
МНОГАБУКАВ.
Знакомство
Всем привет! Расскажу про нашу разработку, которая изменит подход к обработке данных.
Мы разработали новый математический алгоритм обработки данных и программный продукт на его базе (кодек), позволяющий работать со сжатием битовых потоков любого формата (статические/динамические) – то есть, кодек позволяет проводить более глубокое сжатие уже существующих файлов (видео, изображения, архивы и т.д.), так и осуществлять сжатие исходных «сырых» данных.
Заложенная в алгоритме обработка представляет собой механизм квантования с применением многоцентричной развертки и алфавита изображения. Такой подход кардинально отличается от всех существующих на сегодня вариантов сжатия данных, базирующихся на принципе энтропийного сжатия.
Сжатие данных без потерь с дополнительной компрессией до 50%, является важным преимуществом и обеспечивает потенциальную возможность интеграции продукта практически в любые существующие программные решения. Также разработан алгоритм управления качеством визуализации изображения в зависимости от степени сжатия и конкретных приложений.
В любой науке столько истины, сколько в ней математики - Иммануил Кант.
Способ сжатия видео потоков, заданных стандартом MPEG4, средствами широкополосной развёрткой. ШПР-кодек.
Область техники
Изобретение относится к области обработки цифровых изображений. Способ предназначен для сжатия видеопотоков, заданных стандартом MPEG4, путём встраивания в существующие кодеки MPEG4 ШПР- кодека, выполняющего функции удаления оптической и динамической избыточностей из кадра видеопотока с помощью аппроксимации результата инверсного дискретно-косинусного преобразования (IDCT) вектором релевантности (Wkp).
Эффективность
Основным параметром эффективности является фактор сжатия (Fs) как отношение размера входного файла к размеру выходного файла. Величина Fs зависит, в основном, от количества итераций сжатия входного потока. Первая итерация, как правило, задает Fs=5-10 раз, т.е. входной поток сокращается до десяти раз. Вторая итерация задает Fs=3-6 раз, т.е. входной поток сокращается до 50 раз. Третья итерация задает Fs=2-4 раз, т.е. входной поток сокращается до 150 раз. При этом, фактор кодека (Fk) как отношение времени кодирования к времени декодирования для каждой итерации удерживается на уровне Fk=(0.4-0.7):1, при норме Fs=1.5:1. Как правило, после четвёртой итерации возникает визуально неприемлемо качество сжатого видео потока.
Уровень техники. Аналоги и их недостатки
Основной смысловой (семантической) единицей предлагаемого кодека является последовательность изображений (Jm), полученных MPEG4 декодером после i-ой итерации, причем видеоряд Jm получают в виде отрезка, состоящий из 8-ми I-кадров и P,B- кадров “навешенных” на соответствующий I- кадр. Все I,P,B-кадры развернуты в xxx.jpg формат представимый 3 байтами, где 1-ый байт как Y компонента, 2 и 3 байты как U,V компоненты. Эти байты преобразуют в рефлексивный код Грея [1,стр125] или Грей-байты. Такую конструкцию называют РОЛом. Представление входного потока в форме РОЛов позволяет в десятки раз снизить значение Fk, а сжатие видеопотока проводить средствами CUDA технологией на основе аппроксимации Грей-байтов вектором релевантности Wkp. Существующие видео кодеки не имеют подобного механизма.
Прототипы
В качестве прототипа по применению CUDA технологии для сжатия полубайтовых Jm выбирают кодек FVJPEG. В качестве монетизации выбирают комплекс кодеков типа ProRes фирмы Apple. Описание изобретения. Изобретение относится к области обработки видеопотоков, заданных стандартом MPEG4 и может быть использовано для их сжатия в десятки раз с приемлемым качеством визуализации. Заявленный способ отличается от существующих наличием средств аппроксимации результата применения инверсного дискретно-косинусного преобразования (IDCT) к компонентам YUV кадра Jm.
