

Привет! В прошлой статье мы познакомились с aiohttp и написали первое веб-приложение: стену с отзывами. Сегодня продолжим изучение и добавим асинхронное взаимодействие с базой данных PostgreSQL.
Что будет в статье:
Эта статья дополняет код первой части - найти его можно здесь. Код для этой части статьи находится в репозитории по ссылке.
Если вам интересно асинхронное программирование, приходите к нам на курс в KTS, где мы подробно разберем эту тему. Старт — 18 октября.
1 — Поднимаем базу данных PostgreSQL в Docker-контейнере
Это подготовительный этап. Мы будем работать с сервером PostgreSQL версии 11 и старше. Так как Docker все равно понадобится вам для последующей публикации приложения в Интернете, то убьем двух зайцев сразу и запустим сервер PostgreSQL в Docker-контейнере.
Устанавливаем Docker c официального сайта: https://docs.docker.com/engine/install/#server.
Docker-контейнеры по умолчанию не хранят данные, поэтому необходимо создать volume, чтобы не потерять данные нашей базы после перезапуска или после остановки контейнера:
sudo docker volume create postgres-dataТеперь запустим нашу базу командой:
sudo docker run -e POSTGRES_PASSWORD=forum_password -e POSTGRES_USER=forum_user -p 5432:5432 --name postgres --mount source=postgres-data,target=/var/lib/postgresql -d postgres:11Мы запустили docker-контейнер с базой данных от имени root-пользователя. Давайте рассмотрим переданные параметры:
-e POSTGRES_PASSWORD=forum_password— задали пароль для пользователя базы данных, передав его через переменную окружения в контейнер-e POSTGRES_USER=forum_user— задали имя пользователя базы данных аналогичным способом-p 5432:5432— опубликовали 5432-ой порт контейнера во внешнюю среду. Подробнее о том, как устроена сеть Docker, можно прочитать тут--mount source=postgres-data,target=/var/lib/postgresql— примонтировали volumepostgres-dataк нашему контейнеру. Теперь все данные, которые приложение в контейнере записало в/var/lib/postgresql, сохранятся на жестком диске. Иначе при остановке или перезапуске контейнера мы бы их потеряли.-d— запустили командуdocker runв detached-режиме: можем закрыть консоль, а контейнер продолжит работатьpostgres:11— имя образа, на основе которого необходимо запустить контейнер. Подробнее про docker-образы можно прочитать здесь
Проверим, что база работает. Для этого подключимся к ней через CLI:
sudo docker exec -it postgres psql -U forum_userЕсли все настроено верно, то указатель слева в терминале должен поменяться на postgres=#.
Создадим базу данных и дадим все права на нее нашему пользователю:
CREATE DATABASE forum;
GRANT ALL PRIVILEGES ON DATABASE forum TO forum_user;
\qПодготовка закончена, переходим к написанию приложения.
2 — Создаем модель данных
Чтобы получить доступ к базе данных, нам нужен адрес ее сервера, имя и пароль для входа, а также название самой базы. При локальной разработке приложения на компьютере эти параметры могут быть одни, а при публикации в Интернете совершенно другие. Данные, которые могут меняться, обычно выносят в конфигурационный файл и подменяют этот файл в зависимости от окружения.
В корень проекта добавим папку config, а в ней создадим файл config.yaml. Также сразу же создадим файл settings.py в папке app. Структура проекта должна выглядеть следующим образом:
├── app
│ ├── __init__.py
│ ├── forum
│ │ ├── __init__.py
│ │ ├── routes.py
│ │ └── views.py
│ └── settings.py
├── templates
│ └── index.html
├── config
│ └── config.yaml
├── main.py
└── requirements.txt3 — Работаем с файлами конфигурации приложения
В файл config.yaml добавим следующую конфигурацию:
common:
port: 8080 # порт, на котором будет запускаться наше приложение
postgres:
database_url: postgres://forum_user:forum_password@localhost/forum
require_ssl: false # стоит ли шифровать соединение с базойТеперь нам надо научиться как-то работать с этими данными. Для этого откроем файл app/settings.py и запишем в него:
import pathlib
import yaml
BASE_DIR = pathlib.Path(__file__).parent.parent
config_path = BASE_DIR / "config" / "config.yaml"
def get_config(path):
with open(path) as f:
parsed_config = yaml.safe_load(f)
return parsed_config
config = get_config(config_path)Теперь в глобальной переменной config хранится словарь с конфигурацией. Например, чтобы получить порт, нам нужно обратиться к config[“common”][“port”].
