

Разберём как при помощи VictoriaMetrics замониторить kubernetes. Откуда собирать метрики и как автоматически обнаруживать новые цели. Черная магия релейблинга и как она работает. Аннотации для мониторинга приложений и что делать когда их гибкости не хватает

Всем привет! Меня зовут Николай Храмчихин. Я работаю разработчиком в компании VictoriaMetrics.
VistoriaMetrics – это быстрая и простая в установке база данных временных рядов с открытым исходным кодом

Сегодня я расскажу:
-
О сборе метрик из Kubernetes,
-
О том, как это устроено у нас изнутри,
-
И о том, как это можно использовать вам.

Есть небольшие requirements для базового знания Kubernetes. Я на слайде привел картинку из официальной документации.
Что такое Kubernetes в двух словах? Kubernetes – это открытое программное обеспечение для автоматизации развертывания, масштабирования и управления контейнеризированными приложениями.
Он состоит из рабочих уpлов – worker nodes, на которых запускаются пользовательские приложения и Kubernetes Control Plane, который отвечает за работу кластера.

Что там можно мониторить? В первую очередь это сам Kubernetes Control Plane. Центральным его узлом является API-сервер, который хранит свое состояние в базе данных etcd. И к нему подключаются разнообразные системные компоненты. Это Controller Manager, Kebelet, Scheduler и прочее.

Для мониторинга рабочих узлов решения из коробки нет. Kubernetes предоставляет базовую информацию о том, сколько там приложение запрашивает оперативной памяти и CPU, но это не отражает реальную ситуацию. Поэтому самым популярным решением для сбора данных метрик является запуск node-exporter на каждом из worker nodes, который предоставляет эту информацию, собирая ее с самого сервера. Это использование CPU, памяти и прочих разнообразных параметров.
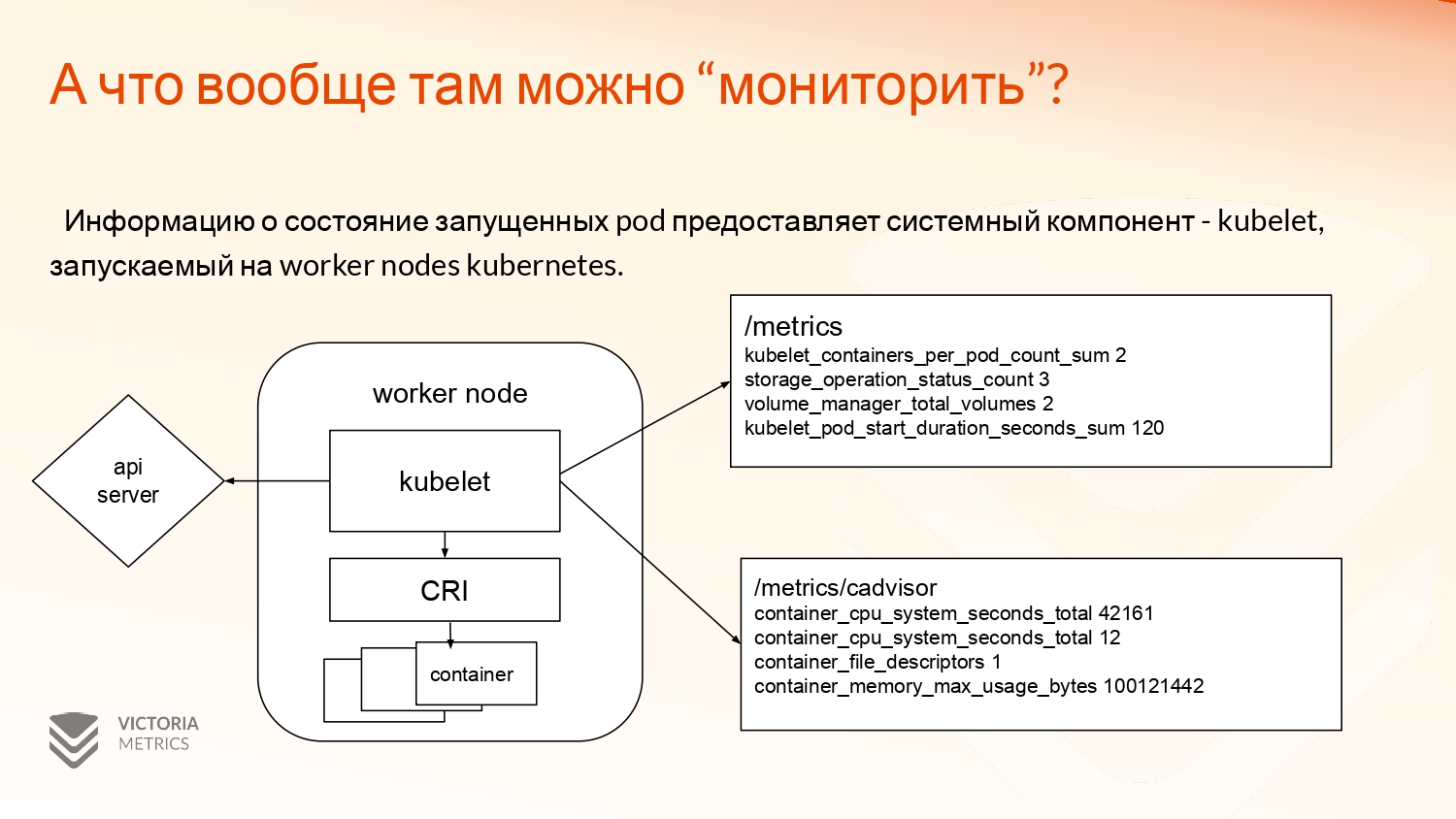
Достаточно важным системным компонентом в Kubernetes Control Plane является Kubelet, который запускается на каждом сервере. Он является связующим звеном между API-сервером и Container Runtime Interface, такими как Docker, Podman. Их сейчас достаточно много появилось. А Container Runtime Interface запускает уже сами контейнеры.
Интересны метрики, которые предоставляет Kubelet находятся на двух API.
-
Это /metrics, который показывает информацию о взаимодействии с API-сервером, разнообразно примонтированных volumes к этому серверу.
-
И /metrics/cadvisor, который предоставляет информацию непосредственно по самим контейнерам, т. е. сколько они используют CPU, оперативной памяти в файловой системе, в сетевой системе.
И конечно это сами пользовательские приложения, которые запускаются в кластере Kubernetes. Их тоже можно и нужно мониторить.

