

Чем больше у компании клиентов, тем выше объем полезных данных, на которых аналитики могут обучить предсказательные модели. Поэтому для развития логистических алгоритмов особый интерес представляют научные публикации исследователей из крупных азиатских, европейских и американских компаний.
Дата-сайентист из команды СберМаркета Дмитрий Руденко рассмотрел три научных статьи, посвященных применению машинного обучения для доставки товаров в международной компании Zalando и в двух китайских компаниях Meituan и Alibaba.
Привет! Меня зовут Дмитрий Руденко. В СберМаркете строю прогностические модели, которые варьируют прайс, предсказывают отсутствие товаров и необходимость предзамены.
Эта статья — адаптация моего доклада с Data Ёлки 2021. Я рассмотрю три публикации 2021 г., размещенные в ACM Digital Library. Если быть кратким, статьи освещают следующие вопросы:
- Как службе доставки строить оптимальные маршруты курьеров и точнее находить время в пути.
- Как компании варьировать цену скоропортящихся продуктов, чтобы получить наибольшую возможную прибыль.
- Как fashion-ретейлеру заблаговременно обнаружить проблемы с размерами одежды, если обратная связь от клиентов запаздывает.
В обзоре я не буду зарываться в детали реализации. Просто изложу в популярной форме главные находки из каждой статьи.
1. Как найти оптимальный маршрут доставки еды, опираясь на опыт курьеров
Исследователи. Meituan — китайская служба доставки еды из местных ресторанов. В третьем квартале 2020 г. компания обрабатывала 35 млн заказов в день. Инженеры пекинского отделения компании Gao C., Zhang F. и др. в 2021 г. опубликовали исследование A Deep Learning method for route and time prediction in food delivery service. Авторы предложили новый алгоритм оптимизации маршрутов доставки на основе глубокого обучения.
Задача. Служба доставки стремится максимизировать прибыль. Для этого нужно:
- показывать курьеру скорейший маршрут доставки, чтобы он успевал выполнить больше заказов;
- уложиться во время доставки, которое обещали клиенту.
Получается, задача заключается в оптимизации маршрута и точной оценке времени пути.
Проблемы. Для поиска маршрута есть графовые алгоритмы: поиск в ширину, алгоритм Дейкстры, Jump Point Search. Они находят глобальное оптимальное решение для детерминированной задачи, но в нашем кейсе есть неопределенности. Например, неизвестно точное время ожидания в ресторане — есть окно возможной задержки. Такие проблемы называются «задачи о приёмке и доставке с временными окнами» (англ. Pickup and Delivery Problem with Time Windows, PDPTW).
По мнению исследователей Meituan, предлагавшиеся ранее эвристические алгоритмы имеют важную проблему — не учитывают контекст перевозки отдельного заказа:
- в каком городе, районе и в какое время происходит доставка,
- каков опыт и особенности вождения конкретного курьера,
- как ранее вели себя другие курьеры относительно узлов маршрута.
Идея. Исследователи Meituan предложили задействовать в обучении опыт курьеров. Ведь сами доставщики заинтересованы в том, чтобы выбирать оптимальный маршрут с учётом текущей ситуации на дороге. Если агрегировать датасет с сотнями тысяч зафиксированных маршрутов, можно построить вероятностную модель. Такой подход учтёт факторы, влияющие на поведение курьеров в те или иные периоды дня и в разных локациях города.
Данные. Маршрут всегда начинается с пикап-пойнта, а заканчивается конечным местом доставки. Между крайними узлами могут быть другие пикап-пойнты и места доставки.

Пример маршрута доставки еды из публикации. Для оптимизации процесса часть заказов курьер забирает по пути. Так, заказ № 3 курьер забрал раньше (в 10:27), чем доставил заказ № 2 (в 10:43)
Датасет Meituan содержит сведения о маршрутах 430 млн заказов, доставленных 1,6 млн курьеров. Маршруты записаны в виде последовательностей координат с метками времени. Датасет содержит и другие данные: город, день недели, период дня с точностью до 10 минут, средняя скорость и численная оценка пунктуальности курьера, GPS-координаты пикап-пойнтов и мест доставки.
Решение. Для предсказания маршрутов и оценки времени аналитики Meituan предложили использовать нейросеть с разработанной ими архитектурой FDNET (Food Delivery Route and Time Prediction Deep Network).
 Архитектура нейросети FDNET состоит из двух модулей: 1) поиск наиболее вероятных маршрутов доставки и 2) предсказание времени перемещения между двумя узлами маршрута
Архитектура нейросети FDNET состоит из двух модулей: 1) поиск наиболее вероятных маршрутов доставки и 2) предсказание времени перемещения между двумя узлами маршрутаМодуль нейросети для предсказания маршрута построен на основе слоя рекуррентной нейронной сети из LSTM-узлов и слоя с механизмом внимания. Последний позволяет учесть поведенческие особенности выбора курьерами того или иного маршрута. Модуль предсказания оценки реализован на основе архитектуры Wide & Deep.
Итог. Результаты офлайн-экспериментов Meituan показали эффективность FDNET в сравнении с классическими методами машинного обучения: логистической регрессией, Random Forest и XGBoost. Метрика hit rate (доля точек найденного маршрута, соответствующих лучшему выбору), оказалась выше на 2–5%, а метрика качества ранжирования следующего узла пути MRR — на 1–3%.
На практике применение алгоритма сократило среднее время доставки на коротких маршрутах на 20 секунд, а среднюю длину пути — на 60 метров.
2. Как выставлять скидки на скоропортящиеся продукты, не проводя с ценой слишком много экспериментов
Исследователи. Аналитики J. Hua, L. Yan, H. Xu и C. Yang из Data-Science-подразделения Alibaba Group в Ханчжоу в августе 2021 г. опубликовали работу Markdowns in e-commerce fresh retail: a counterfactual prediction and multi-period optimization approach. Исследователи предложили новый алгоритм динамического ценообразования скоропортящихся продуктов.
Задача. В продуктовых магазинах много товаров, приходящих в негодность меньше чем за неделю: молоко, мясо, хлеб, многие виды овощей и фруктов. Если товар плохо покупается, магазину выгоднее продать его со скидкой. Иначе компания не только упустит прибыль, но и потеряет деньги на утилизации. Вопрос заключается в том, как выставить оптимальную скидку, чтобы обеспечить компании максимальный доход.
 Пример двух каналов продажи из публикации: слева экран приложения с обычными продажами, справа — для товаров с уценкой
Пример двух каналов продажи из публикации: слева экран приложения с обычными продажами, справа — для товаров с уценкойПроблемы. Обычно маркетологи используют детерминированные алгоритмы «на четвёртый день поставить скидку 50%». Но потребители по-разному относятся к изменению стоимости товаров разных категорий. Экономисты в таких случаях говорят, что у товаров разная эластичность спроса по цене — отношение относительного объёма спроса к относительному объёму товара. К тому же магазину выгоднее менять цену не один раз, а несколько — плавно увеличивать скидку по мере приближения ко дню Х, когда срок годности истечёт.
Сложность в том, что цены на большинство продуктов меняются нечасто. Трудно предсказать продажи товара по льготной цене, которой ранее на рынке не наблюдалось. А рандомизированное контрольное исследование сопряжено с риском ценовой дискриминации. Покупатель как минимум удивится, если узнает, что при прочих равных условиях другой клиент в том же приложении или магазине купил товар дешевле.
Наивный подход к решению задачи — использовать классическое машинное обучение. Взять цену в качестве одного из входных параметров, а продажи — как зависимую переменную. А дальше, как обычно, подгонять модель, минимизируя ошибку. Но распределение «спрос — цена» уценённых товаров значимо отличается от неуценённых, для которых и собраны исторические данные. К тому же большинство ML-алгоритмов являются «чёрными ящиками», в которых нельзя вычленить истинную взаимосвязь между спросом и ценой.
Идея. Аналитики Alibaba предложили использовать для прогноза кривых «цена — спрос» полупараметрическую модель, связывающую между собой 1) «чёрный ящик» машинного обучения и 2) классическую линейную модель. Машинное обучение делает то, что хорошо умеет: прогнозирует базовый спрос. А экономическая модель строит интерпретируемую параметрическую зависимость между ценой и спросом с учетом эластичности.
Эластичность спроса для определённого товара нам заранее не известна. Зато мы знаем, что эластичность различна для разных категорий продуктов. Категории можно представить в виде дерева, как на приведенном рисунке. К примеру, скоропортящийся салат «Айсберг» (отдельный артикул, SKU) находится в отделе сырых овощей (3-й уровень в дереве категорий), тот является частью отдела овощей (2-й уровень), а на верхнем 1-м уровне стоит общий отдел овощей, фруктов и ягод. Корнем дерева является магазин целиком. В модели структуру дерева кодируют с помощью процедуры one-hot encoding.
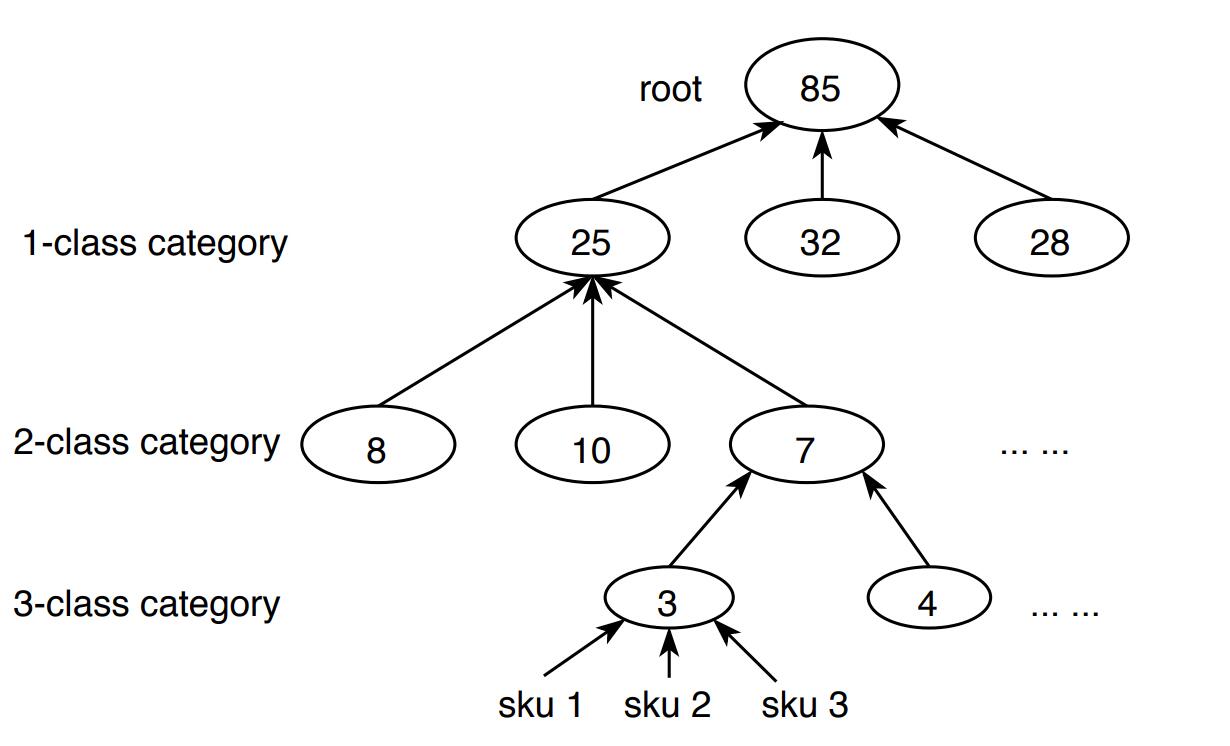
Пример дерева категорий из публикации. Категории разного класса соответствуют различному уровню подразделений магазина, SKU — отдельным артикулам. Число в кружке — количество артикулов, относящихся к данному узлу. Число для корня дерева (root) соответствует суммарному количеству продуктовых позиций магазина
Данные. Для обучения были применены исторические данные об изменении цен в электронном сервисе продажи свежих продуктов Freshippo, входящем в Alibaba Group. У магазина есть два канала продажи: 1) обычный канал, где товары продаются по розничной цене без скидки, 2) канал уценки, где покупатели приобретают товары со скидкой при условии, что общая стоимость покупки превышает определённую сумму.
Решение. Предложенная аналитиками полупараметрическая модель состоит из двух функций: параметрической модели эластичности g и непараметрической модели предсказания базового спроса h:
Обозначения:
-
— обычная цена i-го товара,
-
— прогнозируемая цена,
-
— средний уровень скидок за последние несколько недель,
-
— скидка для прогнозируемой цены,
-
— вектор, в котором методом one-hot encoding закодирована структура дерева категоризации,
-
— вектор эластичности.
Чтобы обучить модель и оптимизировать скидку для максимизации прибыли, исследователи использовали марковский процесс принятия решений. Неопределённость фактических продаж уценённых товаров моделировалась распределением Пуассона. В качестве метрики использовалась RMAE.
Итог. Предложенный алгоритм давал более точные предсказания, чем обычный бустинг, и насыщался сильно быстрее, чем алгоритм на основе глубокого обучения DeepIV при сопоставимой точности.
По сравнению с альтернативными алгоритмами предложенная модель оказалась единственной, для которой наблюдались кривые «спрос — цена», соответствующей экономической модели эластичности спроса по цене. На практике это повышает доверие клиентов: динамика изменения цен воспринимается как более предсказуемая.