Давайте прикрепим config к нашему приложению. Приведем файл main.py к следующему виду:
import aiohttp_jinja2
import jinja2
from aiohttp import web
from app.settings import config, BASE_DIR
def setup_config(application):
application["config"] = config
def setup_external_libraries(application):
aiohttp_jinja2.setup(
application,
loader=jinja2.FileSystemLoader(f"{BASE_DIR}/templates"),
)
# настроим url-пути для доступа к нашему будущему приложению
def setup_routes(application):
from app.forum.routes import setup_routes as setup_forum_routes
setup_forum_routes(application)
def setup_app(application):
setup_config(application)
setup_external_libraries(application)
setup_routes(application)
app = web.Application() # инстанцируем наш веб-сервер
if __name__ == "__main__":
setup_app(app)
web.run_app(app, port=config["common"]["port"])После этого шага мы можем обратиться к app[“config”] и получить доступ к нашему конфигурационному файлу из любого места в приложении.
4 — Подключаемся к базе данных и пишем свой Accessor
Аксессор — сущность, которая помогает работать с данными, находящимися вне памяти приложения, например, бывает аксессор к базе данных или аксессор к стороннему API. В аксессоре сокрыты детали реализации, такие как установка соединения, выполнение SQL-команд, парсинг ответа и т.д. Остальной код приложения не должен "знать" о реализации того или иного метода аксессора, он просто должен вызвать метод и взаимодействовать со сторонним источником данных в удобной форме.
Давайте создадим подключение к базе данных. Для этого в папке app/ создадим еще один модуль store/, в которой будут хранится наши аксессоры. Добавим в папку app/store/database три файла и не забудем добавить файл __init__.py в store/database:
accessor.py — здесь будет располагаться код для подключения к базе
models.py — здесь находится входная точка для наших моделей, о которых будет сказано ниже
Теперь структура вашего проекта должна выглядеть следующим образом:
├── app
│ ├── __init__.py
│ ├── forum
│ │ ├── __init__.py
│ │ ├── routes.py
│ │ └── views.py
│ └── store
| ├── __init__.py
│ └── database
│ ├── __init__.py
│ ├── accessor.py
│ └── models.py
├── templates
│ └── index.html
├── configs
│ └── config.yaml
├── main.py
└── requirements.txtФайлы __init__.py оставьте пустыми, они нужны лишь как признак python-модуля.
В файл accessor.py добавим следующий код:
from aiohttp import web
class PostgresAccessor:
def __init__(self) -> None:
from app.forum.models import Message
self.message = Message
self.db = None
def setup(self, application: web.Application) -> None:
application.on_startup.append(self._on_connect)
application.on_cleanup.append(self._on_disconnect)
async def _on_connect(self, application: web.Application):
from app.store.database.models import db
self.config = application["config"]["postgres"]
await db.set_bind(self.config["database_url"])
self.db = db
async def _on_disconnect(self, _) -> None:
if self.db is not None:
await self.db.pop_bind().close()
Давайте кратко рассмотрим содержание этого файла. Мы создали класс PostgresAccessor, который отвечает за подключение к базе данных и отключение после завершения работы.
Функция _on_connect берет данные о базе из конфигурационного файла и с помощью команды db.set_bind(self.config[“database_url”]) создает необходимое подключение к базе. Если указана неверная конфигурация базы, или по какой-то причине подключение невозможно, то функция бросит исключение, и сервер не запустится.
Важно, чтобы проблемы с подключением к необходимым для работы сторонним сервисам были видны на этапе запуска приложения — это позволит сразу же среагировать на проблему или откатиться к предыдущей версии приложения, а потом уже решать проблему.
Функция _on_disconnect позволяет отключиться от базы после завершения работы приложения и освободить ресурсы базы, например “правильно” разорвать соединение с ней.
Отдельно рассмотрим функцию on_setup — в ней мы используем сигналы aiohttp. Сигналы — это некоторые сообщения, которые говорят об изменении состояния приложения.
