

Процесс обновления «прошивки» для микроконтроллера – опасная вещь. Раньше при обновлении «прошивки» любой аппаратный сбой приводил к тому, что устройство превращалось в кирпич. В наше время часто имеется начальный загрузчик, который позволит произвести процесс обновления заново, но до того, весь функционал устройства будет потерян. Пока не будет завершено обновление, работать оно уже не будет. Самым красивым способом является использование двух областей для размещения «прошивки» — основной и запасной. На рисунке ниже это красная и синяя области. Исходно активная красная, а обновление будет загружаться в синюю. Сбой загрузки не страшен. Если он произойдёт, управление останется у красной области. При успехе операции, активной станет синяя область, а новое обновление будет загружаться в красную. Ну, и так далее. Каждое обновление будет приводить к рокировке.

К сожалению, в системах Cortex M такой путь напрямую невозможен. Программа привязана к абсолютным адресам и не может исполняться в произвольном месте. С чем это связано и как мы сделали её перемещаемой, подправив компилятор LLVM, рассказано в данной статье.
Я уже делал однажды статью, в которой был только «корреспондентом», описывая проект, к которому не имел никакого отношения, но считал, что знания про проброс UART из Линукса в Windows не должны быть утеряны, а обязательно должны дойти до многих читателей. Сегодня я снова побуду в той же роли, но в этом проекте я всё-таки участвовал, пусть только на старте. Завершал же его наш специалист по доработке компиляторов. И, спасибо ему, часть текста не я записывал с его слов, а он оформил для меня в письменном виде. Так что тут я буду не совсем корреспондентом, а скорее соавтором.
Введение
Кто-то, читавший документацию, скажет, что у компиляторов уже имеются ключи для создания перемещаемого кода. Для случая LLMM, это -fropi, -frwpi и другие. Мы начали проверку с них. Оказалось, что эти ключи очень удобны для систем, в которых программа загружается целиком в ОЗУ. В этом случае, и константы (которые размещаются в коде), и переменные (которые размещаются в секции данных) расположены в одном и том же большом сегменте. Поэтому его очень легко можно двигать по памяти.
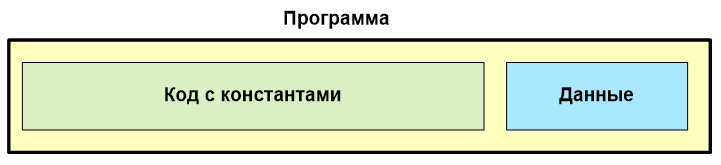
Для контроллеров Cortex M всё сложнее. Там код располагается в ПЗУ большого объёма, а данные – в ОЗУ малого объёма. И эти сущности расположены в разных частях памяти.

Использование этих ключей приводило либо к тому, что данные сдвигались на то же смещение, что и программа… Но ведь размер ОЗУ намного меньше, чем размер ПЗУ! Поэтому они уходили за разрешённый диапазон.
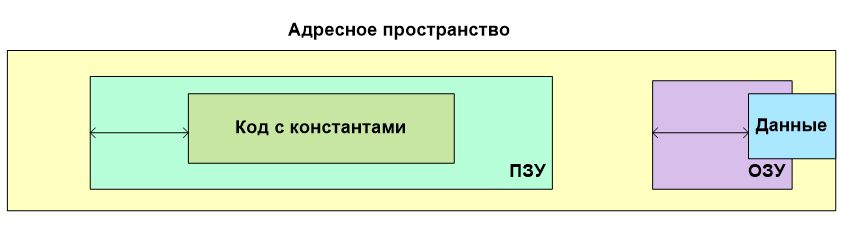
Либо в ОЗУ создавалась огромная таблица указателей на константы в коде. Размер этой таблицы существенно увеличивал размер потребляемого ОЗУ. И того, что предоставлено контроллерами Cortex M иногда просто не хватало.
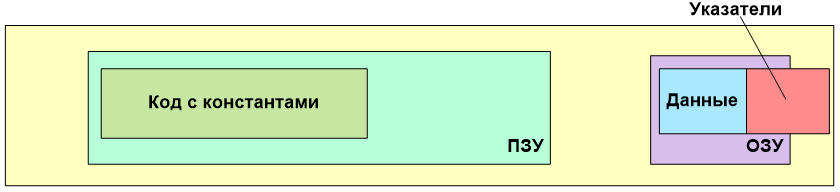
Стало ясно, что для целевой платформы (контроллеры Cortex M) надо вносить изменения в компилятор.
