

Введение
В данном посте мы, с помощью методов автоматической обработки текстов (Natural Language Processing или просто NLP), исследуем стиль речи 6 главных героев знаменитого сериала «Друзья», проведем мультиязычный анализ для русского и английского языков, а также обучим нейросеть общаться в стиле главных героев Друзей.
Intro
Перенос стиля (Style transfer) стремительно завоевывает популярность в NLP, и сегодня его используют в самых разных сферах: от образования до персонализации электронных помощников. А с развитием больших трансформерных моделей, которые показывают выдающиеся способности в области понимания естественного языка и имитации самых разных стилей, style transfer вышел на новый уровень. Сегодня большие языковые модели, такие как GPT3, благодаря своим объемам и миллиардам параметров, способны отлично выучивать все особенности обучающей выборки (то есть train distribution) и генерировать реалистичный текст в определенном стиле.
В данном посте мы исследуем возможности языковых моделей для генерации текста в стиле героев знаменитого сериала “Друзья”. Для этого мы собрали корпус английских транскриптов сериала, перевели его на русский и обучили модели для двух языков общаться в стиле каждого из 6 персонажей.
Помимо этого, мы провели анализ стиля, изучили особенности речи каждого из 6 главных героев, а также сравнительный анализ между английским и русским языками.
Таким образом, наш проект можно условно разделить на 3 части:
Выбор персонажа и сбор данных
Стилистический анализ речи персонажей
Framework для обучения моделей, который пишут текст в стиле одного из 6 персонажей
Весь код и данные вы можете найти в нашем GitHub репозитории, а мы пока расскажем обо всем по порядку.
Данные
Выбор персонажа
Самое первое, что нам необходимо было сделать, до того как приступать к style transfer — выбрать персонажа для переноса стиля. Изначально мы поставили перед собой достаточно амбициозную цель — собрать гигантский датасет с репликами какого-нибудь известного человека или выдуманного героя, но оказалось, что на практике это не так-то просто. Мы сразу решили не ввязываться в политику и тем самым отсекли всех политических фигур. Первым делом мы попробовали найти транскрипты русских шоу типа «Вечерний Ургант», но оказалось, что подобных скриптов нет в публичном доступе (либо они запрятаны так глубоко, что мы их не нашли).
Анализ субтитров на YouTube и других подобных платформах также не дал результатов, так как в них было много ошибок, они не всегда соответствовали истинным словам говорящего, а качество автосгенерированных субтитров оставляло желать лучшего.
Попробовали взять кого-то из литературных героев. Кажется, куда уж более надежный источник данных, чем книги. Но и тут нас ждало разочарование — оказалось, что если отфильтровать только реплики персонажа, убрав все описания и прочее, то не наберется даже на небольшой датасет, пригодный для обучения. Для тех героев из литературы, которых мы рассматривали, нам не удалось набрать и 1000 высказываний, а это совсем-совсем мало.
Тогда мы решили использовать сериалы, и в результате остановились на знаменитом английском ситкоме «Друзья», который шел с 1994 по 2004 год. Несмотря на свой возраст он популярен и сегодня. Этот комедийный сериал рассказывает о жизни шести друзей (Росса, Фиби, Моники, Рейчел, Джоуи и Чендлера), которые живут в Нью-Йорке и постоянно попадают в какие-нибудь передряги и смешные ситуации. Почему мы выбрали именно этот сериал? По трем причинам:
Мы нашли транскрипты 236 эпизодов в публичном доступе. Ура! Достаточное количество данных! На таком датасете уже можно обучать языковую модель.
Сериал содержит диалоги целых шести персонажей (а не одного), что открывает нам возможность для сравнительного анализа
Это популярный сериал, который многие из нас смотрели и хорошо знают. А значит, мы можем делать предположения о данных (например, Фиби говорит более простыми словами и т. п.) и оценивать реалистичность стиля сгенерированного текста на основании нашего зрительского опыта.
Сбор данных
Оригинальные транскрипты, которые мы соскрепили из интернета, были на английском, так как на русском транскриптов в публичном доступе нам найти не удалось. Мы перевели их на русский с помощью Google переводчика (Cloud translation API от Google). Затем мы провели следующую предобработку текста на русском и английском:
Во-первых, мы почистили данные от мелких графемных ошибок, специфичных для транскриптов. Например, если герой говорил что-то протяжно, то его слова могли содержать повторение гласных для имитации длинного звука («неееееееееет»). Другие фразы содержали повторы вопросительных и восклицательных знаков для имитации эмоций на письме («Неееет!!!», «ЧТОоооо???») Так как такие «ошибки» достаточно нестандартные, мы не стали пользоваться готовыми библиотеками, а написали свою систему правил по очистке данных и применили ее к транскриптам.
Во-вторых, мы заметили, что некоторые слова для комичности содержали повторения одного и того же слова. Такие повторения мы также убрали, оставив лишь одну копию повторяемого слова.
В-третьих, поскольку мы хотели уловить стиль уникальный для каждого персонажа, мы выкинули общеупотребительные фразы, которые использовали все 6 главных героев («Знаешь что!», «О боже!» и т.п.)
Таким образом, мы собрали корпус диалогов для 6 героев, который включал 14196 предложений для английского и 14144 для русского. Подробное распределение по числу предложений и слов для каждого персонажа можете посмотреть в таблице ниже:

Анализ стилей персонажей
Перед тем как обучать языковые модели, мы исследовали особенности стиля каждого из героев. А именно, чтобы выявить особенности речи каждого персонажа, мы сделали следующее:
Посчитали описательные статистики для каждого героя: число слов, среднее количество слов в предложении, индекс readability, долю сложных слов и т. д.
Наиболее частотные для персонажей слова;
Долю позитивных и негативных слов.
Из таблицы выше можно сделать предварительные выводы о специфике речи героев. Например, Росс и Рейчел самые разговорчивые, у них максимальное число предложений. Можно также заметить, что количество предложений отличается для русского и английского. Это скорее всего объясняется особенностями структуры каждого из языков (например, более сложные правила пунктуации для русского языка) и неточностями, возникшими при автоматическом переводе.
После такого первичного анализа речи мы исследовали словарный запас каждого из героев подробнее и проанализировали его с точки зрения сложности, используемых героями слов. За «сложные» слова мы условно приняли длинные слова, состоящие более чем из 4 слогов. Долю сложных слов для каждого героя можно видеть на графике ниже:

Речь персонажей действительно сильно отличается по сложности. Так, например, Росс — немного занудный ученый-палеонтолог — использует наибольший процент сложных слов (2,6%), а Рейчел, которая по сюжету наиболее беззаботная из героинь, лишь в двух процентах случаев прибегает к сложным словам.
Затем мы выявили слова, наиболее характерные для каждого персонажа. Для этого мы использовали TF-IDF — это статистическая мера, которая придает большой вес словам, специфичным для данного героя, которые он наиболее часто употребляет, не учитывая при этом частотные слова и стоп-слова, которые присутствуют в речи всех друзей. К таким мусорным стоп-словам относятся, например, предлоги (а, и, но) и местоимения (я, мы, ты) и т. п. На изображениях ниже приведены результаты для Росса и Фиби. Размер слова пропорционален его TF-IDF весу для данного героя (то есть чем больше слово, тем оно характернее для героя). Так, например, слова «Знаю» и «Думаю» намного более типичны для Росса, чем «Могу».


