

Это третья публикация в рамках цикла статей по изучению московской базы ковидных больных. В настоящей работе были созданы векторные представления медицинских терминов, которые теперь доступны на Github. Любой разработчик может использовать их в своих исследовательских целях.
Предыдущие мои публикации можно найти по ссылкам:
Преамбула
Напомню, что автору в руки попала обезличенная база московских больных Covid-19 (без ФИО и информации из каких- либо личных документов). В ней содержатся записи о примерно 106 тыс. пациентах, для каждой из которых есть как ряд характеристик, так и в свободной форме написанные комментарии. Их оставлял медицинский персонал в нескольких случаях:
По результатам телефонного разговора.
Описание по факту первичного выезда бригады СМП (скорой медицинской помощи) к заболевшему.
Комментарий при лечении в стационаре / нахождения на карантине / долечивании на дому.
Разумеется появилось желание получить полезную информацию из этих полей. Было принято решение кластеризовать все тексты по их тематическому содержанию. После этого выбрать набор наиболее частых тем, которые создадут новые фичи. Останется получить проекции каждого текста на ранее отобранные темы, тем самым заполняя фичи конкретными значениями.
Но, к сожалению, готовые модели погружения слов в векторное пространство (т.н. word embeddings) при эксперименте дали ужасный результат на медицинской тематике. Они абсолютно не годились для поставленной задачи. Поэтому было принято решение самостоятельно создать отображение медицинских терминов в векторное пространство.
Создание векторного отображения
Изначальный план был таков: взять векторное погружение слов общей практики и дообучить его на медицинской тематике. В качестве словарной базы использовались подшивки медицинских журналов, поскольку в них содержися более "живой" язык (по сравнению с книжным). Таким образом полная медицинская база состояла из:
Журнал "Consillium medicum" (2004- 2012)
Журнал "Клиницист" (2006- 2016)
Журнал "Врач- аспирант" (2004- 2010)
Журнал "Кардиология" (1996- 2004)
Журнал "Лечащий врач" (2010- 2020)
"Сибирский медицинский журнал" (2004- 2011)
Журнал "Трудный пациент" (2006-2014)
Журнал "Туберкулёз и болезни лёгких" (2010- 2017)
30 медицинских книг
Текстовые комментарии московской базы ковидных больных (~80 тыс. штук).
Оказалось, что импортировать pdf- журналы в txt- формат не так- то просто: дело в том, что текст в них разбит на колонки и при использовании импорта различных pdf- просмотрщиков, получалась каша. Поэтому для конвертации журналов в текст использовался собственный модуль, основанный на библиотеке PyMuPDF. Она позволяет последовательно читать все блоки с pdf- страницы, тем самым получая упорядоченный текст. За счет использования собственного алгоритма импорта появилась возможность алгоритмически удалить "мусорный" текст: список используемой литературы (иногда на несколько страниц!), контактная информация авторов, замечания о конфликте интересов, колонтитуллы. Также удалялись 7 первых и 6 последних страниц в каждом журнале, поскольку как правило этот диапазон страниц содержит рекламу и организационную информацию (оглавнение, приветствие редакции, планы выпуска журнала....)
После импорта журналов в текстовый формат получилась папка размером 385 МБ, а текст всех книг потребовал 26 МБ дискового пространства. Для сравнения напишу, что все 4 тома романа "Война и мир" Л.Н. Толстого в тектовом формате составляют примерно 3 МБ.
На первый взгляд размер словарной базы кажется большим, но оценка сильно зависит от размерности векторного представления: чем выше размерность векторного пространства, тем более разреженно в нем "находятся" слова. Поэтому для качественного представления небольшого корпуса слов (подобного тому, что представлен в настоящей статье для медицинской тематики) желательно использовать низкоразмерное векторное представление.
