

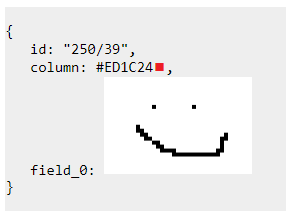
Всё началось с мема, который вы видите выше.
Сначала я посмеялся. А потом задумался: может ли быть так, что скриншот базы равноценен её снэпшоту?
Для этого у нас должно быть такое графическое представление базы, которое 1 к 1 отображает данные и структуру. Если сделать скриншот такого представления, из него можно восстановить базу.
Или... графическое представление и должно быть базой!
Тут, безусловно, можно схитрить и упростить себе жизнь:
Мы можем просто вывести sql скрипт в мелкопиксельном виде, а потом распознать текст со скриншота
Мы можем закодировать sql скрипт в бинарном виде и представить в виде изображения (4 байта на пиксель). Тогда скриншот тоже можно будет легко распарсить.
Но это всё ленивые и скучные способы. Куда интереснее было бы спроектировать базу так, чтобы мы действительно работали с ней как с изображением. Рисовали в пейнте и фотошопе, а не в этих скучных sql консолях и UI с таблицами.
По сути своей это вариант базы, с которой может работать художник (DBA-artist). Ну и конечно для неё нужен будет некий api, потому что использовать данные всё равно будет обычное приложение на обычном языке программирования, которому непонятны все эти художества, ему подавай json-ы.
Как вы понимаете, задача несёт исключительно исследовательский характер.
Начнём с формата данных.
Формат данных
Безумно велик соблазн использовать картинку просто как массив байт. Это и читать и писать удобнее. Для машины. Но цель - сделать не просто массив байт представленный в виде картинки, а осмысленное изображение, которое одновременно является источником данных.
Начнём с простого. Данные на картинке надо как-то находить. Вернее отличать данные от мета-информации и “отсутствия данных”. Давайте выберем некий маркерный цвет и попросим наших DBA-артистов рисовать квадраты этим цветом. Всё, что внутри - данные. Снаружи - не данные.
Цвет я выбрал таким, чтобы он хорош запоминался и при этом не было слишком “простым”, т.к. цвета вроде 0xFF0000, 0x00FF00 и иже с ними наверняка часто будут использоваться в данных.
Выбор пал на 0xBADBEE - нежно-голубой цвет, хорошо смотрящийся на белом фоне, и с мнемоническим названием. Ну и заодно саму базу я тоже так назвал.

Перед вами простейшая БД с одной записью типа “картинка”. Если запустить сервер badbee, дать ему такую картинку, а потом воспользоваться встроенным клиентом, то он покажет нам вот такой стилизованный json:
И, кстати, можно сделать скриншот и вставить в свою базу.
Инструкция для тех, кто хочет попробовать
git clone https://github.com/AlexeyGrishin/badbee.gitустановите докер
docker build -t badbee .создайте
db/temp.pngdocker run -d --rm --name badbee -e DB_FILE=temp.png -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbeeоткройте http://localhost:3030 . Убедитесь что клиент открылся.
сделайте скриншот или просто скопируйте картинку выше и вставьте в
temp.pngнемножко подождите и F5
Если у вас возникли сложности с докером, то можно так:
git clone https://github.com/AlexeyGrishin/badbee.gitInstall rust & cargo from https://www.rust-lang.org/tools/install
Install wasm-pack from https://rustwasm.github.io/wasm-pack/installer/
cargo build.cd web-clientwasm-pack build --out-dir ../static --target webcd ..cargo run --package web-server-
Вероятно надо будет поставить visual studio build tools, но вам об этом скажут или на этапе инсталляции, или на этапе сборки
Первичные ключи
Необязательно, но желательно иметь для записей уникальные первичные ключи. Хотя бы для того, чтобы ссылаться на них из других мест. Я подумал и решил, что самым простым будет использовать координаты верхнего левого угла. Это будет точно уникальный id в рамках БД, его довольно легко получить в любом редакторе изображений. Да, если подвинуть запись, то её id изменится, хотя сама она не поменяется. Ну и ладно, просто будем иметь это ввиду.
Организация данных
Одиночные записи нужны редко. Чаще нам нужно несколько “колонок” для хранения разных сведений. И проще всего это организовать соединив несколько записей визуально.


У нас уже получается база, где хранятся владельцы и их питомцы, причём питомцев может быть разное количество.
Добавим ещё одного человека, у которого есть три рыбки, и одного грустного приятеля без питомцев.

Если заполнить базу большим количеством записей, то в них становится сложно ориентироваться, выбирать что-то и искать. Я имею ввиду - программно. Глазами-то как раз всё легко.
Чтобы упростить себе жизнь и использовать преимущества пространственного расположения, я ввожу понятие “столбца” - тот самый загадочный “column” из примеров выше.

Кстати всё что нарисовано снаружи квадратов не учитывается - можно использовать как “комментарии”.
Все записи, которые вертикально располагаются под цветными пикселями сверху, считаются принадлежащими этому столбцу. Эта база организована так, что в “синем” столбце у нас записи домов, а в “красном” столбце - записи людей.


Типы данных
Хранить и возвращать картинки - это, конечно, полезно. Но недостаточно. В базе нам нужно хранить и строки, и числа, и другую информацию, причём не просто в виде картинок, а в “машинно”-читаемом виде. Поборем желание сериализовывать данные в бинарной форме, и подойдём к решению иначе.
Самое простое - это булево значение. Если “пустота” (белый цвет) - это false. Если не пустота - значит true. В редакторе легко инструментом “заливка” переключать с одного на другое значение.
И тут возникает вопрос: как отличить, где мы имеем ввиду картинку, а где - булево значение? Нужна какая-то схема. И в идеале она должна быть тут же, в картинке.
Подумав над разными вариантами, я решил добавлять маленькие значки типов в уголки записей.

Цвет неважен, важно местоположение. Иконочка похожа на букву b - это и будет признак булева значения.