Кривые «спрос — цена» для для четырёх случайно выбранных товаров (SKU A, B, C, D) и трех моделей: а) Tree model (XGBoost), b) DeepIV и c) модели, предложенной в публикации. Бары соответствуют стандартному отклонению для исторически наблюдаемых продаж, кривые — предсказаниям моделей
Модель была апробирована в офлайн-эксперименте и А/B-тестировании онлайн. Теперь алгоритм применяется в сервисе Freshippo для определения цен продуктов в электронной коммерции и розничной торговле.
3. Как детектировать проблемы с несоответствием размеров одежды при долгой обратной связи
Исследователи. Zalando SE — европейский fashion-ретейлер, продающий онлайн одежду, обувь и аксессуары. По итогам 2020 г. выручка компании составила 7,9 млрд евро. Команда аналитиков из берлинского отделения Zalando SE (Nestler A. и др.) и Университета Париж-Сакле (Hajjar K.) в августе 2021 г. опубликовала работу SizeFlags: reducing size and fit related returns in fashion e-commerce. Исследователи предложили байесовскую модель, которая снижает число возвратов заказов, обусловленных тем, что размер одежды не соответствует ожиданиям клиентов.
Задача. Выбирать одежду онлайн сложно. Покупатели возвращают 60% заказов из-за неправильного размера. Причины понятны: размерные сетки производителей не одинаковы, да и индивидуальные параметры тела отличаются от стандартных параметров моделей. Но если решить задачу даже наполовину, издержки на доставку товаров снизятся на 30%.
Данные. Исходный датасет исследователей содержал фотографии предметов одежды и статистическую информацию по возврату. В процессе построения модели аналитики предложили дополнить набор данных откликами фотомоделей, которые снимаются в продаваемых предметах одежды для демонстрации товаров на сайте ретейлера.
Идея. Авторы публикации предложили ввести
где
Ситуация возврата моделируется биномиальным распределением: клиент или возвращает товар, или оставляет у себя. Обозначим среднее значение распределения для категории
Запишем систему из двух правил, определяющих несоответствие размера:
Чтобы выбрать
Проблемы. Предлагаемый статистический подход на практике связан с несколькими трудностями:
- «холодный старт»: мы не узнаем о несоответствии размера, пока не начнем его продавать и не накопим статистику по возвратам;
- ограничение общего времени продажи: товары из свежих дизайнерских коллекций продаются очень быстро. Компания может продать весь товар, не подозревая о проблеме;
- ограничение времени отклика: возвраты приходят не мгновенно, заказ может идти по почте несколько недель.
В результате модель может работать с незначительной частью реальных заказов.
Решение. Биномиальное распределение имеет сопряженное бета-распределение, которое вводит два фиксированных параметра — α и β. Бета-распределение позволяет более гибко учесть контекст успешных исходов и внести смещение на основе информации, которую мы знаем о товаре априорно. Например, опросить фотографируемых моделей: как им одежда — большая, маленькая, подходит или нет. И задать три уровня:
- Всё хорошо.
- Возможно, не подходит.
- Точно не подходит.
Конечную функцию вероятности можно представить следующим образом:
Переформулируем правило поиска проблемных товаров:
Однако мы не можем полагаться только на ответы фотомоделей. Ведь они имеют стандартные фигуры и могут перемерить лишь небольшую долю товаров. Чтобы расширить покрытие для разных размерных сеток, исследователи решили воспользоваться дополнительной информацией — фотографиями одежды. Для этого инженеры обучили сверточную нейросеть SizeNet на фотографиях и данных о продажах и возвратах.
