

Трудно в одном тексте, с одной стороны, описать всё необходимое для разработки даже самого простого навыка Алисы, а с другой — показать разработку на serverless-стеке так, чтобы и новичку было не слишком сложно, и заядлому девелоперу не пришлось скучать. Но попробую осилить эту задачу, написав навык на Go. И будет у меня семейный список дел.
Какое приложение делаем
Мы разработаем навык для голосового помощника «Список дел». С помощью Алисы вы сможете создавать список дел, редактировать его, добавлять и удалять элементы. Кроме того, можно будет делиться списками дел через сайт в облаке. Вот что у нас должно получиться.
А теперь поэтапно пройдём весь процесс создания навыка — от настройки рабочей среды до разработки клиентской и серверной частей нашего приложения.
Архитектура сервиса
Концептуально архитектура нашего приложения на serverless-стеке не сильно отличается от архитектуры на классическом наборе компонентов. Пользователь приходит или через браузер, или через Алису — платформу Яндекс.Диалоги. В нашем случае платформа выступает как элемент сервиса Cloud Functions, куда можно загрузить свой код.
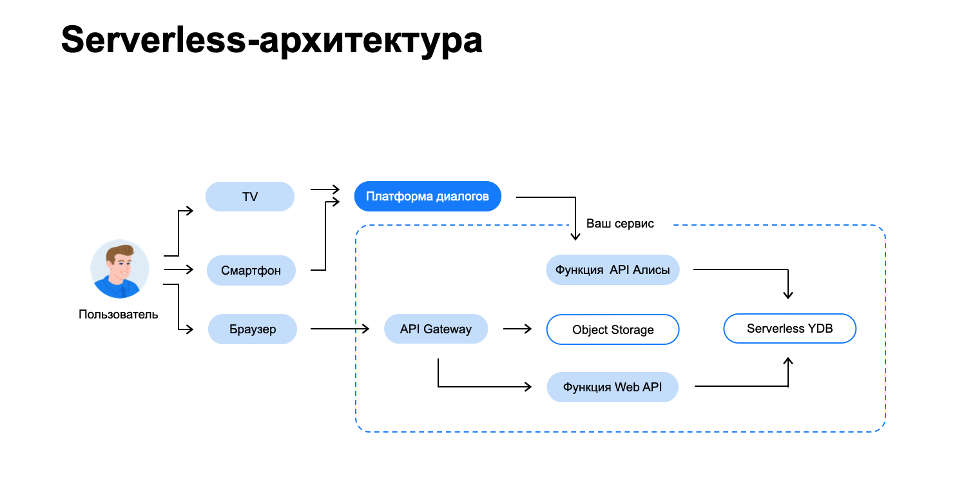
С начала загрузки код будет доступен для вызова в облаке. В момент вызова экземпляр функции аллоцируется и исполняет запрос пользователя. Чем больше пользователей, тем больше экземпляров аллоцируется.
Экономическую особенность использования serverless можно описать известным выражением — pay-as-you-go. Нет запросов — нет денежных трат, потому что плата взимается за время исполнения функции и за количество вызовов. В этом ключевое отличие serverless от классической архитектуры. Также в serverless-архитектуре отсутствуют компонент load-balancer и масштабирование со стороны разработчика — их предоставляет Yandex.Cloud.
Настраиваем рабочую среду
Для создания нашего приложения мы по максимуму используем serverless-стек Yandex.Cloud — все вычисления будут производиться в функциях, данные храниться в Yandex Database, а интеграция выполняться через API Gateway. Так мы избавим себя от создания и обслуживания виртуальных машин, а также уменьшим финансовые затраты.
Для нашего проекта мы воспользуемся следующими сервисами Yandex.Cloud:
Yandex Cloud Functions — при помощи этого сервиса мы можем запускать код в виде функции;
Yandex Database — распределённая NewSQL СУБД с поддержкой бессерверных вычислений;
Yandex Cloud API Gateway — сервис для создания API-шлюзов. Поддерживает спецификацию OpenAPI 3.0 и набор расширений для интеграции с другими облачными сервисами;
Yandex Object Storage — объектное хранилище;
Yandex KMS — сервис для шифровки и дешифровки секретов;
CLI Yandex — командная строка Yandex;
API Yandex ID + OAuth 2.0 — сервисы для авторизации и аутентификации.
Помимо платформенных сервисов, для разработки приложения нам потребуются дополнительные приложения, утилиты и пакеты:
Библиотеку restful-react можно установить позже пакетным менеджером Node/JS/Go и не беспокоиться о ней заранее.
Чтобы работать с serverless-стеком Yandex.Cloud, вы должны иметь аккаунт Yandex.Cloud и пройти процедуру авторизации.
