

Привет, Хабр! Сегодня расскажу, как на хакатоне для студентов SkillFactory я сделал Slack-бота, который оповещает студентов разных курсов о выходе статей на Хабре по интересующей их тематике. На КДПВ вы видите тестирование внедрённого бота; ссылку на его код вы найдёте в конце статьи.
Раньше наш редактор ежедневно заходил на Хабр, просматривал только что вышедшие статьи и вручную оповещал сотрудников SF о всех новых публикациях в специальном канале в Slack. Редактору это надоело, и мы придумали, как упростить ему жизнь и автоматизировать процесс.
Чтобы не утомлять, рассказываю о самых основных моментах, которые касаются объединения трёх основных частей проекта: Django, Celery и парсера Slack-бота. Опущены такие моменты, как получение токена Slack-бота на сайте, построение шаблона и заполнение URL проекта. Об этом уже есть много статей, а строение этого проекта ничем не отличается от большинства других. Я выполнял проект на Windows WSL 2, поэтому указаны команды для Linux. При этом время на выполнение проекта было ограничено, поэтому я старался упрощать все задачи. Поехали!
Вначале создадим виртуальное окружение и проект Django:
python3 -m venv venv
source venv/bin/activate
# В репозитории есть requirements.txt для установки нужных версий библиотек
pip install django
django-admin startproject slackbotВ корневом каталоге проекта создаём новое приложение:
cd slackbot
python3 manage.py startapp interfaceНе забываем добавить interface в settings.py и в INSTALLED_APPS.
Теперь продумаем модели нашего проекта. Напоминаю: программа должна парсить Хабр и отправлять новые статьи в каналы Slack, делать это будет Slack-бот, то есть потребуются две модели — модель бота и модель статьи. Построим модель бота:

name — имя бота;
token — токен бота;
channel — имя канала, куда отправляются сообщения;
task — по условиям есть 2 задачи. Чтобы не писать код автовыбора задачи, я решил прикреплять бота к определённой задаче в момент его создания;
editor_text — текст перед ссылкой на статью;
bot_tags — здесь пропишите теги, по которым бот будет искать статьи.
Теперь построим модель статей, чтобы хранить в базе данных то, что распарсил бот:

headline — заголовок статьи;
public_time — время публикации статьи;
link — ссылка на статью;
status — это поле-флаг определяет, в каком состоянии находится статья. Если она уже была отправлена ботом на канал Slack, статус нужно изменить на sended;
tags — теги статьи;
task — дополнительное поле принадлежности к статье на всякий случай.
Также я решил создать модель конфигурации бота. По условиям в задаче у пользователя должна быть возможность конфигурировать ботов отдельно по времени отправки сообщения и на задержку парсинга.
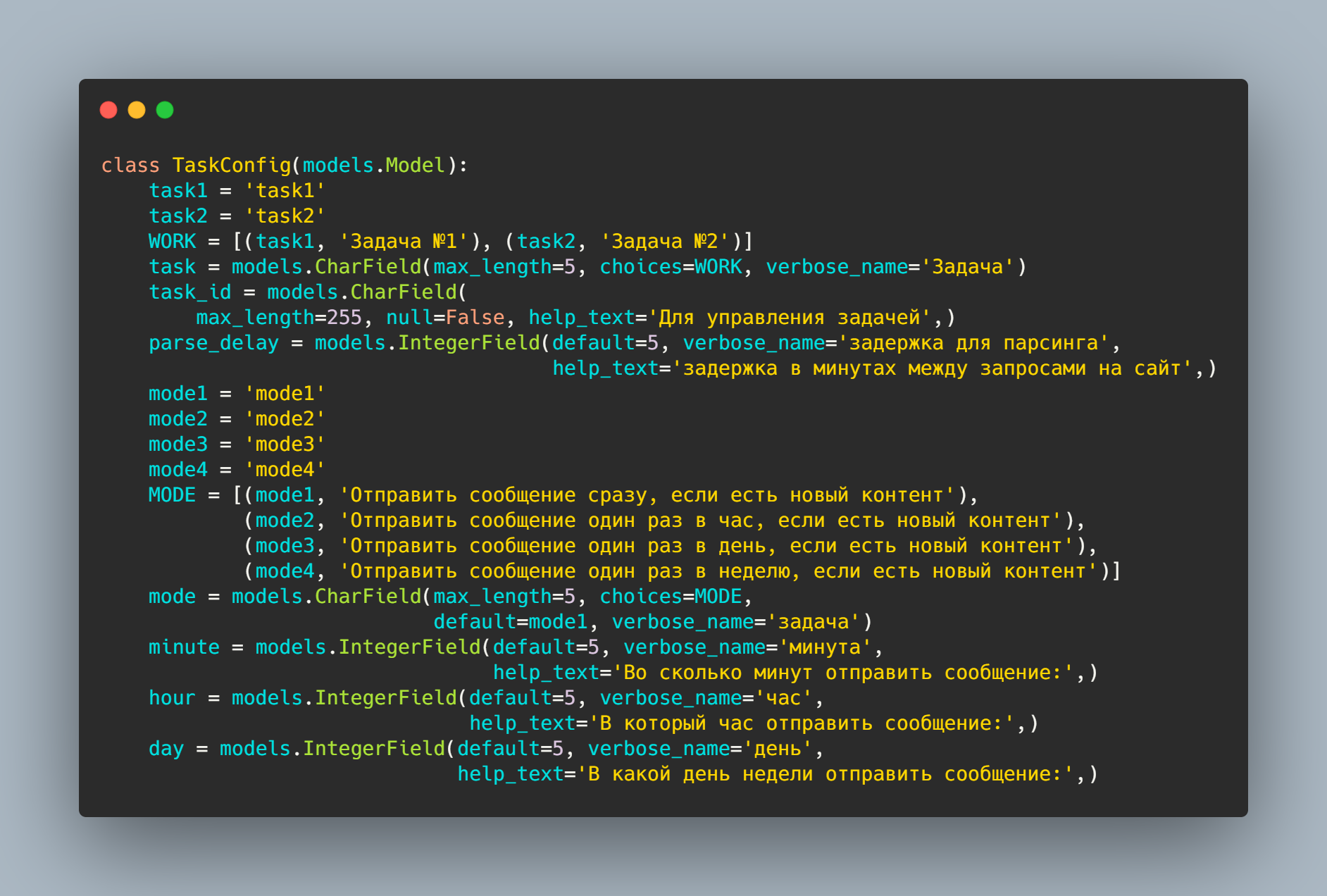
task — у нас 2 задачи, поэтому нужно выбирать из них;
task_id — нужен для управления ботом. Бот будет запускаться асинхронно из под Celery, поэтому, чтобы запускать и останавливать конкретного бота, лучше сразу сохранить идентификатор его задачи;
mode — выбор режимов отправки нового контента в каналы Slack;
minute — если пользователь выбрал отправку каждый час, можно задать минуту часа;
hour — если раз в день, можно задать час отправки;
day — при отправке раз в неделю можно задать день недели отправки.
Модели проекта готовы, пора применить миграции, создать суперпользователя и приступить к работе над интерфейсом для пользователя.
python3 manage.py makemigrations
python3 manage.py migrate
python3 manage.py createsuperuser
python3 manage.py runserverСамый быстрый способ сделать шаблон для проекта — взять готовый и доработать его. Я выбрал этот шаблон.
Создаём папку static/interface и кладём туда скачанный шаблон. Все шаблоны будут наследоваться от этого шаблона. В нём есть готовая шапка, подвал, некоторые элементы js; остаётся вырезать лишнее и подправить section. Вьюха получилась довольно длинной, поэтому опишу только интересные моменты.
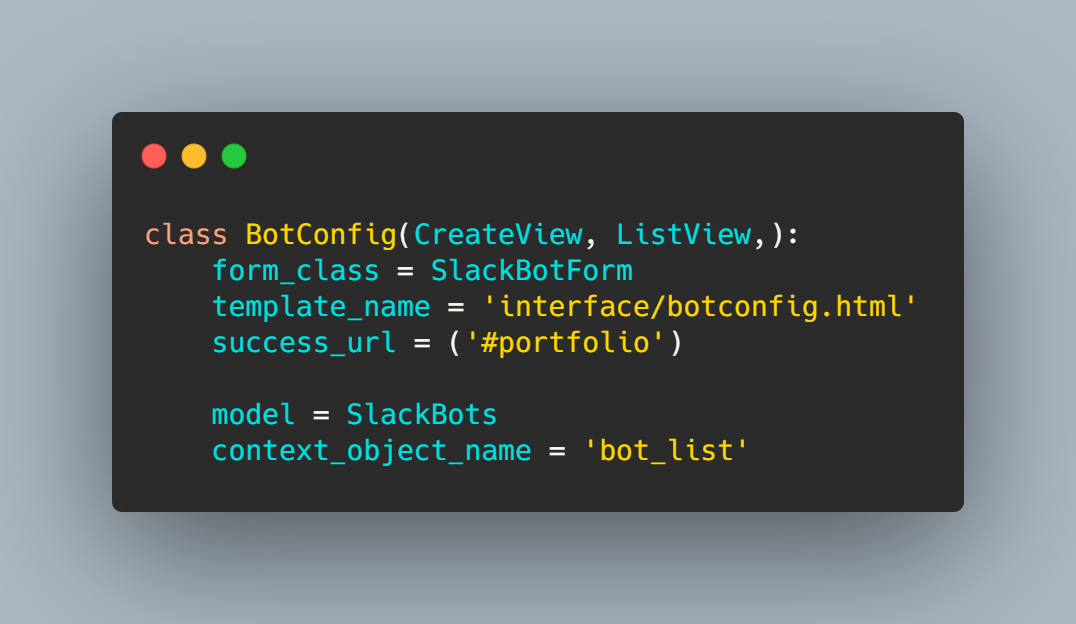
Это вьюха главной страницы, где можно создать и просмотреть список ботов, поэтому она одновременно наследуется от CreateView и ListView. Форма стандартная, а в конце вы найдёте ссылку на репозиторий. Функциональная часть страницы выглядит так:

Здесь можно зарегистрировать, запустить, остановить Slack-бота, а также сконфигурировать задачи и просмотреть список зарегистрированных ботов. Интерфейс между пользователем и ботом готов. Следующий этап — реализация бота.
Перед тем как писать код парсера, нужно прояснить одну вещь. Задача Django — принимать команды пользователя и передавать их боту, а бот должен работать сам по себе, не отвлекая Django от его задач; самым верным решением в этой ситуации будет асинхронность. Поэтому вначале нужно подключить к проекту Celery, а логику бота реализовывать как задачи Celery. Для работы Celery необходим Redis, запускайте его в отдельном окне терминала.
sudo apt-get update
sudo apt-get install redis
redis-serverПосле необходимо установить celery и redis в окружение Django:
pip install celery
pip install redisДалее мы должны добавить некоторые настройки в конфигурацию проекта — settings.py, дописав следующие строки:
CELERY_BROKER_URL = 'redis://localhost:6379'
CELERY_RESULT_BACKEND = 'redis://localhost:6379'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'Затем согласно документации Celery переходим в директорию проекта и рядом с settings.py добавляем файл celery.py:
import os
from celery import Celery
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'mcdonalds.settings')
app = Celery('mcdonalds')
app.config_from_object('django.conf:settings', namespace = 'CELERY')
app.autodiscover_tasks()Также по рекомендациям в документации Celery мы должны добавить следующие строки в файл __init__.py в той же папке, что и settings.py:
from .celery import app as celery_app
all = ('celery_app',)Задачи Celery запускаются в отдельном окне из той же директории, что и runserver. Запускаем:
celery -A slackbot worker -l INFO
Готово! Celery настроен и может принимать задачи.
Наконец, переходим к самому интересному — разработке функций бота! Базовая структурная единица Celery — задача (task). По условиям проекта задачи две:
Парсить все статьи в блоге компании и оповещать о выходе новых статей через Slack.
Парсить все статьи в блоге компании, но оповещать только о статьях с определёнными тегами.
Значит у нас будут задачи parse и parse2. Создаём файл task.py в каталоге приложения interface. Чтобы зарегистрировать функцию как задачу Сelery, достаточно импортировать декоратор from celery import shared_task и задекорировать функцию. Я создал новый файл tasks_extension.py и вынес туда всю логику бота. В конце останется лишь импортировать основные функции триггеры для запуска задачи в tasks.py.
В tasks_extension.py пишем алгоритм работы парсера. Для этого нужны две библиотеки:
pip install requests
pip install beautifulsoup4Берём html-код страницы Хабра.