Например, необходимо создать подключение к базе в момент старта приложения. Для этого мы можем просто добавить в список application.on_startup новую функцию. При запуске приложение aiohttp автоматически пройдет по этому списку и вызовет все функции в порядке добавления. То же самое можно сделать с _on_disconnect, добавив этот метод в список application.on_cleanup — при остановке приложения aiohttp автоматически вызовет эту функцию и отключится от базы данных.
5 — Инстанцируем Gino
Теперь в models.py нужно добавить код:
from gino import Gino
db = Gino()Это очень важный файл. Он инстацирует экземпляр Gino, с помощью которого мы можем выполнять команды в базе и еще множество других вещей. Мы создаем экземпляр Gino глобально, так как он необходим для проведения миграций.
Чтобы понять, что такое Gino и зачем он нужен, посмотрите на картинку ниже. Зеленым цветом обозначены асинхронные объекты, а желтым — синхронные:

Разберемся по шагам.
1. База данных слева может получать команды и отдавать данные по так называемому DB API, которое основано на собственном протоколе работы.
2. Чтобы выполнить SQL-скрипт из Python, необходимо установить пакет, который умеет работать с DB API. Самый популярный пакет — Psycopg. Но проблема в том, что он синхронный: когда запрос уйдет в базу, необходимо дождаться ответа. Во время ожидания никакой другой код выполнен не будет. Для решения этой проблемы создан Asyncpg — обертка над Psycopg, которая позволяет сделать его асинхронным.
Важно понимать, зачем необходимо асинхронное соединение с базой данных. Пример: мы решили посчитать статистику всех продаж магазина за несколько лет. База выполняет подсчет за 20 секунд. На эти 20 секунд синхронный python-код остановит свою работу и не сможет обрабатывать запросы от других пользователей. Говоря по-простому, сервер просто «зависнет». Асинхронное соединение «заморозит» дальнейшее выполнение функции, сделавшей запрос к базе, пока не дождется ответа, и продолжит выполнять другую работу — например, обслуживать другие запросы клиентов.
3. Достаточно неудобно писать SQL-команды вручную. Гораздо быстрее, надежнее и безопаснее писать с использованием Python-кода, хотя из-за этого немного теряется производительность. Для этого существует пакет SQLAlchemy, который позволяет удобно работать с базой, генерируя SQL-команды по нашему Python-коду и не только. К сожалению, по умолчанию SQLAlchemy синхронный пакет, поэтому появляется необходимость в еще одной обертке — Gino.
4. Gino — последнее звено, после которого наше асинхронное приложение наконец-то может асинхронно общаться с базой.
SQLAlchemy, начиная с версии 1.4 поддерживает asyncio "из коробки", поэтому острая необходимость в Gino в асинхронных приложениях отпадает. Но Gino продолжает развиваться и добавляет функционал в SQLAlchemy, поэтому не стоит сбрасывать его со счетов. Подробнее о жизни после SQLAlchemy 1.4 можно прочитать здесь.
Осталось привязать к нашему приложению PostgresAccessor. Добавим подключение аксессора в main.py, написав функцию setup_accessors и изменив код setup_app:
...
from app.store.database.accessor import PostgresAccessor
def setup_accessors(application):
application['db'] = PostgresAccessor()
application['db'].setup(application)
def setup_app(application):
setup_config(application)
setup_accessors(application)
setup_external_libraries(application)
setup_routes(application)
...6 — Создаем модель сообщения
В реляционных базах данных информация хранится в таблицах. Работать с ними не совсем удобно. Чтобы сделать работу с данными более удобной и прозрачной, создают модели — некие абстракции над данными, которые человек воспринимает лучше, чем строка таблицы. Удобство не единственная причина использования моделей, они также позволяют задавать структуру базы данных из кода и добавляют уровень абстракции.
