
Предыдущая статья на тему выборов в государственную думу: «Восстанавливаем результаты выборов 2021 с помощью машинного обучения» вызвала интерес. Вместе с тем к статье было много критических комментариев. В некоторых из этих комментариев были подняты спорные вопросы, которые требовали дополнительных исследований. В целом было очень полезно обсудить результаты предыдущей работы с аудиторией Хабра. Поэтому я призываю оставлять читателей комментарии и под этой статьей.
Данное исследование основано на работах, выполненных электоральным аналитиком Сергеем Шпилькиным. Рекомендую посмотреть видео, где он подробно объясняет свою методологию:
Хотя это исследование и использует данные о выборах в государственную думу, эта статья не о политике. Эта статья о работе с открытыми данными. Она демонстрирует, как используя современные и доступные инструменты, такие как python, matplotlib, scikit-learn можно получить дополнительную информацию из этих данных. В данном исследовании используется примитивная модель и малое количество признаков, скорее для демонстрации подхода, чем для каких-либо громких заявлений. Весь исходный код и данные размещены на GitHub. Если у вас после прочтения статьи появятся новые идеи или замечания к коду, буду рад, если вы улучшите его с помощью своего кода. Или можете начать свой собственный проект на его основе.
Для начала опишем некоторые основные принципы проведения голосования в России, важные в контексте данной статьи. Выборы в нашей стране организует не государство, а независимые избирательные комиссии. Комиссии эти формируются из людей, которые имеют разнонаправленные интересы. Всего на выборах федерального уровня формируется примерно 96000 избирательных участков и соответственно комиссий. На участках среднего размера могут проголосовать 1000-2000 человек. В условиях города это 5-10 многоэтажных домов, расположенных вблизи здания, в котором организуют выборы. Вообще говоря, практически любой гражданин России может войти в состав комиссии и организовать выборы, например, по месту своего жительства.
Чьи интересы могут представлять члены избирательных комиссий? Во-первых, интересы различных политических партий, которые участвуют в выборах. Так, например в большом количестве комиссий можно обнаружить представителей двух крупнейших партий России на данный момент – «Единая Россия» и «КПРФ». Кроме того, там могут присутствовать и просто граждане, которые считают важной задачей организацию выборов высокого качества и готовые для этого пожертвовать существенным количеством личного времени. Существуют некоммерческие организации, которые пытаются координировать деятельность таких граждан. Например, общероссийское общественное движение в защиту прав избирателей "Голос", которое было признано иностранным агентом накануне выборов, в августе 2021 года.
В теории все эти разнонаправленные силы должны уравновешивать друг друга и обеспечивать качество проведения выборов. На многих участках именно так и происходит. Например, на абсолютном большинстве не электронных участков в Москве, это условие было выполнено на последних выборах и победу, с небольшим отрывом, одержала партия КПРФ.
Однако, чтобы группа людей покрыла своими представителями все участки, необходимо по крайней мере по три человека на участок. В условиях пандемии, сроки проведения голосования, были увеличены до трех дней, что фактически утроило количество необходимых человеко-часов. То есть каждую из сторон должны были представлять по 300000 человек, которые должны работать примерно по 30 часов каждый. То есть это около 9 млн человеко-часов. При средней зарплате в России в 350 рублей в час, в рублях это более 3-х миллиардов рублей. Ресурсы групп людей, которые организуют выборы не равны. Существует огромный перекос в сторону партии власти. Это понятно, даже если взглянуть на официальный бюджет партии Единая Россия за 2020 год. 9,6 млрд рублей у Единой России против 1,3 млрд у КПРФ. Только партия Единая Россия обладает достаточным бюджетом, чтобы покрыть все участки достаточным количеством своих представителей. Таким образом существуют участки, где выборы организуют представители только одной из заинтересованных сторон. Не удивительно, что на таких участках качество регистрации результатов может существенно снижаться.
Вероятно, этот изъян избирательной системы, можно было бы уменьшить с помощью оптимизации, как это сейчас происходит в сфере медицины. Можно было бы укрупнить участки и снизить их количество. Это бы позволило сбалансировать состав комиссий на большем количестве участков.
Другим решением проблемы могло бы стать электронное голосование в регионах страны с низкой плотностью населения. Как показало предыдущее исследование "Почему на удалении от крупных городов избиратели ходят на участки охотнее и голосуют за партию власти" именно в отдаленных от крупных городов районах качество регистрации результатов голосования снижается. Очень жаль, что реализация электронного голосования на последних выборах сильно дискредитировала саму идею такого проведения голосования. Фактически в данный момент электронное голосование и представляет из себя участки, в которых выборы организуют исключительно представители партии власти. Чтобы электронное голосование было сбалансированным это должен быть проект с открытым исходным кодом, в который могут вносить изменения все заинтересованный стороны. И, прежде чем его тестировать, нужно чтобы между сторонами был консенсус по поводу того, что работа этого кода не создает преимущества ни одной из сторон. Кроме того, код должен исполняться на вычислительных мощностях, подконтрольных каждой из заинтересованных сторон, а не на серверах, принадлежащих государственным структурам.