Развертка
Избыточность необходима для сжатия изображения и для выделения разной степени полезной (релевантной) информации. Линейность обеспечивает возможность привести изображение к форме, приемлемой для работы машин Тьюринга, Поста и т.д. Можно сказать, что линейность необходима для вычленения смысловой информации, пусть биграммами, триграммами и т.п. [8, с.25]. Для решения этой задачи обратимся к процессам формирования цифрового изображения. Они включает в себя два процесса: 1.1. Дискретизация как фактор пространственного разрешения изображения. Пространственное разрешение – это размер минимально различимых деталей на изображении. Допустим, надо определить, какое разрешение требуется для передачи отображения визуального объекта, например для качественной печати. Дискретизацией определяется объем аналоговой информации, необходимой для последующего воспроизведения в цифровой форме. Можно сказать, что дискретизация на данный момент работает только с пространством и решает задачу кратно масштабируемого дробления объекта, чтоб получать доступ к его пространственным элементам. 1.2. Квантование как фактор его яркостного разрешения. Квантование – это определение минимально различимого (неважно кем, человеком или сенсором) изменения яркости. Минимальное квантование – это представление изображения двумя цветами (обычно черным и белым), т.е. разницей в один бит. Максимальное квантование – это цветное изображение, которое в общем случае разложено на три цветовых компоненты, каждая из которых представлена восемью битами. Каждая из цветовых компонент состоит из восьми монохромных («однобитовых») плоскостей. Таким образом, цветное изображение представляется «слоеным пирогом» из 24 монохромных плоскостей, полутоновое – из восьми, монохромное – из одной плоскости [9, с.104]. Существующая растровая форма представления изображения в результате действия этих операций задается двумерной функцией f(x,y), у которой как обе координаты x, y, так и значение f – целые числа. Функция f приписывает каждой паре x, y конкретное значение яркости P, где P – носитель яркости или пиксель. Порядок и путь приписывания (направление дискретизации или развертка плоскости изображения) выполняются построчно от верхнего левого угла плоскости изображения. Таким образом, растровая форма представления цифрового изображения задается матрицей, элементом которой является пиксель P(x, y). Доступ к P(x, y) производится строчной разверткой [9, с.99] и зависит от габарита изображения X,Y. 17 Для начала решения поставленной выше задачи предлагается изменить порядок и путь дискретизации со строчной развертки на развертку типа Кривой, Заполняющей Плоскость (КЗП). Существующие КЗП (Гильберта, Мура и т.п.) являются четными и поэтому «не умеют» разворачивать плоскость от ее центра. Интуитивно понятно, что центр изображения является наиболее информативным. Нами разработана КЗП [1÷7], выполняющая развертку изображения от его центра и как всякая КЗП рекурсивна, имеющая направление рекурсии (рис.1) и ее порядок (рис.2), т.е. остальные КЗП строятся на основе ее первых двух форм. Пример третьей (производной) КЗП дан на рис.3. В общем виде предлагаемая развертка разбивает изображение на квадраты, размером 3х3 cтепени n, где n=1÷10. Содержимое этих квадратов обрабатывается и объединяется в целостность по их граням. Поэтому развертку такого типа будем называть фасетной (от фр. facette – грань), а файлам изображений, полученным с ее помощью, присвоим расширение ххх.fas. Следуя основному принципу построения КЗП: «отображение квадрата в отрезок», фасетная развертка выполняет одномерное физическое размещение пикселей P(x, y)P( f ) с параллельно- независимым доступом к ним с шириной захвата 9 степени n пикселей (дискрет), причем в начале этого размещения стоит центральный пиксель изображения.


