
db_path9 = "db/master_es_ru.lt"
paragraphs_dict, par_ids, meta_info = reader.get_paragraphs_polybook(
db_paths=[db_path1, db_path2, db_path3, \
db_path4, db_path5, db_path6, \
db_path7, db_path8, db_path9]
)
def save_corpora(paragraphs, lang, output_path):
if lang not in paragraphs:
print(f"{lang} language was not found in data.")
return
flat_list = [sent for par in paragraphs[lang] for sent in par]
print(f"There are {len(flat_list)} sentences for {lang} language.")
with open(output_path, "w", encoding="utf-8") as fout:
fout.write("\n".join(flat_list))
for lang in ["ru", "de", "en", "fr", "zh", "uk", "by", "es", "it", "hu"]:
output_path = f"texts/{lang}.txt"
save_corpora(paragraphs_dict, lang, output_path)В папку texts будут сохранены файлы ru.txt, en.txt, fr.txt и т.д. В каждом из них будет одинаковое количество строк и они будут выровнены друг с другом.

Итог и планы
Мы получили мультиязычный параллельный корпус на 10 языках, его я оформил в отдельный проект и выложил на GitHub — Woland-10.
Из каждого файла с выравниванием можно сделать параллельную книгу и скачать ее в формате html. Можно немного заморочиться и сделать книгу в pdf формате. Например, такую. Инструкция здесь.
Можно дообучить модель на другой язык (например, малоресурсный) и повысить качество выравнивания. Про это здесь.
Сейчас работаю над книгой-трансформером. Об этом расскажу в следующий раз.
Ссылки
Градиент обреченный. Тут пишу про свои проекты, машинное обучение и работу. Буду рад общению.
Чат Ligntrain. Если не получается что-то запустить, есть идеи, или просто любите языки — пишите в чат.
Репозиторий с проектом. Написано на Python + Vue.
На кофе с печеньками. Можно поддержать проект чеканой монетой.
???? Всех с Наступающим! Мира, счастья и добра в Новом Году!
Комментарии (22)

pharo
17.12.2022 16:21В Linux и в частности моём случае использования Puppy Linux, есть команда в контекстном меню (правая клавиша мыши) на файле (пункт выбора UExtract)
так, вот она позволяет средствами системы условно «разархивировать» и файл PDF в текущюю директорию (в формате HTML, Layout, Raw text, картинки)
а, далее можно открыть HTML файл в i-net браузере со встроенным функционалом перевода текста (например SlimJet) и после перевода сохранить или в HTML или PDF (и также его «разархивировав» по UExtract)
после этих действий получаются два файла (исходный и переведённый) исходного содержания, но имеющих шероховатости, как переведённые «слова», которые стоило не переводить, а оставить в англо-транскрипции исходя из контекта содержания текста.
так вот вопрос: в какой степени возможно отработать и такие Тексты или HTML файлы по представленной Вами методике, чтобы оставить не требующие перевода англо-язычные слова в результирующем файле после их синхронизации (например на основе отдельного словаря слов)
P.S. При разархивации PDF файлов в формате HTML каждая строка оформлена строкой, а не в общий абзац, что может не позволить нормально работать с таким файлом при его редактировании/правке в дальнейших инструментах.
qark
17.12.2022 17:05+1Похоже, UExtract — это специфичная для Puppy Linux утилита. Repology о такой не знает.
pharo
17.12.2022 18:02Возможно т.к. она пытается разархивировать множество форматов,
но в плане работы с PDF она, вроде, использует утилиты пакета Poppler.
P.S. Саму Puppy Linux (начиная от Tahr, Xenial, Bionic… Jammy) запускаю в формe LiveCD через Grub2Dos с внешнего SSD. При этом, браузер, к примеру FireFox использую последней версии (обновляя его), сейчас 108, но, бывает, он на каких то сайтах и в таком варианте безбожно зависает не реагируя на мышинные действия и приходится или отключать сетевой кабель или перезагружать систему, (х.з., что такое с ним пытаются проделать скрипты таких сайтов), но это нестрашно так как система загружается каждый раз с SSD в варианте LiveCD и всякой малваре, думаю, такой «прикуп» не по нутру.
В рамках такого варианта, бывает, и собираю какое то ПО штатным Devx GCC пакетом и даже достаточно тяжёлое собиралось.

