
От переводчика. Данный текст является переводом документа Safer Usage Of C++, выложенного в общий доступ командой Chromium/Chrome из компании Google. Текст активно обсуждался на Reddit, и команда PVS-Studio решила, что аудитории Habr-а может быть интересно познакомиться с его русскоязычным вариантом. Для перевода использован текст от 20 сентября 2021, и на момент его чтения он может отличаться от текста по ссылке.
Этот документ является общедоступным. Коммиттеры Chromium могут оставить свои комментарии в исходном документе. Если вы хотите оставить комментарий, но не можете, напишите palmer@. Приятного чтения!
Авторы/Редакторы: adetaylor, palmer
Участники: ajgo, danakj, davidben, dcheng, dmitrig, enh, jannh, jdoerrie, joenotcharles, kcc, markbrand, mmoroz, mpdenton, pkasting, rsesek, tsepez, awhalley, вы!
Вступление
Службу безопасности Chrome попросили рассмотреть [ссылка только для Google, извините], как сделать C++ более безопасным. В данном документе описываются различные механизмы, которые мы можем использовать для более безопасного использования C++. Некоторые из этих механизмов радикальны. Принятие некоторых (а то и большинства) из этих механизмов может привести к тому, что код будет выглядеть совсем не так, как ожидают C++ программисты.
Большинство из предложенных механизмов представляют собой новые паттерны использования, библиотеки и классы. Однако некоторые требуют использования специфичных для компилятора флагов, которые несколько изменяют язык. Например, Chromium уже использует -fno-exceptions, и здесь мы предлагаем -ftrapv, -fwrapv или fsanitize=signed-integer-overflow.
Некоторые из этих механизмов уже используются в сборке Chromium с различным успехом. Например: устойчивый к UAF смарт-указатель MiraclePtr проходит испытания на производительность. Мы расширили использование Oilpan до PDFium, а упрочнение //base, WTF и Abseil существенно и доказало свою эффективность.
Другие механизмы, которые мы предлагаем, представляют собой значительные новые направления для C++ и Chromium и могут даже потребовать новых исследований и разработок в открытых проблемных областях (например, новые формы статического анализа).
Примечание переводчика. И вообще, кажется, команде Chromium стоит уделить больше внимания статическому анализу :). Каждый раз, когда команда PVS-Studio проверяла Chromium, выявлялось большое количество ошибок. И это не абстрактные слова. Подборки багов: 2011-1, 2011-2, 2013-1, 2013-2, 2016, 2018-1, 2018-2, 2018-3, 2018-4, 2018-5, 2018-6, 2018-7.
Язык и культура C++, как правило, предпочитают эффективность безопасности. Поэтому многие из предложенных изменений сложные, противоречивые и не такие надежные, как аналогичные изменения в другом языке. Помимо этого, иногда они могут влиять на микро- и макроэффективность (время, пространство или размер объектного кода).
Предыдущая работа
Безопасный C++ – мечта для многих.
Существует C++ Core Guidelines project и Safe C++ Tool (а также его библиотека SaferCPlusPlus и инструмент автоматического перевода).
Мы не предлагаем новый язык, но, к примеру, CCured и Cyclone были интересными попытками сделать новые варианты языка C, которые были бы совместимы с существующим C.
Также посмотрите анализ того, как маркировка памяти может изменить ситуацию с безопасностью [только для Google].
Предпосылки
Существует два основных типа безопасности памяти: пространственная и временная. Пространственная безопасность – это гарантия того, что программа будет вести себя определенным и безопасным способом, если она обращается к памяти за пределами допустимых границ. Примеры включают границы массива, доступ к структуре и объединению полей, а также доступ к итератору.
Временная безопасность – гарантия того, что программа будет вести себя определенным и безопасным образом, если она обращается к памяти, когда эта память недействительна для доступа. Примеры включают use after free (UAF), двойное освобождение, использование до инициализации и use after move (UAM). Нарушения временной безопасности часто выглядят как путаница в типах. Например, программа ошибочно использует недавно освобожденный объект Dog, как если бы это был объект Cat. (Злоумышленники часто создают полностью поддельные объекты с помощью виртуальных таблиц, что дает им контроль над работой программы).
Из этих двух типов безопасности пространственную безопасность достичь относительно проще (путем изменений в коде Chromium и/или путем упаковки целевых объектов в WASM), хотя и с некоторыми минимальными затратами на эффективность. К примеру, вам необходимо выполнить проверку границ массива, и это может стоить дороже, чем не делать это. Это чисто эмпирический вопрос, который может быть решен только в контексте реальной программы, и результаты могут удивить.
Временную безопасность достичь сложнее и дороже. Решения включают повсеместный подсчет ссылок (например Objective-C с ARC, Swift), запрет общего изменяемого состояния и встраивание borrow-checker в компилятор (например, Rust) или полностью базовую сборку мусора (Go, JavaScript и другие).
Мы считаем, что, учитывая достаточную терпимость к регрессиям микроэффективности, мы могли бы существенно устранить пространственную небезопасность C++ в собственном коде. Мы могли бы сделать это (и уже начали делать) с помощью комбинации изменений и дополнений библиотеки, опций компилятора, правил политики/стиля и проверок перед отправкой (включая запрещенные и поощряемые классы и конструкции). Учтите, что хотя это возможно и обычно относительно легко технически, эта работа вызывает споры в сообществах C++, включая Chromium.
Мы не можем исключить или устранить временную небезопасность C++ без принятия одного из известных решений, например, сборки мусора. Микроэффективная и эргономичная временная безопасность остается открытой проблемой в разработке ПО. Однако, при некоторых потенциально значительных затратах на эффективность мы можем снизить распространенность и возможность использования временной небезопасности. *Scan – это многообещающая возможность, с которой мы экспериментируем.
Неопределенное поведение
Большая часть проблем C/C++ связана с неопределенным поведением (undefined behavior, UB), встроенным в спецификации языка и библиотеки. (Даже совсем недавние языковые дополнения продолжают традицию.) Пространственная и временная безопасности являются подтипами неопределенного поведения; другие примеры включают переполнение целых чисел со знаком. Простое перечисление всех неопределенных поведений в C++ является открытым проектом.
Авторы компилятора видят неопределенное поведение как возможность для микрооптимизации, в то время как злоумышленники рассматривают неопределенное поведение как возможность для эксплуатации.
Для программного обеспечения, работающего в непредсказуемой и даже враждебной среде, такой как Интернет, все шире признается, что написание надежного и безопасного ПО на C/C++ является чрезвычайно сложной задачей из-за множества форм неопределенного поведения, связанных с безопасностью и эргономикой.
Цель данного документа
Учитывая это, наша цель состоит в том, чтобы перечислить некоторые вероятные шаги, которые участники Chromium могли бы предпринять для уменьшения общего эксплуатируемого и неэргономичного UB при использовании C++ в Chromium.
Невозможно полностью "починить" C++ без его фундаментального переопределения. Это не наша цель здесь. Вместо этого мы хотим выявить и сократить некоторые из наиболее стойких и эффективных типов небезопасных UB при использовании Chromium.
Приоретизация и мотивация
Вот руководство по относительной важности каждого из решений, обсуждаемых в этом документе. Это чистое количество ошибок, но обратите внимание, что злоумышленники предпочитают использовать разные классы ошибок:

(источник; ссылка только для Google, но результаты воспроизводимы с общедоступного багтрекера)
Предложения и текущая работа, описанные в остальной части этого документа, примерно упорядочены по тому, какое влияние они могут оказать на наши наиболее значимые классы ошибок.
Управление ожиданиями
Обратите внимание, что многие из этих предлагаемых и незавершенных проектов являются довольно крупными и сложными, даже меняя семантику C++. Пока мы думаем, что большинство из них необходимы, мы также знаем, что этого недостаточно. Такова природа проблемы C++.