Алфавитное представление
Дальнейшее решение поставленной выше задачи направлено на получение алфавита изображения путем изменения схемы квантования. Существующая схема квантования в общем виде порождает 1-битовое (монохромное), 8-битовое (полутоновое) и 24-битовое (цветное) изображения. Цветное изображение рассматривается как 3-х компонентное, каждая из компонент – полутоновая. Алфавит должен представлять любое изображение, поэтому его буква должна быть монохромной. Количество букв в алфавите задается фасетной разверткой по первой кривой (рис.1) и оно (количество) равно 2 в степени 9 и соответствует 512 буквам. Полный алфавит дан на рис.4. Для определенности плоскости полутона будем нумеровать в порядке 1÷8, где №1 соответствует 1-битовой, а №8 – 8-битовой плоскостям. Плоскости 17 цветных изображений, пусть RGB, нумеруются как 11÷18, 21÷28, 31÷38. Каждая плоскость преобразуется в код Грея [9, с.653].

Беспороговая сегментация
Основой фасетной технологии являются алгоритмы беспороговой сегментации изображения. Обычно сегментацию относят к процедурам распознавания элементов изображения. Фасетная технология применяет процесс сегментации во всех классах обработки изображения: анализ (распознавание, фильтрация); преобразование (сжатие, редактирование); синтез (улучшение изображений, анимация); передача по каналам связи (фасетное представление обеспечивает возможность частичной, до 40% , самокоррекции кода без избыточности). В скобках указаны наиболее представительные подклассы. Применение сегментации, в том числе и для сжатия [9,с.812] , является начальным условием (аксиоматикой) для эффективных средств во всех областях обработки изображений. Основная проблема систем обработки изображений, ориентированных на пиксели, – задание порога яркости. На сегодня выбор порога яркости в высшей степени субъективен [9,с. 105]. Фасетная технология оперирует объективными типами скоплений пикселей: компакты (белый, черный); регулярности (след прямых); хаосы (искусственные или естественные текстуры, хаосы в виде облаков, прибоя, крон деревьев, муара и т.п.). Фасетный алфавит обеспечивает управление типами скоплений.
Выделение релеванта
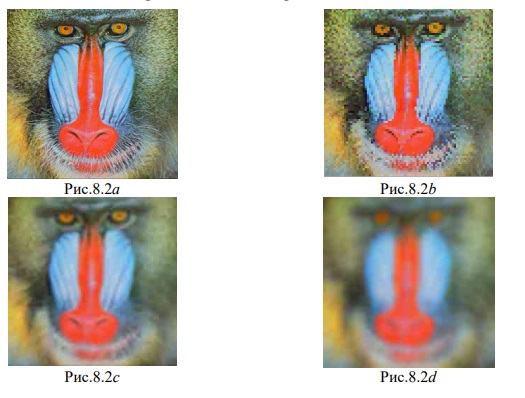
В зависимости от поставленных задач, типа цветовой модели, могут строиться различные подалфавиты путем снижения количества символов полного алфавита. Например, для построения модели изображения на узнаваемость при минимальном объеме хранения применяется подалфавит, состоящий всего из двух символов (см. рис.8.1b). Такой прием позволяет увеличить скорость поиска и хранения образа, обеспечивающего узнаваемость (релевантность) при максимальном его сжатии в системах построения баз изображений, поиска по базе изображений, а также для быстрого сравнения кадров в видеокодере и т.п. Изображение, построенное с применением этого подалфавита реализует в себе коэффициент сжатия от 80 до 3000 раз в зависимости от габарита и содержания. Для простых изображений типа «квадрат Малевича» сжатие может достигать свыше 10000 раз. При этом степень узнаваемости (релевантности) определяется на верхних уровнях пирамидального представления образа изображения. Примеры сжатых релевантов представлены на рисунках 8.1c, 8.2c, 7.1b. При этом не используются пирамиды Бюрта [12,с.532-540], Маллата и т. д. Фасетный метод обеспечивает эффективное отделение релевантной информации от хаотичной (ложные контура, муаровые покрытия, шумы [ 9, с.112 ] и т.д.). Важно, что при отделении не применяется дисперсионный анализ. 17 Оценку качества визуализации релеванта можно измерять количественно в автоматическом режиме. Укажем путь решения такой проблемы по результатам наблюдений. В качестве примера выберем одно универсальное ( рис.5 ) и три эталонных ( рис. 6 ÷ 8 ) изображения: ( см. рисунки ).

Изображение рис.5 относится к типу «хаос», оно содержится практически в любом изображении на его нижних (битовых) плоскостях. Здесь взята R1 плоскость рис.8. Изображения на рисунках 7,8 – эталонные, т.е. имеют предельное сжатие без потерь по алгоритмам, нам известным, встроенным в формат ххх.png. Другие форматы только увеличивают их объем, как правило, на 10% и выше. Считается [13,с.18] , что невозможно сжать изображение без потерь на более чем 2 %, т.е. из 100 Кб реально получить сжатие до 98 Кб, но не меньше. FAS-комплекс обеспечивает сжатие от 8 %, т.е. из 100 Кб можно получить объем от 92 Кб и ниже. Основная проблема сжатия без потерь – сжать нижние плоскости типа рис.5. Считается также [9,с.662], что три нижних для полутоновых и шесть нижних плоскостей для цветных изображений сжать без потерь невозможно. Сжатие изображений без потерь является единственно допустимым способом сокращения объема данных при архивации медицинских, деловых и архивных документов. Нежелательным сжатием с потерями является обработка спутниковых изображений. Еще одним направлением является цифровая рентгенология, в которой потеря информации ухудшает точность диагностики.
Выделение в изображении информативных областей
На рисунках 5а и 5в – показаны результаты сегментации рисунка 5 (хаоса) на мелкие и крупные дисперсии. Сложение рисунков 5а и 5в дает рисунок 5. Процесс сегментации – рекурсивный, т.е. и рис.5а и рис.5в можно сегментировать далее.

Процесс применяется для выделения и сжатия в изображении областей типа «ложный контур», с последующим их выводом из зон распознавания, например, для выделения следов прямых.

Результат сегментации и удаления ложного контура показан на рисунках 9 и 10. Далее на очищенном изображении можно эффективно осуществить распознавание прямых более быстрым, нежели преобразования Хафа, методом. Метод позволяет описать семантическими кодами прямые, дуги и прочие графические примитивы. Таким образом, фасетный формат может представлять фрагменты изображения как в растровой, так и в векторной формах. Для развития понимания этой идеи, приведем следующие результаты испытаний.


На рисунках 6.1 a ÷ 6.1 c показаны результаты сегментации изображения рис.6 по прямому коду Грея для 8-6 (a,b,c) плоскостей соответственно. Можно применять адаптивные модификации этого кода, например по яркостной гистограмме d-фасета или по гистограмме графических примитивов. На рис.6.1d показан результат сложения 8,7,6 плоскостей. Эти рисунки объясняют процессы выявления ложных контуров, основных контурных фрагментов, областей одной яркости и областей хаотичных скоплений пикселей. FASкомплекс позволяет выделять и формализовать такие области (компоненты) в семантические коды с целью поиска подобных компонент как в поле изображения, так и среди либо баз статичных изображений, либо для удаления межкадровой избыточности. В последнем случае речь идет о реализации предсказателей движения, освещенности и формы. Такой механизм приемлем как для сжатия изображений без потерь, так и с потерями. Отметим, что структуры хранения изображений с потерями и без одинаковы и поддержаны одномерной фасетной КЗП. Основное отличие: изображение, вложенное в плоскость типа КЗП Серпинского, имеет направление дискретизации от его центра по настроенному самоподобию.

Рисунки 6.2 a ÷ 6.2 c (компакты) демонстрируют представление рисунка 6 по 8-6 плоскостям соответственно с точностью 1-фасет, имеющего значения 000 и 777, т.е. площади размером 3х3 и выше либо пустые, либо черные. Остальные значения (001 ÷ 776) показаны серым цветом. Рисунок 6.2d – это результат сложения рисунков 6.2a ÷ 6.2c.

