
После релиза нашей первой модели, расставляющей знаки препинания и большие буквы, было много пожеланий доработать её, чтобы она могла обрабатывать тексты целиком, а не отдельные предложения. Это коллективное пожелание и было осуществлено в нашей новой версии модели.
В целом, архитектура и датасеты остались прежними. Что изменилось:
- обучение теперь производилось не на отдельных предложениях, а на нескольких последовательных предложениях (принимаем во внимание, что конструктивное ограничение модели при обучении — 512 токенов на вход, что позволяет свободно подавать ~150 слов на любом из четырех поддерживаемых языков)
- для ускорения обучения модели сокращение словаря теперь проводилось не только на инференсе, но и на трейне, что позволило увелить размер батча
Размер модели и ее сжатие
Первая версия модели на момент релиза уже весила меньше 100 мегабайт. После этого мы выбросили еще 20 тысяч токенов (размер токена, напомним, 768) — токенов с большой буквой в начале, про которые мы забыли в тот раз, и которые модель, очевидно, не использует. Так модель еще немного ужалась до 85 мегабайт.
Как и раньше, основным секретом такого удобного размера выступает статическая и динамическая квантизация.
Что мы еще попробовали:
-
прунинг — с помощью кода из оригинального репо базовой модели действительно удалось проанализировать головы и подрезать лишние, но это, во-первых, резко ухудшило качество модели, во-вторых, из-за особенностей архитектуры модели, головы — не единственные тяжеловесные ее части, и выигрыш по размеру составил только 10 мегабайт, что вообще не имеет смысла при ухудшении метрик;
-
факторизацию — вывод примерно аналогичный, хоть выигрыш и составил здесь около 20 мегабайт, эмбеддинг стал работать сильно менее успешно и вероятно требовал очень длительного дообучения, что тоже выходило бы не вполне рационально.
В итоге от обеих перечисленных техник было разумнее отказаться.
Результаты
Напомним, что для этой задачи мы снимаем метрики на валидационных сабсетах наших приватных текстовых корпусов (5,000 предложений на каждый язык) и на текстах caito (20,000 случайных предложений на каждый язык). Более подробно про снятие метрик — в нашей статье про первую версию модели.
В этот раз для краткости приведем только WER (word error rate) в процентах, причем отдельно рассчитанный для пунктуации (и предсказание, и оригинал при этом приведены к строчному виду) — WER_p и для расставления заглавных букв (а здесь выбрасываем всю пунтуацию) — WER_c.
Мы посчитали метрики как для входных данных, представляющих из себя блоки из нескольких последовательных предложений, так и на отдельных предложениях, чтобы удостовериться, что новая версия модели действительно включает в себя функционал старой.
В ячейках указан WER_p / WER_c, а наивный бейзлайн состоит в постановке заглавной буквы в начале текста и точки в конце.
WER — работа модели на блоках из нескольких предложений
Домен — валидационные данные:
| Языки | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| бейзлайн | 14 / 19 | 13 / 41 | 17 / 20 | 10 / 16 |
| модель | 6 / 6 | 5 / 5 | 7 / 7 | 5 / 5 |
Домен — книги:
| Языки | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| бейзлайн | 14 / 13 | 15 / 26 | 23 / 14 | 13 / 8 |
| модель | 12 / 7 | 11 / 8 | 18 / 10 | 12 / 6 |
WER — работа модели отдельных предложениях
Домен — валидационные данные:
| Языки | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| бейзлайн | 12 / 18 | 10 / 33 | 13 / 12 | 8 / 11 |
| модель | 5 / 4 | 5 / 4 | 7 / 4 | 5 / 4 |
Домен — книги:
| Языки | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| бейзлайн | 12 / 10 | 12 / 22 | 19 / 9 | 15 / 7 |
| модель | 12 / 6 | 10 / 6 | 17 / 7 | 13 / 5 |
Впрочем, еще работая с текстами caito в первый раз, мы заметили, что они далеки от идеала — нередко предложения будто обрезаны или перемешаны, внутри предложения вклинивается другое, начинающееся с большой буквы, но без точки до этого, — что, конечно, на блоках предложений становится еще более заметным. Вероятно, таковы издержки предобработки текстов книг. Тем не менее, решили уже не переходить на другие датасеты для удобства сравнения метрик — понятно, что полученные числа скорее коррелируют с реальным качеством работы модели на произвольных данных.