Базовая теория
Ради связности изложения начнём несколько издалека. В компьютере данные и код располагаются в памяти. В рассматриваемой архитектуре (как и почти во всех других) используется линейное адресное пространство, так что положение объекта в памяти задаётся просто числом. Чтобы произвести с ячейкой памяти некоторую операцию процессор должен знать адрес этой ячейки.
Кстати, тут уже начинаются сложности. Как размер адреса, так и максимальный размер инструкции составляет 32 бита. Следовательно, невозможно поместить в инструкцию произвольный адрес – ведь там нужно ещё место для кода самой инструкции. Одним из выходов является использование относительной адресации. При выполнении программы, в регистре PC находится адрес текущей инструкции. Это полноценный 32-битный регистр, содержимым которого управляет аппаратура. Считав его, программа может узнать своё местоположение в памяти. В инструкции вполне найдётся место для некоторого смещения, так что достаточно большой диапазон адресов вокруг текущего положения становится доступным. Например, если нужно вызвать функцию, которая находится не слишком далеко от выполняемой в данный момент, то переход процессор задаёт одной инструкцией.
Здесь функция MyFunc находится рядом с местом вызова:
bl MyFunc
...
.type MyFunc,%function
MyFunc:
...
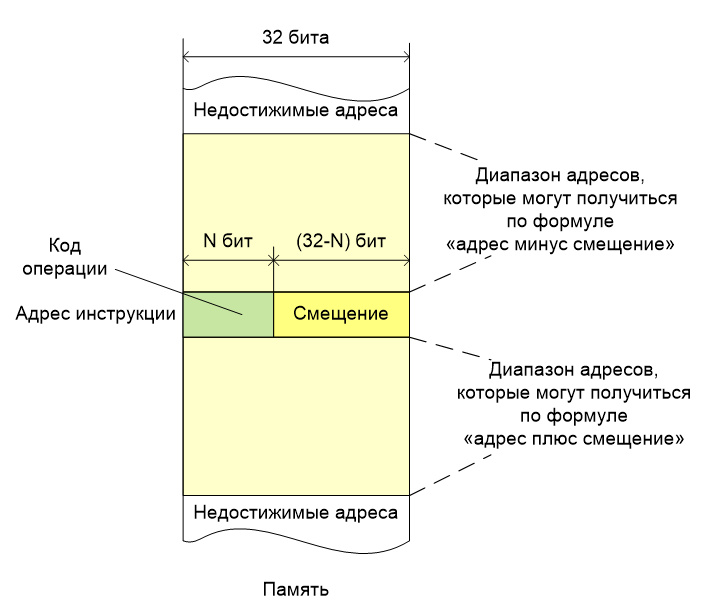
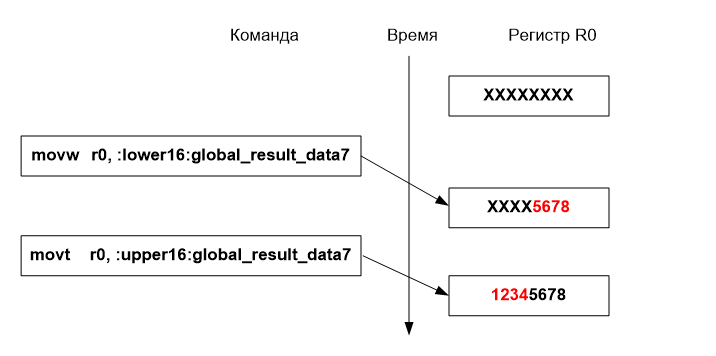
Однако, это полумера, поскольку как далёкие переходы, так и необходимость обращения к ячейкам с произвольными адресами всё-таки остаётся. Тогда можно поступить следующим образом. Поместим нужный адрес в память прямо в коде, недалеко от того места, где он используется. Тогда по аналогии можно выполнить относительную загрузку этого адреса в обычный регистр, а следующей командой выполнить загрузку уже самого значения относительно этого регистра. Более продвинутый вариант – использование пары инструкций movw, movt. Они осуществляют загрузку 16-бит значений в младшую и старшую половины регистра. Целевой 32-бит адрес «режется» пополам и попадает в регистр в два шага. Хотя и требуется выполнить две команды, зато экономится лишняя адресация.
