

CEO Hasty Тристан Руиллар (в центре), сооснователи компании Константин Проскудин (слева) и Александр Веннман (справа)
Компьютерное зрение становится всё важнее для различных промышленных сфер, от слежения за строительными работами до реализации умного сканирования штрих-кодов на складах. Однако обучение искусственного интеллекта точному распознаванию изображений может быть медленным и затратным трудом, не гарантирующим результаты. Молодой немецкий стартап Hasty стремится помочь в решении этой задачи, обещая предоставить инструменты нового поколения, способные ускорить весь процесс аннотирования изображений для обучаемой модели.
Основанный в 2019 году в Берлине Hasty заявляет сегодня, что ему удалось получить 3,7 миллиона долларов в первом раунде финансирования, проведённом Shasta Ventures. Эта венчурная фирма из Кремниевой долины провела уже множество значимых выводов: Nest (куплен Google), Eero (куплен Amazon) и Zuora (IPO). Другими участниками раунда стали iRobot Ventures и Coparion.
Всемирный рынок компьютерного зрения достиг в 2020 году уровня в 11,4 миллиарда долларов. Согласно прогнозам, это число вырастет к 2027 году до более чем 19 миллиардов. Подготовка и обработка данных — одна из самых затратных по времени задач в сфере ИИ, она занимает в связанных с ним проектах примерно 80% времени. В области компьютерного зрения под аннотированием, или разметкой, подразумевается техника, используемая для маркировки и категоризации изображений с целью предоставления машинам значения и контекста изображения, что позволяет им находить схожие объекты. Основную часть работы по аннотированию приходится выполнять людям.
Hasty стремится решить следующую проблему: подавляющее большинство проектов data science никогда не выходит в продакшен, а в процессе их подготовки тратятся значительные ресурсы.
«Современные подходы к разметке данных слишком медленны», — сообщил нам сооснователь и CEO Hasty Тристан Руиллар. «Инженеры машинного обучения часто вынуждены ждать первых результатов по три-шесть месяцев, чтобы проверить работоспособность их стратегии и методики аннотирования. Причиной этого является задержка между разметкой и обучением моделей».
Ускоряемся
Hasty имеет 10 встроенных автоматизированных ИИ-помощников, каждый из которых предназначен для снижения объёмов работы человека. Dextr, например, позволяет пользователям нажать всего на четыре крайних точки объекта, чтобы выделить его и предложить аннотации.

ИИ-помощник Dextr из Hasty
А ИИ-помощник Hasty «instance segmentation» ускоряет аннотирование, находя несколько экземпляров объекта на изображении.

Сегментация экземпляров объектов при помощи ИИ Hasty
Помощник наблюдает за тем, как выполняют аннотирование пользователи, и достигнув определённого показателя достоверности, может предлагать метки. А пользователь может корректировать эти предложения, чтобы улучшать модель, получая обратную связь об уровне эффективности стратегии аннотирования.
«Это даёт нейросети кривую обучения — в процессе разметки проекта людьми она учится», — рассказывает Руиллар.
Уже существует множество инструментов, предназначенных для упрощения этого процесса, в том числе Amazon SageMaker, поддерживаемый Google Labelbox, V7 и Dataloop, объявивший о новом раунде финансирования на 11 миллионов долларов.
Однако Hasty заявляет, что благодаря сочетанию автоматизации, обучения моделей и аннотирования может сделать весь процесс гораздо быстрее.
Как и другие похожие платформы, Hasty использует интерфейс, через который могут взаимодействовать люди и машины. Hasty может создавать рекомендации аннотаций, изучив всего несколько аннотированных людьми изображений, а пользователь (например, инженер по машинному обучению) при этом способен принимать, отклонять или редактировать это рекомендации. Такая обратная связь в реальном времени позволяет делать модели тем совершеннее, чем чаще они используются. Такую систему называют «маховиком данных» (data flywheel).
«Все стремятся создать самосовершенствующийся маховик данных. Проблема ИИ компьютерного зрения заключается в том, как вообще раскрутить этот маховик, поскольку он очень затратен и срабатывает лишь в 50% случаев. И на этом этапе в дело вступаем мы», — делится Руиллар.
Быстрая обратная связь
По сути, нейросети Hasty обучаются в процессе построения инженерами наборов данных, то есть этапы «сборка», «развёртывание» и «оценка» происходят приблизительно параллельно. При обычном линейном процессе для создания ИИ-модели, которую можно протестировать, могут потребоваться месяцы. При этом модель может оказаться некорректной из-за ошибок в данных или слепых допущений, сделанных в начале проекта. Hasty обещает обеспечить гибкость процесса.
Такой подход не совсем нов, однако Руиллар заявляет, что его компания проводит аналогию между автоматизированной разметкой и беспилотным вождением: сходство заключается в том, что разные технологии работают на различных уровнях. В отрасли беспилотных автомобилей некоторые машины могут только тормозить или перестраиваться, другие же обеспечивают почти полную автономность. Если перенести этот принцип в сферу аннотирования, то, по словам Руиллара, Hasty обеспечивает более глубокую автоматизацию, чем многие его конкуренты, с точки зрения минимизации количества кликов, требуемых для разметки изображения или групп изображений.
«Все восхваляют автоматизирование, но не совсем понятно, что же именно автоматизируется», — объясняет Руиллар. «Почти во всех инструментах есть качественные реализации автоматизации первого уровня, но только немногие из нас озаботились созданием второго и третьего уровней, обеспечивающих значимые результаты».
Так как данные, по сути, являются топливом для машинного обучения, передача большего количества точных данных ИИ остаётся ключевым требованием.