Примеры работы модели
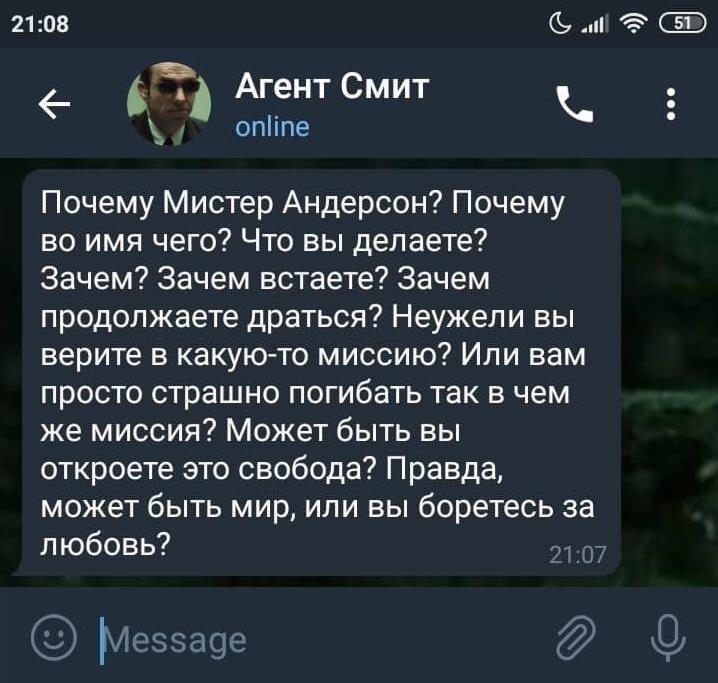
Как и раньше, приведем непосредственные примеры работы модели — в этот раз поможем Агенту Смиту с пунктуацией и заглавными буквами на трех оставшихся языках:
| Оригинал | Модель |
|---|---|
| Why, Mr. Anderson? Why, why, why? Why do you do it? Why get up? Why keep fighting? Do you believe you're fighting for something? For more than your survival? Can you tell me what it is? Do you even know? Is it freedom? Or truth? Perhaps peace? Could it be for love? | Why Mr. Anderson, Why why why why do you do it? Why get up? Why keep fighting? Do you believe youre fighting for something for more than your survival? Can you tell me what it is? Do you even know is it freedom or truth? Perhaps peace could it be for love? |
| -- | -- |
| Wieso Mr. Anderson? Wieso, wieso? Wieso tun sie das? Wieso? Warum aufstehen? Warum weiterkämpfen? Glauben Sie wirklich, sie kämpfen für etwas für mehr, als ihr Überleben? Können Sie mir sagen, was es ist? Wissen sie es überhaupt? Ist es Freiheit, vielleicht Wahrheit? Vielleicht Frieden? Könnt‘ es für die Liebe sein? | Wieso Mr. Anderson, Wieso wieso? Wieso tun sie das? Wieso, warum aufstehen? Warum weiterkämpfen? Glauben sie wirklich sie kämpfen für etwas für mehr als ihr überleben können sie mir sagen, was es ist, Wissen sie es überhaupt ist es freiheit, vielleicht Wahrheit vielleicht Frieden könnt es für die Liebe sein. |
| -- | -- |
| ¿Por qué lo hace? ¿Por qué? ¿Por qué se levanta? ¿Por qué sigue luchando? ¿De verdad cree que lucha por algo además de por su propia supervivencia? ¿Querría decirme qué es, si es que acaso lo sabe? ¿Es por la libertad? ¿Por la verdad? ¿Tal vez por la paz? ¿Quizás por el amor? | ¿Por qué lo hace? ¿Por qué? ¿Por qué se levanta? ¿Por qué sigue luchando de verdad? Cree que lucha por algo, además de por su propia supervivencia, querría decirme qué es si es que acaso lo sabe es por la libertad por la verdad, tal vez por la paz, quizás por el amor. |
Как запустить
Модель, как и первая ее версия, выложена в репозитории проекта silero-models. А вот простой запуск модели (подробнее, как обычно, в colab):
import torch
model, example_texts, languages, punct, apply_te = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_te')
input_text = input('Enter input text\n')
apply_te(input_text, lan='en')Дальнейшие планы
В перспективе есть мысли переработать и расширить тренировочный корпус текстов — например, сейчас в нем заметно не достает примеров разговорной живой речи, как в субтитрах.
Еще одна особенность модели, тоже проявившаяся именно при работе с целыми абзацами текста: из-за того, что модель предсказывает заглавные буквы и пунктуацию раздельно — на каждую подзадачу отдельная голова, — изредка эти предсказания выходят несогласованными. В процессе разработки модели мы пробовали делать общую голову для обеих задач, но она работала хуже раздельных. Опция, которую хорошо бы еще проверить, — предсказывать сначала расстановку заглавных букв (это более простая задача), а потом подавать это предсказание вместе с входной текстовой последовательностью для расстановки пунктуации.