Функция print здесь используется в качестве простой реализации логирования.
@onceEveryXSeconds(delay) — это декоратор задержки, чтобы не собирать HTML Хабра каждую секунду.
Находим на странице статьи и записываем их в переменную items:

Метод find_all библиотеки beautifulsoup4 вернёт список, итерируя который мы заполним модель статей в базе данных. Итак, у нас есть логика парсера, а собранные данные лежат в базе, остаётся написать конфигурацию для рассылки статей по каналам.

Функция принимает на вход один из режимов работы и отправляет рассылку согласно настроенному времени. Интерфейс настроек выглядит так:
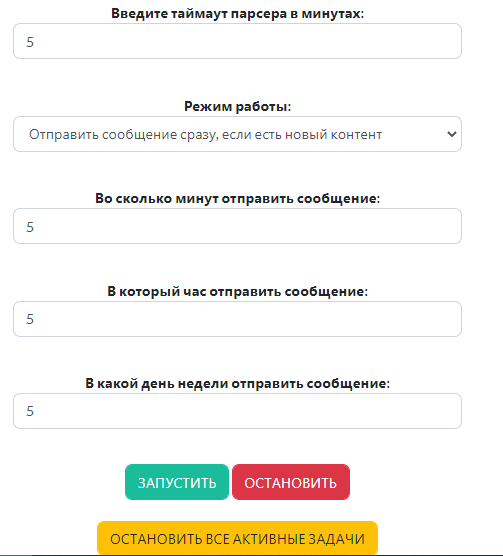
И функция отправки сообщений:

Теперь импортируем необходимые функции в файл tasks.py и напишем основную задачу для Celery:

Сама задача будет запускаться кнопкой на скрине выше; напишем функцию запуска бота:

Главное — записать id задачи, чтобы в дальнейшем остановить её. Функция остановки выглядит так:

Чтобы задача останавливалась корректно, её нужно декорировать в task.py:
@app.task(bind=True, base=AbortableTask)Cоздаём нового бота:
И запускаем задачу в консоли Сelery:


Готово! Бот работает:

Репозиторий проекта.
В пандемию, когда контакты с людьми сводятся к минимуму, боты незаменимы — и если вам интересна их разработка, то вы можете обратить внимание на наш курс о Fullstack-разработке на Python, а если хочется пойти дальше и создавать программы с ИИ, вы можете присмотреться к нашему курсу «Machine Learning и Deep Learning», который полностью подготовит вас к началу карьеры в области ИИ с нуля или прокачает ваши навыки. Также вы можете узнать, как начать карьеру или продолжить развитие в других направлениях:

Python, веб-разработка
Data Science и Machine Learning
Мобильная разработка
Java и C#
От основ — в глубину
А также:
Комментарии (3)

froOzzy
09.09.2021 14:54Для одного бота юзать django и celery наверное как то жирно. Когда API хабра до восстановят https://habr.com/ru/docs/help/api/, можно будет уйти от bs4. Но в целом идея хорошая

maxiy01
09.09.2021 14:54А зачем так сложно? В слаке ж вроде из коробки можно добавлять RSS ленты в канал?
yakimka8
Вот любите вы в skillfactory все задачи через парсинг решать.
Но ведь у хабра есть RSS-лента, как для своего кастомного фида, так и для любого хаба. В вашем случае фид будет иметь ссылку https://habr.com/ru/rss/company/skillfactory/blog/?fl=ru
И получать посты с RSS гораздо проще и правильнее, чем парсить html.