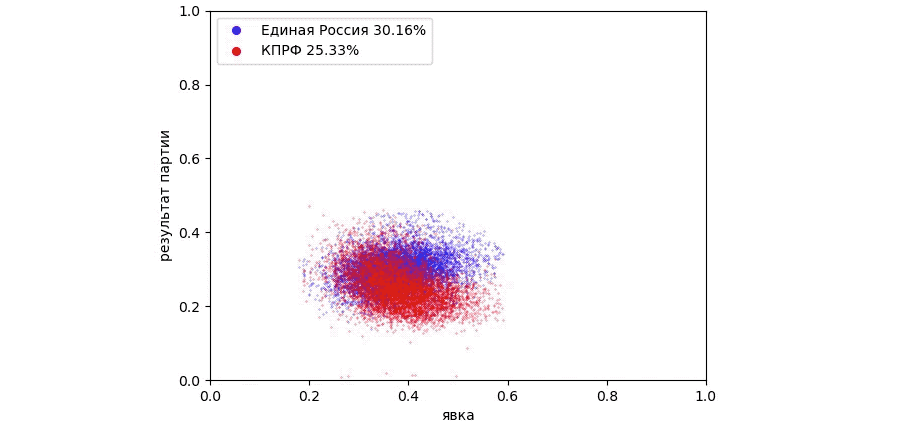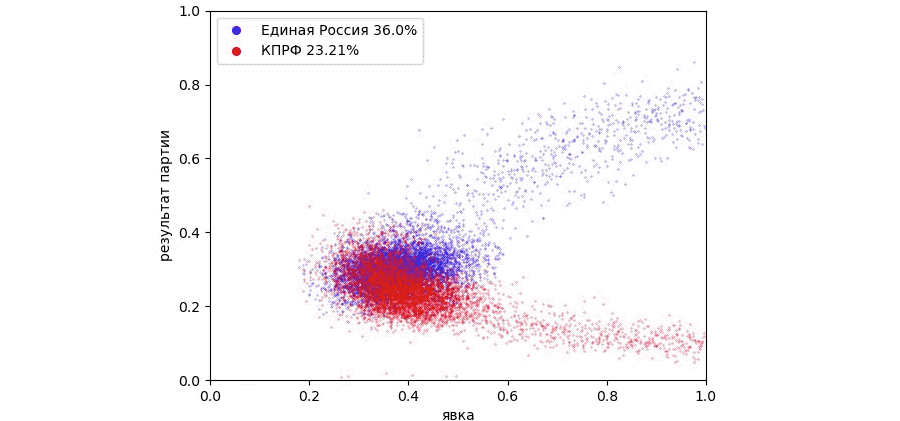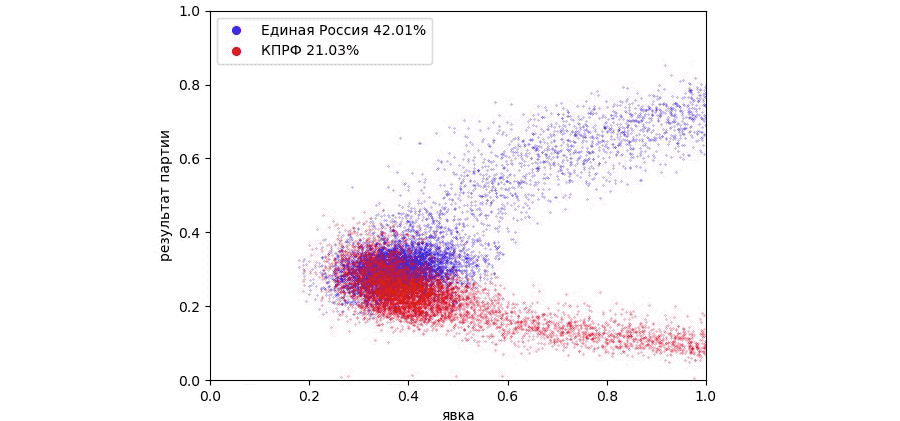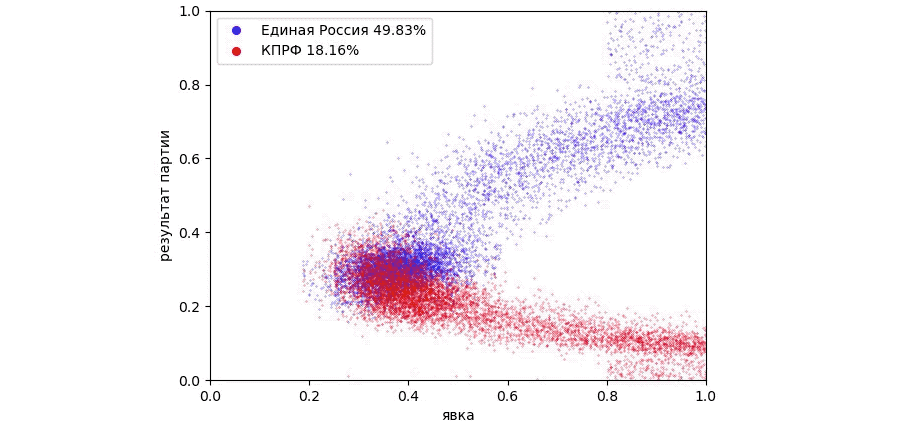
Рассмотрим график зависимости результатов партии Единая Россия и КПРФ от явки на всех участках:

На графике можно выделить две характерные области. Плотное ядро из участков, где красные и синие точки практически наслаиваются друг на друга. В этой области результат партии КПРФ очень близок к результату партии Единая Россия. Кроме того, на графике отчетливо видны две области, которые в видео выше Сергей Шпилькин называет «хвостами кометы». Синий хвост направлен в сторону большего результата партии, красный в сторону меньшего результата партии. Это означает, что на участках с большей явкой результат Единой России растет, а КПРФ падает.
Как же выглядит зависимость результатов партий от явки на участках, где выборы были организованы сбалансированными составами комиссий? В предыдущем исследовании "Почему на удалении от крупных городов избиратели ходят на участки охотнее и голосуют за партию власти" было установлено, что в центрах городов с населением свыше 300000 человек качество подсчета голосов было наиболее высокое. Ниже представлен график зависимости результата партий КПРФ и Единая Россия на участках, расположенных в 43 крупных городах России, на удалении менее 6 км от центров городов. Для Москвы это примерно эквивалентно площади внутри третьего транспортного кольца. Данные о результатах выборов на этих участках сохранены в файл ‘cities_ok.csv’.
Загрузим данные:
#%% Загружаем данные
import numpy as np
import pandas as pd
uiks = pd.read_csv('data/cities_ok.csv', index_col=0)
# uiks['voted'] = uiks['ballots_ok'] + uiks['ballots_spoiled']
uiks['total_voters'].sum()Проверим сколько избирателей могло участвовать в выборах:
#%% Количество избирателей:
uiks['total_voters'].sum()
12451827Более 12 миллионов человек. Это более 10% от общего числа избирателей в России.
Теперь построим график зависимости результатов двух крупнейших партий от явки:
#%% График зависимости результата на участках от явки
import matplotlib.pyplot as plt
uiks['er_percent'] = uiks['er'] / (uiks['voted'])
uiks['kprf_percent'] = uiks['kprf'] / (uiks['voted'])
uiks['turnout'] = uiks['voted']/uiks['total_voters']
plt.scatter(uiks['turnout'], uiks['er_percent'], color='blue', s=0.05, label="Единая Россия")
plt.scatter(uiks['turnout'], uiks['kprf_percent'], color='red', s=0.05, label="КПРФ")
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.xlim(0,1)
plt.ylim(0,1)
plt.show()
На графике можно рассмотреть ядро, в котором красные и синие точки наслаиваются друг на друга. Результат Единой России составил 30.16% и немного превышает результат КПРФ – 25.33%, поэтому синие точки в верхней части графика преобладают над красными.
Сгенерируем таблицу с результатами для участков из выборки с разбивкой по городам:
#%% Итоговый результат для различных городов
cities = uiks['city300'].drop_duplicates()
city_result = pd.DataFrame()
i=0
for city in cities:
i+=1
city_data = uiks[uiks['city300'] == city]
city_er_percent = city_data['er'].sum()/city_data['voted'].sum()
print(city_er_percent)
city_kprf_percent = city_data['kprf'].sum()/city_data['voted'].sum()
print(city_kprf_percent)
city_result = city_result.append(pd.DataFrame({'name':city,'er_percent': city_er_percent,'kprf_percent': city_kprf_percent}, index=[i]))
city_result
Город |
Результат ЕР |
Результат КПРФ |
Хабаровск |
22.59 |
26.29 |
Владивосток |
24.43 |
35.47 |
Киров |
24.86 |
17.35 |
Ярославль |
25.39 |
25.34 |
Омск |
26.42 |
35.63 |
Москва |
26.47 |
27.43 |
Орёл |
28.12 |
23.34 |
Тверь |
28.43 |
25.50 |
Липецк |
28.47 |
29.23 |
Мурманск |
28.49 |
19.86 |
Барнаул |
29.04 |
31.98 |
Чебоксары |
29.14 |
24.26 |
Томск |
29.17 |
23.26 |
Новосибирск |
29.22 |
28.00 |
Ульяновск |
29.26 |
37.74 |
Челябинск |
29.90 |
18.48 |
Ижевск |
29.92 |
27.66 |
Красноярск |
30.30 |
21.82 |
Иваново |
30.60 |
29.66 |
Пермь |
30.71 |
22.17 |
Вологда |
30.79 |
21.16 |
Архангельск |
30.83 |
18.53 |
Курган |
30.85 |
24.78 |
Магнитогорск |
30.88 |
22.45 |
Воронеж |
30.97 |
31.00 |
Иркутск |
31.14 |
31.18 |
Рязань |
31.31 |
25.96 |
Калининград |
31.40 |
24.48 |
Тольятти |
31.49 |
28.84 |
Сургут |
31.59 |
19.15 |
Чита |
31.68 |
23.02 |
Екатеринбург |
31.92 |
20.22 |
Калуга |
32.53 |
22.07 |
Улан-Удэ |
32.83 |
30.24 |
Череповец |
32.94 |
25.49 |
Оренбург |
32.95 |
24.75 |
Нижний Тагил |
33.33 |
21.01 |
Самара |
33.74 |
29.33 |
Нижний Новгород |
34.09 |
23.71 |
Курск |
34.12 |
23.13 |
Владимир |
34.25 |
26.97 |
Пенза |
34.43 |
24.74 |
Смоленск |
37.21 |
24.77 |
В дальнейшем эта таблица будет служить эталоном для оценки работы алгоритма машинного обучения.
Произведем вброс голосов на случайно выбранные участки в пользу партии Единая Россия:
#%% Осуществляем вброс
from random import uniform
uiks = uiks.sample(frac=1)
uiks['er_fraud'] = uiks['er']
uiks['kprf_fraud'] = uiks['kprf']
uiks['voted_fraud'] = uiks['voted']
uiks['added'] = False
i = 0
er_percent = uiks['er_fraud'].sum()/uiks['voted_fraud'].sum()
for index, row in uiks.iterrows():
if er_percent < 0.47:
total_voters = row['total_voters']
voted = row['voted']
max_fraud = total_voters - voted
min_fraud = max_fraud*0
number = int(uniform(min_fraud, max_fraud))
uiks.loc[index, 'er_fraud'] = row['er'] + number
uiks.loc[index, 'voted_fraud'] = row['voted'] + number
uiks.loc[index,'added'] = True
er_percent = uiks['er_fraud'].sum()/uiks['voted_fraud'].sum()
uiks['turnout_fraud'] = uiks['voted_fraud']/uiks['total_voters']
uiks['er_percent_fraud'] = uiks['er_fraud']/uiks['voted_fraud']
uiks['kprf_percent_fraud'] = uiks['kprf']/uiks['voted_fraud']
plt.scatter(uiks['turnout_fraud'], uiks['er_percent_fraud'], color='blue', s=0.05)
plt.scatter(uiks['turnout_fraud'], uiks['kprf_percent_fraud'], color='red', s=0.05)
plt.xlim([0,1])
plt.ylim([0,1])
plt.show()
uiks['kprf'].sum()/uiks['voted_fraud'].sum()

В результате вброса появилось два «хвоста» в области больших значений явки. Результат Единой России увеличился c 30 до 47 %. Однако, для большего сходства с графиком, построенным по результатам ЦИК не хватает участков, где результат Единой России превышает 80%. Вбросом такого результата не достичь, так как явка превысит 100%. Чтобы получить такой результат нужно забрать голоса у других партий и передать их Единой России. Или проще говоря задать результаты выборов на участках псевдослучайным образом для всех партий:
#%% Осуществляем замену голосов
uiks_change = uiks[~uiks['added']]
uiks['changed'] = False
for index, row in uiks_change.iterrows():
if er_percent < 0.4982:
total_voters = row['total_voters']
random_voted = int(uniform(total_voters * 0.8, total_voters))
voted = random_voted
random_er = int(uniform(random_voted * 0.8, random_voted))
uiks.loc[index, 'voted_fraud'] = voted
uiks.loc[index, 'er_fraud'] = int(random_er)
uiks.loc[index, 'kprf_fraud'] = int((random_voted - random_er)*0.3)
uiks.loc[index, 'changed'] = True
er_percent = uiks['er_fraud'].sum() / uiks['voted_fraud'].sum()
uiks['turnout_fraud'] = uiks['voted_fraud']/uiks['total_voters']
uiks['er_percent_fraud'] = uiks['er_fraud']/uiks['voted_fraud']
uiks['kprf_percent_fraud'] = uiks['kprf_fraud']/uiks['voted_fraud']
plt.scatter(uiks['turnout_fraud'], uiks['er_percent_fraud'], color='blue', s=0.05)
plt.scatter(uiks['turnout_fraud'], uiks['kprf_percent_fraud'], color='red', s=0.05)
plt.xlim([0,1])
plt.ylim([0,1])
plt.show()
uiks['kprf_fraud'].sum()/uiks['voted_fraud'].sum()

После генерации результатов в область явки свыше 80 процентов и результата Единой России свыше 80 процентов заполнилась точками. Результат Единой России достиг 49.83 %, результат КПРФ снизился до 18.16%.