Мы видим, что Росс и Фиби на английском часто используют такие слова как "Thank'' и "Guy'', при этом на русском для них нет подобного характерного аналога. А такие слова как "Know" (знаю/знаешь) и "Hey" (привет) имеют большой TF-IDF на обоих языках. Получается, что в специфической лексике героев между языками нет полного соответствия и набор типичных слов отличается от языка к языку. При этом мы видим, что характерные слова различаются для героев. Фиби обожает словечко «Ой» (Oh) в то время как русскоязычный Росс частенько употребляет слова «Просто» и «Эй», а его англоязычная версия любит словечки типа “Okay” и “Hey”.
В заключении нашего анализа стиля мы посмотрели на то, насколько позитивными являются наши герои. Для этого мы взяли корпус эмоционально окрашенных слов из Twiiter’а, который содержал списки позитивных (к таким словам относятся like, yes, good, please, best и т. д.) и негативных (например, horror, no, lazy, illness) слов. Затем мы подсчитали долю слов каждого класса в речи персонажей. Результаты приведены на графике ниже.

Из графика видно, что все персонажи используют негативные слова примерно с одинаковой частотой, около 2%. Лидирует по негативности с результатом 2,21% Фиби, а наименее негативной оказывается Моника, у которой доля негатива составляет всего 1,93%. При этом Фиби оказывается и наиболее позитивной из всех, вырываясь вперед с результатом 5,94%, а замыкает рейтинг вновь Моника с долей позитивных слов 5,03%. Простыми словами, речь Фиби оказывается наиболее эмоционально окрашенной, в то время как Моника является самой нейтральной из Друзей, не склонной к проявлению эмоций.
Что ж, собрав воедино все результаты стилистического анализа, мы выбрали трех персонажей, на которых в дальнейшем решили тестировать наши модели по style transfer:
Росс — немного занудный ученый, употребляющий наиболее сложную лексику в своей речи;
Рейчел — позитивная и беззаботная героиня, с простой и несложной речью;
Фиби — яркая и эмоциональная, употребляющая при этом достаточно простые слова.
Структура финального датасета
Итак, мы определились с наиболее интересными персонажами, с которыми мы будем экспериментировать в первую очередь. Для моделирования мы снабдили все реплики дополнительным набором токенов и тэгов:
Специальные токены <s> и </s>, которые обозначают начало и конец примера.
Имя одного из 6 героев (автора реплики), написанное заглавными буквами.
Специальный псевдоним НЕДРУГ (NOTFRIED), который являлся маркером реплики другого спикера в диалоговых парах “реплика НЕДРУГА — ответ ГЕРОЯ”. Такой псевдоним мы использовали, чтобы отделить реплики других людей, от героя, стиль которого мы хотим имитировать.
Используя данные с дополнительными токенами, мы сформировали по три вида датасетов для каждого персонажа для русского и английского языков. Ниже приведено краткое описание каждого из них:
1.Raw monologues (монологи) — датасет, содержащий отдельные реплики одного из персонажей. Такие данные позволяют модели получить наибольшую информации о стиле конкретного персонажа.

2.Raw dialogues (диалоги) — датасет, содержащий пары “реплика НЕДРУГА — ответ ГЕРОЯ”, разделенные символом переноса строки \n. Диалоговый датасет нужен, так как мы хотим, чтобы наша модель умела поддерживать беседу с пользователем в стиле Друзей, а не просто генерировать текст.

3.Cleaned dialogues (очищенные диалоги) — модификация предыдущего диалогового датасета, из которого мы выкинули частотные реплики, произносимые всеми героями, не несущими никакой информации о стиле конкретного персонажа. Например: «Да, ты был прав!»