К сожалению, для русского языка в свободном доступе нашлись только 300- мерные представления слов общей практики. Небольшой объем медицинских терминов "растворился" бы в этой бездне, показывая что все слова между собой очень далеки. Поэтому план изменился: было решено получить также базу слов общей практики и на обоих базах самостотяельно обучить 48-ми, 64-ех и 100- мерные векторные представления.
В качестве словарной базы общей практики использовались:
После импорта в тексовый формат общеязыковая база составила 705 МБ (а обе базы вместе ~1.1 ГБ).
При выполнении обучения использовались два лемматизатора pymorphy2 и pymystem3. Последний использовался только в случае, если pymorphy2 предлагал слово из словаря FakeDictionary (т.е. не находил слова и начинал заниматься предположениями). В качестве токенизатора использовался старый добрый nltk.
Общее количество слов в наборах составило 45 млн, из них уникальных- 302 тыс. При этом было принято решение проводить отбраковку редких слов на уровне не менее 30 использований (против 5, используемых по- умолчанию). Это позволяет значительно более качественно понять статистику контекстов использования слов, по которым далее будет происходить сопоставление слов между собой. Конечно, это сильно снизило итоговую языковую "мощность": векторизуемое моделью word2vec количество слов составило 44 млн, а уникальных- всего 41 тыс. слов.
При обучении word2vec все исследователи столкнутся с проблемой нехватки памяти. Дело в том, что для обучения модели общий объем текстов необходимо хранить в виде отдельных слов, что в Python реализованно неэффективно. Gensim предлагает использовать периодическую подгрузку данных с диска, что очевидно сильно замедляет обучение. Поэтому был придуман альтернативный вариант: хранение данных в оперативной памяти в сжатом виде. Для этого использовался класс, который умеет "на лету" сжимать и разжимать данные:
import zlib
class CompressedCorpus:
COMPRESSION_LEVEL = 2
def __init__(self):
self.compressed_corpus = []
def add_compressed_sentences(self, sentences):
self.compressed_corpus.extend(sentences)
@staticmethod
def compress_sentences(sentences):
bin_data = pickle.dumps(sentences)
return zlib.compress(bin_data, level=CompressedCorpus.COMPRESSION_LEVEL)
def __iter__(self):
for compressed in self.compressed_corpus:
bin_data = zlib.decompress(compressed)
sentences_of_document = pickle.loads(bin_data)
for sentence in sentences_of_document:
yield sentenceВ результате выполнения обучения с помощью пакета gensim были получены векторные представления медицинских терминов (выбирайте подходящую для вас размерность векторного пространства).
После экспериментов оказалось, что 64- мерное представление слов показывает в решаемой задаче примерно на 20% более качественный результат, по сранению со 100- мерным. Насколько падает качество у 300- мерных векторов, можно только догадываться. Напомню, что при сравнении вариативности пространств нельзя линейно сравнивать их "мерности", необходимо использовать экспоненциальный закон. 48- мерное пространство показало схожие результаты, но иногда появлялся шум, из- за близости векторов.