Я буду рассматривать сбор метрик с приложений, экспортирующих сами метрики в prometheus text формате.
В этом случае приложение запускает у себя web-сервер, один из endpoint’ов, который отдает эти метрики. А коллектор приходит к этому приложению и http-запросом их забирает.
В control-plane Kubernetes все компоненты отдают метрики в prometheus text формате.

И с помощью VictoriaMetrics Single версии, которая при помощи конфигурационного файла, задаваемым флагом --promscrape.config, будет это собирать.
Но приведенная информация справедлива не только для VictoriaMetrics, но и для vmagent и Prometheus, с которым VictoriaMetrics совместима, можно использовать один и тот же конфигурационный файл.

Небольшой пример. Важная секция – это scrape_configs, в котором описывается каждая из параметров jobs, которые будут забирать эти метрики.
Можно использовать как статичные configs, которые никогда не поменяются, просто задать IP-адрес хоста или его DNS-имя.
Также можно использовать Service Discovery Configs, которые будут динамически получать метрики из Kubernetes и как-то взаимодействовать с этими всеми объектами.

Нужен ли Service Discovery или нет? По идее самым простым способом сбора метрик из Kubernetes – это просто перечислить все нужные targets через static_configs. Это, в принципе, даже будет работать. Вы не каждый день добавляете новый API-сервер или удаляете старый. И в целом адреса для Controller Managers достаточно статичны. А у серверов можно руками поправить, если что.

Но для пользовательских приложений это не работает. Если мы пытаемся описать каждое наше приложение через вычисления его IP-адреса и порта, откуда нужно забирать метрики, то у нас это не очень сильно получится, потому что приложения обновляются. Они могут меняться, и нам нужно будет каждый раз обновлять конфигурационный файл. Это не очень удобно. А на больших объемах это даже может быть невозможно.

Поэтому нам пригодится Service Discovery, который решает эту задачу, автоматически обнаруживая изменения в Kubernetes. Он запускает и останавливает сбор метрик с targets.

Как это происходит. VictoriaMetrics использует Kubernetes watch API, подписываясь на изменение объектов в API Kubernetes и как-то на это реагирует.

Например, если мы подписываемся на изменение подов.
Под – это, наверное, самая маленькая единица API в Kubernetes, которая объединяет несколько контейнеров.
На примере у нас под с именем app-1. Он в каком-то namespace, там есть какие-то labels. И него есть один 80 порт.
После того, как VictoriaMetrics получает ответ от Kubernetes API, она преобразует полученную сущность, в данном случае под, в специальный список labels вида _meta_kubernetes с какими-то параметрами. Например, _meta_kubernetes_pod_name: app-1. Это имя пода. А label из metadata env будет в _meta_kubernetes_pod_label_env: dev с каким-то значением.
И также присутствует специальный label address, куда записывается ip пода и, соответственно, контейнер порт, с которого собирать метрики.

Каждый обнаруженный элемент из списка labels проходит через фазу relabeling, где к нему применяются специальные правила. Например, базовое использование relabeling config.

Что такое Relabeling, что это за магия? В интернете часто можно встретить гигантские relabeling_configs и как они работают не всегда понятно.
Relabel_cjonfigs – это набор правил, позволяющий выполнять различные операции над labels и их значениями. Каждое из правил выполняется последовательно и зависит от результатов предыдущего.

Что там доступно? Доступная секция – это source_labels, т. е. те labels, над какими нужно проводить операции. Может быть не одна, а несколько labels.
Есть action, который надо выполнить.
Modulus – это специальный модуль для action hashmod. Но он редко используется. Используется в основном для масштабирования и кластеризации собираемых целей.
Regex – это регулярное выражение, по которым должен происходить matching. Возможно использование группы захвата. Например, как здесь. И можно использовать в replacement в специальном поле, где можно поменять значение label.
Separator – это разделитель, потому что для большинства actions, при использовании несколько source_labels они конкатенируются в одну строку с заданным separator’ом. Разделитель по умолчанию – это точка с запятой.
Target_label – это название того label, куда нужно записать результат action.

Какие нам доступны actions? Они делятся на две группы.
- Это actions, которые есть в VM и Prometheus:
-
Replace,
-
Keep,
-
Drop,
-
Labelmap,
-
Labelkeep,
-
Labeldrop,
-
Hashmod.
- И actions, которые есть исключительно в VM. Они немного расширяют функционал и делают его более удобным. Например, keep_if_equal. Я покажу дальше, как можно его использовать на примере match по порту.

Relabeling-правила можно использовать для:
-
Фильтрации обнаружения targets,
-
Изменения названия labels,
-
Изменения значения labels,
-
Добавления новых labels,
-
Удаления ненужных labels.

Пара простых примеров, как можно использовать relabel_configs.
Мы можем оставить из всех обнаруженных под в кластере Kubernetes только те, которые находятся в namespace default. Для этого мы используем sourcelabels: [ _meta_kubernetes_pod_namespace]. В action мы используем keep – это значит, что нужно отфильтровать только те, которые попадают под нужные нам условия. И в регулярном выражении namespace default.

Также можно обогатить все метрики, которые мы собираем с самого приложения, полезной информацией. Например, из label пода можно достать окружение, в котором он запущен и, например, namespace, в котором он запускается. Для этого нужно использовать source_labels и target_label, куда нужно это написать.

Более подробно ознакомиться с тем, как работает relabeling и на хороших примерах, можно по ссылочке: https://medium.com/@valyaya/cs-8b90fc22c4b2.

Вернемся к Service Discovery. После фазы relabeling, все labels с прификсом __ meta отбрасываются.
Это нужно для того, чтобы снизить нагрузку на базу данных и уменьшить объем информации, которую нужно хранить. Kubernetes экспортирует достаточно большой объем metadata. И если записывать все, то будет 40-60 labels на 1 deploy, что достаточно много. И в 90 % случаев вы их никогда не будете использовать.
Оставить нужные вам labels можно во время relabeling, убрав у них префикс или поменяв на имя, нужное вам.

Какие можно выбирать объекты из API Kubernetes? Они определяются специальной настройкой role.
Это может быть:
-
Pod,
-
Service,
-
Endpoints,
-
Endpointslice,
-
Node,
-
Ingress.
В зависимости от role, VM подписывается на изменение разных объектов и возвращает разные labels.
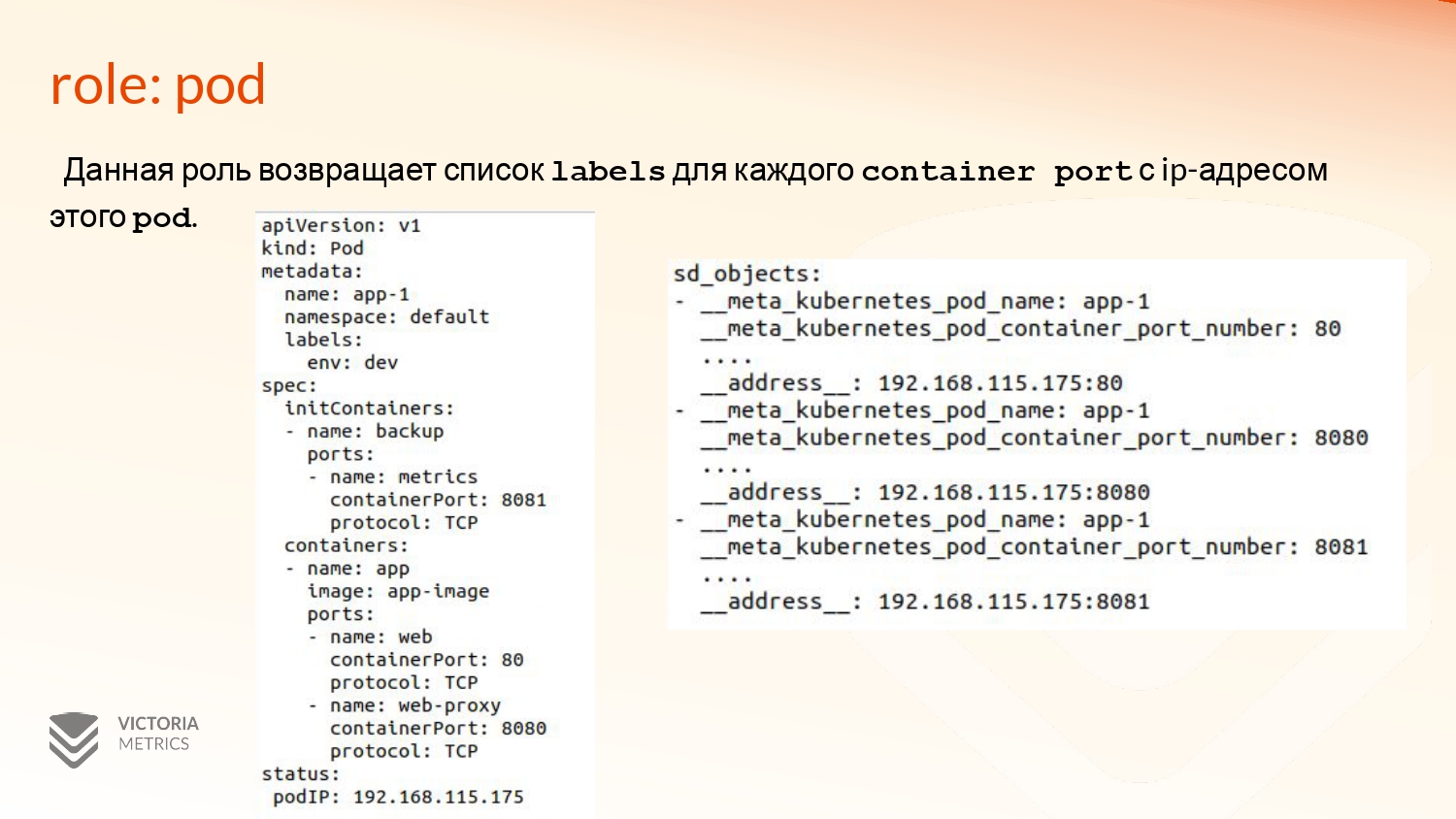
Давайте рассмотрим, какие role что возвращают.
Первая из них – это pod, которую мы видим на примере. Она возвращает список с элементами labels для каждого container port с ip-адресом этого пода.
На примере есть некий под, у которого 3 порта, один из которых находится в initContainer. И в статусе находится его ip-адрес.
Соответственно, VM на relabeling 3 элемента в списке с ip-адресом этого контейнера и с каждым из портов. Там дополнительная мета-информация из metadata и еще некоторая другая будет.

