
Данные — это душа каждой модели машинного обучения. В этой статье мы расскажем о том, почему лучшие команды мира, занимающиеся машинным обучением, тратят больше 80% своего времени на улучшение тренировочных данных.
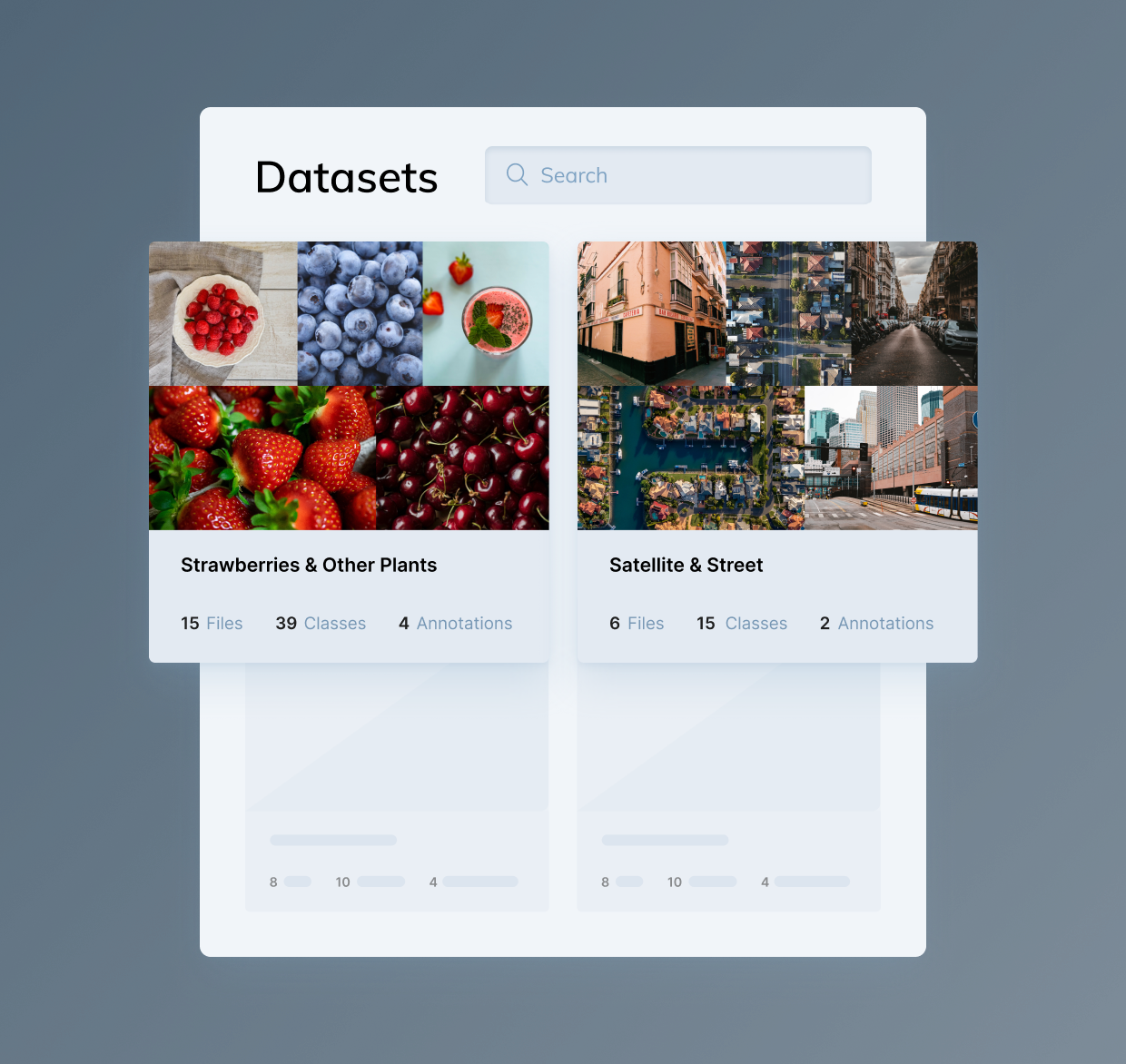
Точность ИИ-модели напрямую зависит от качества данных для обучения.
Современные глубокие нейронные сети во время обучения оптимизируют миллиарды параметров.
Но если ваши данные плохо размечены, это выльется в миллиарды ошибочно обученных признаков и многие часы потраченного впустую времени.
Мы не хотим, чтобы такое случилось с вами. В своей статье мы представим лучшие советы и хитрости для улучшения качества вашего датасета.
Под данными для обучения понимается исходный набор данных, передаваемый модели машинного обучения, на котором обучается модель.
Люди лучше всего учатся на примерах, и машинам тоже нужен набор данных, чтобы узнавать из него паттерны.
В большинстве случаев данные обучения содержат пары «входящие данные: аннотация», собранные из различных источников, которые используются для обучения модели выполнению конкретной задачи с высоким уровнем точности.
Они могут состоять из сырых данных (изображений, текстов или звука), содержащих аннотации, например, ограничивающие прямоугольники, метки или связи.
Модели машинного обучения изучают аннотации данных обучения, чтобы в будущем обрабатывать новые, неразмеченные данные.