С этими словами, представляем их вам.
Удаление/уменьшение сырых указателей
Проблема: Ручное управление временем жизни и владением оказалось слишком сложным для того, чтобы даже очень опытные инженеры могли надежно выполнять правильные действия. Это приводит к ошибкам UAF, а также к утечкам памяти.
Решение: Запретить прямое использование сырых указателей, new и delete. Вместо этого попросите разработчиков использовать, например, одну из реализаций MiraclePtr. Обратите внимание, что упаковка указателей в некотором синтаксисе полезна для большинства подходов (Oilpan, MiraclePtr, *Scan, и др.) и ценна сама по себе.
Текущее состояние: Работа продолжается для полей T* в процессе браузера (по состоянию на август 2021 г.). Проект MiraclePtr нацелен на создание смарт-указателя, который делает UAF непригодным для использования, при этом не слишком сильно снижая производительность.
Затраты: Производительность. По состоянию на август 2021 года, мы активно оцениваем влияние нескольких внедрений, поэтому данный пункт будет уточнен. Отклонение от норм языкового сообщества С++. C++ за пределами Chrome с гораздо меньшей вероятностью примет этот подход. Следовательно, он не получит временной безопасности, которую обеспечивает MiraclePtr. Например, код Google, вставленный в Chrome, зависимости с открытым исходным кодом. Сложность диагностики сбоев — только один стек вызовов из MiraclePtr в противовес трем из ASAN: выделить, освободить, использовать. Если мы желаем применить эти меры защиты к стороннему коду, нам потребуется разветвить репозитории таким образом, чтобы другие их потребители также использовали нестандартный C++. Большинство UAF происходят в коде первой стороны. Текущие затраты на переписывание большого количества кода — конфликты слияния и т.д.
Преимущества: на UAF приходится около 48% серьезных ошибок безопасности (и число растет). MiraclePtr планирует охватить ~50% от них и теоретически может охватить еще 20% в будущем, запретив сырые указатели в контейнерах, локальных переменных и параметрах функций. На практике использование MiraclePtr в локальных переменных и критичных к быстродействию циклах может привести к непомерным затратам на производительность. Предлагаемая реализация, BackupRefPtr, включает потенциальные затраты этапа исполнения на подсчет атомарных ссылок, что все еще можно победить при помощи арифметики указателей и алиасинга.
Дополнительные сведения см. в разделе "Идеи безопасности указателей".
Тем не менее, Project Zero считает, что внутри процессов визуализации большинство UAF не являются исправлениями MiraclePtr. Вместо этого они приводят к инвалидации итераторов и другим неудачам на протяжении всего времени жизни.
Аннотирование времени жизни
Проблема: Время жизни в C++ неизвестно компилятору и его невозможно отследить с помощью статического анализатора.
Решение: В некоторых случаях мы можем аннотировать время жизни с помощью [[clang::lifetimebound]]. Этим мы сообщаем, что время жизни привязано к объекту.
Атрибут имеет много ограничений. Он не является решением для обеспечения безопасности памяти, но он может помочь в некоторых важных сценариях. Ограничения:
- Нет никакого способа провести различие между разными временами жизни.
- Нет никакого способа аннотировать статическое время жизни.
- Атрибут присоединяется к параметрам функции и всегда неявно ссылается на самый внешний ссылочный тип; его невозможно присоединить к части типа — например, к T* в const std::vector<T*>&.
- Единственное время жизни неявно применяется к внешнему ссылочному типу в возвращаемом типе функции или к значению построенного объекта, в случае конструктора. Опять же, невозможно связать время жизни с внутренними ссылочными типами в возвращаемом значении — например, T* в const std::vector<T*>&.
- Невозможно добавить параметр времени жизни в структуру. Это означает, что параметры могут быть привязаны к времени жизни объекта только в том случае, если они заданы конструктору, а не в других установщиках.
Теоретически, мы должны применить это к:
- Любому ссылочному параметру конструктора, хранящемуся в поле. Однако, в нем не хватает даже тривиальных примеров: https://godbolt.org/z/Ysq41G6vb
- Любому параметру указателя конструктора, который может содержаться в элементе const. Другими словами, указатель никогда не переназначится. Однако, в нем не хватает даже тривиальных примеров: https://godbolt.org/z/Ma7P8q8WG
- Любому методу класса, который возвращает ссылку или указатель на член класса, но, к сожалению, не на указатели внутри членов класса. Однако, в нем не хватает даже тривиальных примеров: https://godbolt.org/z/9er4WE6zK, https://godbolt.org/z/GW9j4zrdT
- Любой функции, которая получает ссылки/указатели и возвращает ссылку/указатель на свои входные данные. Это включает шаблонные функции, которые возвращают один из своих входных данных, например, min/max/clamp.
Единственный случай, когда этот атрибут действительно фиксируется только в данный момент, — это недопустимое использование временных объектов. Хотя это действительная/важная ошибка безопасности памяти, она не соответствует типу ошибок, которые мы видим в наших ошибках безопасности UAF.
- И это даже не ловит все временные:
- https://godbolt.org/z/PbnM1TY8n
- https://godbolt.org/z/aMbaq4W55
- https://godbolt.org/z/9G77fcE18
- На самом деле, трудно построить пример, который он действительно улавливает.
Некоторые ключевые потенциальные места для этого:
- конструктор base::span
- конструктов base::StringPiece
- base::clamp
- ????
- Методы, возвращающие ссылки/указатели повсюду, но только в том случае, если мы сможем показать, что аттрибут действительно помогает (см. godbolts выше для встречных примеров).
Обратите внимание, что base::span предназначен для удержания недопустимого указателя за пределами контейнера, на который он "указывает", и анализ времени жизни не может помочь в решении этой проблемы. Это проблема безопасности пространственной памяти, встроенная в C++. Но это может потенциально помочь в использовании base::span за пределами времени жизни объекта, на который он указывает, если атрибут будет использоваться не по назначению.
Текущее состояние: Работа не начата.
Затраты: Визуально зашумленные аннотации (куча макросов Abseil), присутствующие в коде. Мы познакомимся с ними поближе. Но существует много мест, где эти аннотации не могут быть использованы. Аннотация может быть написана неправильно, если она более строгая, чем требуется для объекта. Или со временем она может стать неправильной, если объект будет изменен. Например, если base::span создал метод для повторного назначения указателей.
Поскольку атрибут генерирует предупреждения только в случае обнаружения нарушения, он фактически не гарантирует, что нарушения будут обнаружены. И похоже, что большинство из них таковыми не являются (см. примеры godbolt выше). Это может создать ложное впечатление о безопасности, что может привести к тому, что разработчики попытаются полагаться на атрибут, улавливающий их ошибки, и фактически напишут больше UAF.
Кроме того, невозможно обеспечить наличие аннотаций там, где это возможно, что позволило бы писать новый код без них. Авторы кода, которые полагаются на аннотации для проверки их правильности, останутся без каких-либо проверок.
Преимущества: Ошибки компилятора при написании некоторого набора простых ошибок времени жизни.
Реализация автоматическим управлением памятью
Проблема: Временная безопасность и корректность (UAF, утечки).
Решение: Подсчет ссылок (например, подобные ARC семантики) и/или полный запуск сборщика мусора.
Текущий статус: Oilpan теперь является универсальной многоразовой библиотекой (более не специальной для Blink). Плюс мы перенесли его в PDFium для решения многих наших временных проблем безопасности в этом проекте. Например, это позволило нам выпустить поддержку XFA Forms! На данный момент, правда, она отключена по умолчанию из-за пробелов в функциональности.
