

Размер современных приложений и сложность языка C++ превышают возможности людей по всестороннему анализу текста программ на обзорах кода. Компенсационная методология – статический анализ кода.
Сложность разработки современных С++ приложений
Два основных вызова, с которыми сталкиваются С++ программисты, — это размер программного кода современных проектов и сложность языка. Стало тяжелее, вернее, невозможно удержать всё нужное в голове. Следствие — большое количество ошибок и дополнительные затраты на тестирование и сопровождение программного кода. Давайте разберёмся, как это происходит.
Размер проектов
С ростом проекта увеличивается плотность ошибок. Чем больше проект, тем больше неявных взаимосвязей между различными частями программы и тем сложней вносить изменения, не сломав что-то.
Это нельзя назвать новым наблюдением. Например, эффект роста плотности ошибок описан в книге Стива Макконнелла "Совершенный код". А он в свою очередь указывает в качестве источников данных "Program Quality and Programmer Productivity" (Jones, 1977), "Estimating Software Costs" (Jones, 1998).

Однако от того, что ситуация понятна и давно изучена, легче не становится. Увеличивается количество как высокоуровневых ошибок, так и низкоуровневых. Частая причина высокоуровневых ошибок – неправильные представления о том, как работают другие части программы, и, как следствие, неправильное взаимодействие с ними. Часто причина низкоуровневых ошибок – что-то поправили в коде, но не учли последствия.
Рассмотрим ошибку, которая появилась в своё время в проекте CovidSim. Обратите внимание, что, хотя изменение кода было простым, ошибка всё равно попала в pull request. И чем больше и сложнее код, тем чаще возникают подобные ошибки из-за невнимательности.
В изначальном варианте кода память выделялась на стеке:
char buf[65536], CloseNode[2048], CloseParent[2048];Программист решил, что это плохо, и начал выделять динамическую память:
char* buf = new char[65536];
char* CloseNode = new char[2048];
char* CloseParent = new char[2048];Однако он поспешил и просто добавил вызовы операторов delete [] в конце файла. На первый взгляд, исправление выглядит хорошо, но на самом деле перед нами фрагмент недостижимого кода и утечка памяти:
int GetXMLNode(....)
{
....
if (ResetFilePos)
fseek(dat, CurPos, 0);
return ret;
delete[] buf;
delete[] CloseNode;
delete[] CloseParent;
}Ручное управление очисткой памяти не является правильным подходом, и намного лучше использовать умные указатели или std::vector. Однако это уже другая тема. Важно, что ошибка возникла в реальном проекте.
Подобные ошибки можно заметить на обзорах кода, но это не всегда легко. Ситуация усложняется, если нужно учитывать взаимосвязи между кодом в разных файлах.
Например, кто-то увлёкся сокращением имён с помощью макросов:
....
#define scout std::cout
#define sstringstream std::stringstream
#define sofstream std::ofstream
#define sifstream std::ifstream
#define sfstream std::fstream
....И помимо других сокращений написал в заголовочном файле вот такой макрос:
#define sprintf std::printfВ результате совсем в другом месте сломана работа обыкновенной функции sprintf:
char buf[128];
sprintf(buf, "%d", value);Это реальная ошибка, которая имела место в проекте StarEngine.
В таком изолированном виде ошибки кажутся простыми, очевидными и непонятно, как их пропустили. Но чем крупнее проект, тем проще таким ошибкам появиться и тем сложнее их заметить при обзорах кода.
Сложность языка C++
Язык C++ развивается, что позволяет писать более лаконичные и безопасные конструкции. Но есть и обратная сторона. Язык стал столь большим, что очень сложно изучить все его аспекты и использовать конструкции правильно. Более того, если даже программист прочитал про какую-то особенность языка, про неё легко забыть.
Возьмём для примера range for. С одной стороны, его использование может защитить от одной из классических 64-битных ошибок.
void foo(std::vector<char> &V)
{
for (int i = 0; i < V.size(); i++)Этот код мог десятилетиями успешно работать в 32-битной программе. Переход на 64-битную архитектуру позволяет обрабатывать большие объёмы данных, и количество элементов в векторе может превысить значение INT_MAX. В результате возможно переполнение знаковой переменной. Это является неопределённым поведением, которое проявляется иногда весьма причудливым образом.
Использование range for делает такой код более коротким и безопасным:
for (auto a : V)Теперь неважно, какой размер имеет контейнер. Будут обработаны все элементы. К сожалению, на место одних паттернов ошибок приходят другие. В случае с range for, например, легко забыть, что на каждой итерации создаётся копия элемента, а не ссылка, если специально это не указать. Пример такой ошибки из проекта Krita:
const qreal invM33 = 1.0 / t.m33();
for (auto row : rows) {
row *= invM33;
}Здесь не происходит никакого умножения элементов на константу. Правильный вариант:
for (auto &row : rows) {
row *= invM33;
}Хорошо, можно сказать, что рассмотренный случай – это просто невнимательность и сложность языка здесь преувеличивается. Рассмотрим другой пример. Считаете ли вы следующий код чем-то подозрительным?
std::vector<std::unique_ptr<Modifier>> Modifiers;
Modifiers.emplace_back(new LoadModifier(BB, &PT, &R));
Modifiers.emplace_back(new StoreModifier(BB, &PT, &R));
Modifiers.emplace_back(new ExtractElementModifier(BB, &PT, &R));
Modifiers.emplace_back(new ShuffModifier(BB, &PT, &R));Такой код не показался подозрительным даже разработчикам LLVM. Фрагмент кода как раз взят из этого проекта.
На самом деле, такое использование emplace_back потенциально опасно. В случае если вектору понадобится реаллокация и он не сможет выделить память под новый массив, то он бросит исключение. Как следствие, указатель, возвращенный оператором new, будет потерян. Произойдёт утечка памяти. Правильнее:
Modifiers.push_back(
std::unique_ptr<LoadModifier>(new LoadModifier(BB, &PT, &R));Конечно, в случае маленьких массивов, таких, которые создаются в LLVM, опасность выглядит надуманной. Однако в проекте с массивами большого размера такой код недопустим. Все ли знают про такую потенциальную ошибку? Хотя это не сложная тема, учесть всё это при программировании на С++ нереально. Уж очень много вот таких мелких и тонких моментов. Собственно, про такие моменты целые книги пишут, например Дьюхэрст Стефан К. – "Скользкие места С++".
Итоговая ситуация
Чем больше становятся проекты и чем хитрее язык С++, тем сложнее написать качественный надёжный код. И можно прямо сейчас наблюдать, как растёт размер проектов и сложность языка.
Тех технологий, которых хватало 10-20 лет назад для обеспечения качества кода, теперь недостаточно.
Образно говоря, чтобы написать MS-DOS 1.0, достаточно обзоров кода, юнит-тестов и тестирования. Но этого недостаточно, чтобы сейчас вести разработку ClickHouse. Почему?
Потому, что MS-DOS 1.0 – это 12 тысяч строк кода на языке ассемблер. А ClickHouse – это более 500 тысяч строк на языке C++.
Примечание. Считается, что писать на ассемблере сложнее, чем на C или C++. Но эта сложность из-за "многословности". Просто приходится много писать, чтобы достичь нужного результата :). При равном количестве строк программа на C++ сложнее, чем на ассемблере.
Итог. Мы разобрались почему потребовались компенсационные технологии, чтобы совладать с повышением сложности разработки надёжного кода.
Механизмы компенсации
Когда-то классическими методами для обеспечения качества программного обеспечения являлись обзоры кода и ручное тестирование. Затем стали много говорить про юнит-тесты и разработку через тестирование (TDD). Сейчас разрабатывать программный проект без использования юнит-тестирования считается варварством. Следующими технологиями, которые были призваны улучшать стабильность и надёжность программ, являются динамический и статический анализ кода.
Написанное выше весьма условно! Те же статические анализаторы применяются в сфере разработки с незапамятных времён. Другое дело, что за последнее десятилетие они вышли на новый уровень. Современные статические анализаторы – это не те же самые "линтеры", с которыми программисты работали 20 лет назад.
Динамические анализаторы тоже пережили второе рождение. И сейчас санитайзеры активно встраиваются в процесс разработки огромного количества проектов. Однако сегодня поговорить хочется именно о статических анализаторах.
Статический анализ кода
Статический анализ кода – это обзор кода, выполняемый программой. Анализатор указывает программисту на фрагменты программы, которые содержат какие-то аномалии. Изучая эти предупреждения, автор кода принимает решение, исправить код или оставить всё как есть (подавить срабатывания).
Статический анализ кода не заменяет классические обзоры кода! Он их дополняет. При обзорах кода происходит обмен опытом, обучение новых сотрудников, выявляются высокоуровневые дефекты и ошибки проектирования. С другой стороны, статические анализаторы не устают и хорошо находят опечатки, которые легко ускользают от людей (примеры: 1, 2, 3).
Статические анализаторы не конкурируют с динамическими анализаторами или другими методологиями выявления ошибок. Только комплексное использование различных подходов позволяет сейчас достигать высокого качества и надёжности в больших развивающихся проектах.
Рассмотрим на конкретных примерах, как статические анализаторы кода помогают делать код понятней, качественней и надёжней. Для демонстрации возьмём статический анализатор кода PVS-Studio. Он может использоваться как самостоятельно, так и как плагин для Visual Studio, SonarQube и так далее. Сейчас мы воспользуемся плагином PVS-Studio для среды разработки JetBrains CLion.
Кстати, в самой среде JetBrains CLion уже встроен статический анализ кода, который сразу выделяет подозрительные конструкции в процессе написания кода. Тем не менее, есть смысл посмотреть и на внешние анализаторы кода. У каждого анализатора есть свои сильные стороны. Один статический анализатор – хорошо, а два – лучше :).
Возьмём с GitHub проекты Poco и Boost. Откроем их в JetBrains CLion, проверим с помощью плагина PVS-Studio и разберём некоторые предупреждения.
Утечка памяти – ошибка из-за невнимательности
Запустив проверку проекта Poco, мы можем увидеть предупреждение, сигнализирующее об утечке памяти. Динамически выделяется массив, адрес которого сохраняется в переменной pAdapterInfo. Программист выбрал ручное управление памятью, что чревато ошибками. Сложно контролировать, чтобы все пути выполнения программы содержали код для освобождения памяти. Именно эта опасность и проявила себя: функция может быть завершена вызовом оператора return без предварительного вызова оператора delete [].
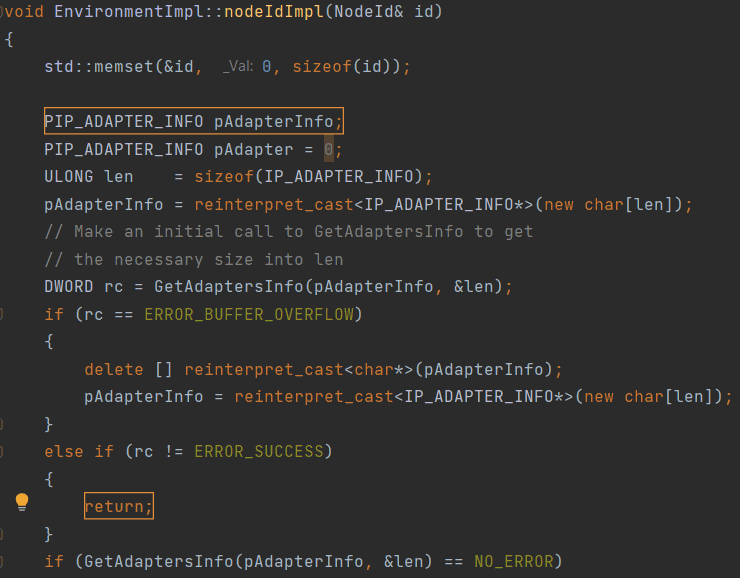
Предупреждение PVS-Studio: V773 The function was exited without releasing the 'pAdapterInfo' pointer. A memory leak is possible. Environment_WIN32U.cpp(212), Environment_WIN32U.cpp(198)
Эта ошибка, обнаруженная анализатором, возникла из-за невнимательности. Однако, если смотреть глубже, причина ошибки – опасный стиль программирования. Намного лучше использовать в таких случаях умные указатели. И это хороший повод вспомнить уже прозвучавшую ранее мысль, что статический анализ не заменяет обзоры кода и общение людей. Анализатор может найти ошибку. А вот задача обучения, которая представляет собой высокоуровневый процесс, по-прежнему остаётся ответственностью человека. На обзоре кода и разборе таких ошибок можно и нужно учить коллег, как писать надёжный и безопасный код.
Отсюда вытекает сценарий, когда об ошибках, найденных в коде, уведомляется не только сам программист, но и его руководитель. Ведь недостаточно, чтобы программист просто исправил баг. Важно ещё и научить его писать код так, чтобы минимизировать вероятность таких ошибок. В PVS-Studio для таких целей может быть использована утилита blame-notifier. Впрочем, мы отвлеклись, давайте вернёмся к статическому анализу кода.
Всегда истинное условие — опечатка
Ещё одна ошибка, возникшая в проекте Poco по невнимательности. На первый взгляд, код вполне осмысленный. Если же присмотреться, выясняется, что часть условия всегда истинна.
Чтобы увидеть ошибку, сразу скажем, что константа POLLOUT объявлена в системном файле WinSock2.h следующим образом:
#define POLLWRNORM 0x0010
#define POLLOUT (POLLWRNORM)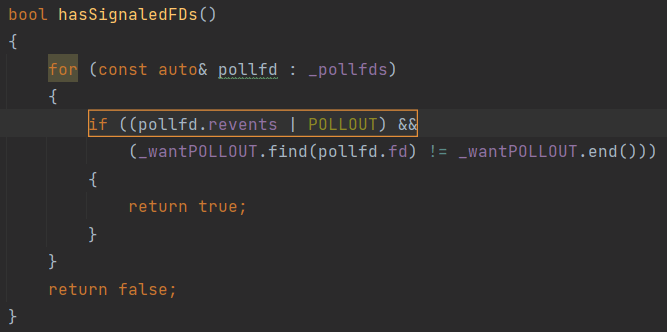
Предупреждение PVS-Studio: V617 Consider inspecting the condition. The '(0x0010)' argument of the '|' bitwise operation contains a non-zero value. PollSet.cpp(398)
Правильным вариантом будет использование оператора &. Классическая опечатка.
Фокусники не рассказывают про свои секреты. Как только расскажешь, магия исчезнет. Всё будет казаться очевидным и неинтересным.
Похожий эффект есть со статическим анализом. Сейчас, рассматривая эту ошибку, вы удивляетесь, как её вообще можно было допустить, а потом не заметить на обзоре кода. Кажется, что статический анализ — это какой-то обман. Находятся и без того очевидные и заметные ошибки. Однако даже вот такие простые ошибки успешно появляются в коде, а потом мешают жить. Люди склонны преувеличивать свою внимательность и аккуратность (1, 2, 3). Инструменты статического анализа – отличные помощники, которые никогда не устают и не ленятся проверять даже самый скучный код.
Нет затирания памяти — особенности оптимизаций компиляторов
До этого мы рассматривали случаи, когда ошибки сразу понятны любому программисту. Однако статические анализаторы способны помочь и в выявлении дефектов, которые связаны с "тайными знаниями". Имеется в виду, что программист может просто не знать, что использует какой-то ошибочный паттерн. Он просто не знает, что так писать код нельзя.
Красивым примером может служить вызов внутри DllMain функций, которые вызывать там нельзя. Работоспособность кода будет зависеть от везения (последовательности загрузки DLL). Программист может не догадываться, что код некорректен, так как именно у него всё может успешно работать. Подробнее.
Другим хорошим примером, который мы сейчас разберём, является отсутствие затирания памяти. Перед нами всё тот же проект Poco. В деструкторе программист планирует затереть какие-то приватные данные, после чего освободить буферы, в которых они хранились.
Если не знать нюансы, то кажется, что всё отлично. На самом деле перед нами классический дефект безопасности CWE-14 (Compiler Removal of Code to Clear Buffers).
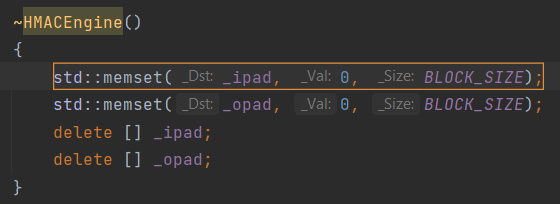
Предупреждения PVS-Studio:
- V597 The compiler could delete the 'memset' function call, which is used to flush '_opad' object. The RtlSecureZeroMemory() function should be used to erase the private data. HMACEngine.h(62)
- V597 The compiler could delete the 'memset' function call, which is used to flush '_ipad' object. The RtlSecureZeroMemory() function should be used to erase the private data. HMACEngine.h(61)
Компиляторы, выполняя оптимизации, вправе удалить вызов функций memset. Более того, они не только вправе, они это делают на практике. С точки зрения языка C++ выполнение операции затирания памяти является избыточным действием. Память после заполнения некими значениями сразу освобождается. Значит, заполнение избыточно и его можно удалить. Подробности можно найти в статье "Безопасная очистка приватных данных".
Компилятор прав в рамках языка C++. То, что где-то в памяти остаются приватные данные, это более высокоуровневое понятие, про которое компилятор не знает. К сожалению, про него не знают и многие программисты. Аналогичные ошибки можно встретить даже в таких проектах, как Crypto++, XNU kernel, MySQL, Sphinx, Linux Kernel, Qt, PostgreSQL, Apache HTTP Server и так далее.
Статические анализаторы могут выявить многие такие дефекты. Особенно это ценно, если речь идёт о потенциальных уязвимостях кода. В больших проектах без этого вообще непонятно как обойтись. Как узнать, что все приватные данные успешно затираются в легаси-коде? Или, возможно, там уже 7 лет есть уязвимость, которую кто-то нашёл и тихо использует?
Неопределённое поведение – тонкости языка
Мы говорили, что язык C++ сложен, и это мешает писать надёжный код. Продемонстрируем это на фрагменте кода, взятого из библиотеки Boost.
Вначале нам понадобится показать, как объявлен член i.
typedef long int_literal_type;
typedef unsigned long uint_literal_type;
....
union {
int_literal_type i;
uint_literal_type ui;
bool b;
} value;Теперь некорректный код:

Предупреждение PVS-Studio: V610 Undefined behavior. Check the shift operator '<<='. The right operand is negative ('shift_by' = [-64..64]). cpp_expression_value.hpp(676)
Программист ограничивает значение переменной shift_by диапазоном [-64..64]. Соответственно, он хочет сдвигать значение знаковой переменной i влево или вправо. Но так делать нельзя! Это неопределённое поведение. Вот что говорит стандарт:
The type of the result is that of the promoted left operand. The behavior is undefined if the right operand is negative, or greater than or equal to the length in bits of the promoted left operand.
Этот код нарушает стандарт два раза. Во-первых, нельзя использовать отрицательные значения во втором операнде. Во-вторых, значение 64 великовато, даже если int_literal_type всегда представлен 64-битным типом. И вообще лучше не связываться со сдвигами знаковой переменной, раз у нас есть её беззнаковый аналог.
Правильно будет написать приблизительно так:
if (shift_by <= -64 || shift_by >= 64)
{
value.ui = 0;
}
else if (shift_by < 0)
{
value.ui >>= -shift_by;
}
else // shift_by > 0
{
value.ui <<= shift_by;
}Да, это длиннее, но зато нет неопределённого поведения.
Внедрение статического анализа кода
Существует множество различных анализаторов кода: List of tools for static code analysis. У них есть свои слабые и сильные стороны. Выбор статического анализатора кода – непростая задача, и эта тема выходит за рамки статьи. Однако подскажу, от чего можно оттолкнуться.
Первое. Нужно попробовать сформулировать для себя требования к статическому анализатору. Затем можно попробовать те, которые соответствуют выбранным критериям, и решить, какой наиболее удобен для вас. Для примера, самые простые критерии: поддержка используемого вами языка программирования, поддержка вашей среды разработки, возможность интеграции в вашу CI/CD.
Рассмотрим другой пример. Допустим, вы разрабатываете программное обеспечение для встраиваемых систем и ваш код должен соответствовать стандарту MISRA. Естественно, что тогда вам потребуется такой анализатор, который этот стандарт поддерживает. Например, им может быть анализатор кода, встроенный в среду разработки CLion. Среда сразу подсвечивает код, который не соответствует стандарту MISRA (см. MISRA checks supported in CLion). Это поможет сразу писать код, во многом удовлетворяющий требованиям встраиваемых систем. Однако этого будет недостаточно, когда станет вопрос получения отчёта MISRA Compliance. И придётся воспользоваться дополнительными инструментами или другим анализатором. См. также статью "Зачем нужен отчёт MISRA Compliance и как его получить в PVS-Studio?".
Второе. Стоит учитывать, нужна ли вам инфраструктура для интеграции анализатора в большой проект. Дело в том, что любой статический анализатор выдаёт ложно-положительные срабатывания, которых особенно много на этапе внедрения. И это может стать препятствием. Достаточно плохая идея сразу "сразиться" с тысячами предупреждений.
Если вы используете простой статический анализатор, например Cppcheck, то данной инфраструктуры просто нет. И такой плюс, как бесплатность Cppcheck, будет полностью нивелирован невозможностью быстро и просто начать использовать его в legacy-проекте.
В свою очередь профессиональные инструменты, такие как PVS-Studio, предоставляют такую вещь, как baseline. Анализатор может сразу спрятать все сообщения, которые он сейчас выдаёт. Это технический долг, к которому вы сможете вернуться позже. Так вы увидите предупреждения, относящиеся только к новому или изменённому коду. При этом анализатор хранит в базе больше информации, чем номера строк со скрытыми предупреждениями. Это позволяет ему не ругаться на старый код, как на новый, если вы добавите в начало файла несколько строк.
Впрочем, всё это технические возможности, и мы не будем погружаться в них более детально. Важно то, что анализатор позволит сразу внедрить его и начать получать пользу от использования.
Подробнее данная тема раскрывается в статье "Как внедрить статический анализатор кода в legacy проект и не демотивировать команду".
Про выбор анализатора поговорили, а теперь – самое важное! В конце концов, не так принципиально, какой анализатор вы выберете. Самое важное – использовать его регулярно!
Это простая, но очень важная мысль. Частая ошибка — запускать анализ кода только перед релизом. Это крайне неэффективно. Это то же самое, что включать предупреждения компилятора только перед релизом. А всё остальное время мучиться, устраняя ошибки с помощью отладки.
Рекомендую дополнительно прочитать вот эту статью "Ошибки, которые не находит статический анализ кода, потому что он не используется". Она и забавная, и грустная одновременно.
Заключение
Вы совершили экскурсию в мир статического анализа кода. Да, в статье было много отсылок к другим материалам. Прошу прощения, что потребуется время, чтобы их изучить или хотя бы полистать. Зато обещаю, что после этого у вас сложится целостная картина.
И самое время попробовать статический анализ в деле. Например, установить плагин PVS-Studio для CLion.
Спасибо за внимание и безбажного вам кода.
Дополнительные ссылки на тему статического анализа кода
- Джон Кармак. Статический анализ кода.
- PVS-Studio. Статический анализ кода.
- Al Bessey, Ken Block, Ben Chelf, Andy Chou, Bryan Fulton, Seth Hallem, Charles Henri-Gros, Asya Kamsky, Scott McPeak, Dawson Engler. Coverity. A Few Billion Lines of Code Later: Using Static Analysis to Find Bugs in the Real World.
- Loic Joly, SonarSource. False positives are our enemies, but may still be your friends.
- The Cherno. Static Analysis in C++.
- C++ Siberia 2021: Анастасия Казакова. JetBrains Статический анализ кода++.
Koval97
Самое гениальное, когда до 90% багов и проблем отладки убирает самое обычное комментирование кода, ещё лучше самая обычная справка по используемым библиотекам.
А ещё лучший совет, просто записывать хотя бы набросок задачи на бумаге и уже понимая это реализовывать в программе.
Я не буду давить на больное, но слишком часто приходится видеть, как опытные программисты, выдающие себя за наставников, пренебрегают даже такими элементарными вещами.
El_Kraken_Feliz
Документация кода это очень тяжёлый труд. И не очень интересный и обычно малооплачиваемый. Так что живём, как живём. Я в свои старые проекты иногда заглядываю и тоже сначала задаюсь вопросом "а чё это вообще" и потом "какой идиот это писал?". Больше опыта - больше понимания что можно, а что нельзя. Но подозреваю, что лет через пять мой нынешний код тоже мне покажется жутким
DarkEld3r
Который ещё и быстро устаревает.
Koval97
MSDN - крупнейшая документация по Windows, функциям ее основных библиотек и служб. Живет и здраствует в трёх десятилетиях.
Документация по DirectX, OpenGL и говорить не приходится. Документация по всем серверным движкам - туда же.
Маунлы к плагинам AIMP, MPC, VLC, к движкам Chromium, WebKit, Kisco и множества других - актуальны в любое время.
И этот список можно было бы продолжать, и продолжать. Но я говорил, даже не об справке к серьёзному ПО, инструкциях ReadMe к любому любительскому или от энтузиастов.
Я говорил об простом человеческом комментирование, а вы сразу минусовать.
Koval97
Я тоже много гавнокодил, когда только начинал. Все через это проходили, совершенно не понимаю чего тут стесняться. В резюме так и так только актуальные проекты смотрят, и то для того чтобы узнать твой стиль. И никогда это не было условием отказа - по себе говорю, был и на более шизонутых собеседованиях.
CodeRush
Комментарии лгут, и компилятор их игнорирует. Код нужно так писать, чтобы комментарии были нужны исключительно для объяснения архитектурных моментов, которые из непосредственно кода реконструировать сложно из за разницы в уровне абстракции. Все остальное должно быть написано так, чтобы поняли и человек, и машина, и статический анализатор очень помогает в том, чтобы прояснить моменты, которые для человека очевидны в одну сторону, а для машины — в другую, вон как с упомянутой выше разницей между memset и memset_s, с as-if rule, и прочими вещами, про которые ребята из СиПроВер постоянно статьи пишут. Писать же человеку одно, а машине другое — гарантировать себе проблемы с тем, что теперь непонятно, чему верить, что на самом деле имел в виду автор, и зачем он это имел в виду.
Koval97
Я сферических коней в вакууме не обсуждаю. Мне это не интересно.
Комментарии нужны для человека, а не компилятора. И каким бы код вы не писали, но без комментариев человек рано или поздно потеряет семантическую нить. Это с виду кажется, что одного приема нейминга переменных хватит с головой, на деле чуть ли не схематические диаграммы рисуют чтобы понять "что, куда и в каком виде".
Не было бы С++, классов, пяти основ и всего ООП, если хватало только "чистого кода". Не понимаю я этого перфекционизма - прекрасно работаю и без него. И самое главное, никакого стресса от сложной работы.
Как и притензий ребят выше. Верить надо академическим справочникам, а не всяким форумным сплетням, генерируемым форумными "экспертами", которые самый простой скрипт пишут от силы раз в год.