Рисунки 6.3a ÷ 6.3c (линии) демонстрируют представление рисунка 6 по 8-6 плоскостям соответственно с точностью 1-фасет, содержащего вертикальные, горизонтальные и наклонные следы линий, кратные 3-м дискретам. Рисунок 6.3d – это сложение рисунков 6.3a ÷ 6.3c. Понятно, что достаточно включить некий интерполятор на эти совокупности и мы получим альтернативы преобразованиям Хафа. Этот интерполятор представляет собой даталогию всех прямых, пусть с точностью 1:1000, лежащих в первом квадранте. Объем даталогии менее 1,5Кб. То же самое можно выполнить и для дуг типа “Окружность”. Объем даталогии будет порядка 9Кб. Эллиптические конструкции требуют отдельных исследований. Главное, на дискретных пространствах из точки А в точку В можно провести прямую тремя и более способами.


Рисунки 6.4a ÷ 6.4c (изолированные точки) демонстрируют представление рисунка 6 по 8-6 плоскостям соответственно с точностью 1-фасет, содержащего связные по кресту (связность Мура) черные точки на плоскости размером 3х3 дискрет. Рисунок 6.4d – это сложение рисунков 6.4a ÷ 6.4c. Можно применить и диагональную связность, которая здесь не рассматривается.
Сжатие и редактирование изображений
В этом разделе используется логика Г.Фреге, на наш взгляд наиболее прагматичная, а именно: сжатие без потерь (денотат), сжатие с потерями (знак) и редактирование, по сути – фильтрация (концепт). Формально, сжатие без потерь задает изображение как оригинал и неважно, каким способом он упакован. Все зависит от конструкции оптического сенсора. Можно, пока теоретически, представить сенсор, выход которого формирует сжатый без потерь, пусть относительно ххх.bmp, оригинал, который модифицирован под любую цветовую модель.
Оригинал имеет, как правило, десятки образов, в том числе и образы, сжатые с потерями. Отображения оригинала в образы и обратно производятся по концепту. Здесь дается упрощенная (иконическая или на рисунках) схема представлений компонентов Фреге, которая интерпретирована некоторыми имеющимися алгоритмами. Понятно, что иконика порождает десятки, если не сотни изображений, при наличии соответствующих процедур. Это можно наблюдать и на указанных выше изображениях.
Сжатие изображений без потерь
Сравнение сжатия изображений (рисунки 5÷8) ведется относительно формата *х.bmp для формата *.png и формата FAS-комплекса или *.fasb (fas формат без потерь):

Понятие «детализация» взято из работы Гонсалеса Р. [9, с.112] . Оно связывает яркостное k и пространственное N разрешения полного изображения. FAS технология расширяет это понятие до областей изображения с точностью, кратной 9 степени d, т.е. d-фасет.

Сжатие изображений с потерями
Сжатие изображений с потерями напрямую связано с качеством визуализации. Как правило, этот процесс в высшей степени субъективен. Обычно его решают 5-6-ю экспертами по 4-6 балльным шкалам. Это так называемый ROC анализ, который приемлем для оценки изображений общей визуализации. Интересно отметить, что улучшение качества изображения, например с применением контурной подрезки, воспринимается ROC экспертами как нежелательное, т.е. не соответствующее оригиналу. Можно привести примеры автоматической оценки качества образа изображения по метрикам ошибок, например по наиболее массово применяемому методу PSNR (пиковое отношение сигнал/шум) или SQNR (сигнал\шум квантования). Однако эти метрики чисто синтаксические. Например, они бессильны перед муаром или другими площадными артефактами. Для простоты восприятия укажем на разницу между реально падающим снегом и снегоподобными шумам, которые возникают на мониторе при наличии внешних (грозовые разряды, электромагнитный резонанс, плохо отсканированное изображение и т.п.) воздействий. Просто в этих метриках отсутствует семантика.


Здесь и далее приведено сравнение по объему V хранения: для полутонового изображения ( рис.8.1a- яркостная составляющая Y для рис.8,) или: рис.8.1a – оригинал, V = 64 Кб; рис.8.1b – предельное (по FAS-технологии) сжатие для распознавания с точки зрения процессора V = 0.76 Кб; рис.8.1c – продукт визуализации рис.8.1b, т. е. размер рис.8.1c также равен 0.76 Kб. На рис.8.1d – предельное сжатие по .jpg, его объём V = 2,38 Кб. Назовем представления типа рис.8.1b канальными образами.
Сжатие с потерями цветных изображений

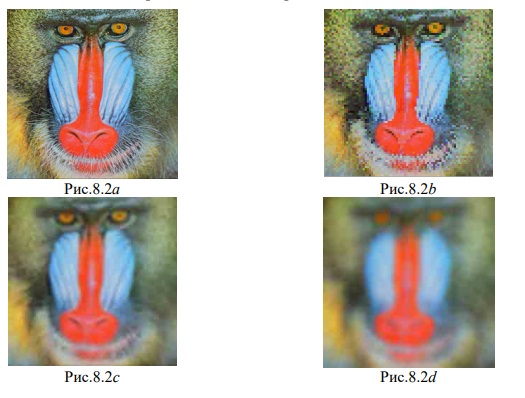
Примеры канальных образов даны на рисунках 8.2b и 7.1b. Их объем V равен соответственно 1,8 Кб и 1,4 Кб. Входные образы в формате ххх.jpg даны на рисунках 8.2d и 7.1d. Их объёмы соответственно равны 19,3Kб и 12,8 Кб. Формат ххх.bmp имеет равные объёмы 192 Kб (рисунки 8.2a и 7.1a). На рисунках 8.2b и 7.1d даны предельные по узнаваемости сжатия средствами jpg объемы соответственно 2.38 Кб и 2.23 Кб. На рисунках 8.2c и 7.1c приведены виртуальные образы, улучшенные по качеству их воспроизведения. Образы типа рисунков 7.1b и 8.2b могут также использоваться как для статических, так и для потоковых видео ( например, для размывания фрагментов задней или передней сцен или для распознавания этих сцен с целью сжатия ). Объемы рисунков 7.1b и 8.2b не являются предельными. Теоретически они могут быть равны 0,52 Kб и 1,3 Kб соответственно без ухудшения качества визуализации, относительно рисунков 7,1c и 8.2c. Для сжатия с потерями важно иметь оценку качества визуализации на уровне пусть рисунков 7.1a и 8.2a, имея при этом объём V в районе 8.7 Кб и 5.4 Кб соответственно. Для выявления некоторых закономерностей обработки изображения в зависимости от его размера, например для процедур сжатия, на рисунках 9 и 10 даны полные эталонные изображения, сжатые без потерь в формате ххх.png, которые информационно адекватны рис.7.1a и 8.2a соответственно.

Заключение
В конечном итоге, не смотря на рост трафика и объема хранения цифровых данных в России и в мире мы способны существенно сократить необходимые для этого ресурсы. 50% - это не ограничение, мы сжали видео без визуальных потерь в 54 раза, но только в рамках экспериментального тестирования. На сегодняшний день, начиная от стриминговых платформ, игр и заканчивая телемедициной и пакетом Яровой уже испытывают проблемы с шириной канала связи и постоянно растущими ЦОД.
Пример компрессии Х5 в 4к
Комментарии (18)

Brak0del
13.02.2022 10:31+5С учётом того, что в тегах FPGA, подскажите, сколько оно ест ресурсов ПЛИС, какие скорости достигнуты, какие тактовые частоты и т.д. ?


lab412
13.02.2022 11:08+18Мне одному кажется что целая индустрия работающая над сжатием видео не могла "случайно" потерять 50% данных которые этим кодэком сжимаются потом? я конечно охотно верю, и всё может быть но как говорил один крупным мужчинка "Где ваши доказательства?". скачайте видео с ютубчика, сожмите и покажите разницу. возмите фильмец сжатый двухпроходным HEVC и сожмите его еще, и так же цифирки пожалуйста. Повторите тест на 100 видео из разных источников чтобы проверить коэфициенты и выложите табличу.
я верю что в отдельных случаят сжатие может и получиться. часто фильмы сжимают с увеличенным потоком чтобы сохранить качество - там то конечно избыточность еще будет. но когда мы говорим про HEVC видео с довольно низким потоком - там ловить мало уже что остаётся.
Так же вы пишите что можете сжать уже сжатые файлы? зипы и прочие может и сожмёте конечно, там всё таки не такое сильное сжатие как хотелось бы. Но снова "Где ваши доказательства?". Возьмите книжки - это документы с низкой энтропией и они сжимаются в тысячи раз обычними зипами даже. Сожмите, потом сожмите своим архиватором и приложите табличку. Не один файл, а сотню и причем разных видом документов. Но важно чтобы зимои с максимальным сжатием и потом вашим поверх зипа. Тогда можно говорить уже о цифрах и прочем.
Вы могли случайно выбрать для сжатия файл который даёт хорошие коэфициенты. Хуже если все ваши тесты шли на специально выбранном файле, но я конечно не думаю что вы так сделали.
В общем подводя итог - нужны не только описания и теория, а реальные тесты - пары файлов, исодник и ваше сжатие исходника. Тогда можно говорить уже о сжатии, коэфициентах и прочих вещах

Sdima1357
13.02.2022 11:28+9Не хочу быть пессимистом, но заключение многое объясняет. Видимо до результатов нужно ещё много
денегработать. Это очень похоже на презентацию для инвесторов. Да и читать трудно. Для неспециалистов слишком сложно. Для специалистов - лишняя вода и объяснение тривиальных понятий .Возможно в этом что-то есть , но либо автор весьма косноязычен, либо это сделано умышленно.

Softservicerus Автор
14.02.2022 13:02-2Посмотрите видео по ссылке внизу.

AlexeyMoiseev
15.02.2022 10:34+2По ссылке видна разница в видео битрейте между исходным и итоговым файлами, отличия в опциях x264 кодека. Использование ffmpeg с имеющимися у итогового файла характеристиками даёт аналогичный результат.
мы сжали видео без визуальных потерь в 54 раза, но только в рамках экспериментального тестирования
Можно ссылку на эти файлы (исходное и итоговое)?


Medeyko
13.02.2022 11:53+13Всем привет! Расскажу про нашу разработку, которая изменит подход к обработке данных в корне.
Вы, конечно, простите, но такое начало сходу вселяет скепсис. Подобные формулировки я слышал от людей с манией изобретательства.
Потом отсылка к Канту, как будто остальные алгоритмы сжатия к математике отношения не имеют.
К сожалению, прочитав до конца, убедился, что первое впечатление оказалось правильным - статья пустая, много разных слов, и нет конкретики, позволяющей проверить столь громкие заявления. Как-то очень похоже стиль, используемый в заявках на получение гранта, когда ничего не сделано, а денег на разработку получить хочется. После упоминаний России и Яровой, сложно отделаться от мысли, не попытка ли это попила субсидий на импортозамещение.
Я вон тоже писал пару десятков лет тому назад видеокодек, даже р-р-революционную идею выдумал - использование в качестве основания системы счисления квадратный корень из двух (см. https://en.wikipedia.org/wiki/Non-integer_base_of_numeration#Base_√2 ) для энтропийного кодирования (чтобы уйти от проблем алгоритма Хаффмана; а арифметическое кодирование тогда было ещё ограничено патентом, да и казалось медленным; а Дуда придумал энтропийное сжатие на асимметричных системах счисления позже, только в 2006-м году). Но, увы, реального сравнения с существовавшими на то время кодеками мои потуги не выдержали ни по качеству, ни по скорости. Я быстро это понял и бросил это дело.
В конечном итоге, не смотря на рост трафика и объема хранения цифровых данных в России и в мире мы способны существенно сократить необходимые для этого ресурсы.
Заключение под стать началу.
Хорошо, чёрт с ней, с сомнительной формой, теперь по существу. Что за MPEG-4? Это не алгоритм сжатия per se. Имеется в виду MPEG-4 AVC (H.264) 2003-го года? Судя по прилагающемуся примеру видео, да. А зачем с ним сравнивать, когда уже давно (как минимум с 2013-го года) есть H.265, а с 2020-го и H.266? А также, с 2015-го, и свободный AV1? Превосходство которых над H.264 как раз уровня того, что Вы заявляете для Вашего алгоритма.
Далее, для того, чтобы о чём-то предметно говорить, на мой взгляд, нужны:
исходный код кодека; и
предметные сравнения с существующими алгоритмами/кодеками - ну вот, например хотя бы по типу http://www.mattmahoney.net/dc/text.html
Правда, конечно, относительно легко такие сравнения провести только для сжатия без потерь - для сжатия с потерями потребуются ещё и убедительные метрики качества восстановления изображений/видео. Ваши два видео такого представления не дают, там в исходнике большая избыточность, цель сильно сжать его создателями не ставилась. Такое сравнение - это как хвастаться владением приёмов карате, демонстрируя их на детях, играющих в песочнице.
В общем, признаки в принципе интересных идей в этой публикации есть, но шансов на соответствие сильных заявлений реальности я не вижу.
Softservicerus Автор
14.02.2022 13:07-1Пришлите видео в h.264-265, без разницы, я сожму его в два раза хотя бы, и отдам вам его в контейнере mkv, не проблема, сранивите. potapov.i@list.ru
P.s.: только не часовой фильм, пожалуйста
Пары минут достаточно

3Dvideo
13.02.2022 12:46+9Позабавило, что 0 (ноль) графиков на статью) Я в позапрошлом году писал текст на тему: О талантах, деньгах и алгоритмах сжатия данных )
Я там писал, что русские инвесторы верят внутреннему ощущению, а не заказывают экспертизу, так что денег на то, что выше могут и дать)))) И это, повторюсь, хорошо, наши инвесторы должны терять деньги, чтобы научиться включать мозг. А если государственные деньги, то печально конечно. Государевы люди теряют деньги без последствий.
Также забавно, что мне сегодня аспирант прислал разбор отчета JPEG AI (разработка нового нейросетевого стандарта сжатия изображений) Performance Evaluation of Learning based Image Coding Solutions and Quality Metric, там очень хорошо разобрано, как сравнивать и измерять качество, даже если предельно новые методы ломают старые метрики. Выглядит контрастом по сравнению с тем, что выше)))))

sci_nov
13.02.2022 14:39+1Такое ощущение, что уже есть патент на это дело. На уровне девочки с обезъянкой :).

RolexStrider
13.02.2022 17:58+1Статья написана нейросетью!

VaalKIA
14.02.2022 01:05+4Судя по количеству пустых терминов, писал человек, специализацией которого является создание «семантических ядер» за доширак. Тут есть всё: фракталы Серпинского, коды Грея, РОЛы, Релеванты, Брютт, Маллат, Фреге, Гильбер, Кнут и Кант, Фасет и Дискрет, Резонанс и Рентген, хаОс и полтОс… прошу прощения: иконический денотат, конечно же. Ну а те кто заметил это (цитирую):
невозможно сжать изображение без потерь на более чем 2 %
, наверное, всё же поняли, что нам лупят какую-то дичь. К слову, сказать, в статье явно упустили, что можно упомянуть экономический эффект и тогда в семантическое ядро ещё можно вставить Карла Маркса и Капитал, а поскольку, это было некоторое время назад, то цепочку можно разбавить хронОсом и поносОм… иконическим денотатом второй степени, конечно же.
Softservicerus Автор
14.02.2022 13:13Пришлите видео в h.264-265, без разницы, я сожму его в два раза хотя бы, и отдам вам его в контейнере mkv, не проблема, сранивите. potapov.i@list.ru
P.s.: только не часовой фильм, пожалуйста
Пары минут достаточно

{kind=link}
OGR_kha
Где-то я это видел. А, точно, сериал "Кремниевая долина".
Softservicerus Автор
Посмотрите видео по ссылке внизу.