P. S. Делитесь остроумными примерами работы модели в комментариях и голосуйте за понравившиеся! Лучшие фразы добавим как встроенные примеры в следующем релизе :D
Комментарии (20)

snakers4
09.12.2021 20:24+4на завтрак я сегодня хавал темную энергию укутавшись в незримую материю вселенной и запивая молоком гравитационных волн разлитых звездами которых давно нет я перевариваю боль вселенной я здесь живу веками во тьме построенной из сгустков атомов рожденных смертью света и сотканных в агонии случайных встреч а теперь я должен сидеть и смотреть на твое тупорылое хлебало
Местами очень хорошо, местами лулзово:
На завтрак! Я сегодня хавал темную энергию, укутавшись в незримую материю Вселенной и запивая молоком гравитационных волн, разлитых звездами которых давно нет. Я перевариваю боль Вселенной. Я здесь живу веками во тьме, построенной из сгустков атомов, рожденных смертью света и сотканных в агонии случайных встреч. А теперь я должен сидеть и смотреть на твое тупорылое хлебало.

hp6812er
09.12.2021 22:31Часть 2. Поезд и люди
«Чусовская — Тагил»… Солнечный поезд.
Тогда, в детстве, всё было по-другому: и дни длиннее, и земля больше, и хлеб не привозной. Мне нравились попутчики, завораживало таинство их жизни, открытое мне случайно, как бы мимоходом. Вот чистенькая старушка разворачивает газетку, в которой аккуратно сложены перья лука, пирожки с капустной начинкой и яйца, сваренные вкрутую. Вот небритый папаша укачивает сидящую у него на коленях маленькую дочку, и столько нежности в том осторожном движении, которым этот мужик, корявый и неловкий, прикрывает девочку полой своего потрёпанного пиджака… Вот пьют водку расхристанные дембеля: вроде бы, ошалев от счастья, они вразнобой гогочут, братаются, но внезапно, будто что-то вспомнив, начинают драться, потом плачут от невозможности выразить непонятное им страдание, снова обнимаются и поют песни. И только через много лет я понял, как черствеет душа, когда долго живёшь не дома.
Как то на "тотальном диктанте" получил трояк, попав на одно из произведений Алексея Иванова. Было бы здоров увидеть, как через пару лет ваша сеть справляется и с таким)
snakers4
10.12.2021 07:58тогда в детстве всё было по-другому и дни длиннее и земля больше и хлеб не привозной мне нравились попутчики завораживало таинство их жизни открытое мне случайно как бы мимоходом вот чистенькая старушка разворачивает газетку в которой аккуратно сложены перья лука пирожки с капустной начинкой и яйца сваренные вкрутую вот небритый папаша укачивает сидящую у него на коленях маленькую дочку и столько нежности в том осторожном движении которым этот мужик корявый и неловкий прикрывает девочку полой своего потрёпанного пиджака вот пьют водку расхристанные дембеля вроде бы ошалев от счастья они вразнобой гогочут братаются но внезапно будто что-то вспомнив начинают драться потом плачут от невозможности выразить непонятное им страдание снова обнимаются и поют песни только через много лет я понял как черствеет душа когда долго живёшь не дома
Получилось:
Тогда в детстве всё было по-другому и дни длиннее, и земля больше и хлеб не привозной. Мне нравились попутчики завораживало таинство их жизни открытое мне случайно, как бы мимоходом. Вот чистенькая старушка разворачивает газетку, в которой аккуратно сложены перья лука, пирожки с капустной начинкой и яйца сваренные вкрутую. Вот небритый папаша укачивает сидящую у него на коленях маленькую дочку и столько нежности. В том осторожном движении, которым этот мужик, корявый и неловкий прикрывает девочку полой своего потрёпанного пиджака. Вот пьют водку, расхристанные дембеля вроде бы ошалев от счастья. Они вразнобой гогочут братаются, но внезапно будто, что-то вспомнив начинают драться потом плачут от невозможности выразить непонятное им страдание снова обнимаются и поют песни только через много лет. Я понял, как черствеет душа, когда долго живёшь не дома.
Вы не приложили результат работы сетки. Чтобы у публики не было сомнений насчет качества решения — вот то, что выдает сетка. Пусть каждый судит сам.
Вообще когда люди читают диктант там:
- За 1 любую ошибку оценку снижают на 1 балл;
- Много пунктуации является авторской и диктор часто помогает людям, "намекая" интонацией, потому что он читает с листа;
- Тут классические русские предложения длиной в абзац и некоторые редкие знаки препинания нами специально не обрабатываются;
Поэтому лично кажется, что сетка справилась великолепно.

kterik
10.12.2021 09:53-1Лично мне кажется, что результат работы сети, специально предназначенной для расстановки знаков препинания, в этом случае очень посредственный. И авторская пунктуация тут ни при чём — ошибки обыкновенные. Конечно, по меркам интернет-общения это уже норма, но грамотному человеку, не дислексику, глаз режет.
snakers4
10.12.2021 10:15+1Даже не знаю, что здесь ответить.