Устанавливаем зависимости
Использование зависимостей упрощает одновременную работу с несколькими объектами. Сервис Cloud Functions на этапе сборки автоматически устанавливает зависимости, необходимые для работы функции, во время создания её новой версии. Причём поддерживаются два способа автоматического управления зависимостями — модули mod и утилита dep. Подробнее об управлении зависимостями можно прочитать в документации.
Для установки зависимостей при помощи модулей нужно загрузить из репозитория файл go.mod вместе с исходным кодом функции. В нём мы будем управлять зависимостями нашего бэкенда. Наш полный список выглядит внушительно, на первый взгляд:
require (
github.com/go-openapi/errors v0.20.0
github.com/go-openapi/loads v0.20.2
github.com/go-openapi/runtime v0.19.26
github.com/go-openapi/spec v0.20.3
github.com/go-openapi/strfmt v0.20.0
github.com/go-openapi/swag v0.19.14
github.com/go-openapi/validate v0.20.2
github.com/golang/protobuf v1.4.3 // indirect
github.com/google/go-cmp v0.5.4 // indirect
github.com/gorilla/securecookie v1.1.1
github.com/gorilla/sessions v1.2.1
github.com/jessevdk/go-flags v1.4.0
github.com/stretchr/testify v1.7.0
github.com/texttheater/golang-levenshtein v1.0.1
github.com/yandex-cloud/go-genproto v0.0.0-20210211094722-b4ab90f1132d
github.com/yandex-cloud/go-sdk v0.0.0-20210211095836-1e646debd48a
github.com/yandex-cloud/ydb-go-sdk v0.0.0-20210203152813-253585cf1c0d
go.uber.org/zap v1.16.0
golang.org/x/net v0.0.0-20210119194325-5f4716e94777
google.golang.org/grpc v1.35.0 // indirect
)Инициализируем приложение
Перед тем как писать наше приложение, разберём, как инициализировать функцию, написать обработчик и разместить приложение. Начнём с простого: напишем hello world, но с возможностями для расширения в настоящее приложение.
Чаще всего простые обработчики делают без какого-либо состояния, например так:
func Handler(_ context.Context, req map[string]string) (string, error) {
return fmt.Sprintf("Hello, %s!", req["name"])
} Но для функции можно задать глобальное состояние и прочитать его при обработке следующего запроса. Таким образом, когда запросы будут приходить в функцию, она не будет «вытеснена». Разница с классическими приложениями в том, что функции с сохранённым состоянием можно использовать для кешей и инициализации «тяжёлых» компонентов, таких как подключения к БД. Но хранить там важную информацию, потеря которой приведёт к проблемам, нежелательно.
Пример написания нашего обработчика можно посмотреть тут.
Код пользователя в Cloud Functions не находится в постоянно запущенном состоянии — его запускает платформа функций, когда в простаивающую функцию вдруг приходят запросы или когда нагрузка растёт и требуется масштабирование функции. Первый запуск функции принято называть cold start. Если такой запуск происходит, то приложение пользователя фактически инициализируется с нуля.
Конкретно для Go это не очень плохой сценарий, потому что язык использует AOT-, а не JIT-компиляцию и в общем накладные расходы на запуск Go-приложения не сказать что огромные.
Но приложению так или иначе нужно стартовать — в нашем случае мы должны инициализировать все логические компоненты приложения (что опять же довольно быстро), а также нужно сделать пару «тяжеловесных» действий:
Расшифровать секреты — для этого мы используем KMS, он, конечно, работает быстро, но это в любом случае поход по сети.
Инициализировать соединение до Yandex Database (об этом чуть позже). Далее мы будем переиспользовать это соединение, но в первый раз его нужно установить — и это тоже может красть драгоценные миллисекунды.
После подготовки обработчика мы складываем все компоненты нашего приложения в структуру app и заворачиваем эту структуру в глобальный singleton. Таким образом приложение станет инициализироваться только при cold start, а при постоянном потоке запросов будет обрабатывать каждый очередной запрос максимально быстро, как в обычном серверном приложении. Весь процесс инициализации нашего приложения выглядит вот так.
Разворачиваем через Terraform
Простые короткие функции проще всего редактировать через веб-интерфейс. Но наш сервис достаточно велик, и кода в нём будет много, поэтому мы воспользуемся Terraform. В качестве референса вы можете посмотреть Terraform-спецификацию деплоя конечной версии проекта по этой ссылке.
Перед развёртыванием кода деплой надо протестировать. Terraform деплоит функцию, и мы убедимся, что она работает, вызвав её с помощью yc serverless function invoke. В процессе выполнения потребуется OAuth token — это токен, выданный в облаке при прохождении процедуры аутентификации. О том, как получить текущий OAuth token, можно прочитать в документации. Срок жизни OAuth-токена — один год. После этого необходимо получить новый OAuth-токен и повторить процедуру аутентификации.
Разберём на несложном примере, как это работает. Для этого возьмём и выполним простой Terraform-рецепт для hello world обработчика:
## Инициализируем:
terraform init --var yc-token=<OAuth-токен облака>
--var folder-id=<id folder в Yandex.Cloud>
## Деплоим:
terraform apply --var yc-token=<OAuth-токен облака>
--var folder-id=<id folder в Yandex.Cloud> Когда деплой закончится, Terraform выдаст ответ:
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Outputs:
function-id = "d4e3rf325cn81ckd5484" После этого можно вызвать функцию, используя уникальный идентификатор function-id, и убедиться в корректности её работы:
yc serverless function invoke d4e3rf325cn81ckd5484 Теперь можно разворачивать приложение, заранее получив OAuth-токен для работы с Yandex.Cloud с помощью запроса к сервису Яндекс.OAuth.
terraform apply -var-file ./variables.json -var yc-token=<OAuth token>Готовим базу данных
В нашем проекте мы используем распределённую NewSQL СУБД с поддержкой бессерверных вычислений — Yandex Database (YDB). Это собственная разработка команды Яндекса. YDB сочетает высокую доступность и масштабируемость с поддержкой строгой консистентности и ACID-транзакций, а также легка в обслуживании.
Но главное, она поддерживает режим бессерверных вычислений и вы будете оплачивать только хранение и операции с данными. До октября 2021 года на специальном тарифе миллион операций в месяц предоставляются бесплатно. Подробнее о Yandex Database можно почитать у моего коллеги.
Для нашего навыка мы создаём в базе данных три таблицы:
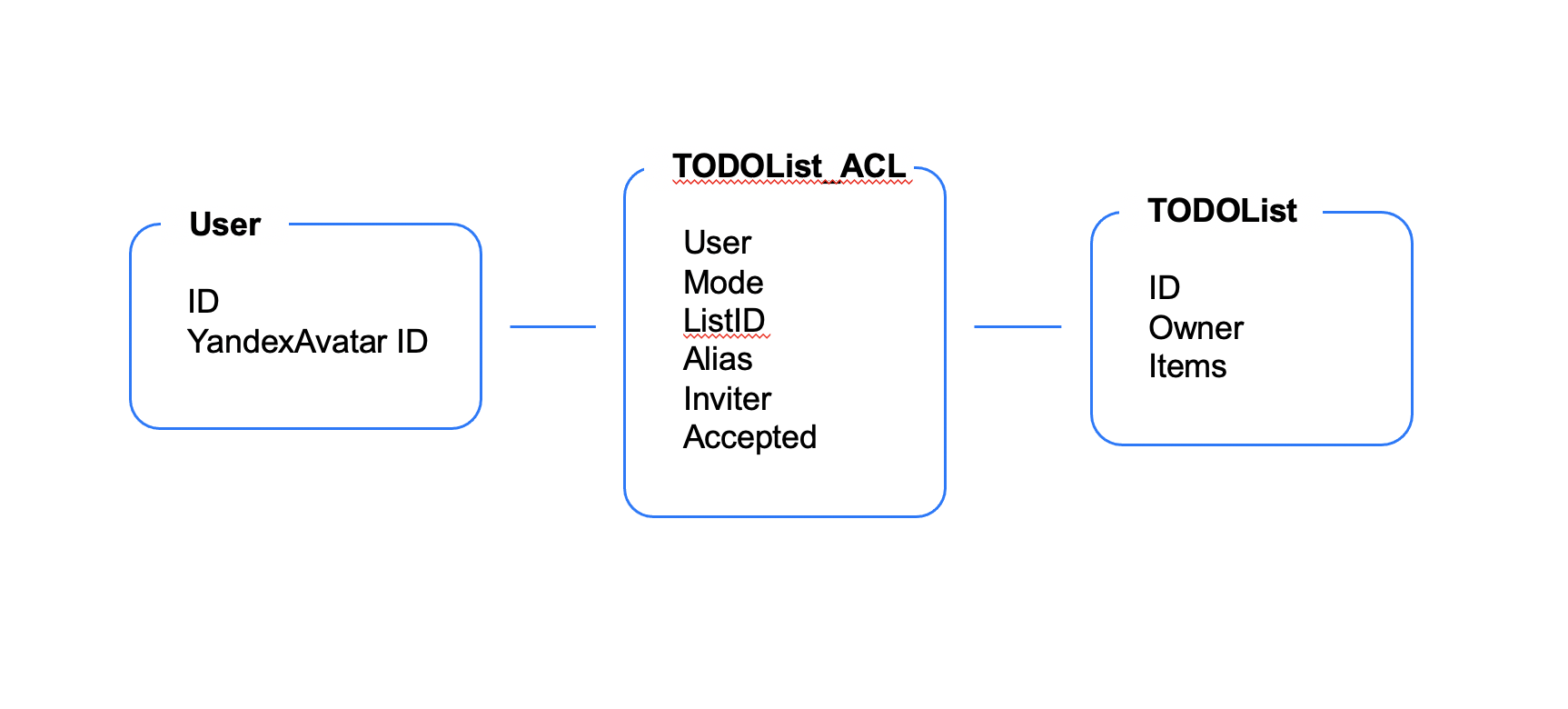
User — таблица пользователей списка дел;
TODOList_ACL — таблица связи. Она нужна нам, чтобы узнавать, как пользователь связан с разными списками;
TODOList — таблица элементов списка дел.