Role: service тоже достаточно простой. Он подписывается на изменения сервиса. И для каждого из портов этого сервиса создает label c мета-датой сервиса и адресом. Это доменное имя данного сервиса в формате: имя сервиса.namespace.svc и номер порта в порт секции.
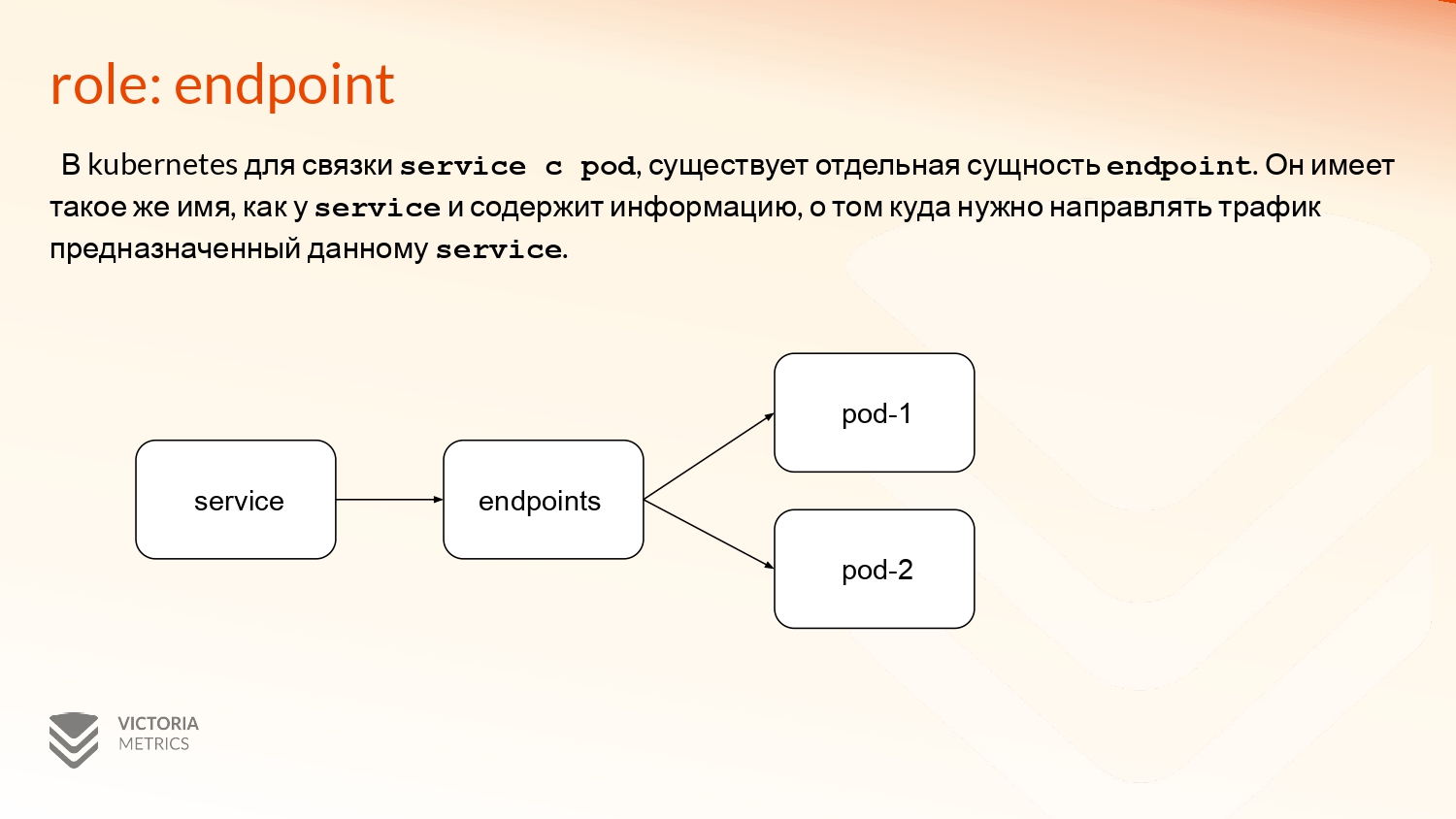
Далее идет достаточно интересный role: endpoint. Здесь нужно небольшое дать объяснение, что такое endpoint, потому что обычно руками их никто не создает.
Это специальная сущность в API Kubernetes, которая нужна для связи сервисов и подов. Она отображает состояние подов, насколько они работоспособны, а также позволяет направлять трафик только на работоспособные поды.