Теперь любой желающий может их использовать для анализа текстов медицинской тематики:
from gensim import models
model = models.Word2Vec.load(file_with_word_embeddings)Созданная модель так определяет близкие слова:
Болезнь
('заболевание', 0.8347288966178894), ('патология', 0.7339873909950256), ('криз', 0.6073477268218994), ('хронический', 0.5976685285568237), ('недуг', 0.595315158367157), ('рак', 0.5917460322380066), ('невроз', 0.5848156809806824), ('поражение', 0.58390212059021), ('алкоголизм', 0.5755941271781921), ('расстройство', 0.5720771551132202), ('цирроз', 0.5429321527481079), ('недостаточность', 0.541659951210022), ('инфекция', 0.5362805128097534), ('колит', 0.5339022874832153), ('изсда', 0.5326570272445679), ('порок', 0.5312889218330383), ('энцефалопатия', 0.5306264162063599), ('ревматизм', 0.5263662934303284), ('синдром', 0.5193524956703186), ('нездоровье', 0.5097973346710205), ('амилоидоз', 0.5093125104904175), ('травма', 0.4981701970100403), ('мононуклеоз', 0.4978249669075012), ('гепатит', 0.4869999587535858), ('астма', 0.4858018755912781), ('перенапряжение', 0.484466016292572), ('осложнение', 0.4818928837776184), ('десинхроноз', 0.479522705078125), ('декомпенсация', 0.47163745760917664), ('остеохондроз', 0.4713606834411621), ('дерматоз', 0.46962982416152954), ('психоз', 0.46953797340393066), ('переутомление', 0.4688436985015869), ('дерматит', 0.46865373849868774), ('страдать', 0.4686203896999359), ('эндартериит', 0.4673176407814026), ('инфаркт', 0.4647698700428009), ('диатез', 0.46466541290283203), ('анемия', 0.46290749311447144), ('злокачественный', 0.462791383266449), ('псориаз', 0.4598379135131836), ('колика', 0.4569317400455475), ('ХНЗЛ', 0.4564151465892792), ('холелитиаз', 0.45443031191825867), ('глаукома', 0.453472763299942), ('порфирий', 0.4516097605228424), ('повреждение', 0.44984397292137146)
Врач
('терапевт', 0.8099639415740967), ('медсестра', 0.7456645369529724), ('педиатр', 0.7449079155921936), ('стоматолог', 0.7308368682861328), ('врачебный', 0.7181729078292847), ('психиатр', 0.6961877942085266), ('невролог', 0.6842734813690186), ('поликлиника', 0.6683478355407715), ('медперсонал', 0.6595726013183594), ('посоветоваться', 0.6528365015983582), ('хирург', 0.6513217091560364), ('специалист', 0.64706951379776), ('фтизиатр', 0.6451202034950256), ('клиницист', 0.6442852020263672), ('отоларинголог', 0.6421664953231812), ('психоневролог', 0.6258573532104492), ('участковый', 0.6253350973129272), ('фельдшер', 0.6252065896987915), ('инфекционист', 0.6225680112838745), ('гинеколог', 0.6195974946022034), ('консультант', 0.6157099604606628), ('медик', 0.6129191517829895), ('медработник', 0.6103352904319763), ('психолог', 0.6088686585426331), ('анестезиолог', 0.6054319739341736), ('интернистый', 0.6031010150909424), ('уролог', 0.6026933193206787), ('провизор', 0.6022548079490662), ('патоморфолог', 0.6018158197402954), ('аллерголог', 0.5998104214668274), ('онколог', 0.5932439565658569), ('ассистент', 0.5927863717079163), ('пульмонолог', 0.5913029909133911), ('дерматолог', 0.5836321711540222), ('эндокринолог', 0.5816663503646851), ('лаборант', 0.581134557723999), ('сотрудник', 0.5809362530708313), ('акушер', 0.5761595368385315), ('психотерапевт', 0.5734131336212158), ('консультировать', 0.572510302066803), ('дежурный', 0.5693656206130981), ('нарколог', 0.5685620307922363), ('консультация', 0.5656259655952454), ('медицинский', 0.5599374175071716), ('дерматовенеролог', 0.5597026944160461), ('куратор', 0.5589353442192078)
Терапия
('лечение', 0.9110350012779236), ('химиотерапия', 0.744488000869751), ('фармакотерапия', 0.7268965840339661), ('монотерапия', 0.64706951379776), ('антибиотикотерапия', 0.6396688222885132), ('препарат', 0.6288763880729675), ('коррекция', 0.5847635269165039), ('психофармакотерапия', 0.5735004544258118), ('гормонотерапия', 0.5589482188224792), ('терапевтический', 0.5570299029350281), ('абт', 0.5562933683395386), ('пхт', 0.5462656617164612), ('ивл', 0.5368460416793823), ('полихимиотерапия', 0.5262065529823303), ('инсулинотерапия', 0.522721529006958), ('иммунотерапия', 0.5146833062171936), ('обезболивание', 0.5121416449546814), ('купирование', 0.5090704560279846), ('медикаментозный', 0.49881476163864136), ('арвт', 0.4972829222679138), ('интерферонотерапия', 0.4958414137363434), ('асит', 0.4925050437450409), ('гкс', 0.4923551380634308), ('птт', 0.4913291931152344), ('агт', 0.48378074169158936), ('диетотерапия', 0.48257237672805786), ('госпитализация', 0.4796653091907501), ('реабилитация', 0.47430941462516785), ('психотерапия', 0.45638275146484375), ('тромбопрофилактика', 0.4539289176464081), ('кардиоверсия', 0.4508218765258789), ('химиопрофилактика', 0.44811952114105225), ('арв', 0.44347259402275085), ('профилактика', 0.4431573152542114), ('ваарт', 0.44169166684150696), ('кислородотерапия', 0.4411754906177521), ('кардиореабилитация', 0.43889859318733215), ('тренировка', 0.43811100721359253), ('комбинация', 0.4334109127521515), ('глюкокортикоид', 0.4329511821269989), ('фототерапия', 0.43233123421669006)
Выздоровление
('излечение', 0.8492449522018433), ('ремиссия', 0.7511098384857178), ('регресс', 0.6205442547798157), ('самоизлечение', 0.5908384323120117), ('абациллирование', 0.5902377367019653), ('заживление', 0.5882741212844849), ('исчезновение', 0.5830905437469482), ('рецидив', 0.578253984451294), ('реконвалесценция', 0.5771373510360718), ('эпителизация', 0.5687963366508484), ('выздороветь', 0.5515270829200745), ('наступление', 0.5395905375480652), ('отпадение', 0.5310086011886597), ('эрадикация', 0.52912837266922), ('разрешиться', 0.525256872177124), ('возвращение', 0.5203354358673096), ('рубцевание', 0.5192395448684692), ('летально', 0.5173105001449585), ('возобновление', 0.5164587497711182), ('персистирование', 0.514289140701294), ('купирование', 0.5132368803024292), ('стихание', 0.5030621290206909), ('окл', 0.5023788809776306), ('рассасывание', 0.500794529914856), ('хронизация', 0.5003021955490112), ('умирание', 0.4988389313220978), ('завершение', 0.4983193278312683), ('исход', 0.4963388442993164), ('ресоциализация', 0.49621516466140747), ('обострение', 0.49614015221595764), ('бесповоротный', 0.4908732771873474), ('негативация', 0.48786062002182007), ('выздоравливать', 0.4863669276237488), ('выписка', 0.4859303832054138), ('восстановление', 0.4747615456581116), ('санировать', 0.47448742389678955), ('лечение', 0.4742755889892578), ('прогрессирование', 0.4742307960987091), ('санация', 0.47037824988365173), ('карантин', 0.46836093068122864), ('трудоспособность', 0.468219131231308)
Кластеризация
С помощью полученного представления удалось векторизовать все тексты, характеризующие состояние и лечение пациентов (как средне- арифметическое всех входящих в текст слов). Существует несколько методик, позволяющих оценить оптимальное количество кластеров.
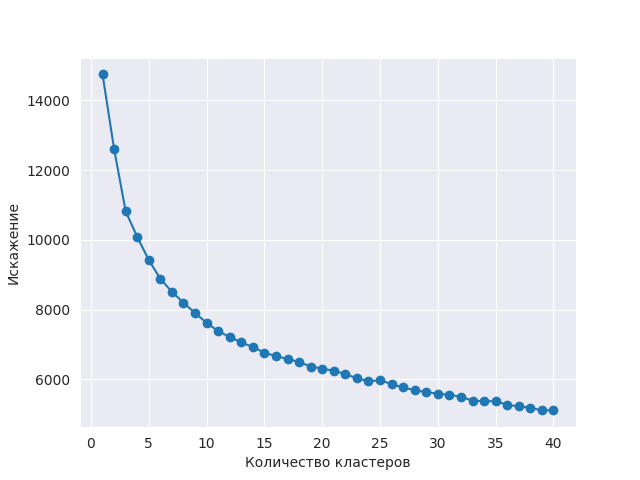
Метод локтя не показывает ярко выраженной точки перегиба, позволяющей установить оптимальное количество кластеров. Хотя в диапазоне между 5 и 10 кластерами происходит заметное снижение искажений.
