
Дано
У нас есть две таблицы с условными названиями «Прайс1» и «Прайс2».


Обе имеют расширение .xlsx и открываются программой excel без каких-либо дополнительных действий. Но есть проблема — таблицы доступны в формате read-only дабы никто кроме владельца не мог изменить данные. Поэтому, для того, чтобы начать применять какие-либо формулы в самих таблицах необходимо таблицы продублировать, сохранив их дубликаты.
Вторая проблема — позиции товаров перемешаны, идут не в алфавитном порядке и вообще могут иметь разное количество позиций наименований.
И проблема третья — столбец с количеством товара не обязательно следует за столбцом с наименованиями товаров.
Как сравнить данные таблицы с наименьшими трудозатратами и сделать, так чтобы это сравнение легко адаптировалось под иные вводные?
Какие предложения от excel ?
Как правило, в задачах подобного рода применяется функция ВПР.
Например формула может выглядеть следующим образом:
=ЕСЛИОШИБКА(ВПР(F4;$B$3:$C$5;2;0);0)Логика следующая: берем позицию в Прайсе2 и ищем ее по Прайсу1, выводя значение.
Однако, этот вариант работает не для всех случаев: если в Прайсе2 нет позиции, которая была в Прайсе1, формула не работает —

Формула посложней
Она повторяет предыдущую, но уже учитывает значение (количество товара) при поиске.
=ЕСЛИ(ЕСЛИОШИБКА(ВПР(F3;$B$3:$C$5;2;0);0)=G3;"";ЕСЛИОШИБКА(ВПР(F3;$B$3:$C$5;2;0);0))Но она также бесполезна, если позиция выбыла в Прайсе2:

И третий вариант формулы
Для небольшого удобства прайсы разнесены по разным листам одной таблицы, а сама итоговая таблица на третьем листе.
Для ячеек в столбце с Прайсом1 формула примет вид:
=ЕСЛИ(ЕНД(ВПР(A2;'D:\Users\al\Desktop\[Прайс1.xlsx]Лист1'!$B$3:$B$5;1;0));"Нет";ВПР(A2;'D:\Users\al\Desktop\[Прайс1.xlsx]Лист1'!$B$3:$C$5;2;0))Для ячеек в столбце с Прайсом2:
=ЕСЛИ(ЕНД(ВПР(A2;'D:\Users\al\Desktop\[Прайс2.xlsx]Лист1'!$B$3:$B$5;1;0));"Нет";ВПР(A2;'D:\Users\al\Desktop\[Прайс2.xlsx]Лист1'!$B$3:$C$5;2;0))Выглядит это следующим образом:

Здесь видно, что формула учитывает моменты, если в Прайсах пропадают или появляются позиции. В таблице они обозначены словом «Нет».
Формула работает. Но, помимо ужасающих размеров, она имеет одно «но», точнее два «но».
Чтобы все работало корректно, необходимо:
- правильно указать диапазоны из Прайсов (выделить их в Прайсах Ctrl+Shift+Enter и перенести в формулу);
- позиции товаров в финальной таблице должны идти с учетом всех выбывших и/или прибывших позиций в обоих Прайсах. Сама формула не будет искать эти позиции в Прайсах и в вставлять в итоговую. Она просто берет наименование в итоговой таблице и ищет его в Прайсах, записывая количество товара и/или его отсутствие.
Неудобно.
Посмотрим, что предлагает python.
Python в деле
Решение №1
Можно пойти через использование библиотеки openpyxl и тогда решение будет выглядеть примерно так.
*Код написан не для прайсов, но для вычисления прямого и косвенного владения в компаниях, но логика та же.
import openpyxl,pprint
from openpyxl.utils import get_column_letter,column_index_from_string
wb = openpyxl.load_workbook('Прайс1.xlsx')
sheet=wb.get_active_sheet()
wb2 = openpyxl.load_workbook('Прайс2.xlsx')
sheet2=wb2.get_active_sheet()
h = open('struct.txt','a')
test={}
test2={}
test3=[]
poisk=str(input('компания: '))
#test - словарь из "кто владеет:номер строки)
for row in sheet['A2':'A290']:
for cellObj in row:
i = cellObj.value
b = cellObj.row
test.setdefault(i,b)
#test2 - словарь из "кем владеют:номер столбца)
for row in sheet['B1':'HH']:
for cellObj in row:
i = cellObj.value
b = cellObj.column
c = column_index_from_string(b) #переводим названия столбцов excel в цифры
test2.setdefault(i,c)
print('\n'+'прямое владение')
# прямое владение
for row1 in sheet['B2':'HH290']:
for cellObj in row1:
if cellObj.value ==None: #пропускаем пустые значения в клетках
continue
i = float (cellObj.value)/100 #A в B
s =sheet.cell(row=cellObj.row,column=1).value
if s!=poisk:
continue
d=sheet.cell(row=1,column=column_index_from_string(cellObj.column)).value #B (кем владеют)
for k,v in test.items():
for u in range (2,217): # все значения- B2:F6
if sheet.cell(row=v, column=u).value ==None:
continue
b = sheet.cell(row=v, column=u).value # % владения
q=float('{:.5f}'.format(i*100))
y=sheet.cell(row=1,column=u).value #кем владеют
p=s+' владеет '+ d +' - '+str(q)+'%'
if p not in test3:
test3.append(p)
print(p)
h.write(p+'\n')
print('\n'+'1-е косвенное участие')
# 1-е косвенное участие
for row1 in sheet['B2':'HH290']:
for cellObj in row1:
if cellObj.value ==None: #пропускаем пустые значения в клетках
continue
i = float (cellObj.value)/100 #A в B
s =sheet.cell(row=cellObj.row,column=1).value
if s!=poisk:
continue
d=sheet.cell(row=1,column=column_index_from_string(cellObj.column)).value #B (кем владеют)
for k,v in test.items():
if d in k: # если кем владеют, есть в кто владеет - то ищем по строке значение
for u in range (2,217): # все значения
if sheet.cell(row=v, column=u).value ==None:
continue
b = sheet.cell(row=v, column=u).value # % владения
q=float(i)*float(b) #процент косвенного владения A через B в С
q1=float('{:.5f}'.format(q)) #5 знаков после запятой и * 100
y=sheet.cell(row=1,column=u).value #кем владеют
print (' через '+ d + ' в ' + y +' - '+str(q1)+'%')
h.write(s+' через '+ d + ' владеет ' + y +' - '+str(q1)+'%'+'\n')
h.write('\n')
Программа собирает все наименования и количество товара по ячейкам в обоих Прайсах, далее заполняет итоговую таблицу excel наименованиями и, найдя по координатам, количество товара — также и значениями количества товара.
Работает. Но громоздко и легко запутаться.
Решение №2
Воспользуемся возможностями библиотеки pandas, если она не установлена, то pip install pandas.
Импортируем библиотеку и считаем Прайсы в датафреймы(наборы данных):
import pandas as pd
df1 = pd.read_excel('Прайс1-.xlsx', sheet_name = 'Лист1')
df2 = pd.read_excel('Прайс2-.xlsx', sheet_name = 'Лист1')
Произведем слияние датафреймов, чтобы охватить случаи, когда товары исчезают/появляются как в первом Прайсе, так и во втором:
m = (df1.merge(df2, how='outer', on=['товар','Количество'],
suffixes=['', '_new'], indicator=True))
m2 = (df2.merge(df1, how='outer', on=['товар','Количество'],
suffixes=['', '_new'], indicator=True))
Создадим третий датафрейм из запросов к двум предыдущим и уберем оттуда дубликаты:
m3=pd.merge(m.query("_merge=='right_only'"), m2.query("_merge=='right_only'"), how ='outer').drop_duplicates(subset=['товар','Количество'])
Осталось сохранить новую таблицу:
m3.query("_merge=='right_only'").to_excel('out.xlsx')
На выходе мы получаем итоговую таблицу:
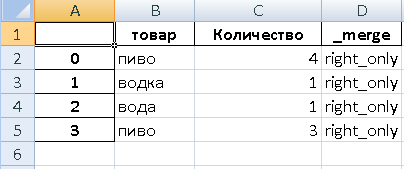
Как видно, в нее не попала позиция «сок», так как в этой позиции не произошло изменений.
Обозначены позиции «пиво» со старым и новым значениями, а также учтены позиции, которые «добавились» и «пропали» в Прайсах.
Какое из решений использовать — дело вкуса.
Однако данный вариант имеет преимущества:
- не требует перевода таблиц из «read-only»;
- нет необходимости вручную выправлять формулы по столбцам и сами таблицы.
Код и примеры таблиц можно скачать — здесь.
Надеюсь, решения, приведенные в статье, окажутся полезными.
Комментарии (14)

Cost_Estimator
24.09.2021 15:04Воспользуемся возможностями библиотеки pandas, если она не установлена, то pip install pandas.
Да, pandas не у каждого читателя может быть установлена…Можно пойти через использование библиотеки openpyxl
Зато эта библиотека есть у каждого встречного =)

SyrexS
24.09.2021 15:32По моему проще допилить эксельку, чем городить такой огород.
Там же есть много прекрасных функций перевода текста в диапазоны.
Ну или просто использовать сводные таблицы

rass5000
24.09.2021 15:38+4Есть же у Excel Надстройка Inquire, в ней есть команда Сравнить файлы.
https://support.microsoft.com/en-us/office/compare-workbooks-using-spreadsheet-inquire-ebaf3d62-2af5-4cb1-af7d-e958cc5fad42


XopHeT
24.09.2021 15:41+6Самое смешное, что в excel есть встроенный механизм сравнения 2х версий документа.
Но, в последнее время, людям проще написать скрипт на питон, чем выучить инструмент в котором они работают.


sshikov
24.09.2021 20:19+1>Решим достаточно тривиальную задачу
А потом выясняется, что и порядок столбцов, и порядок строк разные, и на самом деле задача вообще не такая, какую решает стандартное средство сравнения таблиц в Excel.
В общем, мне кажется автор просто ввел всех в заблуждение, недостаточно четко описав задачу. И стандартное средство тут похоже не применимо совсем.

osscombat
24.09.2021 21:58Какие предложения от excel ?
с 2013 версии там это делается в power query в пяток кликов.

piratarusso
27.09.2021 15:42Оба варианта работают и в принципе лучше ковыряния в excell мышкой . Есть и третий вариант ещё более простой - выгнать данные в csv файлы, их прочитать в структуру словаря, собрать ключи в 2 множества и собрать результирующий csv. Над множествами python умеет выполнять арифметические операции.

zoldaten Автор
28.09.2021 09:25Отвечу фразой одного героя из к/ф «Тени исчезают в полдень»: «Сомневаюсь я».
Операции чтения-записи не прибавят скорости,
— прогон в csv сам по себе может поселить ошибки, например, если имеются столбцы с пробелами в содержимом,
— при сборе в словари надо учесть, что меняться могут не только ключи, но и значения.
А при вычитании множеств надо иметь в виду, что вычитать придется так же(как и в задаче) дважды, т.к. множества могут оказаться неоднородными (количество ключей-значений может быть разным).
Да и на выходе из csv собирать затем excel таблицу?piratarusso
28.09.2021 12:15Строки с пробелами выгоняются как раз нормально. Проверено на довольно больших таблицах.
При сборе с в словари, нужно представлять характер данных. Если существует главный ключ, то вообще задача заметно упрощается. При загрузке в словарь как раз можно и проверить на повторение ключей. Можно и типы полей при этом проверить. На всё - про всё примерно строк 20-40 кода.
Вычитание действительно придётся выполнять как минимум дважды, для того чтобы проверить расхождение по ключам.
Сравнение содержимого полей придётся выполнять в любом случае, независимо от способа обработки.
Результирующую таблицу ( или несколько, если необходимы отчёты по плохим записям) можно тоже) в csv вывести. Ну или сразу в Excel.
Вообще, подобные задачи(анализ корректности данных) считаются довольно сложными и, конечно, Excel для подобных задач подходит плохо.
TionRus
TortoiseSvn умеет сравнивать excel файлы по-ячейкам, кроме того, если используется только эксель и все-таки нужно написать скрипт, то уместнее написать скрипт на VBA чем на питоне.
qbaddev
Вы правы.