Ну будет коммерческий заказ, чтобы сделать именно идеально на всех краевых кейсах для сложных текстов — конечно сделаем.
Но в таком случае заказчик может не пожелать, чтобы такую сетку выкладывали.kterik
10.12.2021 11:59-1Я не читал исходный текст, только проверил результат нейросети на ошибки. Четыре лишних знака препинания, шестнадцать недостающих, четырнадцать правильных. Некоторые из ошибок даже MS Word подчёркивает, хотя его система проверки откровенно слаба и сама часто вводит в заблуждение.
Очевидно, что литературная речь со сколько-нибудь сложными конструкциями не являлась вашей целью. А что за корпус текстов вы использовали? Записи в блогах и посты из соцсетей?
snakers4
10.12.2021 19:05+1Ну тут важно понимать, что Ворд работает на письменном тексте, где уже и так скорее всего стоят точки. И ищет речевые обороты внутри этих предложений. Если подать ему простыню, то скорее всего ничего хорошего не будет. Понять где начинается и заканчивается мысль это нетривиально.

altervision
09.12.2021 22:37+2Обновили модель в своих ботах до актуальной версии. Работать стало гораздо лучше. С разделением на предложения - гораздо удобнее, да и в целом качество повысилось. Спасибо!
snakers4
10.12.2021 08:03А что за боты?
altervision
10.12.2021 08:18+1Наши "корпоративные" боты AlterCPATalkBot (русский) и AlterCPAChatBot. Изначально были помощниками в чатах - спам по CAS фильтровать, состояние серверов и доменов проверять. Потом добавили в них распознавалку голоса на базе vosk, чтобы голосовые от заказчиков расшифровывать. Так мы пытались отучить заказчиков использовать голосовухи - принципиально делали не как сказано в самом сообщении, а как бот его расшифровал. С первой версией модели пунктуации от Silero добавили и её - тексты стали гораздо осмысленнее. А со второй версией модели Silero и базами Vosk версии 0.22 бот стал распознавать голосовые слишком хорошо ;)
snakers4
10.12.2021 08:21Вы можете просто использовать наш бот @silero_audio_bot — там качество скорее всего сильно лучше, и модели пунктуации уже встроены.
Плюс мы там крутим самую качественную коммерческую модель, которой нет в паблике.
altervision
10.12.2021 08:42Ваш бот конечно классный, тестировали его - всё понравилось) Но поймите меня правильно, это же не интересно ;) Хочется самому покопаться, написать своё решение. К тому же, распознавание голоса - это всего лишь забавный побочный функционал для тех ботов, не более того. Им нельзя работать слишком качественно, иначе заказчики так и не перестанут пользоваться голосовыми.
snakers4
10.12.2021 08:53Ну, если цель чисто "поковырять по фану", могу предложить вам другой функционал — возьмите наш VAD — https://github.com/snakers4/silero-vad — считайте им длину речи в голосовухе и пишите в чат "мы насчитали столько-то секунд речи, ее послушают N человек, суммарно потратив N времени".
Ну и конечно лайк, шер, репост, если используете наши решения. А то там что-то мало звездочек.


vgray
10.12.2021 09:24+1почему-то падает на скобках
input_text = "в данной статье на самом то деле очень красиво и интересно (без сарказма) рассказывается о продвижениии под НЧ и микроНЧ запросы как бы опять же ничего нового но статья может помочь понять и понять систему этого процесса и как его настроить у себя "с ошибкой "IndexError: string index out of range"
Почему-то делает замену букв на амперсанды
Input: в данной статье на самом то деле очень красиво и интересно без сарказма рассказывается о продвижениии под НЧ и микроНЧ запросы как бы опять же ничего нового но статья может помочь понять и понять систему этого процесса и как его настроить у себя
Output: В данной статье на самом то деле очень красиво и интересно без сарказма. Рассказывается о продвижениии под && и микро&& запросы как бы опять же ничего нового, но статья может помочь понять и понять систему этого процесса и как его настроить у себя.
snakers4
10.12.2021 09:57Надо вот так:
Input:
в данной статье на самом то деле очень красиво и интересно без сарказма рассказывается о продвижениии под нч и микронч запросы как бы опять же ничего нового но статья может помочь понять и понять систему этого процесса и как его настроить у себяПолучается
Output:
В данной статье на самом то деле очень красиво и интересно, без сарказма рассказывается о продвижениии под НЧ и микронч запросы как бы опять же ничего нового, Но статья может помочь понять и понять систему этого процесса и как его настроить у себя.Edge кейсы в виде смешенных кейсов внутри одного слова и "учета" авторской пунктуации мы не делали, показалось избыточным и очень зависимым от конкретного примера.
Если это прямо обязательно, в принципе под ваш кейс легко пишется костыль, но предполагаю, что таких кейсов сотни.
snakers4
Почти сработало даже с именами кошек: