
 Привет, Хаброжители! Это исчерпывающее руководство поможет вам правильно разрабатывать бенчмарки, измерять ключевые метрики производительности приложений .NET и анализировать результаты. В книге представлены десятки кейсов, проясняющих сложные аспекты бенчмаркинга. Ее изучение позволит вам избежать распространенных ошибок, проконтролировать точность измерений и повысить производительность своих программ.
Привет, Хаброжители! Это исчерпывающее руководство поможет вам правильно разрабатывать бенчмарки, измерять ключевые метрики производительности приложений .NET и анализировать результаты. В книге представлены десятки кейсов, проясняющих сложные аспекты бенчмаркинга. Ее изучение позволит вам избежать распространенных ошибок, проконтролировать точность измерений и повысить производительность своих программ. Прочитав эту книгу, вы:
• ознакомитесь с лучшими практиками разработки бенчмарков и тестов производительности;
• научитесь избегать распространенных ошибок при проведении бенчмаркинга;
• узнаете об аппаратных и программных факторах, влияющих на производительность приложений;
• научитесь анализировать показатели производительности.
Ложные аномалии
Ложная аномалия — это ситуация, похожая на аномалию, но не связанная ни с какими проблемами. Ложная аномалия может быть как временнóй (если анализировать историю производительности), так и пространственной (если анализировать только результаты одной проверки).
Пример. Допустим, у нас есть тест, занимающий 100 мс:
public void MyTest() // 100 мс
{
DoIt(); // 100 мс
}Мы решили добавить объемные уведомления (200 мс), проверяющие, все ли в порядке:
public void MyTest() // 300 мс
{
DoIt(); // 100 мс
HeavyAsserts(); // 200 мс
}На графике производительности мы увидим нечто похожее на ухудшение производительности (со 100 до 300 мс), но с производительностью нет никаких проблем. Это ожидаемое изменение длительности теста. Если у вас недавно появилась аномалия, полезно проверить сначала изменения в исходном коде. Изменения, найденные в теле теста в начале исследования, могут избавить от нескольких часов бессмысленной работы. Можно также сработать на упреждение и договориться с членами команды о том, что каждый, кто намеренно вносит изменения, способные повлиять на производительность, должен их как-то помечать. Например, тест можно снабдить специальным комментарием или атрибутом. Также вы можете создать общее хранилище (базу данных, веб-сервис или даже обычный текстовый файл) со всей информацией о таких изменениях. Неважно, что вы выберете, если все участники команды будут знать, как просмотреть историю намеренных изменений производительности для каждого теста.
Аномалия не всегда означает, что у вас проблема. Они часто появляются по естественным причинам. Если вы постоянно разыскиваете аномалии и исследуете каждую из них, важно знать о ложных аномалиях, не связанных ни с какими проблемами.
Обсудим некоторые распространенные причины появления таких аномалий.
-
Изменения в тестах.
Это одна из самых распространенных ложных аномалий. Если вы вносите в тест изменения (добавляете или удаляете некоторую логику), очевидно, что его длительность может измениться. Таким образом, если у вас появляется аномалия, похожая на ухудшение производительности теста, первым делом нужно проверить, не вносились ли в него изменения. Второе, что нужно проверить, — наличие изменений, намеренно ухудшающих производительность (например, можно пожертвовать производительностью ради точности). -
Изменения порядка тестов.
Порядок тестов можно изменить в любой момент. На это может быть несколько причин, включая переименование тестов. Это может быть ощутимо, если в первый тест набора включена логика инициализации. Допустим, в наборе пять тестов в следующем порядке (проверка А): Test01, Test02, Test03, Test04, Test05. Платформа для тестирования использует лексикографический порядок выполнения тестов. При проверке В мы переименовываем Test05 в Test00. Благоприятные последствия этого переименования показаны в табл. 5.13. Скорее всего, это пример аномалии спаренного ухудшения/ускорения: теперь вместо Test01 медленным стал Test00. Мы уже обсуждали, что логику инициализации лучше вынести в отдельный метод, но это не всегда возможно. Если мы знаем о подобном эффекте первого теста, но ничего с этим сделать не можем, то все равно получим уведомление об аномалии.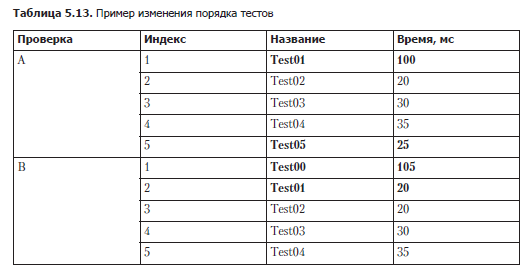
-
Изменения в аппаратных средствах агента непрерывной интеграции.
