
Всем доброго времени суток! В этой статье я собираюсь приоткрыть дверь в мир тестирования систем хранения данных и связанных с ним особенностей. А начну разговор с недостижимой цели любого проекта с точки зрения QA: «Мы хотим протестировать всё и как можно быстрее, желательно ещё до того, как код написан».
Сегодня на примере молодого проекта Dell Technologies под названием PowerStore я попытаюсь рассказать, каким путём мы шли к достижению второй части этой цели, ведь всем доподлинно известно, что протестировать абсолютно всё невозможно, однако шанс ускорить процесс есть почти всегда.

Итак, на заре проекта наш обычный рабочий цикл выглядел следующим образом:

Продолжительность цикла в три месяца — это не шутка и не опечатка, а суровая реальность в мире тестирования СХД. Среднее время прогона одного нашего теста — восемь часов, и сократить его крайне сложно. Мы стараемся держать наши тесты максимально приближёнными к реальным «боевым условиям», поэтому для их прохождения сначала формируем кластер с подключёнными к нему серверами нагрузки, создаём на нём какую-то инфраструктуру, предзаполняем данными и только после этого запускаем тестовые шаги: например, вызываем падение ноды, останавливаем какой-нибудь из процессов, целиком контейнер или отключаем питание полностью всего апплаенса. Наша цель — «сломать» систему, но так как СХД позиционируется как отказоустойчивая, она должна сама привести себя в рабочее состояние — и на всё это требуется время.
Теперь вы получили немного контекста, и мы можем перейти к сути статьи.
В крупных legacy-проектах процессы обычно монолитно устаканены и редко поддаются изменениям. Однако молодые проекты, и PowerStore в частности, более гибкие. Это и позволило нам осуществить задуманное — сократить время выполнения всего цикла тестирования примерно в 12 раз. Сразу возникает вопрос, за счёт чего гипотетически можно этого добиться. Ответ обычно сводится к сферически вакуумным оптимизациям разного рода, чаще всего затрагивающим менеджмент процессов и ресурсов либо апгрейд используемых инструментов. Именно отсюда начался наш долгий путь к цели.
Начнём с менеджмента ресурсов. Если подытожить грубо, то ресурсов обычно имеется четыре вида:
Вопросы времени и команды мы оставим за скобками. Сосредоточимся на оставшихся двух типах — аппаратных ресурсах (серверы для нагрузки и сами СХД) и программных ресурсах (OS на серверах, IP-адреса и т. д.). Простые способы их менеджмента, такие как расшаренная страница на Сonfluence или файл с общим доступом, перестали эффективно работать почти сразу. Поэтому для упрощения нашей жизни и оптимизации процессов были построены три системы, которые позволяли наилучшим образом использовать наши ресурсы в лаборатории. Три наших кита — это Xpool, LabJungle и SWARM.
LabJungle — это база данных, в которой хранится информация обо всех аппаратных атрибутах наших систем, будь то количество нод у кластера, наличие дополнительной полки с дисками, все серийники и т. д.

В SWARM хранится вся информация об окружении: подключённые серверы нагрузки, имена использованных для подключения свитчей, логины, явки и пароли, все IP-адреса кластера — то есть всё, что способно упростить жизнь инженеру при создании окружения. Связка апплаенса и его IP-адресов — это важнейшая функция SWARM, так как эти адреса в дальнейшем используются для автоматической установки и тестирования.
Также у консольной версии инструмента есть дополнительные возможности — логиниться и исполнять скрипты непосредственно на нужных компонентах кластера без дополнительных действий. Так как SWARM знает все IP-адреса, то эту функциональность добавить в него было легче лёгкого.