Таким образом, мы сформировали в общей сложности 36 разных датасетов = 3 типа * 6 персонажей * 2 языка, на которых мы наконец можем обучать наши языковые модели.
Style Transfer
Для того, чтобы научиться имитировать Друзей и генерировать тексты в стиле главных героев, мы выбрали классический подход файн-тьюнинга трансформерных языковых моделей, а именно GPT моделей. Для русского языка мы взяли предобученную RuGPT3-Large, основанную на архитектуре, предложенной в статье, а для английского воспользовались предобученной GPT2. Стоит отметить, что мы не смогли воспользоваться GPT3 для английского языка, так как ее нет в открытом доступе. Для русского мы использовали предобученную RuGPT3-Large из python-библиотеки HuggingFace и использовали стратегию random sampling при генерации, чтобы добавить вариативность в сгенерированные тексты.
Однако, прежде чем обучать финальные Large модели, мы провели серию экспериментов с маленькими версиями RuGPT3-Small, которые содержат значительно меньше параметров, а потому их до-обучение требует намного меньше времени и ресурсов. Основной целью экспериментов было определить, на каком же именно из большого числа сформированных датасетов лучше всего обучать большие Large аналоги.
Мы предположили, что модели лучше обучать в два этапа: вначале на монологах, а затем на диалоговом датасете. Обучение на монологах позволит модели выявить особенности стиля каждого персонажа, специфичные для него слова и обороты, а файн-тьюн на диалогах научит модель имитировать диалог с пользователем. Дополнительно мы также протестировали несколько одноэтапных стратегий файн-тьюна: на монологах, диалогах и очищенных диалогах. Мы сделали это, чтобы проверить, что при двухступенчатом обучении мы не добавляем дополнительный шум.
Таким образом, мы протестировали 5 разных стратегий файн-тьюна для трех героев (Росса, Фиби и Рейчел):
только монологи
только диалоги
только очищенные диалоги
монологи + диалоги
монологи + очищенные диалоги.
Затем мы эмпирически оценили качество на небольшом наборе диалоговых пар для каждого персонажа. Ниже приведен пример для Росса:

По нашим эмпирическим оценкам лучшей оказалась последняя конфигурация (монологи + очищенные диалоги). При ее использовании модель генерировала наиболее осмысленные фразы и лучше всего улавливала стиль. Используя такой двухступенчатый вариант, мы обучили Large версии моделей для всех 6 персонажей для русского и английского языков.
Для того чтобы оценить качество обученных моделей, а также их способность имитировать стиль Друзей, мы прибегли к ручной разметке. Для этого мы выбрали 100 реплик НЕДРУГА на разные темы (кино, спорт, отдых, работа и т. п.), для которых затем сгенерировали ответы трех персонажей: Росса, Рейчел и Фиби (напомню, в разделе по стилистическому анализу мы договорились все основные эксперименты проводить на них). Затем мы оценили сгенерированные реплики по 4 критериям: сила стиля, адекватность, естественность и интересность.
Сила стиля отражает то, насколько легко угадывается стиль персонажа. Например, фраза "You'll see! You'll all see!'' получит высший балл по этому критерию для английской версии Фиби. Адекватность отражает то, насколько ответ героя адекватен и соответствует реплике НЕДРУГА. Так на вопрос НЕДРУГа “Отличный день, не правда ли?” ответ “Да, просто великолепный!” получит самую высокую оценку.
Естественность отвечает за то, насколько “человечно” звучит сгенерированный моделью текст. Например, фраза “Большое спасибо” получит высокую оценку по этому пункту, а “Здоровое спасибо” наоборот — низкую. Заключительный критерий — интересность — отвечает за сложность и нетривиальность сгенерированных предложений и призван отсеять слишком примитивные фразы. Например, просто ответ “Да” будет менее интересным, чем “Да, будет не лишним”.
Мы оценили сгенерированные моделями фразы по трехступенчатой шкале 0, 0.5 и 1 (0 — самая низкая оценка, 1 — наивысшая), а затем усреднили результат между фразами и между тремя ассесорами. Ниже представлены результаты для русского и английского:

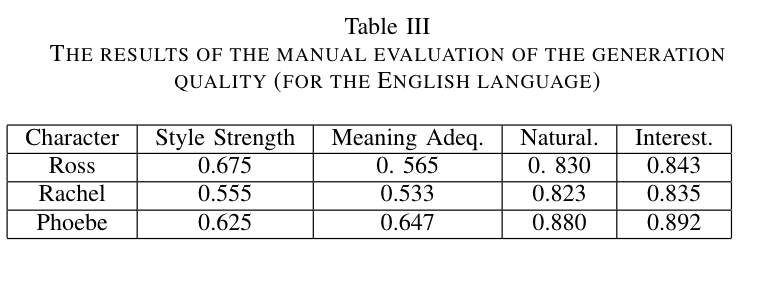
Можно заметить, что для всех героев естественность на русском ниже, чем на английском. Это может быть связано с более низким качеством автопереведенных русских реплик, которые использовались для обучения на русском, по сравнению с качеством оригинальных английских транскриптов. Ожидаемо, для Росса, с более научным стилем речи, богатой сложными словами, его сила стиля на английском значительно выше, чем на русском: 0.675 по сравнению с 0.418. Это верно и для адекватности его речи (0.564 VS 0.515). А вот для Фиби, с более простым и примитивным стилем речи, сила стиля при переходе от английского к русскому наоборот возросла (0.625 VS 0.775).Style Transfer
Заключение и дальнейшие планы
Итак, мы с помощью методов Natural Language Processing исследовали стиль речи 6 персонажей знаменитого сериала «Друзья», провели мультиязычный анализ для русского и английского, а также обучили GPT-based языковые модели разговаривать в стиле главных героев Друзей.
В дальнейшем мы хотим поэксперементировать с моделями еще бОльшего размера. Например, в планах попробовать RuGPT-3 XL, а также методы управляемой генерации текстов для них.
Благодарность
Эта работа результат совместных трудов большой команды из шести человек (нас шестеро, прямо как Друзей): @Mr-S-Mirzoev, @polly_tarants, @spetrov0908, @elina_ted, @alenusch и я, ваша покорная слуга и рассказчица, @mashkka_t. Спасибо вам огромное за совместную работу над «Друзьями», за креативные идеи и ваш вклад в развитие проекта!
Обучение
Также хочу сказать о том, что я являюсь руководителем курсов по Machine Learning в OTUS, поэтому всех кто заинтересован в обучении, приглашаю на наши бесплатные мероприятия. В рамках вебинаров формата "Demo Day" можно будет подробно узнать о курсах, ознакомиться с программой и процессом обучения, а также ближе познакомиться со мной и узнать о моем бэкграунде. Регистрируйтесь по ссылкам ниже:
Комментарии (8)

putnik
26.10.2021 17:42+16Интересно, конечно, но чувствуется недосказанность: «Мы учили и научили, а что получилось — мы вам не покажем».

mashkka_t Автор
27.10.2021 15:14Результаты можно посмотреть в нашем гитхабе, там есть код по обучению моделей https://github.com/Alenush/style_transfer_sirius2021summer/blob/master/utils/Models_Fine_tuning_example.ipynb

shadrap
26.10.2021 18:04+3позволю себе усомниться в цифрах... обычный человек , скажем обычный человек использует 15000-17000 слов в активном разговорном словаре , профессор или энтерпрайз бизнесмен, где-то до 30000, 126 тысяч уникальных слов у Роса это не слишком ли много?
mashkka_t Автор
26.10.2021 19:48Да, тут, к сожалению, возникла небольшая путаница между числом слов и уникальных слов! Спасибо, что заметили! Поправила этот момент! Спасибо!

agoncharov
26.10.2021 19:44+2Если вы насчитали всего 15 тысяч предложений у Росса, то 126 тысяч слов это видимо все слова в этих предложениях, а не словарный запас
mashkka_t Автор
26.10.2021 19:48Да, тут, к сожалению возникла небольшая путаница! Спасибо, что заметили! Поправила этот момент!
Matshishkapeu
Странно, я как-то ожидал что по сложности речи хит парад снизу возглавит Джоуи, может ему зачли те сложные слова которые он учил со специальной туалетной бумаги выучил и для репетиций и прослушиваний.
J:"Hey, look, I don't need you getting all judgemental and condescending and pedantic.",
mashkka_t Автор
Оказывается, Джоуи не так уж и прост ;)