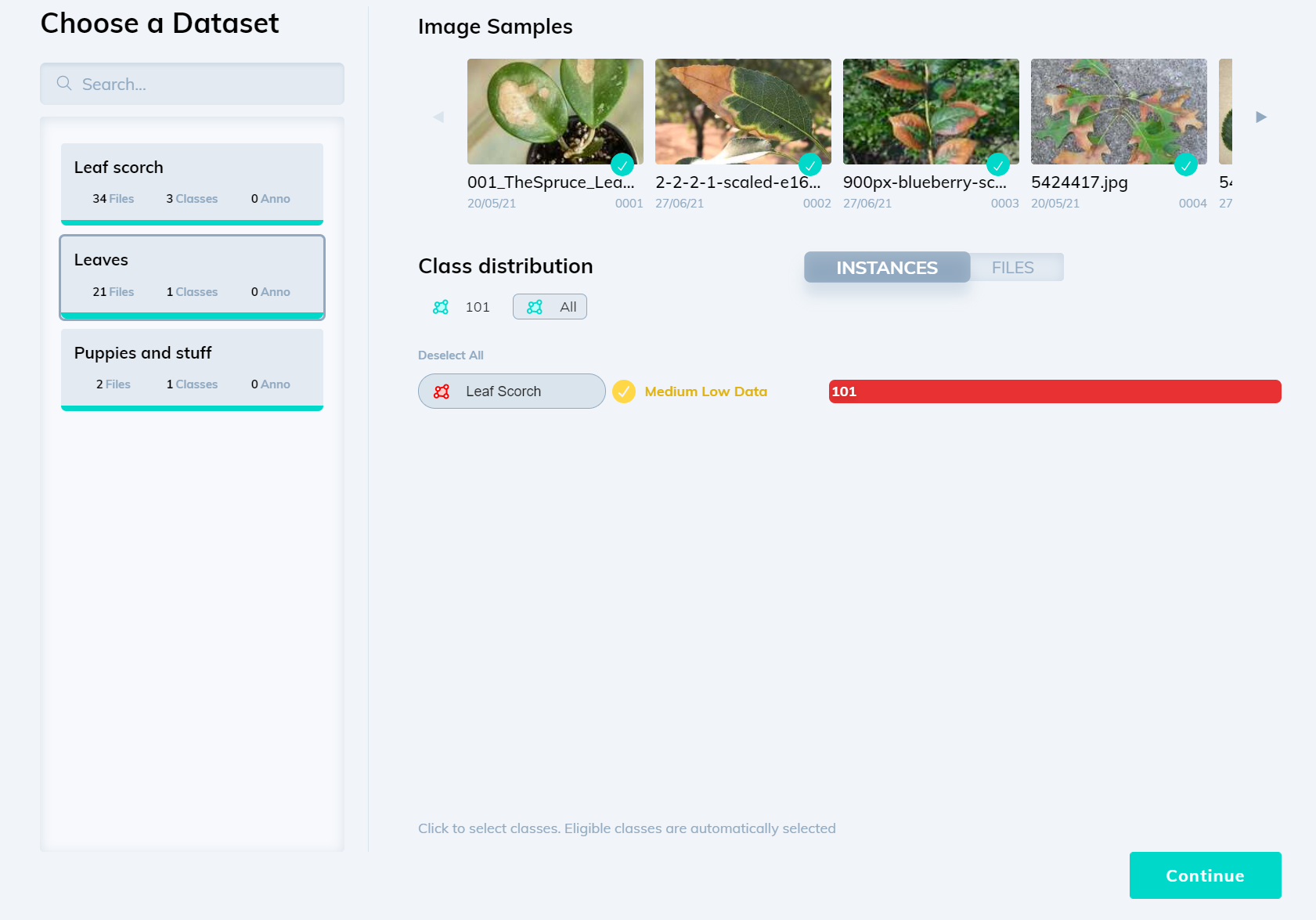
В чём разница датасета для контролируемого и неконтролируемого обучения?
При контролируемом обучении люди размечают данные и сообщают модели именно то, что ей нужно найти.
Например, в сфере распознавания спама входящими данными является любой текст, а метка даёт понять, является ли сообщение спамом.
Контролируемое обучение строже, потому что мы не позволяем модели делать собственные выводы на основе данных вне пределов, аннотированных нашими метками.
При неконтролируемом обучении люди передают модели сырые данные без меток, а модель находит в данных паттерны. Например, распознавая уровень схожести или различия двух примеров данных на основании общих извлечённых признаков.
Это помогает модели делать заключения и приходить к выводам, например, разделять похожие изображения или объединять их в кластеры.

Обучение с частичным контролем (semi-supervised learning) — это сочетание двух вышеперечисленных типов: данные частично размечаются людьми, а часть прогнозов оставляют на усмотрение модели.
Обучение с частичным контролем часто используется, когда люди могут направить модель в нужном направлении работы, но сами прогнозы становится сложно аннотировать из-за слишком большого количества нюансов.
В реальности нет такого понятия, как полностью контролируемое или неконтролируемое обучение, существуют только различные степени контроля.
Все методики обучения начинаются со сбора сырых данных из различных источников.
Сырые данные могут иметь любой вид: текст, изображения, звуки, видео и т.д. Однако чтобы сообщить модели, что необходимо находить в этих данных, вы должны добавить аннотации.
Эти аннотации позволяют контролировать обучение, гарантировав, что модель сфокусируется на указанных вами признаках, а не будет экстраполировать выводы из других коррелированных (но не обусловленных) элементов данных.

Все входящие данные должны иметь соответствующую метку, позволяющую машине двигаться в направлении того, как должен выглядеть прогноз. Такой обработанный набор данных можно получить при помощи людей, а иногда и других моделей ML, достаточно точных для надёжного проставления меток.
После того, как размеченный набор данных готов к передаче ИИ, начинается этап обучения.
На нём модель пытается выявить важные признаки, общие для всех примеров, которым вы назначили метки. Например, если вы сегментировали несколько легковых автомобилей на снимках, то она поймёт, что колёса, зеркала заднего вида и ручки дверей являются признаками, коррелирующими с легковым автомобилем.
Модели непрерывно тестируют сами себя на наборе данных валидации, подготовленном перед этапом обучения.
После завершения модели выполняют последнюю проверку на тестовом датасете (наборе, который модель ранее никогда не видела); это даёт нам понимание о качестве работы модели на релевантных новых примерах.
Наборы данных для обучения, валидации и тестирования являются частями данных обучения. Чем больше данных обучения у вас есть, тем выше точность модели.
Теперь давайте дадим определения некоторым популярным терминам, которые вы можете встретить при работе с датасетами.
Размеченные данные — это данные, дополненные метками/классами, содержащими значимую информацию.
Вот несколько примеров размеченных данных: изображения с меткой «кошка»/«собака», электронные письма/сообщения, размеченные как спам, прогнозы цен фондовых рынков (меткой является состояние в будущем), определение злокачественности узелков с их выделением многоугольником, аудиофайлы с информацией о том, какие слова в них произнесены.
Точно размеченные данные позволяют машине распознавать паттерны в соответствии с задачей, поэтому они широко используются в решении сложных задач.
