

Human-in-the-loop AI — это технология автоматизации, устраняющая многие проблемы разработки и внедрения машинного обучения.
Большинство проектов создания ИИ завершается провалом. 80% никогда не доберётся до стадии внедрения. Ещё большее количество никогда не вернёт вложенные в них инвестиции. Проблема заключается в том, что разработка ИИ — это процесс экспериментирования, однако при традиционном подходе об этом забывают.
Многие команды разработчиков сегодня начинают применять технологию под названием human-in-the-loop AI (HITL). Технология подразумевает, что можно быстро развернуть работающую модель с меньшим количеством данных и с гарантированно качественными прогнозами. Это похоже на чудо, но в своей статье мы расскажем, что такое HITL и как вы можете использовать эту технологию в собственных проектах разработки ИИ.
Если говорить в общих чертах, при HITL система ИИ и команда людей совместно работают над реализацией задачи.
Существует два основных режима HITL: офлайн-режим (люди помогают в обучении модели) и онлайн-режим (люди помогают модели создавать прогнозы). Режим следует выбирать в соответствии с типом решаемой вами задачи машинного обучения. Это позволит вам выполнять итерации для быстрого получения работающей модели и создать общую архитектуру системы с гарантированным уровнем качества.
Я накопил опыт создания таких систем, работая над конвейерами обучения Alexa, но с той же эффективностью их можно применять при разработке конвейеров ИИ для беспилотных автомобилей (как это происходит в Tesla) или при мелкомасштабной автоматизации задач бэк-офиса.
Начнём мы с рассмотрения традиционного подхода к машинному обучению, адаптированного из каскадного процесса разработки ПО, а уже потом перейдём к объяснению гораздо более качественных технологий обучения и внедрения при помощи HITL.
Типичный каскадный процесс обучения модели машинного обучения приводит к замедлению циклов итерации модели и фальстартам.
Типичный процесс обучения модели ML — это каскадный процесс, в котором следующий этап начинается после завершения предыдущего:
- ставится задача и определяется структура проекта
- собираются и вручную размечаются данные, часто этим занимается коллектив сотрудников
- дата-саентисты пробуют несколько архитектур моделей и техник обучения, от самых простых до самых мощных, чтобы проверить, какие из них подходят
- если выбранная архитектура и техника обеспечивают хорошую производительность, её развёртывают на сервере c API инференса.

В типичном процессе разработки машинного обучения этапы следуют один за другим, как в каскаде. Серьёзный недостаток такого подхода заключается в том, что на первых этапах он требует много времени для получения обратной связи, то есть циклы итераций очень медленные, а этапы необходимо повторять.
Этот подход кажется простым и чудесным, но в нём таится множество ловушек:
В начале задача часто задана нечётко
Невероятно сложно заранее спрогнозировать, какой будет наилучшая структура для проекта ИИ. Например, как сформулировать задачу (классификация, извлечение, сегментация и т. п.), какие признаки или ограничения нужны, требуется ли применять какую-то предварительную обработку? И так далее. Обычно только после исследования точности первоначальной модели задачу можно превратить в нечто более определённое с вероятностью высокой производительности.
Создание гайдлайнов аннотирования — итеративный процесс
Кроме того, сложно заранее понять, как необходимо аннотировать данные. Только при помощи выявления и исследования сложных примеров данных гайдлайны аннотирования можно превратить в качественный рабочий документ. Для сбора таких данных могут потребоваться недели или месяцы, особенно если эту задачу отдали на аутсорс.
Тестовые данные ≠ реальным данным, и выяснится это только в конце
При таком подходе над моделью работают, пока она не достигнет нужных критериев точности на тестовых данных, и только после этого её внедряют. Однако данные реального мира могут сильно отличаться от тех, которые были собраны изначально. Если не используется система мониторинга, эти проблемы могут проявиться только спустя много месяцев.
Аннотирование данных и обучение модели необходимо повторять
Компании-разработчики ИИ выяснили, что ML модель практически никогда нельзя реализовать полностью, чтобы потом забыть о ней. Её создание больше похоже на постоянные эксплуатационные расходы, ведь приходится многократно аннотировать новые данные для отслеживания текущей производительности модели и совершенствования системы. Так происходит, потому что со временем меняются данные и появляются новые потребности. Управление этими данными и их поддержка, скорее всего, будут основной задачей команды разработчиков ИИ.