Попробуем теперь вернуть участки из «хвостов» обратно в «ядро» с помощью инструментов библиотеки scikit-learn.
Для начала нужно решить задачу кластеризации: отделить участки с фальсификациями от участков с правильными результатами. Участки с правильными результатами затем будут использованы для обучения модели, которая восстановит результаты выборов. Мы знаем, что участки с верными результатами находятся в плотном ядре. Поэтому можно использовать алгоритм DBSCAN для его выделения.
#%% Выделяем кластер с нормальной и аномальной явкой
from sklearn.cluster import DBSCAN
er = uiks[['turnout_fraud', 'er_percent_fraud']]
er = er.to_numpy()
db = DBSCAN(eps=0.045, min_samples=200).fit(er)
plt.scatter(er[:, 0], er[:, 1], c=db.labels_, s=0.01)
plt.show()
uiks['db'] = db.labels_
uiks_normal = uiks[uiks['db'] == 0]
uiks_abnormal = uiks[uiks['db'] != 0]
plt.scatter(uiks_normal['turnout_fraud'], uiks_normal['er_percent_fraud'], color='blue', s=0.05)
plt.scatter(uiks_abnormal['turnout_fraud'], uiks_abnormal['er_percent_fraud'], color='red', s=0.05)
plt.show()
Важно отметить, что точность восстановления результатов выборов зависит от выбора оптимальных параметров DBSCAN. С одной стороны, чем больше участков с правильными результатами попадет в кластер ядра, тем соответственно будет больше выборка для обучения. С другой стороны, слишком большой кластер ядра захватит и участки с фальсификациями. Это приведет к ошибкам в обучении модели.
Установим общее число участков с правильными результатами:
#%% Количество участков без фальсификаций
len(uiks)-len(uiks[uiks['added']])-len(uiks[uiks['changed']])
3768Общее количество участков в ядре:
#%% Количество участков в ядре
len(uiks_normal)
4044Количество участков со вбросами в ядре:
#%% Количество участков с вбросами в ядре
len(uiks_normal[uiks_normal['added']])
353Таким образом в ядре находится почти все участки на которых не было фальсификаций и менее десяти процентов участков с фальсификациями.
Далее используем кластер участков без фальсификаций для обучения модели и восстановления результатов партии Единая Россия:
#%% Создаем pipeline для машинного обучения
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsRegressor
pipe = Pipeline([("scale", StandardScaler()), ("model", KNeighborsRegressor(weights='distance'))])
#%% Обучаем модель и делаем предсказание
from sklearn.model_selection import GridSearchCV
mod = GridSearchCV(estimator=pipe, param_grid={'model__n_neighbors': [1,2,3,4,5,6,7,10,11,12,13,14,15,16,17,18,19,20]}, cv=3)
X = uiks_normal[['kprf_fraud', 'total_voters', 'lat', 'lon']]
y = uiks_normal['er_fraud']
Xx = uiks_abnormal[['kprf_fraud', 'total_voters', 'lat', 'lon']]
mod.fit(X, y)
prediction = mod.predict(Xx)
uiks_abnormal['er_predicted'] = prediction.round()
pd.DataFrame(mod.cv_results_)
Теперь, когда у нас есть восстановленные результаты для партии Единая Россия, вычислим явку и процент проголосовавших за партии:
#%% Вычисляем явку по результатам машинного обучения
uiks_abnormal['voted_predicted'] = uiks_abnormal['voted_fraud'] - uiks_abnormal['er_fraud'] + uiks_abnormal['er_predicted']
uiks_abnormal['turnout_predicted'] = uiks_abnormal['voted_predicted'] / uiks_abnormal['total_voters']
uiks_abnormal['er_percent_predicted'] = uiks_abnormal['er_predicted'] / uiks_abnormal['voted_predicted']
uiks_abnormal['kprf_percent_predicted'] = uiks_abnormal['kprf'] / uiks_abnormal['voted_predicted']
uiks_normal['er_predicted'] = uiks_normal['er_fraud']
uiks_normal['voted_predicted'] = uiks_normal['voted_fraud']
uiks_normal['turnout_predicted'] = uiks_normal['turnout_fraud']
uiks_normal['er_percent_predicted'] = uiks_normal['er_percent_fraud']
uiks_normal['kprf_percent_predicted'] = uiks_normal['kprf_percent_fraud']
uiks_predicted = uiks_normal.append(uiks_abnormal)
Так как у нас есть результаты выборов до фальсификаций мы можем оценить, насколько хорошо справилось машинное обучение с задачей установления истинных результатов голосования.
Вот как выглядела зависимость результатов партий от явки до фальсификаций:
#%% Строим график зависимости результатов на участках со вбросами до фальсификаций
uiks_added = uiks_abnormal[uiks_abnormal['added']]
er_string = str(round(100*uiks_added['er'].sum()/uiks_added['voted'].sum(),2)) + '%'
kprf_string = str(round(100*uiks_added['kprf'].sum()/uiks_added['voted'].sum(),2))+ '%'
plt.scatter(uiks_added['turnout'], uiks_added['er_percent'], color='blue', s=0.05, label="Единая Россия " + er_string)
plt.scatter(uiks_added['turnout'], uiks_added['kprf_percent'], color='red', s=0.05, label="КПРФ " + kprf_string)
plt.xlim([0, 1])
plt.ylim([0, 1])
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.title("До фальсификаций")
plt.show()

После фальсификаций в виде вброса голосов ядро рассыпалось и превратилось в два «хвоста»:
#%% Строим график зависимости результатов на участках от явки со вбросами c фальсификациями
er_string = str(round(100*uiks_added['er_fraud'].sum()/uiks_added['voted_fraud'].sum(),2)) + '%'
kprf_string = str(round(100*uiks_added['kprf_fraud'].sum()/uiks_added['voted_fraud'].sum(),2))+ '%'
plt.scatter(uiks_added['turnout_fraud'], uiks_added['er_percent_fraud'], color='blue', s=0.05, label="Единая Россия " + er_string)
plt.scatter(uiks_added['turnout_fraud'], uiks_added['kprf_percent_fraud'], color='red', s=0.05, label="КПРФ " + kprf_string)
plt.xlim([0, 1])
plt.ylim([0, 1])
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.title("С фальсификациями")
plt.show()

После применения машинного обучения график зависимости результатов партий гораздо больше похож на оригинальный, чем график, построенный по фальсифицированным данным:
#%% Строим график зависимости результатов на участках с заменой до фальсификаций
uiks_changed = uiks_abnormal[uiks_abnormal['changed']]
er_string = str(round(100*uiks_changed['er'].sum()/uiks_changed['voted'].sum(),2)) + '%'
kprf_string = str(round(100*uiks_changed['kprf'].sum()/uiks_changed['voted'].sum(),2))+ '%'
plt.scatter(uiks_changed['turnout'], uiks_changed['er_percent'], color='blue', s=0.05, label="Единая Россия " + er_string)
plt.scatter(uiks_changed['turnout'], uiks_changed['kprf_percent'], color='red', s=0.05, label="КПРФ " + kprf_string)
plt.xlim([0, 1])
plt.ylim([0, 1])
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.show()
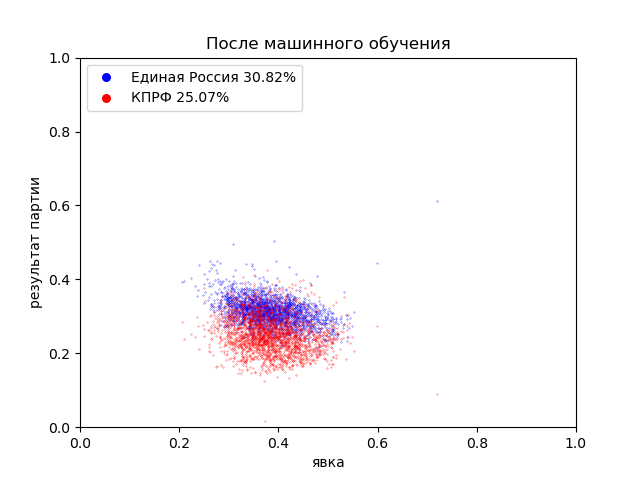
Теперь оценим, как справилась модель с восстановлением данных на участках, где результаты были полностью переписаны случайным образом:
#%% Строим график зависимости результатов на участках с заменой до фальсификаций
uiks_changed = uiks_abnormal[uiks_abnormal['changed']]
er_string = str(round(100*uiks_changed['er'].sum()/uiks_changed['voted'].sum(),2)) + '%'
kprf_string = str(round(100*uiks_changed['kprf'].sum()/uiks_changed['voted'].sum(),2))+ '%'
plt.scatter(uiks_changed['turnout'], uiks_changed['er_percent'], color='blue', s=0.05, label="Единая Россия " + er_string)
plt.scatter(uiks_changed['turnout'], uiks_changed['kprf_percent'], color='red', s=0.05, label="КПРФ " + kprf_string)
plt.xlim([0, 1])
plt.ylim([0, 1])
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.title("До фальсификаций (участки с заменой)")
plt.show()

Построим график зависимости результатов партий от явки для участков, где была замена голосов:
#%% Строим график зависимости результатов на участках от явки с заменой c фальсификациями
er_string = str(round(100*uiks_changed['er_fraud'].sum()/uiks_changed['voted_fraud'].sum(),2)) + '%'
kprf_string = str(round(100*uiks_changed['kprf'].sum()/uiks_changed['voted_fraud'].sum(),2))+ '%'
plt.scatter(uiks_changed['turnout_fraud'], uiks_changed['er_percent_fraud'], color='blue', s=0.05)
plt.scatter(uiks_changed['turnout_fraud'], uiks_changed['kprf_percent_fraud'], color='red', s=0.05)
plt.xlim([0, 1])
plt.ylim([0, 1])
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.title("С фальсификациями (участки с заменой)")
plt.show()

После фальсификаций результаты партий концентрируются в прямоугольных областях от 80% до 100% для Единой России и от 5% до 0% для КПРФ.
Оценим результат применения модели к данным участков, где была замена голосов:
#%% Строим график зависимости результатов на участках от явки с заменой после машинного обучения
er_string = str(round(100*uiks_changed['er_predicted'].sum()/uiks_changed['voted_predicted'].sum(),2)) + '%'
kprf_string = str(round(100*uiks_changed['kprf_fraud'].sum()/uiks_changed['voted_predicted'].sum(),2))+ '%'
plt.scatter(uiks_changed['turnout_predicted'], uiks_changed['er_percent_predicted'], color='blue', s=0.05, label="Единая Россия " + er_string)
plt.scatter(uiks_changed['turnout_predicted'], uiks_changed['kprf_percent_predicted'], color='red', s=0.05, label="КПРФ " + kprf_string)
plt.xlim([0, 1])
plt.ylim([0, 1])
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
lgnd.legendHandles[0]._sizes = [30]
lgnd.legendHandles[1]._sizes = [30]
plt.xlabel("явка")
plt.ylabel("результат партии")
plt.show()

Из графика видно, что модель работает не удовлетворительно. Вместо ядра получился «шлейф» в области низкой явки. Это и не удивительно. Ведь при заменен голосов были полностью фальсифицированы результаты для всех партий. А в нашей модели мы предполагали, что результат КПРФ был зафиксирован верно. К счастью, количество участков, где мы симулировали замену голосов, было не велико. Поэтому на итоговом результате эти искажения скажутся не сильно. Здесь интересно заметить, что в предыдущей статье «Восстанавливаем результаты выборов в государственную думу 2021 года с помощью машинного обучения» в итоговых результатах наблюдается очень похожий «хвост» в области низкой явки. Можно предположить, что в него попали итоги голосования на участках, где не были достоверно зарегистрированы результаты ни для одной из партий.
Изначально мы ставили задачу восстановить итоговый результат выборов в отдельных городах. Проверим как с этим справилось машинное обучение:
#%% Итоговый результат для городов
cities = uiks_predicted['city300'].drop_duplicates()
city_result_predicted = pd.DataFrame()
i=0
for city in cities:
i+=1
city_data = uiks_predicted[uiks_predicted['city300'] == city]
city_er_percent = city_data['er'].sum()/city_data['voted'].sum()
city_er_percent_fraud = city_data['er_fraud'].sum()/city_data['voted_fraud'].sum()
city_er_percent_predicted = city_data['er_predicted'].sum()/city_data['voted_predicted'].sum()
er_error = city_er_percent_predicted - city_er_percent
city_result_predicted = city_result_predicted.append(pd.DataFrame({'name':city,'er_percent_fraud': city_er_percent_fraud,'er_percent_predicted': city_er_percent_predicted, 'er_percent': city_er_percent,'er_error': er_error}, index=[i]))
city_result_predicted.sort_values('er_percent')
Город |
Результат ЕР с фальсификациями |
Результат ЕР после машинного обучения |
Результат ЕР до фальсификаций |
Ошибка модели |
Хабаровск |
40.33 |
24.10 |
22.59 |
1.51 |
Владивосток |
48.85 |
27.46 |
24.43 |
3.03 |
Киров |
41.44 |
26.31 |
24.86 |
1.45 |
Ярославль |
50.26 |
27.87 |
25.39 |
2.48 |
Омск |
48.10 |
27.78 |
26.42 |
1.36 |
Москва |
46.39 |
27.49 |
26.47 |
1.02 |
Орёл |
48.25 |
29.14 |
28.12 |
1.02 |
Тверь |
45.31 |
29.39 |
28.43 |
0.96 |
Липецк |
47.87 |
30.36 |
28.47 |
1.89 |
Мурманск |
49.66 |
29.74 |
28.49 |
1.25 |
Барнаул |
48.86 |
30.44 |
29.04 |
1.40 |
Чебоксары |
43.76 |
29.48 |
29.14 |
0.34 |
Томск |
52.42 |
30.55 |
29.17 |
1.38 |
Новосибирск |
52.77 |
30.06 |
29.22 |
0.84 |
Ульяновск |
52.61 |
31.43 |
29.26 |
2.17 |
Челябинск |
47.48 |
30.80 |
29.90 |
0.90 |
Ижевск |
50.06 |
31.30 |
29.92 |
1.38 |
Красноярск |
51.22 |
31.02 |
30.30 |
0.72 |
Иваново |
51.37 |
31.65 |
30.60 |
1.05 |
Пермь |
54.06 |
32.04 |
30.71 |
1.33 |
Вологда |
46.55 |
30.80 |
30.79 |
0.01 |
Архангельск |
48.04 |
32.13 |
30.83 |
1.30 |
Курган |
47.86 |
31.53 |
30.85 |
0.68 |
Магнитогорск |
47.71 |
31.29 |
30.88 |
0.41 |
Воронеж |
52.25 |
31.96 |
30.97 |
0.99 |
Иркутск |
49.23 |
31.90 |
31.14 |
0.76 |
Рязань |
49.04 |
31.90 |
31.31 |
0.59 |
Калининград |
49.63 |
32.20 |
31.40 |
0.80 |
Тольятти |
50.02 |
32.96 |
31.49 |
1.47 |
Сургут |
51.57 |
32.45 |
31.59 |
0.86 |
Чита |
60.76 |
33.03 |
31.68 |
1.35 |
Екатеринбург |
48.60 |
32.60 |
31.92 |
0.68 |
Калуга |
52.28 |
32.17 |
32.53 |
-0.36 |
Улан-Удэ |
53.60 |
33.62 |
32.83 |
0.79 |
Череповец |
47.23 |
33.21 |
32.94 |
0.27 |
Оренбург |
50.70 |
33.30 |
32.95 |
0.35 |
Нижний Тагил |
45.81 |
32.44 |
33.33 |
-0.89 |
Самара |
55.76 |
34.85 |
33.74 |
1.11 |
Нижний Новгород |
56.50 |
34.77 |
34.09 |
0.68 |
Курск |
55.74 |
33.61 |
34.12 |
-0.51 |
Владимир |
53.26 |
33.65 |
34.25 |
-0.60 |
Пенза |
52.99 |
34.43 |
34.43 |
0.00 |
Смоленск |
69.93 |
36.24 |
37.21 |
-0.97 |
Как видно из таблицы, погрешность восстановления результатов максимальная для Владивостока и достигает трех процентов, однако этот результат существенно ближе к истине, чем данные с фальсификациями.
Для визуализации качества работы модели построим график зависимости восстановленных результатов партии «Единая Россия» в городах от истинных результатов:
#%% Строим график зависимости результатов городов сгенерированных от первоначальных
plt.scatter(city_result_predicted['er_percent'], city_result_predicted['er_percent'], color='red', label = "Истинные результаты")
plt.scatter(city_result_predicted['er_percent'], city_result_predicted['er_percent_predicted'], color='blue', label = "Результаты машинного обучения")
lgnd = plt.legend(loc="upper left", scatterpoints=1, fontsize=10)
plt.xlabel("Результат ЕР в городах")
plt.ylabel("Результат ЕР в городах")
plt.show()
По результатам исследования можно сделать следующие выводы:
Фальсификации результатов выборов на участках в виде вбросов бюллетеней формируют на графике зависимости результатов партий от явки характерные области, которые тянутся расходящимися «хвостами» из ядра. С помощью фальсификаций в виде вбросов не возможно добиться результатов близких к 100% ни за одну из партий.
Результат близкий к 100 % может свидетельствовать о другом типе фальсификаций: на участках происходила замена бюллетеней с голосами за одну из партий на бюллетени с голосами за другую партию или генерация итогового результата случайным образом.
В результате фальсификаций в кластере ядра могут оказаться участки с недостоверными результатами, однако их число незначительно по сравнению с числом участков в ядре.
Применение простой модели машинного обучения для восстановления результатов выборов на участках с фальсификациями в виде вбросов может давать удовлетворительный результат, который существенно ближе к истинному результату на участках, чем фальсифицированный результат.
На участках с фальсификациями в виде замены голосов фактически полностью отсутствует информация о проведенном голосовании. Попытка применить к ним ту же модель, что и к участкам, где были выбросы приводит к появлению шлейфа из участков в области низкой явки на графике результат партии-явка. Подобный шлейф образовался и при попытке применить модель машинного обучения к результатам выборов на всех участках России. Подробнее об этом можно прочитать в этой статье.
Простую модель, примененную в ходе данного эксперимента, можно улучшить, добавив дополнительную информацию из открытых источников.
Какие выводы после прочтения статьи можете сделать вы? Напишите, пожалуйста в комментариях.
Комментарии (26)

pchirikov
02.12.2021 18:57+9Я понимаю, что комментировать статью не читая это не прилично. Но мне достаточно прочтения заголовка и диагонального скроллинга, чтобы понять следующее:
Вы сфальсифицировали результаты, а потом отменили фальсификацию с помощью ML,
Скорее всего в теле статьи вы попытались сделать из этого какие-то выводы (напр. фальсификация имела место на самом деле, или наоборот не имела, или что ее можно выявить вашим способом), иначе статья не имеет смысла,
Никакой конкретики в выводах в конце статьи я не увидел,
Тем самым вы предлагаете читателям хабра внимательно прочитать вашу длинную статью, посмотреть видео, проверить на наличие ошибок/просчетов в вашей цепочке рассуждений и сделать выводы за вас?

Archemagus
02.12.2021 20:36+1Насколько я понял, статья не связана именно с Выборами (с большой буквы), и авторы не забывают об этом напомнить (по понятным причинам)
Статья по большей части рассказывает о возможности применения ML для, получения доп данных, и в целом о возможности использования ML в выборах как сфере деятельности, что как по моему относительно свежая идея.
А Хабр это про конкретный вывод? А - молодец, Б - не очень. А как же вывод делайте сами?
К тому же политика отдельным пунктом числится в правилах Хабра.Но если вам очень хочется - то пожалуйста, ваш персональный вывод: с развитием технологий, не стоит забывать про социальный сегмент. Современный трэнд на машинное обучение так же имеет хорошие шансы вписаться в политику. Анализ выборов, поддержка электората, факторы влияющие на эту поддержку и т.д. и т.п.
zzzzbh Автор
02.12.2021 22:54Здравствуйте! Спасибо за комментарий! Я уже пару месяцев рассматриваю данные результатов выборов. Делюсь находками, которые мне кажутся интересными. Статья на самом деле не очень длинная. В ней много кода, который можно читать по диагонали. В предыдущей статье «Восстанавливаем результаты выборов 2021 с помощью машинного обучения» больше конкретики. Возможно, она будет вам более интересна.

Matshishkapeu
02.12.2021 19:12+23Бллджжад. Люди берут федеральные данные (куда входит, например, Чеченская республика с явкой за 90 процентов и результатами голосования за ЕР тоже за 90 процентов). Потом люди тренируют модель не включая такие регионы. Потом делают искусственные выбросы чтобы распределение не включая было похоже на федеральное распределение с их включением, потом вычитают то что сами выдумали. Вопщем теребили пандас изо всех сил. Натренировали модель на профильтрованных данных, потом модель выдала результат похожий на тренировочную выборку (шок!!!11).
При этом никто не озадачивается вопросом, а может избиратели в Адыгее и Махачкале и правда не голосуют за ЛДПР, или там СР, просто потому что Жириновский и Прилепин не особо среди них популярны. А в Хабаровске ЛДПР популярны, а в Москве -нет. Может отрицательная корреляция голосов за ЕР с размером участка это потому что участки в 2000 человек это крупные города, а в 200 сельская местность. Может положительная корреляция ЕР с голосами на дому это пожилые избиратели которые рады приходу гостей из внешнего мира и в целом чаще голосуют лояльно (это как бы некая естественная реакция взаимности, к ним пришли в гости и они рады, как кришнаиты перед просьбой денег делают символический подарок и люди чаще жертвуют).
И последнее, про наблюдателей и потребные миллиарды. Трижды в прошлом наблюдатель, денег получал на пожрать и ночью на такси домой вернуться. Наблюдатели нанятые за деньги отбывали рядом номер без малейшей заинтересованности в работе. Так что это не вопрос денег, это вопрос наличия сторонников.
zzzzbh Автор
02.12.2021 23:18Здравствуйте! Спасибо за комментарий! В этой статье используются данные о результатах выборов на 6602 участках. Участков из Северного Кавказа среди них нет. Такая выборка была сделана для удобства эксперимента. На участках симулируются фальсификации разного типа, чтобы посмотреть, как они могут выглядеть на графиках. Потом применяется модель, чтобы восстановить результат. Таким образом у нас появляются исходные данные, для проверки корректности работы модели. Статья не о результатах выборов, а о возможности применения модели для восстановления результатов.
То, что вы ходили наблюдателем бесплатно, это очень хорошо! Я тоже ходил наблюдателем за свой счет на выборы в Госдуму 2021. Если было бы пол миллиона таких энтузиастов как вы, качество регистрации результатов выборов бы существенно выросло! К сожалению, не каждый сейчас может себе это позволить.
KoteMilote
03.12.2021 07:14+6Участков из Северного Кавказа среди них нет. Такая выборка была сделана для удобства эксперимента.
Это называется подогнать под ответ.
major-general_Kusanagi
03.12.2021 06:36Напоминает охоту на ведьм в википедии:
— группа участников https://ru.wikipedia.org/wiki/Арбитраж: Группа_участников_из_дискорд-чата_и_её_деструктивное_влияние_на_рувики
— прорвалась на выборах в арбитры
— заблокировала своих противников https://ru.wikipedia.org/wiki/Арбитраж: Группа_вокруг_Vajrapani
— и теперь занимается тотальной зачисткой и баном всех кто «не так» голосовал https://ru.wikipedia.org/wiki/Арбитраж: Ботоферма
MAXH0
03.12.2021 10:12Если говорить конкретно про статью, то не напоминает. А вот если говорить абстрактно, то и с ситуация с Выборами в РФ (да и в других странах), и ситуация с Вики, и с "демократией" на Хабре показывают уязвимость системы перед массовыми скоординированными манипуляциями.