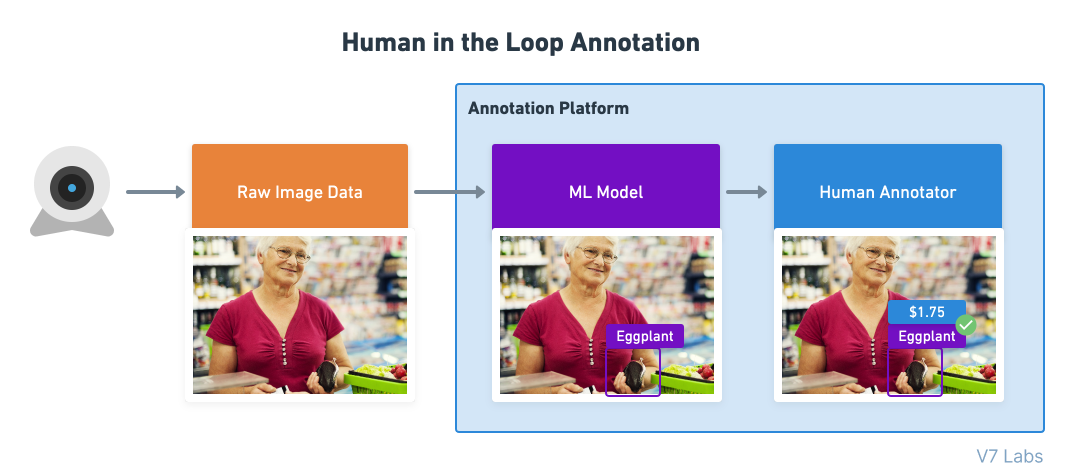
Процесс «оператор в контуре управления» (human in the loop, HITL) используется тогда, когда модель только частично способна решить задачу, и часть работы передаётся живому человеку.
Примером human in the loop является разметка данных при помощи модели, когда модель ML создаёт первоначальные прогнозы, а человек дополняет их метками, исправлениями или другими типами аннотаций, не поддерживаемыми моделью.
Люди обеспечивают непрерывную обратную связь, улучшающую качество работы модели.
Обычно люди используют инструменты аннотирования для разметки сырых данных, чтобы помочь машинам обучаться и делать прогнозы. Они валидируют полученные моделью результаты и проверяют прогнозы, когда машина не уверена в своих результатах, чтобы убедиться, что обучение модели происходит в нужном направлении.
Однако иногда люди постоянно остаются в контуре управления, добавляя в данные новые метки, создание которых нельзя полностью доверить моделям.
Например, во многих автоматизированных системах медицинской диагностики или системах идентификации личности задействуются операторы в контуре управления, чтобы не оставлять на долю алгоритмов машинного обучения выбор окончательного важного решения.
В этом контуре машины и люди работают рука об руку!
Ни одну ИИ-модель невозможно обучить и протестировать на одних и тех же данных.
Почему? Всё просто — оценка модели будет смещенной, потому что модель тестируется на том, что она уже знает. Это аналогично тому, как если бы мы давали на экзамене студентам те же вопросы, на которые они уже ответили в классе. Так мы не узнаем, запомнил ли студент ответы или действительно понял тему.
Те же правила применимы и к моделям машинного обучения.
Вот их процентные соотношения объёмов данных:

Данные обучения (Training data) — не менее 60% данных должно использоваться для обучения.
Данные валидации (Validation data) — выборка (10-20%) из общего набора данных, используемая для валидации и периодически проверяемая на модели во время обучения. Этот набор данных валидации должен представлять собой репрезентативную выборку из набора данных обучения.
Данные тестирования (Test data) — этот набор данных используется для тестирования модели после её полного обучения. Он отделяется и от набора обучения, и от набора валидации. После обучения и валидации модель тестируется на наборе тестирования. Данные в наборе тестирования должны выглядеть точно так же, как будут выглядеть реальные данные после развёртывания модели.
В общем наборе данных может быть несколько наборов тестирования.
Каждый набор тестирования можно использовать для проверки того, достаточно ли модель обучилась для конкретного сценария применения. Например, модель беспилотного вождения, наученная распознавать пешеходов, может обучаться на видео, снятом по всей территории США.

Её основной набор тестирования может состоять из перемешанных данных всех штатов страны, однако вам может потребоваться создать отдельные наборы тестирования для конкретных сценариев. Например:
Эти наборы тестирования обычно хранятся в системе управления наборами данных и вручную подбираются дата-саентистами. Поэтому они являются свидетельством того, что вы полностью понимаете, как выглядят ваши данные и что вы соответствующим образом пометили все краевые сценарии, чтобы из них можно было создавать наборы тестирования.
Наборы тестирования используются не только для оценки качества работы ИИ-моделей. Иногда они применяются для тестирования качества работы и живых аннотаторов.
Такие наборы называются «золотыми наборами» (Gold Set).
Выборка тщательно размеченных изображений, точно описывающих то, как выглядит эталонно верная разметка, называется gold set.
Эти наборы изображений используются как уменьшенные наборы тестирования для живых аннотаторов, или как часть вводного обучения, или их примешивают к задачам разметки, чтобы убедиться, что качество работы аннотатора не ухудшается из-за его плохой работы или из-за изменения инструкций.
Gold sets обычно позволяют проверять следующие аспекты:
Слепые этапы — это задачи аннотирования, при которых несколько людей (или моделей) присваивают метки независимо друг от друга; при этом этап считается пройденным, только если все они сойдутся на одном результате.
Слепые этапы используются для создания сверхточных данных обучения и автоматизации проверок контроля качества. Аннотаторы очень часто пропускают объекты, но двое или несколько аннотаторов пропустят один и тот же объект с меньшей вероятностью.
Разметка на слепых этапах выполняется параллельно и каждый участник не может видеть прогресс остальных.
Когда все аннотаторы завершат свою версию задания, оно проходит через проверку консенсусом, валидирующую, что аннотаторы сошлись на одном решении. Если это не так или если решения недостаточно совпадают друг с другом пространственно, то задача передаётся живому контролёру, которые вносит исправления; при этом совершивший ошибку аннотатор уведомляется, чтобы он мог улучшить свою работу.

Простой ответ: чтобы на каждый возможный класс из вашего сценария было не менее чем 1000 обучающих примеров.
Почему 1000? Если вы используете 10% данных в качестве набора тестирования, то сможете определить точность класса с погрешностью по крайней мере в 1%.
Для справки:
1000 примеров — это достаточный набор данных.