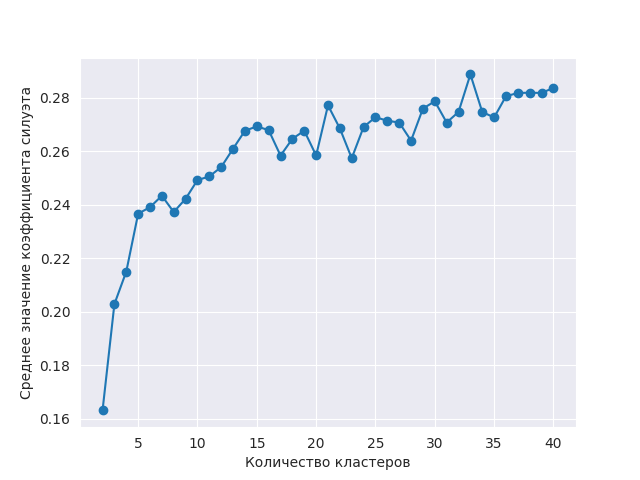
Построение среднего значения коэффициента силуэтов показывает остановку быстрого роста в диапазоне 7- 12 кластеров.
Информационные критерии Акаике и Байесса, полученные с помощью кластеризации Gaussian Mixture, переходят на "плато" в диапазоне 4- 12 кластеров. Все же не надо забывать, что подобный метод выбора числа кластеров представляет собой меру успешности работы GMM как оценивателя плотности распределения, а не как алгоритма кластеризации.

Посмотрим на размеры получаемых кластеров: глупо выделять кластеры, в которые входит небольшое количество объектов. Необходимо заранее задать примерно верное количество кластеров, чтобы получить корректные размеры каждого кластера (исходя из предыдущих оценок, было использованно значение 10). По графику можно принять осторожное решение о выделении до 9 кластеров.

За всей этой батареей методов был упущен из вида самый простой и очевидный подход: так как мы кластеризуем тексты, то можно найти максимально близкие слова к каждому кластеру и предоставить их пользователю для анализа. Так было установлено, что 7 кластеров имеют независимые непересекающиеся тематики (это важно, поскольку мы по сути ищем базис, на который позже будем искать проекции).
После выбора оптимального количества кластеров была успешно проведена кластеризация алгоритмом K- means (в качестве конкурентов у него были методы "Gaussian mixture" и "OPTICS", которые показали более худший результат). Это позволило в векторном пространстве обнаружить центры 7-ми популярных текстовых тематик (как центры кластеров). Используя косинусное расстояние между нормированными векторами текстов и центров кластеров, были получены проекции каждого текста на популярные тематики.
А стоит ли устанавливать значения проекций для всех фичей- кластеров? Может чтобы не было лишнего "шума" стоит устанавливать значение только для кластера с максимальной проекцией, или для нескольких, чья проекция близка к максимальной? Ведь большинство слов посвящено одной тематике (медицина) и возможно предположить, что тексты будут близки друг к другу независимо от своего содержания. Как определить размер близости косинусных расстояний, который задаст "серьезные" проекции? Для этого можно использовать вложенную кластеризацию, которая отделит между собой группы близких и далеких проекций. Получается кластеризация в кластеризации.

После выполнения "вложенной" кластеризации "важными" проекциями оказались те, чье косинусное расстояние не меньше, чем 0.785 от максимальной проекции. Этим фичам устанавливалось значение проекции, а все остальные проекции считались шумовыми и их фичи получали значение 0.