CREATE TABLE `user`
(
id string,
name utf8,
yandex_avatar_id string,
PRIMARY KEY (id)
);
CREATE TABLE `todolist_acl`
(
user_id string,
mode string,
list_id string,
alias utf8,
accepted bool,
inviter string,
PRIMARY KEY (list_id, user_id),
INDEX UserToListACL GLOBAL ON (user_id)
);
CREATE TABLE `todolist`
(
id string,
owner_user_id string,
items Json,
PRIMARY KEY (id)
);
COMMIT; 
Пишем код для работы с базой данных
Теперь нам надо написать код для обращения к нашей базе данных. Забираем из этой папки файлы с кодом для каждой из сущностей и помещаем их в свой проект или создаём отдельные файлы и копируем только код. Дальше описываем config для входа в БД напрямую из функции, если вы скопировали весь пакет db. Переделываем обработчик и дополняем рецепт деплоя.
Для проверки вызываем функцию командой:
yc serverless function invoke d4e3rf325cn81ckd5484 -d '{"user": "test-user"}' В результате вызова получаем новую запись в таблице базы данных. Теперь необходимо настроить бизнес-логику приложения при работе с базой данных, для этого создадим два интерфейса.
Интерфейс Repository будет содержать простые методы для работы с базой данных, где каждый метод делает что-то только с одной таблицей.
type Repository interface {
GetTODOList(ctx context.Context, id model.TODOListID) (*model.TODOList, error)
SaveTODOList(ctx context.Context, list *model.TODOList) error
DeleteTODOList(ctx context.Context, id model.TODOListID) error
SaveACLEntry(ctx context.Context, entry *model.ACLEntry) error
ListACLByUser(ctx context.Context, id model.UserID) ([]*model.ACLEntry, error)
ListACLByList(ctx context.Context, id model.TODOListID) ([]*model.ACLEntry, error)
SaveUser(ctx context.Context, user *model.User) error
GetUser(ctx context.Context, id model.UserID) (*model.User, error)
GetACL(ctx context.Context, userID model.UserID, listID model.TODOListID) (*model.ACLEntry, error)
DeleteACL(ctx context.Context, userID model.UserID, listID model.TODOListID) error
}Второй — более высокоуровневый интерфейс Service. В нём уже есть взаимодействие с авторизацией и с несколькими таблицами сразу. Это уже действие, которое пользователь может делать на сайте или через Алису.
type Service interface {
Create(ctx context.Context, req *ListCreateRequest) (model.TODOListID, errors.Err)
Get(ctx context.Context, req *ListGetRequest) (*model.TODOList, *model.ACLEntry, errors.Err)
AddItem(ctx context.Context, req *ItemAddRequest) errors.Err
RemoveItem(ctx context.Context, req *ItemRemoveRequest) errors.Err
GetUserLists(ctx context.Context, req *GetUserListsRequest) ([]*model.ACLEntry, errors.Err)
GetListUsers(ctx context.Context, req *GetListACLRequest) ([]*model.ACLEntry, errors.Err)
InviteUser(ctx context.Context, req *InviteRequest) errors.Err
AcceptAndRenameList(ctx context.Context, req *AcceptAndRenameListRequest) errors.Err
RemoveList(ctx context.Context, req *RemoveListRequest) errors.Err
RevokeInvitation(ctx context.Context, req *InvitationRevokeRequest) errors.Err
}Пишем код работы списка
Подобрались к самому важному — реализации методов работы списка.
func (r *repository) SaveTODOList(ctx context.Context, list *model.TODOList) error {
const query = `
DECLARE $id AS string;
DECLARE $owner_user_id AS string;
DECLARE $items AS json;
UPSERT INTO todolist(id, owner_user_id, items) VALUES ($id, $owner_user_id, $items);
`
itemsJson, err := json.Marshal(list.Items)
if err != nil {
return fmt.Errorf("serializing list items: %w", err)
}
return r.execute(ctx, func(ctx context.Context, s *table.Session, txc *table.TransactionControl) (*table.Transaction, error) {
tx, _, err := s.Execute(ctx, txc, query, table.NewQueryParameters(
table.ValueParam("$id", ydb.StringValue([]byte(list.ID))),
table.ValueParam("$owner_user_id", ydb.StringValue([]byte(list.Owner))),
table.ValueParam("$items", ydb.JSONValue(string(itemsJson))),
))
return tx, err
})
}Когда мы пишем код работы списка, то используем расстояние Левенштейна. Этот способ поиска по неточному совпадению — один из многих, которые подходят для решения нашей задачи. В чём она заключается и почему мы не можем просто искать список по названию?
Мы пишем навык для Алисы, с которой пользователь взаимодействует голосом. То, что он наговаривает, конвертируется в текст, и стопроцентной гарантии полного совпадения результата распознавания с тем, что есть в базе данных, быть не может. Поиск по неточному совпадению нам нужен для сопоставления распознанного текста с сохранённым в БД названием.
В приложении у нас есть бизнес-логика и два интерфейса над ней: Алисы с неточным распознаванием и веб — без этих особенностей. Почему же решение с неточным поиском находится в бизнес-логике, а не в коде для Алисы? Потому что в первую очередь мы создаём навык, и если пользователь сможет создать два списка с похожими названиями, то ему будет сложно их выбирать через Алису. Чтобы это исправить, мы вводим ограничение на схожесть названия в бизнес-логике. Благодаря этому даже частичное дублирование списков полностью исключено.
То есть сначала мы убеждаемся, что пользователь авторизован, затем проверяем, что список с таким названием не дублируется. И делаем это не равенством: начинаем искать в списках лучшие совпадения.
Авторизация и секреты
Так как наше приложение может работать с несколькими пользователями, то для них обязательно должна быть авторизация. Чтобы списки дел оставались приватными, кроме случаев, когда их создатель сам готов ими поделиться.
Воспользуемся инструментами авторизации Яндекса. Для нашего проекта это подходит, потому что мы делаем навык для Алисы. Схема авторизации выглядит так: новый пользователь авторизуется на Яндексе, а мы принимаем его логин как идентификатор пользователя на нашем сайте. Для этого используем Yandex OAuth 2.0 API и API Яндекс ID.
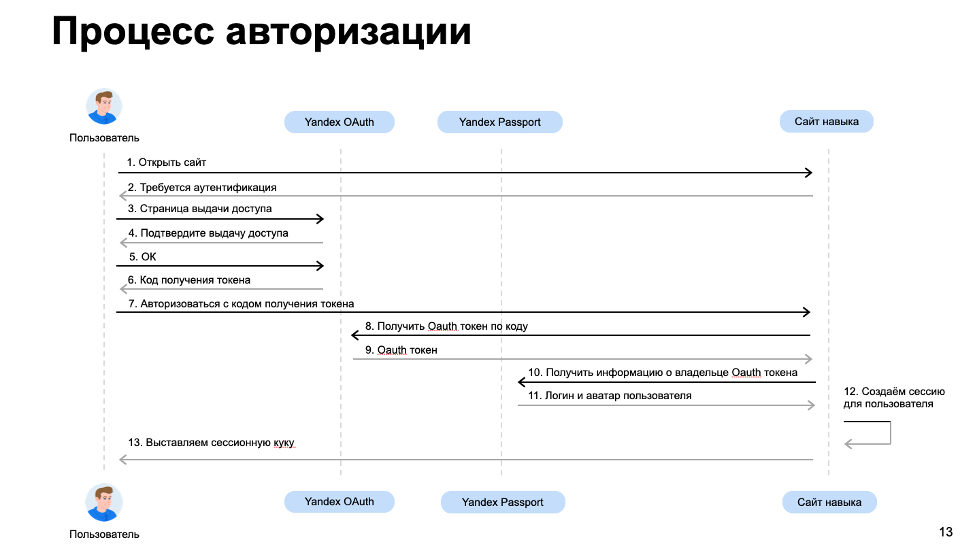
Мы не хотим, чтобы пользователь проходил авторизацию каждый раз, когда совершает какое-то действие на сайте. Поэтому применим механизм HTTP-сессий. Когда пользователь будет авторизовываться, мы запишем ему сессионную куку и положим в неё его Яндекс-логин. В дальнейшем мы будем авторизовывать его по этой куке, минуя API Яндекса. Для работы с куками используем библиотеку Gorilla Sessions.
Кроме этого, нам нужно передавать в приложение секретные значения — secret из Yandex OAuth и ключ шифрования, который используется при работе с HTTP-сессиями. Для шифрования и расшифровки секретов воспользуемся сервисом Yandex KMS. Ключи шифрования в KMS неизвлекаемые — ключ не может утечь, и расшифровать секрет можно только с соответствующим разрешением в Yandex.Cloud.
Разрешим сервисному аккаунту нашей функции использовать ключи шифрования.
Зашифруем наши секреты ключом KMS.
Запишем зашифрованные секреты в environment-переменные функции.
В коде функции расшифруем секреты с помощью Yandex Cloud SDK.
Заводим приложение в OAuth
Следующим шагом регистрируем новое приложение в https://oauth.yandex.ru/ .
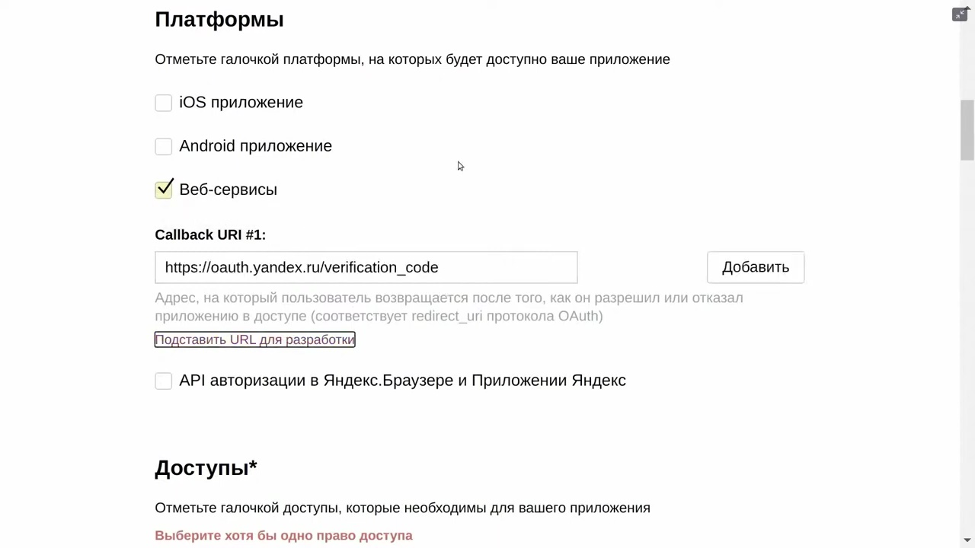
При заполнении формы отмечаем поле Веб-сервисы. В Callback URI указываем страницу редиректа, куда OAuth-сервис будет отправлять пользователя, когда тот подтвердит доступ, и технический домен API Gateway.
https://social.yandex.net/broker/redirect
<apigateway technical domain>/yandex-oauth Пишем спецификацию API 3.0
Cервис API Gateway позволяет декларативно описать HTTP API. В нём используется спецификация OpenAPI 3.0, к ней мы и прибегнем. Эта спецификация позволяет описать пути на вашем сайте и некоторые детали запроса, например форму ответа. В спецификации можно указать пути, по которым нужно идти в функцию или сделать что-то с объектами в хранилище Object Storage. Пользоваться спецификацией — это самый верный способ делать serverless-сайты.
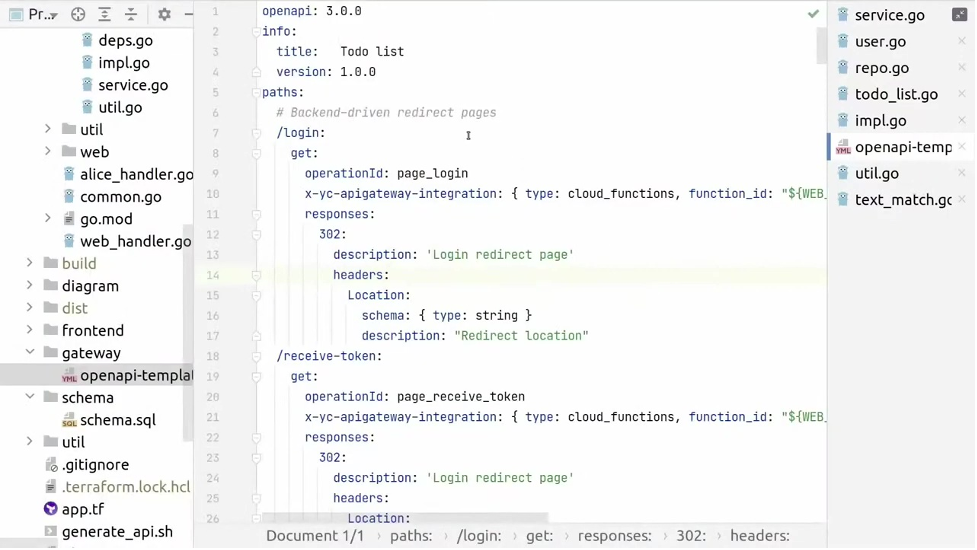
# Backend-driven redirect pages
/login:
get:
operationId: page_login
x-yc-apigateway-integration: { type: cloud_functions, function_id: "${WEB_FUNCTION_ID}", tag: $latest, service_account: "${GATEWAY_SA_ID}" }
responses:
302:
description: 'Login redirect page'
headers:
Location:
schema: { type: string }
description: "Redirect location"
/receive-token:
get:
operationId: page_receive_token
x-yc-apigateway-integration: { type: cloud_functions, function_id: "${WEB_FUNCTION_ID}", tag: $latest, service_account: "${GATEWAY_SA_ID}" }
responses:
302:
description: 'Login redirect page'
headers:
Location:
schema: { type: string }
description: "Redirect location"
parameters:
- name: state
in: query
schema: { type: string }
- name: code
in: query
required: true
schema: { type: string } Аналогичным образом производится настройка для всех остальных путей.
Можно сделать API Gateway и на более простой схеме, не указывая все формы ответа и запроса. Но хорошая спецификация, которая подробно описывает ваш API, позволяет генерировать вам клиентский и серверный код, а также документацию. Нам выгодно описывать схему максимально подробно, чтобы потом использовать её.
При создании шлюза создаётся служебный домен, по которому мы уже можем вызывать наш API Gateway, когда он перейдёт в статус running. К спецификации есть много утилит для разных языков, позволяющие генерировать разный код — валидацию, клиентский, серверный. В частности, для этого проекта мы выбрали две библиотеки: для бэкенда go-swagger и для фронтенда restful-react.
Работаем с серверной и клиентской библиотеками, загружаем статику в Object Storage
Теперь перейдём к разработке на Go серверной и клиентской частей нашего проекта.
Пишем серверную часть
Для Go генерируются модели и сервер, готовые обслуживать HTTP-запросы. Но так как наш сервер будет не на виртуальной машине, а в виде функции со своим API, то мы должны принять JSON-запрос и вернуть JSON-ответ. Посмотреть, как это делается, можно тут.

Пишем клиентскую часть
Мы можем сделать фронтенд с Node.js внутри функции, но пойдём более простым путём — завернём клиентскую часть в SPA, когда весь рендеринг будет выполняться на стороне клиента прямо в браузере, а для сервера надо только раздать статику и прописать API, что уже сделано. Для создания SPA воспользуемся библиотеками React и Bootstrap, чтобы оживить веб-приложение и не верстать таблички руками.
Для спецификации при помощи библиотеки restful-react сгенерировался файл, загружаем компоненты в бакет OS, к которому уже подключили API Gateway.
Что умеет Алиса: создаем навык
На своей стороне Алиса инкапсулирует распознавание речи, сама занимается text-to-speech и speech-to-text. Нам нужно реализовать простой API: Алиса приходит с JSON-запросом, а нам нужно вернуть JSON-ответ. Этот API подробно описан в документации. Для нас важно, что Алиса умеет нативно интегрироваться с Yandex Cloud Functions, поэтому и навык нам проще будет создать на функциях.
Идём в Диалоги и настраиваем навык. В главных настройках выбираем уже написанную функцию — навык интегрирован.
Авторизация в Алисе
Теперь нам необходимо связать пользователя нашего сайта с пользователем Алисы. Наша задача — дать пользователю возможность редактировать список через Алису, а потом делиться им через сайт. Для этого в Алисе есть настройки авторизации, и мы можем авторизовать пользователя на любом сервисе, который поддерживает OAuth 2.0. Поскольку мы авторизовались через сервис Яндекс.Паспорт, нам достаточно скопировать настройки в интерфейс Алисы.
Идентификатор приложения: id вашего Yandex OAuth приложения
Секрет приложения: секрет (пароль) вашего Yandex OAuth приложения
Authorization url: https://oauth.yandex.ru/authorize
URL for token receive: https://oauth.yandex.ru/token
URL for token refresh: https://oauth.yandex.ru/token
Интенты в Алисе
Интенты — это намерения пользователя, то, что он может хотеть от навыка. Они описаны в платформе Диалогов. Для нашего навыка это означает, что интенты приходят уже распознанные и распарсенные, поэтому нам гораздо проще с ними взаимодействовать.