Если у вас есть возможность запускать тесты производительности на одном и том же агенте непрерывной интеграции (физическом устройстве) все время, это замечательно. Но этот агент может сломаться, а найти идентичную замену бывает нелегко. На производительность могут повлиять любые перемены в окружении, от небольшого изменения в номере модели процессора до объема памяти RAM. Сравнивать измерения с разных устройств всегда сложно, поскольку реальные изменения непредсказуемы. Если вы хотите применять нанобенчмарки, обычно вам нужен набор идентичных физических агентов непрерывной интеграции. -
Изменения в ПО агентов непрерывной интеграции.
Проблемы могут появиться и на том же агенте без замены аппаратных средств. Довольно часто администраторы устанавливают системные обновления. Это могут быть незначительные обновления системы безопасности или значительные обновления ОС (например, от Ubuntu 16.04 к Ubuntu 18.04). Любые изменения в окружении могут повлиять на производительность. Это приводит к тому, что на графике производительности отражается подозрительное ухудшение или ускорение без каких-либо изменений исходного кода. -
Изменения в наборе агентов непрерывной интеграции.
Только у самых везучих есть возможность запускать тесты на наборе агентов непрерывной интеграции с выделенными идентичными устройствами. Гораздо чаще встречается динамический пул агентов: нельзя предсказать, какое окружение будет использоваться для следующего запуска набора тестов. В таком наборе агентов что-то постоянно меняется: одни устройства выключаются, другие подключаются к работе, некоторые устройства обновляются, часть занята разработчиками, исследующими производительность, и т. д. В такой ситуации повышается дисперсия из-за постоянных скачков между устройствами и возникают аномалии производительности, основанные на изменениях в наборе агентов. На рис. 5.8 показана аномалия производительности в тесте MonoCecil в Rider для агентов из macOS, появившаяся около 20 октября. В исходном коде ничего не поменялось, ухудшение было вызвано плановым обновлением всех агентов из macOS. Процесс обновления потребляет ресурсы процессора и диска и влияет на производительность тестов (это был не специальный тест производительности, а обычный, запущенный на обычных агентах из набора). Как только обновление завершилось, производительность вернулась к нормальному уровню (если можно сказать «нормальный» в отношении теста с такой дисперсией).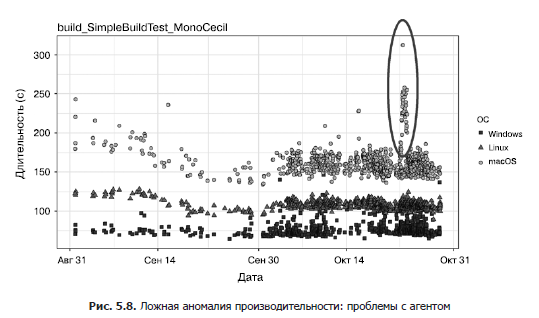
-
Изменения во внешнем мире.
Если у вас есть какие-то внешние зависимости, они могут стать постоянным источником аномалий производительности. К сожалению, избавиться от них не всегда возможно. Когда зависимость становится частью тестируемой логики, она проникает в ваше пространство производительности. Классическим примером подобной зависимости является внешний веб-сервис. Например, вы что-то загружаете из Интернета или тестируете метод идентификации.
У меня была подобная проблема с тестами NuGet Restore в Rider, которые проверяли, можно ли корректно и быстро восстанавливать пакеты. Первая версия тестов использовала nuget.org в качестве источника всех пакетов NuGet. К сожалению, эти тесты были очень нестабильны. Раз в день возникала ситуация, когда один из тестов упал из-за медленных ответов nuget.org. В следующий раз мы создали зеркало nuget.org и разместили его на локальном сервере. После этого у нас почти не было падений, но дисперсия этих тестов все еще была очень велика. При финальной итерации мы использовали локальный источник пакетов (все пакеты были загружены на диск перед запуском набора тестов). Мы получили почти стабильные тесты с низкой дисперсией. Необходимо заметить, что это не простая реструктуризация кода теста. Мы пожертвовали частью логики (загрузка пакетов с удаленного сервера) ради уровня ложной аномалии. -
Любые другие изменения.
Мир постоянно меняется. Что угодно может произойти в любую минуту. Вы всегда должны быть готовы столкнуться с ложными аномалиями производительности. Специалист по производительности, ответственный за обработку аномалий, должен знать, какие виды ложных аномалий часто встречаются в инфраструктуре этого проекта. Первым делом перед исследованием производительности нужно проверить, не является ли аномалия ложной. Эта простая проверка поможет вам сберечь время и предотвратить превращение ложной аномалии в ошибку 1-го рода (ложноположительную).
