

Дисклеймер номер один: 18+. В этой статье присутствует ненормативная лексика, так как автор текстов, которые мы анализируем, не стесняется в выражениях. Мы не хотим никого задеть или оскорбить чьи-то чувства, присутствие мата объясняется лишь объектом нашего исследования.
Все знают телеграм-канал Артемия Лебедева, в котором очень часто можно увидеть хлесткое матерное слово, а некоторые его посты и вовсе неоднозначны. Я и мой коллега Егор решили как следует разобраться в семантике текстов Артемия, скачали все посты телеграм-канала и проанализировали его словарный диапазон. Сегодня мы обсудим важные этапы исследования и, что самое главное, обсудим аналитические выводы о телеграм-канале Артемия Лебедева.
Изначально, мы поставили перед собой следующие задачи: собрать тексты всех постов и метаинформацию о них, получить динамику подписчиков на канале, а после провести описательный и семантический анализы собранных данных. Но нам удалось сделать даже больше — в результате мы смогли обучить нейронную сеть на текстах Артемия Лебедева.
Теперь мы можем писать тексты для тг-канала Лебедева без него самого. Правда-правда.
Хотите узнать как?
Подготовка и сбор данных
Дисклеймер номер два (если вы не обратили внимание на первый): осторожно, в статье присутствует мат!
На самом деле, это уже далеко не первый наш анализ текстов: полгода назад мы подробно изучили тексты песен нового альбома Земфиры и определили основной их смысл, а еще раньше мы анализировали настроения в сети Вконтакте относительно внесения поправок в конституцию. Поэтому, к анализу текстов в телеграм-канале Лебедева мы подошли с некоторой экспертностью.
Для начала мы скачали информацию обо всех постах из канала Артемия Лебедева с помощью API Telegram, используя библиотеку Telethon. На момент скачивания, 31.08.2021, в канале было опубликовано 4382 записи. В результате все полученные данные мы записали в json-файл с глубокой вложенностью. Так выглядел наш основной датафрейм после обработки:

Кто читает Артемия Лебедева?
Уже в самом начале мы столкнулись с одной трудностью: API Telegram не позволяет обычному пользователю отслеживать динамику подписчиков — эта опция открыта только администраторам канала. Поэтому нам пришлось воспользоваться сторонним сервисом, который занимается аналитикой Telegram-каналов, и спарсить оттуда необходимые данные. Так выглядит динамика подписчиков канала:
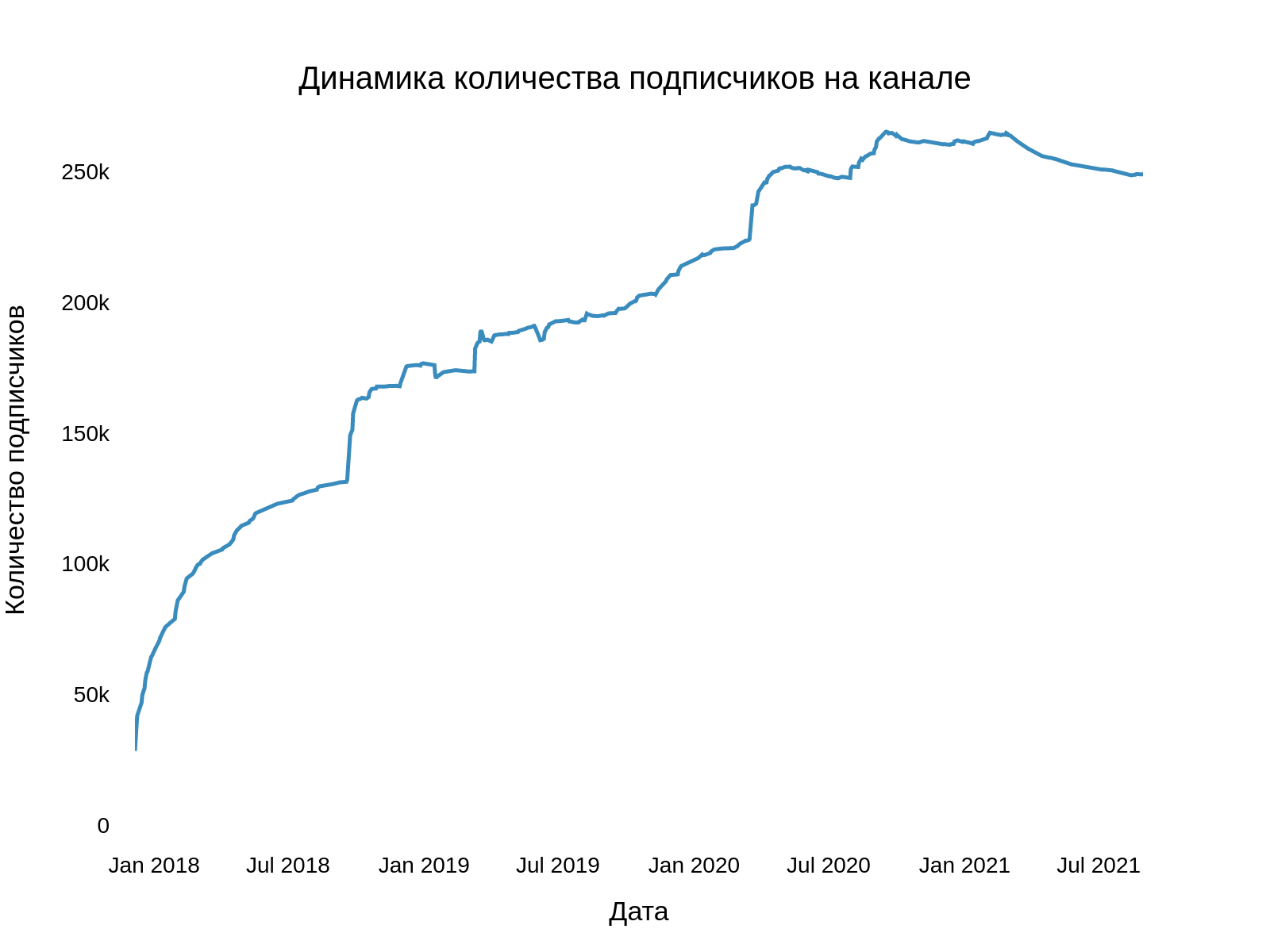
Глядя на динамику роста числа подписчиков канала, заметно, что в первые полгода с момента запуска канала количество подписчиков бурно увеличивалось, а затем рост стал чуть более плавным. Также, невооруженным взглядом видно несколько скачков — моментов стремительного роста.
На основе динамики были рассчитаны Day-over-Day изменения количества подписчиков, то есть ежедневный относительный прирост их числа. Также, мы определили выбросы как значения, которые не попадают в промежуток между усами боксплотов для анализа данных по относительным приростам (период становления канала – до пунктирной черты – мы рассмотрели отдельно, так как динамика там гораздо более бурная). График ниже показывает динамику изменения числа подписчиков канала, разделенную на нормальные значения, положительные и отрицательные выбросы.
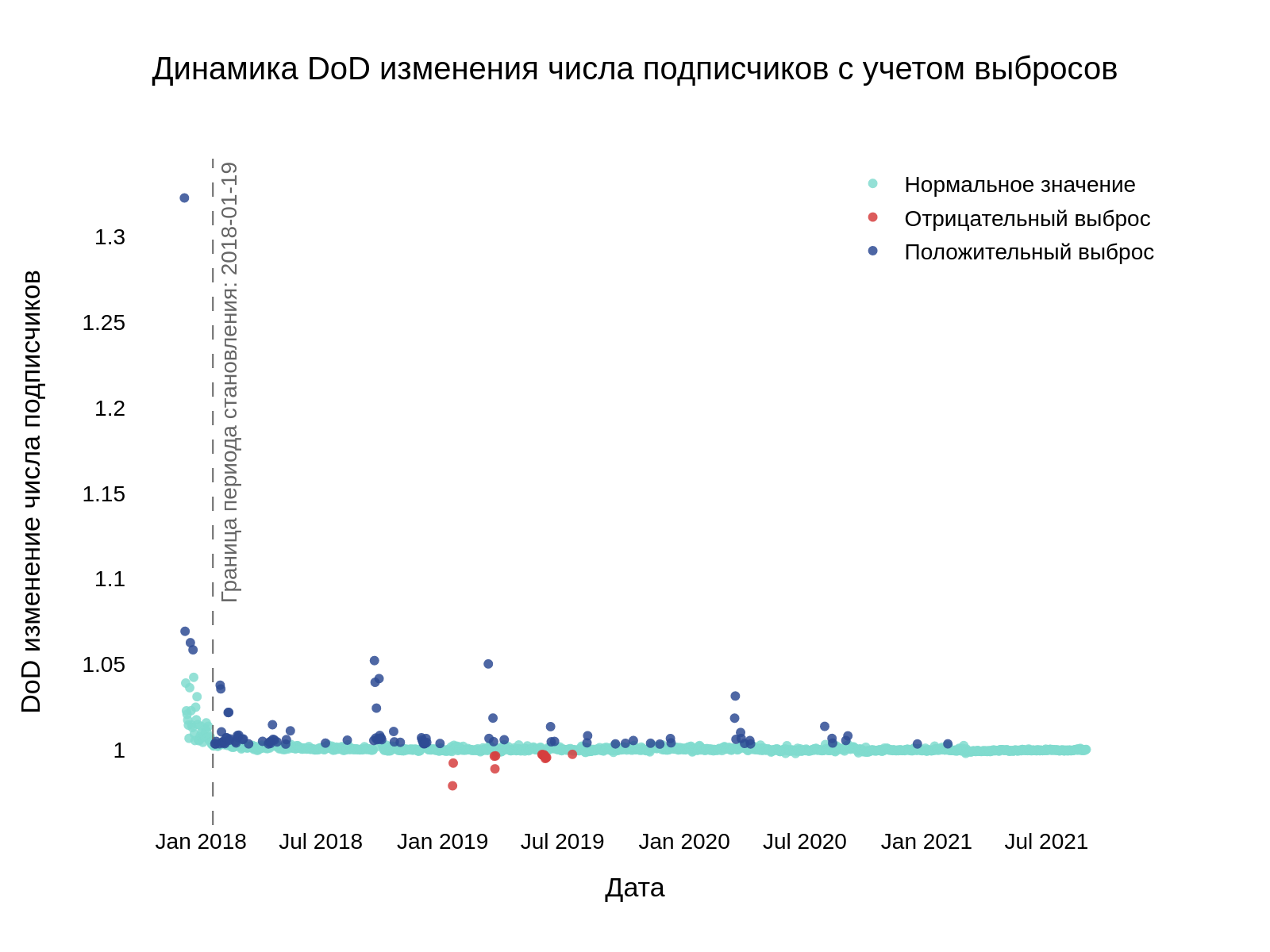
Каждой точке сопоставлен день и соответствующее Day-over-Day изменение числа подписчиков. Темно-синие точки соответствуют положительному приросту, т.е. увеличению числа подписчиков на канале, а красные — наоборот, снижению. Так как Артемий часто пишет несколько постов в день, то для дальнейшего анализа мы выбрали наиболее значимые посты: для каждого дня-выброса был выбран пост с наибольшим количеством просмотров.
Что нравится и что не нравится читателям?
Если вы были подписаны на телеграм-канал Артемия, то знаете, что до мая 2021 года под его постами были две кнопки: лайк и дизлайк (с октября 2020 года появилась возможность оставить свое мнение в виде комментария под записью). Так вот, в большинстве постов было отмечено наличие этих двух кнопок. Эту информацию мы тоже собрали и сохранили в JSON-файле.
В результате обработки этих данных были построены графики, представляющие собой динамику лайков и дизлайков со скользящим средним в 7 дней:

Невооруженным взглядом заметно, что лайки преобладают над дизлайками в несколько раз. Вы можете увидеть смену линейного тренда в динамике положительных оценок, которая отмечена пунктирной линией. Она наблюдается трижды (снижение-рост-снижение), а динамика дизлайков достаточно стабильна. Возможно, существует группа людей, которая неизменно ставит дизлайки практически под каждым постом Артемия. Также, общее число оценок не менялось во времени, хотя количество подписчиков увеличивалось постоянно. Можно предположить, что объем активного ядра канала особо не менялся, несмотря на общий рост числа подписчиков.
Мы решили понять, есть ли зависимость между резкими снижениями числа подписчиков и задизлайканными постами. Дней, когда число подписчиков резко уменьшилось, было всего 14:

В таблице представлены записи за эти 14 дней. Каждая строка содержит дату, количество подписчиков и DoD изменение. is_outlier = -1 определяет то, что в этот день зафиксирован отрицательный выброс.
Для записей с индексами 406-407 у значимых постов не было слишком много дизлайков, как и у других постов, которые были опубликованы в эти дни. Поэтому сложно судить, что именно повлияло на динамику подписчиков.
Для записей с индексами 469-471 только в первый день можно выделить значимый пост:

У этого поста 982 лайка и почти 7 тысяч дизлайков. Возможно, подписчики не оценили дизайн логотипа и отписывались от канала 3 дня подряд.
Интересным выглядит участок для записей с 541 по 548. В эти дни, идущие друг за другом, количество подписчиков неуклонно падало. Однако, и значимые посты, и все остальные посты имели значительно больше лайков, чем дизлайков. Возможно, что-то произошло вне телеграм-канала.
Можно предположить, что людям не понравился книжный фестиваль, который проводился с 1 по 6 июня 2019 года, или новость о нем.
Последняя запись таблицы кажется наиболее очевидной — Лебедев запостил бессмысленный и беспощадный набор слов, а в ответ на это подписчики решили уйти.

Хотя всё это, конечно, догадки.
На этом этапе анализа мы уже достаточно изучили динамику канала, поэтому переключились на более интересную задачу — анализ текстов постов.
Как понять, о чем пишет Лебедев?
После анализа динамики мы приступили к основной части — работе с текстом. Для начала мы избавились от всего лишнего: удалили пунктуацию, союзы, предлоги, числа, ссылки, местоимения и хэштеги. Также, мы удалили рекламные вставки в конце постов. Для каждого поста были проведены токенизация – разделение текста на отдельные слова – и лемматизация – приведение слова к канонической форме, то есть лемме, с помощью морфологического анализа. В результате обработки мы даже получили несколько пустых постов, которые пришлось удалить. Итого, в нашей выборке осталось 4147 записей.
Стоит отметить, что Артемий часто публикует один и тот же пост несколько раз, о чем он и сам говорит (причем, опять же, с повторами):