В противовес изложенному выше подходу была опробирована идея более слабого ограничения на количество кластеров (20 и даже 30 выявляемых тематик) с последющим сжатием пространства методом главных компонент (PCA). Это не принесло улучшения по сравнению с первоначально предложенным вариантом.
Заключение
С новыми фичами было достигнуто улучшение качества обучения Catboost, который занимался предсказанием тяжести заболевания и смерти пациентов. Например, по метрике Каппа Коэна улучшение составило почти 5% и, например, для предсказания смерти пациента достигло 84% (при этом с помощью анализа ShapValues было подтверждено отсутствие утечек).
Надеюсь мое решение поможет другим в достижении успеха на исследовательской ниве.
zoldaten
Так понимаю, 7 кластеров были выбраны как основные. Что это за кластеры? И какие наиболее частые темы удалось выделить?
По поводу векторизации тоже есть вопросы.
Например, слово «Врач» и слова «лаборант», «ассистент». Они (последние слова) имеют схожее векторное расстояние с «пульмонологом», «дерматологом». То же встречается и в других словах («перенапряжение»!=«болезнь»). Кроме того, с болезнями надо быть аккуратнее, так как подходы к отнесению в эту категорию меняются. Например, диатез, если память не изменяет, перестал быть болезнью. Хорошо, конечно, что нейросеть «ухватила» суть, но доработка нужна.
26 Гб наверно? Чем вы обрабатывали такие объемы и насколько это было долго?
PythonAnalyst Автор
Тематику можно определить опосредованно, по наиболее близким словам к центру кластеров. Вот они:
1. 'мазка', 'ковид', 'мазок', 'ротоглотка', 'осмотреть', 'отоскопия', 'носоглотка', 'бактериологический', 'цитологический', 'папаниколау'
2. 'информированный', 'согласение', 'согласие', 'договариваться', 'подписать', 'подписывать', 'огласить', 'испрашивать', 'направительный', 'анонимный'
3. 'томография', 'кт', 'рентгенография', 'грудной', 'скт', 'МСКТ', 'узи', 'мрт', 'мультиспиральный', 'ркт'
4. 'тестирование', 'тест', 'положительный', 'проба', 'ложноотрицательный', 'испытуемый', 'ложноположительный', 'отрицательный', 'кфт', 'самоотчёт'
5. 'сообщить', 'поступить', 'выдать', 'выписать', 'отобрать', 'перевести', 'обследоваться', 'емиас', 'выписываться', 'указать'
6. 'пневмония', 'вирусный', 'диагноз', 'внебольничный', 'вп', 'ковид', 'инфекция', 'сепсис', 'подозрение', 'миокардит'
7. 'гбуз', 'гкб', 'дзм', 'госпитализировать', 'долечивание', 'гуз', 'ткб', 'поликлиника', 'окб', 'больница'
PythonAnalyst Автор
Методология word2vec дает близость слов по одинаковым контекстам использования. Т.е. если два разные слова употребляются рядом с одними и теми же словами, то word2vec решит, что эти слова близки. Например, в мед. литературе вполне логично, что слова врач, лаборант, ассистент взаимозаменяемы (поскольку врач может кому- то ассистировать во время операции, а лаборант выполнять тот же нарбор действий, что и врач).
Для улучшения качества можно разве что увеличить порог учета слова (я выбрал значене 30, против значения 5, предложенного по- умолчанию).
PythonAnalyst Автор
Текст занимает очень мало места. Поэтому никакой опечатки нет: все 30 книг поместились в 26 МБ дискового пространства. И все же корпус слов, хранимый в оперативной памяти действительно вышел гигантский, в силу чего произошла нехватка оперативной памяти (даже при использовании файла подкачки).
Поэтому я "на лету" сжимал данные с помощью gzip, и также "на лету" их разжимал. Добавлю об этом в статью, поскольку при работе с word2vec абсолютно все столкнутся с этой проблемой.