Скрытые проблемы и рекомендации
Обычно аномалии производительности сообщают нам о различных проблемах проекта. Вот некоторые из них.
-
Ухудшение производительности.
Это может показаться очевидным, но крупнейшая проблема при данной аномалии и есть ухудшение производительности. Обычно люди начинают тестировать производительность, стремясь предотвратить ухудшения. -
Скрытые ошибки.
Пропущенные уведомления являются ошибками в тестах, но похожие ошибки могут существовать и в рабочем коде. Если у теста высокая дисперсия, первое, о чем вы должны подумать: «Почему здесь такая дисперсия?» В большинстве случаев за ней скрывается недетерминированная ошибка. Например, это может быть состояние гонки или взаимная блокировка (с завершением в момент истечения времени, но без уведомления). -
Медленный процесс сборки.
Нужно слишком долго ждать, пока все тесты будут переданы на сервер непрерывной интеграции. Это обычное требование, которому должны соответствовать все тесты, после чего станет доступен установщик или развернут веб-сервис. Когда весь набор тестов занимает 30 мин или даже час, это приемлемо. Но если для этого требуется много часов, процесс разработки замедляется. -
Медленный процесс разработки.
Если тест стал «красным» и вы пытаетесь исправить ситуацию, нужно запускать его локально снова и снова после каждой попытки исправления. Если тест занимает 1 ч, за стандартный 8-часовой рабочий день у вас будет только восемь попыток. Более того, ждать результата теста сложа руки бессмысленно, поэтому разработчики часто переключаются на решение другой проблемы. Переключение контекста для разработчика всегда неприятно. К тому же большая продолжительность тестов подразумевает высокий уровень погрешности. Если тест занимает 1 ч, погрешность в несколько минут — это нормально. В подобной ситуации сложно выставить строгие уведомления (мы обсудим это позже). -
Непредсказуемо большая длительность.
Мы уже обсуждали большую длительность тестов и пришли к выводу: это не очень хорошо. Куда хуже, когда она непредсказуемо большая. Работать с производительностью таких тестов трудно. Если у вас есть ограничения времени (распространенное решение, поскольку тесты могут зависать), тест может быть нестабильным, поскольку его общая длительность иногда может превышать ограничение. -
Трудно установить уведомления.
Еще раз рассмотрим рис. 5.6. Вы видите график истории производительности теста распараллеливания из набора тестов IntelliJ IDEA. Некоторые из запусков могут занять 100 с (особенно в Windows), а некоторые — 4000 с (особенно в macOS). И те и другие значения можно наблюдать в результатах одной и той же проверки без каких-либо изменений. Представьте, что появляется ухудшение производительности. Как его определить? Даже если производительность ухудшается на 1000 с, это можно упустить, поскольку дисперсия слишком велика.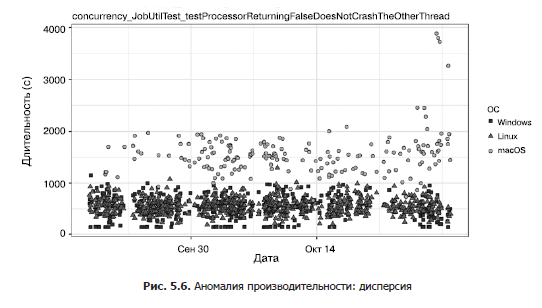
-
Пропущенные уведомления.
Я много раз видел тесты с «зеленой» историей производительности, выглядевшие примерно так: 12,6; 15,4; 300; 14,3; 300; 16,1 с… Типичный пример: мы отправили запрос и ждем ответа. Ограничение времени ожидания — 5 мин, но уведомления о том, что ответ получен, нет. Через 5 мин мы просто прекращаем ждать и заканчиваем тест с «зеленым» статусом. Это может показаться глупой ошибкой, но таких ошибок в реальности очень много. Подобные тесты легко обнаружить, если поискать тесты с очень высокими значениями. -
Неожиданные задержки в работе.
Сталкивались ли вы когда-нибудь с такой ситуацией: операция, которая обычно производится мгновенно, вдруг заставляет приложение зависнуть на несколько секунд? Подобное всегда раздражает пользователей. Существует много причин такого поведения. Обычно их сложно исправить, потому что у вас нет стабильного воспроизведения. Однако некоторые из них также могут вызвать выбросы на графике производительности. Если у вас систематически появляются выбросы на сервере непрерывной интеграции, можно добавить журнал, найти проблему и исправить ее. -
«Костыли» в логике теста.