В нашем проекте нам нужно создать модель сообщения, в которой будет хранится такая информация:
Id сообщения — для уникальности и сортировки сообщений
text — сам текст сообщения
created — дата и время создания сообщения
Хранить эти данные мы будем в таблице Message:
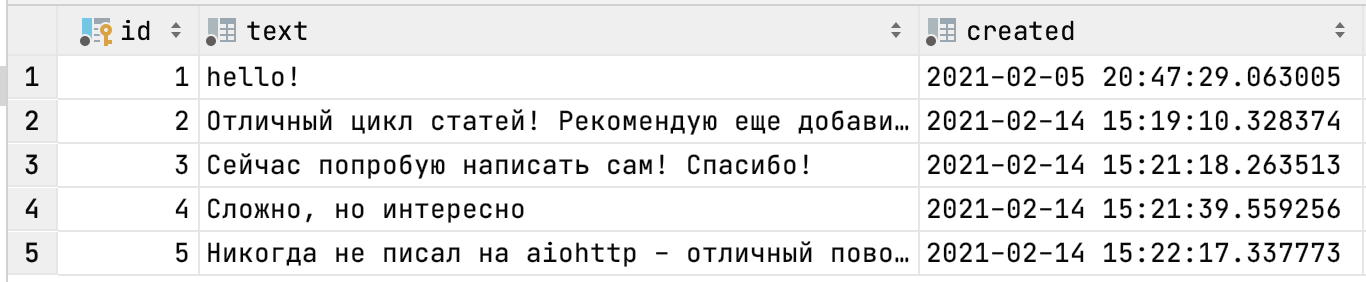
Конечно, можно создать эту таблицу вручную, но это не очень удобно и безопасно при запуске приложения из нового места или если проект ведут несколько разработчиков. Если из-за ошибок в коде структуры базы данных будут несколько различаться это может привести к серьезным и трудно-исправляемым сбоям сервиса. Миграции призваны решить данную проблему.
Миграции — это набор операций, которые надо применить к базе, чтобы привести ее в необходимое состояние. С помощью них можно как повысить, так и понизить версию структуры базы данных.
Пример: можно выполнить миграцию и создать новые таблицы, а в случае ошибки откатить миграцию обратно и удалить таблицы.
При таком подходе несколько разработчиков могут изменять структуру базы параллельно — каждый создает необходимые ему миграции, а во время слияния кода эти миграции объединяются и дают структуру базы, которая удовлетворяет всем новым условиям. Если же мы планируем запустить наше приложение в новом месте, то достаточно выполнить все миграции, чтобы получить новейшую структуру базы.
Подошло время написать нашу первую модель Message. Для этого в папке forum/ создадим файл models.py и вставим в него следующий код:
from app.store.database.models import db
class Message(db.Model):
__tablename__ = "message"
id = db.Column(db.Integer, primary_key=True)
text = db.Column(db.String, nullable=False)
created = db.Column(db.DateTime, nullable=False)Этим кодом мы декларативно задали, данные каких типов хотим хранить в таблице message. Также наша модель стала наследником db.Model, где db — экземпляр Gino. Теперь у нас все готово, чтобы сгенерировать первую миграцию.
7 — Генерируем миграцию
Когда нам нужна работа с миграциями, на помощь приходит пакет Alembic. Он позволяет автоматизировать процесс применения миграции и их создание.
Наша миграция будет содержать создание таблицы message со всеми необходимыми полями. Для этого в корне нашего проекта выполним следующую команду:
alembic init migrationsЕсли все правильно, в корне вашего проекта должны появиться директорий migrations и файл alembic.ini. Alembic может работать, ничего не зная о наших моделях, которые заданы в коде — но тогда теряется возможность автоматической генерации миграций. Чтобы дать возможность Alembic «познакомиться» с нашим кодом, необходимо сделать два действия:
В файле alembic.ini заменить строку
sqlalchemy.url = driver://user:pass@localhost/dbnameна
sqlalchemy.url = Noneи сохранить файл.
2. Заменить код файла migrations/env.py на следующий:
from logging.config import fileConfig
from alembic import context
from sqlalchemy import create_engine
from app.settings import config as app_config
from app.store.database.accessor import PostgresAccessor
from app.store.database.models import db
config = context.config
fileConfig(config.config_file_name)
target_metadata = db
def run_migrations_online():
# Alembic видит только те модели, которые импортированы в момент генерации миграции.
# PostgresAccessor инстанцируется и импортит все нужные модели, тем самым позволяя автогенерировать миграции
PostgresAccessor()
connectable = create_engine(app_config["postgres"]["database_url"])
with connectable.connect() as connection:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
run_migrations_online()Этими действиями мы привязали к конфигурации Alembic конфигурацию нашего приложения. Теперь Alembic знает о наших моделях.