Загрузка в регистр r0 слова по адресу global_result_data7:
movw r0, :lower16:global_result_data7
movt r0, :upper16:global_result_data7
ldr r0, [r0]
Рассмотрим процесс загрузки регистра подробнее, если адрес переменной global_result_data7 равен 0x12345678:
Теперь, когда мы выяснили, как процессор работает с адресами, пришло время рассказать откуда они берутся. Память предполагается (с некоторыми оговорками) однородной, то есть функция, расположенная с адреса, например, 0x1000 с тем же успехом могла бы находиться и по адресу 0x2000, лишь бы этот адрес был известен. Распределением адресов занимается компоновщик (linker). Он получает на вход все объекты, составляющие программу, и выделяет им место согласно приложенному файлу конфигурации. Таким образом, каждый объект получит свой адрес, и эти адреса пропишутся в места их использования. Кроме того, следует учесть, что память отнюдь не обязана начинаться с нулевого адреса, например, достаточно часто встречается начальный адрес 0x08000000. Эту величину следует добавить ко всем глобальным адресам.
Постановка задачи
Итак, получился бинарный образ, пригодный для загрузки в память устройства. Если записать его с того адреса, который был указан при компоновке, и запустить на выполнение, то программа заработает. Все данные найдутся в предполагаемых местах, по вызываемым адресам окажутся нужные функции и так далее. И сразу возникает вопрос – а что будет, если загрузить образ со смещённого адреса? Первым движением хочется сказать, что всё развалится. Программа обратится за значением ячейки по адресу 0x1000, а оно лежит совсем в другом месте. Однако, представим себе минимальную программу, которая состоит из единственной инструкции – перехода на себя же. Очевидно, что такая программа будет вполне перемещаемой: поскольку такой короткий переход выполняется относительно PC, он автоматически «подстраивается» под новое местоположение. Более того, если все переходы в программе относительные, то она может быть достаточно большой и сложной, по крайней мере функции будут вызываться правильно. Беда наступит, как только программа попытается использовать глобальный адрес, значение которого окажется смещённым относительно ожиданий.
Тут пришло время задать вопрос: а есть ли проблема? Что плохого, если программа привязана к фиксированным адресам? Для чего могла бы пригодиться программа, которая умеет работать, будучи загружена в произвольное место? В качестве ответа можно привести соображение, что всегда приятно иметь некую возможность, если цена не слишком высока. Но есть и более конкретные применения. Например, плата вполне может получить извне порцию кода, расширяющую возможности имеющейся программы и самостоятельно загрузить её в дополнение к имеющемуся. Тогда будет очень удобно, если этот код сможет работать независимо от своего положения в памяти. Наконец, может прийти полное обновление прошивки. Тогда опять же её следует разместить где-то в памяти и передать ей управление насовсем. При этом мы не знаем, куда она попадёт, так что возможность запускаться с произвольного адреса является необходимой.
Таким образом, вопрос о способах получения перемещаемого кода заслуживает рассмотрения. Сразу следует сказать, что в серьёзных системах он решается через механизм виртуальной памяти. Логические адреса, используемые в программе, невидимым образом отображаются на физические, так что проблемы не возникает. Однако, это совсем другой уровень технологии, мы же ориентируемся на платформу Coretx-M без модуля MMU. Поэтому, в нашем случае следует «подправить» глобальные адреса, просто добавив к ним величину сдвига программы в памяти. Поскольку вся адресная арифметика сводится к смещениям и разности указателей, других изменений не потребуется.
Кстати, возникает новая задача – узнать величину смещения программы в памяти относительно того адреса, который был задан при компоновке. Например, можно воспользоваться таким трюком. Глобальные адреса остаются неизменными, в то время как значение в PC окажется другим. Можно определить разность между каким-то глобальным адресом и PC при загрузке с «нормального адреса» и «зашить» её в программу. Тогда при запуске со смещённого адреса эта разность окажется другой, и изменение как раз и даст величину сдвига. Однако, как будет сказано ниже, существует более прямой способ выяснить её значение, так что пока будем считать, что оно известно.
Реализация (первоначальный подход)
Итак, процессор загрузил в регистр глобальный адрес. Если писать на ассемблере, то достаточно вставить следующей инструкцию, которая прибавит к полученному значению величину смещения.