Интенты дают Алисе контекст и улучшают распознавание речи. Они упрощают задачу на стороне кода навыка, описываются грамматикой и позволяют вычленять параметры. Их настройка производится на вкладке Интенты:
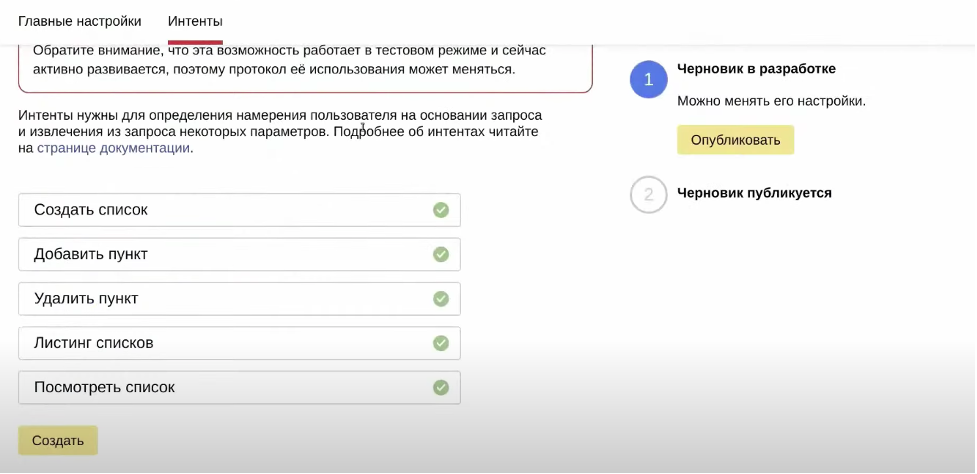
Кнопки в Алисе
Кнопки рассказывают пользователю о том, какие сценарии поддерживает ваш навык. Они позволяют на смартфоне отвечать Алисе в один тап. Кнопки не требуют эвристик и угадывания намерений пользователя на стороне навыка — работают как контролы в обычном UI. Вот пример ответа Алисе кнопками, а также простая функция на bash, которая позволяет потестировать кнопки:
echo '{
"version": "1.0",
"response": {
"text": "Посмотри на мои кнопки",
"buttons": [
{
"title": "Кнопка 1",
"payload": {
"a": "b"
}
},
{
"title": "Кнопка 2",
"payload": {
"a": "c"
}
}
]
}
}' Пишем навык
Для создания навыка нам необходимо описать структуру запроса и все нужные интенты, поддержать их приём на стороне навыка и написать обработчик, не забыв про авторизацию.
Храним сценарии
Сценарий можно описать автоматом. Когда у нас появляется состояние — например, пользователь добавляет что-то в список дел, — надо помнить о том, чтобы он не оказался в тупике, а мог сказать «Отмена» или вернуться в начальное состояние.
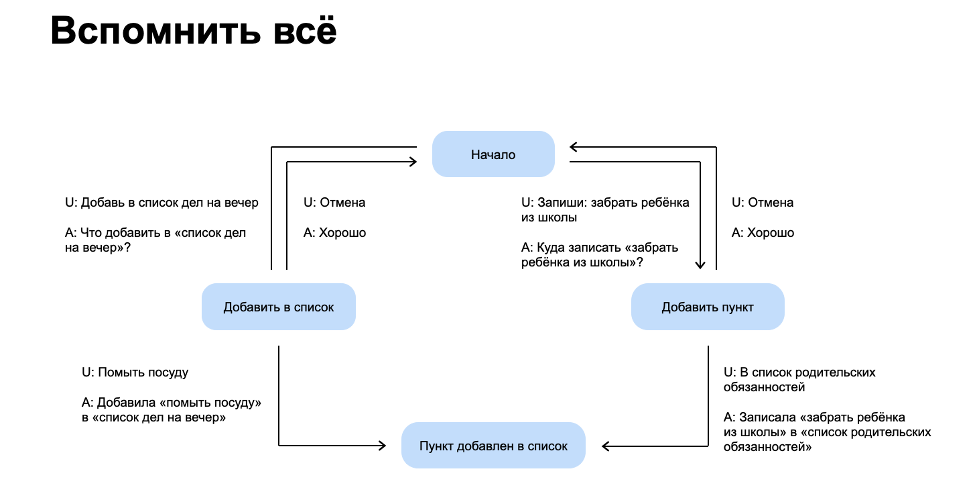
Вопрос в том, что делать с этим состоянием. Хранить в базе данных? В платформе Диалогов есть готовая фича — хранить состояние на стороне Диалогов (с ограничением в 1 КБ) и возвращать состояние в ответе. Оно придёт к нам в запросе.
Запрос:
type ReqState struct {
Session StateData `json:"session"`
}Ответ:
type Response struct {
Version string `json:"version"`
Response *Resp `json:"response"`
StartAccountLinking *EmptyObj `json:"start_account_linking"`
State *StateData `json:"session_state"`
}Код хранения сценариев — stateless handler
Код хранения сценариев — stateful handler
В статье мы с вами рассмотрели основные этапы разработки веб-приложения на Go в serverless-стеке на Yandex.Cloud для навыка Алисы. Подробное руководство и недостающие детали есть в видеозаписи и Readme на GitHub, где весь проект полностью доступен в исходных кодах.
Разрабатываем вместе с сообществом
В Yandex.Cloud есть живое и растущее serverless-комьюнити Yandex Serverless Ecosystem и официальный чат Yandex.Cloud в Telegram, где можно задавать вопросы и оперативно получать ответы от единомышленников и коллег. Присоединяйтесь!
И ещё в Yandex.Cloud действует программа free tier. Это позволяет реализовать массу проектов бесплатно, если не выходить за лимиты.