У вас когда-нибудь были нестабильные тесты с состоянием гонки? Как их лучше всего исправлять? Существует неверный, но популярный способ исправления: введение там и сям Thread.Sleep. Обычно это исправляет нестабильность — тест снова становится постоянно «зеленым». Однако исчезают только симптомы проблемы, а не она сама. После одобрения такого исправления становится сложно снова воспроизвести ее. Также сложно найти тесты с такими «умными» исправлениями. К счастью, подобные «костыли» можно разглядеть на графиках производительности невооруженным глазом. Любые запросы Thread.Sleep или другие приемы, предотвращающие состояния гонки или похожие проблемы, невозможно спрятать от хорошего специалиста по производительности. -
Ложные аномалии.
Основная проблема ложных аномалий очевидна — вы тратите время на исследования, но не получаете полезного результата.
Существует несколько основных рекомендаций по работе с аномалиями производительности.
-
Систематический мониторинг.
Это самая важная рекомендация: нужно постоянно следить за аномалиями производительности. Поскольку у реального приложения их может быть сотни, можно использовать панель наблюдения: для каждой аномалии отсортировать все тесты по соответствующей метрике и посмотреть на верхнюю часть списка. Посмотрите на тесты с самой большой длительностью, дисперсией, выбросами, модальными значениями и т. д. Попытайтесь понять, откуда взялись эти аномалии. Скрываются ли за ними проблемы? Можно ли эти проблемы исправить? Можете смотреть на панель наблюдения раз в месяц, но полезнее делать это ежедневно: в этом случае можно отследить новые аномалии, как только они появляются. -
Серьезные аномалии нужно исследовать.
Если систематически отслеживать аномалии, можно найти много серьезных проблем с кодом. Иногда даже обнаружить проблемы с производительностью, не проверяемые тестами производительности. Также можно выявить проблемы в бизнес-логике, не проверяемые функциональными или модульными тестами. Иногда оказывается, что проблем нет: аномалия может быть ложной или естественной (вызванной естественными факторами, которые невозможно контролировать, например производительностью сети). Если вы не знаете, откуда взялась конкретная аномалия, стоит ее исследовать. Если не можете сделать это сейчас, создайте ошибку в программе для мониторинга ошибок или добавьте эту аномалию в список исследований производительности. Если вы будете игнорировать найденные аномалии, то можете пропустить серьезные проблемы, которые обнаружатся только на стадии производства. -
Берегитесь высокого уровня ложных аномалий.
Если увеличивается число ошибок 1-го рода (ложноположительных), системе мониторинга аномалий становится невозможно доверять и она теряет ценность. Лучше пропустить несколько реальных проблем и увеличить количество ошибок 2-го рода (ложноотрицательных), чем перегрузить свою команду ложными сигналами тревоги, которые могут свести на нет все попытки улучшить производительность. При виде аномалии производительности первым делом необходимо проверить наличие естественных причин. Обычно такие проверки не занимают много времени, но могут застраховать вас от бесполезных исследований. Вот несколько примеров проверок. - Проверка на изменения в тесте. Если кто-то менял исходный код теста, проверьте эти изменения.
- Проверка на изменения в порядке тестов. Просто сравните порядок тестов в текущей и предыдущей проверках.
- Проверка истории агентов непрерывной интеграции. Вы использовали один и тот же агент для текущих и предыдущих результатов? Не вносили ли вы каких-нибудь изменений в программные или аппаратные средства агента?
- Проверка типичных источников ложных аномалий. Если вы все время ищете аномалии производительности, то, вероятно, знаете самые распространенные причины ложных аномалий. Допустим, вы загружаете данные с внешнего сервера с 95 % рабочего времени. Если сервер не работает, вы пытаетесь связаться с ним, пока он снова не начнет работать. Подобное поведение часто может быть источником выбросов без каких-либо изменений. Если вы знаете, что какая-то группа тестов страдает от подобного феномена, первым делом нужно проверить в журнале сообщения о повторных попытках связаться с сервером.
-
Берегитесь привыкания к синдрому тревоги
Если вы можете отследить все проблемы с производительностью — прекрасно. Но нужно понимать, сколько ошибок может исследовать ваша команда. Если в очереди слишком много аномалий производительности, процесс исследования становится бесконечным и изматывающим. Нельзя все время решать проблемы, связанные с производительностью, нужно ведь и новые функции разрабатывать, и ошибки исправлять.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Бенчмарк
Caraul
Для обычных тестов сборочные системы предлагают историю прохождений, благо она простая - красный/зеленый тест. Бенчмарки как результат выдают не boolean, а кортеж значений - время прохождения, аллокации в поколениях и т.д. Нет ли где-то чего-то готового для хранения историй бенчмарков с графиками по параметрам, алертами и пр.?