В функцию DoOperation передаётся глобальный адрес global_operation5, который корректируется значением из регистра r9:
movw r0, :lower16:global_operation5
movt r0, :upper16:global_operation5
add r0, r9
bl DoOperation

Ради этого стоит зарезервировать регистр для постоянного хранения этого значения. Конечно, можно каждый раз загружать его из памяти, но потери (ёмкость ПЗУ и такты процессора) ожидаются больше, по сравнению с утратой одного регистра. Но как быть, если мы пишем на C? Очевидно, что вся затея имеет смысл, только если не придётся модифицировать исходный код. Ещё можно пойти на какие-то специальные манипуляции в одном-двух ключевых местах, но в целом никаких переделок не допускается. К счастью, с поставленной задачей вполне справится компилятор после небольшой доработки.
Дело в том, что компилятор прекрасно понимает, что именно он делает. Мы использовали LLVM, поскольку имеем большой опыт доработок этого компилятора, так что в дальнейшем речь пойдёт о нём. В LLVM предусмотрен механизм раздельного адресного пространства (address space), который позволяет привязать к указателю атрибут, задающий размещение данных. В нашем случае предполагалось, что смещается только содержимое ROM, а адреса RAM неподвижны. В таком случае следует задать отдельное адресное пространство для глобальных константных объектов (функции, константные данные, строковые литералы, в общем всё, что кладётся в read-only память).
Здесь вводится отдельное адресное пространство для константных данных и назначается глобальным объектам:
llvm::Optional<LangAS> ARMTargetInfo::getConstantAddressSpace() const {
return getLangASFromTargetAS(REL_ROM_AS);
}
LangAS getGlobalVarAddressSpace(CodeGenModule &CGM, const VarDecl *D) const override {
if (D && CGM.isTypeConstant(D->getType(), false)) {
auto ConstAS = CGM.getTarget().getConstantAddressSpace();
assert(ConstAS && "No const AddressSpace");
return ConstAS.getValue();
}
return TargetCodeGenInfo::getGlobalVarAddressSpace(CGM, D);
}
Этот атрибут «живёт» внутри типа всё время компиляции, и при загрузке адреса объекта есть возможность опознать размещение в ROM и вставить инструкции для добавления смещения.
Проблема статической инициализации
К сожалению, имеется один сценарий, который невозможно обработать указанным способом. Допустим, у нас есть глобальный массив указателей, который инициализируется смесью адресов ROM и RAM.
Массив arr содержит два адреса: из ROM и из RAM:
int rw;
const int ro;
const int *arr[] = { &ro, &rw };
Такая инициализация делается статически, то есть компоновщик просто выделяет память и заполняет её некими числами, которые назначаются символьным адресам.
Статическая инициализация массива arr:
.type arr,%object
.section .rodata,"a",%progbits
arr:
.long ro
.long rw
.size arr, 8
Он ещё не знает величину будущего смещения, так что ничего сделать не может. Тут следует оговориться – компоновщики бывают разные, их возможности могут быть очень большими, но пока речь идёт о простом случае бинарного образа. Итак, мы получили массив в виде простого набора чисел. Но теперь на этапе выполнения сделать тоже ничего нельзя, ведь мы уже не знаем какие там адреса из ROM, а какие из RAM. Получается, что вся затея потерпела крах?
В принципе, есть очень затратный, но вполне универсальный выход. Если известны диапазоны адресов для ROM и RAM, то можно всю адресацию пропускать через специальную функцию, которая по значению адреса определит его принадлежность и при необходимости скорректирует. Однако, страшно себе представить, каких накладных расходов это потребует. В данном случае решение является чисто теоретическим, очевидно непригодным на практике, за исключением, быть может, каких-то отдельных случаев.
Реализация (новая идея)
Вот если бы удалось скорректировать адреса на этапе загрузки прошивки… Конечно, это дополнительно потребует изменения программы для загрузки образа в память, плюс дополнительной информации к самому образу, но если подумать, то идея оказывается не такой уж безнадёжной. Как было сказано выше, полная способность работать с любого загрузочного адреса даётся ценой увеличения, пусть и небольшого, размера кода и замедления работы. Если бы удалось исправить все проблемные места непосредственно в бинарном образе, то перемещаемость была бы достигнута без указанных выше потерь эффективности. Там могут встретиться подводные камни, но идею стоит проверить в деле.