Чтобы сгенерировать миграцию, надо в корне выполнить следующие команды:
export PYTHONPATH=.
alembic revision -m 'create table Message' --autogenerateКоманда export необходима, чтобы Alembic смог понять, о каком приложении мы говорим, так как оно может не находиться в PYTHONPATH — директориях, где python ищет свои модули.
Флаг -m во второй команде позволяет задать человекочитаемое название миграции, чтобы сделать назначение миграции понятнее.
Если все прошло успешно, то в папке migrations/versions появится файл примерно с таким названием: 6356fd90ab82_create_table_message.py. Код в начале названия — уникальный идентификатор миграции, который используется для сопоставления миграции и состояния базы, а также для того, чтобы обеспечить верный порядок применения миграций.
Давайте рассмотрим фрагменты этого файла более детально:
revision = "6356fd90ab82"down_revision = None
branch_labels = None
depends_on = Nonerevision — тот же код, который хранится в названии
down_revision — код миграции, которую надо применить для того, после этой при понижении версии базы. Сейчас он пустой, так как это первая миграция в нашем проекте.
branch_labels — указывается, если несколько миграций должны быть выполнены после одной и той же родительской миграции — это может произойти например при слиянии кода нескольких разработчиков, которые создали миграции для одной и той же таблицы.
depends_on — код миграции, только после исполнения которой, может быть выполнена данная. Например, мы создали модель пользователя User и привязали ее к нашей модели Message, как автора сообщения. Тогда миграция создающая модель Message будет зависима от миграции создающую модель User, так как Message нельзя будет создать, пока не существует User.
Также стоит рассмотреть две функции из этого файла: upgrade() — вызывается при повышении версии базы данных, а downgrade() — при понижении.
Повысим версию нашей базы до последней:
alembic upgrade headТеперь при прямом подключении к БД мы можем увидеть созданную структуру:

8 — Alembic: добавляем взаимодействие с базой данных
В последнем шаге на сегодня рассмотрим взаимодействие с базой данных: получение и создание записей. Для этого необходимо создать новый View в файле app/forum/views.py. Добавьте этот код в конец файла:
from app.forum.models import Message
class ListMessageView(web.View):
async def get(self):
messages = await Message.query.order_by(Message.id.desc()).gino.all()
messages_data = []
for message in messages:
messages_data.append({
"id": message.id,
"text": message.text,
"created": str(message.created),
})
return web.json_response(data={'messages': messages_data})В этом View мы получаем отсортированные по id сообщения в порядке убывания. Так как номера id добавляются в базу последовательно, то сначала будут отданы сообщения, добавленные последними. Затем преобразуем Python-модели в список словарей, преобразуем их в json-формат, а затем возвращаем их в ответ на запрос.
Не забудьте указать путь, по которому будет доступен данный View. В файле app/forum/routes.py в функции setup_routes() добавьте:
app.router.add_view("/api/messages.list", views.ListMessageView)Для проверки вручную добавьте вручную пару сообщений. Для этого откройте psql:
sudo docker exec -it postgres psql -U forum_userТеперь выполните команды:
\c forum
INSERT INTO message (text, created) VALUES ('Первое сообщение', NOW()), ('Второе сообщение', NOW());
\qС помощью команды \c мы подключаемся к конкретной базе данных и можем выполнять запросы к ее таблицам, например, выполнить команду INSERT .
Чтобы посмотреть имеющиеся таблицы в базе данных, после подключения к ней необходимо выполнить команду \d:
forum=# \d
List of relations
Schema | Name | Type | Owner
--------+-----------------+----------+------------
public | alembic_version | table | forum_user
public | message | table | forum_user
public | message_id_seq | sequence | forum_userЗаметьте, что у нас существуют две таблицы и одна последовательность:
alembic_version — в ней хранится номер последней примененной к базе миграции, которая должна соответствовать префиксу в последнем примененном файлом миграции:
forum=# select * from alembic_version;
version_num
--------------
d7c499ade9c2message — таблица, где содержатся данные о сообщениях:
forum=# select * from message;
id | text | created
----+------------------+---------------------------
1| Первое сообщение | 2021-03-11 22:53:00.15665
2| Второе сообщение | 2021-03-11 22:53:00.15665message_id_seq — последовательность, которая используется для генерации новых id сообщений в базе.