Поэтому перед тем, как приступить к вычислению различных характеристик текста, нужно было определить пул уникальных постов. Для этого мы использовали семантическое сходство текстов, так как при простом сравнении строк даже мизерные изменения могут показать, что два почти идентичных поста являются разными.
Мы выбрали модель, которую часто применяют в задаче NLP — Word2Vec, и взяли за основу предыдущий материал из блога — анализ последнего альбома Земфиры.
Для начала, мы самостоятельно обучили модель на собранных данных.
Алгоритм получился следующий:
- Из данных выбрали только те посты, длина которых > 5 слов, так как маленькие тексты неинформативны и являются по большей части мусором. Всего их получилось 3584.
- На этих данных была обучена первая модель Word2Vec.
- С помощью первой модели по косинусной мере были определены уникальные посты и их повторы.
- На уникальных постах была обучена вторая модель Word2Vec с увеличенной минимальной частотой встречи слова по сравнению с первой моделью, что предположительно могло повысить ее робастность.
- Для каждого поста был рассчитан вектор-представление (среднее по векторам слов). Эти векторы и были искомыми для семантического анализа, о котором мы расскажем чуть позже.
Почему бы не повториться, если мысль – достойная?
Для начала, мы хотим вам рассказать подробнее о тех данных, на которых мы построили модель.
Сперва мы представили распределение количества повторов уникальных постов (записи без дубликатов на диаграмме не отображены):
Число уникальных постов: 3171
Число постов с повторениями: 329
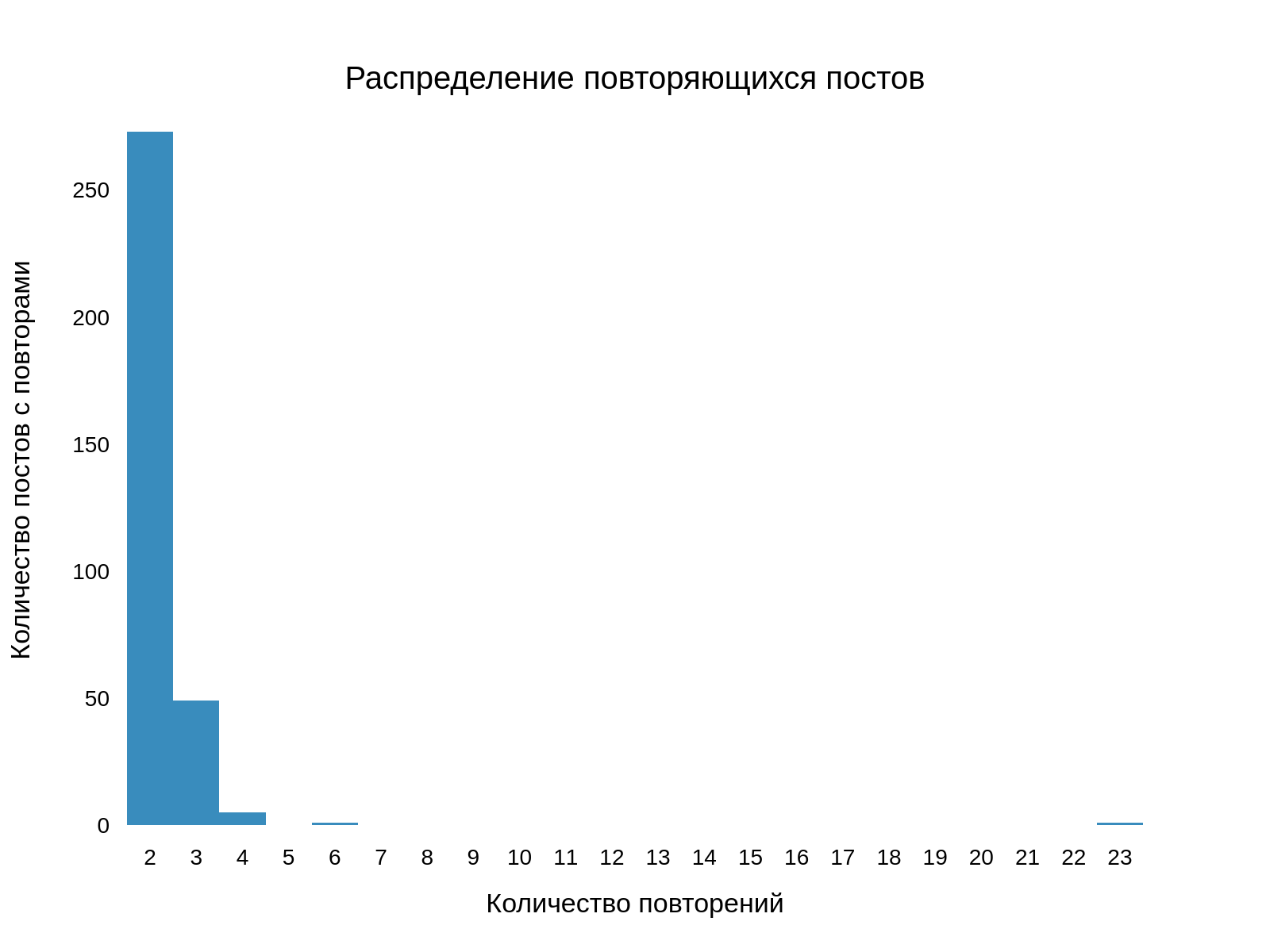
Можно заметить, что примерно 10% всех постов Артемий публикует повторно. Мы посчитали средние интервалы времени между повторными публикациями и получили следующее:
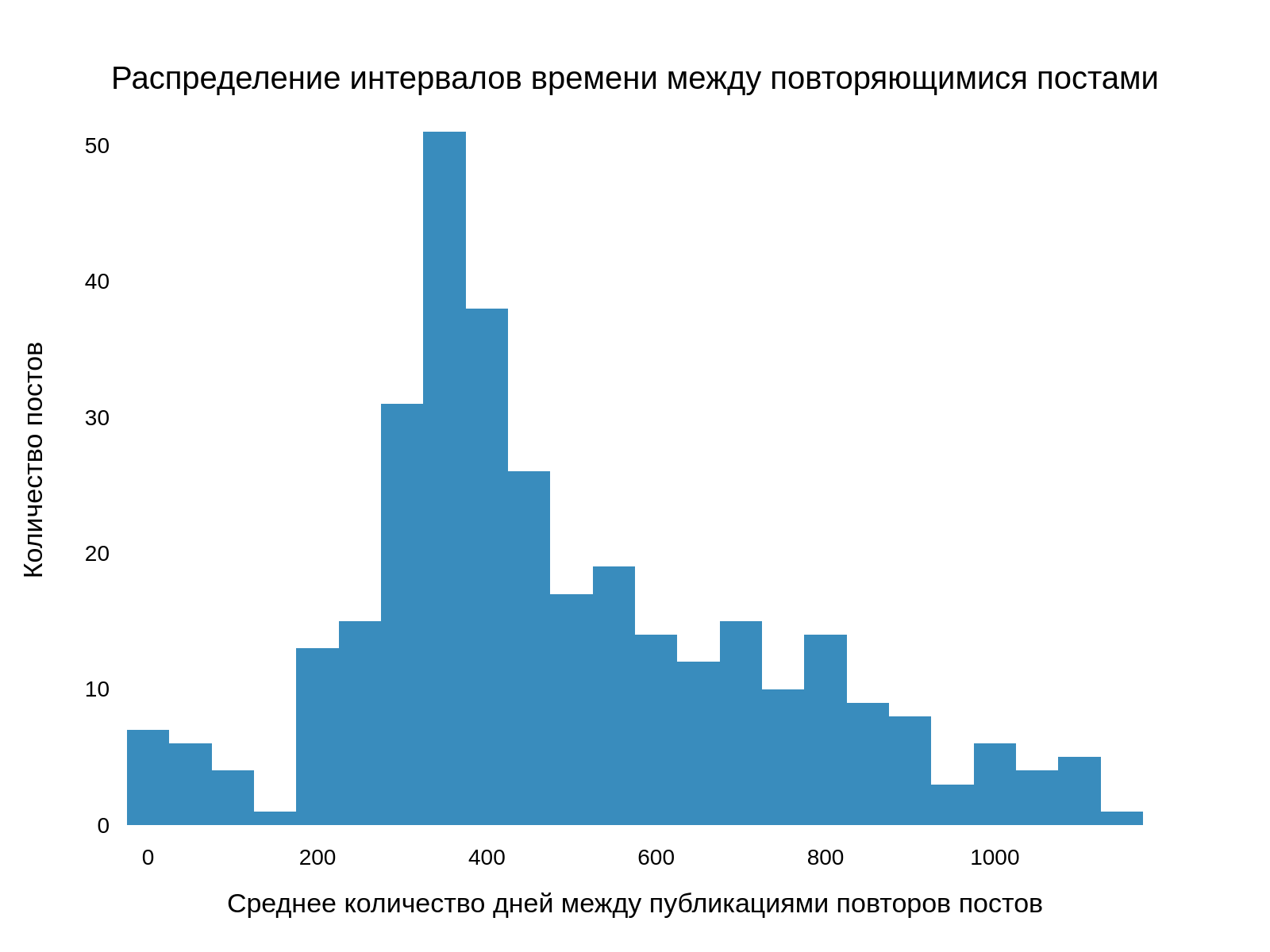
Получается, Артемий публикует дубликаты постов минимум спустя год.
Привет, Заюня: общение с подписчиками
Если вы когда-либо были подписаны на этот канал, то знаете, что Артемий очень любит обращаться в своих записях к воображаемому собеседнику с помощью всевозможных вариаций слова “заяц”:
Всего вариаций обращения: 19
Топ 5:
зай, 172
зая, 107
заюня, 50
зайчик, 31
заюша, 13
Для большей наглядности мы построили облако слов:

Стоит отметить, что этот анализ был проведен перед всеми вышеперечисленными действиями, так как слова “зай”, “зая” и т.д. были отнесены к ненужным и удалены ввиду того, что они могут мешать определению семантики текстов постов.
Пи***ц и 480 мест, где можно его найти
До этого раздела мы не уделяли внимания тому, что Артемий Лебедев активно использует мат в своих постах. Причем делает это крайне метко и красноречиво! Поэтому, дальше мы расскажем про анализ ненормативной лексики, которую Артемий употребляет в своих постах. С помощью регулярного выражения мы составили словарь матерных слов Артемия Лебедева:
Всего уникальных матерных слов: 247
Топ-10:
(Догадайтесь сами, что это за слова такие)
пи***ц (очень плохо), 480
на**й (к черту), 263
ху**я (чушь полнейшая), 228
бл**ь (у-уух), 203
**й (иногда кладут на чужое мнение), 198
ох****ый (шикарный), 109
ни**я (обычно в холодильнике), 80
по**й (индифферентно), 74
ох**нно (очень хорошо), 71
х**вый (далекий от идеала), 67
Таким получилось облако матерных слов:

Мы определили описательные характеристики:
54.75% постов без мата, 45.25% постов с матом
Матерных слов в среднем для всех постов: 0.89%
Матерных слов в среднем для постов с ненормативной лексикой: 1.97%
Артемий любит материться, вот пример поста, в котором 21 матерное слово:

Поговорим о семантике текстов Артемия Лебедева
А есть ли в его постах смысл?
Далее, с помощью обученной модели Word2Vec мы определили смысл каждого поста, то есть топ-N слов, имеющих вектора, наиболее близкие к вектору анализируемого поста по косинусной мере.
Однако, далеко не у каждого поста получилось определить адекватный смысл, поэтому мы решили использовать другую модель – RusVectores – предобученную на НКРЯ и Википедии.
Мы выбрали один пост и решили определить его смысл двумя способами – с помощью нашей модели Word2Vec (Custom) и с помощью модели RusVectores (Pretrained) – выделяя топ-10 значимых слов поста.


Вы можете увидеть, что модели очень хорошо дополняют друг друга. Слева выводится по 10 слов для каждой модели, а справа – топ-10 слов для обеих моделей, отсортированных по значению близости.
Есть ли в постах что-то общее: кластерный анализ
Для кластеризации постов был выбран алгоритм DBSCAN (имплементация из sklearn), так как он позволяет выполнить поставленную задачу, не задавая при этом заранее определенное количество кластеров. Алгоритму на вход подавались векторы постов, рассчитанные ранее обеими моделями. При вариации параметров получались различные наборы кластеров, какие-то при этом исчезали, а какие-то сливались в один. Приведем несколько интересных примеров полученных кластеров.
Сперва была проведена кластеризация значимых постов. Максимум было получено 6 значимых кластеров, однако только на один из них стоит обратить внимание:

Затем мы опробовали алгоритм на наборе всех уникальных постов. На кастомной модели получалось до 53 кластеров, на предобученной – до 32. В целом, кластеры получились адекватными, правда, в основном в них входили по 2 поста. В большой кластер были выбраны все рекламные дайджесты.
Вот еще несколько примеров:


Лебедев чаще позитивный или негативный: сентимент анализ постов
В нашем блоге мы уже проводили сентимент-анализ текста, поэтому мы решили применить тот же алгоритм к текстам постов Артемия Лебедева. Для этого так же была использована библиотека Dostoevsky. Для каждой записи предобученная модель выдавала по 2 значения, соответствующих 2 наибольшим вероятностям отнесения тональности поста к одной из 5 категорий — neutral (нейтральный окрас), negative (негативный окрас), positive (позитивный окрас), speech (разговорные фразы без эмоций), skip (невозможно определить). Нас же интересовали только первые три категории.
По результатам были построены следующие распределения:

Далее для каждого поста был определен эмоциональный окрас исходя из наибольшей полученной вероятности:
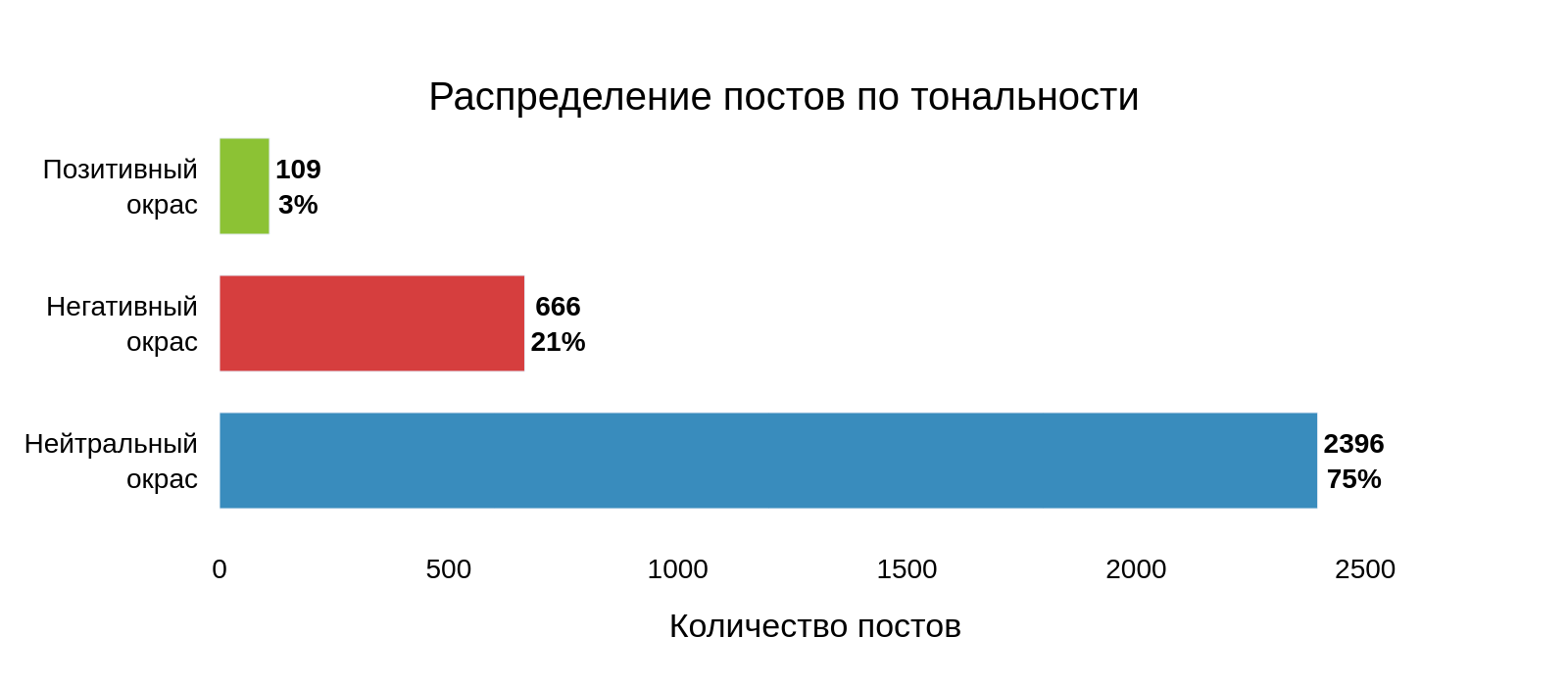
Как можно заметить, большинство постов, согласно модели, имеют нейтральный окрас, а записей с позитивным окрасом оказалось, наоборот, очень мало.
Представим топ-5 негативных постов, наиболее характерных (а также их вероятности):

Мы объединили анализ матерных постов и сентимент анализ, поскольку нам было интересно изучить, в какой тональности использовалась ненормативная лексика.
Для этого уникальные посты были разбиты на несколько групп по количеству матерных слов.

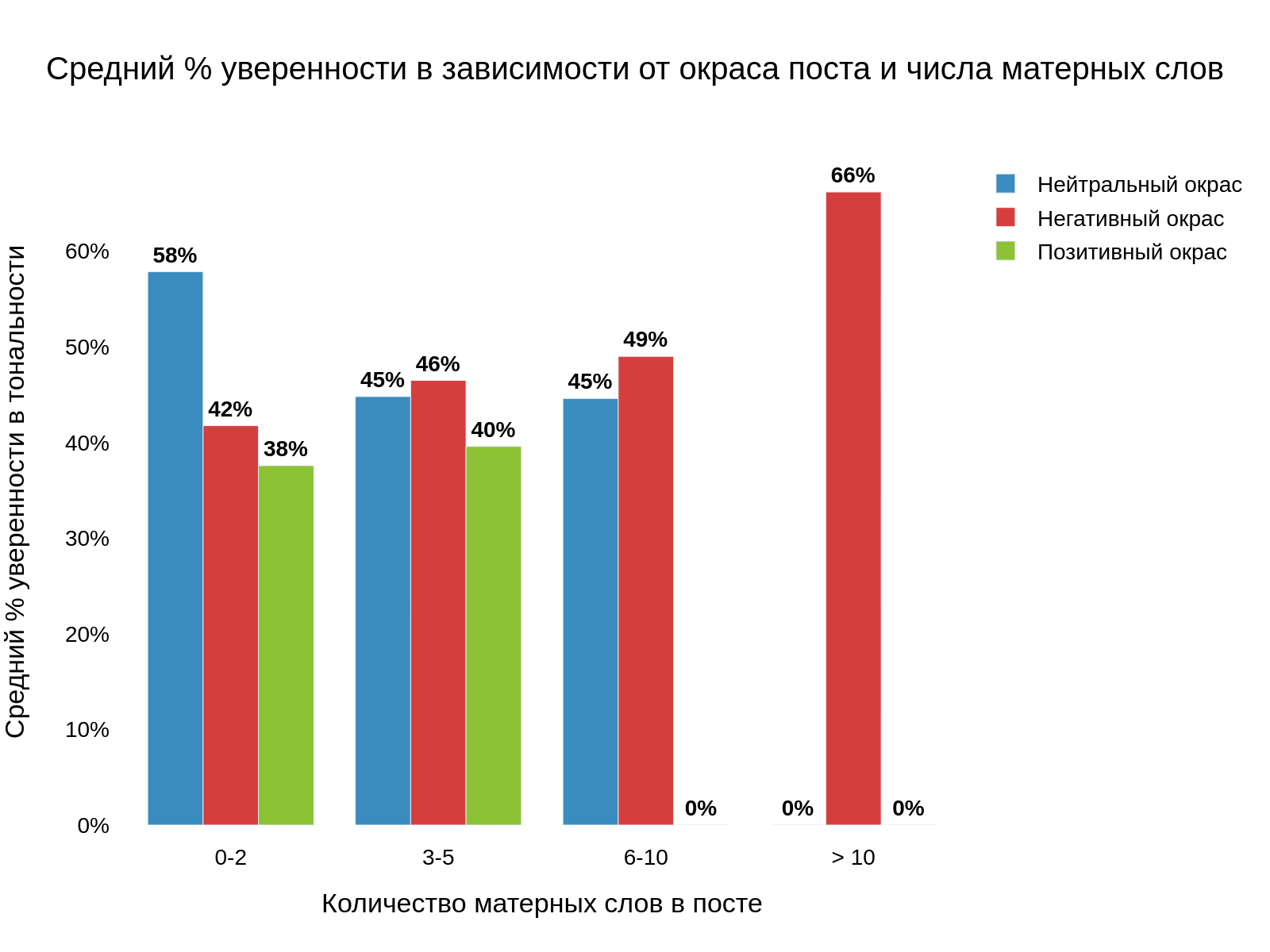
Количество нейтральных постов значительно падает с увеличением матерных слов. Поэтому, можно сделать вывод, что чем больше мата, тем более вероятно, что опубликованный текст имеет негативную тональность.
Генератор постов Артемия Лебедева

В завершение нашего анализа мы решили обучить нейронную сеть воспроизводить посты в стиле Артемия Лебедева. Было испробовано несколько моделей для этой цели, но в итоге мы остановились на GPT-3 от Hugging Face, которая была обучена командой Сбербанка для генерации текстов на русском языке. Её-то мы и решили стилизовать нашими исходными данными.
Так как дообучение и стилизация такой нейронной сети – процесс крайне ресурсозатратный (говорить об обучении с нуля даже смысла нет), мы решили перенести этот процесс в облако. Сначала была попытка осуществить всё в Google Colab, но нам помешало ограничение по памяти. В итоге, мы перешли на платформу Kaggle. Мы обучали модель GPT-3 Small в течение 5 эпох на корпусе текстов постов из канала, из которых была удалена вся информация, касающаяся рекламы (она значительно ухудшала результат работы при первой попытке создания генератора).
Обученную модель мы задеплоили с помощью сервиса Yandex.Cloud Datasphere. О том, как это сделать, вы можете прочитать в нашем блоге. В результате у нас есть нода с развернутой моделью, которая генерирует тексты в стиле Артемия Лебедева. К ней можно обращаться с помощью API-запросов. Все это мы обернули в Flask web-приложение, которое развернули на нашем AWS сервере.
Та-дам! Теперь вы тоже можете написать пост в стиле Артемия Лебедева. Просто зайдите на сайт, напишите начальную фразу, а потом созданием поста займется нейросеть. Копируйте ссылку на ваш уникальный текст и делитесь тем, что у вас получилось в комментариях или своих социальных сетях!
А еще, читайте мой блог о кейсах и методах анализа данных LeftJoin и телеграм-канал Left Join!
Комментарии (9)

belch84
10.01.2022 14:03+3Попробовал пару раз — получилось как-то неинтересно, то, что генерировалось, было мало связано с затравочной фразой

joffer
10.01.2022 15:03+4Забавно) Попробовал пару раз - стилистика получается похожая, а вот контекстно совсем не Лебедев)
Если написать что-то вроде "как же меня бесят автобусные остановки", то сгенерированный текст больше похож на жалобу в соцсети, чем на пост от Лебедева, Лебедев вкладывает больше контраста, противоречия, смыслов, у него сначала идёт нытьё, но потом какой-то вывод, или парадокс, или неожиданная мысль, оригинальное соображение, а сгенерированная речь лишена этого всего. Такое ощущение, что кто-то чужой пытается говорить что-то своё, используя построение фраз Лебедева, но поскольку контекстное построение не соответствует - Лебедев не считывается)
по крайней мере, это то, каким это всё показалось лично мне

valiotti Автор
10.01.2022 15:43Кажется, вы прям в точку попали с описанием генерируемого текста. Хотя нам кажется, что местами лексика прям очень похожим образом получается.



foxairman
11.01.2022 13:50А можно обработать википедию или хабр и чтобы бот присылал интересную тему, а потом по ней что-то полезное отвечал?
Cost_Estimator
Еще хочется узнать - зачем. Это тема для следующей вашей статьи, да?
valiotti Автор
Поэкспериментировать с нейросетью на практике и на отдельном корпусе текстов.
Miharus
За тем, чтобы Лебедев рассказал о нем в самых честных новостях и пропиарил все тут.