Это требует много времени
Наверно, самая серьёзная проблема. Для этого процесса требуются различные команды, от дата-саентистов и специалистов в соответствующей области знаний до инженеров инфраструктуры, и весь цикл может занимать месяцы.
Поэтому если вы выберете такой подход, то для завершения проекта ИИ вам, скорее всего, потребуется слишком много времени.
В чём же секрет всех успешных проектов ИИ? Ну, откровенно говоря, у многих из них крупные бюджеты, позволяющие прорываться сквозь трудности этого подхода, несмотря на потраченное время, усилия и деньги. Они вкладывают большие средства в мониторинг и конвейеры данных, чтобы преодолеть эти недостатки и создать еженедельные/ежемесячные циклы повторного обучения на протяжении всего процесса.
Практичные компании начинают с приемлемого решения и быстро выполняют итерации. Это может обучение HITL, выполняемое для совершения итераций с моделью и данными, или какая-то разновидность внедрения HITL, благодаря которым они могут пользоваться системами задолго до того, как модели станут идеальными.
Обучение Human-in-the-loop — это agile-процесс построения машинного обучения
Разработчики систем human-in-the-loop вместо того, чтобы надеяться на плавный и линейный прогресс, для построения модели в обучении используют итеративный подход. Он аналогичен концепции agile-разработки ПО.
Рабочую модель обучают с первых элементов данных. В процессе добавления новых данных она часто обновляется. Модель и специалисты в соответствующей области знания совместно работают над построением, адаптацией и совершенствованием модели при помощи аннотирования данных или изменения задачи в процессе уточнения требований и производительности.
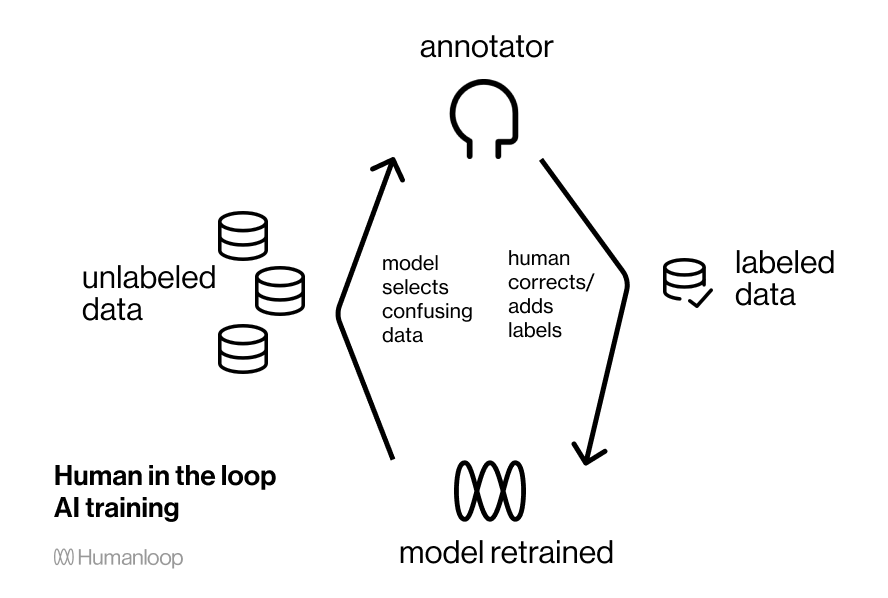
Активное обучение — это разновидность обучения human-in-the-loop, при котором данные для аннотирования выбираются моделью. Сосредоточившись на наиболее информативных данных, можно значительно снизить количество необходимых размеченных данных, а также итеративно работать над задачей и моделью, что получается быстрее.
У этого гораздо более быстрого цикла обратной связи, реализуемого благодаря обучению human-in-the-loop, есть множество преимуществ:
Быстрые итерации модели.
Мы в реальном времени получаем обратную связь о точности модели. Благодаря этому можно понять, требует ли задача адаптации и пригодятся ли дополнительные данные.
Обратная связь о том, как можно повысить качество данных.
Почти во всех случаях на конечную точность гораздо сильнее влияют данные, а не модель. В рамках масштабного процесса отладки данных модель может дать понять, где, по её мнению, данные были размечены неверно.
Снижение объёма требуемых аннотированных данных может быть десятикратным.
Благодаря активному обучению модель может выбирать наиболее информативные примеры данных, таким образом значительно снижая объём необходимых аннотаций.