10000 — отличный набор данных.
100 тысяч-1 миллион — превосходный набор данных.
Если у вас есть 1 миллион размеченных примеров каких-нибудь данных, то вы будете одним из лидеров среди команд разработчиков ИИ.
Некоторые компании сегодня обучают модели на миллиардах изображений, видео и аудиосэмплов. Эти наборы данных имеют множество наборов тестирования и многократно размечены для увеличения масштабов задач.
Да, теоретически вы можете обучить модель на 100 примерах каких-то данных. Например, V7 позволяет обучить модель всего на 100 примерах, однако на новых примерах качество будет довольно низким.
Высококачественные модели обучаются на больших объёмах данных обучения, и на то есть причины — современные архитектуры нейронных сетей великолепно работают, потому что способны эффективно хранить множество весов (параметров). Однако если у вас мало данных обучения, то вы сможете использовать только долю потенциала своей модели.
Размер набора данных также зависит от области вашей задачи и дисперсии каждого класса.
Если вы планируете распознать каждый батончик Mars в мире, то дисперсия исчерпается после 10000 примеров. Модель научится каждому возможному углу, типу освещения и степени помятости упаковки.
Однако если вам требуется обобщённый распознаватель людей, то набор из 10000 сэмплов будет только небольшой частью вариаций размеров, поз и типов внешностей и одежды. Поэтому для класса с высокой дисперсией, например, «человек», требуется гораздо больше данных обучения.
Вот некоторые из факторов, сильно влияющих на размер финального датасета:
Сколько данных уже есть в системе?
Если сырые данные отсутствуют, то обеспечьте возможность их сбора в том масштабе, который необходим в вашем случае. Например, если вы работаете на логистическую компанию, обрабатывающую по 10000 счетов в день, то это хороший показатель того, каким должен быть набор данных тестирования, то есть набор данных обучения должен состоять не менее чем из 100000 файлов, чтобы можно было точно сравнивать его с качеством работы человека.
Насколько разрежена репрезентация меток, которые вам нужно распознавать?
Если ваша цель заключается в распознавании очень равномерного набора объектов, то вы можете обойтись несколькими тысячами примеров. Если вам нужно идентифицировать что-то разнообразное, например, автомобильные номера всех стран при различных погодных и световых условиях, то для достижения надёжных результатов ваш набор данных должен содержать несколько сотен примеров каждого возможного сценария. Количество классов пропорционально увеличивает требования к размеру наборов данных.
Вы выполняете распознавание объектов или семантическую сегментацию?
Каждый тип задачи классификации требует своего количества данных обучения. В задачах распознавания объектов необходимо вычислить количество ожидаемых экземпляров объектов. Если вы ожидаете только одного объекта на файл, то будете обучать модель чуть медленнее, чем при 4-5 объектах.
Будет ли ваше распределение (содержимое того, что должен представлять собой набор данных) меняться со временем?
Например, если вы создаёте распознаватель мобильных телефонов, то вам придётся периодически добавлять новые данные обучения для учёта новых моделей. Если вы делаете распознаватель лиц, то нужно учесть использование масок.
Инструменты тоже меняются со временем — камеры современных телефонов делают HDR-снимки в высоком разрешении, и модели, обученные на таких данных, будут работать качественнее.
Чем больше весов в вашей модели, тем больше требуется данных обучения.
Другими словами, с увеличением сложности модели растёт и необходимый размер датасета. Современные глубокие нейронные сети могут хранить миллионы или даже миллиарды параметров. Следовательно, сложность модели почти никогда не является узким местом — всегда стремитесь к увеличению объёмов данных обучения, чтобы улучшить качество работы вашей модели.
Если вы используете классическое машинное обучение или работаете на устройствах с ограниченными ресурсами, то выгода от многомилионных наборов данных будет минимальной.
Приблизительного вычисления количества необходимых данных более чем достаточно для начала работы. Вот пара способов, которые помогут в этом:
Это самый распространённый из способов примерной оценки.
Это правило гласит, что модель требует в десять раз больше данных, чем у неё есть степеней свободы. Под степенью свободы понимается любой параметр, влияющий на модель, или любой атрибут, от которого зависят выходные данные модели.
Это более логичный подход, построенный на опыте.
Кривая обучения демонстрирует взаимосвязь между качеством работы модели машинного обучения и размером датасета. Мы создаём график результатов работы модели в зависимости от увеличения размера набора данных на каждой итерации.
Вот пороговый размер набора данных, после которого качество работы модели начинает стагнировать или уменьшаться.

Высокое качество разметки датасета необходимо для точной работы модели машинного обучения.
Под термином «качественные данные» подразумеваются очищенные данные, содержащие все атрибуты, от которых зависит обучение модели.
Мы можем замерить качество по постоянству и точности размеченных данных.
Давайте рассмотрим этот аспект подробнее, чтобы понять, как гарантировать качество данных.
Есть три основных фактора, непосредственно влияющих на качество данных обучения.
Люди, процесс и инструменты (People, Process, Tool, P-P-T) — вот три компонента, жизненно необходимые любому бизнес-процессу.
Давайте рассмотрим каждый из них.
Качество начинается с человеческих ресурсов, которым дали задачу разметки. Выбор и обучение работников существенно влияют на эффективность работы и окончательные результаты. Обучение под конкретную задачу — ключ к повышению качества данных.
Это последовательность действий, которые работники выполняют для сбора и разметки данных, за которыми следует процесс контроля качества.
Многие платформы предоставляют компаниям инструменты, помогающие людям в реализации процесса. Также они автоматизируют некоторые части процесса для максимизации качества данных.

Теперь давайте рассмотрим рекомендации по подготовке данных обучения.
Сырые данные могут быть очень грязными и повреждёнными во многих смыслах. При отсутствии надлежащей очистки они могут искажать результаты и заставить ИИ-модель создавать ошибочные результаты.
Очистка данных — это процесс исправления или удаления неправильных, повреждённых, дублированных данных в пределах набора данных. Этапы процесса очистки данных зависят от конкретного набора данных.
Рекомендации:
Разметка данных — это процесс, в котором мы присваиваем данным значение в виде класса или метки.
Разметку данных могут выполнять сотрудники, операторы в контуре управления или любые автоматизированные машины, ускоряющие процесс разметки.