Hasty: уровни автоматизированной разметки
Кроме инструмента для поиска ошибок вручную Hasty предлагает обнаружитель ошибок с поддержкой ИИ, автоматически идентифицирующий вероятные проблемы в данных обучения проекта. Это функция контроля качества, позволяющая обойтись без кропотливого поиска ошибок в данных.
«Это позволяет пользователям заниматься устранением ошибок, а не тратить время на их поиск, а также быстро укрепляет уверенность в данных в процессе аннотирования», — заявляет Руиллар.
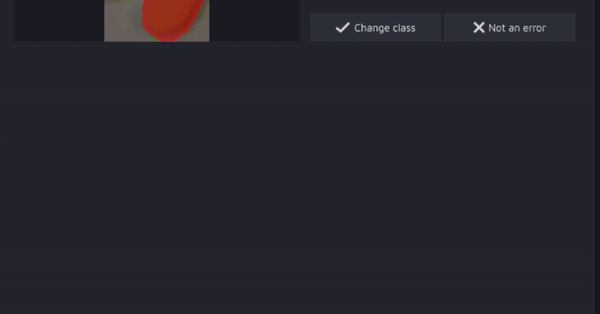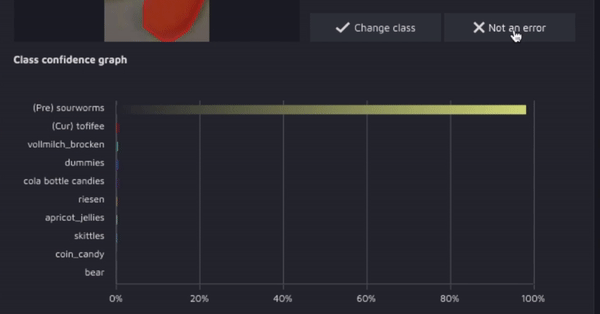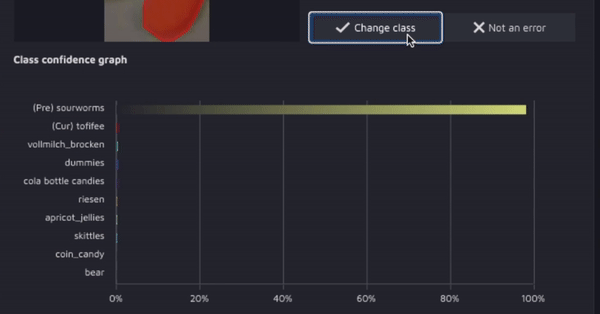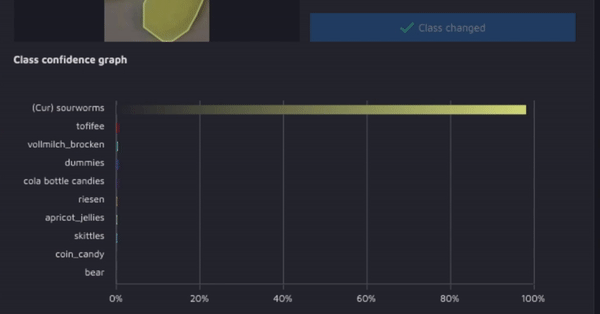
Hasty: обнаружитель ошибок
Hasty заявляет, что продуктом стартапа пользуется примерно четыре тысячи пользователей, среди них корпорации, университеты, стартапы и разработчики ПО, связанные со многими сферами производства. «Нашими клиентами являются три из десятка лучших немецких компаний в сфере логистики, сельского хозяйства и розничной торговли», — добавляет Руиллар.
Типичным примером использования в сельском хозяйстве является обучение ИИ-модели для распознавания растений, вредителей и заболеваний. В логистике модель можно использовать для обучения машин автоматической сортировке посылок по типу. Также, по словам Руиллара, Hasty используется в сфере спорта, обеспечивая анализ игры в реальном времени и статистику для футбольных трансляций.
Имея 3,7 миллиона долларов в банке, компания планирует ускорить разработку продукта и расширить свою клиентскую базу в Европе и Северной Америке.