Теперь, запустив наше приложение командой python main.py в корне проекта и перейдя в браузер по ссылке 0.0.0.0:8080/api/messages.list, мы должны увидеть такую картину:

Готово! Мы получили данные, которые хранятся в нашей базе и передали их в ответ на запрос.
Чтобы добавить данные не вручную, создайте еще один View. Откройте файл app/forum/views.py и добавьте в конец следующий код:
from datetime import datetime
class CreateMessageView(web.View):
async def post(self):
data = await self.request.json()
message = await self.request.app["db"].message.create(
text=data['text'],
created=datetime.now(),
)
return web.json_response(
data={
'message': {
'id': message.id,
'text': message.text,
'created': str(message.created),
},
},
)Можно заметить, что в этом коде мы создаем новое сообщение в базе данных — то есть записываем новую строчку в базу, а затем возвращаем созданное сообщение обратно.
Отдельно остановимся на том, как мы получаем данные извне: строчка data = await self.request.json() позволяет получить json-информацию, которая пришла вместе с запросом. Почему нам приходится использовать await для получения данных из объекта запроса? Дело в том, что aiohttp стремится оптимизировать взаимодействие с сетью и не получать данных больше того, что необходимо в данный момент.
Пример: мы можем получить первый HTTP-пакет запроса и увидеть, что метод запроса неверен. Тогда мы не будем выполнять дальнейшие операции, или читать небольшими порциями, а не считывать все данные запроса целиком.
Изначально объект self.request— это информация из первого считанного HTTP-пакета (их может быть несколько, если данных много), поэтому в нем сразу же доступны метод запроса, заголовки и адрес отправителя. Для получения тела запроса необходимо выполнить асинхронную операцию, после выполнения которой в data будет находиться обычный Python-словарь.
Добавим путь к нашему новому View в app/forum/routes.py в функции setup_routes():
app.router.add_view("/api/messages.create", views.CreateMessageView)9 — Добавляем новые возможности в интерфейс
При добавлении нового сообщения мы используем HTTP-метод POST, что является правильным при запросе на создание новой информации. Браузер при выполнении запроса из поисковой строки выполняет GET-запрос. Поэтому если мы попробуем выполнить 0.0.0.0:8080/api/messages.create, получим следующую ошибку:

Давайте добавим в наш интерфейс функции, которые будут отображать сообщения из нашего ListMessageView и создавать новые сообщения, используя CreateMessageView. Для этого в файл templates/index.html добавьте код, располагающийся по этой ссылке, сразу после строчки </body>, заменив имеющийся <script>…</script>.