Затраты: Подсчет ссылок должен быть атомарным, что потребует микрозатрат по времени. Полностью универсальный сборщик мусора может быть дорогим.
Преимущества: на UAF приходится около 48% серьезных ошибок безопасности (и число растет). Этот подход является альтернативой универсальному применению поверяемых типов указателей (см. выше). Помимо этого, сборка мусора обладает отличной эргономикой для разработчика.
Внедрение анализа владения
Проблема: Временная безопасность и корректность (UAF, утечки).
Решения: Убедитесь во время выполнения, что у любого объекта есть один "владелец", и объект может быть изменен только с помощью std::move. Разрешите заимствования с помощью Rust-подобных правил, которые предотвращают одновременное существование нескольких изменяемых ссылок и гарантируют, что доступ к объектам не будет осуществляться за пределами их времени жизни.
Решение кажется плохо подходящим для C++, но его все ещё предлагают. Поэтому его обсуждение здесь может быть важным.
Rust достигает этой модели благодаря довольно сложной поддержке компилятора. Большинство объектов не требуют затрат времени выполнения для такого рода проверки владения; всё это статично. Разработчики могут опционально вместо этого использовать версию этапа исполнения (RefCell<>), которая выполняет те же проверки во время исполнения. Мы предполагаем, что эта модель была бы слишком дорогой, если бы каждый объект отслеживался во время исполнения, и мы не видим способа обеспечить статическое исполнение во время сборки в C++ без радикальных изменений компилятора и языка. (Clang добавил ограничения на время жизни для простых случаев, но см. выше).
Текущий статус: У нас есть несколько ранних экспериментов по обеспечению соблюдения прав владения во время выполнения. Безопасность во время компиляции невозможна без фундаментальных изменений в C++, таких как новые ссылочные типы. Существует работа для ограниченной безопасности в предупреждениях Clang, которые будут улавливать висячие ссылки с помощью анализа потока управления, но, по замыслу, они не будут улавливать недопустимые указатели кучи.
Затраты: Затраты на выполнение, эквивалентные подсчету ссылок. Необходимо различать 'owner_ptr' от 'borrowed_ptr'.
Преимущества: на UAF приходится около 48% серьезных ошибок безопасности (и число растет). Этот подход является альтернативой универсальному применению проверяемых типов указателей (см. выше).
Использование -Wdangling-gsl
Google в этом добился хороших результатов, обнаруживая и исправляя ошибки UAF. Chrome тоже должен попробовать это. Есть несколько ложных срабатываний, но при этом истинных срабатываний также полно.
Определение всех стандартных моделей поведения библиотеки
(Где это возможно)
Проблема: Стандартная библиотека изобилует потенциально уязвимым неопределенным поведением. Это включает в себя отсутствие проверки границ (например, std::span::operator[]) и валидности (std::optional::operator*). Доступность std::string_view для UAF, однако, является отдельной проблемой. Это особенно прискорбно в недавних дополнениях библиотеки, потому что быстрые, но небезопасные опции уже были доступны.
Поскольку в std много неопределенного поведения, мы не можем быть уверенными в том, что используемые нами реализации будут полностью защищены от UB. Особенно по мере добавления новых функций. Вместо этого мы должны использовать замену, подобную std, на дизайн и реализацию которой мы сможем влиять более эффективно. К примеру, Abseil. В качестве альтернативы мы могли бы выделить персонал для работы с вышестоящим libcxx, чтобы обеспечить надежность и поддержку усиленного режима.
Решения: Добавьте "защищенный" режим (выбираемый во время компиляции) в реализацию стандартной библиотеки. Это позволит поменять неопределенное поведение на четко определенное и безопасное. Это довольно "легко" для пространственной безопасности. Для временной безопасности см. выше.
Текущее состояние: Команда Abseil уже добавила в Abseil режим усиления пространственной безопасности. Возможно, ему не помешал бы аудит полноты, но по состоянию на август 2021 г., выглядит довольно неплохо. Мы используем этот режим в Chromium. Аналогичный режим упрочнения для LLVM libcxx находится в процессе работы (вышестоящий). Мы также добавили пространственное упрочнение в //base (но могли бы использовать аудит полноты). WTF имеет тот же статус, что и //base.
Мы также рассматриваем проект по созданию стандартной библиотеки без UB [Ссылка пока только для Google, извините], так как нет желания делать //base автономной. Однако, Abseil с упрочнением может этого избежать. Но если есть общий интерес к библиотеке с открытым исходным кодом, std(-подобной), в которой указано, что UB отсутствует, мы могли бы выделить для этого персонал.
Затраты: Возможные микрозатраты во время выполнения из-за увеличения проверки.
Преимущества: Пространственная небезопасность составляет 16% ошибок безопасности высокой степени серьезности. Возможно, 17.5%.
Определение неопределенного поведения итераторов
Проблема: В частности, представляется важным упомянуть два класса ошибок, связанных с UB в итераторах. Спасибо Сергею и Марку из P0, что подняли эти вопросы.
for (auto& iter : my_container) {
MaybeChangeMyContainer();
}и
auto iter = my_container.find(the_thing);
DCHECK(iter != my_container.end());
iter->second->Foo();По словам Марка:
Похоже, что проблема инвалидации итераторов может быть эффективно решена.
ЛИБО заставляем контейнер отслеживать живые итераторы и "нейтрализовать" любые живые итераторы, когда происходит инвалидирующая операция. Такая операция редко выполняется со многими живыми итераторами, поэтому это должно быть довольно недорогим и повлечет за собой нулевые накладные расходы на доступ к итератору.
ЛИБО используем что-то вроде тега генерации, который будет проверяться при доступе к итератору; это добавит накладные расходы на доступ к итератору, поэтому это может быть слишком дорого?
ЛИБО, что более важно для API, мы могли бы просто ПРОВЕРИТЬ инвалидирующие операции, когда есть живые итераторы. Это было бы дешевле, но, вероятно, потребовало бы значительного тестирования и изменений кода, чтобы гарантировать, что итераторы в стеке отбрасываются, как только они перестают использоваться.
Решение: У нас есть тип CheckedIterator в //base.
Текущий статус: На практике это было дорого (из-за отсутствия поддерживаемого способа в libcxx выразить, что его можно оптимизировать), но теперь это исправлено. Мы должны расширить его использование теперь, когда мы можем сделать это эффективно. Например, должна быть возможность создать четко определенный шаблон синглтона для конечного итератора, который после поломки не затронет ничего больше.
Затраты: Надеемся, что накладные расходы во время выполнения сейчас приемлемы.
Преимущества: Меньше UB при инвалидации итераторов, включая пространственную и временную небезопасность.
Определение целочисленной семантики
Проблема: целочисленная семантика C/C++ безумна: перенос, переполнение, антипереполнение, неопределенное поведение, неявное приведение и молчаливое усечение – все это приводит к небезопасности и плохой эргономике. В результате разработчикам трудно правильно рассчитать размеры, индексы и смещения, особенно когда злоумышленник может контролировать некоторые условия. Арифметическое переполнение и антипереполнение часто приводят к ошибкам в выделении и доступе к памяти, а оттуда к уязвимым ошибкам. Другие классы ошибок также возникают из-за переполнения целых чисел, таких как перенос значений счетчика ссылок, в результате которого уникальные идентификаторы перестают быть уникальными.
Неявное преобразование из целого числа в число с плавающей точкой скрывает тот факт, что сохраненное значение может измениться. Это коварно, так как в пределах обычных диапазонов значение не меняется, но, если злоумышленник может контролировать значение целого числа, он может сделать его достаточно большим, чтобы нарушить предположение. Затем при обратном преобразовании в целое число результат становится недействительным.