kraidiky
03.12.2021 22:16+2Как я и писал под прошлой его статьей с упоминанием Шпилькина в качестве исходных данных:
Если бы он такое на экзамене по матстатистике выдал, его бы выперли с экзамена с двойкой, но для наших несогласных вполне проканывает.
И вот автор выходит на пересдачу и… Барабанная дробь… несёт то же самое.
Как я уже один раз говорил: «Автор подумал, что если у Шпилькина проканало, то и у него проканает тоже. Не проканало. Ну ничё, может в следующий раз зайдёт».
Вот только не ожидал, что следующий раз наступит так скоро.zzzzbh Автор
05.12.2021 16:06Здравствуйте! Спасибо за комментарий! Очень приятно, что вы внимательно следите за моими публикациями. Эту статью я как раз и решил выпустить быстро после того, как получил критические комментарии, в том числе от вас. К этой статье всего один дизлайк за "другое". Значит она была более убедительной, чем предыдущая. Поэтому третью статью пока не планирую выпускать.

CDCrom
03.12.2021 09:24На сколько я помню ролик в начале, там на графике были данные по электронному голосованию и естественно они отмечались как высокая явка и соответственно у вас данные результаты будут отсеяны как фальсификация хотя это и не так.
Точнее так показатель "явка" может быть реальным, а вот "результаты голосования" под вопросом, так как доверия к электронному голосованию у многих нет.Тут вариантом повышения уровня доверия к электронному голосованию может служить, как было указано в статье, проект с исходным кодом подконтрольный всем участникам голосования. Но думаю такой проект должен быть дублером государственной системы и данные принимать одновременно с данными госсистемы. Таким образом можно будет проверить корректность результатов и уже по ним судить на сколько правильно работает госсистема.
Кстати дополнительным вариантом повышения уровня доверия к системе может быть возможность "открытого голосования", то есть когда голосующий открыто заявляет о своем решении. Да "тайное голосование" сделано для защиты голосующего от давления со стороны и последующего преследования, но если гражданин не сомневается, что своим выбором он себе на навредит он может подтвердить, что голос его, а не чей-то другой и тогда подделать его голос будет невозможно.

vyachin
03.12.2021 09:36-2Авторам спасибо, вы проделали огромный труд, но напрасно. Такими статьями, как мне кажется, вы не сможете заставить думать тех, кто думать перестал.
sherezha95
04.12.2021 18:10А нельзя вывести список УИКов с вбросами по вашей системе и накинуть их на карту?
Подсветится наверняка Кавказ.
Ещё бы глянуть на те УИКи, где вбросы были не за ядро, а за коммунистов. Под вбросами вы ж понимаете отклонение от среднего по больнице? На сколько? На 3 сигма?
zzzzbh Автор
05.12.2021 15:55-1Здравствуйте! Спасибо за комментарий! Под вбросами в данной статье мы понимаем вбросы, которые сами и осуществляем с помощью простого цикла. Карта была построена в предыдущей статье «Восстанавливаем результаты выборов 2021 с помощью машинного обучения».
MAXH0
Господа. Как я понимаю дальнейшие действия - работать с КПРФ в ГД над совершенствованием электронной части выборов?
Хотя вот ИМХО - двухпартийная система ЕР и КПРФ - не образец демократии. Но, видимо даже по самым оптимистичным прогнозам, это тот максимум, который мы можем получить при абсолютно честно-прозрачных выборах.
itsoft
Выборы — это не только голосование и подсчёт. Выборы — это долгий процесс, это прежде всего свободные СМИ, отсутствие политзаключённых, регистрация всех партий и кандидатов, свобода собраний, честные суды.
Тогда будет многопартийная система, в которой 30% будет максимальный результат.
CTDEVIce
Не бывает свободных СМИ в политике. Другое дело, что должно быть много разных СМИ, подконтрольных разным политическим, экономическим (и, чего уже скрывать, криминальным) группам.
MAXH0
Замечательный ответ. Его стоит занести в учебник . Только вот ИМХО реальность против этих красивых слов. Почему я так считаю?
Во всём мире прохождение в парламент становится все дороже и дороже. В том числе и потому, что методы манипуляции электоратом через анализ данных и таргетированную рекламу всё эффективнее, хотя и дороже. Следовательно политики больше зависят от олигархов. Как итог мы имеем в парламенте несколько олигархически ангажированных партий. Партии же из политических (оцениваемых по программе и делам), превращаются в полит-технологические (оцениваемых по лозунгам и шумихе в СМИ). Взять того же лося!
itsoft
Не знаю где вы имеете несколько партий. Там ровно одна, и не вы её имеете, а она всех нас. Остальные — псевдопартии, фактически филиалы главной партии под полным контролем администрации.
MAXH0
Вы бы не могли снизить накал полемики? Мы же все же не на митинге.
Я имел, в общем то ситуацию в целом в мире.
Elordis
Выборы - это в первую очередь, внезапно, наличие выбора. А у нас в стране пока реальная политическая сила только одна (с фронтэндом в виде Единой России). Та же КПРФ показала свое полное бессилие, не выведя никого на улицы после выборов.
Как только альтернативные силы появятся, все остальное вырастет само собой в процессе конкуренции. А без них все умрет, даже если прилетит волшебник и взмахом палочки все сделает.
itsoft
Без всего перечисленного они и не появятся. Тут, конечно, уже вопрос что первично курица или яйцо. Но страна с монополией одной партии хиреет и рано или поздно заканчивается как это уже было много раз в истории.
MagisterXXI
Дряхлеет или нет, это смотря с какой стороны посмотреть. Обама говорил что разорвал в клочья, а Милли спустя 7 лет говорит что мир стал триполярным (Россия, США и Китай). Выходит за это время сместилась то оценочка.
Так что мнения, как видно могут быть разными, и не надо излишне абсолютизировать своё персональное.
zzzzbh Автор
Здравствуйте! Спасибо за комментарий! Я в статье использовал результаты только Единой России и КПРФ, так как на этих выборах их результаты были близки на многих участках и их удобно сравнивать.
Ferliness
Добрый день, было бы здорово возьми вы также анализировать результаты других стран, с учётом их вероятной честности или нечестности, финансирования, количества партий и т.д.