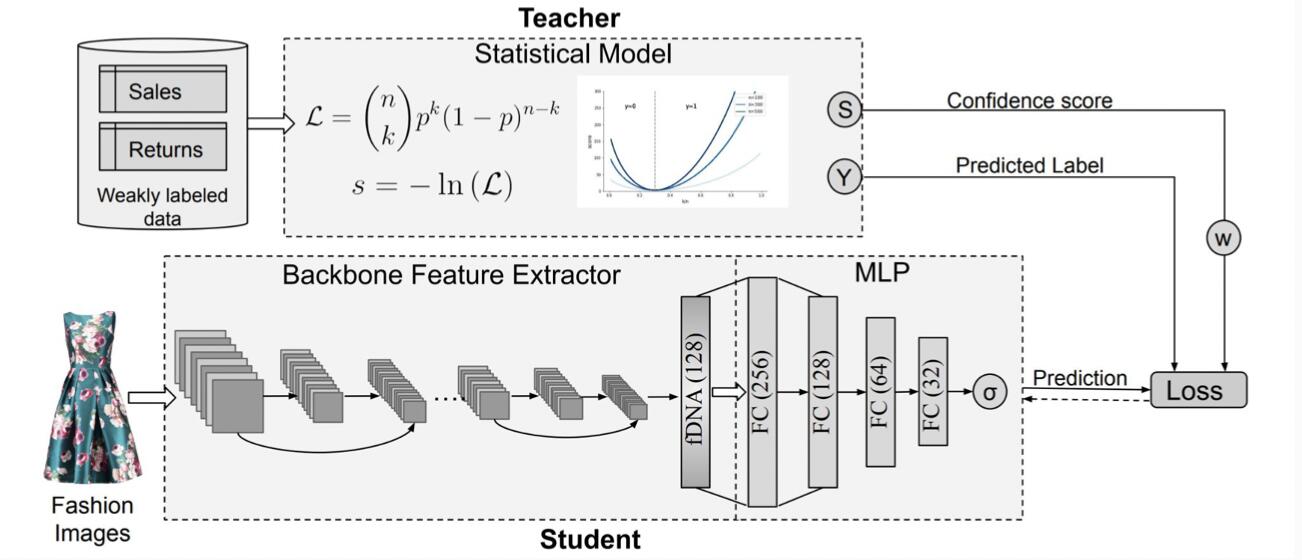
Архитектура сверточной сети SizeNet, обучающейся определять несоответствие размера по фотографиям по статистике возвратов

Процесс обработки заказа сводит вместе три фидбэка от 1) клиентов, 2) моделей и 3) нейросети, обученной на фотографиях одежды и статистике возвратов
Итог. Применение модели уменьшило число возвратов и заказов, в которых пользователи остались недовольны, на 20%. Наилучшие результаты были достигнуты при использовании обратной связи от всех перечисленных каналов.
Заключение
Улучшения качества предсказаний ML-моделей в электронной коммерции можно достигнуть, если учитывать контекст ситуации и реальный опыт участников процесса, например курьеров, доставляющих продукты, и фотомоделей, участвующих в съемке продаваемых предметов одежды.
Сочетание моделей машинного обучения с классическими экономическими моделями позволяет получать интерпретируемые результаты. За счет этого решения компании, связанные, например, с изменением стоимости товаров, воспринимаются клиентами как более логичные и последовательные, чем те, что получаются при лобовом применении стандартных ML-алгоритмов.
Комментарии (4)

XaBoK
29.03.2022 00:41Решение Alibaba, похоже, тоже очень специфичное. Для e-com гиганта с топовой инвентаризацией и автоматизацией склада, либо с очень дешевой рабочей силой. Определить спрос и цену мало, если нельзя знать срок и стоимость каждого отдельного товара.

Asimandia Автор
29.03.2022 11:27Склад- это то, от чего сейчас делается e-commerce. Мы в Сбермаркете тоже прорабатываем поставку данных о сроках годности от наших партнеров, чтобы лучше контролировать даже внешние склады.
Условно если у магазина А подключенного к Сбермаркету кончается товар, мы об этом должны знать и выключать его с нашей витрины немного заранее, потому что зачастую остатки не очень хороший опыт несут для клиентов. Условно, если остался один банан, то товар все еще в наличии, но его показывать на витрине не очень целесообразно.
XaBoK
Интересно, для Meituan, насколько критичны эти 20 секунд и 60 метров в задаче коммивояжёра? Стоило ли заморачиваться по усилиям и финансам ради такого выигрыша. Тот же Waze использует историю поездок и реальные маршруты других пользователей. Учитывая, что им всё равно нужно интегрировать какие то системы трафика, то существующие системы навигации не выглядят устаревшим решением. Хотя может у них свои нюансы. Типа обычным делом является доставщик на скутере, который едет по тротуару и игнорирует правила или пеший курьер, который лазит через заборы.
Asimandia Автор
Тут ценность в том, что менее опытным курьерам можно подсказать правильную последовательность доставок/пикапов. 20 секунд и 60 метров- это среднее детектированное отклонение, даже учитывая тех, кто в тестовой группе не пользовался роутами модели. Скорее всего итоговый отложенный отклик даже больше. Но если считать цифрами их головы: каждый заказ по 30 минут -> 20 секунд это чуть больше одного процента прироста. Думаю ускорение на 1% в их масштабах может стоить затраченных ресурсов, ведь модельку все же легче масштабировать, чем нанимать еще 500 курьеров по всей стране.
Насчет маршрутов других курьеров: тут встает задача о том, как выбирать роуты других курьеров и как их мерджить на разных сегментах. Meituan эту проблему частично решают.