Теперь откроем в браузере 0.0.0.0:8080 и увидим следующее:
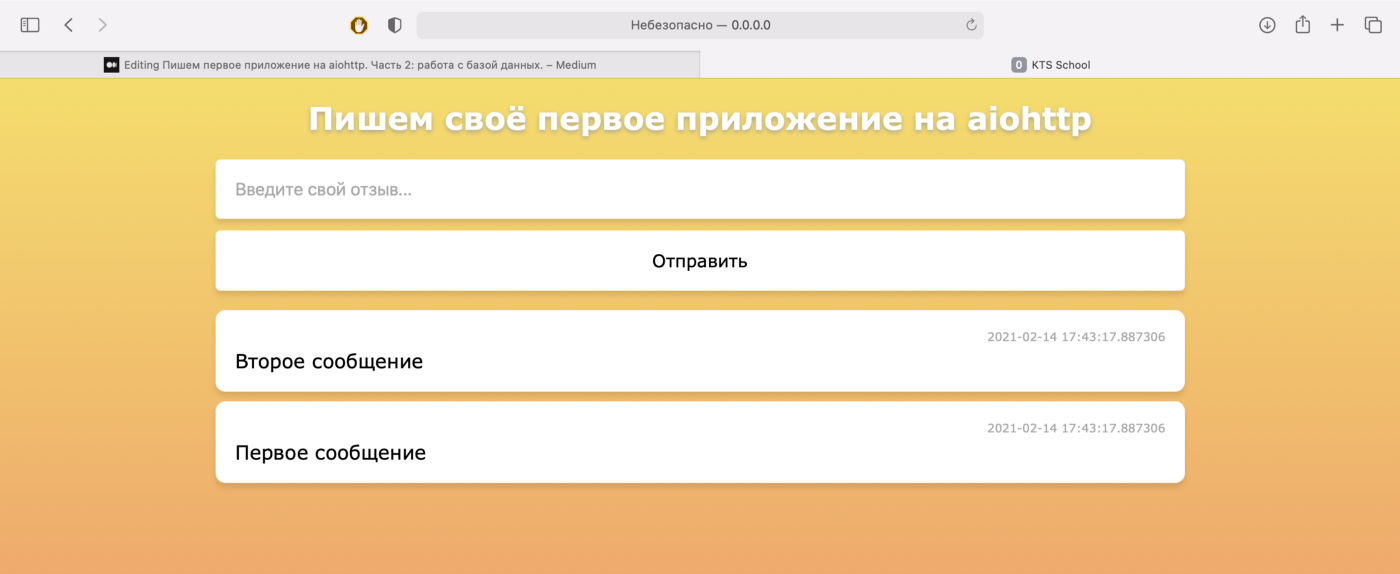
Если мы введем и отправим сообщение, оно отобразится на странице и сохранится в базе.
10 — Резюме
Подведем итоги. В этой статье мы:
Научились поднимать базу данных PostgreSQL в Docker-контейнере
Поработали с файлами конфигурации приложения
Написали свой Accessor, который позволил нашему приложению получать данные из сторонних источников. По аналогии с ним можно создать каналы получения данных из других источников, например из стороннего API.
Создали модель Message, абстракцию над «сухой» строчкой в таблице базы данных
Узнали как асинхронно общаться с PostgreSQL из Python
Настроили alembic и с его помощью сгенерировали первую миграцию
Обратились из Python-кода к данным в нашей базе данных и отдали их в виде HTTP-ответа
Код для второй части статьи находится в этом репозитории.
Асинхронное программирование — большая тема. Если хотите разобраться в ней подробнее, приходите к нам на курс. Занятия начнутся 18 октября, а 22 сентября мы проведем вебинар, на котором расскажем, что будет в программе.
Комментарии (12)

TyVik
22.09.2021 17:13+1Но ведь алхимия 1.4 уже асинхронная, даже core. Нужна ли всё ещё дополнительная обёртка в виде Gino?

adbakulev Автор
22.09.2021 22:00+1Добрый день!
Да, действительно SQLAlchemy, начиная с 1.4 уже имеет встроенную поддержку asyncio, что позволяет не использовать Gino в большинстве asyncio-проектов. При этом в статье мы рассказываем про Gino по двум причинам:
1) Gino не только обеспечивает асинхронность для SQLAlchemy - он также добавляет различные фичи, поэтому он не станет "мертвым грузом" в проекте. Вот, например, что пишут сами разработчики Gino по поводу добавления поддержки asyncio в SQLAlchemy и как они планируют развивать Gino дальше: https://python-gino.org/docs/en/1.0/how-to/faq.html#sqlalchemy-1-4-supports-asyncio-what-will-gino-be
2) Большинство проектов нашей компании используют Gino, так как стартовали до выхода SQLAlchemy 1.4. Эту статью мы даем студентам наших курсов - потенциальным будущим стажерам - в качестве доп. материала и поэтому нам хотелось бы, чтобы они учились тому, что используем мы.
Спасибо за вопрос, добавлю в статью упоминание о SQLAlchemy 1.4 для полной картины

mariner
23.09.2021 00:00+2Я тут недавно запилил мини обёртку над алхимией 1.4 - https://github.com/alex-oleshkevich/aerie
Может найдётся полезной, хоть и сырая ещё.

armature_current
04.10.2021 11:52Спасибо за туториал. Очень увлекательно для новичка. Есть пара советов для тех, кто будет с нуля повторять по шагам:
1. SQLAlchemy по умолчанию встанет версией, несовместимой с Gino - надо переставить, какую pip подскажет. Иначе генератор миграций не будет работать
2. В тексте пропущен момент, что надо еще реализовать функции upgrade() и downgrade(). Реализации не сложные, найти можно в репозитории с исходникамиadbakulev Автор
04.10.2021 14:02Спасибо большое за замечания!
В ближайшем времени добавлю их в статью.
adbakulev Автор
05.10.2021 19:36Начал добавлять к статье Ваши замечания и понял, что они не совсем актуальны:
1. SQLAlchemy по материалам статьи не устанавливается явно - она устанавливается, как зависимость Gino, что гарантирует, что версия SQLAlchemy будет совместима с версией Gino.
2. Действительно функции upgrade() и downgrade() можно написать самостоятельно, но по материалам статьи они автогенерируются связкой SQLAlchemy + Alembic (см. 7 — Генерируем миграцию)
В любом случае постараюсь побольше акцентировать внимание на этих вещах. Еще раз спасибо!armature_current
05.10.2021 23:34Спасибо за отклик. Я все же на своем буду настаивать
1. В вашем requirements.txt alembic указан выше Gino, поэтому вероятнее всего сначала будет удовлетворена зависимость alembic. Если посмотреть выхлоп pipdeptree:SQLAlchemy==1.3.24 - alembic==1.5.2 [requires: SQLAlchemy>=1.3.0] - gino==1.0.1 [requires: SQLAlchemy>=1.2.16,<1.4]видно, что встанет версия >=1.3.0 и скорее всего самая последняя стабильная
2. Я не про то, что их самостоятельно писать надо. Они генерируются, но пустые, т.е. в теле функции только
pass. Может я что-то делаю не так?adbakulev Автор
15.10.2021 16:32Добрый день!
1. Вы правы, порядок модулей в requirements.txt неверен, поправил.
2. Здесь мной также допущена ошибка, миграции действительно не автогенерировались в таком окружении. Дело в том, что Alembic видит только те модели, которые были импортированы в момент генерации миграций. Соответственно в коде статьи модель Message не была импортирована и Alembic ее не видел. Скорее всего импорт был, но так как явно его ничего не использовало, то он был убран при оптимизации. Чтобы таких ситуации больше не возникало и миграции могли быть автоматически сгенерированы, я добавил в функцию run_migrations_online в файл migrations/env.py импорт и инстанцированиеPostgresAccessor, который в свою очередь импортирует все нужные модели. Теперь модели будут в памяти при генерации миграций и импорт будет использован явно.
Большое спасибо Вам, что заметили ошибки и настояли на своем мнении!

script1
15.10.2021 16:47def setup_routes(application): from app.forum.routes import setup_routes as setup_forum_routesasync def _on_connect(self, application: web.Application): from app.store.database.models import dbвы действительно учите новичков вот таким подходам?
adbakulev Автор
15.10.2021 17:06+1Добрый день!
Если Ваше замечание касается локальных импортов, то Вы правы - здесь они излишни. Видимо они были добавлены в первую итерацию написания кода для этой статьи и в свое время "развязывали" циклические импорты. В текущей версии кода они не нужны, поправил это, спасибо за замечание.
Для новичков можно сказать, что использования локальных импортов необходимо в двух случаях:
1. При кольцевых импортах. То есть когда разные модули вашего приложения импортят друг друга по кругу.
2. Для повышения скорости первоначального запуска вашего приложения. "Ленивые" импорты позволяют не загружать при запуске все модули, а подгружать их по мере необходимости.
Критической ошибки в локальных импортах нет - код в большинстве случаев будет исполняться как и задумано. Хочу заметить три нюанса из моей практики, связанных с локальными импортами:
1. В одном файле два объекта могут импортировать один и тот же модуль локально - соответственно он будет импортирован два раза локально, вместо одного глобального, что повлияет на производительность.
2. Сколько раз будет исполнен код с импортом - столько раз модуль будет импортирован. Это может повлиять на производительность. В статье функции с локальными импортами исполняются один раз, поэтому разницы между глобальным и локальным импортом немного.
3. Импорт наверху файла улучшает читаемость кода - при взгляде на файл, сразу видно что он использует и с чем он связан.
Mopckou
Хорошая статья, полезно будет для новичков