Для Service Discovery это одна из интересных самых ролей, потому что здесь не одна сущность, как было в предыдущих ролях, а целых три, которые нужно отслеживать и обогащать.
Это service. Здесь есть его definition, endpoints и сам непосредственно под.
В приведенном примере на сервисе только один порт заэксплужен, это 8429. Соответственно, в endpoint’е он тоже один, а в контейнере два порта.

И это преобразуется в список labels с двумя элементами. Здесь используется не только тот порт, который есть в endpoints, service, но и порт контейнера дополнительный 2003, который нигде не был указан, но у него не будет мета-информации по endpoint.

Endpointslice – это оптимизированная версия endpoints с точки зрения Kubernetes API. Технически она никак не отличается от endpoints, только там меняются названия префиксов для labels с meta_kubernetes_endpoint на meta_kubernetes_endpointslice.
Какие могут быть подводные камни не использования endpoint? Если у вас очень много endpoints, по-моему, больше 1 000, то Kubernetes их обрезает. Соответственно, вы не получите часть endpoints. Насколько я знаю, в следующей версии VM будет логировать данное сообщение с WARN ошибкой, если такое случается.

Следующая роль – это node. Соответственно, worker node в Kubernetes, для которой используется в качестве адреса первый ip-адрес worker node. В нашем случае – это InternalIP. И порт Kubelet, который указан в описании этой ноды. И дополнительная metadata-информация тоже добавляется. Это annotations: some-annotation: value labels. Ее можно использовать.

Наверное, самая мало встречаемая роль – это ingresses. Она в основном нужна для мониторинга. Я много видел примеров с Blackbox Exporter, который мониторил состояние ingresses через Service Discovery.
И она возвращает комбинацию из хостов в rules с каждым из их путей. Соответственно, в адресе остается только host name, а сам path записывается в специальную _ _meta_kubernetes_ingress_path, как видно на примере.

Полное описание для каждой роли и о том, какие labels она возвращает, можно найти на сайте Prometheus.io. Там достаточно хорошая документация на этот счет и много примеров того, что возвращается.

Service Discovery возвращает все поды, но нам не обязательно собирать с них метрики, а, может, они их и не отдают.
Самым популярным решением для фильтрации данных подов является добавление специальной аннотации Prometheus.io/scrape: “true” в metadata.annotations объекта. В данном случае это в template пода в deployment указывается, что нужно собирать метрики.

Магическим образом это не работает. Kubernetes не знает про это ничего, поэтому нужно использовать специальный конфигурационный файл для scraping, в котором можно фильтровать по мета-информации из annotation. Мы используем _ _meta_kubernetes_pod_annotation_prometheus_io_scrape с regex: true.

Дополняют эту аннотацию две другие аннотации. Это prometheus.io/port с номером порта, который нужно использовать для scraping. И prometheus.io/path, откуда эти метрики нужно забирать.
Данные аннотации удобно использовать для сбора метрик только с определенных портов в поде и с определенных путей, если нам нужно что-то переназначить.
Соответственно, в приведенном relabeling_config используются матчи, только если они не пустые.

Самым большим недостатком при использовании обнаружения и фильтрации через annotations является то, что мы не можем использовать сбор для нескольких портов в контейнере, например, как в примере.
Если мы будем использовать эту аннотацию, то будут собираться метрики с трех портов, хотя initContainer уже не работает. И будет возвращаться ошибка.

К сожалению, prometheus.io/port тоже не сильно здесь поможет, потому что он будет фильтровать только по одному порту, а с другого мы уже данные получать не можем. В Prometheus есть интересный issues по этому поводу. К сожалению, здесь у меня ссылочки нет.

Как это можно решить? Можно использовать кастомные аннотации, т. е. создать prometheus.io/scrape: “true”, который будет собирать все метрики только с контейнеров, у которых один порт экспортирует метрики и отдельную config-секцию, которая будет по другой аннотации собирать либо с нескольких портов по их номерам, либо со всех, которые доступны. Это может быть не совсем удобно.

А можно создать под каждое приложение в конфигурационном файле отдельную секцию с именем этого приложения, с фильтрацией по какому-то из его labels для имени. И, соответственно, с указанием того порта, откуда нужно собирать метрики.
В примере используется endpoints, соответственно, с endpoints, на который экспортирует сервис.

Как можно решить еще? VictoriaMetrics operator – это последний подход. Он автоматизирует процесс генерации таких конфигурационных файлов для ваших приложений и дописывает нужные relabeling-правила, обогащая мета-информацией метрики с собираемого приложения. Ссылочка на него здесь есть.

Как он работает? Он использует Custom Resource Definitions. Это специальные объекты, расширяющие API Kubernetes через Custom Resource. И уже нужно описывать мониторинг в самом приложении через этот Custom Resource, и у вас все будет работать.

Набор кастомных ресурсов достаточно большой. В документации можно ознакомиться со всеми. Сегодня я расскажу кратко о VMPodScrape, который поможет нам решить проблему мониторинга нескольких портов приложения.

И посмотрим, как это можно сделать.
Слева пример deployment, который описывает состояние самого приложения с именованием портов.
Справа пример VMPodScrape, который позволяет также в YAML-формате описать то, откуда мы будем забирать метрики. Соответственно, здесь у нас есть два порта: http и backup-metrics.

В результате у нас будет сгенерировано две секции scrape в конфигурационном файле, который будет выполнять matching по source_labels с названием того, который есть в deployments, и с именем порта, который указан в самом приложении.

Это только один из примеров использования VMPodScrape. Он также позволяет гибко настроить мониторинг приложения и делегировать эту конфигурацию владельцу приложения.
Таким образом можно построить Git-ops-подход для мониторинга.
Единственное, этот конфигурационный файл генерируется только для VMagent, который управляется оператором. Это нужно знать, это одно из ограничений.

Сегодня мы узнали:
-
Основные цели, с которых можно собирать метрики в Kubernetes.
-
Что такое Service Discovery.
-
Какие проблемы решает relabeling_congig.
-
Как они работают, что для них доступно и как их использовать.
-
Про аннотацию prometheus.io/scrape – ее плюсы и минусы.
-
И кратко рассказал про VM operator, о том, как можно декларативно описывать мониторинг приложения.