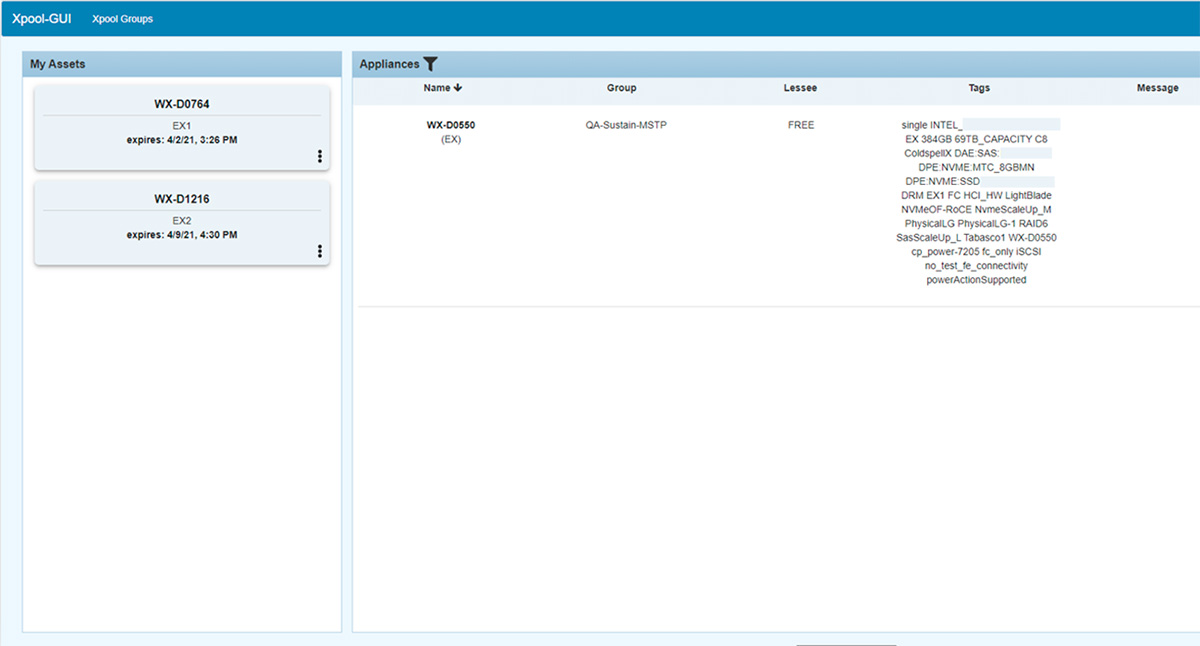
Xpool — система резервирования и оркестрации ресурсов между командами и инженерами. Именно с этим инструментом чаще всего имеют дело члены любой команды, так как в нём с помощью тегов можно найти необходимую систему и зарезервировать её на себя на определённое время. С его же помощью можно автоматически запустить деплой этой системы с помощью одной команды и получить на выходе готовую для тестирования СХД с накаченным на нее билдом. После завершения работы или времени резервирования окружение уходит обратно в свободный пул.
LabJungle существовал ещё до PowerStore, так как он жизненно необходим администраторам лабораторий, а вот SWARM и Xpool были написаны нашими разработчиками и тестировщиками соответственно. Все три инструмента тесно взаимосвязаны, и кластеры постоянно ими мониторятся, чтобы поддерживать информацию в базах в актуальном состоянии. Также они синхронизированы, поскольку данные в них частично пересекаются. Возникает логичный вопрос: зачем было тратить столько времени и ресурсов на создание инструментов для менеджмента ресурсов (no pun intended)?
Помимо специфики тестирования СХД, которую мы уже вкратце упомянули, есть ещё специфика самого проекта. На сегодня в проекте работает более 200 QA-инженеров. Наши команды находятся в разных странах и в разных часовых поясах — от Тихоокеанского побережья США до Азии, — а это до 15 часов разницы во времени. Инженеры работают с 1000+ СХД в четырёх тестовых лабораториях, которые также разбросаны по миру, чтобы командам было удобно ими пользоваться. В самом начале, когда команда была небольшая, мы использовали общую страничку на Confluence, и в принципе этого было достаточно. Но как только команда разрослась, выросли аппетиты на ресурсы, и первоначальная система перестала работать.
Процесс тестирования после внедрения проходил так: описание всех наших кластеров находится в LabJungle и SWARM, они мониторятся (как мы рассказывали ранее) и готовы к установке. И вот наш инженер сначала идёт в тест-менеджмент систему и ищет там тесты, прикреплённые к текущему циклу, за которые он отвечает. Далее он ищет кластер уже в Xpool, используя теги и фильтры, и отправляет кластер на установку и настройку через всё тот же Xpool. При этом необходимые IP-адреса и ресурсы окружения автоматически подтягиваются из SWARM. Проделав всё это, инженер идёт в тестовый фреймворк, ищет нужный тест, запускает его — и после выполнения теста кластер отпускается в свободный пул ресурсов.
Всё ещё звучит не очень удобно, правда? Нам тоже так показалось, потому мы на этом не остановились. Рабочий процесс всё ещё требовал много ручных действий и включал много мест, где можно ошибиться. А учитывая продолжительность тестов, ошибка при запуске стоила нескольких часов простоя, если её не заметили вовремя. С этим нужно было что-то делать.
Также осталась ещё одна большая проблема, наш elephant in the room. Это уникальные конфигурации железа, имеющие специфические параметры, необходимые для конкретных тестов. Они — «золотой ресурс»: таких в лаборатории считанное количество и их всегда сложно найти.
Да, мониторинг оборудования стал автоматизированным, но влияние человеческого фактора хоть и уменьшилось, но всё равно постоянно вызывало нехватку уникальных конфигураций. Менеджерам всё так же требовался прозрачный мониторинг выполнения цикла, уменьшение времени простоев и чтобы всё проходило быстрее, а инженеры хотели меньше рутинной и больше интересной работы.
Дальнейшим шагом оптимизации был выбран Jenkins: в частности, мы рассматривали вариант использования Matrix Plugin либо Pipeline. Ещё одним вариантом было написать что-то своё, как это мы сделали уже трижды. Забегая вперёд, скажу, что нам пришлось совместить оба варианта.
Matrix Plugin позволял прогонять много тестов параллельно, использовать сразу много кластеров и централизованно всем этим управлять. С его помощью можно было гибко задавать параметры для тестов, плюс он прекрасно интегрировался с тремя предыдущими утилитами. Но в каждой бочке мёда есть ложка дёгтя. В нашем случае ею стало то, что несколько тестов параллельно можно было выполнять только из одной области. Было очень сложно гибко распределить параметры в Jenkins job (далее джоба), чтобы всё сразу заработало, и в итоге приходилось запускать много инстансов одной джобы для тех или иных тестов.
Pipeline позволял выполнять множество тестов на одном кластере, что позволяло проводить полное тестирование области. Но этот вариант тоже имел свои ограничения:
Если команда занимается исключительно одной областью продукта или одной фичей, то для неё Pipeline подходит идеально, но если в задаче инженера пересекаются несколько областей, то Pipeline, наоборот, привносит дополнительный оверхед и усложняет работу.
В итоге мы выбрали Matrix Plugin как более универсальный вариант — и почти сразу после внедрения столкнулись с тем, что джобы в Jenkins превратились в «зоопарк». Каждая команда — да что там, каждый инженер внутри команды — создавали их как хотели, набивая джобу параметрами в произвольном порядке. А скрипт сборки внутри джоб вообще хотелось посадить в отдельный вольер на заднем дворе подальше от глаз. В итоге, чтобы запустить джобу, созданную коллегой, нужно было посильнее натянуть на себя шапочку из фольги, вооружиться магическим шаром и запастись терпением: миссию сделать всё правильно с первого раза даже Том Круз бы не выполнил.
Тогда на свет появился документ Jenkins Job Standard с чёткой структурой джоб в проекте. Сами джобы было решено разбить по областям тестирования. Чтобы было проще ориентироваться, мы использовали те же области, что и в системе тест-менеджмента. Опции теста, как мы уже успели понять, отличались в зависимости от области тестирования, но далеко не все они были уникальными. Поэтому (пройдясь по гораздо большему числу джоб, чем хотелось бы) мы прописали «параметры по умолчанию», которые должны быть в любом тесте, и стали требовать от инженеров, создающих джобы, чтобы у каждого параметра было описание. Нашей целью было, чтобы любой человек из любого проекта знал, что ему нужно в Jenkins-джобе, чтобы запустить её.

Справа — матрица, по одной из осей которой задаётся Test ID, а по другой оси указаны конфигурации кластера. В данном случае это количество устройств, из которых нужно собрать кластер, чтобы в дальнейшем использовать его в тестах.
В итоге мы пришли к следующему процессу:
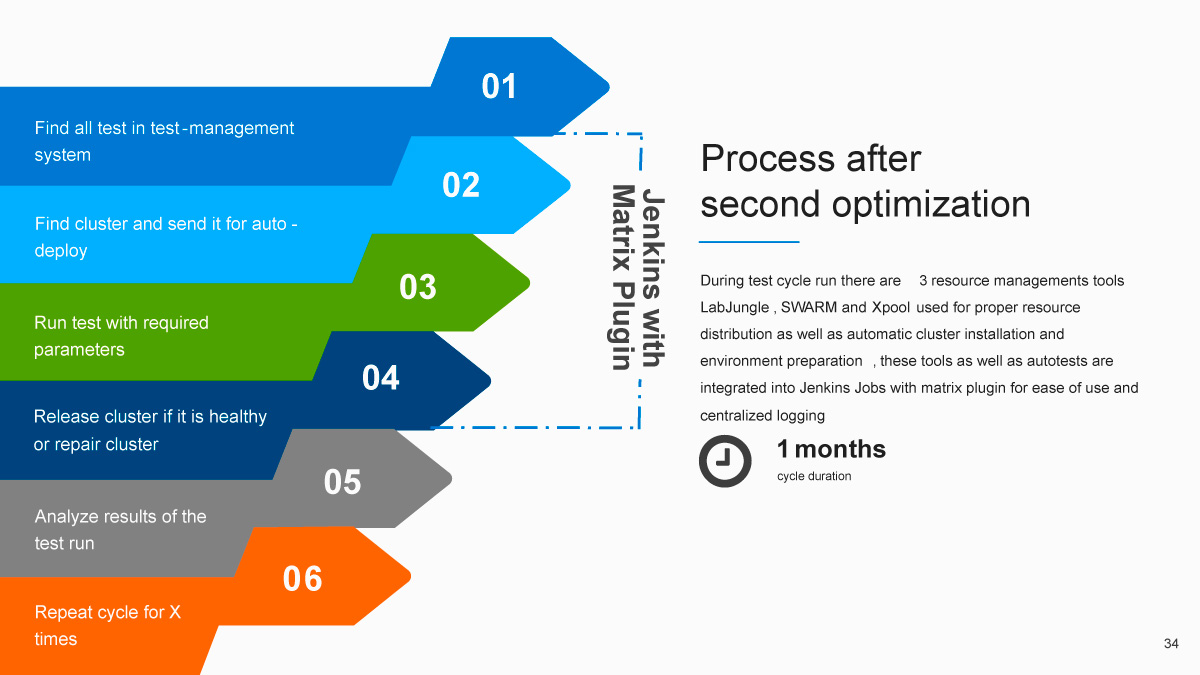
С трёх месяцев до одного — неплохо, правда?
Как же стал выглядеть рабочий процесс для инженера? Первый шаг остался прежним: нужно было найти тесты в тест-менеджмент системе и понять, что требуется запустить. Следующие три шага объединил Jenkins Matrix Plugin: это поиск кластера с соответствующим атрибутом, деплой окружения, поиск и подготовка ресурсов и непосредственно прогон самого теста. Далее инженеру требовалось проанализировать результаты, расшифровать их и зафиксировать. Затем — повторить цикл нужное количество раз. При этом Jenkins автоматически освобождал кластер, если тест проходил успешно, что сильно упрощало процесс.
Изначально внедрение Jenkins дало небольшую оптимизацию, а бОльшую роль сыграла стандартизация джоб. Именно она позволила уменьшить влияние человеческой ошибки, так как «зоопарк» был рассажен по клеткам, убран и снабжён указателями с пояснениями. Иными словами, теперь параметры тестов во всех джобах, да и сами джобы были почти одинаковыми, что максимально снизило порог вхождения для инженеров.
Казалось бы, всё здорово и красиво, но наш elephant in the room был всё ещё с нами. Да, с помощью Jenkins мы полностью автоматизировали подготовку всего окружения, включая Pre-Steps для тестов, и распараллелили тестирование, при этом приобретя централизованное логирование и лёгкое прослеживание истории прогонов теста между тест-менеджмент системой и непосредственно логом самого теста. Вот только мы не вполне учли, что единожды заполучив «золотой ресурс», инженеры не стремятся отпускать его обратно в свободный пул. Потому простои в выполнении тестов, конечно, уменьшились — но, как мы все знаем, «бесконечность — не предел».
Мы всё ещё были убеждены, что можно сделать лучше и решить и эту проблему — ну, или хотя бы сильно снизить её влияние. Из предыдущей части нашего пути мы твёрдо уяснили, что простои случаются там, где вмешивается человеческий фактор. В попытках ещё больше сократить его влияние в наших головах родилась идея «Запускатора». Мы решили создать одну большую красивую кнопку «сделать хорошо», после нажатия которой все ресурсные и тест-операции проходили бы автоматически, а инженеру оставалось только проанализировать результаты и, в традициях Древнего Рима, поднять палец вверх или вниз. Затем следовал автоматический перезапуск тестов, упавших не по причине проблем в продукте, а из-за некорректности теста или проблем с окружением (ведь когда железо долгое время пытаются сломать, оно рано или поздно не выдерживает).
Чтобы достичь желаемого, мы устроили мозговой штурм и составили список требований-«хотелок», чтобы наша жизнь стала ещё проще:
Вот так и появился «Запускатор». Изначальный концепт монолита в итоге превратился в шесть микросервисов. Основу составила база данных со всеми реквизитами и связями с каждым тестом и оборудованием. Для связи с этой базой данных был создан отдельный компонент DB Agent, который занимался организацией работы с ней. Кроме того, за взаимосвязь с Jenkins отвечает компонент под названием Jenkins Agent — он «помнит» о том, какие есть джобы, знает, что запущено в текущий момент, где и что лежит, какова логика взаимосвязи между тестом и джобой, какие нужны параметры, чтобы правильно её запустить. На этом этапе мы ещё больше оценили то, что имеем стандарт для джоб: в противном случае разобраться в сильно разросшемся «зоопарке» было бы в разы сложнее.
Как вы уже могли догадаться, все эти процессы происходили не за один день и даже не за месяц, а релизы при этом никто не отменял. Как и новые фичи, новые тесты и новые джобы.

Три самых важных компонента «Запускатора» — Test Manager, Resource Manager и General Manager. Test Manager отвечает за взаимодействие с системой тест-менеджмента и знает все нюансы и конфигурации тестов, их параметры и особенности. Resource Manager занимается взаимодействием с ресурсной системой, собирает из Xpool всю информацию об имеющихся в распоряжении команды кластерах и помнит, какие ограничения есть при запуске тестов. Управляет же всем этим General Manager, который запускает очереди, указывает, что, кому и когда делать, чтобы всё работало как единый механизм. Написан «Запускатор» был на Python с использованием PostgreSQL и RabbitMQ. Также к нему был прикручен ненагромождённый Web UI на Flask.

Интерфейс инженера-тестировщика с формой старта цикла тестирования.
Итак, мы плавно приближаемся к концу нашего путешествия и дню сегодняшнему. Для запуска всего цикла инженеру нужно убедиться, что у него достаточно свободных кластеров в Xpool, выбрать цикл и нажать на старт. Спустя некоторое время как из рога изобилия начнут сыпаться результаты тестов, и команде останется только проанализировать их. Таким образом, инженеры участвуют в процессе лишь при запуске и разборе результатов — а в остальное время разрабатывают новые тесты и тест-планы либо помогают анализировать проблемы клиентов, чтобы перенять и применить этот опыт в тестировании.
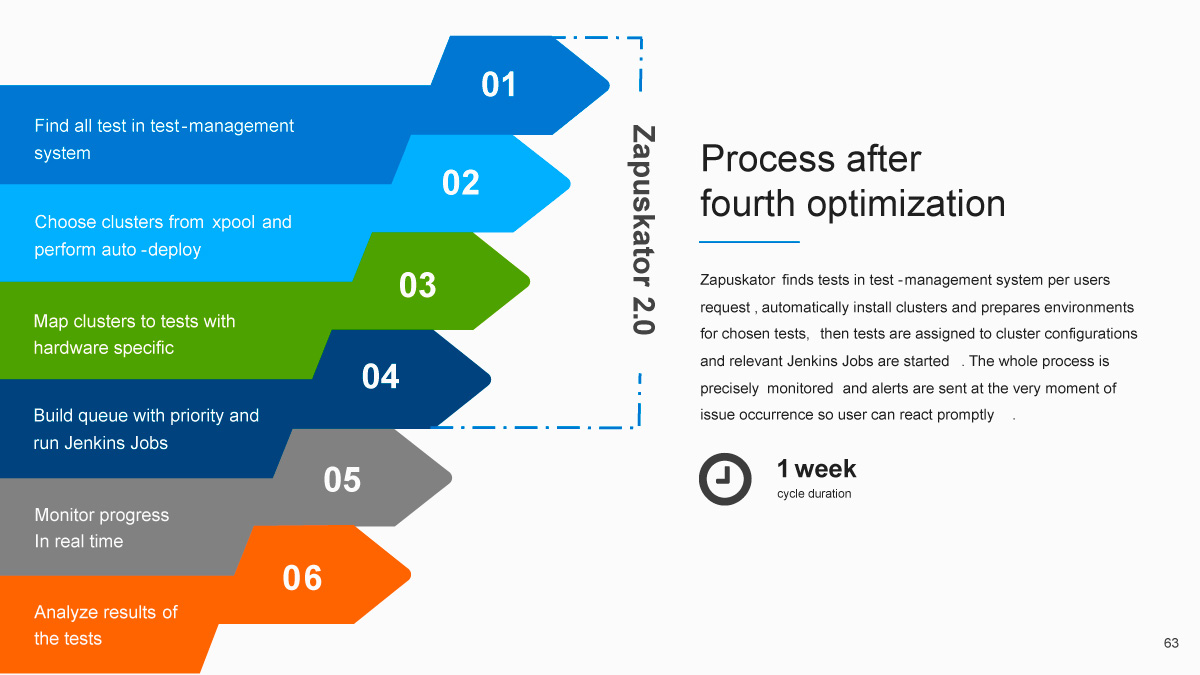
Одна неделя вместо трёх месяцев — вот время, которое теперь занимает прогон всего цикла. Такой результат позволил нам открыть шампанское, чтобы отпраздновать маленькую победу в вечной войне за оптимизацию. Можно ли было что-то сделать по-другому? Конечно, однако набивать шишки приходится всегда, и ничего тут не поделаешь. Мы ни в коем случае не претендуем на истину в первой инстанции, а всего лишь хотим поделиться нашим опытом в довольно специфической области.
Спасибо, что дочитали до конца! Надеемся, что слушать о нашем путешествии вам было столь же интересно, как нам — рассказывать.
Сегодня на примере молодого проекта Dell Technologies под названием PowerStore я попытаюсь рассказать, каким путём мы шли к достижению второй части этой цели, ведь всем доподлинно известно, что протестировать абсолютно всё невозможно, однако шанс ускорить процесс есть почти всегда.
Введение в контекст
Итак, на заре проекта наш обычный рабочий цикл выглядел следующим образом:
Продолжительность цикла в три месяца — это не шутка и не опечатка, а суровая реальность в мире тестирования СХД. Среднее время прогона одного нашего теста — восемь часов, и сократить его крайне сложно. Мы стараемся держать наши тесты максимально приближёнными к реальным «боевым условиям», поэтому для их прохождения сначала формируем кластер с подключёнными к нему серверами нагрузки, создаём на нём какую-то инфраструктуру, предзаполняем данными и только после этого запускаем тестовые шаги: например, вызываем падение ноды, останавливаем какой-нибудь из процессов, целиком контейнер или отключаем питание полностью всего апплаенса. Наша цель — «сломать» систему, но так как СХД позиционируется как отказоустойчивая, она должна сама привести себя в рабочее состояние — и на всё это требуется время.
Теперь вы получили немного контекста, и мы можем перейти к сути статьи.
Начало путешествия: Xpool, LabJungle и SWARM
В крупных legacy-проектах процессы обычно монолитно устаканены и редко поддаются изменениям. Однако молодые проекты, и PowerStore в частности, более гибкие. Это и позволило нам осуществить задуманное — сократить время выполнения всего цикла тестирования примерно в 12 раз. Сразу возникает вопрос, за счёт чего гипотетически можно этого добиться. Ответ обычно сводится к сферически вакуумным оптимизациям разного рода, чаще всего затрагивающим менеджмент процессов и ресурсов либо апгрейд используемых инструментов. Именно отсюда начался наш долгий путь к цели.
Начнём с менеджмента ресурсов. Если подытожить грубо, то ресурсов обычно имеется четыре вида:
- аппаратные;
- программные;
- время;
- команда.
Вопросы времени и команды мы оставим за скобками. Сосредоточимся на оставшихся двух типах — аппаратных ресурсах (серверы для нагрузки и сами СХД) и программных ресурсах (OS на серверах, IP-адреса и т. д.). Простые способы их менеджмента, такие как расшаренная страница на Сonfluence или файл с общим доступом, перестали эффективно работать почти сразу. Поэтому для упрощения нашей жизни и оптимизации процессов были построены три системы, которые позволяли наилучшим образом использовать наши ресурсы в лаборатории. Три наших кита — это Xpool, LabJungle и SWARM.
LabJungle — это база данных, в которой хранится информация обо всех аппаратных атрибутах наших систем, будь то количество нод у кластера, наличие дополнительной полки с дисками, все серийники и т. д.
В SWARM хранится вся информация об окружении: подключённые серверы нагрузки, имена использованных для подключения свитчей, логины, явки и пароли, все IP-адреса кластера — то есть всё, что способно упростить жизнь инженеру при создании окружения. Связка апплаенса и его IP-адресов — это важнейшая функция SWARM, так как эти адреса в дальнейшем используются для автоматической установки и тестирования.
Также у консольной версии инструмента есть дополнительные возможности — логиниться и исполнять скрипты непосредственно на нужных компонентах кластера без дополнительных действий. Так как SWARM знает все IP-адреса, то эту функциональность добавить в него было легче лёгкого.
Xpool — система резервирования и оркестрации ресурсов между командами и инженерами. Именно с этим инструментом чаще всего имеют дело члены любой команды, так как в нём с помощью тегов можно найти необходимую систему и зарезервировать её на себя на определённое время. С его же помощью можно автоматически запустить деплой этой системы с помощью одной команды и получить на выходе готовую для тестирования СХД с накаченным на нее билдом. После завершения работы или времени резервирования окружение уходит обратно в свободный пул.
LabJungle существовал ещё до PowerStore, так как он жизненно необходим администраторам лабораторий, а вот SWARM и Xpool были написаны нашими разработчиками и тестировщиками соответственно. Все три инструмента тесно взаимосвязаны, и кластеры постоянно ими мониторятся, чтобы поддерживать информацию в базах в актуальном состоянии. Также они синхронизированы, поскольку данные в них частично пересекаются. Возникает логичный вопрос: зачем было тратить столько времени и ресурсов на создание инструментов для менеджмента ресурсов (no pun intended)?
Помимо специфики тестирования СХД, которую мы уже вкратце упомянули, есть ещё специфика самого проекта. На сегодня в проекте работает более 200 QA-инженеров. Наши команды находятся в разных странах и в разных часовых поясах — от Тихоокеанского побережья США до Азии, — а это до 15 часов разницы во времени. Инженеры работают с 1000+ СХД в четырёх тестовых лабораториях, которые также разбросаны по миру, чтобы командам было удобно ими пользоваться. В самом начале, когда команда была небольшая, мы использовали общую страничку на Confluence, и в принципе этого было достаточно. Но как только команда разрослась, выросли аппетиты на ресурсы, и первоначальная система перестала работать.
Продолжаем оптимизировать: создание Jenkins Job Standard
Процесс тестирования после внедрения проходил так: описание всех наших кластеров находится в LabJungle и SWARM, они мониторятся (как мы рассказывали ранее) и готовы к установке. И вот наш инженер сначала идёт в тест-менеджмент систему и ищет там тесты, прикреплённые к текущему циклу, за которые он отвечает. Далее он ищет кластер уже в Xpool, используя теги и фильтры, и отправляет кластер на установку и настройку через всё тот же Xpool. При этом необходимые IP-адреса и ресурсы окружения автоматически подтягиваются из SWARM. Проделав всё это, инженер идёт в тестовый фреймворк, ищет нужный тест, запускает его — и после выполнения теста кластер отпускается в свободный пул ресурсов.
Всё ещё звучит не очень удобно, правда? Нам тоже так показалось, потому мы на этом не остановились. Рабочий процесс всё ещё требовал много ручных действий и включал много мест, где можно ошибиться. А учитывая продолжительность тестов, ошибка при запуске стоила нескольких часов простоя, если её не заметили вовремя. С этим нужно было что-то делать.
Также осталась ещё одна большая проблема, наш elephant in the room. Это уникальные конфигурации железа, имеющие специфические параметры, необходимые для конкретных тестов. Они — «золотой ресурс»: таких в лаборатории считанное количество и их всегда сложно найти.
Да, мониторинг оборудования стал автоматизированным, но влияние человеческого фактора хоть и уменьшилось, но всё равно постоянно вызывало нехватку уникальных конфигураций. Менеджерам всё так же требовался прозрачный мониторинг выполнения цикла, уменьшение времени простоев и чтобы всё проходило быстрее, а инженеры хотели меньше рутинной и больше интересной работы.
Дальнейшим шагом оптимизации был выбран Jenkins: в частности, мы рассматривали вариант использования Matrix Plugin либо Pipeline. Ещё одним вариантом было написать что-то своё, как это мы сделали уже трижды. Забегая вперёд, скажу, что нам пришлось совместить оба варианта.
Matrix Plugin позволял прогонять много тестов параллельно, использовать сразу много кластеров и централизованно всем этим управлять. С его помощью можно было гибко задавать параметры для тестов, плюс он прекрасно интегрировался с тремя предыдущими утилитами. Но в каждой бочке мёда есть ложка дёгтя. В нашем случае ею стало то, что несколько тестов параллельно можно было выполнять только из одной области. Было очень сложно гибко распределить параметры в Jenkins job (далее джоба), чтобы всё сразу заработало, и в итоге приходилось запускать много инстансов одной джобы для тех или иных тестов.
Pipeline позволял выполнять множество тестов на одном кластере, что позволяло проводить полное тестирование области. Но этот вариант тоже имел свои ограничения:
- строгое следование тестов друг за другом;
- невозможность гибко задавать параметры;
- негибкость конфигурации.
Если команда занимается исключительно одной областью продукта или одной фичей, то для неё Pipeline подходит идеально, но если в задаче инженера пересекаются несколько областей, то Pipeline, наоборот, привносит дополнительный оверхед и усложняет работу.
В итоге мы выбрали Matrix Plugin как более универсальный вариант — и почти сразу после внедрения столкнулись с тем, что джобы в Jenkins превратились в «зоопарк». Каждая команда — да что там, каждый инженер внутри команды — создавали их как хотели, набивая джобу параметрами в произвольном порядке. А скрипт сборки внутри джоб вообще хотелось посадить в отдельный вольер на заднем дворе подальше от глаз. В итоге, чтобы запустить джобу, созданную коллегой, нужно было посильнее натянуть на себя шапочку из фольги, вооружиться магическим шаром и запастись терпением: миссию сделать всё правильно с первого раза даже Том Круз бы не выполнил.
Тогда на свет появился документ Jenkins Job Standard с чёткой структурой джоб в проекте. Сами джобы было решено разбить по областям тестирования. Чтобы было проще ориентироваться, мы использовали те же области, что и в системе тест-менеджмента. Опции теста, как мы уже успели понять, отличались в зависимости от области тестирования, но далеко не все они были уникальными. Поэтому (пройдясь по гораздо большему числу джоб, чем хотелось бы) мы прописали «параметры по умолчанию», которые должны быть в любом тесте, и стали требовать от инженеров, создающих джобы, чтобы у каждого параметра было описание. Нашей целью было, чтобы любой человек из любого проекта знал, что ему нужно в Jenkins-джобе, чтобы запустить её.
Справа — матрица, по одной из осей которой задаётся Test ID, а по другой оси указаны конфигурации кластера. В данном случае это количество устройств, из которых нужно собрать кластер, чтобы в дальнейшем использовать его в тестах.
В итоге мы пришли к следующему процессу:
С трёх месяцев до одного — неплохо, правда?
Как же стал выглядеть рабочий процесс для инженера? Первый шаг остался прежним: нужно было найти тесты в тест-менеджмент системе и понять, что требуется запустить. Следующие три шага объединил Jenkins Matrix Plugin: это поиск кластера с соответствующим атрибутом, деплой окружения, поиск и подготовка ресурсов и непосредственно прогон самого теста. Далее инженеру требовалось проанализировать результаты, расшифровать их и зафиксировать. Затем — повторить цикл нужное количество раз. При этом Jenkins автоматически освобождал кластер, если тест проходил успешно, что сильно упрощало процесс.
Изначально внедрение Jenkins дало небольшую оптимизацию, а бОльшую роль сыграла стандартизация джоб. Именно она позволила уменьшить влияние человеческой ошибки, так как «зоопарк» был рассажен по клеткам, убран и снабжён указателями с пояснениями. Иными словами, теперь параметры тестов во всех джобах, да и сами джобы были почти одинаковыми, что максимально снизило порог вхождения для инженеров.
Казалось бы, всё здорово и красиво, но наш elephant in the room был всё ещё с нами. Да, с помощью Jenkins мы полностью автоматизировали подготовку всего окружения, включая Pre-Steps для тестов, и распараллелили тестирование, при этом приобретя централизованное логирование и лёгкое прослеживание истории прогонов теста между тест-менеджмент системой и непосредственно логом самого теста. Вот только мы не вполне учли, что единожды заполучив «золотой ресурс», инженеры не стремятся отпускать его обратно в свободный пул. Потому простои в выполнении тестов, конечно, уменьшились — но, как мы все знаем, «бесконечность — не предел».
Нет предела совершенству: как мы придумали «Запускатор»
Мы всё ещё были убеждены, что можно сделать лучше и решить и эту проблему — ну, или хотя бы сильно снизить её влияние. Из предыдущей части нашего пути мы твёрдо уяснили, что простои случаются там, где вмешивается человеческий фактор. В попытках ещё больше сократить его влияние в наших головах родилась идея «Запускатора». Мы решили создать одну большую красивую кнопку «сделать хорошо», после нажатия которой все ресурсные и тест-операции проходили бы автоматически, а инженеру оставалось только проанализировать результаты и, в традициях Древнего Рима, поднять палец вверх или вниз. Затем следовал автоматический перезапуск тестов, упавших не по причине проблем в продукте, а из-за некорректности теста или проблем с окружением (ведь когда железо долгое время пытаются сломать, оно рано или поздно не выдерживает).
Чтобы достичь желаемого, мы устроили мозговой штурм и составили список требований-«хотелок», чтобы наша жизнь стала ещё проще:
- Мы хотели только указывать название цикла в тест-менеджмент системе, а выборка по тестам для прогона должна была собираться автоматически.
- Мы хотели запускать любые тесты сразу на правильных кластерах, а не методом перебора, и не искать их в Xpool самостоятельно. Система должна была сама выполнять поиск.
- Мы хотели выбирать тесты по бесконечному числу параметров (а их обычно больше 10) и как можно скорее видеть, какого ресурса нам не хватает для успешного запуска.
- Мы хотели гибкости при старте и во время всего цикла — а именно, изменять параметры и всё, что можно изменить.
- Мы хотели дополнительной логики при выборе кластера.
- Мы хотели видеть все отчёты и логи в одном месте, а не бегать сломя голову по всему Jenkins.
Вот так и появился «Запускатор». Изначальный концепт монолита в итоге превратился в шесть микросервисов. Основу составила база данных со всеми реквизитами и связями с каждым тестом и оборудованием. Для связи с этой базой данных был создан отдельный компонент DB Agent, который занимался организацией работы с ней. Кроме того, за взаимосвязь с Jenkins отвечает компонент под названием Jenkins Agent — он «помнит» о том, какие есть джобы, знает, что запущено в текущий момент, где и что лежит, какова логика взаимосвязи между тестом и джобой, какие нужны параметры, чтобы правильно её запустить. На этом этапе мы ещё больше оценили то, что имеем стандарт для джоб: в противном случае разобраться в сильно разросшемся «зоопарке» было бы в разы сложнее.
Как вы уже могли догадаться, все эти процессы происходили не за один день и даже не за месяц, а релизы при этом никто не отменял. Как и новые фичи, новые тесты и новые джобы.
Три самых важных компонента «Запускатора» — Test Manager, Resource Manager и General Manager. Test Manager отвечает за взаимодействие с системой тест-менеджмента и знает все нюансы и конфигурации тестов, их параметры и особенности. Resource Manager занимается взаимодействием с ресурсной системой, собирает из Xpool всю информацию об имеющихся в распоряжении команды кластерах и помнит, какие ограничения есть при запуске тестов. Управляет же всем этим General Manager, который запускает очереди, указывает, что, кому и когда делать, чтобы всё работало как единый механизм. Написан «Запускатор» был на Python с использованием PostgreSQL и RabbitMQ. Также к нему был прикручен ненагромождённый Web UI на Flask.
Интерфейс инженера-тестировщика с формой старта цикла тестирования.
Заключение
Итак, мы плавно приближаемся к концу нашего путешествия и дню сегодняшнему. Для запуска всего цикла инженеру нужно убедиться, что у него достаточно свободных кластеров в Xpool, выбрать цикл и нажать на старт. Спустя некоторое время как из рога изобилия начнут сыпаться результаты тестов, и команде останется только проанализировать их. Таким образом, инженеры участвуют в процессе лишь при запуске и разборе результатов — а в остальное время разрабатывают новые тесты и тест-планы либо помогают анализировать проблемы клиентов, чтобы перенять и применить этот опыт в тестировании.
Одна неделя вместо трёх месяцев — вот время, которое теперь занимает прогон всего цикла. Такой результат позволил нам открыть шампанское, чтобы отпраздновать маленькую победу в вечной войне за оптимизацию. Можно ли было что-то сделать по-другому? Конечно, однако набивать шишки приходится всегда, и ничего тут не поделаешь. Мы ни в коем случае не претендуем на истину в первой инстанции, а всего лишь хотим поделиться нашим опытом в довольно специфической области.
Спасибо, что дочитали до конца! Надеемся, что слушать о нашем путешествии вам было столь же интересно, как нам — рассказывать.
Комментарии (4)

sYB-Tyumen
10.11.2021 14:47Интересно, кто-нибудь фиксировал, насколько выросло энергопотребление лабораторий в результате? (Понятно, что предполагается 4 раза, но интересно, сколько вышло на самом деле)

DellTechTeam Автор
11.11.2021 16:39Системы в лабораториях работают 24/7 в любом случае, так как их uptime крайне важен пусть и в простое, поэтому энергопотребление не изменилось, а вот эффективность использования этой энергии напротив выросла. Спасибо за ваш интерес!
amarao
Я понимаю необходимость этого, но мне больно вас читать. Вы описываете CI-антиутопию, в которой test cycle неделя, и если в коде бага, то ждать "ок" на багфикс надо неделю.
Я очень понимаю почему так, и мне больно. Худший CI-пайплайн, с которым я имел дело, занимал примерно полтора часа (кровью и болью его скрутили в 40 минут), и работа с ним звучит как отправка на каторгу.
неделя же - это новый, неизведанный уровень антиутопии...
DellTechTeam Автор
Спасибо за ваш интерес! Мы чувствуем вашу боль и хотим поделиться взглядами на проблему в нашем недавнем развернутом выступлении: https://www.youtube.com/watch?v=b4o4a-_jdME&t=314s