Сразу напрашивается грубый, но многообещающий метод. Что если собрать две прошивки для загрузки с разных адресов и сравнить их? Ведь должны измениться только адреса, так что мы увидим все места, которые следует корректировать. Однако, на практике оказывается, что различий существенно больше. Часть из них можно отсеять, как не имеющие отношения к задаче, но нет никакой гарантии, что всегда удастся правильно отличить нужные от артефактов. И потом, сам подход выглядит слишком наивным для серьёзного применения.
Из сказанного выше следует, что нам нужно исправить как минимум некоторые адреса, использованные для инициализации глобальных указателей. Допустим для простоты, что генерация кода производится с созданием промежуточного ассемблерного файла, а также у нас есть возможность вмешаться в этот процесс. Тогда появляется такая идея. Каждый раз, когда компилятор использует для инициализации глобальный адрес, можно посмотреть, в каком адресном пространстве тот находится, и если он из ROM, то поставить перед ним метку.
Перед инициализацией ROM адресами поставлены метки.

mainMenu:
Reloc2:
.long mainMenuEntriesC
.long mainMenuEntriesM
Reloc3:
.long mainMenuEntriesC+8
В конце модуля мы добавляем секцию со специальным именем и помещаем все те метки в неё.
Метки собраны в секцию reloc_patch:
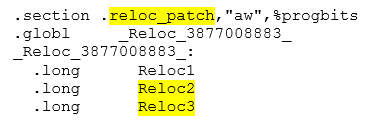
.section .reloc_patch,"aw",%progbits
.globl _Reloc_3877008883_
_Reloc_3877008883_:
.long Reloc1
.long Reloc2
.long Reloc3
В скрипте компоновщика мы объявили эту секцию как KEEP, чтобы она уцелела, так как обращений к её данным, очевидно, нет. Далее, когда будет собираться исполняемый файл, все добавленные секции объединятся, а метки получат конкретные значения, соответствующие адресам в бинарном образе. Ключевой момент здесь в том, что эти же адреса означают и смещения в выходном файле. Таким образом, мы сумели локализовать места, подлежащие исправлению. Есть небольшая тонкость – если сами инициализируемые данные располагаются в RAM, то их инициализация лежит в ROM по известному смещению. Таким образом нам потребуется две секции: для ROM и RAM данных. Первая обрабатывается, так как было описано, а из адресов во второй следует вычесть адрес начала RAM, а потом добавить смещение блока инициализации, которое определяется в файле скрипта компоновщика.
Далее мы написали небольшую утилиту, которая извлекает из ELF-представления наши секции и получает список смещений, по которым находятся глобальные адреса.
Развитие идеи
В принципе, этого уже достаточно, чтобы исправить прошивку на этапе загрузки, но можно пойти ещё дальше. Введём простой набор команд, например так:
’D’ [qty] {data} — записать следующие qty байт из входного потока
’A’ [qty] — трактовать следующие qty слов как адреса, прибавить к ним некоторое значение и вывести в выходной поток.
Передать в выходной поток четыре байта, а потом скорректировать два адреса:
’D’ 0x4 0x62 0x54 0x86 0x12 ’A’ 0x2 0x00001000 0x00001008
Если смещение составляет 0x4000, то получится так (для наглядности не будем раскладывать числа на байты):
0x62 0x54 0x86 0x12 0x00005000 0x00005008
Теперь преобразуем исходный бинарный образ в набор таких команд. Все данные, вплоть до первого адреса, подлежащего исправлению, пропускаются без изменений, потом следует команда, исправляющая один или несколько адресов, снова данные и так далее, до конца файла. Таким образом, информация для корректировки адресов оказывается внедрена в бинарный образ. С одной стороны, полученный файл уже не является прошивкой, пригодной для непосредственной загрузки. Но теперь его можно обрабатывать «на лету», в потоковом режиме по мере поступления, используя небольшой буфер. То есть следует слегка доработать программу загрузки, чтобы она не просто записывала входящий поток в память платы, а исправляла адреса согласно принимаемым командам. Также можно сделать дополнительную утилиту, которая принимает на вход такой файл и адрес загрузки и изготовляет обычную прошивку.