averkij Автор
17.12.2022 19:09А можно пример текстов, которые вы хотите выровнять?
pharo
18.12.2022 01:01+1Да, написал сообщение в личку, чтобы не засорять текущий тред.
averkij Автор
18.12.2022 17:58+1Спасибо, посмотрю
pharo
18.12.2022 20:32Рад, что может быть дальнейшее улучшение функционала возможностей проекта.
Как, понимаю, сейчас интересно в «тестировнии» проекта использовать оригинальные англоязычные тексты и их перевод в сети в формате книг или профессиональных переводов сделанных для них?
P.S. А, есть ли, текущаяя дорожная карта проекта?
cno6
17.12.2022 18:36+3Отличная статья, давно слежу за Lingtrain и созданием параллельных книг, да вот никак руки не доходят. Будет интересно прочитать про книгу-трансформер.
averkij Автор
17.12.2022 21:50+1Книга-трансформер будет выглядеть примерно так:
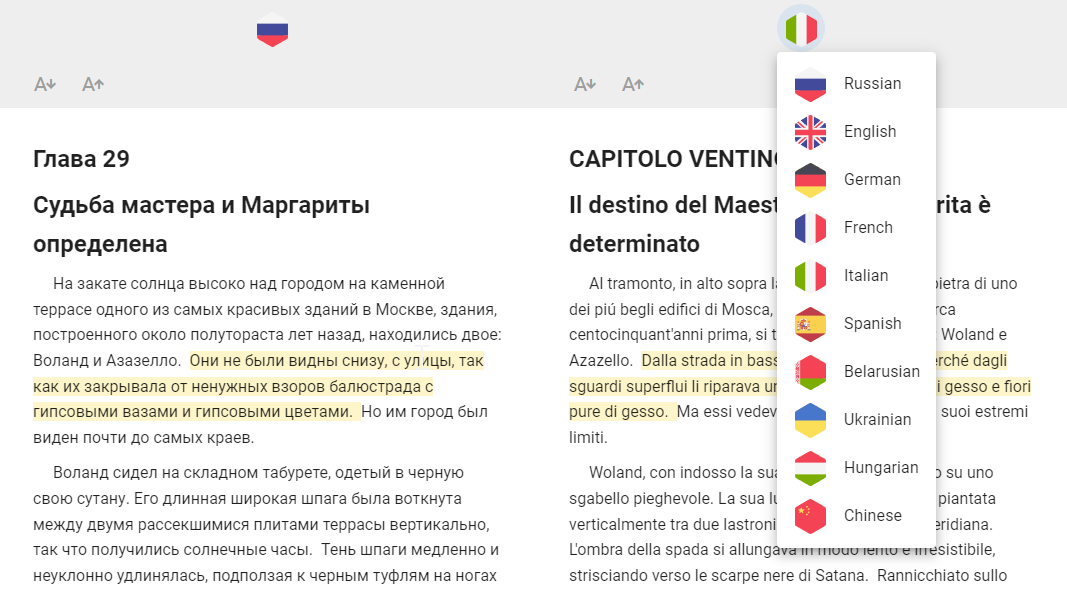
Можно будет выбирать любую пару языков, играть с подсветкой, менять режимы (одна/две колонки, чередование абзацев), шрифты и другие штуки.
Хочу сделать, чтобы можно было развернуть такую книгу у себя на GitHub Pages и читать с любого устройства.

kith404
17.12.2022 18:52+3Хорошо бы развернуть всю систему на общедоступном мощном сервере.
averkij Автор
17.12.2022 21:45Это есть в планах, пока есть рабочая бета на beta.lingtra.in для русского и английского языков.

tumikosha
17.12.2022 21:40+1Метод чтения Ильи Франка — метод, облегчающий чтение книг на иностранном языке благодаря особому расположению оригинального текста и перевода (без упрощения текста оригинала). В книгах, изданных с использованием данного метода, текст разбит на небольшие отрывки.
Можешь замутить ресурс с книгами по этому методу. Я когда-то давно искал такие книги
averkij Автор
17.12.2022 21:53Франка мы, конечно, все знаем. У него не только перевод, но и разные варианты + примечания. Автоматически можно сделать что-то более простое, типа подстрочного перевода.

gasyoun
17.12.2022 23:57+2разные варианты + примечания = все же не сильная сторона книг Франка, поэтому да, это замена Франка в сети

aanovik42
19.12.2022 15:50Вопрос не совсем по теме, но всё же позволю себе воспользоваться случаем. Есть довольно известный сайт Context Reverso, которое ищет отрывки статей и книг с указанным словом или фразой. К сожалению, у него нет никакого API, а за парсинг большого количества страниц можно и блокировку словить. Вы наверняка изучали конкурентов своего продукта: может, знаете что-то похожее на Context Reverso, но с публичным API?
gasyoun
Сергей, это действительно грандиозно. Ждем добавления санскрита!
averkij Автор
Спасибо! Обязательно попробую дообучить, учитывая, что для него есть параллельный корпус.
Greenback
Отличный проект! А есть ли возможность автоматизировать создание epub/mobi книг для чтения "по методу Ильи Франка"? Это когда читаешь на иностранном языке, но рядом с каждым предложением стоит перевод на русский, курсивом. Очень похоже на то что вы публикуете в своём телеграм-канале, но у вас перевод целыми абзацами и в PDF.
averkij Автор
Привет, выравнивание идет на уровне предложений, так что в принципе можно разместить их последовательно или одно под другим.
В книжке-трансформере будут разные режимы. Про epub тоже подумаю.