Ускорение аннотирования.
Благодаря присутствию в цикле обратной связи модели можно также выполнять предварительную разметку данных. Это позволяет организовать рабочий процесс, в котором аннотирование превращается в задачу подтверждения/отклонения рекомендованных ИИ предсказаний.
Благодаря всему вышеперечисленному этот способ гораздо лучше подходит для обучения моделей. Серьёзным препятствием его реализации является сложность подготовки. Большинство интерфейсов аннотирования не позволяет работать вместе с обучаемой моделью, и приходится прикладывать значительные усилия для того, чтобы процесс обучения был достаточно скоростным и обеспечивал быструю обратную связь в цикле активного обучения. Кроме того, сложно добиться, чтобы активное обучение было качественным. Упрощённые методики выбора данных на основании неуверенности модели могут приводить к искажению модели или склонны обращать внимание на неинформативные, но шумные точки данных, что иногда может нанести больший вред, чем случайный выбор.
Внедрение HITL — это процесс обеспечения людьми обратной связи, помогающей модели создавать прогнозы
Машинное обучение очень хорошо справляется с частичным решением практически любой задачи. Проблема заключается в том, чтобы заставить ML решить задачу целиком.
Попытки совершенствования дают несущественную отдачу. Реальный мир полон сюрпризов, и чтобы справляться с ними, нужна способность адаптироваться.
Длинный хвост (здесь показан на примере поискового трафика) может составлять большинство данных. Производительность модели на этих редких по отдельности событиях может определять общую производительность, но сложно накопить достаточно данных обучения, чтобы покрыть все случаи.
Можно потратить бесконечное количество времени, ресурсов и денег, пытаясь разметить больше данных, чтобы повысить производительность модели до необходимой точности. Или же можно придумать структуру системы, в которой идеальная точность модели не требуется. Во втором случае и возможно использование HITL.
Для создания устойчивого к сбоям UX необходимо искать способы сделать систему в целом независимой от идеальных прогнозов модели; обычно этого достигают, позволив пользователю управлять системой ИИ и становиться частью цикла обратной связи.
Или же можно создать механизм контроля, например worker in the loop («работник в контуре управления»), проверяющий прогнозы в случае неуверенности модели.
Пользователи в контуре управления — это устойчивый к сбоям UX для многих систем ИИ
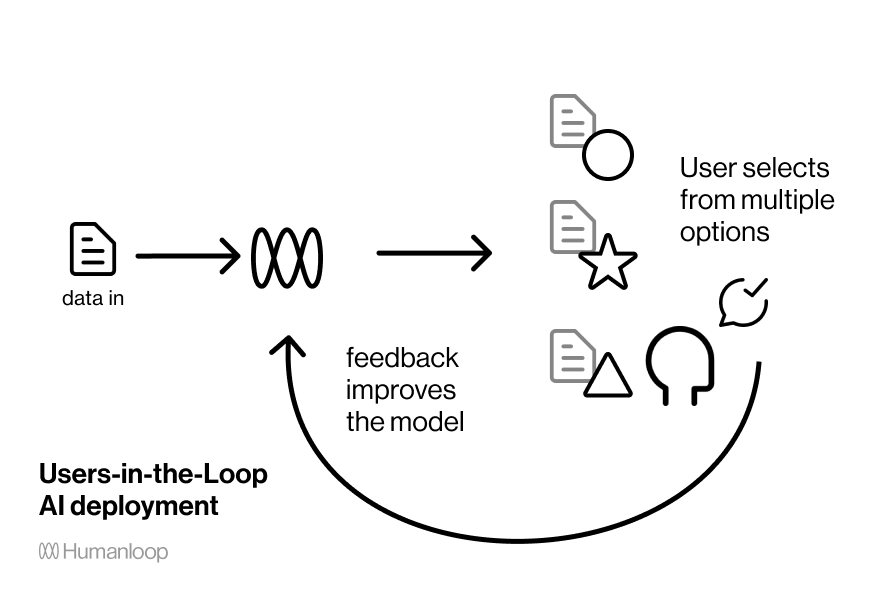
Структура системы «пользователь в контуре управления» даёт пользователю больший контроль для компенсации недостатков точности модели.
Для работы с несовершенной моделью нужно, чтобы её влияние было не таким сильным. Такая парадигма встречается очень часто. Например, системы рекомендаций демонстрируют пользователям ранжированный список, а не наилучший выбор, и выбор пользователя улучшает алгоритм на будущее. Сам поиск Google является примером этого — он отображает страницу со ссылками, из которых нужно выбирать, а не просто перенаправляет пользователя на первый результат. Smart Reply почтовой службы Gmail является устойчивым к сбоям UX — он не считает, что знает идеальный ответ, и вместо этого отображает несколько вариантов, которые пользователь может выбрать или отклонить.
Варианты, предложенные пользователю Twitter, как ответ на сообщение друга о том, что он сломал ногу: «Согласен», «Lol», «Точно подмечено».
Smart Reply в Gmail — это система «пользователь в контуре управления». Модель предлагает три варианта, которые пользователь может выбрать или игнорировать. Первый прототип автоматического ответа первым наилучшим вариантом, вероятно, был отклонён юридическим отделом компании.
Чтобы реализовать это, система ИИ должна передавать часть управления пользователю и записывать его ответ, чтобы он помог улучшить модель в будущем.
Workers-in-the-loop гарантирует высококачественные прогнозы, постепенно автоматизирующиеся со временем
Внедрение human-in-the-loop заключается в том, что команда из людей проверяет и корректирует прогнозы в случае неуверенности модели.

Внедрение worker-in-the-loop позволяет постепенно автоматизировать процессы, имея точный контроль над качеством результатов. Можно указывать пороговое значение уверенности модели, при котором требуется этап проверки человеком, и каждое вмешательство человека со временем совершенствует модель.
Внедрение worker-in-the-loop обеспечивает оптимальный компромисс между качеством, затратами и скоростью параллельно с автоматизированием процесса.
Представьте ползунок, на одном краю которого написано «скорость», а на другом — «качество». Если перетащить его на «скорость», то вы будете использовать только прогнозы модели, максимизировав скорость обработки и минимизировав затраты, но качество, вероятно, будет не очень высоким. Сегодня подобную архитектуру имеют многие системы ИИ. Перетащите ползунок на другой край, и вы перейдёте к работе с полным человеческим управлением. Эту структуру можно считать обёрткой вокруг человеческого рабочего процесса. Это гарантирует качество на уровне работы человека, но такая система будет более дорогой и намного более медленной.
Платформа внедрения worker-in-the-loop позволяет перетащить этот ползунок в любое подходящее вам положение. Он устанавливает порог степени уверенности модели, ниже которого управление передаётся команде людей. Система будет становиться лучше с каждым вмешательством человека.
Можно гарантировать высокое качество результатов. При большинстве внедрений мы стремимся к тому, чтобы основная часть данных обрабатывалась автоматически. Мы хотим, чтобы механизм контроля людьми использовался только для редких примеров данных. Или же можно установить очень высокий порог, чтобы этап контроля присутствовал всегда. Это может потребоваться в критически важном ПО, например, для медицинской диагностики.
Работающую систему можно запустить сразу же, а затем постепенно её автоматизировать. Процесс, управляемый исключительно людьми — это модель обслуживания с очень высокой стоимостью. Если система должна расти, необходима стратегия автоматизации. Многие стартапы начинают с выполнения работы сотрудниками, но переход к частичной автоматизации завершается неудачей. Поэтому имеет смысл интегрировать инфраструктуру HITL с самого начала.
Те же системы, которые обеспечивают обучение HITL, могут обеспечить и внедрение HITL. Вам необходимы модели машинного обучения с тщательно откалиброванными метриками неуверенности, чтобы точно знать, что они чего-то не знают. К сожалению, большинство систем глубокого обучения обычно слишком уверены в своих прогнозах, что может привести к негативным последствиям.
Подведём итог
Системы HITL решают многие проблемы машинного обучения, от создания до практического применения модели. Чтобы узнать, как включить их в структуру вашей системы, можно прочитать потрясающую книгу Human-in-the-loop Machine Learning. Однако простейший подход заключается в использовании платформы разработки ИИ, предназначенной конкретно для процесса HITL.
А вы используете Human-in-the-Loop для своих задач? Как организуете процесс? В рамках курса "Сбор и обработка данных с помощью краудсорсинга" мы рассказали студентам ВШЭ и ШАДа, как внедрять HITL, а также сделали интересную домашку. Если вам тоже интересно ознакомиться, вот ссылка на материал: github.com/Kucev/human_in_the_loop_task