Решение 1. Требуйте, чтобы разработчики использовали библиотеку //base/numerics или что-то подобное. Укажите конкретные типы для преднамеренного переноса (wrapping), насыщения (saturating) и захвата (trapping) (как это делает Rust). Нормой должно быть то, что люди по умолчанию используют надежную арифметику и в максимально возможной степени оставляют примитивную арифметику C позади. В частности, мы должны выделить некоторую численность персонала для улучшения общности и эргономики //base/numerics и превратить ее в автономную зависимость. (Она уже легко отделима от //base, но вам нужно скопировать и вставить.)
Решение 2: Мы могли бы потребовать, чтобы параметры компилятора заставляли переполнение со знаком вести себя так же, как и без знака (т. е. перенос). То есть мы могли бы принять за стандарт поведение Java и Go: мы могли бы использовать -fwrapv в отладочных и производственных сборках. В качестве альтернативы мы могли бы использовать -fwrapv в сборках выпуска и -ftrapv в отладочных сборках (например, Rust).
Решение 3. В Clang также есть параметры санитайзера, которые можно настроить для немедленного захвата, что не требует поддержки во время выполнения, для обработки деления на 0, усечения, неявного приведения и смещения влево слишком далеко, приведения целого числа к недопустимому значению enum.
Android уже использует -fsanitize=signed-integer-overflow, -unsigned-integer-overflow в больших (и растущих) частях кодовой базы.
Примечания enh@: "В сочетании с фаззингом это довольно хорошо работает, чтобы показать вам, где вам нужен __builtin_add_overflow или что-то еще. Без фаззинга это "хороший" источник для обратной передачи исправлений безопасности, если/когда что-то найдено в полевых условиях".
Решение 4. Clang выдает предупреждение о неявном преобразовании int в float, через -Wimplicit-int-float-conversion. Мы должны включить это предупреждение.
Текущее состояние: //base/numerics успешно используются во многих местах. Нам просто нужно больше им пользоваться. API нуждается в некоторых эргономических улучшениях.
Мы не используем ни -ftrapv, ни -fwrapv ни в одном файле .gn или .gni. Мы отключили предупреждение -Wimplicit-int-float-conversion.
Создайте профили, которые используют is_ubsan проверяют переполнения знакового int, и со значительным списком блокировок. Похоже, что он не включен в производственных сборках Chrome.
Расходы: Обучение. Перенос кода. Некоторые сторонние проекты (например, Skia) сопротивляются системным решениям. Потенциал для регрессии микроэффективности, если люди используют проверенную арифметику в критичных циклах. Потенциал для увеличения размера бинарных файлов, если мы поставляем UBSan с перехватом (который не требует библиотеки поддержки среды выполнения UBSan и создает небольшие, объединяемые целевые объекты для сборки веток).
Предположим, что поведение переполнения является существенным изменением в семантике C/C++. Разработчики LLVM, например, стараются избегать введения новой семантики с помощью параметров командной строки; но некоторые из них уже существуют по необходимости. Если разработчики начнут полагаться на четко определенное поведение целых чисел, код может стать ошибочным, если кто-нибудь отключит эту опцию (мы можем и должны защитить себя от этого с помощью тестов). Использование явных типов для захвата, переноса и насыщения позволяет избежать этого, но тяжело работает для зависимостей 3P и требует явных изменений для мест вызовов.
Преимущества: Переполнение целых чисел составляет около 2% наших ошибок безопасности высокой степени серьезности, хотя, возможно, это будет менее важно, если нам действительно удастся предотвратить переполнение буфера (см. ниже). Использование -fwrapv может и должно быть максимально совместимо с существующим кодом и соответствовать ожиданиям большинства разработчиков. Использование UBSan с ловушкой при сбое охватывает большинство проблем, но может потребовать некоторых сокращений и может привести к некоторой регрессии скорости и размера бинарных файлов (эмпирический вопрос). Места вызовов, которые нуждаются в явной проверке, в любом случае должны продолжать использовать //base/numerics.
Существуют также логические ошибки, такие как ожидание, что увеличивающиеся числа останутся уникальными в качестве идентификаторов, перенос значений счетчика ссылок и так далее. Опять же, отлов или санитайзер поймали бы их. С помощью Trapping<T> в //base/numerics мы могли бы статически гарантировать это.
Определение поведения и пропуск некоторых оптимизаций, основанных на неопределенном поведении целых чисел, также могут улучшить эргономику.
Установление для указателей значения null после free
Проблема: Содержимое области памяти после free не определено. Это сбивает с толку и потенциально может быть использовано зллоумышленниками.
Решение: kcc@ отмечает: "Еще одним потенциальным исследованием является обнуление (компилятором) указателей после free. После delete foo->bar добавьте foo->bar = nullptr>. Очевидно, что это исправит небольшую часть случаев (предположительная оценка: 1% – 10%); например, он не может обработать delete getBar();. Но это ~ нулевые накладные расходы и относительно легко реализовать. Патчи LLVM кружат рядом (но я не знаю текущее состояние)".
Это также поможет сделать любые подходы, основанные на GC, более эффективными.
Текущее состояние: Отсутствует.
Затраты: kcc@ говорит ~ ноль.
Преимущества: Обнаружение 1 – 10% UAF. Улучшена эргономика разработчика (modulo aliasing, теперь определяется содержимое области после освобождения и до ее повторного использования).
Определение разыменований нулевого указателя
Проблема: Разыменование нулевого указателя – это неопределенное поведение. Это является проблемой, потому что разработчики (обоснованно) готовятся к тому, что разыменование нулевого указателя приведет к прерыванию процесса вместо его продолжения. Однако иногда компилятор удаляет разыменование нулевого указателя при оптимизации. В некоторых случаях, отмена его проверки (даже при продолжении выполнения программы) может привести к гораздо худшему состоянию и стать приманкой для злоумышленников.
Например, наш смарт-указатель типа WeakPtr был уязвим к UAFs (use-after-frees): если указанный объект был уничтожен, WeakPtr::get возвращал нулевой указатель, а последующее разыменование должно было приводить к сбою программы. Однако clang правильно определил, что хранение нулевого указателя и немедленное разыменование этого указателя – неопределенное поведение. Поэтому полностью удалил нулевой указатель. WeakPtr::get фактически вернул устаревший указатель, а разыменование привело к UAF. Была найдена как минимум 1 ошибка безопасности высокой степени серьезности (исправлено с помощью явной CHECK).
Решение: Clang предоставляет флаг компилятора под названием -fno-delete-null-pointer-checks (название сложилось исторически), который определяет разыменование нулевого указателя. С этим флагом разыменования нулевого указателя никогда не оптимизируются.
Текущее состояние: Принято.
Затраты: 42 Кб Android двоичный размер (как минимум) и некоторые регрессии микро-бенчмарков в парсинге Blink.
Преимущества: С этим флагом компилятор ведет себя так, как ожидает большинство разработчиков, облегчая понимание смысла кода.
Использование паттернов кодирования для уменьшения времени жизни ошибок
Преимущества: На UAF приходится около 48% серьезных ошибок безопасности (и число растет). Улучшенные паттерны кодирования не являются надежным решением, поскольку они все еще подвержены человеческому фактору. Они могут устранить определенную часть ошибок. В сочетании с надежным решением, таким как детерминированный MiraclePtr, паттерны кодирования могут устранить некоторые (непригодные для эксплуатации) сбои.
Использование absl::variant вместо перечислений для стейт-машин
Проблема: перечисления часто используются для стейт-машин. К сожалению, перечисление не единственная часть стейт-машин — почти всегда есть дополнительные поля, которые относятся к подмножеству состояний. Эти вещи не скоординированы, что вызывает проблемы с временем жизни объекта и логические ошибки.
struct StateMachine {
enum {
CONNECTING,
CONNECTED,
DISCONNECTING,
} state;
// These fields could get out of sync with 'state':
int thing_relevant_only_when_connected;
std::string thing_relevant_only_after_connection;
};Решение: Использование absl::variant, типобезопасного размеченного объединения (tagged union). Все данные, относящиеся только к одному из состояний, должны быть связаны с этим конкретным variant.
Текущее состояние: absl::variant недавно одобрен. Не было предпринято никаких попыток внести изменения в существующий код.
struct Connecting { int thing; }
struct Connected { std::string thing; }
struct Disconnecting { std::string thing; }
auto state_machine = absl::variant<Connecting, Connected, Disconnecting>;Затраты: Неудобный синтаксис (спорный). Сложность в определении того, какие перечисления используются для стейт-машин. (Можем ли мы просто запретить все перечисления?)
Преимущества: Уменьшено количество логических ошибок и ошибок времени жизни объекта, количество которых в настоящее время не определено.
Исключение использования std::unique_ptr::get; использование общих указателей (shared pointers)
Проблема: unique_ptr поддерживает концепцию одного владельца, однако мы видим, что такие указатели содержат use-after-free ошибки, поэтому такая концепция определенно неверна. (unique_ptr действительно гарантирует уникальный deleter, необязательно уникальный owner.)
Решение: Предотвращение любых способов получения сырого указателя из unique_ptr (по мере возможности). Даже проверенных указателей: если разработчики получают какие-либо дополнительные указатели на что-то в уникальном указателе, значит он не является действительно уникальным, а разработчики должны использовать общий указатель. (Да, нам действительно приходится брать на себя расходы за подсчет ссылок.) В большинстве случаев, когда используется unique_ptr, возможно, лучше использовать base::Optional чтобы получить конструкцию в одной ячейке кучи.
Текущее состояние: Противоречит современным передовым методам, которые поощряют unique_ptr и не поощряют общие указатели.
Обратите внимание, что dcheng имеет противоположное мнение: мы, наоборот, хотим четко понимать время жизни объектов и возможность более четко определять принадлежность, лучше, чем позволяет shared_ptr/подсчет ссылок/GC:
Я думаю, что нам нужна безопасная версия сырого указателя для определения времени жизни объекта, у которого мы предполагаем наличие одного владельца. CheckedPtr – предыдущая попытка сделать это (хотя в данный момент это немного противоречит реализации MiraclePtr's)… Возможно, нам следует серьезно отнестись к этой попытке, потому что, кажется, об этом упоминалось неоднократно.
Затраты: Может оказаться, что многим объектам нужен подсчет ссылок. Но нам необходимо осуществить это чтобы повысить безопасность. Уменьшилась ясность в отношении времени жизни и времени запуска деструктора объекта. Также, было бы проще создавать циклические зависимости.
Преимущества: Уменьшение ошибок времени жизни объекта, количество которых в настоящее время не определено. Меньше выделений динамической памяти и разыменований, если мы используем композицию чаще, чем указатель.
Инициализация всей памяти
Проблема: Если программа использует переменные до их инициализации, возникают ошибки. Сюда можно включить разыменования висячих указателей и ошибки, приводящие к раскрытию информации (которой могут воспользоваться злоумышленники). Использование неинициализированной памяти также может привести к семантическим ошибкам, которые могут оказаться уязвимостями безопасности.
(Ошибки, приводящие к раскрытию информации могут возникать, когда у структур есть заполнение (padding), а в коде memcpys копирует структуру и отправляет результат другому процессу. Заполнение может быть неинициализированным. Это значит, что вне зависимости от данных, которые были там ранее, есть вероятность, что они конфиденциальны. Мы уже встречали подобные ошибки. Безусловно, чтобы исправить ошибки, приводящие к раскрытию информации, нужно правильно выполнить сериализацию структуры. Изначальная инициализация всей структуры обеспечит хорошую всестороннюю защиту).
Решения: В дополнение к хорошему, четко определенному поведению (и, следовательно, выгодному для разработчика, как показал Go), инициализация всей памяти (либо до 0, либо до некоторого значения канарейки (canary value)) устраняет ошибки с висячим указателем и семантикой, возникающие при использовании неинициализированной памяти.
В качестве альтернативы мы могли бы настроить компилятор так, чтобы он отклонял объявления переменных, у которых нет инициализатора.
Текущее состояние: vitalybuka@ как порядочный программист включил автоматическую инициализацию стека на не-Андроиде с некоторыми изменениями и в течение нескольких месяцев работал над улучшением производительности путем исключения критических путей (hot paths).
Вот что думает enh@:
У Android R нулевая инициализация стека для ядра и пользовательского пространства. Мы обнаружили относительно немного мест в пользовательском пространстве, которые пришлось аннотировать для повышения производительности. Ребята рассматривают использование нулевой инициализации для S. Что, вероятно, будет сложнее осуществить.
Планы на будущее:
- Поработать над автоматической инициализацией (auto-init) кучи (на данный момент доступна только для стека)
- Попробовать снова протолкнуть нулевую инициализацию (zero-init)
- Посмотреть, сможем ли мы переключиться на __attribute((uninitialized)) вместо внесения изменений в конфигурацию сборки
- Еще раз попробовать V8?
Затраты: Было доказано, что автоматическая инициализация заметно увеличивает время выполнения в критических путях (hot paths). (Виталий вручную отобрал эти критические пути из автоматической инициализации.)
Предположим, что автоматическая инициализация значительно изменится в семантике C/C++. Если разработчики начнут полагаться на автоматическую инициализацию, есть вероятность, что код будет содержать больше багов, если кто-то отключит ее. (Мы можем и должны в любом случае защититься от этого с помощью тестов.)
Преимущества: На неинициализированную память приходится небольшая часть наших ошибок безопасности высокой степени серьезности – не более 1,5%. Автоматическая инициализация снижает когнитивную нагрузку (нет особой необходимости запоминать все случаи неопределенного поведения) и может обеспечить более чистый код, если разработчики гарантируют, что автоматическая инициализация всегда включена, пока программа запущена.
Поскольку в некоторых местах нужно отключать автоматическую инициализацию, такие места должны быть "очевидны" и документально подтверждены. (Понятный и документально подтвержденный пример: использование __attribute((uninitialized)) или аналогичного в точках доступа, а не в частных случаях в сборке.)
Удаление примитивных массивов
(Может быть описано в разделе Удаление сырых указателей.)
Проблема: В примитивных массивах в C границы не проверяются. Это приводит к ошибкам пространственной безопасности. -fsanitize=bounds работают только когда компилятор может статически определить размер массива, что случается не всегда.
Решения: Необходимо использовать тип, подобный std::array, где сейчас используются массивы в стиле C. Возможно, удастся автоматически перенести старый код в std::array (аналогично тому, как мы автоматически переносим код в MiraclePtr). Обратите внимание, что это повышает уровень безопасности, если мы также используем реализацию std, в которой определено все неопределенное поведение; например, std::array::operator[] не проверяет границы. (См. раздел Определение всех стандартных моделей поведения библиотеки.)
Текущее состояние: Отсутствует.
Затраты: Низкозатратно, но требует обсуждений и дополнительного обучения. Может потребоваться написать PRESUBMIT проверку или (предпочтительно) clang предупреждение, если это возможно.
Преимущества: Пространственная небезопасность составляет 16% ошибок безопасности высокой степени серьезности. Возможно, 17.5%.
Удаление изменяемого общего состояния
Проблема: В C++ невозможно предотвратить гонку данных.
Решения: Реализовать поддержку этого и borrow checker'а в компиляторе.
Текущее состояние: Отсутствует.
Затраты: Неизвестны. Существенно отличается от ожиданий разработчиков. Если Chromium будет активно использовать общее изменяемое состояние в некоторых местах, этот код потребуется значительно переработать.
Преимущества: На гонки данных приходится ~1% ошибок безопасности высокой степени серьезности; однако они связаны со множеством ошибок, которые позже относят к другим категориям (например, временная небезопасность), поэтому есть вероятность, что масштаб проблемы недооценен.
Проверка приведения типов
Проблема: Ошибки type confusion, например:
void SomeFunction(Animal* animal) {
// NOTE: Dog and Cat are subclasses of Animal.
DCHECK(IsCat(animal));
Cat* cat = static_cast<Cat*>(animal);
cat->Meow(); // If animal is really a Dog*, memory unsafety may ensue!
}может быть уязвимым, потому что может нарушить целостность памяти, если код неправильно обрабатывает объект 1 класса, так как считает его экземпляром другого.
static_cast должен быть dynamic_cast или должен автоматически проверяться не только в отладочных сборках с DCHECK, но и в сборках для продакшн. Исторически Chrome избегал dynamic_cast, потому что затраты на динамическую идентификацию типа данных слишком высоки (например, огромный объектный код). Это позволяет ошибкам, которые не обнаруживаются во время отладки и фаззинга, стать уязвимостями на практике.
Вот что отмечает davidben@ по поводу размера объектного кода:
После работы с godbolt, мне показалось, что затраты на динамическую идентификацию типа данных заключаются в том, что каждая таблица виртуальных методов (vtable) теперь также получает typeinfo с несколькими quad и названием класса. Выглядит не так уж дорого, да?
Я получил (возможно, используя неправильные флаги сборки) увеличение с 171М до 178М в урезанной релизной сборке Linux. Существенное увеличение, но не такое уж огромное значение, верно? Android наткнулся на какую-то ошибку линковки с use_rtti, хотя я предполагаю, что это поправимо.
Если предположить, что здесь действительно нужны имена типов, может нам просто использовать Clang флаг, чтобы не использовать их? std:type_info::name предположительно ничего не обещает, поэтому пустая строка должна идеально подойти...
Решения: TODO. dcheng@ говорит:
Предполагаю, что вы хотите использовать casting helpers, которые inferno@google.com изначально добавили в WebKit. Здесь используется ручная реализация динамической идентификации типа данных.
Я улучшил ее и сделал более "современным" решением на основе паттернов C++. Но поскольку сегодня мы вообще не поддерживаем динамическую идентификацию типа данных, здесь нет dynamic_cast даже в режиме отладки.
Вот как это работает сегодня:
- Blink классы реализуют IsX
-Есть трейты, которые подсказывают cast helper'ам, как использовать различные IsX методы.- DynamicTo<> ведет себя как dynamic_cast<> и возвращает значение nullptr, если проверка типа завершается неудачей. Используется в тех местах, где вы хотели бы использовать IsA<X> с последующим To<X>.
- To<> ведет себя как static_cast<>, но имеет DCHECK(IsA<X>);.
В моем идеальном миром было бы так:
- To<> всегда выполняет проверку типа
- DynamicTo<> остается прежним.
- UnsafeTo<> пропускает проверку типа в официальных сборках, когда необходимо добиться большей производительности.
- <Что-то> вынуждает нас использовать эти helpers для осуществления операции приведения типов, а не static_cast.
tsepez@ говорит:
Несколько лет назад я задумывался о создании subclass_cast<> (или down_cast<>), который определялся бы как dynamic_cast, если бы была включена динамическая идентификация типа данных и static_cast в ином случае (чтобы избежать предупреждений о динамическом приведении в сборках, отличных от динамической идентификации типа данных). В итоге я сделал вывод, что это была плохая идея. Получается, что вы улучшаете языки, удаляя из них то, что не следует использовать, вместо того чтобы добавлять новые фичи, которые следует использовать.
markbrand@ говорит: "На сколько я понимаю, clang-cfi (Clang Control-flow integrity) поддерживает это, но я не уверен, требуется ли динамическая идентификация типа данных."
kcc@ спрашивает: "Почему бы не использовать cast-cfi? Microsoft использует его."
Текущее состояние: Теперь в Blink есть соглашение для работы с проблемой "приведения к неправильному подклассу", которая раньше часто возникала в Blink. Возможно, теперь его можно применять более широко.
Затраты: Мы можем уменьшить расходы по сравнению с применением динамической идентификации типа данных и dynamic_cast, но во время выполнения всегда будут некоторые микро-затраты и, возможно, некоторые затраты на размер объектного кода.
Преимущества: 7% ошибок безопасности высокой степени серьезности приходится на type confusion, хотя значительная часть этих ошибок относится к V8 и не будет входить в улучшения C++ (или в новый язык программирования общего назначения). Злоумышленники особенно сильно любят использовать такие ошибки.
Превращать все DCHECKs в CHECKs
Проблема: DCHECKs используются для проверки некоторого статического инварианта, но иногда их используют не по назначению для проверки динамического инварианта (иногда предполагая, что это поможет обнаружить ошибку динамически в отладочных сборках). Если во время релиза DCHECK пропущен, это может привести к нарушению безопасности памяти, а иногда и спровоцировать появление логической ошибки. В любом случае это вполне может стать ошибкой безопасности.
Решения: Следить за наличием ненужных DCHECKs (такие тоже могут быть), а затем превратить оставшиеся DCHECKs в CHECKs. Некоторые DCHECKs действительно проверяют статичные инварианты. Их не следует преобразовывать.
Текущее состояние: Сборка Albatross. Предложение включить DCHECKs для проведения некоторых проверок в сборке.
Затраты: Дополнительная команда ветвления во время выполнения. Проверка в некоторых DCHECKs приводит к существенному раздуванию бинарных файлов и вычислению времени выполнения (например, сравнение деревьев кодов операций в V8). Придется это как-то обойти там, где это возможно.
Преимущества: Может решить проблемы безопасности доступа к памяти и ошибки логики/корректности. Около 30% наших ошибок безопасности высокой степени серьезности не являются проблемами безопасности памяти. 10% наших ошибок безопасности высокой степени серьезности приходятся на DCHECKs, которые, как мы определили, могут стать угрозой для безопасности, если во время релиза DCHECK пропускается.
Реализация NOTREACHED через CHECK
Проблема: NOTREACHED означает, что программа перешла в неопределенное состояние, и результатом будет неопределенное поведение. В отладочных сборках эта проблема устраняется, но, к (не)счастью наших пользователей, попадает в продакшн.
Решения: Заставьте NOTREACHED выполнить CHECK(false) вместо DCHECK(false) или эквивалент.
Текущее состояние: Есть план того, как сделать NOTREACHED [[noreturn]], который включает в себя создание IMMEDIATE_CRASH.
Затраты: Больший бинарный размер для наших пользователей, так как эти проверки скомпилированы в релизных сборках. Это должно занимать значительно меньше места и быть значительно безопаснее, чем глобально преобразовывать DCHECK в CHECK, поскольку NOTREACHED используется чтобы задокументировать неопределенное поведение и встречается реже. Вероятно, для имплементации этого потребуется несколько попыток. Любые NOTREACHED данные, обнаруженные в продакшн, должны быть удалены и преобразованы для правильной обработки этого случая.
Предотвращать использование use after move
Проблема: C++ позволяет программистам перемещать объекты, а затем использовать освободившееся место. (Мы называем это use after move или UAM.) Состояние этого места не определено, а его использование провоцирует неопределенное поведение.
Решение: Внедрить плагин Clang, чтобы предотвратить использование любого перемещенного значения.
Существующие работы:
- Clang MisusedMovedObject check
- Clang-Tidy bugprone-use-after-move развернута в google3 и в Chromium.
Проверка Clang-tidy полезна, но ее недостаточно. Он не рассматривает это как UAM:
auto consumes = [](OnceClosure c) {};
auto moves = [&](OnceClosure& c) {
consumes(std::move(c)); };
auto c = BindOnce([]() {});
moves(c);
moves(c); // Use after move.В настоящее время Chromium полагается на читаемые OnceCallback и unique_ptr (находящиеся в нулевом состоянии) после перемещения.
Текущее состояние: Отсутствует. Ошибка при использовании атрибута для аннотирования допустимых применений.
Затраты: Возможно, никаких?
Преимущества: Снижение количества ошибок времени жизни объекта.
Приложение: поиск решений логических ошибок
Ошибки, связанные с безопасностью доступа к памяти в C++, сильно беспокоят Chrome. Однако, как только все они будут исправлены, злоумышленники вместо этого начнут использовать логические ошибки. В других языках существуют определенные средства и идиомы, которые предполагают уменьшение вероятности возникновения таких ошибок. Пожалуй, мы могли бы сделать что-то в C++, чтобы предотвратить логические ошибки в критически важных для безопасности областях. Они также потенциально могут способствовать снижению временной небезопасности.
Логические ошибки составляют около 10% наших ошибок безопасности высокой степени серьезности.
Рекомендуется использовать type wrappers для инвариантов безопасности
Проблема: C++ затрудняет написание type wrappers. В других языках у вас может быть (например) IpAddress и IpAddressWhichIsNotLoopback (оборачивание IpAddress с нулевым временем выполнения, за исключением первоначальной проверки). Некоторые API будут принимать только последний тип, обеспечивая нулевое влияние на время выполнения. Все это возможно и в C++. Но это нераспространенный паттерн, потому что в C++ его трудновато применять.
Так же, может быть полезно иметь ranged integers.
Например, существует множество веб-платформенных функций, которые требуют, чтобы вызывающая программа находилась в безопасной среде. Часть этой проверки заключается в проверке того, что источник вызывающей программы является одной из безопасных URL схем. На данный момент мы передаем обычные GURL и url::Origins (предпочтительно последнее!) и ожидаем, что вызываемая (функция) выполнит явную проверку.
Вместо этого мы могли бы выполнить эту проверку в конструкторе ограниченного класса, например:
class SecureGURL : public GURL {
// This constructor is intentionally not `explicit`:
SecureGURL(const GURL& gurl) { CHECK(gurl.IsSecureScheme()); ... }
}
std::vector<byte> LoadTrustedResource(const SecureGURL& gurl);Таким образом, вызываемый объект, в данном случае гипотетический LoadTrustedResource, может быть вызван только с помощью GURL, который уже прошел проверку и которому уже не нужно явно выполнять проверку.
ellyjones@ отмечает, что мы могли бы пойти дальше и могли бы сделать SecureGURL не подклассом GURL, чтобы никто не мог случайно выполнить приведение вниз. Однако нам пришлось бы пересмотреть весь интерфейс GURL.
Решение: Безопасность типов во время компиляции может устранять логические ошибки более высокого уровня. Необходимо искать случаи в кодовой базе, в которых это может помочь. (Например, адрес начала программы, URIs и т. д. могут оказаться подходящими областями.)
Текущее состояние: Отсутствует.
Затраты: По задумке затрат на время выполнения не должно быть. На самом деле наоборот. Это означает, что проверка может быть выполнена только один раз статически, а не динамически или несколько раз. Может быть сложно определить случаи, когда такой паттерн имеет смысл в существующей кодовой базе.
Преимущества: Если какие-либо случаи выявляются, можно устранить некоторые логические ошибки без снижения производительности (или сделать небольшое улучшение, например, избавиться от CHECK).
Приложение: аппаратная поддержка для обнаружения проблем с памятью
Разметка памяти
Все новое – хорошо забытое старое: размеченная память возрождается. (Между этим и распространенностью JavaScript, в конце концов победил Lisp!) См. ARM MTE. В зависимости от конкретного механизма указатели и/или области памяти "помечаются", и, если код пытается загрузить или сохранить память без использования правильного тега, программа выдает ошибку. Это помогает нам обнаруживать ошибки и останавливать эксплойты с определенной (обычно высокой) вероятностью для каждого случая.
MTE может скоро появиться в устройствах высокого класса, но потребуется гораздо больше времени, чтобы это распространилось по большей части мира.
Тегирование не является идеальной защитой. Если злоумышленник узнает или угадает правильный тег — часто им удается это сделать — он сможет незаметно использовать правильный тег во время эксплойта. Чтобы воспользоваться преимуществами тегирования, нам нужно сделать так, чтобы злоумышленникам было сложно найти или угадать значения тегов. (Например, сделать так, чтобы браузер ограничивал навигацию по сайтам, у которых слишком часто ломается рендер. Правда я не уверен, поможет ли это.)
Control Flow Integrity
В настоящее время мы предоставляем поддержку Intel Control-flow Enforcement Technology (CET) для Windows.
Поддержка этого значительно увеличивает шансы продвижения Clang CFI/Windows CFG. Мы рассматриваем возможность осуществления этого в 2021 году. TODO: ENDBRANCH.
Мы также собираемся изучить возможность поддержки CET на всех операционных системах, надеюсь, также в 2021 году.
TODO: ARM PAC сейчас предоставляется для устройств Apple. Также было бы неплохо изучить PAC и BTI на других устройствах и операционных системах.
Приложение: типы ошибок
В этом документе говорится о влиянии исправления различных типов ошибок безопасности в процентном соотношении. Эти проценты получены при проведении ручного анализа каждой ошибки безопасности высокой степени серьезности, которая повлияла на стабильный канал с начала 2019 года. Точные первопричины вычислены приблизительно. Стоит отметить, что сектор "временной безопасности" растет из года в год.
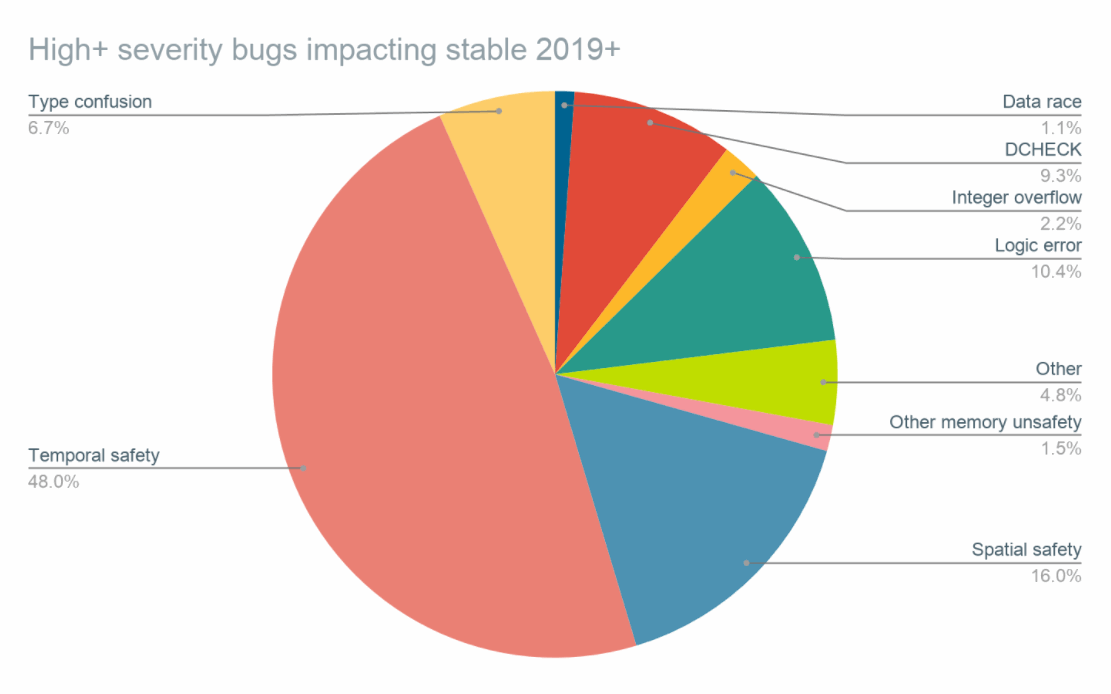
Приложение: удаление нулевых указателей
Проблема: Хоть разыменование нулевого указателя не считается уязвимостью системы безопасности (если только злоумышленник не может контролировать смещение указателя, что случается редко), они действительно являются причиной значительной доли ошибок стабильности. Ответственному за защищенность данных (Security Sheriff) может потребоваться значительное время, чтобы убедиться, что данная ошибка действительно является "обычной" ошибкой стабильности (пример).