Можно пойти и ещё дальше. Как было сказано, некоторые адреса «зашиты» прямо в пары инструкций movw, movt. Компилятор может определить, какие из них соответствуют загрузке ROM адреса, поставить там метки и сделать ещё одну секцию для них. Также мы добавили команду, которая выбирает из потока два слова, трактует их как пару инструкций загрузки, извлекает адрес, исправляет его и помещает обратно. В таком случае необходимость в дополнительных действиях на этапе исполнения пропадает вовсе. Кроме того, появляется возможность достаточно гибкого исправления программы, например, изменения номера версии и т.п.
Заодно появляется способ сообщить программе величину смещения, если она всё-таки потребуется. Делаем функцию со специальным именем, которая записывает константу в ячейку RAM. В коде такая функция будет начинаться с двух пар movw, movt – первая для загрузки RAM адреса ячейки, а вторая – для самой константы.
Получение смещения в ячейке RAM и регистре r9:
int rel_code = 0;
int set_rel_code() {
rel_code = 0x12345678;
return rel_code;
}
void __attribute__((section(".text_init"))) Reset_Handler(void) {
set_rel_code();
asm(“mov r9, r0”);
...
}
Добавляем ещё одну потоковую команду, которая не добавляет смещение к зашитому в пару инструкций загрузки значению, а просто меняет его на указанное. В результате окажется, что функция запишет в RAM именно величину смещения, и после её вызова это значение будет доступно. И вообще, открывается весьма широкий спектр возможностей, так что дополнительные осложнения выглядят оправданными.
Существующие ограничения
Следует отметить, что необходимость работать с промежуточным ассемблерным файлом безусловно выглядит как недостаток реализации. Он представляется несущественным, поскольку трудно сказать, чем это мешает. Возможно, в будущих версиях мы от него избавимся, создавая метки непосредственно во внутреннем представлении компилятора. Также нехорошо то, что служебные секции, предназначенные для получения смещений в бинарном образе, занимают место. Но для них можно задать фиктивные адреса, где память реально отсутствует, если при загрузке не будет возникать ошибок.
Заключение
Компилятор LLVM был доработан для генерации такого двоичного кода, который перед самой загрузкой во флэш-память может быть привязан к любым адресам без использования исходных кодов и среды разработки. Вся информация для привязки содержится в двоичном коде.
Комментарии (13)

gudvinr
02.09.2021 14:43+1А патчи в LLVM вы отправляли, или свой форк поддерживаете для этого?

EasyLy Автор
02.09.2021 16:15Пока свой. Считаем, что для отправки это сыровато. Вот когда проведём исчерпывающее тестирование и Заказчик погоняет на большом наборе боевых данных, тогда... Но идея уже достойна публикации, поэтому и описали. Потом детали забудутся.

Krasutski
02.09.2021 15:37+2К сожалению, в системах Cortex M такой путь напрямую невозможен. Программа привязана к абсолютным адресам и не может исполняться в произвольном месте.
Во первых, Cortex-M широкое понятие. Да ядро такого механизма не предоставляет, но такой механизм может присутствовать у отдельных MCU,может называться, например, "Memory remapping", https://www.st.com/resource/en/application_note/dm00230416-onthefly-firmware-update-for-dual-bank-stm32-microcontrollers-stmicroelectronics.pdf
Второе, есть такая штука как PIC(Position-independent code) и многие компиляторы в том числе LLVM эту фишку поддерживают, было бы интересно увидеть сравнение вашей реализации и PIC механизма, понятно что размер прошивки в PIC будет больше но на насколько? Хотя бы для вашего практического случая...EasyLy Автор
02.09.2021 16:04-1По первому пункту, всё просто. У Заказчика был свой список контроллеров, и менять он его не хотел. И за решение своей проблемы оплачивал работы. Поэтому замечательно, что производители тоже думают над решением этой проблемы, но Заказчику требовалось решить на его технике. И у нас есть разрешение опубликовать результаты исследований.
По второму - всё тоже не сильно сложно. Мы на тестовых примерах разобрались с этой самой таблицей GOT, на очередном совещании с Заказчиком показали всё на эту тему, получили чёткое указание больше в этом направлении не работать... И, собственно, не работали. Так что боевых метрик мы не снимали.
Без конкретики, сама идеология в начале статьи расписана. При этом было бы полбеды, если бы выросла прошивка. Когда прошивка растёт - данные в ОЗУ сдвигаются. А когда они не сдвигаются - растёт не прошивка, а требования к ОЗУ. А его мало. Это - то, что успели выяснить до того, как нам сказали идти другим путём.

VelocidadAbsurda
03.09.2021 02:47+3В самом формате ELF «из коробки» предусмотрены (и отлично документированы) relocations. Добавляете компоновщику ключ -q (это для GNU ld, насчёт clang не уверен) и в выходном файле появляются соответствующие секции. А дальше либо вытаскиваете их для своих нужд (readelf -r), либо, если объём RAM позволяет, накатываете их уже на целевой платформе.
Но конкретно для случая системы с чередованием рабочей/обновляемой зон я бы просто собирал образы под оба начальных адреса и при обновлении давал понять который нужен - дёшево и надёжно.
EasyLy Автор
03.09.2021 22:50+1А ведь и правда! Мы чего-то увлеклись. Просто исходно Заказчик хотел, чтобы код был перемещаемым от рождения. Ключики не давали правильного эффекта, поэтому мы начали менять генератор кода. И сначала всё было даже замечательно. Дальше Заказчик стал присылать всё более и более заковыристые конструкции... Добавляемый для этого код, распознающий каждый раз диапазон, стал всё более и более убойным. Вставляемых инструкций при вычислениях средней сложности становилось больше, чем рабочих!
И вот тут Заказчик сдался. Он согласился на то, чтобы код был не честно перемещаемым, а готовился перед прошивкой (кстати, абдейт прошивки и два банка - только одна красивая иллюстрация, по ТЗ он должен работать где угодно). Но к тому времени, настроение было такое (и команда проекта этому соответствовала), что надо продолжать править компилятор. Вот и понеслось. Что, собственно, и получилось.
Подкупало и то, что получившийся метод сохранял CLANGовскую возможность использования команд movt/movw для загрузки 32 битных адресов, что эффективнее, чем GCCшный вариант... Хотя, лично я признаю их эффективность, но не считаю её повышение уж слишком высоким. Но и правку делал не я. Я к тому времени уже был на другом проекте. Есть у получившегося метода и другие потенциальные плюсы, но в действующее ТЗ они всё равно не входили.
Спасибо, что сняли шоры с наших глаз. Сегодня было много проверок в GCC с Вашими ключиками. Пробовали разный тестовый код и разные уровни оптимизации, приговаривая: "Ну тут-то не поможет". Пока помогло везде... Склоняемся к тому, чтобы всё переделать...
VelocidadAbsurda
04.09.2021 05:13+1Посмотрел документацию clang, там тот же самый ключ -q (он же --emit-relocs).
Relocations вообще неотъемлемая часть "больших" компиляторов, ими пользуется и компоновщик, "склеивая" вместе объектные файлы (те по сути — ELFы, собранные под одни и те же адреса, но с relocations компоновщик может их свободно сдвигать), и динамические загрузчики исполняемых файлов в "больших" ОС (например, исполняемый файл ссылается на две динамические библиотеки, собранные под одинаковые адреса. Загрузчик перебазирует их и никто ничего не заметит).
Gryphon88
Спасибо за статью. Я не очень понимаю волшебство линковщика. Вы говорите, что
На каком этапе он её узнаёт? Ведь без этого знания ELF не получится.
GarryC
Собственно на этапе связывания. Сначала распределяются статические метки и заносятся в таблицу, затем на первом проходе таблица дополняется нестатическими метками и на втором заполняются ссылки на них. Вроде бывают и другие линкеры, это про тех, с которыми работал.
Gryphon88
Я немного не понимаю, почему тогда потребовался патч к LLVM, тут никак скриптом линковщика не обойтись?
EasyLy Автор
И такая идея у нас была. Действительно, если в ELF сохранить информацию обо всех символах, то можно узнать многое.
Но дело в том, что наш подход концептуально позволяет выполнять очень широкий набор операций. Мы фактически расставляем метки и группируем их по сортам.
Например, коррекция адреса - это только одна из возможностей. В статье приводился пример исправления пары инструкций, где адрес разбит на две части и хитро перемешан с битами инструкции. Возможны и другие варианты.
Кроме того, исправление компилятора не было для нас проблемой, так что мы решили пройти по сложному, но многообещающему пути.
Gryphon88
В итоге сделали патч (ака пуллреквест в апстрим) или плагином к компилятору?
EasyLy Автор
Мы внесли изменения для платформы ARM. То есть, сделали патч. Но как я уже писал в ветке ниже - пока что всё делали локально.