Теперь числа. Числами мы обычно что-то считаем. Если этого “чего-то” не очень много - то проще это что-то и нарисовать в нужном количестве. Например:

Состав кота: 2 глаза, 2 уха, 1 рот и 6 усов

Алгоритм парсинга простой:
Объявляем счётчик = 0
-
Ищется не “пустой” пиксель (цвет != белый). Если нашли:
Увеличиваем счётчик на 1
Выполняем “flood fill” в памяти, запоминая все не-пустые пиксели соединённые с этим
Повторяем с шага 2, отбрасывая пиксели, запомненные на шаге 2.2
У котика должно быть имя. Его должно быть можно прочитать и “машине”, и человеку в paint-е - таковы наши условия. Значит, нам нужно использовать текст, который легко парсится. Простой моноширинный шрифт подойдёт как нельзя лучше.

То, что он мелкий, имеет свои плюсы и минусы.
Плюсы:
Легко “писать” карандашом в пейнте, буквы простые
Легко парсить
Минусы:

В базе это выглядит вот так:

Ещё один интересный тип данных - это float. Как представить число с плавающей запятой? Например, от 0 до 1 - проценты, доля чего-то. Правильно, как визуальную долю!

Предположим, что это - уровень сытости котика.

76% - неплохо.

А что, если отмечать не одну долю, а несколько, разными цветами? Этакий говорящий сам за себя pie chart?
Например, мы хотим хранить распорядок дня котика. Каждый цвет кодирует некую деятельность (а легенда сверху помогает не запутаться).


Что ж, наш котик не так уж и много тыгыдыкает, как слон, а смотрит рыбов гораздо чаще, чем ест. В нашей базе уже можно хранить много полезного!
Ссылки
В примерах выше у нас были 2 домика и 3 человека. Хочется расселить человеков по домам, при этом оставив записи домов и людей раздельными, не объединяя их в огромную колбасу.
На помощь приходят ссылки. Выглядят они как пустые записи с типом “ссылка”. И в отличие от других маркеров типов, цвет тут имеет значение.

Ссылки, как мы видим, просто нарисованы от “внешнего ключа” к “первичному” (а точнее - к записи). Алгоритм следования по ссылкам (тот же flood fill, на самом деле) толерантен к небольшим разрывам, поэтому линии можно смело пересекать, если они разных цветов.

Если человек переедет из одного дома в другой, надо будет просто стереть одну линию и нарисовать другую.

Детали реализации
Каких-то алгоритмических откровений тут нет. Как примерно читается “база” я упоминал выше. Сначала, при запуске приложения, происходит чтение “схемы”, т.к. в памяти строится модель - где какие записи, какого типа, как связаны между собой. Чаще всего используется flood fill, который позволяет найти связи между записями.
Сами данные считываются при чтении уже конкретных записей. В теории это позволяет менять данные снаружи не меняя схему и видеть актуальные данные, но пока только в теории.
Для реализации сервера и простенького клиента я взял rust. Тупо потому что давно хотел что-нибудь на нём попробовать сделать. Скорее всего какие-то вещи я сделал неправильно, буду рад услышать продуктивную критику.
Что такое продуктивная критика
Я придерживаюсь убеждения, что фразы вроде “полная хрень”, “тут неправильно всё”, “зачем так делать” и иже с ним не являются критикой. Они являются способом публичного самоутверждения. Критика - это указание на ошибки таким образом, чтобы критикуемый получил достаточно информации о сути проблемы и возможных способах исправления, или хотя бы направление для самостоятельного исследования. Если сообщение не помогает критикуемому стать лучше - это не критика.
С кодом можно ознакомиться тут: https://github.com/AlexeyGrishin/badbee
Серверная часть
Тут я выделил 2 основных части. Библиотека с “ядром” базы, у которой есть апи для чтения/записи. И веб-сервер, который превращает http запросы в запросы к базе и затем превращает ответ в json.
Для веб-сервера взял warp(https://github.com/seanmonstar/warp/). Несмотря на то, что его сильно нахваливают, честно говоря мне не удалось его “грокнуть”. Я послушно копировал примеры, адаптировал их под себя, но как устроена эта система фильтров, к чему именно применится тот или иной фильтр - понять было сложновато. Если брать express.js и его middleware, то там это было как-то проще для понимания. Но то node.js и динамическая типизация, думаю в warp многое наворочено в угоду производительности.
Для работ с базами я попробовал реализовать простую модель акторов. Каждая база (да, сервер может обрабатывать несколько картинок-баз) - это актор, который запускается в отдельном “лёгком потоке” (скорее корутине, или как это называется правильно у tokio). Веб-сервер посылает команды актору базы и ждёт ответа, не мешая запросам к другим базам.
Актор выглядит примерно так:
while let Some(message) = rx.recv().await {
if let DBMessage::Shutdown = message {
break;
}
db.handle(message).await
}
async fn handle(&mut self, message: DBMessage) -> () {
match message {
DBMessage::Shutdown => {...},
DBMessage::SetModel { model, image } => {...}
DBMessage::CloneRecord { x, y, tx } => {...}
DBMessage::GetRecords { query, tx } => {...}
...
DBMessage::Sync => {...}
}
}
Вообще сначала я попытался делать “по-старинке”, через mutex-ы. Но бесконечные заворачивания всего подряд в Arc<Mutex<Box<...>>> меня немного утомили. С акторами код стал почище и попонятнее, но возникла проблема, которую я не очень пока понимаю как правильно решать (как неправильно - придумать могу много способов).
Актор в такой схеме получается “однопоточным”. Пока он обрабатывает одну команду (например GetRecords) он не может обрабатывать другие. Если кто-то запросил 10000 записей, а ещё кто-то 1, то этот второй будет ждать пока соберутся 10000 записей для первого. А если понадобится выполнить сохранение изменений на диск или загрузку изменений с диска...
Но, допустим, мы хотим распаралелить только чтение. Самое простое, что приходит в голову - делегируем операцию чтения какому-то “пулу” потоков, каждый из которых может читать из одного и того же участка памяти, где хранятся данные базы... Стоп, но тогда их снова надо в мютексы заворачивать, а как раз хотелось от этого уйти... В общем, интересно как это делают в мире акторов, и не только в rust.

Работать с rust мне скорее понравилось, чем нет. Borrow checker иногда хочет странного, но зато если скомпилировалось и запустилось - то скорее всего работает. Бинарник получился размером в 4 мегабайта, а при запуске с мелкой картинкой занимает 5 мегабайт RAM (5 мегабайт! Не гигабайт!). Я уже отвык от таких чисел в кровавом энтерпрайзе.
Несколько моментов, которые мне особенно запомнились при работе, может быть кому-то из новичков будет интересно.
Обработка ошибок
На начальном этапе разработки я пренебрёг обработкой ошибок. В языках с exception-ами такой подход прокатывал - можно было потом try/catch-ей насовать. В расте это уже не прокатывает. Понатыкав везве вызовов unwrap() я потом частенько с болью смотрел на то, как сервер падает (причём совсем) то там то тут из-за каких-то мелких ошибок, выходов за границы и прочих ожидаемых ошибок. А когда я решил исправить ситуацию и заодно возвращать какие-то осмысленные ошибки в своём api, то мне пришлось по всей цепочке вызовов заворачивать все ответы в Result, трансформировать виды ошибок, активно использовать оператор ? и всё прочее. Оно того стоило, на мой взгляд, но в следующий раз я потрачу лишние пару секунд и сразу предусмотрю и Result, и прокидывание ошибок вместо unwrap().
Явные и неявные преобразования
Очень мощным мне показался механизм трейтов From/Into. Как чаще всего выглядит какая-нибудь функция в api в java:
public Something createSomething(String value) { ... }Возможно, автор библиотеки заморочился и добавил несколько перегрузок функции с другими аргументами, чтобы было удобно пользоваться. А возможно нет. Тогда придётся все свои нестандартные типы данных превращать в строки явно при использовании библиотеки.
В rust же можно записать вот так:
fn create_something<T>(value: T) -> Something where T: Into<String> { ... }Что означает “можно передать сюда что угодно, что можно конвертировать в String”. И достаточно для вашего типа реализовать trait From - и можно передавать ваши типы в библиотечную функцию. Причём тут <T> - это не типа дженерика в java, а скорее темплейт в C++. То есть для вашего типа создастся своя версия create_something, где будет вызвано преобразование в String (и, скорее всего, как-нибудь хитро заинлайнено и оптимизировано - я бы ожидал).
Компилятор
Сообщения об ошибках в rust - это произведение искусства. В кои-то веки компилятор не орёт на тебя как полоумный, а реально пытается помочь и подсказать. Посмотрите, ну разве не прелесть?

Клиентская часть
Т.к. для демонстрации работы api мне нужен был простенький клиент, то я решил и его тоже сделать на rust, благо rust можно превращать в web assembly.
На пробу взял фреймворк sauron (https://github.com/ivanceras/sauron). Как вы можете догадаться, взял чисто из-за названия, потому что иных критериев выбора у меня не было.
Работой с ним я более-менее доволен. Чем-то напомнил мне elm. Ну и react немного тоже. Довольно круто то, что jsx-подобный синтаксис реализован с помощью rust-овских макросов. Причём макросы в rust - это не то же самое, что макросы в C/C++. Там это просто замена строк, здесь же выполняется полноценный синтаксический разбор, компилятор не даст опечататься и предупредит о выстрелах в ногу.
Пример кода:
fn boolean_view(value: serde_json::Value, rec_id: &str, field_idx: usize) -> Node<Msg> {
let rec_id = rec_id.to_string();
let value = value.as_bool().unwrap();
node! [ <span>
<input
type = { "checkbox" }
checked = { value }
on_checked=move |e| { Msg::PatchRequested { id: rec_id.clone(), fi: field_idx, new_value: json!{ e } } }
/>
</span> ]
}
Что мне не понравилось. Из примеров и документации неясно как выполнять декомпозицию. В примере выше можно видеть, что для рендера мне надо возвращать Node<Msg>, где Node - это собственно элемент virtual dom, а Msg - enum с сообщениями, и вот он уникален для моего приложения. Как выносить отдельные виджеты в библиотеки, как реюзать их, чтобы они отправляли разные сообщения - неясно. Я не говорю, что такой возможности нет вообще, но я не увидел как это сделать.
Так же не все события можно использовать в макросах, что вынуждает переключаться на составление node вручную (например - image onload). Это в целом не так страшно выглядит, но мне не нравится когда в проекте используются разные техники для одного и того же.
Событие on_mount было бы полезным, но оно вызывается до того как созданный dom element вставлен в документ и до того как созданы дочерние элементы. То есть какие-то операции можно проводить только над самим элементом, а связать его с другими элементами в dom - уже не получится.
В общем, как следует помучавшись, я смог таки сделать даже простенькую рисовалку, чтобы иметь возможность менять значения полей типа image.

Ссылка на соответствующий код, если интересно: https://github.com/AlexeyGrishin/badbee/blob/demo/web-client/src/field_view.rs#L53
После компиляции набор ресурсов занимает примерно 400 килобайт.

Не с чем сравнить, чтобы понять, много это или мало для такого приложения. Но как будто многовато, тем более это уже бинарник, а не текстовый листинг. Возможно, выбранный фреймворк слишком прожорливый.
Большой файл с данными
Выше я писал, что при запуске с небольшой картинкой приложение занимает в памяти 5 мегабайт. Хорошо, а что если картинка - большая?
Для проверки я сделал картинку 10000х40000 пикселей, 32 цвета, PNG. Занимает она на диске 287 мегабайт, и внутри содержится более 9000 записей (в каждой записи - 8 полей).
Добавлять её в статью или на github я, конечно, не буду.

Запускаю сервер с одной только этой картинкой в докере (называется она husky_bigger.png)
docker run -d --rm --name badbee -e DB_FILE=husky_bigger.png -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee
Через некоторое время открываю клиент:

Нормально, загрузилось. 10 секунд потребовалось чтобы распарсить модель.
А что по памяти?

Уже не так круто. Но ничего особо неожиданного в этом нет. PNG - сжатый формат. Чтобы работать с отдельными точками, надо сначала распаковать всё в более плоскую модель. 10000 пикселей на 40000 пикселей на 4 байта на пиксель - получаем те самые 1.5 гигабайта.
Выглядит уже не так масштабируемо, как хотелось бы. А что если файл будет в 10 раз больше? Плюс понятно, что нам не нужно постоянно держать всё в памяти. В разное время будут требоваться разные записи, и хорошо было бы держать в памяти только какие-то кусочки, а остальное пусть подргужается с диска, когда нужно.
Но тут нас ждёт проблема. PNG использует сжатие Deflate - по сути тот же zip. И (поправьте меня, если я ошибаюсь) нет способа в общем виде достать что-то из середины zip архива не распаковав то что было в начале. Мы не можем из png на диске выбрать часть картинки из середины.
И тогда на помощь приходит...
BMP!
Этот формат хранит изображение без сжатия, а данные отдельных пикселей располагаются предсказуемым образом и построчно (правда почему-то снизу вверх, т.е. в начале файла идёт последняя строка пикселей, потом предпоследняя, и в конце - первая).

Это означает, что можно разрезать изображение на горизонтальные полоски, и подгружать в памяти их с диска по мере надобности (и выгружать тоже).
Если для работы с png я использовал библиотеку rust image (https://github.com/image-rs/image), то для работы с bmp навелосипедил своего кода (https://github.com/AlexeyGrishin/badbee/blob/demo/backend/src/io/bmp_on_disk.rs)
Для начала просто превратим наш png в bmp и посмотрим что изменится.
Во-первых изменился размер файла. Он стал 1.2Гб. Почему не 1.5? Потому что в bmp нет альфа-канала, и на каждый пиксель приходится максимум 24 бита (3 байта), а не 32.
Теперь запустим приложение с этим файлом.
docker run -d --rm --name badbee -e DB_FILE=husky_bigger.bmp -e BMP_KEEP_IN_MEM_INV=1 -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee

Всё то же самое, но грузилось подольше. Возможно потому, что файл грузится не сразу целиком, а полосками по 1024 пикселя. Возможно потому, что я выдал не настолько быстрый код, как авторы библиотеки image.
Что по расходу памяти?

Ожидаемо.
Теперь перезапустим, изменив параметр BMP_KEEP_IN_MEM_INV. Его смысл - указать приложению, что в памяти надо держать не более 1/BMP_KEEP_IN_MEM_INV от объёма файла. Предыдущий раз мы запускали со значением 1, теперь возьмём значение 6
docker run -d --rm --name badbee -e DB_FILE=husky_bigger.bmp -e BMP_KEEP_IN_MEM_INV=6 -p 3030:3030 -v "$pwd/db:/usr/badbee/db" badbee
Загрузка прошла примерно за то же время:

А памяти стало занимать меньше:

Если листать в клиенте туда сюда, то в логах контейнера можно увидеть, как он выгружает/загружает кусочки изображения.

Заключение
Тут я даже не знаю что писать. Замеры перформанса? Планы на развитие? Сферы применения? Мы точно говорим о базе данных, хранимых в png?
Впрочем, формат можно использовать для хранения конфигов. В геймдизайне, например. Зачем тюнить параметры юнитов в скучном json, когда можно делать это прямо в текстурах в фотошопе?
А вот как может выглядеть docker-compose.png
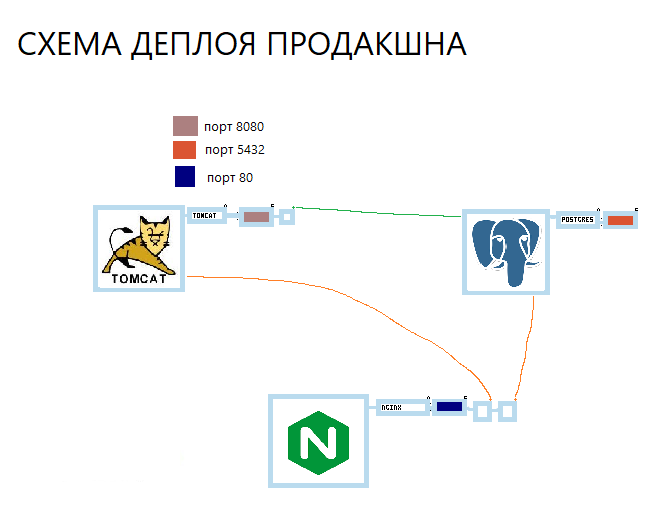
Это и конфиг, и схема в одном флаконе. Можно сфотографировать на телефон и дома поднять сервер по фотографии.

Ещё одно возможное применение - это обучение основам БД. Всё-таки при работе с базами данных приходится изучать и принципы, и инструменты. А тут можно наглядно показывать принципы в любом графическом редакторе, объяснять понятия записей, схемы данных, ключей и связей.
На этом всё. Не забывайте делать бэкапы. И скриншоты тоже. На всякий случай.
Комментарии (87)

roofroot
21.11.2021 17:15+15Великолепно! Можно залить базу данных клиентов в картинки с голыми тетями. Спасибо за идею и реализацию)

AlexanderS
22.11.2021 15:32+1Оригинальный способ обеспечения надёжности сохранения, путём неподконтрольного резервирования ;)





MichaelBorisov
21.11.2021 18:05-32Поздравляю вас, автор, вы изобрели стеганографию!

GRaAL Автор
21.11.2021 18:14+88Вообще нет. Стеганография - про сокрытие информации в изображении, незаметное для того кто картинку глазами смотрит. Тут ничего общего.
Так что и я вас поздравляю, вы изобрели оставление комментария без прочтения поста.

VT100
21.11.2021 21:43+12Тем не менее, заголовок провоцирует имеено такую мысль — стеганография.
GRaAL Автор
21.11.2021 21:56+7Действительно, не подумал об ассоциациях. Но менять название сейчас будет как-то некорректно, плюс - имхо - вступление довольно чётко даёт понять что речь не о стеганографии.
Ваше замечание уместно и корректно, т.к. указывает на реальную проблему и её последствия. Замечание товарища выше - нет.

petropavel
22.11.2021 13:52+2Кстати, и цель, поставленная в заголовке не достигнута — внимание санитаров привлечено :)

littleleshy
22.11.2021 16:31У меня заголовок спровоцировал мысль о слишком простых вещах – альтернативных потоках.

k2589
21.11.2021 18:13+16Как раз начинаю новый проект и не мог определиться с бд. Автор, спасибо, воспользуюсь badbee!
Единственный вопрос - под какой лицензией распространяется?
GRaAL Автор
22.11.2021 08:45+5Признаюсь, я так и не сумел придумать достойную ответную шутку.


Medeyko
22.11.2021 17:57+9По-моему, Вы пытаетесь уклониться от ответа!
Суровая правда жизни же состоит в том, что Вы не готовы поделиться с человечеством плодами трудов своих тяжких. Вы отлично понимаете, что за такими базами данных - будущее, а Ваша реализация практически идеальна. И надеетесь разбогатеть на её использовании! Не будьте буржуйским жмотом, отдайте Ваше произведение городу и миру под свободной лицензией!
А если серьёзно, то мало ли кому-нибудь ещё станет скучно, и он захочет развить Вашу шуточную систему. Я не вижу ни одной причины, почему бы не указать на самом видном месте репозитория (например, в файле LICENSE) свободную лицензию (или сходный инструмент). Очень обидно бывает, когда понимаешь, что автор был бы не против использования его произведения, но использовать невозможно из-за отсутствия явного и корректного указания на это.
Чтобы Вам не искать, я привожу в спойлере CC0
Statement of Purpose
The laws of most jurisdictions throughout the world automatically confer exclusive Copyright and Related Rights (defined below) upon the creator and subsequent owner(s) (each and all, an "owner") of an original work of authorship and/or a database (each, a "Work").
Certain owners wish to permanently relinquish those rights to a Work for the purpose of contributing to a commons of creative, cultural and scientific works ("Commons") that the public can reliably and without fear of later claims of infringement build upon, modify, incorporate in other works, reuse and redistribute as freely as possible in any form whatsoever and for any purposes, including without limitation commercial purposes. These owners may contribute to the Commons to promote the ideal of a free culture and the further production of creative, cultural and scientific works, or to gain reputation or greater distribution for their Work in part through the use and efforts of others.
For these and/or other purposes and motivations, and without any expectation of additional consideration or compensation, the person associating CC0 with a Work (the "Affirmer"), to the extent that he or she is an owner of Copyright and Related Rights in the Work, voluntarily elects to apply CC0 to the Work and publicly distribute the Work under its terms, with knowledge of his or her Copyright and Related Rights in the Work and the meaning and intended legal effect of CC0 on those rights.
1. Copyright and Related Rights. A Work made available under CC0 may be protected by copyright and related or neighboring rights ("Copyright and Related Rights"). Copyright and Related Rights include, but are not limited to, the following:
the right to reproduce, adapt, distribute, perform, display, communicate, and translate a Work;
moral rights retained by the original author(s) and/or performer(s);
publicity and privacy rights pertaining to a person's image or likeness depicted in a Work;
rights protecting against unfair competition in regards to a Work, subject to the limitations in paragraph 4(a), below;
rights protecting the extraction, dissemination, use and reuse of data in a Work;
database rights (such as those arising under Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases, and under any national implementation thereof, including any amended or successor version of such directive); and
other similar, equivalent or corresponding rights throughout the world based on applicable law or treaty, and any national implementations thereof.
2. Waiver. To the greatest extent permitted by, but not in contravention of, applicable law, Affirmer hereby overtly, fully, permanently, irrevocably and unconditionally waives, abandons, and surrenders all of Affirmer's Copyright and Related Rights and associated claims and causes of action, whether now known or unknown (including existing as well as future claims and causes of action), in the Work (i) in all territories worldwide, (ii) for the maximum duration provided by applicable law or treaty (including future time extensions), (iii) in any current or future medium and for any number of copies, and (iv) for any purpose whatsoever, including without limitation commercial, advertising or promotional purposes (the "Waiver"). Affirmer makes the Waiver for the benefit of each member of the public at large and to the detriment of Affirmer's heirs and successors, fully intending that such Waiver shall not be subject to revocation, rescission, cancellation, termination, or any other legal or equitable action to disrupt the quiet enjoyment of the Work by the public as contemplated by Affirmer's express Statement of Purpose.
3. Public License Fallback. Should any part of the Waiver for any reason be judged legally invalid or ineffective under applicable law, then the Waiver shall be preserved to the maximum extent permitted taking into account Affirmer's express Statement of Purpose. In addition, to the extent the Waiver is so judged Affirmer hereby grants to each affected person a royalty-free, non transferable, non sublicensable, non exclusive, irrevocable and unconditional license to exercise Affirmer's Copyright and Related Rights in the Work (i) in all territories worldwide, (ii) for the maximum duration provided by applicable law or treaty (including future time extensions), (iii) in any current or future medium and for any number of copies, and (iv) for any purpose whatsoever, including without limitation commercial, advertising or promotional purposes (the "License"). The License shall be deemed effective as of the date CC0 was applied by Affirmer to the Work. Should any part of the License for any reason be judged legally invalid or ineffective under applicable law, such partial invalidity or ineffectiveness shall not invalidate the remainder of the License, and in such case Affirmer hereby affirms that he or she will not (i) exercise any of his or her remaining Copyright and Related Rights in the Work or (ii) assert any associated claims and causes of action with respect to the Work, in either case contrary to Affirmer's express Statement of Purpose.
4. Limitations and Disclaimers.
No trademark or patent rights held by Affirmer are waived, abandoned, surrendered, licensed or otherwise affected by this document.
Affirmer offers the Work as-is and makes no representations or warranties of any kind concerning the Work, express, implied, statutory or otherwise, including without limitation warranties of title, merchantability, fitness for a particular purpose, non infringement, or the absence of latent or other defects, accuracy, or the present or absence of errors, whether or not discoverable, all to the greatest extent permissible under applicable law.
Affirmer disclaims responsibility for clearing rights of other persons that may apply to the Work or any use thereof, including without limitation any person's Copyright and Related Rights in the Work. Further, Affirmer disclaims responsibility for obtaining any necessary consents, permissions or other rights required for any use of the Work.
Affirmer understands and acknowledges that Creative Commons is not a party to this document and has no duty or obligation with respect to this CC0 or use of the Work.
Я в репозитории не то что на видном месте, вообще нигде не нашёл указания на лицензию. Может, конечно, в упор не увидел, конечно :)
Medeyko
23.11.2021 13:18+1Ага, вижу, прислушались, спасибо огромное! https://github.com/AlexeyGrishin/badbee/commit/08eac3a3df5dee0f9c8e9dc6f7cd1c271dbc340c
Согласен, сюда такая лицензия вписывается идеально :)
Вас больше ни о чём не прошу, но позанудствую в сторону (как один из тех, благодаря кому в российском ГК появилось положение об открытых лицензиях):
Лучше стараться использовать тщательно продуманные с юридический точки зрения лицензии типа одной Creative Commons - чтобы быть уверенными, что в них сказано всё, что нужно. Во многих юрисдикциях при отсутствии прямого указания на срок и территорию действия лицензии устанавливаются ограниченные дефолтные значения...



krote
21.11.2021 19:28+2Я почему то из названия ожидал что автор вспомнит про карточки персонажей png в некоторых играх, это реально применяется и реально удобно, люди загружают их в галереи на сайты а другие скачивают и игра из них достает все параметры и внешний вид персонажа, а пользователь всегда видит их превью в любом редакторе.
Но конечно информация там кодируются не в самом изображении а в отдельной неиспользуемой секции, я понимаю что статья не об этом)
GRaAL Автор
21.11.2021 19:44+3Да, есть такая техника. Её, кстати, я тоже использовал в своё время. В нашей игре Protolife (про неё есть статья тоже на Хабре) есть редактор пушек. И вот они хранятся в виде png, где в дополнительной секции лежит json со всей информацией. Тоже получается удобное встроенное превью.
А первый раз я про такое узнал в игре spore. Насколько я помню там тоже существа сохранялись в "картинку", и в таком виде можно было распространять. Впечатлился.

iShrimp
22.11.2021 19:47В игре Mekorama каждый уровень имеет карточку, содержащую QR-код со всей структурой уровня. Отсканировав код, можно сразу начать в него играть.


bars_arseniy
21.11.2021 20:08+4Можно сфотографировать на телефон и дома поднять сервер по фотографии.
Это забавно звучит и к тому же работает, в отличие от диагнозов по аватарке и лечению по фотографии.
Замечательно!SAVFOD
22.11.2021 11:35+1Скорее всего, не сработает. Ведь при фотографии слегка поломаются цвета, прямоугольные рамки, пиксельные модификаторы типа. Чтобы надёжно экспортировать небольшую базу через фотографию нужны другие технологии, вроде QR-кода.
База в QR, вероятно, не поместится, там всего несколько килобайт. Для такого случая был вариант с видео на 700-800 KB/s https://habr.com/ru/company/vdsina/blog/534412/
Но в обычный QR легко поместится докерфайл, например. Вполне "поднять сервер".

bethoven
21.11.2021 20:10+5Класс, немного сумасшедших и красивых идей ;) Скучный и однообразно монстрообразный софт из кроваво - энтерпрайзного мира так надоел. И пишете так приятно и понятно, с легко читаемыми примерами и веселыми кото-картинками ))), аж захотелось почитать про rust и все что вокруг него сейчас происходит. И вообще выйти из ридонли мода и оставить комментарий под статьей. Пойду ка почитаю еще Ваши статьи. )
GRaAL Автор
21.11.2021 21:51+4Значит, я не зря
пью свои таблеткипотратил своё время. Я рад, если вдохновило.

lgorSL
21.11.2021 20:19+9Можно открыть bmp как memory mapped file и смело читать из любого места, ОС сама будет лениво подгружать данные с диска или выгружать обратно.
GRaAL Автор
21.11.2021 21:49+2Да, так тоже можно. Я думал про memory mapped files, но пока ещё работал с png, и понял, что там это не прокатит. А когда дошёл до bmp, то как-то вылетело из головы.

rogoz
21.11.2021 20:29+3Этот формат хранит изображение без сжатия, а данные отдельных пикселей располагаются предсказуемым образом и построчно
Как я понимаю, в общем случае не всегда.Так что может прийти неждан, особенно когда «навелосипедил своего кода».GRaAL Автор
21.11.2021 21:48+2Да, это правда. Забыл об этом упомянуть.
Но хорошо то, что в моём случае нет необходимости поддерживать все возможные форматы. Если DBA нужно меньшее потребление памяти - придётся ему использовать BMP нужного вида.
Другое дело, что мой велосипед действительно сейчас не ждёт других вариантов. В production ready коде это нужно было бы обязательно учесть.

befree
21.11.2021 23:17+1Есть такая утилита steghide - вроде даже еще и шифрует данные. Я использовал в linux - когда для целей разработки надо было кое-чего заиметь во внутреннем контуре сети. Была связь только по email и левые форматы резались. А картинки норм.
В локальном репозитории внутреннего сегмента сети - нашлась такая утилитка.

engine9
21.11.2021 23:42+1Не совсем в тему, но вспомнилось. Есть программа для создания бумажных "хардкопий" файлов, которая может создавать документы для сохранения файлов в виде распечаток. Она же позволяет производить сканирование и распознавание. Paperback называется.

AHOHNMYC
22.11.2021 08:43+2Если уж мы начали играть в ассоциации, есть PhonoPaper, который считывает с бумаги особым родом закодированный звук) Вот авторская статья: https://habr.com/ru/post/220061/

tyomitch
22.11.2021 12:00+1Не «особым образом закодированный», а ru.wikipedia.org/wiki/Спектрограмма — в этом формате его удобно и просматривать глазами, и редактировать. Вот моя статья: habr.com/ru/post/469775



MoonInHell
22.11.2021 11:52+1Можете, пожалуйста, объяснить суть статьи для самых маленьких
и тупых? Очень интересно, но ничего не понятно.GRaAL Автор
22.11.2021 12:06+6Попытка ответа на теоретический вопрос "Как сделать базу данных, чтобы а) файл с данными был одновременно визуализацией этих данных б) файл с даннными можно было бы редактировать в пейнте в) с данными можно было бы работать извне по api". То есть такая визуализация данных, которую и человек, и машина могут прочитать.
tyomitch
22.11.2021 13:02+4Отличный синопсис. В идеале он должен быть где-то ближе к началу статьи, потому что сейчас вопрос «что у автора на уме?» терзает читателей до самого её конца. (Судя по комментариям про стеганографию и QR-коды, замысел многим так и оставался неясным.)

Aldrog
22.11.2021 13:50+2Ближе к началу статьи есть такое:
Но это всё ленивые и скучные способы. Куда интереснее было бы спроектировать базу так, чтобы мы действительно работали с ней как с изображением. Рисовали в пейнте и фотошопе, а не в этих скучных sql консолях и UI с таблицами.
Но по заголовку и даже тексту до ката конечно совершенно не ясно, о чём статья будет.
Я тоже ожидал открытие автором стеганографии или упаковку бинарника в png, и очень рад что всё-таки её открыл и прочитал.



trijin
22.11.2021 13:03все же возвращаясь к мему, а есть метод создания screenshot(snapshot) базы, или только парсинг собственноручно нарисованных картинок?
GRaAL Автор
22.11.2021 13:15Смотря какой базы. Если BADBEE - то есть. Если postgresql/mysql - то пока нет. Но если мне опять будет скучно, я подумаю над этой задачей.
trijin
22.11.2021 17:07А можно глянуть на такой автоматический сгенерированный рисунок, допустим с вашими тестовыми данными для статьи?
GRaAL Автор
22.11.2021 17:22+3А, я неправильно понял ваш вопрос.
Вы имеете ввиду "можно ли накидать в базу данных, чтобы она их нарисовала". Т.е. чтобы не я их рисовал, а сама БД.
С некоторыми ограничениями - можно. Например, та большая база с собаками создана почти автоматически. В базе изначально была только 1 запись - пустой шаблон для инфы о собаках.
Дальше у меня был скрипт, который брал публичную информацию о собаках со страницы сайта http://ingrus.net/husky/photo . И посылал в базу через api следующие команда:
Склонировать самую первую запись. Движок искал свободное место в файле картинки, копировал запись туда и возвращал id новой записи
Дальше уже заполнялись поля этой записи.
Можно ли научить БД создавать записи с нуля - рисовать квадратики и связи между ними? Да, можно, хоть я до этого и не дошёл. Найти свободное место движок уже умеет. Нарисовать квадратик несложно. Соединить его с другим - какой-нибудь вариант A* в помощь.
Основная проблема - что делать, если "место" закончится. Надо увеличить размер картинки. И даже в bmp это не тривиально, т.к. там почему-то задом наперёд данные записаны, и если дописывать в конец файла - они дорисуются в начале (и все id поедут). Скорее всего пришлось бы делать что-то вроде "создать картинку на диске в 2 раза больше, сохраниться туда, старую удалить, новую переименовать".
Вот код который я использовал для импорта, чисто для демонстрации.
let avatarCanvas = document.createElement("canvas"); avatarCanvas.width = 97 avatarCanvas.height = 106 let flagCanvas = document.createElement("canvas"); flagCanvas.width = 37 flagCanvas.height = 27 function img2dataUrl(img, canvas) { canvas.getContext("2d").drawImage(img, 0, 0, img.naturalWidth, img.naturalHeight, 0, 0, canvas.width, canvas.height) return canvas.toDataURL() } async function importCellToDB(td) { let avatarImg = td.querySelector(".myBlock img") if (!avatarImg) return null let newRecord = (await(await fetch("https://e80e-185-97-201-39.ngrok.io/husky_big.png/records/53/30/clone", { method: "POST" } )).json())[0]; async function putValue(fi, value) { await fetch(`https://e80e-185-97-201-39.ngrok.io/husky_big.png/records/${newRecord.id}/${fi}`, { headers: {"Content-Type": "application/json"}, method: "PUT", body: JSON.stringify(value) }); } //field 1 - avatar await putValue(0, {value: {data_url: img2dataUrl(avatarImg, avatarCanvas), width: 97, height: 106}}); //field 2 - gender await putValue(1, {value: td.querySelector("img[src*=female]") != null ? "#CE82C7" : "#00A2E8"}) //field 3 - count of kuboks, skip //field 4/5 - parents, skip //field 6 - name await putValue(5, {value: td.querySelector("b").innerText}) //field 7 - colors (random) let r = Math.random() await putValue(6, {value: { "#000000": r, "#ffffff": 1-r }}); //field 8 - country await putValue(7, {value: {data_url: img2dataUrl(td.querySelector("img[src*=flag]"), flagCanvas), width: 37, height: 27}}); }
LoadRunner
24.11.2021 10:31+1И даже в bmp это не тривиально, т.к. там почему-то задом наперёд данные записаны, и если дописывать в конец файла - они дорисуются в начале (и все id поедут).
Храните смещения, а не координаты. Да, координаты - это те же смещения, но от точки 0.0. Просто в вашем случае точка 0.0 в правом нижнем углу. И эта система очень сильно переворачивает мозг.
Например. в фоллаут (который гексогональный) начало координат - правый верхний угол.

Aldrog
22.11.2021 13:57+2Сообщения об ошибках в rust — это произведение искусства. В кои-то веки компилятор не орёт на тебя как полоумный, а реально пытается помочь и подсказать. Посмотрите, ну разве не прелесть?
Чисто для справки — в компиляторах C++ (gcc, clang) такие подсказки тоже есть, помню как радовался им после обновления до GCC 9.


Gordon01
22.11.2021 15:11+1Наглядный пример того, что действительно пишут на расте, кроме надоевшего RiiR coreutils и криптостартапов.
Обращайтесь в личку за билетом на r/rustjerk %)
GRaAL Автор
22.11.2021 16:01Да, я посмотрел вакансии, и там куча криптостартапов и прочего финтеха, который я не очень люблю ( Даже обидно как-то. Мне понравился rust. Я видел высоконагруженные проекты на C/C++, связанные с перформанс-тестированием, которые запускались на отдельных железках. Мб rust как раз пригодился бы на подобных проектах.
Gordon01
22.11.2021 16:36+1В Pop_os! вроде нужны разработчики в графическое подразделение. У них все на расте.
А так да, вакансий маловато, с другой стороны в криптостартапе можно заработать больше, чем на обычной работе, а потом открыть свой, нормальный.
Если вам интересны микроконтроллеры и легковесные no_std библиотеки, можете со мной пилить: https://github.com/Gordon01/rugui/tree/experimental (сорян, ничего не оформлено, но если склонить и запустить, то заработает)
Вот тут можно эмулятор в браузере запустить: https://gordon01.github.io/rugui-emulator/
GRaAL Автор
22.11.2021 16:56Спасибо!
Репозиторий посмотрю, а то я не видел ещё как другие на расте пишут.

morijndael
22.11.2021 16:02Неплохо было бы иметь имена у полей, с field_{1,2,3,...} будет не очень удобно работать. Способ написать текст у нас есть, можно, например, написать имя поля по краю квадратика
Lordicus
22.11.2021 16:57Выставил дамп базы как NFT:
This DB goes hard feel free to screenshot.
Жду статью по хранению БД в виде звука.

vesper-bot
22.11.2021 19:22+1Интересно, а как обходить ситуацию, когда позарез нужно скриншот базы впихнуть в Badbee как элемент базы данных? Ну или если потребуется, чтобы какой-то элемент данных содержал рамку из цвета 0xbadbee? Сдается мне, этот формат хранения БД такое не осилит распарсить корректно.
GRaAL Автор
22.11.2021 20:12+1Не, нормально!
Единственный баг - он распарсил и то, что внутри, тоже. Забыл добавить проверку на вхождение точки в уже найденный блок в одном месте.
Пофикшено: https://github.com/AlexeyGrishin/badbee/commit/7b01805d73ffef3ba2823c05e7883d81e6e54b93
Спасибо за ваш вклад!
Aldrog
23.11.2021 13:21А если добавить картинку с внешней рамкой цвета #badbee? Она просто съестся или ещё и тип записи может поменяться? Не очень понял из статьи, зависит ли что-то от толщины рамки.
GRaAL Автор
23.11.2021 14:40Съестся. Толщина рамки может быть произвольной, я не стал ограничивать художников. Придётся "экранировать" с помощью белой рамки, увы.


ilving
22.11.2021 20:13Уважаемый автор, подскажите, пожалуйста: за голубыми полями картинки таки "комментарии" или модификаторы со связями? И если таки комментарии и прочий арт - может логичнее было их цветовые маркеры разместить на поле рамки? )
GRaAL Автор
22.11.2021 20:17+2Там может быть и то, и другое. Однако сейчас я уже подумал, что маркеры типов надо было не снаружи голубых квадратов вставлять, а внутрь.
Если соблюдать несложные правила, то должно быть сложно перепутать незначимый арт и линии связей. Можно конечно комментарии тоже во что-то заворачивать, или линии связей рисовать особыми цветами. Но мне хотелось снизить "порог вхождения", чтобы можно было быстро сориентироваться, а не зубрить кучу правил по рисованию базы.
mondzucker
22.11.2021 22:17А есть же вроде PNG24, трёхканальный
Aldrog
23.11.2021 13:27Основная-то проблема была не в четырёх каналах, а в отсутствии произвольного доступа.

palyaros02
23.11.2021 09:49+1Это ШЕДЕВР! Сейчас занимаюсь с учеником, как раз через неделю будем БД разбирать, ваша разработка будет очень и очень наглядным примером, и вообще есть идея внедрить ее в образовательный процесс. Единственная проблема - ее невозможно использовать без лицензии. Так что слёзно прошу добавить лицензию ????.
LoadRunner
24.11.2021 11:08Если бы не необходимость в поддержке изображений, как часть хранимых в базе данных, я бы предложил вместо bmp использовать etc2. Сжатие с потерями, всё-таки.
Vaprubnyak
29.11.2021 14:21Вот он первый шаг к визуальной работе с базой данных средствами дополненной или виртуальной реальности! Гениально!
13_beta2
А если вспомнить про apng? Там, по-моему, каждый кадр сжимается отдельно и уже можно соорудить какую-никакую страничную адресацию. Но "простота" редактирования в paint пострадает, это да.
GRaAL Автор
Да, и gif тоже. Думал над этим, благо есть покадровые редакторы гифок. Но решил сосредоточиться на варианте попроще, а то был риск остыть и не доделать.