Всем, спасибо! Ваши вопросы.
Спасибо большое! Как грамотно интегрировать мониторинг Kubernetes, например, с Service Management, либо с Service Desk для того, чтобы заводить тикеты на те или иные события, в том числе нас интересует мониторинг самого Kubernetes и также master nodes? Вы очень подробно нам рассказали о подах, а как мониторить master nodes и сам Kubernetes как инфраструктуру, чтобы заводить тикеты?
Как я вижу, здесь есть две части. Первая – это та, которая непосредственно собирает метрики. Вторая часть – это та, которая с ними взаимодействует. Под мониторингом этих метрик я подразумеваю какие-то правила, которые выполняются, т. е. насколько этот API-сервер жив или нет.
В экосистеме VM есть vmalert, который выполняет эти правила. И результат он отправляет в Alertmanager. У Alertmanager уже есть достаточно много интеграций, куда дальше передавать эти события, где их можно визуализировать и как ими можно управлять.
Лично я пробовал комбинацию из Alertmanager и alerta, где можно уже assign (назначать) все эти события, нездоровости API-сервера и как-то с ними уже взаимодействовать.
Мы можем интегрировать, например, метрики и события в Zabbix? Либо, к примеру, в Аксиусе напрямую? Kubernetes очень мониторится Prometheus’ом. Можно ли какую-нибудь использовать связку, чтобы эти события продублировать в Zabbix для того, чтобы удобнее было заводить заявки, например, в Аксиусе?
Я понял вопрос. Насколько я знаю, есть проект Glaber. Это практически Zabbix, только лучше. И он дает возможность получать различные бэкенды для хранения и можно интегрировать в VM через Glager для мониторинга.
Понял, большое спасибо!
Привет! Спасибо за доклад! У меня, может быть, вопрос не совсем по теме доклада, но все-таки задам. Какие планы у VM по downsampling?
Я ждал этого вопроса. Спасибо большое! Нам его очень часто задают. Мы над ним работаем. Я надеюсь, сделаем его в каком-то виде к концу года. Пока более точных сроков у меня нет.
Когда появится web-интерфейсы у ваших продуктов?
Он уже есть. Вы можете ознакомиться с документацией. Там есть Web UI. Он достаточно красивым в последнем релизе стал. Там можно скролить, листать, визуализировать метрики. И даже у VMalert появился отдельный UI. Мы над этим работаем, они развиваются.
Здравствуйте! Спасибо за доклад! Как у вас дела обстоят с OpenShift? Есть у вас с ним интеграция?
Лично я тестировал интеграцию с OpenShift при помощи оператора deployment. И он из коробки понимает все то, что генерирует OpenShift и можно это все мониторить, использовать. Насчет визуализации через графический интерфейс OpenShift – я не в курсе. Я не смотрел, но было бы достаточно интересно.
Расскажи, как Виктория падает? Какие есть самые яркие, запоминающиеся кейсы?
В основном пример, когда падает и плохо работает, это кластерная версия. Когда выходит из строя одна из storage node и кластер сильно утилизирован, то он какое-то время может не справляться с нагрузкой, потому что нужно зарегистрировать временные ряды на других storage nodes. Такое бывает, мы с этим работаем. Надеюсь, что все в будущем будет хорошо.
P.S. Чат по VictoriaMetrics https://t.me/VictoriaMetrics_ru1
Немного рекламы: На платформе https://rotoro.cloud/ вы можете найти курсы с практическими занятиями:
Комментарии (4)

dlazerka
01.11.2021 19:55После того, как VictoriaMetrics получает ответ от Kubernetes API, она преобразует полученную сущность, в данном случае под, в специальный список labels вида _meta_kubernetes с какими-то параметрами.
Так а где узнать список всех доступных
_meta_*лейблов?

valyala
02.11.2021 12:45+1Когда выходит из строя одна из storage node и кластер сильно утилизирован, то он какое-то время может не справляться с нагрузкой, потому что нужно зарегистрировать временные ряды на других storage nodes. Такое бывает, мы с этим работаем. Надеюсь, что все в будущем будет хорошо.
Эта проблема бывает только при условии, если в кластере недостаточно свободных ресурсов для быстрой регистрации новых временных рядов, "переехавших" с вышедшей из строя storage node на оставшиеся в живых storage nodes. Поэтому, чтобы избежать этой проблемы, нужно оставить в кластере достаточно свободных ресурсов (CPU, RAM). См. https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#capacity-planning
Nastradamus
Спасибо за статью! Отлично подходит как справочник-напоминалка и для тех, кто это уже всё настраивал :)