

Довольно прозаичный и понятный в быту термин порой все еще вызывает вопросы в IT. Зачем при разработке приложений использовать очереди или сервисы очередей, чтобы автоматизировать этот процесс? Ответим на этот вопрос практическими примером — напишем в serverless-стеке Yandex.Cloud сервис для конвертации видео в GIF, используя Yandex Message Queue — ту самую очередь.
Что такое сервис очередей и зачем он нужен
Очередь что-то накапливает и постепенно выдает. Как же это реализует для разработки сервис очередей? Сервис очередей — решение для обмена сообщениями между приложениями, реализуемое с помощью API. С одной стороны, в него можно складывать какие-то события, а с другой — выдавать их обработчику (или нескольким обработчикам) для выполнения поставленной событием задачи, после решения которой событие в очереди отмечается как решенное.
Сервисы очередей находят применение в широком спектре сценариев, особенно в ресурсоемких задачах с ограничениями в скорости обработки. Пользователи одномоментно могут сгенерировать множество новых событий, обработчики не справятся с потоком, что приведет к отказу в работе. Использование сервиса очередей амортизирует нагрузку на сервис, когда приходит слишком много событий, они встают в очередь и ждут, пока у обработчика до них «дойдут руки». Задачи никуда не теряются даже в случае аварийного завершения системы.

С технической стороны можно представить очередь как специализированную базу данных с очень узким API и строго определенным сценарием использования. Причем организовать ее можно и поверх базы данных общего назначения. Правда, это не самая лучшая история. Вот почему.
С задачей организации очереди сталкиваются многие, берут обычную базу данных и делают в ней простейшую структуру типа такой:

Когда нам необходимо что-то положить в очередь, мы делаем INSERT — запрос, который складывает события очередь. С другой стороны обработчик делает SELECT самого старого события, что-то с ним делает, и когда завершает работу, удаляет событие из нашей таблицы DELETE. Вот, казалось бы, и готова очередь на MySQL. И этот проход работает, многие разработчики идут именно по этому пути. Но в нем есть целая прорва нюансов.
При рассмотрении частного примера, приведенного выше, возникают вопросы: а что делать, если у нас несколько обработчиков, которые исполняют задачи конкурентно, и как сделать так, чтобы задачи, находящиеся в работе, блокировались? Если один обработчик взял задачу в работу, нужно чтобы второй параллельные не обрабатывал. Если мы задачи заблокируем, то надо уметь их разблокировать в случае, когда совсем обработчик умер и не реагирует на запросы. На все вопросы можно придумать решения, но только путем серьезного усложнения структуры таблиц в базе данных и написания дополнительного кода. И эти задачи также можно решить путем добавления новых полей и команд. Только зачем «изобретать велосипед»? Даже создатели некоторых баз данных против их нецелевого использования. Например, в документации к Apache Cassandra есть специальный абзац, который не рекомендует ее использование для организации очередей. Вы тратите свои ресурсы на создание собственного фреймворка, ищете баги и отлаживаете его, а в итоге получаете решение, которое уже есть на рынке и готово к работе по нажатию одной кнопки.
Сервис очередей — это готовый сервис, который решает свою узкую задачу. И, как в случае с большинством других специализированных инструментов, такой сервис решает свою узкую задачу лучше, чем инструменты общего назначения.
Преимущества сервиса очередей Yandex Message Queue
Yandex Message Queue (YMQ) — это сервис очередей, который входит в состав платформы Yandex.Cloud. Он построен по serverless-принципу, а значит надежен, отказоустойчив, способен выдерживать высокие нагрузки, не требует администрирования, а оплачивается по модели pay-as-you-go — сколько использовали, за столько и заплатили. Достаточно в несколько кликов создать очередь, и можно сразу начинать с ней работать. В YMQ реализованы очереди двух типов: стандартные неупорядоченные очереди и очереди FIFO (First In, First Out), а также добавлена поддержка API Amazon SQS — все инструменты, которые работают с очередями от Amazon, также будут работать и с YMQ.
Так как YMQ является частью serverless-стека Yandex.Cloud, то он прекрасно работает с другими его компонентами. Они — как кирпичики, из которых можно очень быстро и просто собрать готовые сервисы с минимумом кодирования и изобретения костылей. Yandex Message Queue имеет готовые интеграции, но самое важное — позволяет повесить на себя триггер для подключения функций Yandex Cloud Functions. Можно даже не разбираться в API YMQ, а отправлять в нее и из нее сообщения прямо в подключенные функции.
От теории к практике — пишем в конвертер видео в GIF
В качестве примера использования очереди Yandex Message Queue мы реализуем небольшой проект, который позволит пользователям нашего сервиса конвертировать видео по ссылке в файл GIF. Такая задача хорошо демонстрирует один из сценариев использования очереди, потому что она CPU-intensive — сильно загружает процессор. Чем больше размер видео и лучше его качество, тем больше надо ресурсов для его обработки. Конвертирование может занимать от десятков секунд до нескольких часов, и без использования очередей не добиться стабильной работы сервиса. Почему?
Если бы мы решали эту задачу в лоб, то она выглядела бы так: пользователь вставляет в сервис ссылку на видео и ожидает, что тот ему синхронно вернет ссылку на готовый GIF. Но такой способ работает плохо. Синхронное ожидание на TCP-соединении — ненадежная история: соединение в любой момент может оборваться, например у пользователя «моргнет» Wi-Fi. Когда коннект рвется, пользователю приходится делать новый запрос и снова ждать конвертации, а вам на стороне сервера — выполнять задачу заново. Если связь плохая, то пользователь может никогда не дождаться выполнения задачи, а будет видеть постоянные ошибки. Это первая проблема.
Вторая проблема связана с тем, что конвертация видео — ресурсоёмкая задача. Если на сервис придет одновременно десять пользователей и каждый захочет сконвертировать свое длинное видео, может банально не хватить мощностей. И при такой примитивной реализации сервиса кто-то из пользователей сразу получит ошибку, что конвертация невозможна. Чтобы избежать этих проблем, мы и добавляем в архитектуру сервиса очередь.
Вот как будет работать наш сервис в serverless-стеке с использованием очереди:
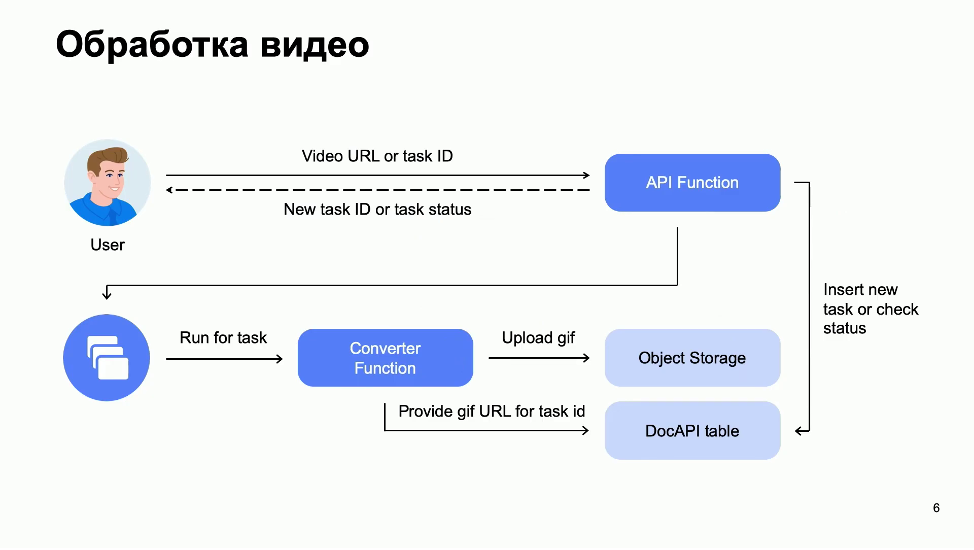
Пользователь приходит в нашу функцию (API Function) и создает задачу на конвертацию видео: вводит URL со ссылкой на файл. Для корректной работы нашего тестового сервиса исходный файл должен лежать на Яндекс.Диске. Вместо того чтобы сразу начинать синхронно работать, мы генерируем идентификатор задачи и говорим пользователю: «Вот твоя задача, жди ее выполнения где-то там за дверью». Тем временем наша функция складывает это событие в два места: непосредственно в очередь, ставя задачу «сконвертировать видео и отписаться в такой-то идентификатор, когда итоговое видео будет готово», а также в DocAPI-таблицу, то есть дополнительную базу данных, где мы также отмечаем, что по идентификатору задачи выполняется конвертация видео. Использование дополнительной обычной базы данных для проверки пользователем состояния задачи необходимо из-за того, что YMQ — специализированная система и она не позволяет осуществлять поиск по ключу. Пользователь ждет с идентификатором на руках, периодически, например раз в 5 секунд, обращаясь по нему в функцию с запросом, не готова ли задача. Когда задача будет выполнена, он получит ссылку на скачивание файла GIF.
В это время внутри нашего сервиса происходит следующее. На очередь у нас повешен обработчик Converter Function. Это функция, которая через триггер подключена к очереди и по мере своих возможностей забирает из очереди задачи и конвертирует видео в GIF. Когда очередная задача выполнена, мы выгружаем готовую гифку в Object Storage, а в таблице DocAPI отмечаем флажком, что такая-то задача выполнена, и записываем туда ссылку на скачивание файла.
В нашей схеме сервиса помимо YMQ мы задействовали другие serverless-сервисы — Cloud Functions и Object Storage — которые легко настраиваются с помощью консоли Yandex.Cloud. А также используем DocAPI Table — это API к Yandex Database в serverless-режиме, она также совместима с Amazon DynamoDB.
Реализация проекта в Yandex.Cloud
Заходим в консоль Yandex.Cloud и в каталоге проекта создаем сервисный аккаунт, которому назначаем все требуемые для реализации проекта роли. В продакшене так делать не рекомендуется, но для упрощения примера поступим именно так.

ymq.reader и ymq.writer (чтение и запись YMQ);
storage.viewer и storage.uploader (чтение и запись из Object Storage);
ydb.admin (права администратора YDB, чтобы взаимодейсвовать с DocAPI-таблицей);
ydb.admin;
serverless.functions.invoker (роль Functions.invoker, чтобы вызывать функции);
lockbox.payloadViewer (для работы с Lockbox).
Далее создаем статический ключ доступа, который нужен для работы с Amazon-совместимыми API. Так как у нас в проекте три таких API, ключ нам обязательно потребуется.


Чтобы донести эти ключи до функции, воспользуемся новым сервисом хранения секретов платформы Yandex.Cloud — Yandex Lockbox. Он позволяет безопасно доставлять секреты куда угодно. В сервисе мы создаем секрет и сохраняем в нем под разными именами наши два ключа: ACCESS_KEY_ID и SECRET_ACCESS_KEY.

Теперь перейдем к созданию необходимых для реализации проекта ресурсов:
Yandex Message Queue;
Yandex Object Storage;
DocAPI Table;
Yandex Cloud Finctions.
Начнем с создания очереди Yandex Message Queue. Задаем имя, выбираем тип «Стандартная» (дополнительная гарантия fifo для нашего тестового проекта не важна и fifo-очередь не позволяет создавать триггеры). Не включаем в тесте «Перенаправлять недоставленные сообщения», но в «проде» эту галочку лучше ставить. Когда эта функция выключена, при появлении сообщения, вызывающего падение или выход за лимит исполнения нашей функции, триггер будет бесконечно по кругу пытаться подсовывать это сообщение в функцию, что приведет к бесцельной трате денег. Активация возможности «Перенаправлять недоставленные сообщения» с настройкой Dead Letter Queue позволит после нескольких неудачных попыток такие «сломанные» сообщения отправлять в DLQ, где их можно будет проанализировать в ручном или автоматическом режиме.

Теперь создаем новую serverless-базу данных. В ней нам нужна одна табличка с типом «Документная таблица» и одним ключом. Такой тип необходим, чтобы иметь возможность работать с DynamoDB API.


Последнее — создаем бакет в Object Storage с дефолтными настройками.

Ресурсы созданы, переходим к написанию кода и взаимодействия с API.
Создаем первую функцию для работы с API. Писать код мы будем на Python, именно это язык выбираем в редакторе функции. В функции описываем зависимости. Поскольку мы будем работать с разными API, нам надо добавить зависимости SDK. Для работы с сервисом Yandex Lockbox нам потребуется библиотека yandexcloud, которая содержит SDK для работы с большинством сервисов Яндекс.Облака. А вот для работы с сервисами, реализующими AWS compatible API — мы добавляем библиотеку boto3.


Код функции целиком посмотреть тут. Остановимся на основных этапах ее выполнения.

Сначала мы извлекаем секреты из Lockbox и переносим его в переменную функции:
response = lockbox.Get(GetPayloadRequest(secret_id=os.environ['SECRET_ID']))И читаем ключи:
for entry in response.entries:
if entry.key == 'ACCESS_KEY_ID':
access_key = entry.text_value
elif entry.key == 'SECRET_ACCESS_KEY':
secret_key = entry.text_value
if access_key is None or secret_key is None:
raise Exception("secrets required")
Инициализируем сессию boto3, а затем все остальные компоненты:
ymq_queue = get_boto_session().resource(
service_name='sqs',
endpoint_url='https://message-queue.api.cloud.yandex.net',
region_name='ru-central1'
).Queue(os.environ['YMQ_QUEUE_URL'])— передаем через переменные в функцию URL очереди.
Описываем нашу табличку DocAPI с передачей endpoint в функцию через переменную окружения:
docapi_table = get_boto_session().resource(
'dynamodb',
endpoint_url=os.environ['DOCAPI_ENDPOINT'],
region_name='ru-central1'
).Table('tasks')Инициализируем клиент Object Storage:
storage_client = get_boto_session().client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net',
region_name='ru-central1'
)Теперь посмотрим, как работает код, который описывает поведение нашей функции, реализующей API.
В нем три функции:
create_task(src_url) — создает задачу на конвертацию видео. Принимает от пользователя URL видео для конвертации, генерирует идентификатор задачи, складывает запись в табличку DocAPI со статусом «не сделана», кладет задачу также в YMQ, ставит событие, что надо обработать видео.
get_task_status(task_id) — проверка статуса задачи. Принимает от пользователя идентификатор задачи, идет в табличку и смотрит статус готовности задачи. Если готова, то возвращает пользователю ссылку на готовый GIF.
handle_api(event, context) — точка входа в функцию. Что будет производить функция по запросу пользователя: конвертировать или проверять статус готовности.
Далее вставляем этот код в функцию, заполняем дополнительные поля и переменные SECRET_ID, YMQ_QUEUE_URL, DOCAPI_ENDPOINT.

Функция готова, можно ее протестировать. Задаем входные данные в формате запроса JSON со ссылкой на исходное видео. На выходе получаем идентификатор задачи. Если его проверить, то статус будет false, так как задачу еще никто не обрабатывает: обработчик мы не подключили.

В интерфейсе YMQ мы видим, что сообщений в очереди стало «1», так как наше сообщение попало в очередь и ждет, пока будет обработано.

Теперь создаем вторую функцию, которая непосредственно будет обрабатывать видео. Также в интерфейсе создаем новую функцию и выбираем язык Python.

Код функции целиком посмотреть тут. Остановимся на основных моментах.
download_from_ya_disk(public_key, dst) — скачивание видео с Яндекс.Диска.
upload_and_presign(file_path, object_name) — выгрузка видео в Object Storage и генерация presigned url для него.
handle_process_event(event, context) — точка входа нашей обрабатывающей функции из очереди. Получаем идентификатор, само видео, вызываем конвертер ffmpeg с параметрами, получаем готовый GIF, выгружаем его вспомогательным методом и отмечаем в табличке DocAPI по идентификатору, что задача выполнена.
Чтобы использовать функцию ffmpeg, которой нет в стандартной поставке функции, загружаем статический бинарник для архитектуры AMD64 с официального сайта ffmpeg.org. Размер файла довольно большой, а в функциях есть ограничения на размер исходника, который можно передать напрямую через интерфейс. Если размер превышает 3,5 МБ, то его необходимо загружать через Object Storage.
Кладем исходники функции (requirements.txt, index.py) и бинарник ffmpeg в архив src.zip и загружаем его в бакет Object Storage.


А в редакторе функции указываем способ доставки исходников — наш бакет, объект (архив) и точку входа, другие параметры и переменные.

Теперь создаем триггер для начала обработки события. Проверяем, что выбран тип триггера Message Queue и нужная очередь сообщений, а также названия функции и сервисного аккаунта — ffmpeg-converter и ffmpeg соответственно.

Очередь по триггеру передала задачу в обработку, что можно увидеть в окне «Обзор» — поле «Сообщений в обработке».

Убедиться, что задача выполняется, можно в окне «Логи» нашей функции.

Снова переходим в окно тестирования и проверяем статус задачи через нашу функцию API, получаем результат со ссылкой на скачивание готового файла GIF. Переходим по ссылке и скачиваем результат, созданный по заданным в коде параметрам ffmpeg.

Таким образом мы решили с помощью serverless-стека Yandex.Cloud задачу по конвертированию видео в GIF с использованием сервиса Yandex Message Queue. Такой способ создания приложений удобен способом оплаты pay-as-you-go, когда вы платите только за выполненные операции, а также не требует администрирования, отказоустойчив и безопасен.
Запись вебинара вы можете найти по этой ссылке: https://www.youtube.com/watch?v=uyIMvEtr3cI
Инструкция и код выложены в нашем GitHub: https://github.com/yandex-cloud/examples/tree/master/serverless/video-converting-queue
П.С.
Сейчас на наши serverless-сервисы действует программа free tier, а значит эксплуатация небольших проектов будет бесплатной. Заходите в наше serverless-комьюнити, где разработчики делятся своим опытом, рассказывают истории успеха, помогают решать задачи и осваиваться в новой технологии.
pavelpromin
Я правильно понимаю, что безсерверные сервисы Яндекса - это попытка повторить aws и по сути сейчас они не могут предложить ни лучшие сервисы ни лучшие цены по сравнению с aws?!
Или все же есть какие-то киллерфичи в Я?(ФЗ не в счет)