Рекомендации:
Теперь давайте поговорим о том, где мы можем найти релевантные данные для наших проектов data science и глубокого обучения.
Если вы ищете качественные данных для своих бизнес-процессов или хотите построить свою первую модель компьютерного зрения, критически важно иметь доступ к качественным наборам данных.
Вот несколько способов, которые можно применить для их получения.
Первый метод — исследование таких вариантов, как открытые наборы данных, онлайн-форумы по машинному обучению и поисковые движки наборов данных, которые бесплатны и относительно просты в работе. Существует множество веб-сайтов, предоставляющих доступ к разнообразным бесплатным наборам данных, например, Google Dataset Search, Kaggle, Reddit, репозиторий UCI. Необходимо будет только предварительно обработать данные, чтобы они подходили конкретно к вашей задаче.
Этот метод в основном используется в случаях, когда в качестве разнообразных входящих данных нам нужны данные из множества источников. Сбор данных выполняется извлечением данных из различных публичных онлайн-ресурсов, например, правительственных веб-сайтов или соцсетей.
Иногда вышеперечисленные варианты не очень хорошо подходят для сбора датесета.
В этом случае необходимо рассмотреть возможные варианты, реализуемые внутри компании. Например, если вы работаете над чат-ботом, предназначенным для ответа на вопросы студентов, вместо использования наборов данных NLP можно попробовать извлечь данные из бесед научных руководителей и студентов, если логи и сообщения где-то хранятся.
В некоторых случаях мы не можем собрать данные, соответствующие нашим потребностям.
Вместо этого можно чуть-чуть изменить данные, чтобы расширить набор данных. Под расширением данных (data augmentation) подразумевается применение различных преобразований к исходным данным для генерации новых данных, соответствующих требованиям. Например, в случае работы с изображениями размер датасета можно увеличить такими простыми операциями, как поворот, изменение цвета, яркости и т.д.
В конце давайте повторим всё то, что мы узнали из этого руководства по качественным данным обучения:
Точность ИИ-модели напрямую зависит от качества данных для обучения.
Современные глубокие нейронные сети во время обучения оптимизируют миллиарды параметров.
Но если ваши данные плохо размечены, это выльется в миллиарды ошибочно обученных признаков и многие часы потраченного впустую времени.
Мы не хотим, чтобы такое случилось с вами. В своей статье мы представим лучшие советы и хитрости для улучшения качества вашего датасета.
Что такое данные для обучения ИИ?
Под данными для обучения понимается исходный набор данных, передаваемый модели машинного обучения, на котором обучается модель.
Люди лучше всего учатся на примерах, и машинам тоже нужен набор данных, чтобы узнавать из него паттерны.
Данные обучения — это данные, которые мы используем для обучения алгоритма машинного обучения.
В большинстве случаев данные обучения содержат пары «входящие данные: аннотация», собранные из различных источников, которые используются для обучения модели выполнению конкретной задачи с высоким уровнем точности.
Они могут состоять из сырых данных (изображений, текстов или звука), содержащих аннотации, например, ограничивающие прямоугольники, метки или связи.
Модели машинного обучения изучают аннотации данных обучения, чтобы в будущем обрабатывать новые, неразмеченные данные.
Данные обучения при контролируемом и неконтролируемом обучении
В чём разница датасета для контролируемого и неконтролируемого обучения?
При контролируемом обучении люди размечают данные и сообщают модели именно то, что ей нужно найти.
Например, в сфере распознавания спама входящими данными является любой текст, а метка даёт понять, является ли сообщение спамом.
Контролируемое обучение строже, потому что мы не позволяем модели делать собственные выводы на основе данных вне пределов, аннотированных нашими метками.
При неконтролируемом обучении люди передают модели сырые данные без меток, а модель находит в данных паттерны. Например, распознавая уровень схожести или различия двух примеров данных на основании общих извлечённых признаков.
Это помогает модели делать заключения и приходить к выводам, например, разделять похожие изображения или объединять их в кластеры.
Обучение с частичным контролем (semi-supervised learning) — это сочетание двух вышеперечисленных типов: данные частично размечаются людьми, а часть прогнозов оставляют на усмотрение модели.
Обучение с частичным контролем часто используется, когда люди могут направить модель в нужном направлении работы, но сами прогнозы становится сложно аннотировать из-за слишком большого количества нюансов.
В реальности нет такого понятия, как полностью контролируемое или неконтролируемое обучение, существуют только различные степени контроля.
Контролируемое обучение: процесс работы с данными обучения
Все методики обучения начинаются со сбора сырых данных из различных источников.
Сырые данные могут иметь любой вид: текст, изображения, звуки, видео и т.д. Однако чтобы сообщить модели, что необходимо находить в этих данных, вы должны добавить аннотации.
Эти аннотации позволяют контролировать обучение, гарантировав, что модель сфокусируется на указанных вами признаках, а не будет экстраполировать выводы из других коррелированных (но не обусловленных) элементов данных.
Все входящие данные должны иметь соответствующую метку, позволяющую машине двигаться в направлении того, как должен выглядеть прогноз. Такой обработанный набор данных можно получить при помощи людей, а иногда и других моделей ML, достаточно точных для надёжного проставления меток.
После того, как размеченный набор данных готов к передаче ИИ, начинается этап обучения.
На нём модель пытается выявить важные признаки, общие для всех примеров, которым вы назначили метки. Например, если вы сегментировали несколько легковых автомобилей на снимках, то она поймёт, что колёса, зеркала заднего вида и ручки дверей являются признаками, коррелирующими с легковым автомобилем.
Модели непрерывно тестируют сами себя на наборе данных валидации, подготовленном перед этапом обучения.
После завершения модели выполняют последнюю проверку на тестовом датасете (наборе, который модель ранее никогда не видела); это даёт нам понимание о качестве работы модели на релевантных новых примерах.
Наборы данных для обучения, валидации и тестирования являются частями данных обучения. Чем больше данных обучения у вас есть, тем выше точность модели.
Теперь давайте дадим определения некоторым популярным терминам, которые вы можете встретить при работе с датасетами.
Что такое размеченные данные?
Размеченные данные — это данные, дополненные метками/классами, содержащими значимую информацию.
Вот несколько примеров размеченных данных: изображения с меткой «кошка»/«собака», электронные письма/сообщения, размеченные как спам, прогнозы цен фондовых рынков (меткой является состояние в будущем), определение злокачественности узелков с их выделением многоугольником, аудиофайлы с информацией о том, какие слова в них произнесены.
Точно размеченные данные позволяют машине распознавать паттерны в соответствии с задачей, поэтому они широко используются в решении сложных задач.
Кто такой оператор в контуре управления?
Процесс «оператор в контуре управления» (human in the loop, HITL) используется тогда, когда модель только частично способна решить задачу, и часть работы передаётся живому человеку.
Примером human in the loop является разметка данных при помощи модели, когда модель ML создаёт первоначальные прогнозы, а человек дополняет их метками, исправлениями или другими типами аннотаций, не поддерживаемыми моделью.
Люди обеспечивают непрерывную обратную связь, улучшающую качество работы модели.
Обычно люди используют инструменты аннотирования для разметки сырых данных, чтобы помочь машинам обучаться и делать прогнозы. Они валидируют полученные моделью результаты и проверяют прогнозы, когда машина не уверена в своих результатах, чтобы убедиться, что обучение модели происходит в нужном направлении.
Однако иногда люди постоянно остаются в контуре управления, добавляя в данные новые метки, создание которых нельзя полностью доверить моделям.
Например, во многих автоматизированных системах медицинской диагностики или системах идентификации личности задействуются операторы в контуре управления, чтобы не оставлять на долю алгоритмов машинного обучения выбор окончательного важного решения.
В этом контуре машины и люди работают рука об руку!
Датасеты для обучения, валидации и тестирования
Ни одну ИИ-модель невозможно обучить и протестировать на одних и тех же данных.
Почему? Всё просто — оценка модели будет смещенной, потому что модель тестируется на том, что она уже знает. Это аналогично тому, как если бы мы давали на экзамене студентам те же вопросы, на которые они уже ответили в классе. Так мы не узнаем, запомнил ли студент ответы или действительно понял тему.
Те же правила применимы и к моделям машинного обучения.
Вот их процентные соотношения объёмов данных:
Данные обучения (Training data) — не менее 60% данных должно использоваться для обучения.
Данные валидации (Validation data) — выборка (10-20%) из общего набора данных, используемая для валидации и периодически проверяемая на модели во время обучения. Этот набор данных валидации должен представлять собой репрезентативную выборку из набора данных обучения.
Данные тестирования (Test data) — этот набор данных используется для тестирования модели после её полного обучения. Он отделяется и от набора обучения, и от набора валидации. После обучения и валидации модель тестируется на наборе тестирования. Данные в наборе тестирования должны выглядеть точно так же, как будут выглядеть реальные данные после развёртывания модели.
В общем наборе данных может быть несколько наборов тестирования.
Каждый набор тестирования можно использовать для проверки того, достаточно ли модель обучилась для конкретного сценария применения. Например, модель беспилотного вождения, наученная распознавать пешеходов, может обучаться на видео, снятом по всей территории США.
Её основной набор тестирования может состоять из перемешанных данных всех штатов страны, однако вам может потребоваться создать отдельные наборы тестирования для конкретных сценариев. Например:
- Набор тестирования для вождения на закате
- Набор тестирования для снежного климата
- Набор тестирования для вождения в сильные бури
- Набор тестирования для ситуаций, когда объектив камеры загрязнился или поцарапан.
Эти наборы тестирования обычно хранятся в системе управления наборами данных и вручную подбираются дата-саентистами. Поэтому они являются свидетельством того, что вы полностью понимаете, как выглядят ваши данные и что вы соответствующим образом пометили все краевые сценарии, чтобы из них можно было создавать наборы тестирования.
Наборы тестирования используются не только для оценки качества работы ИИ-моделей. Иногда они применяются для тестирования качества работы и живых аннотаторов.
Такие наборы называются «золотыми наборами» (Gold Set).
Gold Set — идеальный золотой стандарт
Выборка тщательно размеченных изображений, точно описывающих то, как выглядит эталонно верная разметка, называется gold set.
Эти наборы изображений используются как уменьшенные наборы тестирования для живых аннотаторов, или как часть вводного обучения, или их примешивают к задачам разметки, чтобы убедиться, что качество работы аннотатора не ухудшается из-за его плохой работы или из-за изменения инструкций.
Gold sets обычно позволяют проверять следующие аспекты:
- Время выполнения задачи.
- Точность каждой аннотации
- Рост качества работы с повышением опыта
- Ухудшение качества работы после изменения инструкций
Слепые этапы — несколько проходов, выполняемых разными аннотаторами
Слепые этапы — это задачи аннотирования, при которых несколько людей (или моделей) присваивают метки независимо друг от друга; при этом этап считается пройденным, только если все они сойдутся на одном результате.
Слепые этапы используются для создания сверхточных данных обучения и автоматизации проверок контроля качества. Аннотаторы очень часто пропускают объекты, но двое или несколько аннотаторов пропустят один и тот же объект с меньшей вероятностью.
Разметка на слепых этапах выполняется параллельно и каждый участник не может видеть прогресс остальных.
Когда все аннотаторы завершат свою версию задания, оно проходит через проверку консенсусом, валидирующую, что аннотаторы сошлись на одном решении. Если это не так или если решения недостаточно совпадают друг с другом пространственно, то задача передаётся живому контролёру, которые вносит исправления; при этом совершивший ошибку аннотатор уведомляется, чтобы он мог улучшить свою работу.
Какой объём данных обучения вам нужен?
Простой ответ: чтобы на каждый возможный класс из вашего сценария было не менее чем 1000 обучающих примеров.
Почему 1000? Если вы используете 10% данных в качестве набора тестирования, то сможете определить точность класса с погрешностью по крайней мере в 1%.
Для справки:
1000 примеров — это достаточный набор данных.
10000 — отличный набор данных.
100 тысяч-1 миллион — превосходный набор данных.
Если у вас есть 1 миллион размеченных примеров каких-нибудь данных, то вы будете одним из лидеров среди команд разработчиков ИИ.
Некоторые компании сегодня обучают модели на миллиардах изображений, видео и аудиосэмплов. Эти наборы данных имеют множество наборов тестирования и многократно размечены для увеличения масштабов задач.
Да, теоретически вы можете обучить модель на 100 примерах каких-то данных. Например, V7 позволяет обучить модель всего на 100 примерах, однако на новых примерах качество будет довольно низким.
Высококачественные модели обучаются на больших объёмах данных обучения, и на то есть причины — современные архитектуры нейронных сетей великолепно работают, потому что способны эффективно хранить множество весов (параметров). Однако если у вас мало данных обучения, то вы сможете использовать только долю потенциала своей модели.
Размер набора данных также зависит от области вашей задачи и дисперсии каждого класса.
Если вы планируете распознать каждый батончик Mars в мире, то дисперсия исчерпается после 10000 примеров. Модель научится каждому возможному углу, типу освещения и степени помятости упаковки.
Однако если вам требуется обобщённый распознаватель людей, то набор из 10000 сэмплов будет только небольшой частью вариаций размеров, поз и типов внешностей и одежды. Поэтому для класса с высокой дисперсией, например, «человек», требуется гораздо больше данных обучения.
Пять сложных аспектов в вычислении количества данных обучения
Вот некоторые из факторов, сильно влияющих на размер финального датасета:
Размер имеющегося корпуса сырых данных
Сколько данных уже есть в системе?
Если сырые данные отсутствуют, то обеспечьте возможность их сбора в том масштабе, который необходим в вашем случае. Например, если вы работаете на логистическую компанию, обрабатывающую по 10000 счетов в день, то это хороший показатель того, каким должен быть набор данных тестирования, то есть набор данных обучения должен состоять не менее чем из 100000 файлов, чтобы можно было точно сравнивать его с качеством работы человека.
Дисперсия классов
Насколько разрежена репрезентация меток, которые вам нужно распознавать?
Если ваша цель заключается в распознавании очень равномерного набора объектов, то вы можете обойтись несколькими тысячами примеров. Если вам нужно идентифицировать что-то разнообразное, например, автомобильные номера всех стран при различных погодных и световых условиях, то для достижения надёжных результатов ваш набор данных должен содержать несколько сотен примеров каждого возможного сценария. Количество классов пропорционально увеличивает требования к размеру наборов данных.
Тип классификации
Вы выполняете распознавание объектов или семантическую сегментацию?
Каждый тип задачи классификации требует своего количества данных обучения. В задачах распознавания объектов необходимо вычислить количество ожидаемых экземпляров объектов. Если вы ожидаете только одного объекта на файл, то будете обучать модель чуть медленнее, чем при 4-5 объектах.
Текущие изменения
Будет ли ваше распределение (содержимое того, что должен представлять собой набор данных) меняться со временем?
Например, если вы создаёте распознаватель мобильных телефонов, то вам придётся периодически добавлять новые данные обучения для учёта новых моделей. Если вы делаете распознаватель лиц, то нужно учесть использование масок.
Инструменты тоже меняются со временем — камеры современных телефонов делают HDR-снимки в высоком разрешении, и модели, обученные на таких данных, будут работать качественнее.
Сложность вашей модели
Чем больше весов в вашей модели, тем больше требуется данных обучения.
Другими словами, с увеличением сложности модели растёт и необходимый размер датасета. Современные глубокие нейронные сети могут хранить миллионы или даже миллиарды параметров. Следовательно, сложность модели почти никогда не является узким местом — всегда стремитесь к увеличению объёмов данных обучения, чтобы улучшить качество работы вашей модели.
Если вы используете классическое машинное обучение или работаете на устройствах с ограниченными ресурсами, то выгода от многомилионных наборов данных будет минимальной.
Как вычислить необходимое количество данных для обучения?
Приблизительного вычисления количества необходимых данных более чем достаточно для начала работы. Вот пара способов, которые помогут в этом:
Правило десяток
Это самый распространённый из способов примерной оценки.
Это правило гласит, что модель требует в десять раз больше данных, чем у неё есть степеней свободы. Под степенью свободы понимается любой параметр, влияющий на модель, или любой атрибут, от которого зависят выходные данные модели.
Кривые обучения
Это более логичный подход, построенный на опыте.
Кривая обучения демонстрирует взаимосвязь между качеством работы модели машинного обучения и размером датасета. Мы создаём график результатов работы модели в зависимости от увеличения размера набора данных на каждой итерации.
Вот пороговый размер набора данных, после которого качество работы модели начинает стагнировать или уменьшаться.
Как повысить качество данных для обучения ИИ?
Высокое качество разметки датасета необходимо для точной работы модели машинного обучения.
Под термином «качественные данные» подразумеваются очищенные данные, содержащие все атрибуты, от которых зависит обучение модели.
Мы можем замерить качество по постоянству и точности размеченных данных.
Давайте рассмотрим этот аспект подробнее, чтобы понять, как гарантировать качество данных.
4 характеристики качественных данных для обучения ML моделей
- Релевантность (relevancy) — набор данных должен содержать только те признаки, которые предоставляют модели значимую информацию. Выявление важных признаков — сложная задача, требующая знания области и чёткого понимания того, какие признаки стоит учитывать, а какие нужно устранить.
- Постоянство (consistency) — схожие примеры должны иметь схожие метки, обеспечивая однородность набора данных.
- Однородность (uniformity) — значения всех атрибутов должны быть сравнимыми для всех данных. Неравномерности или наличие выбросов в наборах данных отрицательно влияют на качество данных обучения.
- Полнота (comprehensiveness) — набор данных должен содержать достаточное количество параметров или признаков, чтобы не осталось неохваченных пограничных случаев. Набор данных должен содержать достаточно сэмплов этих пограничных случаев, чтобы модель могла обучиться и им.
Что влияет на качество данных обучения?
Есть три основных фактора, непосредственно влияющих на качество данных обучения.
Люди, процесс и инструменты (People, Process, Tool, P-P-T) — вот три компонента, жизненно необходимые любому бизнес-процессу.
Давайте рассмотрим каждый из них.
Люди
Качество начинается с человеческих ресурсов, которым дали задачу разметки. Выбор и обучение работников существенно влияют на эффективность работы и окончательные результаты. Обучение под конкретную задачу — ключ к повышению качества данных.
Процесс
Это последовательность действий, которые работники выполняют для сбора и разметки данных, за которыми следует процесс контроля качества.
Инструменты
Многие платформы предоставляют компаниям инструменты, помогающие людям в реализации процесса. Также они автоматизируют некоторые части процесса для максимизации качества данных.
Как подготовить данные обучения: рекомендации
Теперь давайте рассмотрим рекомендации по подготовке данных обучения.
Очистка данных
Сырые данные могут быть очень грязными и повреждёнными во многих смыслах. При отсутствии надлежащей очистки они могут искажать результаты и заставить ИИ-модель создавать ошибочные результаты.
Очистка данных — это процесс исправления или удаления неправильных, повреждённых, дублированных данных в пределах набора данных. Этапы процесса очистки данных зависят от конкретного набора данных.
Рекомендации:
- Проверяйте наличие дубликатов — в наборе данных может несколько раз присутствовать один и тот же пример данных. Это может быть вызвано сбором данных из разных источников, в результате чего в них оказываются схожие данные. Их необходимо удалить, поскольку они могут привести модель к переобучению на некоторые паттерны и созданию ложных прогнозов.
- Устраните выбросы — некоторые части данных ведут себя не так, как остальные данные. Примером может служить SessionID, постоянно встречающийся в данных weblog. Это может происходить из-за каких-то злонамеренных действий, которые не нужно передавать нашей модели. Поэтому слежение за выбросами — один из способов устранения данных, которые не должны передаваться машине.
- Исправьте структурные ошибки — в некоторых случаях в наборе данных может быть ошибочная разметка. Например, «Cat» и «cat» считаются различными классами, а «caat» и «cat» различаются из-за опечатки, приводящей к ошибочному распределению классов.
- Проверяйте отсутствующие значения — в наборе данных могут быть элементы, для примеров данных которых отсутствуют атрибуты/признаки. Решить эту проблему можно, просто не включив эти элементы в набор данных обучения.
Разметка данных
Разметка данных — это процесс, в котором мы присваиваем данным значение в виде класса или метки.
Разметку данных могут выполнять сотрудники, операторы в контуре управления или любые автоматизированные машины, ускоряющие процесс разметки.
Рекомендации:
- Создайте золотой стандарт — в сфере разметки данных дата-саентисты и специалисты считаются золотым стандартом, размечающим сырые данные с максимальной чувствительностью и точностью. Их разметка считается ориентиром для команды аннотаторов и может использоваться как ответы при скриннинге вариантов аннотаций.
- Не используйте слишком много меток — разделение набора данных на большое количество классов может запутывать сотрудников при его аннотировании. Кроме того, для выбора среди множества меток потребуется анализ большего количества признаков. Например, аннотаторам будет сложно размечать данные такими классами, как «Very Expensive», «Expensive», «Less Expensive».
- Используйте несколько проходов — разметка данных должна выполняться несколькими аннотаторами. Это необходимо для повышения общего качества данных. Хотя это требует больше времени и увеличивает затраты ресурсов, такой подход используется для установления консенсуса в команде.
- Создайте систему проверки — для снижения вероятности ошибок готовая разметка данных должна проверяться другим человеком или при помощи проверок самосовершенствования. Благодаря этому любой аннотатор сможет понять, в чём ему можно совершенствоваться, его уровень точности и вид обучения, необходимый для улучшения его работы.
Теперь давайте поговорим о том, где мы можем найти релевантные данные для наших проектов data science и глубокого обучения.
4 способа поиска высококачественных наборов данных обучения
Если вы ищете качественные данных для своих бизнес-процессов или хотите построить свою первую модель компьютерного зрения, критически важно иметь доступ к качественным наборам данных.
Вот несколько способов, которые можно применить для их получения.
Открытые наборы данных и поисковые движки
Первый метод — исследование таких вариантов, как открытые наборы данных, онлайн-форумы по машинному обучению и поисковые движки наборов данных, которые бесплатны и относительно просты в работе. Существует множество веб-сайтов, предоставляющих доступ к разнообразным бесплатным наборам данных, например, Google Dataset Search, Kaggle, Reddit, репозиторий UCI. Необходимо будет только предварительно обработать данные, чтобы они подходили конкретно к вашей задаче.
Скрейпинг веб-данных
Этот метод в основном используется в случаях, когда в качестве разнообразных входящих данных нам нужны данные из множества источников. Сбор данных выполняется извлечением данных из различных публичных онлайн-ресурсов, например, правительственных веб-сайтов или соцсетей.
Собственные данные
Иногда вышеперечисленные варианты не очень хорошо подходят для сбора датесета.
В этом случае необходимо рассмотреть возможные варианты, реализуемые внутри компании. Например, если вы работаете над чат-ботом, предназначенным для ответа на вопросы студентов, вместо использования наборов данных NLP можно попробовать извлечь данные из бесед научных руководителей и студентов, если логи и сообщения где-то хранятся.
Расширение данных
В некоторых случаях мы не можем собрать данные, соответствующие нашим потребностям.
Вместо этого можно чуть-чуть изменить данные, чтобы расширить набор данных. Под расширением данных (data augmentation) подразумевается применение различных преобразований к исходным данным для генерации новых данных, соответствующих требованиям. Например, в случае работы с изображениями размер датасета можно увеличить такими простыми операциями, как поворот, изменение цвета, яркости и т.д.
Качественные данные обучения: основные выводы
В конце давайте повторим всё то, что мы узнали из этого руководства по качественным данным обучения:
- Данными обучения называются данные, применяемые для тренировки алгоритма машинного обучения.
- Точность модели зависит от используемых данных — подавляющую часть времени дата-инженер занимается подготовкой качественных данных обучения.
- Контролируемое обучение использует размеченные данные, а неконтролируемое использует сырые, неразмеченные данные.
- Необходимы высококачественные наборы данных для обучения и валидации и отдельный независимый набор данных для тестирования.
- Золотой набор (gold set) — это выборка точно размеченных данных, идеально отображающая то, как должна выглядеть правильная разметка.
- Чтобы достичь качественных результатов, необходим существенный объём данных обучения для репрезентации всех возможных случаев с не менее чем 1000 сэмплов данных.
- 4 характеристики качественных данных обучения: релевантность содержимого, постоянство, однородность и полнота.
- Используемые вами инструменты очистки, разметки и аннотирования данных играют важнейшую роль в том, чтобы готовую модель можно было использовать в реальных условиях.
QtRoS
У supervised/unsгpervised learning есть устойявшийся перевод: обучение с учителем/без учителя.