Удаление нулевых указателей также поможет улучшить работу — разработчики смогут избавиться от когнитивных и кодовых издержек, связанных с проверкой на ноль.
Примечание: ASan сообщает о сбое как о null-deref, если ошибочный адрес находится в пределах [0, 4096). Без использования ASan нужно смотреть на значение регистров, но люди иногда совершают ошибки. Воспроизведение как можно большего количества сбоев в ClusterFuzz, скорее всего, снизит вероятность ошибки.
Решения: Изменить тип смарт указателя, чтобы для указателей, которые могут быть пустыми, требовалась явная аннотация или флаг конструктора. Проверить наличие и избавиться от таких указателей. Проверить конструкцию на наличие тех указателей, которые не должны быть нулевыми.
Как и в случае с целочисленной семантикой, возможно, удастся получить то, что мы хотим, с помощью параметров компилятора. Доступно несколько вариантов, в том числе -fsanitize=null и -fsanitize=nullability-arg. Параметры nullability-* работают с аннотацией _Nonnull от Clang.
Текущее состояние: Отсутствует.
Затраты: Микрозатраты на проверку.
Преимущества: Мы можем обнаружить ошибки стабильности раньше и сможем сэкономить время на сортировку ошибок безопасности.
Приложение: меры по смягчению последствий
В этом документе внимание уделяется подходам к проблеме на уровне языка: кодификации более безопасных паттернов использования C++ для повышения безопасности памяти и уменьшения неопределенного поведения в целом.
Использование мер по устранению уязвимостей и усовершенствованных методов поиска ошибок могут дополнить такую работу. Например:
- HWASAN
- GWP-ASan
- Разметка памяти (например, Memory Tagging Extension)
- CFI и защита стека
- Классические: W^X/DEP, stack canaries, heap canaries, ASLR
Приложение: иные идеи
Возможно, будут рассматриваться:
- Удаление base::Unretained – требует, чтобы разработчики определяли правильную модель владения для каждого объекта. (WeakPtr не всегда является серебряной пулей, потому что его нельзя использовать в последовательностях/потоках.)
- Или вернуться к использованию Unretained с MiraclePtr.
- Улучшения Mojom для обеспечения хранения всех объектов в подходящих контейнерах.
- Запрет на паттерны разработки, которые, как правило, вызывают проблемы (например, singleton'ы (одиночки) по сути означают общее и вероятное изменяемое состояние)). (Была предпринята попытка систематического расследования.)
- Акцент на композицию, а не какой-либо указатель. (Можем ли мы написать программу проверки для поиска объектов, принадлежащих по указателю, которые вместо этого могли бы просто принадлежать по значению?)
- Замена base::Bind и весь код, который его использует на линейную версию (promises? Какой-нибудь генератор кода на C++?), чтобы упростить написание асинхронного кода и обнаружение ошибок.
- Дизайн фаззинга: использование паттернов в mojo и реализациях, которые облегчают фаззинг форматов и время жизни объектов из ненадежной программы рендеринга.
- Дизайн для статического анализа: избегайте использования паттернов, которые затрудняют работу статических анализаторов.
- SAL аннотации. Подходит для операционных систем, где аннотации уже доступны. По сути, это новый язык для разработчиков base::, с которым можно взаимодействовать, чтобы в полной мере использовать преимущества.
- Компилируйте части кода с помощью WebAssembly. (Мы изучаем это, начиная с августа 2021 года.)
Комментарии (12)

RC_Cat
29.09.2021 21:31Я вот чего-то не понял. Безопасность предоставляемая Rust не совсем либо совсем не бесплатная?

apro
30.09.2021 03:04+1Для инварианта что в один момент времени существует только одна не константная ссылка на данный участок памяти есть два способа проверки: во время компиляции и во время работы программы. Программист может выбрать любой из двух вариантов и конечно оба варианта не бесплатны. Для первого нужен сложный компилятор и в существующий компилятор C++ подобное добавить очень сложно, для второго нужны доп. проверки во время работы программы.

Gordon01
30.09.2021 06:22RefCell использует проверки в рантайме, все остальное — во время компиляции (то есть бесплатно и быстрее любых аналогов на С++, а иногда и С).
Не забывайте еще и то, что любые аргументы функций в Rust имеют аналог спецификатора restrict, что еще сильнее повышает производительность и уже С может остаться позади.

domix32
30.09.2021 11:48+2Зависит от рассматриваемого контекста. Любые абстракции так или иначе стоят времени компиляции, это включая проверки времен жизни и границ блоков памяти, выравниваний и тд. После компиляции большая часть бесплатная. If it's compiled, it works. Иногда есть некоторые окна для оптимизаций (например обращение по индексу массива с выпиленным bound check через get_unchecked), но чаще всего они не дадут значимого прироста если код написан идиоматично. Всякие RefCell, Arc и иже с ними работают в динамике и как любые умные указатели они работают в момент работы программы и естественно для этого кейса блокировка указателя тоже будет стоить что-то. Частично это пытаются нивелировать при помощи недавно появившихся const функций который позволяют сделать бесплатную статичную альтернативу refcell, но естественно применимость тоже ограничена.

NightShad0w
29.09.2021 21:34-3Сколько сырых указателей надо перевести на умные и оптимизированные по производительности, чтобы сайты Гугла, написанные с использованием Polymer, работали хотя бы со скоростью сайтов 2010 года?
150кбайт загружается с главной страницы, с одним полем, 2 кнопками и главным меню в уголочке. Несомненно, стоит оптимизировать умные указатели в С++ и изобретать прочие улучшения языка.
F0iL
30.09.2021 00:10+1А причем здесь вообще гугловский фронтенд-то?
Ну и да, сырые либо умные указатели влияют в первую очередь на стабильность и безопасность, а на производительность либо вообще не влияют при грамотном подходе , либо влияют негативно (например, из-за накладных расходов на подсчет ссылок), но это все равно того стоит.

Gordon01
30.09.2021 06:14+7TLDR: как превратить С++ в плохой диалект Rust, который потребует проприетарных костылей и будет непонятен рядовому плюсовику.

Andrey2008 Автор
01.12.2021 19:26Документ навеял мысли повторить проверку Chromium :)
Проверка Chromium спустя три года. Ну и как оно?
ncr
На третий деньВ 2021 годуиндеец Зоркий ГлазGoogle заметил, чтов тюрьме нет четвёртой стеныумные указатели облегчают жизнь.F0iL
У них в Blink сборщик мусора (тот самый Oilpan) появился ещё за много лет до этого, а указатели с подсчетом ссылок -- ещё гораздо раньше.